Yelp reúne em — e transformar esses dados em algo realmente útil nunca foi tão complicado. A ofensiva anti-bot do Yelp em 2024–2025 derrubou, sem fazer alarde, a maioria dos tutoriais de raspagem em Python que existiam por aí.
Se você tentou rodar um raspador de Yelp recentemente e bateu numa sequência de erros 403, respostas HTML vazias ou CAPTCHAs que não apareciam há seis meses, não é coisa da tua cabeça. Hoje o Yelp usa fingerprinting de TLS/JA3, nomes de classes CSS ofuscados e em rotação, além de uma pontuação agressiva de reputação de IP — ou seja, a velha abordagem requests + BeautifulSoup, ainda tão recomendada em tutoriais antigos, morre logo na primeira requisição. Passei semanas testando caminhos diferentes contra a estrutura atual do Yelp, e este guia reúne tudo o que realmente funciona em 2025: a API oficial Fusion (e por que ela provavelmente não dá conta), um fluxo completo de raspagem em Python com estratégia em camadas para evitar bloqueios e uma alternativa sem código, em 2 cliques, com para quem só quer os dados sem a dor de cabeça da depuração.
Por Que Raspar o Yelp com Python (e Quem Realmente Se Beneficia)
Antes de escrever uma linha de código, qual é o caso de negócio real para os dados do Yelp? A plataforma não é só um site de avaliações de restaurantes — na prática, ela funciona como um banco de dados vivo de negócios locais, com informações estruturadas de contato, avaliações, categorias, horários e centenas de milhões de comentários de clientes.
Veja quem mais se beneficia e o que costuma extrair:
| Caso de uso | Campos de dados principais | Por que isso importa |
|---|---|---|
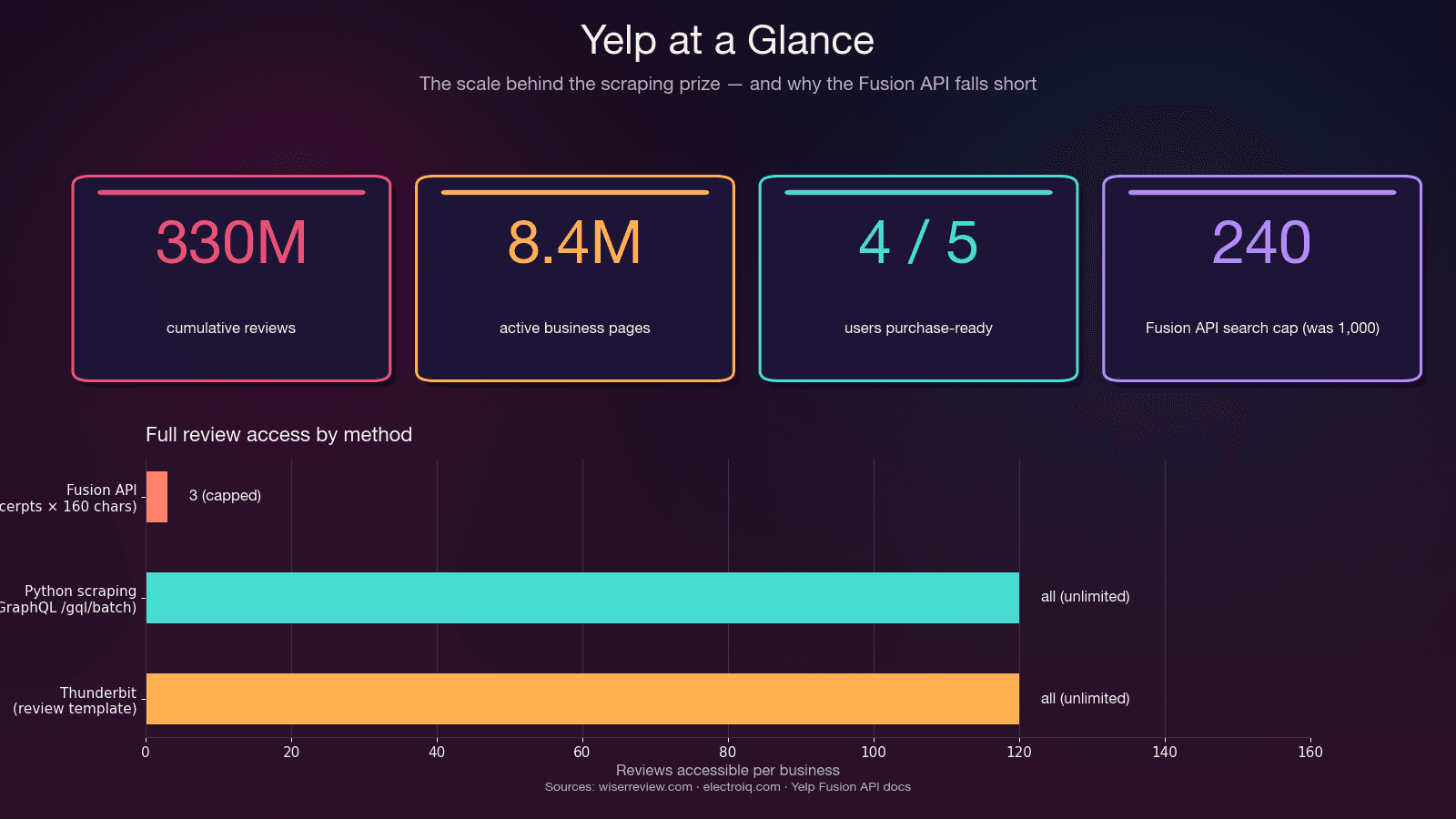
| Vendas e geração de leads | Nome da empresa, telefone, site, endereço, categoria, avaliação | Monte listas segmentadas de potenciais clientes SMB locais — 4 em cada 5 usuários do Yelp já estão prontos para comprar ao chegar na plataforma |
| Inteligência competitiva | Avaliações, estrelas, volume de avaliações, sentimento | Acompanhe a reputação dos concorrentes, encontre falhas no atendimento e observe tendências |
| Pesquisa de mercado e NLP | Texto completo das avaliações, datas, metadados do avaliador | Análise de sentimento, modelagem de tópicos — avaliações do Yelp são um dos corpora de NLP mais usados na pesquisa acadêmica |
| Imóveis e escolha de localização | Densidade de negócios, mistura de categorias, qualidade das avaliações por região | Seleção de pontos para franquias e varejo — o Yelp vende Location Intelligence como produto B2B licenciado exatamente para isso |
| Ecommerce e operações | Sinais de preço, reclamações de clientes, horário de atendimento | Compare como os concorrentes são avaliados e identifique padrões operacionais |
O ponto em comum: o objetivo real é obter dados estruturados, e o Python é só um meio para chegar lá. Algumas pessoas querem controle total via código. Outras só precisam de uma planilha com contatos de encanadores em Austin. Aqui você encontra os dois caminhos.
API Yelp Fusion vs. Raspagem em Python: Qual Devo Usar?
A maioria dos guias ignora essa decisão e já vai direto para o código, sem avaliar se a oficial — agora rebatizada como “Yelp Places API” — já resolveria o problema. Pela minha experiência, essa análise poupa horas de trabalho jogado fora, porque a API é excelente em alguns cenários e totalmente insuficiente em outros.
O Que a Fusion API Realmente Entrega
A Fusion API oferece busca estruturada de empresas, detalhes do negócio, autocomplete e um endpoint de avaliações. Ela é autorizada, bem documentada e não exige malabarismos anti-bot.
Mas é justamente no endpoint de avaliações que tudo desanda. Veja o que a própria equipe do Yelp confirmou no GitHub:
"A API do Yelp não retorna o texto completo das avaliações. Por padrão, são fornecidos três trechos de 160 caracteres." —
Isso não é bug — é de propósito. A API limita fisicamente o retorno a 3 trechos de avaliação (7 no plano Premium), cada um truncado para cerca de 160 caracteres. Não há metadados da avaliação (votos útil/divertido/interessante), nem histórico do avaliador, nem respostas do proprietário. E o depois de maio de 2023 — antes eram 5.000. O preço inicial começa em .
Estrutura de Decisão
| Fator | API Yelp Fusion | Raspagem em Python | Thunderbit (sem código) |
|---|---|---|---|
| Avaliações completas | ❌ Só 3 trechos (~160 caracteres cada) | ✅ Todas as avaliações via GraphQL | ✅ Todas as avaliações visíveis |
| Limites de taxa | 300–500/dia (novos); 5.000 (legado) | Gerenciado por você (orçamento de proxy) | Baseado em créditos |
| Esforço de configuração | ~15 min (chave de API + SDK) | De horas a dias | ~2 minutos |
| Campos de negócio | ~20 campos estruturados | Ilimitado (HTML/JSON) | Campos sugeridos por IA |
| Tratamento anti-bot | N/A (autorizada) | Você precisa implementar | Tratado automaticamente |
| Risco legal | ✅ Autorizado | ⚠️ Área cinzenta nos Termos | ⚠️ Mesmo risco da raspagem |
| Custo | A partir de $29/mês | Grátis (+ proxies de $0,75–$4/GB) | Plano grátis disponível |
| Manutenção | Baixa (API estável) | Alta (seletores quebram, bloqueios aumentam) | Baixa (IA se adapta) |
Use a Fusion API se: você precisa de informações básicas da empresa, consultas em pequena escala ou uma integração autorizada — e 3 trechos de avaliação por empresa já bastam.
Use raspagem em Python se: você precisa do texto completo das avaliações, de todas as avaliações de um negócio, de metadados das reviews, de mais de 240 resultados por busca ou se seu orçamento é inferior a $29/mês.
Use o Thunderbit se: você quer os dados rápido, sem escrever ou manter código. Falo mais sobre isso na seção sem código abaixo.
O Atalho Sem Código: Raspe Yelp com Thunderbit (Sem Python)
Antes de entrar na parte pesada do Python, aqui vai o caminho mais rápido para quem quer o dado, não a maratona de programação. A maioria dos concorrentes parte do pressuposto de que você domina Python, mas no meu trabalho na Thunderbit vejo que muita gente que procura “raspar Yelp” é da área comercial, de operações ou dona de pequeno negócio — e só quer uma planilha com empresas locais, não um curso intensivo de fingerprinting de TLS.
já vem com modelos prontos para o Yelp:
- — extrai nome da empresa, avaliação, contato, endereço, horário e categoria
- — extrai usuário do avaliador, conteúdo da avaliação, nota, data e localização do avaliador
Como Funciona na Prática
- Abra uma página de resultados de busca do Yelp ou a página de uma empresa no Chrome
- Clique em AI Suggest Fields na — a IA lê a página e sugere colunas (nome da empresa, avaliação, número de reviews, faixa de preço, categoria, endereço, telefone, URL)
- Clique em Scrape — pronto
Com os modelos prontos do Yelp, fica ainda mais simples: abra o template e clique em Scrape.
A raspagem de subpáginas faz automaticamente o enriquecimento dos dados — comece por uma página de resultados do Yelp, ative a raspagem de subpáginas e o Thunderbit visita cada página de empresa para coletar horário, avaliações completas, site, fotos e comodidades. Sem configuração extra.
A paginação é automática — tanto por clique quanto por rolagem, já vem pronta. (Para entender melhor como isso funciona, veja nosso .)
As exportações são grátis em todos os planos — Excel, Google Sheets, Airtable, Notion, CSV, JSON. Sem pandas, sem código para escrever CSV.
Comparação de Tempo
| Tempo | Raspador em Python | Thunderbit |
|---|---|---|
| Primeira execução | Horas a dias (seletores, paginação, proxies, retries) | ~30 segundos com o modelo pronto do Yelp |
| Quando o Yelp muda o HTML | Reescrever seletores manualmente | Clique em AI Suggest Fields de novo — a adaptação é automática |
| Quando o IP é bloqueado | Depurar, trocar pools de proxy, testar de novo | O modo Cloud cuida da rotação de IP |
| Exportar para Google Sheets | Escrever OAuth + integração com pandas | Um clique, grátis |
Se você testar o Thunderbit primeiro e ele atender às suas necessidades, pode pular o resto do artigo. Se você precisa de controle programático total, campos personalizados ou escala acima de alguns milhares de registros por mês — continue lendo.
Bibliotecas Python para Raspagem do Yelp: Qual Escolher
“Devo usar Scrapy, BS4+requests ou Selenium?” é uma das perguntas mais comuns em tópicos do r/webscraping sobre o Yelp. Mesmo assim, quase todo tutorial simplesmente escolhe sua biblioteca favorita e segue em frente sem explicar o motivo. Aqui vai a análise honesta.
A Realidade de 2025: requests + BeautifulSoup Está Quebrado para o Yelp
A pilha que todo tutorial clássico recomenda — pip install requests beautifulsoup4 — já é bloqueada na primeira requisição em 2025. Não na 50ª. Na primeira.
O motivo: a biblioteca requests do Python envia uma assinatura TLS/JA3 que não corresponde a nenhum navegador real. A camada anti-bot do Yelp detecta isso no nível do handshake TLS, antes mesmo de ler teu cabeçalho User-Agent. Testei várias vezes — IP novo, cabeçalhos realistas, atrasos aleatórios — e ainda assim recebi 403 Forbidden imediatamente com requests puro.
Matriz de Decisão das Bibliotecas
| Biblioteca | Ideal para | Lida com JS? | Anti-Bot? | Curva de aprendizado | Velocidade |
|---|---|---|---|---|---|
requests + BeautifulSoup | ❌ | ❌ | Muito baixa | Rápido (até ser bloqueado) | |
httpx async + parsel | Raspagem assíncrona em larga escala | ❌ | ❌ | Baixa | Muito rápido |
curl_cffi + parsel | Específico para Yelp: imitação de TLS | ❌ | ✅ TLS/JA3/HTTP2 | Baixa | Muito rápido |
Scrapy 2.14 | Pipelines completos de rastreamento com paginação | Parcial (via scrapy-playwright) | AutoThrottle, middleware de retry | Média-Alta | Rápido |
Selenium 4.43 / Playwright 1.58 | Páginas pesadas em JS, contornos para CAPTCHA | ✅ | Parcial | Média | Lento (~10–30 páginas/min) |
| Thunderbit | Quem não programa e quer extração rápida | ✅ (no navegador) | Integrado (modo Cloud) | Muito baixa | Rápido |
A Descoberta do curl_cffi
A biblioteca que mudou meu fluxo de raspagem do Yelp foi o — uma ligação Python para o curl-impersonate. Ela emite a mesma impressão digital de TLS/JA3 + HTTP/2 de um Chrome real, e sua API substitui o requests sem exigir mudanças grandes no código:
1from curl_cffi import requests
2r = requests.get(
3 "https://www.yelp.com/biz/some-restaurant",
4 impersonate="chrome131",
5)
6print(r.status_code, len(r.text))Essa única mudança — from curl_cffi import requests junto com impersonate="chrome131" — contorna a sem precisar abrir um navegador. Nos meus testes, isso faz a diferença entre 403 instantâneo e respostas 200 limpas.
Minha stack recomendada para o Yelp em 2025: curl_cffi + parsel + jmespath + proxies residenciais. Se você precisa de um pipeline completo de rastreamento com agendamento, encaixe isso no Scrapy 2.14 com um downloader middleware baseado em curl_cffi.
Configurando Seu Ambiente Python para Raspar o Yelp
- Dificuldade: Intermediária
- Tempo necessário: ~15 minutos de configuração, 1–2 horas para um raspador funcional
- O que você vai precisar: Python 3.10+ (recomendado 3.12), um terminal e, opcionalmente, um provedor de proxy residencial
Passo 1: Crie um Ambiente Virtual e Instale os Pacotes
1python3.12 -m venv .venv
2source .venv/bin/activate # No Windows: .venv\Scripts\activate
3pip install "curl_cffi>=0.11" "parsel>=1.9" "jmespath>=1.0" pandasO que cada pacote faz:
curl_cffi— faz requisições HTTP com a impressão digital TLS do Chrome (o bypass anti-bot)parsel— seletores CSS/XPath para analisar HTML (o mesmo motor usado pelo Scrapy, mas mais leve)jmespath— consulta declarativa de JSON (mais limpa que acessar dicionários aninhados no JSON embutido do Yelp)pandas— exportação de dados para CSV/Excel
Opcional, mas útil:
1pip install fake-useragent # Observação: o repositório foi arquivado em abril de 2026, mas ainda pode ser instaladoPasso a Passo: Como Raspar o Yelp com Python
Este é o tutorial principal. O insight-chave que deixa tudo mais resistente: pule os seletores CSS e extraia o JSON oculto. O Yelp randomiza os nomes das classes CSS em cada build (y-css-14xwok2 numa semana, y-css-hcq7b9 na seguinte), então qualquer raspador preso nisso quebra em poucas semanas. Os payloads JSON embutidos — application/ld+json e react-root-props — são estáveis.
Passo 2: Raspe os Resultados da Busca do Yelp
As URLs de busca do Yelp seguem um padrão previsível: https://www.yelp.com/search?find_desc={termo}&find_loc={localização}. Os dados dos resultados ficam embutidos em uma tag <script data-id="react-root-props"> como JSON — e não perdidos no meio das classes CSS.
1import re, json, jmespath
2from curl_cffi import requests
3from parsel import Selector
4HEADERS = {
5 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
6 "AppleWebKit/537.36 (KHTML, like Gecko) "
7 "Chrome/124.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
9 "image/avif,image/webp,image/apng,*/*;q=0.8",
10 "accept-language": "en-US,en;q=0.9",
11 "accept-encoding": "gzip, deflate, br",
12 "cookie": "intl_splash=false",
13}
14def scrape_search(term: str, location: str, max_pages: int = 3):
15 results = []
16 for page in range(max_pages):
17 url = (f"https://www.yelp.com/search?"
18 f"find_desc={term}&find_loc={location}&start={page * 10}")
19 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
20 if r.status_code != 200:
21 print(f"Bloqueado na página {page}: {r.status_code}")
22 break
23 sel = Selector(text=r.text)
24 script = sel.xpath(
25 "//script[@data-id='react-root-props']/text()"
26 ).get() or ""
27 m = re.search(r"react_root_props\s*=\s*(\{.*?\});", script, re.S)
28 if not m:
29 print(f"react-root-props não encontrado na página {page} — possível bloqueio silencioso")
30 break
31 data = json.loads(m.group(1))
32 businesses = jmespath.search(
33 "legacyProps.searchAppProps.searchPageProps"
34 ".mainContentComponentsListProps"
35 "[?searchResultBusiness].searchResultBusiness.{"
36 "name: name, url: businessUrl, rating: rating, "
37 "reviews: reviewCount, phone: phone, "
38 "neighborhoods: neighborhoods}",
39 data,
40 ) or []
41 results.extend(businesses)
42 import time, random
43 time.sleep(random.uniform(3, 7))
44 return resultsVocê deve receber uma lista de dicionários com nomes de empresas, URLs, avaliações e número de reviews. Se react-root-props não aparecer na resposta, o Yelp provavelmente entregou uma página de bloqueio “vazia” — troque o IP e tente novamente.
O cabeçalho Cookie: intl_splash=false é um workaround comum para o redirecionamento de splash de país do Yelp. Sem ele, IPs fora dos EUA podem cair numa página de entrada que parece bloqueio, mas não é exatamente isso.
Passo 3: Raspe as Páginas das Empresas no Yelp
Cada URL de empresa vinda dos resultados leva a uma página de detalhes com dados mais ricos. O alvo mais estável para extração é o bloco <script type="application/ld+json"> — ele contém dados estruturados em schema.org que o Yelp mantém para SEO e não costuma ofuscar.
1def scrape_business(biz_url: str) -> dict:
2 url = f"https://www.yelp.com{biz_url}" if biz_url.startswith("/") else biz_url
3 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
4 if r.status_code != 200:
5 return {"url": url, "error": r.status_code}
6 sel = Selector(text=r.text)
7 biz_id = sel.css('meta[name="yelp-biz-id"]::attr(content)').get()
8 for raw in sel.css('script[type="application/ld+json"]::text').getall():
9 try:
10 data = json.loads(raw)
11 except json.JSONDecodeError:
12 continue
13 for node in (data if isinstance(data, list) else [data]):
14 if node.get("@type") in (
15 "Restaurant", "LocalBusiness", "FoodEstablishment",
16 "HealthAndBeautyBusiness", "HomeAndConstructionBusiness",
17 ):
18 return {
19 "biz_id": biz_id,
20 "name": node.get("name"),
21 "rating": (node.get("aggregateRating") or {}).get("ratingValue"),
22 "review_count": (node.get("aggregateRating") or {}).get("reviewCount"),
23 "address": node.get("address"),
24 "telephone": node.get("telephone"),
25 "price_range": node.get("priceRange"),
26 "hours": node.get("openingHours"),
27 "url": url,
28 }
29 return {"biz_id": biz_id, "url": url}O valor de meta[name="yelp-biz-id"] é o ID codificado da empresa que você vai precisar para o endpoint de reviews. Pegue isso aqui — você vai usar no próximo passo.
Passo 4: Raspe as Avaliações do Yelp com Paginação
É aqui que a Fusion API fica curta e a raspagem mostra sua força. O endpoint interno GraphQL do Yelp retorna texto completo das avaliações, informações do avaliador, datas, notas e contagem de votos — tudo o que a API não fornece.
O endpoint é https://www.yelp.com/gql/batch, e ele usa um documentId estático para a operação GetBusinessReviewFeed. A paginação funciona por meio de um cursor codificado em base64.
1import base64
2GQL_URL = "https://www.yelp.com/gql/batch"
3DOC_ID = "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
4def fetch_reviews(enc_biz_id: str, num_pages: int = 5):
5 all_reviews = []
6 for page in range(num_pages):
7 offset = page * 10
8 cursor = base64.b64encode(
9 json.dumps({"version": 1, "offset": offset}).encode()
10 ).decode()
11 payload = [{
12 "operationName": "GetBusinessReviewFeed",
13 "variables": {
14 "encBizId": enc_biz_id,
15 "reviewsPerPage": 10,
16 "after": cursor,
17 "sortBy": "DATE_DESC",
18 "language": "en",
19 },
20 "extensions": {
21 "operationType": "query",
22 "documentId": DOC_ID,
23 },
24 }]
25 r = requests.post(
26 GQL_URL,
27 json=payload,
28 headers={
29 **HEADERS,
30 "content-type": "application/json",
31 "x-apollo-operation-name": "GetBusinessReviewFeed",
32 "apollographql-client-name": "yelp-main-frontend",
33 },
34 impersonate="chrome131",
35 )
36 if r.status_code != 200:
37 print(f"Falha ao buscar reviews no offset {offset}: {r.status_code}")
38 break
39 data = r.json()
40 # Navegue pela estrutura da resposta para extrair as avaliações
41 try:
42 reviews = data[0]["data"]["business"]["reviews"]["edges"]
43 for edge in reviews:
44 node = edge.get("node", {})
45 all_reviews.append({
46 "reviewer": node.get("author", {}).get("displayName"),
47 "rating": node.get("rating"),
48 "date": node.get("localizedDate"),
49 "text": node.get("text", {}).get("full"),
50 })
51 except (KeyError, IndexError, TypeError):
52 break
53 import time, random
54 time.sleep(random.uniform(3, 7))
55 return all_reviewsCada página retorna 10 avaliações. O offset é incrementado no cursor base64 para paginar. O parâmetro sortBy aceita DATE_DESC (mais recentes primeiro), RATING_ASC, RATING_DESC e outros.
Passo 5: Exporte Seus Dados do Yelp
1import pandas as pd
2# Supondo que você já tenha coletado empresas e avaliações
3df_businesses = pd.DataFrame(businesses)
4df_businesses.to_csv("yelp_businesses.csv", index=False)
5df_reviews = pd.DataFrame(all_reviews)
6df_reviews.to_csv("yelp_reviews.csv", index=False)
7# Ou salve em JSON para mais flexibilidade
8import json
9with open("yelp_data.json", "w") as f:
10 json.dump({"businesses": businesses, "reviews": all_reviews}, f, indent=2)Para quem segue o caminho sem código, o Thunderbit exporta os mesmos dados direto para Excel, Google Sheets, Airtable ou Notion — sem pandas e sem escrever código de arquivo.
O Plano Anti-Bloqueio: Como Raspar o Yelp Sem Ser Barrado
Esta seção existe por um motivo: o Yelp endureceu bastante suas medidas anti-bot desde o fim de 2024 — estão todos em jogo. A maior parte dos guias por aí está desatualizada porque foi escrita antes dessa ofensiva.
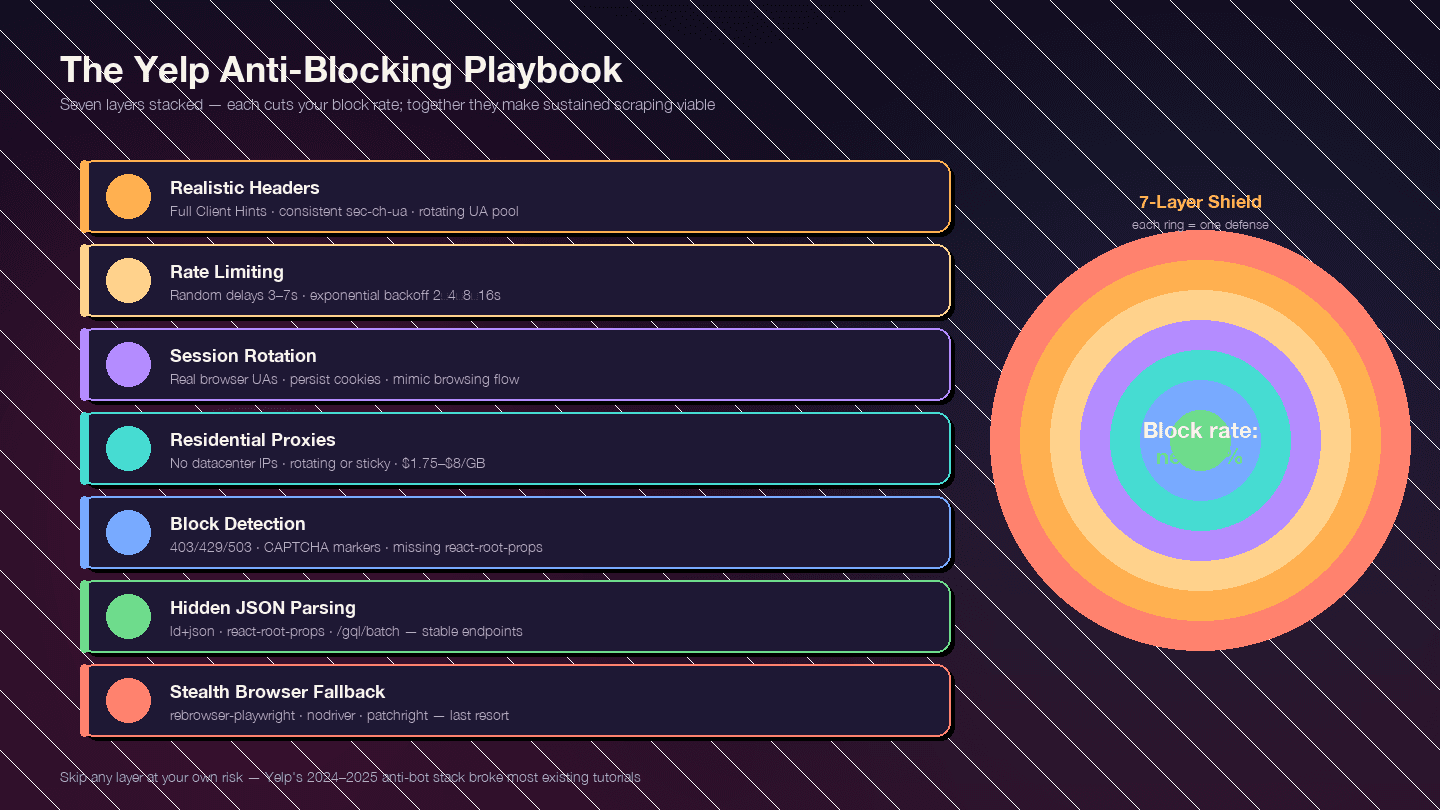
A estratégia é em camadas. Cada camada reduz tua taxa de bloqueio; juntas, elas tornam a raspagem contínua viável.
Camada 1: Cabeçalhos Realistas de Requisição
Os cabeçalhos padrão do requests enviam User-Agent: python-requests/2.x — bloqueio instantâneo. Mas só um User-Agent realista não basta. O Yelp verifica o conjunto completo de cabeçalhos para consistência.
1FULL_HEADERS = {
2 "authority": "www.yelp.com",
3 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36",
6 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
7 "image/avif,image/webp,image/apng,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 "accept-encoding": "gzip, deflate, br",
10 "sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
11 "sec-ch-ua-mobile": "?0",
12 "sec-ch-ua-platform": '"Windows"',
13 "sec-fetch-dest": "document",
14 "sec-fetch-mode": "navigate",
15 "sec-fetch-site": "same-origin",
16 "sec-fetch-user": "?1",
17 "upgrade-insecure-requests": "1",
18 "referer": "https://www.yelp.com/",
19 "cookie": "intl_splash=false",
20}Três erros que fazem você ser sinalizado:
- O UA diz Chrome, mas o
sec-ch-uaestá ausente ou contradiz a versão do UA - O
sec-ch-ua-platformdiz "Windows" enquanto a string do UA aponta macOS - O mesmo UA sendo usado em milhares de requisições de um único IP — alterne entre 10 a 20 strings recentes de Chrome/Firefox/Safari
Camada 2: Limitação de Taxa e Delays Aleatórios
Padrões de tempo previsíveis são um sinal de alerta. Adicione intervalos aleatórios entre requisições e implemente backoff exponencial quando houver erro.
1import random, time
2def polite_get(client_get, url, attempt=0):
3 r = client_get(url, headers=FULL_HEADERS, impersonate="chrome131")
4 if r.status_code in (403, 429, 503):
5 if attempt >= 4:
6 raise RuntimeError(f"Bloqueado após {attempt + 1} tentativas em {url}")
7 backoff = 2 ** (attempt + 1) + random.random()
8 print(f" Recebi {r.status_code}, aguardando {backoff:.1f}s (tentativa {attempt + 1})")
9 time.sleep(backoff)
10 return polite_get(client_get, url, attempt + 1)
11 time.sleep(random.uniform(3, 7))
12 return r| Parâmetro | Valor recomendado |
|---|---|
| Pausa aleatória entre requisições | random.uniform(3, 7) segundos |
| Backoff em 429/403/503 | 2 → 4 → 8 → 16s, máximo de 5 tentativas |
| Trabalhadores simultâneos por IP | 1 (serialize por IP; use proxies para paralelismo) |
| Taxa máxima sustentada por IP residencial | ~1 req / 5s (~12 rpm) |
Camada 3: Rotação de User-Agent e Sessão
Alterne entre vários User-Agents reais de navegadores. Preserve sessões e cookies para simular comportamento de navegação autêntico — o Yelp usa detecção baseada em cookies, então criar uma sessão nova a cada requisição também parece suspeito.
1UA_POOL = [
2 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
3 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14.4; rv:125.0) Gecko/20100101 Firefox/125.0",
6 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 Safari/17.4.1",
7 # Adicione mais 5–10 strings recentes
8]Camada 4: Rotação de Proxies
Em qualquer volume real, você vai precisar de proxies residenciais. Proxies de data center e gratuitos não funcionam no Yelp — a camada de reputação de IP do Yelp já bloqueia preventivamente faixas de AWS, GCP e DigitalOcean.
| Fornecedor | Preço inicial por GB | Observações |
|---|---|---|
| IPRoyal | $1.75/GB | Mais barato; hospeda o tutorial de Yelp mais citado |
| Decodo (ex-Smartproxy) | $3.20–$3.50 | Melhor relação GB/$ em escala |
| Bright Data | $4.00 (PAYG) | Pool com mais de 150M de IPs; página dedicada para proxies Yelp |
| Oxylabs | $6.00–$8.00 | Premium; mais de 10M de IPs |
| Aluvia (SIM móvel) | $3.00 | IPs móveis reais de operadoras dos EUA, posicionados para Yelp |
Rotação residencial (um IP novo por requisição) funciona melhor para crawls de busca em alto volume. Sessões fixas (manter um IP por 10 minutos) funcionam melhor quando você quer preservar cookies num fluxo de página da empresa → reviews → paginação.
Camada 5: Detectando e Tratando Bloqueios
Nem todo bloqueio aparece do mesmo jeito. O Yelp muitas vezes devolve um shell genérico de “page not available” em vez de um CAPTCHA, e é por isso que raspadores ingênuos acham que estão recebendo dados quando, na verdade, estão recebendo respostas vazias.
1BLOCK_MARKERS = (
2 "captcha", "px-captcha", "page not available",
3 "access denied", "unusual traffic",
4)
5def is_blocked(resp):
6 if resp.status_code in (401, 403, 429, 503):
7 return True
8 body = resp.text.lower()
9 if any(m in body for m in BLOCK_MARKERS):
10 return True
11 # Se for uma página de busca/empresa e react-root-props estiver ausente,
12 # o Yelp entregou uma resposta bloqueada e enxuta
13 if "react-root-props" not in body and "/biz/" in str(resp.url):
14 return True
15 return False| Sinal | Significado |
|---|---|
| HTTP 403 | Bloqueio duro — IP/cabeçalho/TLS queimados |
| HTTP 429 | Limite de taxa — geralmente recuperável com backoff |
| HTTP 503 | Bloqueio genérico ou redução de carga |
Redirecionamento para /error ou corpo com "page not available" | Bloqueio leve |
| vazio com apenas | Página de desafio aguardando JS |
captcha / g-recaptcha / px-captcha no corpo | Escalonado — CAPTCHA exigido |
Ausência de react-root-props em uma página de listagem | Resposta bloqueada e enxuta |
Camada 6: O Truque de Parsing Resiliente — JSON Oculto em vez de Seletores CSS
Vale repetir: o Yelp randomiza os nomes das classes CSS a cada build. Um raspador preso a h3.y-css-14xwok2 vai quebrar em poucas semanas quando o Yelp fizer um novo deploy com h3.y-css-hcq7b9.
Os payloads que não mudam:
<script type="application/ld+json">— dados estruturados schema.org (nome, endereço, telefone, avaliação, horário)<script data-id="react-root-props">— dados completos dos resultados da busca em JSONhttps://www.yelp.com/gql/batch— endpoint GraphQL de avaliações comdocumentIdestável
Se você estiver analisando classes CSS, está construindo sobre areia. Analise o JSON em vez disso.
Camada 7: O Plano B com Navegador Discreto
Use um navegador headless só quando curl_cffi + proxies residenciais não derem conta — normalmente quando o Yelp apresentar uma página de desafio em JavaScript ou um CAPTCHA.
Para 95% da raspagem de empresas, busca e reviews, curl_cffi + JSON oculto + proxies residenciais é mais rápido, mais barato e mais confiável do que um navegador. Mas quando você realmente precisar de um navegador:
| Ferramenta | Status (2025) | Observações |
|---|---|---|
| rebrowser-playwright | Ponto de partida recomendado | Playwright adaptado para corrigir vazamentos de CDP |
| nodriver | Melhor da categoria para stealth no Chrome | Sucessor do undetected-chromedriver; evita totalmente o protocolo WebDriver |
| patchright | Fork do Playwright mantido ativamente | Passa em testes modernos de detecção |
| playwright-stealth | Maduro | Corrige navigator.webdriver, remove HeadlessChrome do UA |
Evite Selenium puro para o Yelp. Ele é fácil demais de identificar.
API Yelp Fusion vs. Raspagem em Python vs. Thunderbit: Comparação Completa
| Dimensão | API Yelp Fusion | Raspagem em Python | Thunderbit |
|---|---|---|---|
| Texto completo das avaliações | ❌ 3 trechos × ~160 caracteres | ✅ Ilimitado (GraphQL) | ✅ Modelo de reviews integrado |
| Metadados das reviews (votos, resposta do dono) | ❌ | ✅ | ✅ Via campos sugeridos por IA |
| Fotos | ❌ (0 no plano Base) | ✅ Ilimitadas | ✅ |
| Máximo de resultados por busca | 240 (era 1.000 antes de 2024) | Ilimitado (com paginação) | Ilimitado |
| Limite diário | 300–500 (novos) / 5.000 (legado) | Só o orçamento de proxy | Baseado em créditos (3.000/mês no Pro) |
| Esforço de configuração | ~15 min | Horas a dias | ~2 minutos |
| Tratamento anti-bot | N/A | Seu problema | Tratado (modo Cloud) |
| Risco legal | Baixo (autorizado) | Médio (área cinzenta nos termos) | Médio (mesmo da raspagem) |
| Custo inicial | $29/mês | ~$0.75–$4/GB em proxies + tempo de desenvolvimento | Plano grátis |
| Custo em uso intenso | $643+/mês | $50–$500/mês em proxies + tempo de desenvolvimento | $38–$49/mês |
| Exportação de dados | JSON | CSV/JSON (você implementa) | Excel / Sheets / Airtable / Notion — grátis |
| Manutenção | Baixa | Alta (seletores quebram, bloqueios aumentam) | Baixa (IA se adapta) |
Dicas Legais e Éticas para Raspar o Yelp
Não sou advogado, e isso não é aconselhamento jurídico. Mas o cenário legal mudou o suficiente nos últimos dois anos para que você entenda o básico antes de investir tempo num projeto de raspagem do Yelp.
O que os Termos de Serviço do Yelp dizem: a proíbe explicitamente usar “qualquer robô, spider... ou outro dispositivo automatizado” para “acessar, recuperar, copiar, raspar ou indexar qualquer parte do Serviço”. Também adicionou linguagem sobre “AI Technologies e/ou outras ferramentas automatizadas”.
O : “O Yelp não permite raspagem de nenhum tipo no site.”
O que o robots.txt diz: o tem um wildcard User-agent: * / Disallow: / e bloqueia especificamente GPTBot, ClaudeBot, PerplexityBot, CCBot e Meta-ExternalAgent. Só Googlebot, Bingbot e alguns rastreadores de redes sociais estão liberados.
O precedente jurídico que importa: em (N.D. Cal., jan. 2024), o tribunal decidiu que raspar dados públicos e sem login não violava os Termos de Serviço do Meta. A distinção central é esta: dados públicos sem login vs. dados atrás de login. O caso estabeleceu que raspar dados públicos provavelmente não viola o CFAA, mas a hiQ ainda perdeu em ações civis estaduais (trespass to chattels, misappropriation) e recebeu uma condenação de $500.000.
Orientações práticas:
- Raspe só páginas públicas e sem login
- Limite a taxa das requisições (os atrasos deste guia também funcionam como limites éticos)
- Não revenda texto bruto de avaliações atribuído a usuários identificados — respeite a privacidade dos avaliadores
- Cumpra as leis locais de proteção de dados (CCPA, GDPR)
- Não faça login para raspar — isso cruza a linha da autorização
- Trate informações comerciais (nome/endereço/telefone/avaliação) como dados factuais públicos; trate o texto das avaliações como algo mais sensível
Consulte um profissional jurídico para o teu caso específico.
Conclusão
Três caminhos, um objetivo.
A API Yelp Fusion é a opção autorizada e de baixa manutenção — mas limita a 3 trechos de avaliação e começa em $29/mês. A raspagem em Python oferece controle total sobre cada ponto de dado do Yelp, mas exige investimento real: curl_cffi para imitar TLS, proxies residenciais, atrasos aleatórios, parsing de JSON oculto e manutenção contínua à medida que as defesas do Yelp evoluem. O Thunderbit leva você de “preciso dos dados do Yelp” até “aqui está minha planilha” em cerca de 30 segundos, sem código e sem configuração de proxy.
Os fundamentos anti-bloqueio que realmente funcionam em 2025: cabeçalhos realistas com Client Hints completos, curl_cffi para imitar a impressão digital TLS, atrasos aleatórios com backoff exponencial, rotação de proxies residenciais e — acima de tudo — parsing de JSON oculto (application/ld+json e react-root-props) em vez de seletores CSS frágeis.
Não sabe qual caminho faz mais sentido? Experimente primeiro o . Se ele atender ao que você precisa, você economiza horas. Se precisar de mais controle — pipelines programáticos completos, campos personalizados, integração estreita com CRM — o guia em Python acima cobre isso. E, para uma visão mais ampla do cenário de ferramentas de raspagem, veja nosso resumo das ou nosso guia sobre .
FAQs
Posso raspar o Yelp gratuitamente com Python?
Sim — usando bibliotecas grátis como curl_cffi, parsel e jmespath. Mas, em qualquer volume real (mais do que algumas dezenas de páginas), você vai precisar de proxies residenciais pagos, que começam em torno de . O Thunderbit também oferece um plano grátis com 6 páginas/mês para extração rápida, sem código.
O Yelp bloqueia raspadores?
Sim, e de forma agressiva. O Yelp usa . O requests puro é bloqueado na primeira tentativa. A estratégia em camadas deste guia — curl_cffi para imitar TLS, cabeçalhos realistas, atrasos aleatórios e proxies residenciais — é o que funciona em 2025.
A API Yelp Fusion é melhor do que raspar?
Depende do que você precisa. A API é autorizada e tem baixo risco, mas retorna apenas , limita os resultados de busca a 240 e começa em $29/mês. Se você precisa do texto completo das avaliações, metadados das reviews ou de mais de algumas centenas de registros por dia, a raspagem é a única opção.
Como faço para raspar avaliações do Yelp com Python?
Use curl_cffi com impersonate="chrome131" para buscar a página da empresa, extraia o ID codificado da empresa em <meta name="yelp-biz-id"> e depois envie um POST para https://www.yelp.com/gql/batch com a operação GetBusinessReviewFeed, paginando via um cursor after codificado em base64. O código passo a passo está na seção de tutorial acima. O também é uma boa referência de implementação.
Posso raspar o Yelp sem programar?
Sim — o já traz modelos prontos de e . Abra uma página do Yelp, clique em AI Suggest Fields e depois em Scrape. As exportações para Google Sheets, Excel, Airtable e Notion são gratuitas em todos os planos, inclusive no grátis.
Saiba mais