O Walmart altera os preços de alguns itens . Se você já tentou acompanhar isso programaticamente, sabe bem como é frustrante: o script funciona durante 20 minutos e, de repente, passa a devolver páginas de CAPTCHA disfarçadas de respostas normais 200 OK.
Passei muito tempo lidando com as defesas anti-bot do Walmart como parte do nosso trabalho de extração de dados na , e quero partilhar tudo o que aprendi — os métodos que realmente funcionam em 2025, as falhas silenciosas que contaminam os dados e os trade-offs honestos entre escrever o seu próprio scraper, pagar por uma API de scraping e simplesmente usar uma ferramenta no-code. Este guia cobre três métodos de extração (parse de HTML, JSON __NEXT_DATA__ e interceptação de API interna), tratamento de erros pronto para produção que a maioria dos tutoriais ignora por completo e uma estrutura de decisão franca para escolher a abordagem certa. Há algo aqui para si, tanto se estiver a escrever em Python como se só quiser uma folha de cálculo cheia de preços até ao almoço.
Por que fazer scraping do Walmart com Python?
O Walmart é o maior retalhista do mundo em receita — no ano fiscal de 2025, mantendo o . O site hospeda cerca de , com o CFO do Walmart a citar no marketplace. Cerca de , o que significa que o catálogo é volátil — vendedores entram e saem, variantes mudam e o stock vira de um dia para o outro.
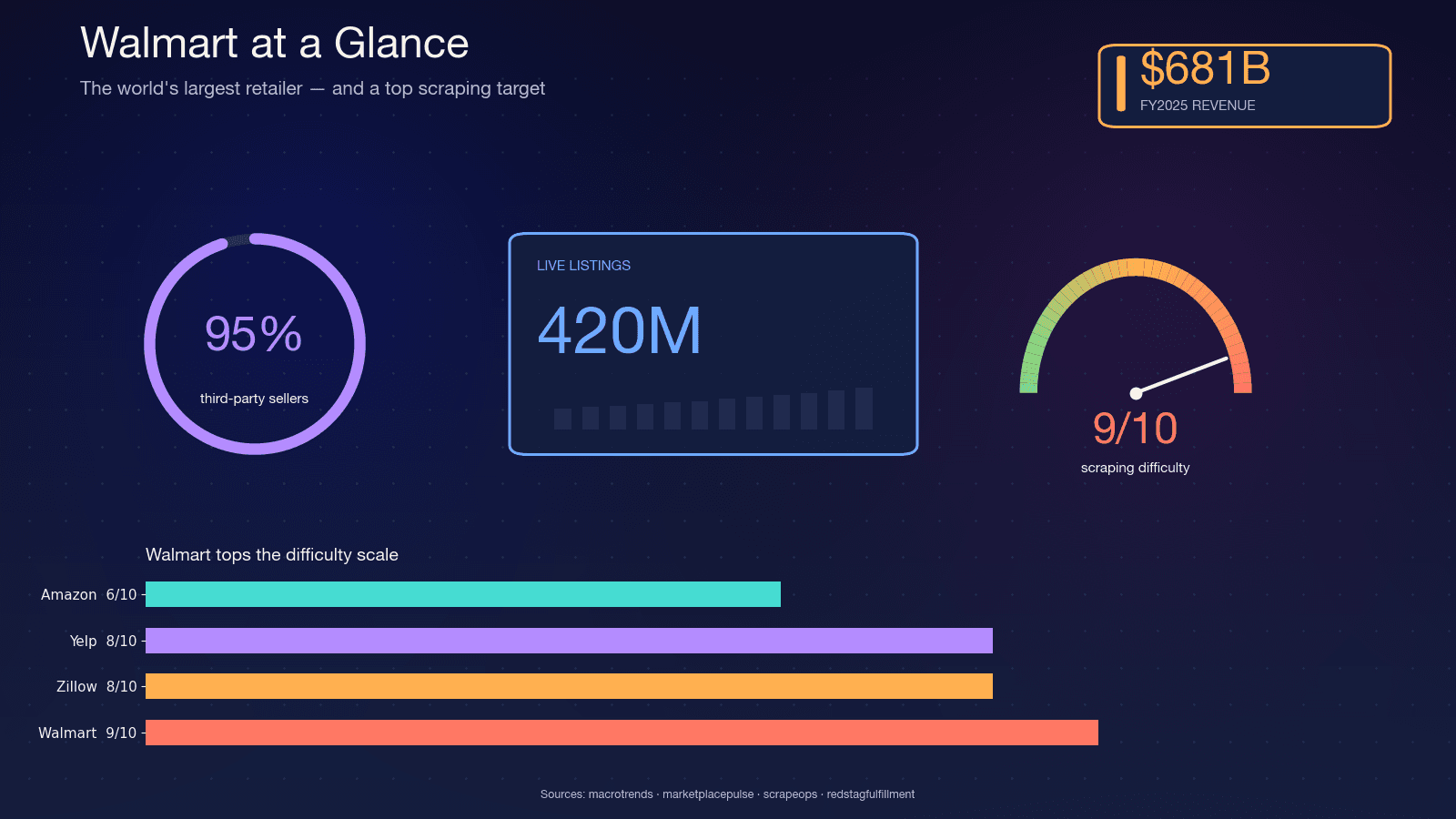
Essa volatilidade é precisamente o motivo pelo qual o scraping importa. Um relatório trimestral não capta o que um scrape noturno consegue. Aqui estão os casos de uso mais comuns que vejo:
| Caso de uso | Quem precisa disso | O que extraem |
|---|---|---|
| Monitorização de preços da concorrência | Operações de e-commerce, ferramentas de repricing | Preços, promoções, conformidade com MAP |
| Enriquecimento do catálogo de produtos | Equipas de vendas e merchandising | Descrições, imagens, especificações, variantes |
| Acompanhamento da disponibilidade em stock | Cadeia de abastecimento, dropshippers | Estado de stock, informações do vendedor |
| Pesquisa de mercado e análise de tendências | Marketing, gestores de produto | Avaliações, reviews, sortido por categoria |
| Geração de leads | Equipas de vendas | Nomes de vendedores, quantidade de produtos, categorias |
Só o e a previsão é chegar a US$ 5,09 mil milhões até 2033. O comportamento do consumidor impulsiona esse investimento: , e 83% pesquisam preços em vários sites.
Python é a linguagem padrão para este trabalho. O Infrastructure Report de 2026 da Apify estima , e a biblioteca principal (requests) recebe . Se faz scraping em qualquer escala, quase de certeza está a fazê-lo em Python.
Por que o Walmart é um dos sites mais difíceis de fazer scraping
O Walmart é especialmente difícil porque executa dois produtos comerciais anti-bot em série: , como camada de WAF e fingerprinting de TLS na borda, e , como camada de desafio JavaScript comportamental. A Scrape.do chama a esta combinação de "rara e extremamente difícil de contornar".
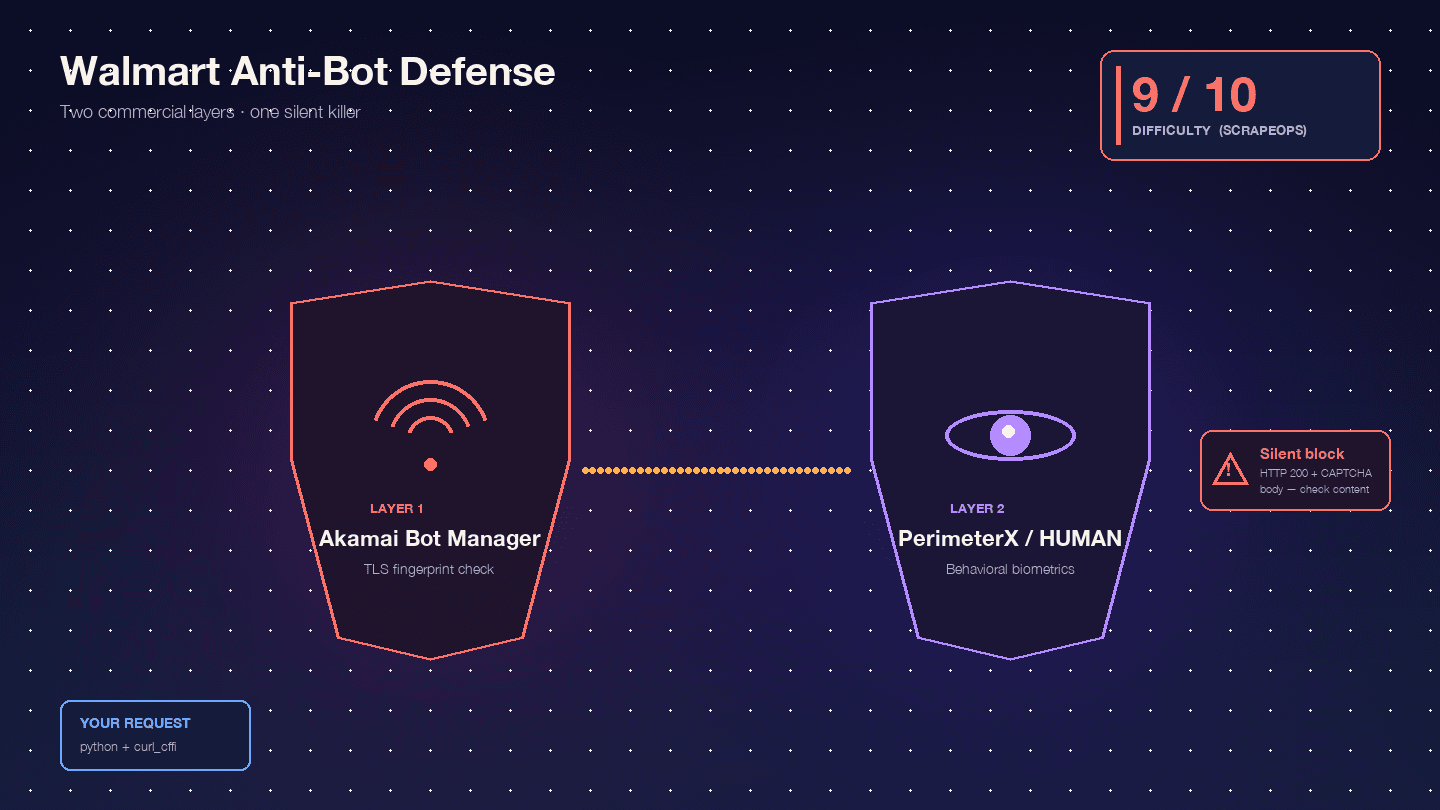
, com o Akamai sozinho em 9/10. Pela minha experiência, isso faz sentido.
Veja com o que está realmente a lidar:
Akamai Bot Manager inspeciona o fingerprint de TLS (hash JA3/JA4), a ordem dos frames HTTP/2, a ordem e o case dos headers, além dos cookies de sessão (_abck, ak_bmsc). Uma chamada padrão do Python requests emite um fingerprint de TLS que nenhum navegador real produz — o Akamai identifica isso antes mesmo de a sua requisição chegar aos servidores do Walmart.
PerimeterX/HUMAN entra em ação depois do Akamai, executando fingerprinting em JavaScript (px.js) que verifica propriedades do navigator, renderização de canvas, WebGL, contexto de áudio e biometria comportamental (movimento do rato, velocidade de scroll, dinâmica de teclas). A falha visível é o famoso desafio — um botão que precisa de ser pressionado durante cerca de 10 segundos enquanto os sinais comportamentais são recolhidos. A Oxylabs é clara: "O Walmart usa o modelo de CAPTCHA 'Press & Hold', oferecido pelo PerimeterX, que é conhecido por ser quase impossível de resolver por código."
O comportamento realmente perigoso é o bloqueio silencioso. O Walmart devolve HTTP 200 com um corpo de CAPTCHA em vez de 403. : "O Walmart devolve um estado 200 OK mesmo quando serve uma página de CAPTCHA. Não pode confiar apenas no código de estado para saber se a requisição funcionou." O seu script analisa alegremente o HTML do CAPTCHA como se fosse "produto não encontrado" e segue em frente. Metade do seu dataset vira lixo, e nem dá por isso.
Depois há o problema dos dados ligados à loja. Os preços e o stock do Walmart são específicos por localização, controlados por cookies como locDataV3 e assortmentStoreId. Sem os cookies corretos, recebe dados "nacionais padrão" que podem parecer completos, mas não batem certo com o que compradores reais veem. Cookies em falta não geram uma página de bloqueio — geram dados errados sem falha visível, o que é pior.
Três métodos para extrair dados do Walmart (e como eles se comparam)
Antes do passo a passo, aqui estão as três abordagens principais de extração. A maioria dos tutoriais da concorrência cobre só uma ou duas. Vou passar pelas três para que possa escolher a que faz sentido para o seu caso.
| Método | Fiabilidade | Completude dos dados | Dificuldade anti-bot | Esforço de manutenção |
|---|---|---|---|---|
| HTML + BeautifulSoup | ⚠️ Baixa (os seletores quebram a cada deploy) | Moderada | Alta | Alta |
JSON __NEXT_DATA__ | ✅ Boa | Alta | Médio-alta | Média |
| Interceção de API interna | ✅ Melhor | Mais alta (variantes, stock, reviews) | Médio-alta | Baixa (JSON estruturado) |
| Thunderbit (no-code) | ✅ Boa | Alta | Baixa (gerida pela IA) | Nenhuma |
O parse de HTML é a pior opção para o Walmart — o site entrega bundles Next.js com nomes de classes CSS com hash que mudam a cada deploy. O método de JSON __NEXT_DATA__ é a escolha pragmática usada por todos os scrapers sérios de Walmart em open source de 2024 a 2026. A interceção de API interna é a mais poderosa, mas vem com ressalvas que a maioria dos tutoriais ignora. E a Thunderbit é a escolha certa quando nem sequer precisa de um pipeline personalizado.
Configurando o seu ambiente Python para fazer scraping do Walmart
Vai precisar de:
- Dificuldade: Intermédia
- Tempo necessário: ~30 minutos para configuração, mais o tempo de codificação
- O que vai precisar: Python 3.10+, pip, um editor de código e, para uso em produção, um serviço de proxy ou uma API de scraping
Crie a pasta do projeto e o ambiente virtual:
1mkdir walmart-scraper && cd walmart-scraper
2python -m venv venv
3source venv/bin/activate # No Windows: venv\Scripts\activateInstale as bibliotecas necessárias:
1pip install curl_cffi parsel beautifulsoup4 lxmlcurl_cffi é o padrão de 2025 para fazer scraping de alvos difíceis. É um binding de libcurl que consegue imitar com precisão os fingerprints de TLS de navegadores reais. : "O Walmart usa fingerprinting de TLS como parte da sua deteção de bots, e mesmo definir o User-Agent para simular um navegador real não vai contornar isso." requests puro ou httpx não passam pelo Akamai, independentemente dos headers que definir. É o curl_cffi com impersonate="chrome124" que faz a diferença.
Também vale ter json (nativo), csv (nativo), time, random e logging para os padrões de produção que veremos adiante.
Passo a passo: faça scraping de páginas de produtos do Walmart com Python
Passo 1: buscar a página do produto no Walmart
A sua primeira tarefa é fazer uma requisição HTTP que não seja bloqueada imediatamente. Aqui está o conjunto de headers canónico usado pela Scrapfly, Scrapingdog, Oxylabs e ScrapeOps entre 2024 e 2026:
1from curl_cffi import requests
2HEADERS = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
5 "AppleWebKit/537.36 (KHTML, like Gecko) "
6 "Chrome/124.0.0.0 Safari/537.36"
7 ),
8 "Accept": (
9 "text/html,application/xhtml+xml,application/xml;q=0.9,"
10 "image/avif,image/webp,*/*;q=0.8"
11 ),
12 "Accept-Language": "en-US,en;q=0.9",
13 "Accept-Encoding": "gzip, deflate, br",
14 "Upgrade-Insecure-Requests": "1",
15 "Sec-Fetch-Dest": "document",
16 "Sec-Fetch-Mode": "navigate",
17 "Sec-Fetch-Site": "none",
18 "Sec-Fetch-User": "?1",
19 "Referer": "https://www.google.com/",
20}
21session = requests.Session(impersonate="chrome124")
22url = "https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/1752657021"
23response = session.get(url, headers=HEADERS)O parâmetro impersonate="chrome124" é o que faz o trabalho pesado aqui. Ele diz ao curl_cffi para corresponder exatamente ao ClientHello TLS, à ordem dos frames HTTP/2 e à sequência de pseudo-headers do Chrome 124. Sem isso, o Akamai vê um hash JA3 específico de Python e bloqueia-o antes que a requisição chegue à camada de aplicação do Walmart.
Como é uma resposta bloqueada: se vir "Robot or human?" no título do HTML da resposta, ou se a resposta redirecionar para walmart.com/blocked, foi apanhado. O detalhe complicado é que o Walmart muitas vezes devolve um código 200 com o corpo do CAPTCHA — por isso, verificar apenas response.ok não chega.
Para qualquer uso em produção ou repetido, vai precisar de proxies residenciais. IPs de datacenter são queimados instantaneamente pelo sistema de reputação de IP do Akamai. Vou cobrir toda a estratégia de tratamento de erros e proxies na secção de produção abaixo.
Passo 2: analisar os dados do produto a partir do JSON __NEXT_DATA__
O Walmart.com é uma aplicação Next.js, e o HTML renderizado no servidor embute todo o payload de hidratação dentro de uma única tag script: <script id="__NEXT_DATA__" type="application/json">. Essa é a mina de ouro.
: "Em 2026, o Walmart usa Next.js com JSON estruturado em tags script __NEXT_DATA__, tornando a extração de dados ocultos mais fiável do que o parse tradicional por seletores CSS." Todo scraper de Walmart open source de grande visibilidade — , , — usa este método.
Veja como extraí-lo:
1import json
2from parsel import Selector
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6product = data["props"]["pageProps"]["initialData"]["data"]["product"]
7idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})A maioria dos tutoriais para aqui. Abaixo está um mapa completo dos caminhos JSON para os campos que realmente importam — verificado em páginas ativas do Walmart entre 2024 e 2026:
| Campo de dados | Caminho JSON (em initialData) | Tipo | Observações |
|---|---|---|---|
| Nome do produto | data > product > name | String | — |
| Marca | data > product > brand | String | — |
| Preço atual (número) | data > product > priceInfo > currentPrice > price | Float | Pode variar conforme o cookie da loja |
| Preço atual (string) | data > product > priceInfo > currentPrice > priceString | String | Formatado, por exemplo "US$ 9,99" |
| Descrição curta | data > product > shortDescription | String HTML | Analise com BeautifulSoup para obter texto |
| Descrição longa | data > idml > longDescription | String HTML | Fica em idml, e NÃO dentro de product — essa é a armadilha que tutoriais antigos erram |
| Todas as imagens | data > product > imageInfo > allImages | Array | Lista de objetos {id, url} |
| Avaliação média | data > product > averageRating | Float | A chave é averageRating, não o legado rating |
| Quantidade de reviews | data > product > numberOfReviews | Integer | — |
| Variantes | data > product > variantCriteria | Array | Grupos de opções (tamanho, cor) |
| Disponibilidade | data > product > availabilityStatus | String | IN_STOCK, OUT_OF_STOCK, LIMITED_STOCK |
| Vendedor | data > product > sellerDisplayName | String | — |
| Fabricante | data > product > manufacturerName | String | — |
O caminho longDescription é a armadilha que apanha muita gente. Um post da ScrapeHero de 2023 colocava-o em product.longDescription, mas fontes de 2024+ mostram consistentemente que fica na chave irmã idml. Leia sempre primeiro idml.longDescription e use product.longDescription como fallback para páginas mais antigas.
Aqui está o padrão seguro de extração usando encadeamento com .get():
1def extract_product(data):
2 product = data["props"]["pageProps"]["initialData"]["data"]["product"]
3 idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})
4 price_info = product.get("priceInfo", {})
5 current_price = price_info.get("currentPrice", {})
6 image_info = product.get("imageInfo", {})
7 return {
8 "name": product.get("name"),
9 "brand": product.get("brand"),
10 "price": current_price.get("price"),
11 "price_string": current_price.get("priceString"),
12 "short_desc": product.get("shortDescription"),
13 "long_desc": idml.get("longDescription", product.get("longDescription")),
14 "images": [img.get("url") for img in image_info.get("allImages", [])],
15 "rating": product.get("averageRating"),
16 "review_count": product.get("numberOfReviews"),
17 "variants": product.get("variantCriteria"),
18 "availability": product.get("availabilityStatus"),
19 "seller": product.get("sellerDisplayName"),
20 "manufacturer": product.get("manufacturerName"),
21 }Para quem não quer lidar com navegação por caminhos JSON, a identifica e estrutura estes campos automaticamente — sem mapear caminhos manualmente. Clica em "AI Suggest Fields", a IA lê a página e recebe uma tabela. Mas, se estiver a construir um pipeline personalizado, o mapa acima é a sua referência.
Passo 3: intercecionar os endpoints internos da API do Walmart para obter dados mais ricos
Nenhum artigo da concorrência cobre este método devidamente. É a forma de extração mais poderosa — e a mais complicada.
O front-end do Walmart chama um . Os endpoints ficam em www.walmart.com/orchestra/*:
/orchestra/pdp/graphql/...— hidratação da página de produto + troca de variantes/orchestra/snb/graphql/...— paginação de search-n-browse/orchestra/reviews/graphql/...— reviews paginados
Eles devolvem JSON limpo e estruturado com dados que o __NEXT_DATA__ às vezes trunca — preços por variante, contagens de stock em tempo real, paginação completa de reviews.
O detalhe que os posts de blog costumam contornar: o Walmart usa . O corpo da requisição envia apenas um hash SHA-256 (persistedQuery.sha256Hash), não o texto da query. Se o hash não for conhecido pelo servidor, recebe PersistedQueryNotFound. O Walmart roda esses hashes a cada deploy. É por isso que nenhum dos scrapers de Walmart open source mais conhecidos publica código pronto a copiar e colar em /orchestra/.
A versão prática e honesta deste método é um exercício no DevTools:
- Abra uma página de produto do Walmart no Chrome
- Abra o DevTools → separador Network, filtre por "Fetch/XHR"
- Navegue normalmente pela página — clique em variantes, faça scroll até aos reviews, altere a localização da loja
- Procure requisições para endpoints
/orchestra/*que devolvam JSON com dados do produto - Clique com o botão direito na requisição → "Copy as cURL"
- Converta o comando cURL para Python usando
curl_cffi
Veja como fica uma chamada de API reproduzida:
1import json
2from curl_cffi import requests
3session = requests.Session(impersonate="chrome124")
4# Primeiro, aqueça a sessão visitando a página do produto
5session.get("https://www.walmart.com/ip/some-product/1234567", headers=HEADERS)
6# Depois, reproduza a chamada da API interna (copiada do DevTools)
7api_url = "https://www.walmart.com/orchestra/pdp/graphql"
8api_headers = {
9 **HEADERS,
10 "accept": "application/json",
11 "content-type": "application/json",
12 "referer": "https://www.walmart.com/ip/some-product/1234567",
13 "wm_qos.correlation_id": "your-copied-correlation-id",
14}
15payload = {
16 # Cole aqui o corpo exato da requisição a partir do DevTools
17 "variables": {"productId": "1234567"},
18 "extensions": {
19 "persistedQuery": {
20 "version": 1,
21 "sha256Hash": "the-hash-you-copied"
22 }
23 }
24}
25api_response = session.post(api_url, headers=api_headers, json=payload)
26api_data = api_response.json()A etapa de aquecimento da sessão é crítica. Os cookies PerimeterX do Walmart (_px3, _pxhd, ACID) precisam de ser definidos pela pesquisa inicial do HTML antes de a chamada da API funcionar. Sem eles, recebe um 412 ou 403.
Quando usar este método: quando precisa de dados que o __NEXT_DATA__ não inclui — preços profundos por variante, reviews paginados além do primeiro lote ou contagens de stock em tempo real. Para a maioria dos casos, __NEXT_DATA__ é suficiente e muito mais simples.
Fazendo scraping dos resultados de busca e de várias páginas do Walmart
Os resultados de busca seguem um padrão __NEXT_DATA__ semelhante, mas com um caminho JSON diferente:
1search_url = "https://www.walmart.com/search?q=laptops&page=1"
2response = session.get(search_url, headers=HEADERS)
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6search_result = data["props"]["pageProps"]["initialData"]["searchResult"]
7items = search_result["itemStacks"][0]["items"]
8# Filtre produtos patrocinados
9organic_items = [i for i in items if i.get("__typename") == "Product"]
10for item in organic_items:
11 print(item.get("name"), item.get("priceInfo", {}).get("currentPrice", {}).get("price"))A paginação funciona incrementando o parâmetro page: &page=1, &page=2 etc. Mas há um limite não documentado: o Walmart limita os resultados de busca a 25 páginas, independentemente do total real. : "O Walmart define o número máximo de páginas de resultados que podem ser acedidas em 25, independentemente do total de páginas disponíveis."
Alternativas para obter cobertura mais profunda:
- Alternar a ordem de classificação: execute a mesma consulta com
&sort=price_lowe depois com&sort=price_highpara obter cerca de 50 páginas de cobertura - Dividir por faixa de preço: adicione
&min_price=X&max_price=Ypara dividir o catálogo em janelas menores - Dividir por categoria: pesquise dentro de categorias específicas em vez de fazer uma busca ampla no site
Observe que itemStacks é um array. A Scrapfly fixa [0] no repositório dela, mas páginas de categoria e navegação às vezes contêm vários stacks ("Top picks", "More results"). O padrão robusto itera por todos os stacks:
1for stack in search_result.get("itemStacks", []):
2 for item in stack.get("items", []):
3 if item.get("__typename") == "Product":
4 # processar item
5 passTambém vale notar: o robots.txt do Walmart . Páginas de produto (/ip/...) e a maioria das páginas de categoria (/cp/...) não estão bloqueadas. Se se preocupa com conformidade, comece por páginas de produto e árvores de categoria em vez de busca.
Não deixe bloqueios silenciosos estragarem os seus dados: tratamento de erros pronto para produção
A maioria dos tutoriais desmorona aqui. Eles mostram como buscar uma página, analisar um produto e pronto. Em produção, está a buscar milhares de páginas, e o Walmart está ativamente a tentar impedir isso. A diferença entre um scraper de demonstração e um scraper que realmente funciona está em como lida com falhas.
Detete bloqueios silenciosos antes que corrompam os seus dados
A função mais importante num scraper do Walmart é o detetor de bloqueios. Com base no consenso dos fornecedores, entre , , e , precisa de quatro verificações independentes:
1BLOCK_MARKERS = (
2 "Robot or human",
3 "Press & Hold",
4 "Press & Hold",
5 "px-captcha",
6 "perimeterx",
7)
8def is_walmart_blocked(response) -> bool:
9 # 1. Redirecionamento para o endpoint dedicado de bloqueio
10 if "/blocked" in str(response.url):
11 return True
12 # 2. Códigos de estado duros
13 if response.status_code in (403, 412, 428, 429, 503):
14 return True
15 # 3. 200 OK com corpo de CAPTCHA (o caso de bloqueio silencioso)
16 body = response.text or ""
17 if any(m.lower() in body.lower() for m in BLOCK_MARKERS):
18 return True
19 # 4. Sinal de sanidade pelo tamanho da resposta — PDPs reais têm 300–900 KB
20 if len(response.content) < 50_000 and "/ip/" in str(response.url):
21 return True
22 return FalseEssa quarta verificação — tamanho da resposta — deteta os casos em que o Walmart devolve uma página reduzida que não contém marcadores óbvios de CAPTCHA, mas também não contém os dados do produto de que precisa.
Lógica de retry com backoff exponencial e jitter
Quando uma requisição falha, não quer bombardear o Walmart imediatamente. O padrão é usar backoff exponencial com jitter para dessincronizar as tentativas:
1import time
2import random
3import logging
4from curl_cffi import requests as cffi_requests
5log = logging.getLogger("walmart")
6def fetch_with_retry(session, url, max_retries=5, base_delay=2, max_delay=60):
7 for attempt in range(max_retries):
8 try:
9 response = session.get(url, headers=HEADERS, timeout=15)
10 if response.status_code in (429, 503):
11 raise Exception(f"Throttle: \{response.status_code\}")
12 if is_walmart_blocked(response):
13 raise Exception("Bloqueio silencioso detetado")
14 return response
15 except Exception as e:
16 if attempt == max_retries - 1:
17 raise
18 wait = min(max_delay, base_delay * (2 ** attempt)) + random.uniform(0, 3)
19 log.warning(f"Falha na tentativa {attempt + 1}: \{e\}. A tentar novamente em {wait:.1f}s")
20 time.sleep(wait)
21 return NoneO jitter (random.uniform(0, 3)) não é cosmético — ele dessincroniza os workers para que uma frota de scrapers não tente tudo no mesmo segundo e ative os detetores de velocidade do Akamai.
Limitação de taxa
Tanto a como a convergem para um atraso aleatório de 3 a 6 segundos por requisição no Walmart: "limite as suas requisições esperando de 3 a 6 segundos entre carregamentos de página e randomize os seus atrasos."
1import time
2import random
3def rate_limited_fetch(session, url):
4 response = fetch_with_retry(session, url)
5 time.sleep(random.uniform(3.0, 6.0))
6 return responseEm escala, considere usar aiolimiter para limitação assíncrona de taxa:
1from aiolimiter import AsyncLimiter
2limiter = AsyncLimiter(max_rate=10, time_period=60) # 10 requisições por minutoValidação dos dados
Mesmo quando a resposta não está bloqueada, os dados analisados podem estar errados (loja errada, payload degradado). Valide antes de gravar a saída:
1def validate_product(product):
2 """Retorna True se os dados do produto parecerem legítimos."""
3 if not product.get("name"):
4 return False
5 price = (product.get("priceInfo") or {}).get("currentPrice", {}).get("price")
6 if not isinstance(price, (int, float)) or price <= 0:
7 return False
8 if product.get("availabilityStatus") not in ("IN_STOCK", "OUT_OF_STOCK", "LIMITED_STOCK"):
9 return False
10 return TrueRegisto de sessão
Acompanhe a sua taxa de sucesso por sessão. Quando ela cair abaixo de 80% durante 10 minutos, algo mudou — o seu IP foi queimado, os cookies expiraram ou o Walmart implementou uma nova regra anti-bot.
1class ScrapeMetrics:
2 def __init__(self):
3 self.total = 0
4 self.success = 0
5 self.blocks = 0
6 self.errors = 0
7 def record(self, result):
8 self.total += 1
9 if result == "success":
10 self.success += 1
11 elif result == "blocked":
12 self.blocks += 1
13 else:
14 self.errors += 1
15 @property
16 def success_rate(self):
17 return (self.success / self.total * 100) if self.total > 0 else 0
18 def check_health(self):
19 if self.total > 20 and self.success_rate < 80:
20 log.critical(f"A taxa de sucesso caiu para {self.success_rate:.1f}% — considere rodar proxies ou pausar")Nada glamoroso. Mas é isso que mantém os seus dados limpos.
Python DIY vs. API de scraping vs. no-code: escolhendo a abordagem certa para fazer scraping do Walmart
Muitos programadores avançam logo para escrever um scraper personalizado sem perguntar se essa é mesmo a melhor decisão. . Utilizadores de fóruns descrevem-no como "basicamente 9/10" e perguntam "se uma API dedicada de web scraping não seria exagero". A resposta depende de volume, orçamento e capacidade de engenharia.
| Fator | Python DIY (requests + proxies) | API de scraping (Oxylabs, Bright Data etc.) | Ferramenta no-code (Thunderbit) |
|---|---|---|---|
| Tempo de configuração até à primeira linha | Horas | 15–60 min | ~2 min |
| Tempo de configuração até produção | 40–80 h | 4–16 h | ~30 min |
| Tratamento anti-bot | Você gere (difícil) | Gerido pelo fornecedor | Gerido automaticamente |
| Custo em pequena escala (<1K páginas/mês) | Baixo (proxies custam ~US$ 4–8/GB) | Tiers iniciais de US$ 40–49/mês | Gratuito–US$ 15/mês |
| Custo em escala (100K+ páginas/mês) | Menor por requisição | Maior por requisição | Varia |
| Personalização | Controlo total | Parâmetros da API | Limitada pela interface/campos |
| Manutenção contínua | 4–8 h/mês | Quase zero | Nenhuma (a IA adapta-se) |
| Melhor para | Programadores a criar pipelines personalizados | Scraping em produção de escala média | Utilizadores de negócios, extrações rápidas e pontuais |
Quando Python DIY faz sentido
O DIY ganha quando já tem um contrato de proxy, precisa de controlo rígido sobre headers, targeting por CEP ou grupos de vendedores, está a indexar milhões de páginas por mês onde taxas por registo de API se acumulam, ou precisa de garantias de on-premise ou compliance. O trade-off é tempo real de engenharia: um spider Scrapy pronto para produção com paginação, retries, rotação de proxy, impersonação de TLS e esquemas para múltiplos tipos de página leva , mais 4–8 horas por mês de manutenção à medida que o Walmart altera fingerprints.
Quando uma API de scraping poupa o seu tempo
As APIs de scraping tratam da camada anti-bot por si. mostram taxas de sucesso de e 98% para a Scrape.do no Walmart. O preço inicial fica na faixa de US$ 40–49/mês para ferramentas como , e . Se é uma equipa de 2 a 5 engenheiros e o volume de scraping é de 10 mil a 1 milhão de páginas por mês, uma API quase sempre é a escolha certa. Troca custo por requisição por manutenção zero.
Quando no-code é a escolha certa
serve um perfil diferente. Se é PM, analista ou operador de e-commerce e precisa dos dados de produtos do Walmart numa folha de cálculo ainda hoje — não no próximo sprint — uma ferramenta no-code é a resposta honesta.
O fluxo é simples: instale a , navegue até uma página de produto ou busca do Walmart, clique em "AI Suggest Fields" e a IA da Thunderbit lê a página e sugere colunas (nome do produto, preço, avaliação etc.). Clique em "Scrape" e os dados são preenchidos numa tabela. Exporte para Excel, Google Sheets, Airtable ou Notion — tudo gratuito, sem paywall.
A Thunderbit lida com anti-bot na nuvem, por isso não precisa de lidar com CAPTCHAs, proxies ou fingerprinting de TLS. A IA adapta-se automaticamente às mudanças de layout, então não há manutenção. Para utilizadores que não querem lidar com navegação por caminhos JSON, este é o caminho de menor resistência.
Limitações honestas: a Thunderbit não foi feita para 100 mil+ páginas por dia. Os créditos e limites na nuvem tornam a ingestão de alto volume menos económica do que APIs brutas. Também não consegue fixar um CEP específico ou ASN, a menos que a ferramenta suporte isso. Para pipelines contínuos e de alto volume, o DIY ou uma API de scraping continuam a ser o caminho.
Preço aproximado de cabeça: 1.000 linhas de produtos do Walmart na Thunderbit custam cerca de 2.000 créditos (~US$ 0,60–1,10 nos planos Starter/Pro). Isso é comparável à API do Walmart da Oxylabs e mais barato do que a maioria das APIs de scraping para hobby em baixo volume. para detalhes atualizados.
Exportando os dados do Walmart que extraiu
Depois de obter os dados, precisa de os colocar num sítio útil. Três formatos cobrem a maioria das necessidades:
CSV — o formato mais básico que analistas realmente abrem:
1import csv
2def export_csv(products, filename="walmart_products.csv"):
3 fieldnames = ["name", "price", "availability", "rating", "review_count", "seller", "url"]
4 with open(filename, "w", newline="", encoding="utf-8-sig") as f:
5 writer = csv.DictWriter(f, fieldnames=fieldnames, quoting=csv.QUOTE_MINIMAL)
6 writer.writeheader()
7 for p in products:
8 writer.writerow({k: p.get(k) for k in fieldnames})Use a codificação utf-8-sig para compatibilidade com Excel. O marcador BOM impede que o Excel deturpe caracteres especiais.
JSONL — o formato de produção para pipelines de scraping:
1import json
2import gzip
3def export_jsonl(products, filename="walmart_products.jsonl.gz"):
4 with gzip.open(filename, "at", encoding="utf-8") as f:
5 for p in products:
6 f.write(json.dumps(p, ensure_ascii=False) + "\n")(uma escrita interrompida perde só a última linha), pode ser transmitido em fluxo com memória constante e mantém dados aninhados como variantes e reviews intactos.
Excel — para entregas pontuais a analistas:
1from openpyxl import Workbook
2def export_excel(products, filename="walmart_products.xlsx"):
3 wb = Workbook(write_only=True)
4 ws = wb.create_sheet("Products")
5 ws.append(["Nome", "Preço", "Disponibilidade", "Avaliação", "Reviews", "Vendedor"])
6 for p in products:
7 ws.append([p.get("name"), p.get("price"), p.get("availability"),
8 p.get("rating"), p.get("review_count"), p.get("seller")])
9 wb.save(filename)A Thunderbit cobre a parte de exportação para utilizadores que não usam Python: exportação com um clique para Google Sheets, Airtable, Notion, Excel, CSV e JSON — tudo grátis no plano básico. Para monitorização contínua, o recurso de raspador agendado da Thunderbit pode executar extrações recorrentes automaticamente.
Uma ressalva sobre agendamento: . Os runners do GitHub Actions ficam em intervalos de IP da Azure que o anti-bot do Walmart bloqueia instantaneamente. Use APScheduler num VPS ou faça todo o tráfego passar por proxies residenciais.
Diretrizes legais e éticas para fazer scraping do Walmart
Utilizadores de fóruns expressam esta preocupação de forma clara: "Estou tranquilo em brincar ao gato e ao rato com programadores, mas cauteloso em mexer com o departamento jurídico deles."
Os Termos de Utilização do Walmart usar "qualquer robô, spider... ou outro dispositivo manual ou automático para recuperar, indexar, 'scrape', 'data mine' ou de outra forma recolher quaisquer Materiais" sem "consentimento prévio por escrito expresso".
O robots.txt do Walmart /search, /account, /api/ e dezenas de endpoints internos. Páginas de produto (/ip/...) e reviews (/reviews/product/) não estão bloqueadas.
O precedente hiQ v. LinkedIn (9.ª Vara, ) estabeleceu que fazer scraping de dados publicamente disponíveis dificilmente viola o CFAA federal. Mas o mesmo tribunal depois decidiu que e impôs um contra ela. Decisões mais recentes de 2024 (, ) restringiram ainda mais o CFAA e criaram defesas de preempção de copyright, mas esses julgamentos dependem de uma linguagem específica dos ToU que não se aplica de forma direta ao Walmart.
Diretrizes práticas: não sobrecarregue servidores. Respeite limites de taxa. Não faça scraping de dados pessoais ou de utilizadores. Use os dados com responsabilidade. Fazer scraping de páginas públicas de produtos do Walmart a uma taxa moderada para pesquisa pessoal é um perfil de risco muito diferente de fazer scraping em escala comercial contra os Termos do Walmart. Se está a criar um produto baseado em dados do Walmart, fale com um advogado e considere as .
Aviso: estas são informações educacionais, não aconselhamento jurídico.
Conclusão e principais conclusões
Fazer scraping do Walmart com Python é um desafio de por causa da sua dupla camada anti-bot Akamai + PerimeterX. Não é impossível — mas precisa das ferramentas e dos padrões certos.
Principais conclusões:
- A extração de JSON
__NEXT_DATA__é a escolha pragmática para a maioria dos casos. É o que todos os scrapers sérios de Walmart open source de 2024 a 2026 usam. O caminho base éprops.pageProps.initialData.data.productpara PDPs esearchResult.itemStackspara busca/navegação. curl_cfficomimpersonate="chrome124"é obrigatório.requestsouhttpxpuros não passam pelo fingerprinting de TLS do Akamai, independentemente dos headers.- Bloqueios silenciosos são o verdadeiro perigo. O Walmart devolve 200 OK com corpos de CAPTCHA. Verifique o conteúdo da resposta, não só os códigos de estado.
- Scrapers de produção precisam de mais do que código de caminho feliz. Backoff exponencial com jitter, deteção de bloqueio em quatro sinais, limitação de taxa de 3 a 6 segundos por requisição, validação de dados e monitorização da saúde da sessão são essenciais.
- A interceção da API interna via
/orchestra/*é poderosa, mas frágil. Use-a como um exercício no DevTools para necessidades específicas de dados, não como o seu método principal de extração. - O Walmart limita os resultados de busca a 25 páginas. Vá mais longe alternando a ordem de classificação e dividindo por faixa de preço.
- Escolha a sua abordagem com honestidade: Python DIY para programadores com necessidades personalizadas e alto volume. APIs de scraping para equipas de escala média sem um engenheiro de scraping. para utilizadores de negócios que querem os dados no Google Sheets ainda hoje.
Se quiser experimentar a rota no-code, a tem uma versão gratuita — pode extrair algumas páginas do Walmart e ver os resultados por si próprio. Se for seguir pelo Python, os padrões de código deste artigo foram testados em produção. De qualquer forma, agora tem um mapa das defesas do Walmart e três caminhos para as atravessar.
Para mais sobre técnicas de web scraping, veja os nossos guias sobre , e . Também pode assistir aos tutoriais no .
FAQs
É legal fazer scraping dos dados de produtos do Walmart?
Os Termos de Utilização do Walmart proíbem scraping automatizado sem consentimento por escrito. A decisão da 9.ª Vara em hiQ v. LinkedIn (2022) estabeleceu que o CFAA federal provavelmente não se aplica ao scraping de páginas públicas, mas o mesmo caso terminou com uma contra o scraper. Fazer scraping de páginas públicas de produtos a ritmos modestos para pesquisa pessoal envolve um perfil de risco muito diferente da extração em escala comercial. Consulte um advogado se estiver a construir um negócio com dados do Walmart.
Por que o meu scraper do Walmart continua a ser bloqueado?
As causas mais comuns são: usar requests ou httpx puros (que emitem um fingerprint de TLS específico de Python que o Akamai identifica de imediato), headers ausentes ou incorretos, ausência de rotação de proxy, taxa de requisição mais rápida do que 3 a 6 segundos por página e cookies de sessão ausentes (_px3, _abck, locDataV3). Mude para curl_cffi com impersonate="chrome124", use proxies residenciais e implemente os padrões de deteção de bloqueio e retry descritos neste artigo.
Que dados posso extrair do Walmart com Python?
Nomes de produtos, preços (atuais e de rollback), imagens, descrições curtas e longas, avaliações, quantidade de reviews, estado de disponibilidade em stock, nomes de vendedores, informações do fabricante, opções de variantes (tamanho, cor) e posicionamento na categoria. Usando o método __NEXT_DATA__, tudo isto está disponível como JSON estruturado. A interceção da API interna também pode devolver preços por variante, contagens de stock em tempo real e dados paginados de reviews.
Preciso de proxies para fazer scraping do Walmart?
Sim, para qualquer uso em produção ou repetido. — mesmo com headers perfeitos, um IP não residencial será sinalizado pelo sistema de reputação de IP do Akamai. Proxies residenciais ou móveis são necessários. IPs de datacenter são queimados quase imediatamente. Considere algo em torno de US$ 3 a US$ 17 por 1.000 páginas, dependendo do fornecedor e do plano de proxy.
Posso fazer scraping do Walmart sem escrever código?
Sim. A é uma extensão Chrome com IA que faz scraping do Walmart em dois cliques: "AI Suggest Fields" para detetar automaticamente as colunas de dados do produto e depois "Scrape" para extrair os dados. Ela lida com desafios anti-bot na nuvem e exporta diretamente para Excel, Google Sheets, Airtable ou Notion — tudo grátis. É mais indicada para analistas, PMs e utilizadores de negócios que precisam de dados rapidamente sem criar um pipeline personalizado. Para scraping de alto volume ou altamente personalizado, Python ou uma API de scraping continuam a ser a melhor opção.
Saiba mais