

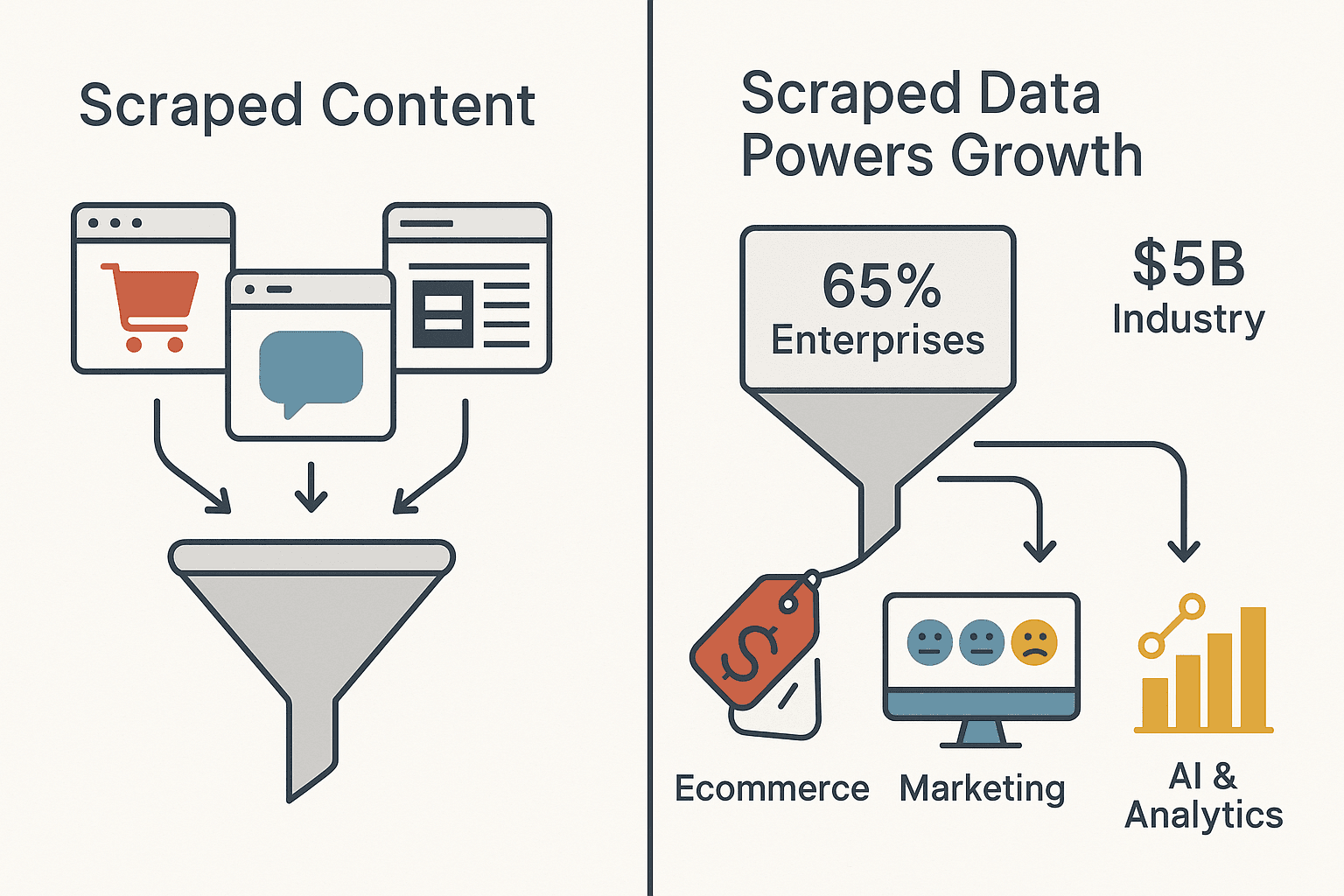
Já se perguntou como algumas empresas parecem saber sempre o que os concorrentes estão a cobrar, quais produtos estão em alta ou o que os clientes estão a dizer — antes de toda a gente? Não é magia, nem é só uma sala cheia de estagiários colados aos ecrãs. O segredo é o conteúdo raspado: dados recolhidos automaticamente de sites e fontes online, e depois transformados em inteligência de negócio acionável. No cenário digital de hoje, o conteúdo raspado está a impulsionar tudo, desde guerras de preços no ecommerce até à análise de sentimento em tempo real no marketing. Na verdade, 65% das empresas já usam web scraping para alimentar IA e analytics, e o setor global de web scraping já vale quase US$ 5 bilhões.
Extraia dados de qualquer site usando IA Get Started Free
Como alguém que passou anos a criar ferramentas de automação e IA — e, sim, a raspar uma boa quantidade de dados da web —, vi em primeira mão como o conteúdo raspado está a remodelar a estratégia de negócio. Mas com grandes dados vem grande responsabilidade — sobretudo quando o assunto é conformidade legal e qualidade dos dados. Vamos perceber o que é, de facto, o conteúdo raspado, porque importa, como usá-lo de forma responsável e porque Thunderbit é a minha principal escolha para tirar o máximo partido deste recurso poderoso.
Conteúdo Raspado: os fundamentos explicados
Vamos começar pelo básico. Conteúdo raspado é qualquer dado extraído de sites ou plataformas online através de ferramentas automatizadas — como bots, scripts ou agentes de IA. Em vez de copiar e colar informações manualmente, software de web scraping consegue recolher, em escala e em formato estruturado, desde preços e avaliações de produtos até imagens e dados de contacto.
Fontes fiáveis como DataDome definem data scraping como “o processo de extrair dados específicos, em formato estruturado, de sites ou fontes online publicamente disponíveis”. Em termos simples: um scraper visita uma página, recolhe as informações de que precisa (como nomes, preços e datas) e coloca-as numa folha de cálculo ou base de dados para facilitar a análise.
Recolha manual vs. automatizada
No passado, se quisesse dados de um site, ou copiava tudo à mão ou esperava que o site oferecesse uma API. O conteúdo raspado inverte essa lógica ao automatizar o processo. Os scrapers modernos conseguem lidar com sites dinâmicos (aqueles com JavaScript, rolagem infinita ou botões de “Carregar mais”) e até imitar a navegação humana para aceder a conteúdos que só aparecem depois da interação do utilizador.
O que pode ser raspado?
Quase tudo o que é visível numa página pode ser raspado, incluindo:
- Texto: descrições de produtos, preços, notícias, publicações nas redes sociais.
- Imagens: fotos de anúncios, redes sociais ou galerias de produtos.
- Links e metadados: URLs, tags ou outros atributos HTML.
- Registos estruturados: tabelas, diretórios, dados de ações, anúncios imobiliários.
- Conteúdo gerado por utilizadores: avaliações, classificações, comentários.
As empresas normalmente focam-se em pontos de dados específicos, alinhados com os seus objetivos — como raspar preços de concorrentes no ecommerce ou agregar avaliações de clientes para análise de sentimento no marketing.
A base da ciência de dados e da investigação
Depois de raspado, esse conteúdo é armazenado num formato estruturado (como CSV, Excel ou JSON). Passa então a ser a matéria-prima para analytics, dashboards e modelos de machine learning. Seja para otimizar preços, acompanhar tendências de mercado ou criar uma lista de leads, o conteúdo raspado costuma ser a espinha dorsal da tomada de decisão orientada por dados.
Porque o conteúdo raspado é importante nos negócios modernos
Conteúdo raspado não é só um termo da moda — é um recurso prático que está a mudar a forma como as empresas operam. Eis porque se tornou tão importante:

- Inteligência competitiva: retalhistas raspam preços e informações de produtos dos concorrentes para ajustar as suas ofertas em tempo real. Até 2025, espera-se que 81% dos retalhistas dos EUA usem ferramentas automatizadas de raspagem de preços.
- Velocidade e escala: o scraping permite que as empresas recolham enormes volumes de dados em minutos, apoiando decisões ágeis e em tempo real.
- Decisões orientadas por dados: equipas de vendas, marketing, produto e operações dependem do conteúdo raspado para inteligência de preços, análise de tendências, geração de leads e muito mais.
Aqui fica uma visão rápida de como diferentes setores usam conteúdo raspado:
| Setor/Equipa | Caso de uso do conteúdo raspado | Benefício para o negócio |
|---|---|---|
| Ecommerce/Retalho | Raspar preços e listagens de produtos dos concorrentes | Preços dinâmicos em tempo real, otimização da estratégia de produtos |
| Marketing e Marca | Raspar avaliações, classificações e comentários nas redes | Análise de sentimento, monitorização da reputação da marca |
| Vendas e Geração de Leads | Raspar diretórios, LinkedIn, dados de contacto | Criação de listas de leads segmentadas, prospeção mais eficiente |
| Imobiliário | Raspar anúncios de imóveis de vários sites | Análise de mercado, agregação de inventário, estratégia de preços |
| Finanças/Investimentos | Raspar notícias financeiras, dados de ações, registos públicos | Dados alternativos para trading, gestão de risco, insights de mercado em tempo real |
O conteúdo raspado entrega ROI tangível: empresas que usam ferramentas de scraping com IA relatam 30–40% de poupança de tempo na extração de dados, libertando as equipas para se focarem na análise e na estratégia.
Conteúdo raspado e conformidade legal: o que precisa de saber
Com toda esta oportunidade, vem uma grande ressalva: scraping não é terra sem lei. As regras em torno do conteúdo raspado são moldadas por leis de direitos de autor, termos de serviço e regulamentos de privacidade de dados. Veja o que precisa de saber:
Web scraping é legal?
De um modo geral, raspar informações públicas não é ilegal por si só na maioria dos lugares, mas a forma como recolhe e usa os dados pode gerar problemas jurídicos. Nos EUA, um caso marcante (hiQ Labs vs. LinkedIn) concluiu que raspar dados publicamente disponíveis não viola leis anti-hacking — mas infringir os termos de serviço de um site ainda pode levar a processos (meitar.com).
Principais marcos legais:
- Direitos de autor: factos como preços ou números de ações não são protegidos, mas copiar e republicar conteúdo criativo (como artigos ou imagens) pode gerar reclamações de copyright. Use conteúdo raspado para análise interna ou garanta que se enquadra em “uso justo”.
- Privacidade de dados: leis como o GDPR na Europa e a CCPA na Califórnia aplicam-se quando raspa dados pessoais. Até perfis públicos podem ser protegidos, e o incumprimento pode resultar em multas pesadas.
- Termos de serviço: violar os ToS de um site (como raspar quando isso é explicitamente proibido) pode resultar em processos civis — mesmo que os dados sejam públicos.
Diferenças regionais: a UE é muito mais rigorosa quanto à raspagem de dados pessoais, exigindo frequentemente consentimento explícito ou um forte interesse legítimo. Os EUA são mais permissivos com dados públicos, mas continuam a fazer valer direitos de autor e contratuais.
Privacidade de dados e consentimento do utilizador no conteúdo raspado
Privacidade é um tema quente, especialmente ao raspar dados pessoais ou sensíveis:
- Público ≠ livre para qualquer utilização: só porque a informação é pública não significa que possa ser usada de qualquer forma. Os reguladores esperam que as empresas minimizem a recolha de dados e sejam transparentes sobre como usam dados raspados.
- Desafios de consentimento: é difícil obter consentimento de todas as pessoas cujos dados raspa. Muitas empresas recorrem ao “interesse legítimo”, mas isso está sob escrutínio crescente na UE.
- Boas práticas: anonimize os dados sempre que possível, recolha apenas o necessário e publique um aviso de privacidade claro sobre as suas atividades de scraping. Se alguém se opuser, esteja preparado para remover os seus dados.
Para saber mais sobre conformidade legal, veja este guia detalhado.
Thunderbit: a forma mais inteligente de lidar com conteúdo raspado
Agora, vamos falar de como realmente obter esses dados — sem perder a cabeça nem a conformidade legal. Thunderbit é uma extensão Chrome de web scraper com IA, criada para utilizadores de negócios que querem resultados, não dores de cabeça.
Porque Thunderbit?
- Ridiculamente fácil de usar: com o Thunderbit, não precisa de saber programar. Basta abrir uma página, clicar em “AI Suggest Fields” e deixar a IA descobrir o que extrair — como nomes de produtos, preços ou dados de contacto.
- Estruturação de dados orientada por IA: o Thunderbit garante que os seus dados raspados fiquem limpos, estruturados e prontos para análise. Ainda pode adicionar prompts personalizados de IA para formatar, categorizar ou traduzir os dados enquanto são raspados.
- Raspagem de subpáginas e paginação: precisa de capturar detalhes de cada página de produto ou lidar com rolagem infinita? A IA do Thunderbit deteta subpáginas e conteúdo paginado, automatizando o que antes era um processo manual e cansativo.
- Raspagem na cloud ou local: raspe na cloud para ganhar velocidade (até 50 páginas de uma vez) ou use o navegador para sites protegidos por login.
- Exportação gratuita de dados: exporte diretamente para Excel, Google Sheets, Airtable ou Notion — sem taxas extra, sem burocracia.
- Abordagem orientada para a conformidade: o Thunderbit incentiva o scraping responsável, permitindo-lhe controlar exatamente que dados recolhe, ajudando a evitar informações pessoais ou sensíveis, a menos que realmente precise delas.
O Thunderbit é confiável para mais de 50.000 utilizadores em todo o mundo, de equipas de vendas a operadores de ecommerce e profissionais do setor imobiliário.
Experimente grátis o Thunderbit AI Web Scraper
Como o Thunderbit simplifica o fluxo de trabalho do conteúdo raspado
Veja como funciona o fluxo do Thunderbit:
- AI Suggest Fields: abra uma página, clique no ícone do Thunderbit e deixe a IA sugerir quais campos extrair (por exemplo, “Nome do Produto”, “Preço”, “URL dos Detalhes”).
- Personalize os campos: adicione ou renomeie colunas, defina tipos de dados ou inclua prompts de IA para formatação ou categorização.
- Raspar: clique em “Scrape” e deixe o Thunderbit fazer o trabalho pesado. Em sites paginados ou com vários níveis, o Thunderbit navega automaticamente.
- Enriquecimento de subpáginas: precisa de mais detalhes? Use “Scrape Subpages” para visitar cada link e extrair informações adicionais.
- Exportar: reveja a sua tabela estruturada e exporte para a ferramenta da sua preferência — Excel, Sheets, Notion ou Airtable.
- Agendar: configure raspagens recorrentes (“todas as segundas-feiras às 9h”) para manter os seus dados sempre atualizados.
Comparado com as ferramentas tradicionais de scraping — que muitas vezes exigem programação, configuração manual e manutenção constante —, a abordagem AI-first do Thunderbit significa menos configuração, menos quebras e mais tempo dedicado à análise, não à resolução de problemas.
Conteúdo raspado em ação: aplicações reais nos negócios
Vamos ao concreto. Aqui estão algumas formas pelas quais as empresas estão a usar conteúdo raspado para obter vantagem real:
- Monitorização de preços no ecommerce: retalhistas raspam preços dos concorrentes diariamente (ou até de hora a hora) para ajustar os seus próprios preços em tempo real. Isto tornou-se tão comum que 81% dos retalhistas dos EUA já usam scraping automatizado para preços dinâmicos.
- Análise do sentimento do cliente: equipas de marketing raspam avaliações e comentários nas redes sociais para medir a satisfação do cliente e identificar problemas cedo. Uma rede de hospitalidade usou avaliações raspadas para identificar propriedades com desempenho abaixo do esperado e voltar a treinar a equipa, elevando as notas de satisfação dos hóspedes.
- Geração de leads: equipas de vendas criam listas de leads hipersegmentadas raspando diretórios, LinkedIn ou listas de participantes de eventos. Com o Thunderbit, ainda pode enriquecer leads raspando subpáginas para obter contexto extra.
- Pesquisa de mercado imobiliário: mediadores e investidores raspam anúncios de imóveis de vários sites para analisar tendências de preços, inventário e mudanças de mercado — poupando horas de pesquisa manual e identificando oportunidades mais depressa.
- Automação de operações: equipas raspam sites de fornecedores para monitorizar níveis de stock ou alterações de preço, automatizando um processo que antes era manual e sujeito a erros.
Em todos estes casos, o conteúdo raspado não é apenas uma pilha de dados — é um ativo estratégico que acelera e melhora a tomada de decisões.
O cenário em evolução: de quantidade para qualidade no conteúdo raspado
Os primeiros dias do web scraping eram guiados pela ideia de que “mais é melhor” — recolher o máximo de dados possível e organizar depois. Mas, à medida que a IA e os analytics amadureceram, o foco mudou para qualidade em vez de quantidade:
- Scraping direcionado: as empresas agora priorizam raspar as fontes certas e os pontos de dados certos, e não apenas tudo o que conseguem encontrar.
- IA para enriquecimento de dados: ferramentas como o Thunderbit usam IA para limpar, categorizar e até resumir os dados enquanto são raspados, tornando-os mais acionáveis.
- Atualização e relevância: raspagens em tempo real ou agendadas garantem que os dados estejam sempre atualizados — algo crucial para monitorização de preços ou análise de sentimento.
- Conformidade como métrica de qualidade: dados obtidos de forma legal e ética são de melhor qualidade porque podem ser usados com segurança e não o vão meter em apuros.
O Thunderbit foi construído para esta nova era: ajuda-o a focar nos dados que importam, garante que sejam estruturados e conformes, e integra-se sem esforço no seu fluxo de trabalho.
O que é data scraping e como fazer em 2025 Get Started Free
O scraping está a evoluir rapidamente, e manter-se à frente significa usar as ferramentas e as melhores práticas certas.
Desafios comuns e como superá-los
Raspagem nem sempre é um mar de rosas. Aqui estão alguns obstáculos comuns — e como o Thunderbit ajuda a superá-los:
- Duplicação de dados: raspar de várias fontes pode criar registos duplicados. O Thunderbit estrutura os dados com chaves únicas e facilita a deduplicação no Excel ou no Sheets.
- Qualidade e precisão: alterações no site podem quebrar scrapers ou causar dados em falta. A IA do Thunderbit adapta-se a mudanças de layout, e pode executar rapidamente novamente o “AI Suggest Fields” para corrigir problemas.
- Defesas dos sites: CAPTCHAs, bloqueios de IP e conteúdo dinâmico podem atrapalhar scrapers básicos. A abordagem baseada no navegador do Thunderbit lida com sites dinâmicos, e a raspagem na cloud usa vários IPs para oferecer velocidade e fiabilidade.
- Escala e desempenho: precisa de raspar milhares de páginas? O modo cloud do Thunderbit raspa até 50 páginas ao mesmo tempo, e pode agendar tarefas recorrentes para necessidades contínuas.
- Riscos de conformidade: raspar acidentalmente dados pessoais ou sensíveis pode transformar-se numa armadilha jurídica. O Thunderbit permite controlar exatamente o que recolhe, ajudando a evitar riscos desnecessários.
O segredo é usar uma ferramenta flexível, orientada por IA e pensada para utilizadores de negócios — não apenas desenvolvedores.
Principais conclusões: como aproveitar ao máximo o conteúdo raspado
Vamos fechar com o essencial:
- O conteúdo raspado é um pilar dos negócios modernos orientados por dados. Impulsiona tudo, desde a inteligência competitiva à geração de leads, e a sua importância só cresce.
- Qualidade vale mais do que quantidade. Foque-se em dados relevantes, precisos e atuais — não apenas em recolher tudo o que for possível.
- Conformidade legal e ética não é opcional. Entenda direitos de autor, privacidade e termos de serviço antes de raspar.
- O Thunderbit torna a raspagem acessível e responsável. Com sugestões de campos baseadas em IA, raspagem de subpáginas e design com foco na conformidade, o Thunderbit é a forma mais fácil para utilizadores de negócios transformarem dados da web em valor para o negócio.
- Integre o conteúdo raspado na sua tomada de decisão. O verdadeiro poder vem de usar esses dados para orientar a estratégia, e não apenas deixá-los parados numa folha de cálculo.
Pronto para ver como o conteúdo raspado pode transformar o seu fluxo de trabalho? Baixe a extensão Thunderbit para Chrome e experimente você mesmo — sem precisar programar. E, para mais dicas, confira o Blog da Thunderbit.
Comece a raspar com o Thunderbit agora
Perguntas frequentes
1. O que exatamente é conteúdo raspado?
Conteúdo raspado é dado recolhido automaticamente de sites ou fontes online usando ferramentas como web scrapers ou agentes de IA. Pode incluir texto, imagens, preços, avaliações, dados de contacto e muito mais — tudo estruturado para análise e uso nos negócios.
2. Web scraping é legal?
Raspar dados públicos geralmente é legal, mas usar conteúdo raspado de formas que violem direitos de autor, leis de privacidade ou os termos de serviço de um site pode gerar problemas jurídicos. Verifique sempre as normas locais e faça scraping de forma responsável.
3. Como as empresas usam conteúdo raspado?
As empresas usam conteúdo raspado para preços competitivos, geração de leads, análise de sentimento, pesquisa de mercado e muito mais. Ajuda as equipas a tomar decisões mais rápidas e orientadas por dados.
4. O que torna o Thunderbit diferente de outras ferramentas de scraping?
O Thunderbit usa IA para tornar a raspagem fácil para utilizadores sem conhecimentos técnicos. Funcionalidades como “AI Suggest Fields”, raspagem de subpáginas e paginação, além de exportação direta para Excel, Sheets, Notion e Airtable, fazem a diferença. Também foi concebido com foco na conformidade e na qualidade dos dados.
5. Como posso garantir que a minha raspagem seja compatível e ética?
Mantenha-se em dados públicos, evite recolher informações pessoais ou sensíveis sem necessidade, respeite os termos de serviço dos sites e anonimize os dados sempre que possível. Ferramentas como o Thunderbit ajudam-no a controlar exatamente o que recolhe, reduzindo riscos de conformidade.
Curioso para aprofundar? Explore mais guias e boas práticas no Blog da Thunderbit — e vamos transformar a web na sua próxima vantagem de negócio.
Experimente o Thunderbit AI Web Scraper hoje Get Started Free




