

O Zillow reúne mais de 160 milhões de registros de imóveis nos EUA, e transformar esses dados em escala é uma das tarefas mais pedidas — e também mais frustrantes — no trabalho com dados imobiliários. Se você já tentou fazer scraping no Zillow e acabou encarando uma página de CAPTCHA em vez dos anúncios, não está sozinho.
Passei bastante tempo pesquisando e testando diferentes formas de extrair dados do Zillow — tanto com Python quanto com ferramentas no-code que desenvolvemos na Thunderbit. Este guia cobre os dois caminhos. Se você quer um passo a passo completo em Python, com estratégias anti-bot, ou só precisa de 200 anúncios numa planilha até a hora do almoço, aqui tem uma parte para você. Vamos ver por que os dados do Zillow são tão valiosos, como o site funciona por baixo dos panos, um tutorial em Python passo a passo, os motivos exatos pelos quais os scrapers quebram e como automatizar extrações recorrentes para monitoramento de preços.
Por que extrair dados do Zillow?
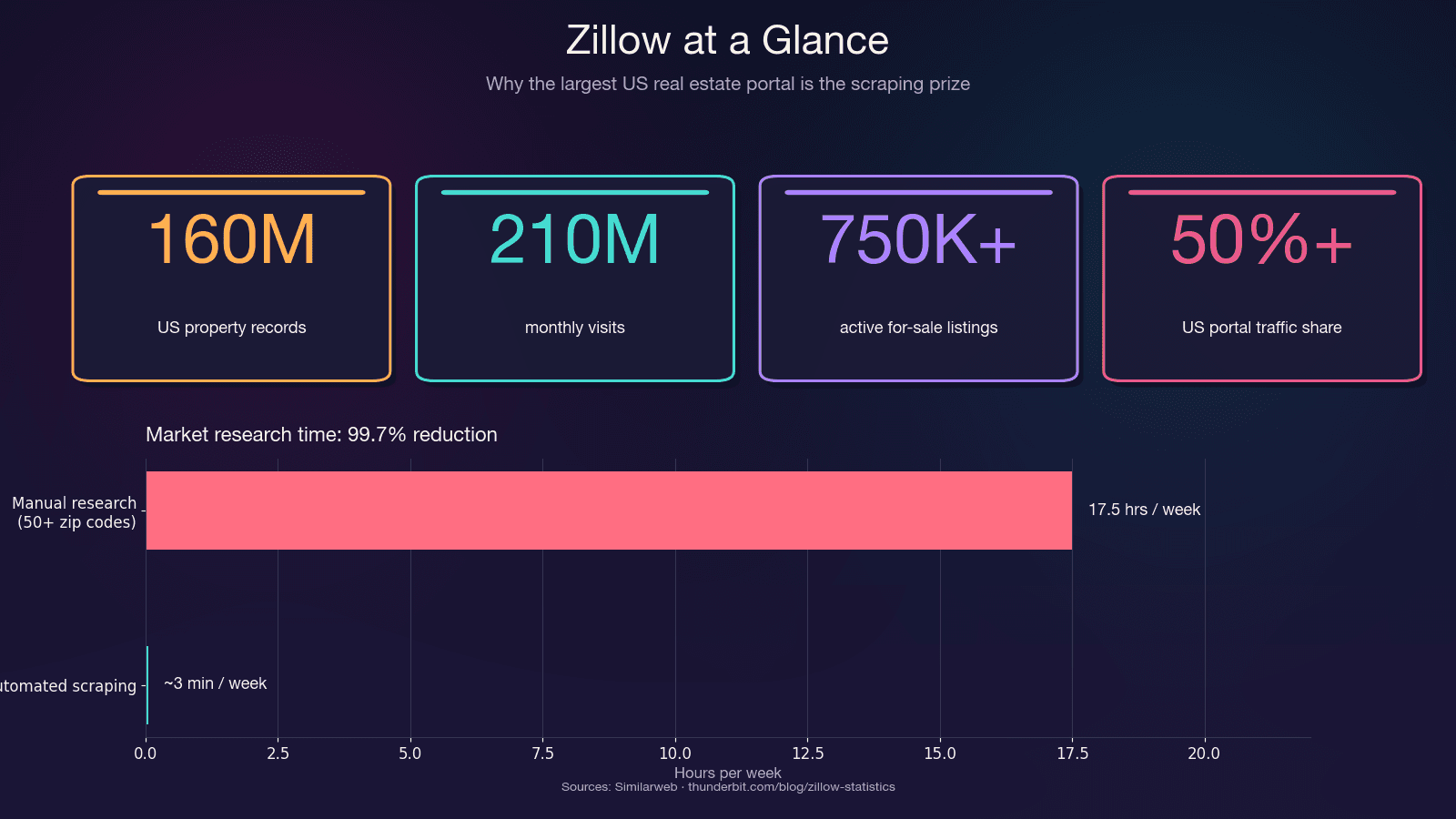
O Zillow é o maior repositório de dados de imóveis residenciais dos Estados Unidos. Ele recebe 210 milhões de visitas por mês e hospeda cerca de 750.000+ anúncios ativos de venda, além de 1,9 milhão de imóveis para aluguel. A plataforma concentra mais de 50% de todo o tráfego dos portais imobiliários dos EUA — mais que o dobro do concorrente mais próximo.
Antes de partir para o código em Python, vale saber que fazer scraping do Zillow com Python não é a única opção — e escolher o método errado pode desperdiçar horas. Ferramentas em Python como httpx e BeautifulSoup exigem conhecimento intermediário, tratamento manual de headers e proxies, rodam com velocidade moderada (1–3 segundos por página) e pedem manutenção frequente, embora sejam gratuitas; Selenium ou Playwright melhoram a resistência a bots ao renderizar JavaScript, mas são mais lentos (5–15 segundos por página) e ainda exigem bastante manutenção; APIs de scraping como ScraperAPI ou ScrapFly são mais rápidas, vêm com suporte anti-bot integrado e manutenção moderada, mas custam de US$ 30 a US$ 599 por mês; a API oficial do Zillow via Bridge Interactive é rápida e de baixa manutenção, porém limitada e custa cerca de US$ 500 por mês; e ferramentas no-code como Thunderbit são amigáveis para iniciantes, rápidas, não exigem manutenção graças à adaptação por IA e normalmente oferecem um modelo freemium.
A economia de tempo por si só já é enorme. Pesquisas manuais em 50+ CEPs podem consumir 15 a 20 horas por semana. O scraping automatizado faz o mesmo trabalho em minutos — uma redução de 99,7% no tempo gasto.
Todas as formas de extrair dados do Zillow: Python vs. API vs. No-Code (comparado)
Antes de mergulhar no Python, saiba que “extrair Zillow com Python” não é a única opção. Escolher o método errado custa tempo. Veja uma comparação lado a lado para decidir com mais clareza:
| Método | Nível de habilidade | Tratamento anti-bot | Velocidade | Manutenção | Custo |
|---|---|---|---|---|---|
| Python + httpx/BeautifulSoup | Intermediário | Manual (headers, proxies) | Moderada (1–3s/página) | Alta (seletors quebram) | Gratuito |
| Python + Selenium/Playwright | Intermediário | Melhor (renderiza JS) | Lenta (5–15s/página) | Alta | Gratuito |
| API de scraping (ScraperAPI, ScrapFly) | Intermediário | Integrado | Rápida | Média | US$ 30–599/mês |
| API oficial do Zillow (Bridge Interactive) | Iniciante–Intermediário | N/A | Rápida | Baixa | ~US$ 500/mês, acesso limitado |
| Ferramenta No-Code (Thunderbit) | Iniciante | Integrado (IA se adapta) | Rápida | Nenhuma (a IA relê a página) | Freemium |
Se você precisa dos dados agora, sem escrever código, comece com o Thunderbit. Se quiser entender a mecânica ou precisar de personalização total, continue lendo o passo a passo em Python.
O caminho mais rápido: extrair Zillow com Thunderbit (sem código)
Antes de aprofundar no Python, aqui está o caminho para quem só precisa dos dados do Zillow rápido — sem instalar Python, sem configurar proxy, sem manter seletores. Criamos esse fluxo na Thunderbit justamente para obter dados imobiliários estruturados sem sobrecarga de engenharia.
Dificuldade: Iniciante
Tempo necessário: ~2 minutos
O que você precisa: Navegador Chrome, extensão Thunderbit para Chrome (o plano grátis funciona)
Etapa 1: Instale o Thunderbit e abra o Zillow
Instale a extensão Thunderbit na Chrome Web Store. Acesse uma página de resultados de busca do Zillow — por exemplo, pesquise casas em Houston, TX.
Etapa 2: Clique em “AI Suggest Fields”
Abra a barra lateral do Thunderbit e clique em “AI Suggest Fields”. A IA lê a página e sugere automaticamente colunas como preço, endereço, quartos, banheiros, metragem, Zestimate, URL do anúncio e muito mais. Nos meus testes, ela costuma identificar mais de 20 campos sem nenhuma configuração manual.
Etapa 3: Clique em “Scrape”
Clique no botão Scrape. Os dados aparecem em uma tabela estruturada dentro da extensão. O Thunderbit lida automaticamente com a paginação do Zillow — tanto por clique quanto por rolagem infinita.
Etapa 4: Enriqueça com scraping de subpáginas
Quer dados da página de detalhes, como histórico de impostos, avaliação das escolas ou histórico de preços? Use “Scrape Subpages” para enriquecer sua tabela. O Thunderbit visita cada URL de anúncio e coleta os campos adicionais — sem código extra.
Etapa 5: Exportar
Exporte para Google Sheets, Excel, Airtable ou Notion. A exportação é gratuita.
Por que o Thunderbit funciona tão bem com o Zillow
A grande vantagem aqui é a resiliência. A IA do Thunderbit relê a estrutura da página toda vez que você faz a extração. Quando o Zillow muda o layout — o que acontece com frequência — não há seletores CSS frágeis para corrigir. A IA se adapta automaticamente. Isso resolve de verdade o problema da fragilidade inerente dos scrapers em código, que tanta dor de cabeça causa.
Quais dados você pode extrair do Zillow? (20+ campos)
A maioria dos guias pega preço e endereço e para por aí. Mas os anúncios do Zillow têm muito mais dados extraíveis do que a maioria imagina — aqui vai uma tabela de referência:
| Campo | Onde encontrar | Dificuldade de extração |
|---|---|---|
| Preço de anúncio | Busca + Detalhe | Fácil |
| Endereço / CEP | Busca + Detalhe | Fácil |
| Zestimate | Busca + Detalhe | Fácil |
| Histórico de preços (cada evento) | Detalhe | Difícil (JSON aninhado) |
| Histórico de impostos | Detalhe | Difícil (JSON aninhado) |
| Quartos / banheiros / m² | Busca + Detalhe | Fácil |
| Ano de construção | Detalhe | Fácil |
| Taxa de HOA | Detalhe | Média |
| Walk Score / Transit Score | Detalhe (iframe) | Difícil (exige renderização JS) |
| Avaliação das escolas | Detalhe | Média |
| Tamanho do terreno | Detalhe | Fácil |
| Dias no Zillow | Busca | Fácil |
| Corretor / imobiliária | Busca + Detalhe | Média |
| Número MLS | Detalhe | Fácil |
| Tipo de imóvel | Busca + Detalhe | Fácil |
| Latitude / Longitude | JSON __NEXT_DATA__ | Média |
| Texto da descrição | Detalhe | Fácil |
| URLs das fotos | Busca + Detalhe | Média |
| Rent Zestimate | Detalhe | Média |
| Vendas comparáveis próximas | Detalhe | Difícil |
Os campos “difíceis” — histórico de preços, histórico de impostos, vendas comparáveis — ficam em JSON aninhado nas páginas de detalhe. A seção em Python abaixo mostra exatamente como extraí-los. E, se preferir pular o código, o AI Suggest Fields do Thunderbit detecta automaticamente a maioria dessas colunas, e o recurso de Scrape Subpages captura os campos da página de detalhe sem esforço.
Configurando seu ambiente Python para extrair Zillow
Dificuldade: Intermediário
Tempo necessário: ~5 minutos para configurar, ~30 minutos para concluir o tutorial
O que você precisa: Python 3.8+, navegador Chrome (para inspecionar páginas), editor de texto ou IDE
Instale as bibliotecas necessárias:
pip install httpx beautifulsoup4 pandas lxml
O que cada uma faz:
- httpx — cliente HTTP com desempenho melhor que
requestse suporte a async - beautifulsoup4 + lxml — análise de HTML
- pandas — exportação de dados para CSV/Excel
- Opcionalmente: selenium ou playwright se você precisar renderizar páginas com muito JavaScript
Entendendo a estrutura da página do Zillow antes de extrair
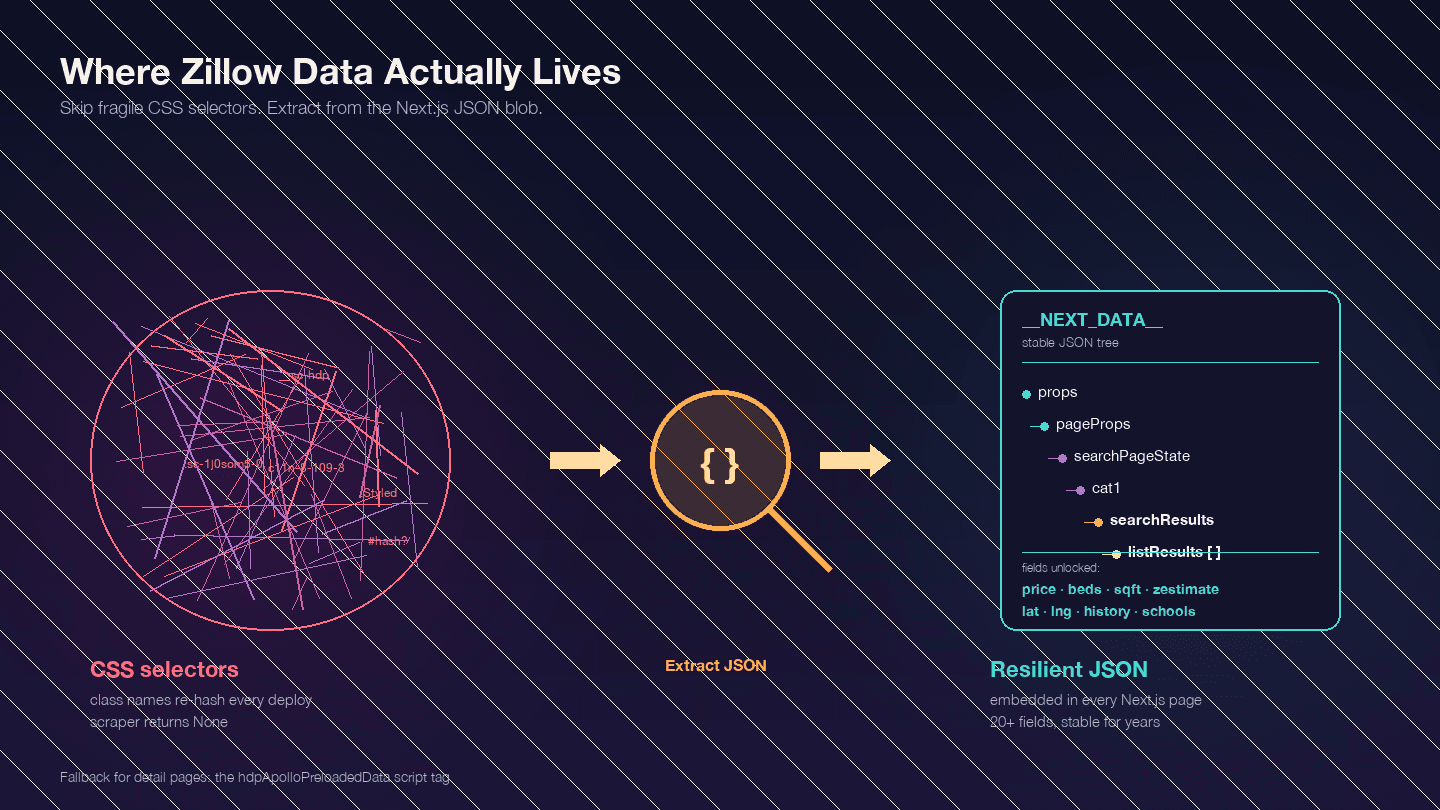
Esta é a coisa mais importante para entender antes de escrever qualquer código. O Zillow é uma aplicação Next.js — confirmado por publicações de engenheiros do Zillow. Isso significa que a maior parte dos dados que você quer não está nos elementos HTML visíveis. Ela fica embutida em um blob JSON dentro da tag <script id="__NEXT_DATA__">.
Abra qualquer página de imóvel do Zillow, pressione F12, vá em Elements e pesquise por __NEXT_DATA__. Você vai encontrar um objeto JSON enorme com todos os dados do anúncio — preços, coordenadas, detalhes do imóvel, histórico de preços, registros de impostos, avaliações escolares e muito mais.
Por que isso importa? Os nomes das classes CSS do Zillow são hashados (gerados por styled-components) e mudam a cada deploy. Uma classe como StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 terá um hash completamente diferente na semana seguinte. Qualquer scraper baseado em seletores CSS quebra com frequência.
A abordagem via JSON do __NEXT_DATA__ é muito mais estável porque não depende da estrutura visual do HTML.
Caminhos importantes de JSON para resultados de busca:
| Caminho | Conteúdo |
|---|---|
props.pageProps.searchPageState.cat1.searchResults.listResults | Array de resultados da busca |
props.pageProps.searchPageState.cat1.searchResults.mapResults | Resultados da visualização no mapa |
props.pageProps.searchPageState.cat1.searchList.totalPages | Total de páginas disponíveis |
Para páginas de detalhe, algumas usam __NEXT_DATA__ e outras usam uma tag de script alternativa chamada hdpApolloPreloadedData. O código abaixo lida com ambos os formatos.
Passo a passo: como extrair Zillow com Python
Etapa 1: Defina headers HTTP para evitar bloqueios imediatos
Enviar um httpx.get() puro para o Zillow não retorna dados dos anúncios, e sim uma página de CAPTCHA. O Zillow usa PerimeterX (HUMAN Security) junto com Cloudflare — ambos classificados com 8/10 de dificuldade em benchmarks de scraping. O sistema verifica fingerprint TLS, headers HTTP e reputação do IP.
Aqui estão os headers mínimos que funcionam em 2025:
import httpx
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
"image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
}
Os headers Sec-Ch-Ua são críticos. Muitos tutoriais os omitem — é exatamente por isso que o código desses tutoriais não funciona contra o PerimeterX.
Etapa 2: Extraia os resultados de busca do Zillow
As URLs de busca do Zillow seguem um padrão previsível. Para Houston, TX:
- Página 1:
https://www.zillow.com/houston-tx/ - Página 2:
https://www.zillow.com/houston-tx/2_p/ - Página 3:
https://www.zillow.com/houston-tx/3_p/
Cada página contém cerca de 41 anúncios. O Zillow limita os resultados a 20 páginas (~820 anúncios). Para bases maiores, você precisará dividir por geografia (falaremos disso mais adiante).
Aqui está o código para extrair os resultados de busca a partir do JSON __NEXT_DATA__:
from bs4 import BeautifulSoup
import json
import time
import random
def scrape_zillow_search(url):
"""Extrai dados de anúncios de uma página de resultados do Zillow."""
response = httpx.get(url, headers=headers, timeout=15)
if response.status_code != 200:
print(f"Status {response.status_code} para {url}")
return []
soup = BeautifulSoup(response.text, "lxml")
script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
if not script_tag:
print("Não foi encontrado __NEXT_DATA__ — provavelmente bloqueado por CAPTCHA")
return []
next_data = json.loads(script_tag.string)
try:
results = (
next_data["props"]["pageProps"]["searchPageState"]
["cat1"]["searchResults"]["listResults"]
)
except KeyError:
print("Estrutura JSON inesperada — o Zillow pode ter mudado o formato")
return []
listings = []
for item in results:
listing = {
"zpid": item.get("zpid"),
"address": item.get("addressStreet"),
"city": item.get("addressCity"),
"state": item.get("addressState"),
"zipcode": item.get("addressZipcode"),
"price": item.get("unformattedPrice") or item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"zestimate": item.get("zestimate"),
"days_on_zillow": item.get("daysOnZillow"),
"listing_url": item.get("detailUrl"),
"img_src": item.get("imgSrc"),
"property_type": item.get("hdpData", {}).get("homeInfo", {}).get("homeType"),
"latitude": item.get("latLong", {}).get("latitude"),
"longitude": item.get("latLong", {}).get("longitude"),
}
listings.append(listing)
return listings
Para extrair várias páginas, faça um loop com atrasos:
all_listings = []
base_url = "https://www.zillow.com/houston-tx/"
for page in range(1, 6): # Primeiras 5 páginas
url = base_url if page == 1 else f"{base_url}{page}_p/"
print(f"Extraindo página {page}...")
page_listings = scrape_zillow_search(url)
all_listings.extend(page_listings)
# Atraso aleatório entre 3 e 7 segundos
delay = random.uniform(3, 7)
time.sleep(delay)
print(f"Total de anúncios extraídos: {len(all_listings)}")
Você deve ver os dados estruturados dos anúncios sendo acumulados em all_listings. Se vier tudo vazio, confira a seção “Por que os scrapers quebram” mais abaixo.
Etapa 3: Extraia as páginas de detalhe dos imóveis do Zillow
Os resultados de busca trazem o básico. As páginas de detalhe contêm os dados mais profundos: histórico de preços, histórico de impostos, avaliação das escolas, informações do corretor e descrição do imóvel. Cada URL de anúncio obtida na Etapa 2 aponta para uma página de detalhe.
As páginas de detalhe do Zillow usam dois formatos de dados possíveis. Aqui está um código que lida com ambos:
def scrape_zillow_detail(url):
"""Extrai dados detalhados de um imóvel na página do Zillow."""
response = httpx.get(url, headers=headers, timeout=15)
if response.status_code != 200:
return None
soup = BeautifulSoup(response.text, "lxml")
# Tenta primeiro __NEXT_DATA__ (o mais comum)
script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
if script_tag:
next_data = json.loads(script_tag.string)
try:
cache_str = next_data["props"]["pageProps"]["componentProps"]["gdpClientCache"]
cache = json.loads(cache_str)
first_key = next(iter(cache))
prop = cache[first_key]["property"]
return extract_property_fields(prop)
except (KeyError, StopIteration):
pass
# Alternativa: hdpApolloPreloadedData
apollo_tag = soup.find("script", {"id": "hdpApolloPreloadedData"})
if apollo_tag:
raw = json.loads(apollo_tag.string)
api_cache = json.loads(raw["apiCache"])
for key, value in api_cache.items():
if "ForSale" in key or "property" in str(value)[:100]:
prop = value.get("property", value)
return extract_property_fields(prop)
return None
def extract_property_fields(prop):
"""Extrai campos estruturados de um objeto JSON de imóvel do Zillow."""
return {
"zpid": prop.get("zpid"),
"zestimate": prop.get("zestimate"),
"rent_zestimate": prop.get("rentZestimate"),
"description": prop.get("description"),
"year_built": prop.get("yearBuilt"),
"lot_size": prop.get("lotSize"),
"hoa_fee": prop.get("monthlyHoaFee"),
"mls_id": prop.get("mlsid"),
"broker_name": prop.get("brokerName") or prop.get("attributionInfo", {}).get("brokerName"),
"price_history": [
{
"date": event.get("date"),
"event": event.get("event"),
"price": event.get("price"),
}
for event in prop.get("priceHistory", [])
],
"tax_history": [
{
"year": record.get("time"),
"tax_paid": record.get("taxPaid"),
"value": record.get("value"),
}
for record in prop.get("taxHistory", [])
],
"schools": [
{
"name": school.get("name"),
"rating": school.get("rating"),
"distance": school.get("distance"),
}
for school in prop.get("schools", [])
],
}
Percorra as URLs dos anúncios com atrasos:
detail_data = []
for listing in all_listings[:10]: # Comece com 10 para testar
detail_url = listing.get("listing_url")
if not detail_url:
continue
if not detail_url.startswith("http"):
detail_url = f"https://www.zillow.com{detail_url}"
print(f"Extraindo detalhe: {detail_url}")
detail = scrape_zillow_detail(detail_url)
if detail:
detail_data.append({**listing, **detail})
time.sleep(random.uniform(3, 8))
Depois dessa etapa, você deverá ter uma lista de dicionários com dados tanto da busca quanto da página de detalhe de cada imóvel.
Etapa 4: Gerencie a paginação para extrair várias páginas
Para áreas com mais de 820 anúncios (o limite de 20 páginas), você precisa dividir por geografia. A API interna do Zillow aceita parâmetros mapBounds. A estratégia é dividir o mapa em quadrantes e extrair cada um separadamente.
def split_bounds(bounds):
"""Divide os limites do mapa em 4 quadrantes."""
mid_lat = (bounds["north"] + bounds["south"]) / 2
mid_lng = (bounds["east"] + bounds["west"]) / 2
return [
{"north": bounds["north"], "south": mid_lat, "east": bounds["east"], "west": mid_lng},
{"north": bounds["north"], "south": mid_lat, "east": mid_lng, "west": bounds["west"]},
{"north": mid_lat, "south": bounds["south"], "east": bounds["east"], "west": mid_lng},
{"north": mid_lat, "south": bounds["south"], "east": mid_lng, "west": bounds["west"]},
]
Na maioria dos casos — monitorando de 50 a 200 anúncios em uma área específica — a paginação padrão por URL é suficiente. A abordagem por quadrantes é para extrações em nível de cidade ou estado.
Etapa 5: Exporte seus dados extraídos do Zillow
Salve tudo em CSV com pandas:
import pandas as pd
df = pd.DataFrame(detail_data)
df.to_csv("zillow_houston_listings.csv", index=False)
print(f"Exportados {len(df)} anúncios para zillow_houston_listings.csv")
Para exportar em JSON:
with open("zillow_houston_listings.json", "w") as f:
json.dump(detail_data, f, indent=2)
Se quiser pular totalmente a etapa de exportação, o Thunderbit exporta gratuitamente para Google Sheets, Airtable e Notion — útil se você quiser os dados em um formato colaborativo imediatamente.
Por que os scrapers do Zillow quebram (e como criar soluções resilientes)
Este é o guia de sobrevivência.
Na minha experiência, os scrapers quebram no Zillow por três motivos específicos — e cada um tem uma correção concreta.
PerimeterX e CAPTCHAs: por que suas requisições retornam dados vazios
A integração do PerimeterX no Zillow verifica vários sinais ao mesmo tempo: fingerprint TLS, headers HTTP, reputação do IP e padrões de requisição. Quando detecta automação, devolve uma página de CAPTCHA “Press & Hold” em vez dos dados do anúncio.
Cenário exato da falha: você envia uma requisição com os headers padrão do Python. O HTML da resposta contém scripts de desafio do PerimeterX em vez dos dados do imóvel — e o parse com BeautifulSoup não encontra a tag __NEXT_DATA__.
A correção: use o conjunto completo de headers que imita um navegador, mostrado na Etapa 1. Se você estiver fazendo mais do que algumas dezenas de requisições, também vai precisar de rotação de proxies (explicada abaixo). Para scraping pesado, considere uma biblioteca como curl_cffi com impersonate="chrome" — é o único cliente HTTP em Python que consegue reproduzir um fingerprint TLS parecido com o do Chrome real.
Seletores CSS dinâmicos: por que o BeautifulSoup retorna None
Se você estiver usando seletores CSS como .list-card-price ou nomes de classe com hash, seu scraper vai quebrar toda vez que o Zillow fizer um deploy.
O Zillow usa styled-components, que geram nomes de classe como StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0. A parte do hash muda a cada build.
A correção: não use seletores CSS. Extraia os dados do blob JSON __NEXT_DATA__, como mostrado no código acima. Essa abordagem se manteve estável por anos porque a estrutura JSON muda muito menos do que o HTML.
Se você realmente precisar fazer parsing do HTML, procure atributos data-test (por exemplo, data-test="property-card") ou use correspondência parcial de classes, como [class*="PropertyCard"]. Mas a extração via JSON é o caminho mais confiável.
Rotação de proxies e backoff exponencial: código que sobrevive a bloqueios de IP
IPs de datacenter são bloqueados imediatamente pelo Zillow. Você precisa de proxies residenciais para ter acesso confiável. Ritmo seguro: 1 requisição a cada 3–8 segundos por IP, mantendo-se abaixo de cerca de 500 requisições por hora.
Aqui vai um decorador de retry com backoff exponencial e jitter:
import random
import time
def backoff_with_jitter(attempt, base_delay=2, max_delay=60):
"""Backoff exponencial com jitter completo no estilo AWS."""
delay = min(max_delay, base_delay * (2 ** attempt))
return random.uniform(0, delay)
def fetch_with_retry(url, max_retries=5):
for attempt in range(max_retries):
try:
response = httpx.get(url, headers=headers, timeout=15)
if response.status_code == 200:
return response
if response.status_code in (403, 429):
delay = backoff_with_jitter(attempt, base_delay=5)
print(f"Bloqueado ({response.status_code}). Tentando novamente em {delay:.1f}s...")
time.sleep(delay)
continue
except Exception as e:
if attempt == max_retries - 1:
raise
time.sleep(backoff_with_jitter(attempt))
return None
E um pool simples para rotacionar proxies:
class ProxyPool:
def __init__(self, proxies):
self.proxies = proxies
self.index = 0
self.failures = {}
def get_next(self):
proxy = self.proxies[self.index % len(self.proxies)]
self.index += 1
return {"http://": proxy, "https://": proxy}
def report_failure(self, proxy):
self.failures[proxy] = self.failures.get(proxy, 0) + 1
if self.failures[proxy] > 3:
self.proxies.remove(proxy)
# Uso:
pool = ProxyPool(proxies=[
"http://user:pass@residential1.example.com:8080",
"http://user:pass@residential2.example.com:8080",
])
Entre os provedores de proxy, DataImpulse oferece proxies residenciais por cerca de US$ 1/GB (a opção mais barata), enquanto IPRoyal e Smartproxy são boas escolhas intermediárias, na faixa de US$ 4–7/GB.
A alternativa sem manutenção
Se você faz scraping do Zillow com frequência e está cansado de consertar seletores quebrados ou gerenciar pools de proxies, a IA do Thunderbit lê a estrutura da página do zero a cada extração. Sem seletores para manter, sem configuração de proxy. Isso resolve de verdade o problema de fragilidade que transforma scrapers em código numa dor de cabeça recorrente.
Automatize o scraping do Zillow: agendamento e monitoramento de preços
Todo investidor imobiliário com quem conversei quer isso, e nenhum outro guia de scraping do Zillow cobre bem esse ponto: extrações automáticas recorrentes para acompanhar preços.
Para usuários de Python: cron jobs e detecção de variação de preço
Configure um cron job para executar seu scraper semanalmente e sinalizar mudanças de preço:
import pandas as pd
from datetime import datetime
def detect_price_changes(new_data, historical_file, threshold=0.05):
"""Compara a nova extração com o histórico e sinaliza mudanças acima do limite."""
try:
old = pd.read_csv(historical_file)
except FileNotFoundError:
new_data.to_csv(historical_file, index=False)
print("Primeira execução — dados base salvos.")
return pd.DataFrame()
merged = new_data.merge(old, on="zpid", suffixes=("_new", "_old"))
merged["price_change_pct"] = (
(merged["price_new"] - merged["price_old"]) / merged["price_old"]
)
alerts = merged[merged["price_change_pct"].abs() > threshold]
# Acrescenta novos dados com timestamp
new_data["scraped_at"] = datetime.now().isoformat()
new_data.to_csv(historical_file, mode="a", header=False, index=False)
return alerts
Adicione isso ao seu crontab para rodar toda segunda-feira às 6h:
0 6 * * 1 cd /path/to/scraper && python zillow_monitor.py
Exemplo prático: acompanhe 50 anúncios em Austin, TX, semanalmente. Toda segunda-feira, o script extrai os preços atuais, compara com a semana anterior e gera um CSV destacando qualquer queda de preço superior a 5%.
Para quem não programa: Scheduled Scraper do Thunderbit
O Scheduled Scraper do Thunderbit permite descrever o intervalo em linguagem natural (“toda segunda-feira às 9h”), inserir suas URLs de busca do Zillow e clicar em Schedule. Os dados são exportados automaticamente para o Google Sheets a cada execução. Sem Python, sem cron, sem servidor para manter. Isso é especialmente útil para corretores ou equipes de operação que precisam acompanhar preços com consistência sem apoio de engenharia.
Dicas para fazer scraping do Zillow de forma responsável
Algumas observações para ficar do lado certo da linha:
- Extraia apenas dados publicamente disponíveis. Não acesse páginas protegidas por login ou autenticação.
- Use taxas de requisição razoáveis. Intervalos de 3 a 8 segundos entre requisições. Não sobrecarregue o servidor.
- Não colete dados pessoais ou privados de usuários. Nomes de corretores e informações de imobiliárias nos anúncios são públicos; dados de contas de usuários não são.
- Armazene e use os dados com ética. Pesquisa de mercado, análise de investimentos e geração de leads são usos legítimos. Spam não é.
- Contexto legal: a decisão hiQ v. LinkedIn estabeleceu que extrair dados publicamente acessíveis não viola o CFAA. A decisão Meta v. Bright Data (2024) reforçou princípios semelhantes. Ainda assim, os Termos de Uso do Zillow restringem o acesso automatizado, e a empresa faz a aplicação dessas regras por meio de bloqueios de IP e CAPTCHAs, em vez de ação judicial. Sempre verifique as orientações mais recentes e respeite o robots.txt.
Escolha a melhor abordagem para extrair Zillow com Python
O melhor caminho depende da sua situação:
Precisa dos dados rápido, sem código? O Thunderbit leva você de uma página de busca do Zillow a uma planilha estruturada em cerca de 2 minutos. A IA se adapta a mudanças de layout, lida com paginação e exporta de graça. Instale a extensão para Chrome e teste numa página de busca do Zillow.
Quer controle total? Use o código Python deste guia. Extraia do JSON __NEXT_DATA__ (e não de seletores CSS) para ganhar estabilidade. Configure headers que imitam um navegador real. Rode proxies residenciais e use backoff exponencial para ter mais confiabilidade.
Quer escalar? APIs de scraping como ScrapFly (99% de taxa de sucesso no Zillow) ou ScraperAPI cuidam da infraestrutura de proxy e CAPTCHA para você, por US$ 30–599/mês, dependendo do volume.
Quer acompanhar preços ao longo do tempo? Configure um cron job com o script de detecção de variação de preço, ou use o Scheduled Scraper do Thunderbit para uma abordagem sem manutenção.
Os dados estão lá. A única questão é quanto tempo de engenharia você quer gastar para tirá-los de lá. Para mais informações sobre como levar dados da web para planilhas, confira nosso guia sobre como extrair dados de sites para o Excel ou nosso resumo de estatísticas do Zillow para ver os dados mais recentes da plataforma. Você também pode assistir a tutoriais no canal da Thunderbit no YouTube.
Experimente o Thunderbit para Scraping do Zillow Get Started Free
Perguntas frequentes
Dá para fazer scraping do Zillow com Python de graça?
Sim — httpx, BeautifulSoup e pandas são todos gratuitos e de código aberto. O custo é o tempo: você precisará gerenciar headers, rotação de proxies e manutenção de seletores por conta própria. Espere investir de 4 a 8 horas na configuração inicial e de 4 a 10 horas por mês em manutenção quando o Zillow mudar o site. O Thunderbit também oferece um plano grátis se você quiser evitar toda a complexidade do código.
O Zillow tem API oficial?
O Zillow descontinuou sua API pública gratuita em setembro de 2021. O acesso agora passa pela Bridge Interactive, que exige aprovação, custa aproximadamente US$ 500 por mês e é voltada para profissionais licenciados do mercado imobiliário. Para a maioria dos usuários — investidores, pesquisadores e corretores que fazem análise de mercado — o scraping é a alternativa prática. O Zillow ainda publica dados de pesquisa gratuitos em CSV para download em zillow.com/research/data/, incluindo o Zillow Home Value Index e o Zillow Observed Rent Index.
Como evitar bloqueios ao extrair dados do Zillow?
Três coisas: (1) use headers de navegador realistas, incluindo Sec-Ch-Ua — esse é o header que a maioria dos tutoriais esquece, e é o primeiro que o PerimeterX verifica; (2) rotacione proxies residenciais — IPs de datacenter são bloqueados imediatamente; (3) extraia dados do JSON __NEXT_DATA__ em vez de seletores HTML para evitar que mudanças no layout quebrem o scraper. Mantenha o ritmo em 1 requisição a cada 3–8 segundos por IP. Ou use uma ferramenta como Thunderbit, que trata a proteção anti-bot automaticamente.
Qual é a melhor forma de extrair Zillow sem programar?
O AI Web Scraper do Thunderbit é o caminho mais rápido. Instale a extensão para Chrome, abra uma página de busca do Zillow, clique em “AI Suggest Fields” para detectar colunas automaticamente e depois clique em “Scrape”. Exporte para Google Sheets, Excel, Airtable ou Notion sem precisar de código. A IA lê a página do zero a cada execução, então não quebra quando o Zillow atualiza o layout.
Com que frequência o Zillow muda a estrutura do site, e como isso afeta os scrapers?
O Zillow lança atualizações com frequência — às vezes semanalmente. Como usa styled-components, os nomes das classes CSS mudam a cada deploy, e scrapers baseados em seletores CSS quebram com regularidade. A abordagem mais resiliente em Python é extrair do blob JSON __NEXT_DATA__, que muda de estrutura com bem menos frequência. Para uma solução sem manutenção, a IA do Thunderbit relê a estrutura da página em cada extração e se adapta automaticamente às mudanças de layout.
Saiba mais




