

A web já não é mais a mesma de antes. Hoje em dia, quase todos os sites que você visita são movidos por JavaScript e carregam conteúdo dinamicamente — pense em rolagem infinita, pop-ups e painéis que só revelam seus segredos depois de um ou dois cliques. Na prática, impressionantes 98,7% de todos os sites já usam JavaScript, o que significa que as ferramentas de scraping à moda antiga, que só leem HTML estático, deixam passar uma enorme quantidade de dados valiosos. Se você já tentou extrair preços de produtos de um e-commerce moderno ou puxar anúncios imobiliários de um mapa interativo, sabe bem a frustração: os dados que você quer simplesmente não estão no código-fonte.
É aí que entra o scraping com Selenium. Como alguém que passou anos criando ferramentas de automação — e, sim, extraindo dados de bem mais sites do que deveria —, posso afirmar: dominar o Selenium é um superpoder para quem precisa de dados dinâmicos e atualizados. Neste tutorial prático de web scraping com Selenium, vou mostrar as etapas principais — da configuração à automação — e explicar como combinar Selenium com Thunderbit para obter dados estruturados e prontos para exportação. Seja você analista de negócios, profissional de vendas ou apenas um usuário curioso de Python, vai sair daqui com habilidades práticas e algumas risadas (porque, convenhamos, depurar seletores XPath também fortalece o carácter).
Experimente o Raspador Web IA do Thunderbit
O que é Selenium e por que usá-lo para web scraping?
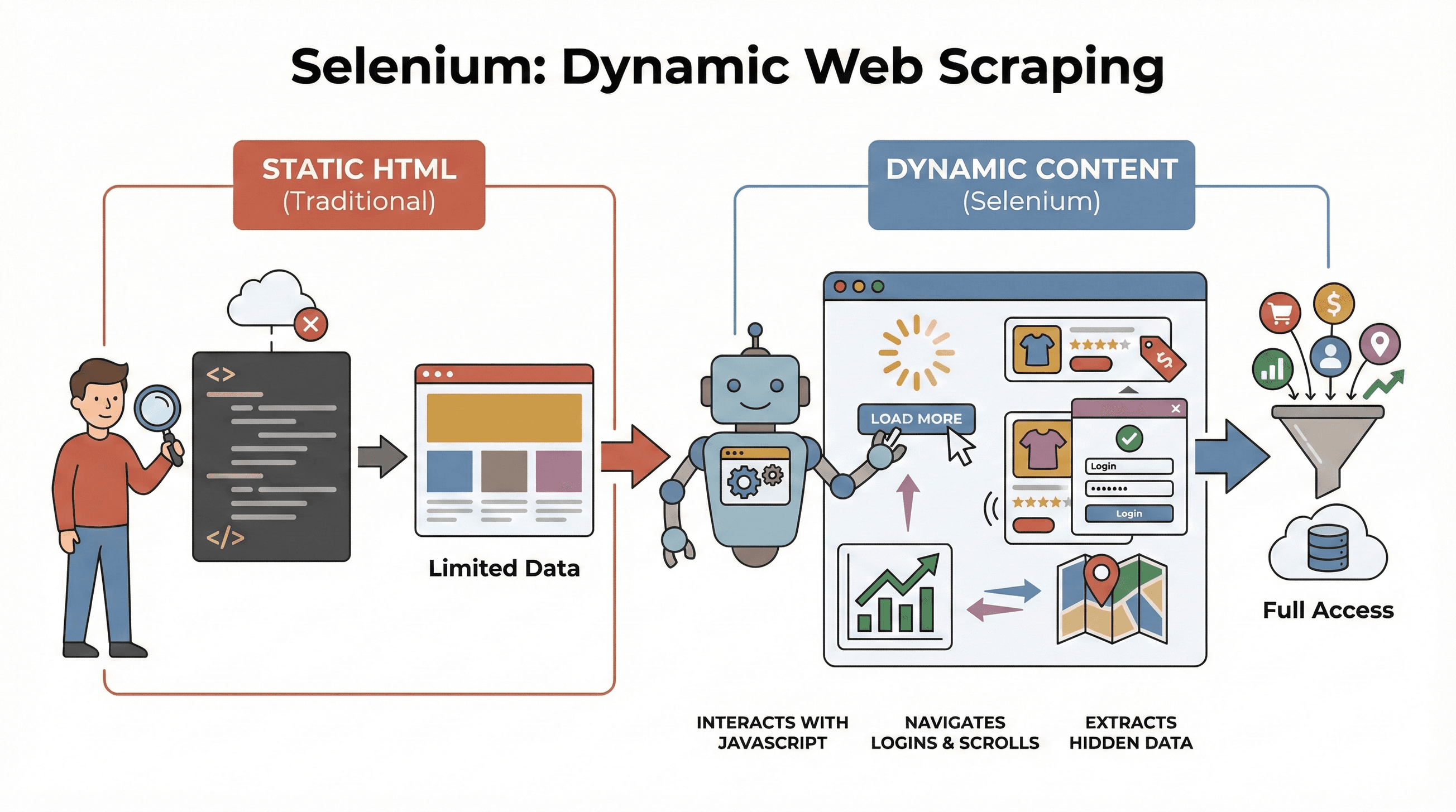 Vamos começar pelo básico. Selenium é um framework de código aberto que permite controlar um navegador de verdade — como Chrome ou Firefox — com código. Pense nele como um robô capaz de abrir páginas, clicar em botões, preencher formulários, rolar a página e até executar JavaScript, exatamente como um utilizador humano. Isso faz muita diferença porque a maioria dos sites modernos não mostra todos os dados logo de início. Em vez disso, carrega o conteúdo de forma dinâmica, muitas vezes depois de você interagir com a página.
Vamos começar pelo básico. Selenium é um framework de código aberto que permite controlar um navegador de verdade — como Chrome ou Firefox — com código. Pense nele como um robô capaz de abrir páginas, clicar em botões, preencher formulários, rolar a página e até executar JavaScript, exatamente como um utilizador humano. Isso faz muita diferença porque a maioria dos sites modernos não mostra todos os dados logo de início. Em vez disso, carrega o conteúdo de forma dinâmica, muitas vezes depois de você interagir com a página.
O que é data scraping e como fazer em 2026 Get Started Free
Por que isso importa no scraping? Ferramentas tradicionais como BeautifulSoup ou Scrapy são ótimas para HTML estático, mas não conseguem “ver” nada que seja carregado por JavaScript depois do carregamento inicial da página. O Selenium, por outro lado, consegue interagir com a página em tempo real, o que o torna perfeito para:
- Extrair listas de produtos que só aparecem depois de clicar em “Carregar mais”
- Capturar preços ou avaliações que são atualizados dinamicamente
- Navegar por formulários de login, pop-ups ou rolagem infinita
- Extrair dados de painéis, mapas ou outros elementos interativos
Em resumo, o Selenium é a ferramenta ideal quando você precisa extrair dados que só aparecem depois de a página terminar de carregar — ou depois de uma ação do utilizador.
Principais etapas para web scraping com Python e Selenium
O scraping com Selenium resume-se a três etapas essenciais:
| Etapa | O que você faz | Por que isso importa |
|---|---|---|
| 1. Configuração do ambiente | Instalar Selenium, WebDriver e bibliotecas Python | Deixar as ferramentas prontas e evitar dores de cabeça na configuração |
| 2. Localização de elementos | Encontrar os dados que você quer usando IDs, classes, XPath etc. | Apontar para as informações certas, mesmo que estejam escondidas por JavaScript |
| 3. Extração e salvamento de dados | Extrair textos, links ou tabelas e salvar em CSV/Excel | Transformar dados brutos da web em algo útil |
Vamos mergulhar em cada etapa com exemplos práticos e código que você pode copiar, adaptar e depois mostrar com orgulho aos amigos.
Etapa 1: Configurando o seu ambiente Python com Selenium
Antes de mais: você precisa instalar o Selenium e um driver de navegador (como o ChromeDriver para o Chrome). A boa notícia? Nunca foi tão fácil.
Instale o Selenium
Abra o terminal e execute:
pip install selenium
Obtenha um WebDriver
- Chrome: faça o download do ChromeDriver (verifique se corresponde à sua versão do Chrome).
- Firefox: faça o download do GeckoDriver.
Dica profissional: com o Selenium 4.6+, você pode usar o Selenium Manager para descarregar os drivers automaticamente, então talvez já nem seja preciso mexer nas variáveis de PATH (docs).
O seu primeiro script em Selenium
Aqui vai um “hello world” rápido para Selenium:
from selenium import webdriver
driver = webdriver.Chrome() # Ou webdriver.Firefox()
driver.get("https://example.com")
print(driver.title)
driver.quit()
Dicas de resolução de problemas:
- Se aparecer o erro “driver not found”, confira o PATH ou use o Selenium Manager.
- Verifique se as versões do navegador e do driver são compatíveis.
- Se estiver num servidor sem interface gráfica (headless), veja as dicas de modo headless abaixo.
Etapa 2: Localizando elementos da web para extração de dados
Agora vem a parte divertida: dizer ao Selenium quais dados você quer. Os sites são construídos com elementos — divs, spans, tabelas e muito mais — e o Selenium oferece várias formas de os encontrar.
Estratégias comuns de localização
By.ID: encontra um elemento com um ID únicoBy.CLASS_NAME: encontra elementos por classe CSSBy.XPATH: usa expressões XPath (super flexível, mas pode ser frágil)By.CSS_SELECTOR: usa seletores CSS (ótimo para consultas complexas)
Veja como usá-los:
from selenium.webdriver.common.by import By
# Encontrar por ID
price = driver.find_element(By.ID, "price").text
# Encontrar por XPath
title = driver.find_element(By.XPATH, "//h1").text
# Encontrar todas as imagens de produtos por seletor CSS
images = driver.find_elements(By.CSS_SELECTOR, ".product img")
for img in images:
print(img.get_attribute("src"))
Dica profissional: use sempre o localizador mais simples e estável possível (ID > classe > CSS > XPath). E, se estiver a extrair uma página que carrega dados com atraso, use esperas explícitas:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
price_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".price")))
Isto evita que o seu script fique bloqueado caso os dados demorem um segundo a aparecer.
Etapa 3: Extraindo e salvando dados
Depois de encontrar os elementos, é hora de capturar os dados e guardá-los em algum lugar útil.
Extraindo textos, links e tabelas
Imagine que você está a extrair uma tabela de produtos:
data = []
rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
data.append([cell.text for cell in cells])
Salvando em CSV com Pandas
import pandas as pd
df = pd.DataFrame(data, columns=["Nome", "Preço", "Stock"])
df.to_csv("products.csv", index=False)
Você também pode guardar em Excel (df.to_excel("products.xlsx")) ou até enviar para o Google Sheets usando a API deles.
Exemplo completo: extraindo títulos e preços de produtos
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome()
driver.get("https://example.com/products")
data = []
products = driver.find_elements(By.CLASS_NAME, "product-card")
for p in products:
title = p.find_element(By.CLASS_NAME, "title").text
price = p.find_element(By.CLASS_NAME, "price").text
data.append([title, price])
driver.quit()
df = pd.DataFrame(data, columns=["Título", "Preço"])
df.to_csv("products.csv", index=False)
Selenium vs. BeautifulSoup e Scrapy: o que torna o Selenium único?
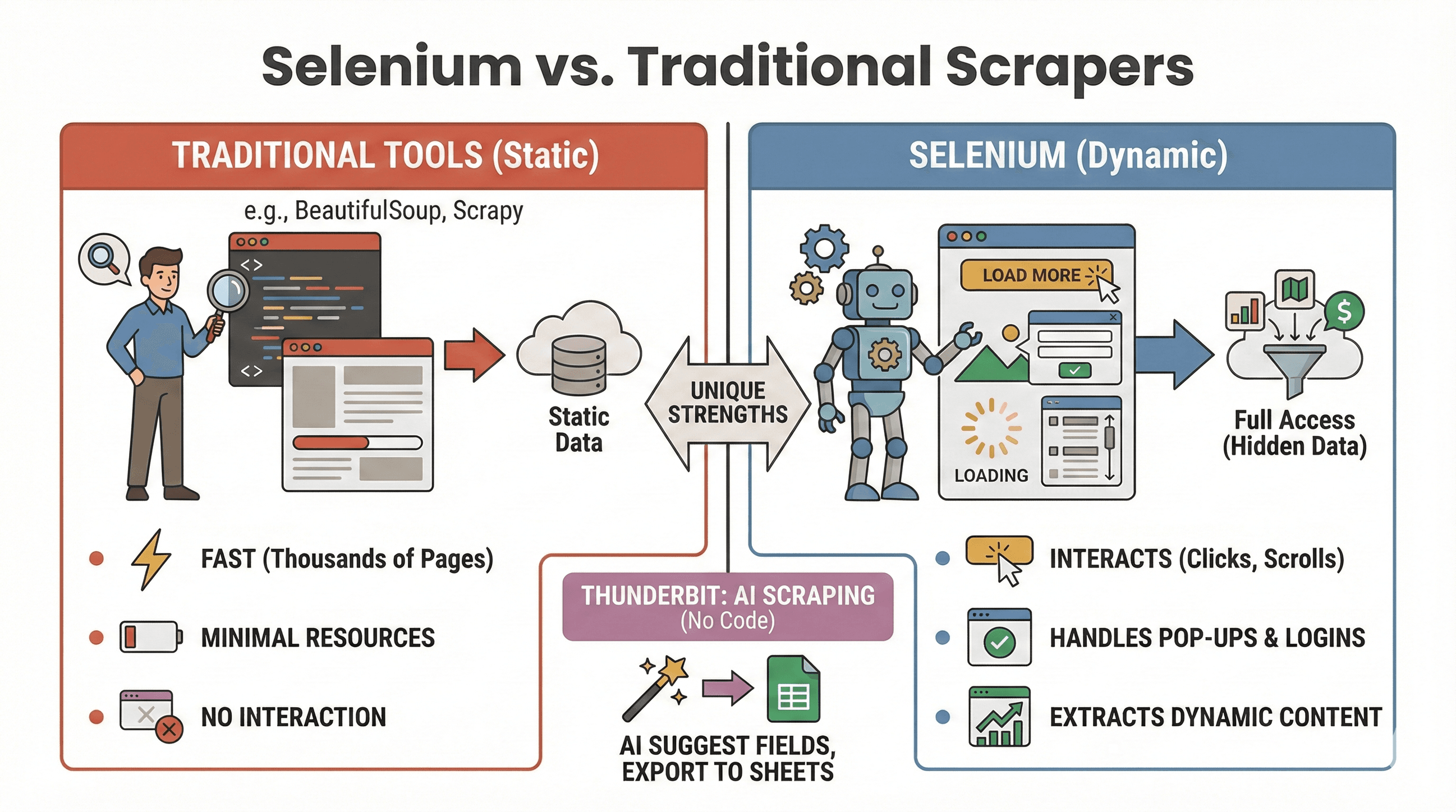 Vamos fechar a questão: quando usar Selenium, e quando algo como BeautifulSoup ou Scrapy é uma escolha melhor? Aqui vai uma comparação rápida:
Vamos fechar a questão: quando usar Selenium, e quando algo como BeautifulSoup ou Scrapy é uma escolha melhor? Aqui vai uma comparação rápida:
| Ferramenta | Melhor para | Lida com JavaScript? | Velocidade e uso de recursos |
|---|---|---|---|
| Selenium | Sites dinâmicos/interativos | Sim | Mais lento, usa mais memória |
| BeautifulSoup | Extração simples de HTML estático | Não | Muito rápido, leve |
| Scrapy | Rastreamento em alto volume de sites estáticos | Limitado* | Super rápido, assíncrono, pouca RAM |
| Thunderbit | Scraping sem código para negócios | Sim (IA) | Rápido para tarefas pequenas/médias |
*O Scrapy consegue lidar com algum conteúdo dinâmico usando plugins, mas esse não é o seu ponto forte (ScrapingBee).
Quando usar Selenium:
- Os dados só aparecem depois de clicar, rolar a página ou fazer login
- Você precisa interagir com pop-ups, rolagem infinita ou dashboards dinâmicos
- Scrapers estáticos simplesmente não dão conta
Quando usar BeautifulSoup/Scrapy:
- Os dados já estão no HTML inicial
- Você precisa extrair milhares de páginas rapidamente
- Quer usar o mínimo possível de recursos
E, se quiser saltar a parte da programação, o Thunderbit permite extrair sites dinâmicos com IA — basta clicar em “Sugerir campos com IA” e exportar para Sheets, Notion ou Airtable. (Falaremos mais disso abaixo.)
Como extrair qualquer site usando IA Get Started Free
Automatizando tarefas de web scraping com Selenium e Python
Vamos ser sinceros: ninguém quer acordar às 2 da manhã para executar um script de scraping. A boa notícia é que você pode automatizar o seu trabalho com Selenium usando as ferramentas de agendamento do Python ou o agendador do seu sistema operativo (como cron no Linux/Mac ou o Agendador de Tarefas no Windows).
Usando a biblioteca schedule
import schedule
import time
def job():
# Seu código de scraping aqui
print("Extraindo...")
schedule.every().day.at("09:00").do(job)
while True:
schedule.run_pending()
time.sleep(1)
Ou com cron (Linux/Mac)
Adicione isto ao seu crontab para executar a cada hora:
0 * * * * python /path/to/your_script.py
Dicas para automação:
- Execute o Selenium em modo headless (veja abaixo) para evitar pop-ups da interface gráfica.
- Registe erros e envie alertas para si mesmo se algo correr mal.
- Feche sempre o navegador com
driver.quit()para libertar recursos.
Aumentando a eficiência: dicas para um scraping com Selenium mais rápido e confiável
O Selenium é poderoso, mas pode ser lento e consumir muitos recursos se você não tiver cuidado. Veja como acelerar tudo e evitar dores de cabeça comuns:
1. Execute em modo headless
Não há necessidade de ver o Chrome abrir e fechar cem vezes. O modo headless executa o navegador em segundo plano:
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.headless = True
driver = webdriver.Chrome(options=opts)
2. Bloqueie imagens e outros conteúdos desnecessários
Por que carregar imagens se você só está a extrair texto? Bloqueie-as para acelerar o carregamento das páginas:
prefs = {"profile.managed_default_content_settings.images": 2}
opts.add_experimental_option("prefs", prefs)
3. Use localizadores eficientes
- Prefira IDs ou seletores CSS simples em vez de XPaths complexos.
- Evite usar
time.sleep()— use esperas explícitas (WebDriverWait) no lugar.
4. Randomize os atrasos
Adicione pausas aleatórias para imitar a navegação humana e evitar bloqueios:
import random, time
time.sleep(random.uniform(1, 3))
5. Alterne user agents e IPs (se necessário)
Se você estiver a extrair muito conteúdo, alterne a string do user agent e considere usar proxies para evitar medidas simples anti-bot.
6. Gerencie sessões e erros
- Use blocos try/except para tratar elementos ausentes com elegância.
- Registe erros e tire capturas de ecrã para depuração.
Para mais dicas de otimização, confira o guia da BrowserStack.
Avançado: combinando Selenium com Thunderbit para exportação estruturada de dados
É aqui que as coisas ficam mesmo interessantes — especialmente se você quiser poupar tempo na limpeza e exportação de dados.
Depois de extrair dados brutos com o Selenium, você pode usar o Thunderbit para:
- Detetar campos automaticamente: a IA do Thunderbit pode ler as suas páginas extraídas ou CSVs e sugerir nomes de colunas (“Sugerir campos com IA”).
- Scraping de subpáginas: se tiver uma lista de URLs (como páginas de produtos), o Thunderbit pode visitar cada uma delas e enriquecer a sua tabela com mais detalhes — sem código extra.
- Enriquecimento de dados: traduzir, categorizar ou analisar dados em tempo real.
- Exportar para qualquer lugar: exportação com um clique para Google Sheets, Airtable, Notion, CSV ou Excel.
Exemplo de fluxo de trabalho:
- Use o Selenium para extrair uma lista de URLs e títulos de produtos.
- Exporte os dados para CSV.
- Abra o Thunderbit, importe o CSV e deixe a IA sugerir os campos.
- Use o scraping de subpáginas do Thunderbit para puxar mais detalhes (como imagens ou especificações) de cada URL de produto.
- Exporte o conjunto final de dados estruturados para Sheets ou Notion.
Esta combinação poupa horas de limpeza manual e permite que você se concentre na análise, e não na luta com dados desorganizados. Para saber mais sobre este fluxo, confira o guia de Selenium do Thunderbit.
Exporte dados do Selenium com a IA do Thunderbit
Boas práticas e solução de problemas para web scraping com Selenium
Web scraping é um pouco como pescar: às vezes você apanha um peixe grande, às vezes acaba preso nas algas. Veja como manter os seus scripts fiáveis — e éticos:
Boas práticas
- Respeite o robots.txt e os termos do site: verifique sempre se a extração é permitida.
- Controle o ritmo das requisições: não sobrecarregue os servidores — adicione atrasos e fique atento a erros HTTP 429.
- Use APIs quando houver: se os dados estiverem disponíveis publicamente via API, use essa opção — é mais segura e confiável.
- Extraia apenas dados públicos: evite informações pessoais ou sensíveis e observe as leis de privacidade.
- Lide com pop-ups e CAPTCHAs: use o Selenium para fechar pop-ups, mas tenha cuidado com CAPTCHAs — eles são difíceis de automatizar.
- Randomize user agents e atrasos: ajuda a evitar deteção e bloqueios.
Erros comuns e correções
| Erro | O que significa | Como corrigir |
|---|---|---|
NoSuchElementException | Não foi possível encontrar o elemento | Revise o localizador; use esperas |
| Erros de timeout | A página ou o elemento demorou demasiado | Aumente o tempo de espera; verifique a velocidade da rede |
| Incompatibilidade entre driver e navegador | O Selenium não consegue abrir o navegador | Atualize as versões do driver e do navegador |
| Falhas na sessão | O navegador fechou inesperadamente | Use modo headless; gerencie os recursos |
Para mais dicas de solução de problemas, veja o tutorial de Selenium do Thunderbit.
Conclusão e principais aprendizados
O web scraping dinâmico já não é exclusivo de programadores hardcore. Com Python e Selenium, você pode automatizar qualquer navegador, interagir com os sites mais complicados e carregados de JavaScript e extrair os dados de que a sua empresa precisa — seja para vendas, pesquisa ou simplesmente para satisfazer a sua curiosidade. Lembre-se:
- O Selenium é a ferramenta ideal para sites dinâmicos e interativos.
- As três etapas principais: configurar, localizar, extrair e guardar.
- Automatize os seus scripts para manter os dados sempre atualizados.
- Otimize velocidade e confiabilidade com modo headless, esperas inteligentes e localizadores eficientes.
- Combine Selenium com Thunderbit para estruturar e exportar dados com facilidade — especialmente se quiser evitar a dor de cabeça das folhas de cálculo.
Pronto para testar por conta própria? Comece com os exemplos de código acima e, quando estiver pronto para levar o seu scraping ao próximo nível, experimente o Thunderbit para limpeza e exportação instantâneas de dados com IA. E, se quiser aprofundar ainda mais, confira o Blog do Thunderbit com análises detalhadas, tutoriais e o que há de mais recente em automação web.
Boas extrações — e que os seus seletores encontrem sempre o que você procura.
Experimente o Raspador Web IA do Thunderbit gratuitamente Get Started Free
FAQs
1. Por que devo usar Selenium para web scraping em vez de BeautifulSoup ou Scrapy?
O Selenium é ideal para extrair sites dinâmicos, em que o conteúdo carrega depois de ações do utilizador ou da execução de JavaScript. BeautifulSoup e Scrapy são mais rápidos para HTML estático, mas não conseguem interagir com elementos dinâmicos nem simular cliques e rolagens.
2. Como faço o meu scraper com Selenium ficar mais rápido?
Use o modo headless, bloqueie imagens e recursos desnecessários, use localizadores eficientes e adicione atrasos aleatórios para imitar a navegação humana. Veja o guia da BrowserStack para mais dicas.
3. Posso agendar tarefas de scraping com Selenium para correr automaticamente?
Sim! Use a biblioteca schedule do Python ou o agendador do seu sistema operativo (cron ou Agendador de Tarefas) para executar scripts em intervalos definidos. Automatizar o scraping ajuda a manter os seus dados atualizados.
4. Qual é a melhor forma de exportar dados extraídos com Selenium?
Use o Pandas para guardar os dados em CSV ou Excel. Para exportações mais avançadas (Google Sheets, Notion, Airtable), importe os seus dados para o Thunderbit e use os recursos de exportação com um clique.
5. Como posso lidar com pop-ups e CAPTCHAs no Selenium?
Você pode fechar pop-ups localizando e clicando nos botões de fechar. CAPTCHAs são muito mais difíceis — se encontrar um, considere usar uma solução manual ou um serviço de resolução de captcha e respeite sempre os termos de serviço do site.
Quer ver mais tutoriais de scraping, dicas de automação com IA ou as últimas novidades sobre ferramentas de dados para negócios? Assine o Blog do Thunderbit ou confira o nosso canal no YouTube para demonstrações práticas.
Saiba mais




