O Redfin atualiza depois que eles entram no ar. Esse nível de atualização vale ouro para quem está montando uma pipeline de dados imobiliários — e é justamente por isso que tanta gente tenta fazer scrapers no Redfin e acaba bloqueada em questão de minutos.
Passei anos trabalhando com ferramentas de extração de dados na e posso afirmar: a diferença entre "extrair dados do Redfin" e "extrair dados do Redfin sem ser bloqueado" é onde a maioria dos tutoriais desmorona. Eles mostram o código com BeautifulSoup, pulam a parte em que o Cloudflare derruba suas requisições, e deixam você encarando uma página 403 sem entender o que deu errado. Este guia é diferente. Vou te mostrar três caminhos reais — parsing de HTML, a API oculta do Redfin e uma alternativa sem código com a Thunderbit — além de dedicar atenção séria às proteções anti-bot que realmente importam. No fim, você vai saber exatamente qual método faz sentido para o seu nível técnico, sua escala e sua tolerância a dores de manutenção.
O que é o Redfin e por que seus dados importam?
O Redfin é uma imobiliária movida por tecnologia, com corretores assalariados que puxam anúncios diretamente dos feeds do MLS. Ele cobre e recebe quase 50 milhões de visitantes por mês. Diferente de portais que só agregam anúncios, os dados do Redfin são verificados por corretores, e o Redfin Estimate AVM proprietário cobre com erro mediano de apenas 1,96% para imóveis anunciados.
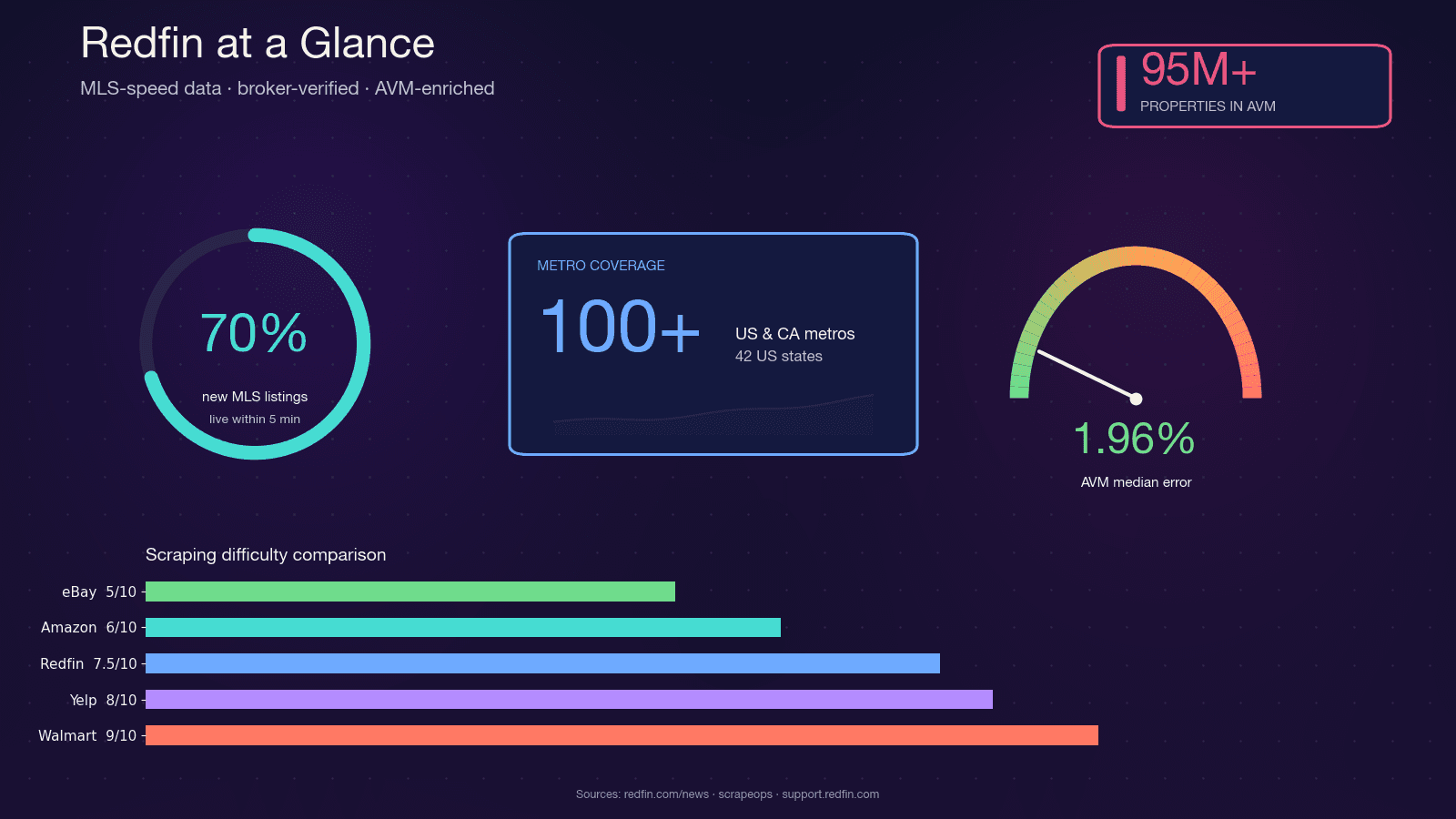
Essa combinação — atualização na velocidade do MLS, qualidade validada por corretores e um AVM preciso — explica por que investidores imobiliários, corretores, startups de proptech e analistas de dados querem acesso programático aos dados do Redfin. Python é a escolha natural para isso: o ecossistema de scraping (requests, BeautifulSoup, Selenium, Playwright) é maduro, a comunidade é enorme e ele se conecta facilmente com pandas e Jupyter para análise.
Por que extrair dados do Redfin com Python?
Os casos de uso variam tanto quanto as pessoas que precisam desses dados. Veja como diferentes perfis costumam usar os dados extraídos do Redfin:
| Perfil | Objetivo principal de scraping | Exemplo de uso |
|---|---|---|
| Corretores imobiliários | Geração de leads, inteligência de mercado | Novos anúncios e anúncios expirados na área de atuação; diretório de agentes para benchmarking competitivo |
| Investidores imobiliários | Originação de negócios, análise de cap rate | Triagem de rendimento de aluguel, identificação de imóveis subvalorizados, alertas diários de novos anúncios |
| Startups de proptech | Pipelines de dados para produto | Dados de treinamento para AVM, dashboards de mercado, motores de aquisição para iBuyer |
| Analistas de dados | Pesquisa de mercado, BI | Tendências de preço mediano por CEP, série histórica de dias no mercado, relação venda/preço de anúncio |
| Atacadistas / flippers | Monitoramento de imóveis problemáticos | Detecção de cortes de preço, foreclosures, comparáveis fora do mercado |
A tendência mais ampla confirma isso: já usam análise preditiva para identificar oportunidades e gerenciar riscos. O mercado de PropTech deve chegar a , com CAGR de 16,4%. Dados imobiliários estruturados já não são um diferencial — são o básico.
Todos os campos de dados do Redfin que você pode extrair (referência completa)
Antes de escrever uma única linha de código, você precisa saber o que realmente está disponível. Auditei as páginas de resultados de busca, as páginas de detalhe dos imóveis e os perfis de agentes do Redfin — e cruzei isso com wrappers open source da Stingray API, como os projetos e . O total chega a 117 campos distintos entre os tipos de página.
Guarde esta tabela nos favoritos. Saber o esquema dos dados antes de codar poupa horas de tentativa e erro caçando seletores.
Campos da página de resultados de busca
Estes são os campos leves disponíveis nos cards dos anúncios — muitas vezes dá para extrair sem renderizar o JavaScript completo:
| Campo | Tipo de dado | Observações |
|---|---|---|
| ID do imóvel | Número | Inteiro interno do Redfin, obtido de /home/{id} no href |
| Preço de anúncio | Número | |
| Endereço completo | Texto | |
| Quartos / Banheiros / Área | Número | Três valores em sequência |
| Tipo de imóvel | Seleção única | Casa, condomínio, townhouse, multifamiliar |
| Status | Texto | Ativo, pendente, contingente |
| Dias no mercado | Número | |
| Indicador de redução de preço | Número | Diferença em relação ao preço original |
| Foto principal | URL de imagem | Uma foto por card |
| Badge Hot Home | Booleano | |
| Data/hora do open house | Texto | |
| Atribuição da corretora | Texto |
Campos da página de detalhes do imóvel
A página de detalhes é onde está a maior riqueza de informação. Muitos desses campos exigem renderização em JavaScript ou a Stingray API:
| Campo | Tipo de dado | Observações |
|---|---|---|
| Redfin Estimate (imóvel anunciado) | Número | Via /stingray/api/home/details/avm |
| Redfin Estimate (fora do mercado) | Número | Via /stingray/api/home/details/owner-estimate; erro mediano de 7,52% |
| Ano de construção / reforma | Número | |
| Tamanho do lote | Número | |
| Taxa do HOA | Número | Mensal, quando aplicável |
| Imposto predial anual | Número | |
| Valor venal | Número | |
| Histórico de vendas | Tabela | Preço, data, tipo de evento |
| Descrição do imóvel | Texto | Parágrafo de marketing |
| URLs das fotos (carrossel) | URLs de imagem | 20+ por anúncio |
| Nome, telefone e e-mail do agente | Texto / Telefone / E-mail | O telefone costuma estar mascarado |
| Avaliações das escolas (fundamental / ensino médio / ensino superior) | Número | Além do nome do distrito |
| Walk / Transit / Bike Score | Número | |
| Pontuações de risco climático | Número | Inundação, incêndio, calor, vento |
| Imóveis similares ativos / vendidos / próximos | URLs | Dados do carrossel |
| Estacionamento, garagem, aquecimento, refrigeração | Texto | Grupos de comodidades |
Campos do perfil do agente
| Campo | Tipo de dado | Observações |
|---|---|---|
| Nome, foto, corretora e bio do agente | Texto / Imagem | |
| Telefone, formulário de contato | Telefone / Texto | Revelado ao clicar |
| Quantidade de anúncios ativos | Número | |
| Vendas nos últimos 12 meses / volume total | Número | |
| Média da relação anúncio-venda | Número | |
| Avaliação em estrelas / número de reviews | Número | |
| Anos de experiência / número de licença | Texto / Número |
Quando você usa o recurso AI Suggest Fields da Thunderbit em uma página do Redfin, ele detecta automaticamente a maioria dessas colunas e atribui os tipos corretos — sem precisar mapear seletores CSS manualmente. Já chego nisso.
As defesas anti-bot do Redfin, descomplicadas (não é só "use um proxy")
Aqui vale cravar a bandeira, porque a maioria dos tutoriais ignora o problema de bloqueio e pula direto para "compre proxies do nosso patrocinador". Isso não ajuda. Se você não entende o que o Redfin faz para detectar scrapers, vai torrar créditos de proxy e ainda assim ser bloqueado. e — "menos agressivo que o WAF corporativo do Zillow, confiando em limitação de taxa personalizada e desafios JavaScript."
O Redfin usa uma pilha em camadas: Cloudflare na borda (desafio JS, Turnstile, fingerprinting TLS/JA3) mais um limitador de taxa na camada de aplicação específico do Redfin. Não existe diretiva Crawl-delay no robots.txt, porque a aplicação das regras acontece no nível do WAF.
Por que requests + BeautifulSoup falha no Redfin
Se você fizer um requests.get() básico para uma página de imóvel do Redfin com headers padrão, normalmente acontece o seguinte:
- HTTP 403 — o desafio JS do Cloudflare não foi resolvido, então você recebe a página de challenge em vez do anúncio.
- Uma página intermediária de challenge — o corpo HTML contém o widget Turnstile do Cloudflare, não os dados do imóvel.
- HTTP 200 com HTML parcial — você recebe uma estrutura-base com um grande bloco JSON embutido em
root.__reactServerState.InitialContext, mas sem os cards de busca renderizados, sem histórico de preço e sem avaliações de escolas.
O Redfin usa seu próprio (não Next.js), e a chave de hidratação é específica do Redfin — root.__reactServerState.InitialContext, com os dados do anúncio aninhados em ReactServerAgent.cache.dataCache. Isso não é __NEXT_DATA__ nem window.__INITIAL_STATE__.
A causa mais comum de 403 silencioso? Faltam os headers Sec-Fetch-*. O Redfin/Cloudflare valida explicitamente Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest e Sec-Fetch-User. Se eles não estiverem presentes, você é sinalizado na hora.
O plano de mitigação: atrasos, headers, proxies e sessões
Aqui está a análise completa, defesa por defesa, com a mitigação específica para cada uma:
| Defesa do Redfin | O que ela faz | Sinal de detecção | Estratégia de mitigação |
|---|---|---|---|
| Desafio JS do Cloudflare | Intersticial que emite cookie cf_clearance | 403 + corpo HTML do Cloudflare | curl_cffi com impersonate="chrome120"; aquecer a sessão pela homepage; proxy residencial dos EUA |
| Cloudflare Turnstile | CAPTCHA interativo em sessões de alto risco | 403 + widget Turnstile | Navegador headless com stealth + proxy residencial |
| Erro 1020 do Cloudflare (banimento por ASN) | Bloqueia IPs/ASNs sinalizados no WAF | Corpo 403 "Error 1020 Access Denied" | Alternar para proxy residencial/móvel; nunca usar ASN de datacenter |
| Fingerprinting TLS/JA3 | Detecta pilhas TLS que não parecem navegador | 403 silencioso mesmo com headers perfeitos | Impersonação via curl_cffi ou navegador real |
| Fingerprinting HTTP/2 | Verifica SETTINGS do HTTP/2 e ordem do HPACK | Bloqueio silencioso | curl_cffi fala HTTP/2 como o Chrome |
| Validação de headers (UA, Sec-Fetch-*) | Conjunto de headers compatível com navegador | 403 na primeira requisição | Header set completo do Chrome, incluindo Sec-Fetch-Site/Mode/Dest/User, e Referer realista |
| Continuidade de cookie/sessão | Rastreia cf_clearance, RF_BROWSER_ID | Challenges em acessos diretos frios | Sessão persistente; aquecer na homepage primeiro |
| Rate limit da camada de aplicação | Limitador por IP | 429 | Delay de 2–5s com jitter; backoff exponencial |
| Reputação de IP de datacenter | Bloqueia ASNs de datacenter conhecidos | 1020/403 imediato | Apenas proxies residenciais ou móveis dos EUA |
| Detecção de concorrência | Várias requisições paralelas do mesmo IP | Escalada súbita para Turnstile | No máximo 2 conexões simultâneas por IP |
Limiares práticos observados pela comunidade:
- Cadência segura: 1 requisição a cada 2–3 segundos por IP
- Sustentar mais de 20–30 req/min em um único IP de datacenter aciona challenge em poucos minutos
- Soft rate limits desaparecem em 5–15 minutos se o tráfego parar
- Bloqueios em IPs de datacenter (AWS, GCP, Azure, OVH) podem durar horas ou dias
O requests padrão do Python (urllib3 + OpenSSL) produz uma — e acaba bloqueado silenciosamente mesmo com headers perfeitos. A solução mais usada no setor é curl_cffi com impersonate="chrome120", que conversa com TLS + HTTP/2 de forma fiel ao Chrome.
Três formas de extrair dados do Redfin com Python (e qual escolher)
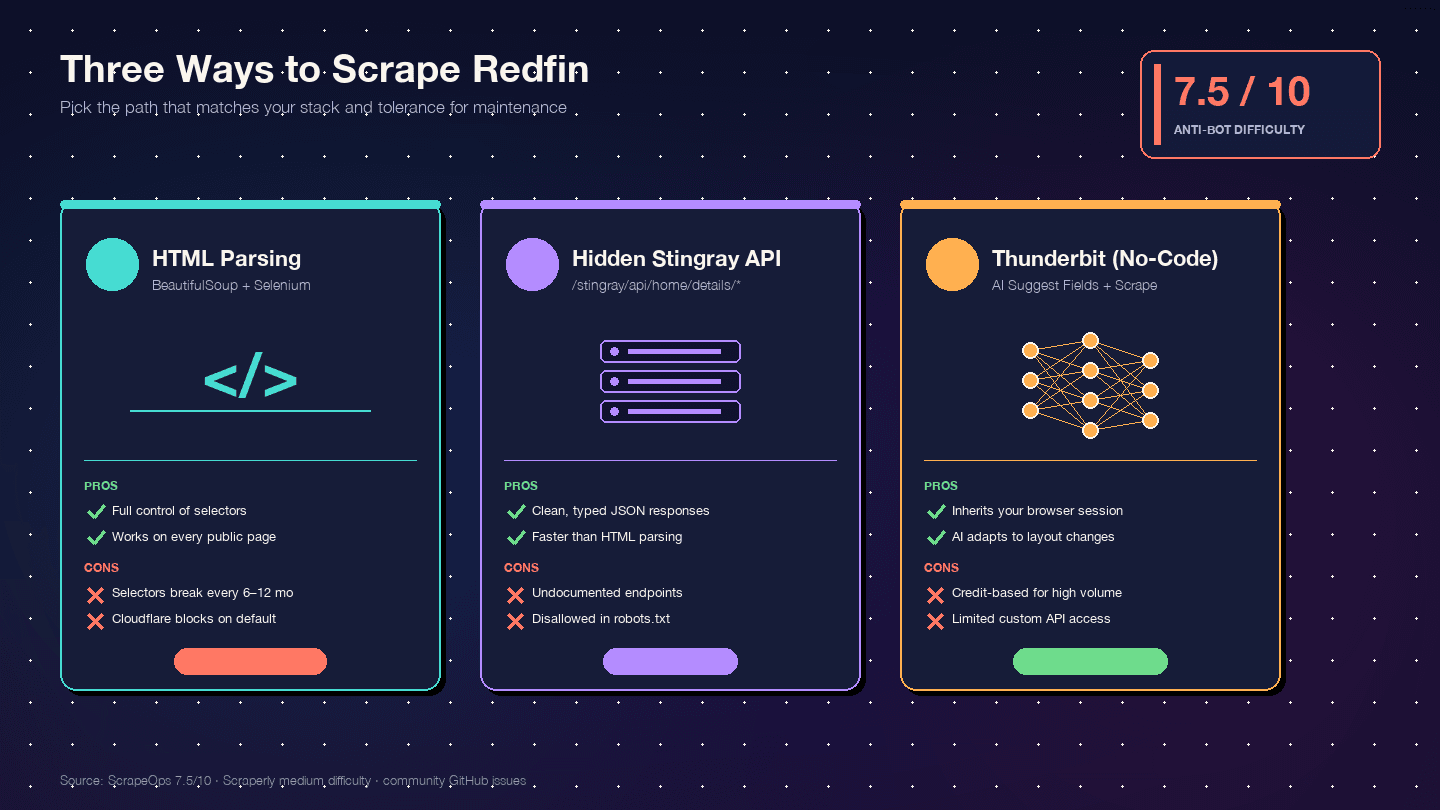
Não encontrei nenhum outro tutorial que compare os três caminhos lado a lado. Aqui vai a matriz de decisão:
| Critério | Parsing de HTML (BS4 + Selenium) | API oculta Stingray | Thunderbit (sem código) |
|---|---|---|---|
| Dificuldade de configuração | Média (ambiente Python + driver de navegador) | Alta (engenharia reversa de endpoints) | Baixa (instalação da extensão Chrome) |
| Risco de anti-bot | Alto (requisições ao DOM são as mais visíveis) | Médio (requisições com cara de API parecem mais limpas) | O mais baixo (usa sua sessão real no navegador) |
| Qualidade da estrutura de dados | Média (HTML não estruturado → parsing manual) | Excelente (JSON pré-estruturado) | Alta (IA detecta campos e tipos automaticamente) |
| Custo de manutenção | Alto — qualquer mudança de layout quebra seletores | Médio — endpoints podem mudar sem aviso | O mais baixo — a IA se adapta a mudanças de layout |
| Escala | Baixa a média (centenas com proxies) | Média a alta (milhares, requisições mais limpas) | Média (50 páginas por lote via cloud scraping) |
| Melhor para | Desenvolvedores que querem controle total | Desenvolvedores que precisam de JSON limpo | Não desenvolvedores, projetos rápidos, dados contínuos sem equipe técnica |
A questão da manutenção merece destaque. O Redfin já lançou duas gerações de DOM dos cards — a antiga (homecardV2Price) e a atual (span.bp-Homecard__Price--value). O histórico de issues no GitHub mostra quebra de seletores CSS aproximadamente a cada 6–12 meses. Quando isso acontece, um scraper com BeautifulSoup quebra do dia para a noite. Um detector de campos baseado em IA se adapta.
Antes de começar
- Dificuldade: Intermediário (Abordagens 1 e 2), Iniciante (Abordagem 3)
- Tempo necessário: ~30 minutos para a Abordagem 1 ou 2; ~5 minutos para a Abordagem 3
- O que você vai precisar:
- Python 3.8+ com pip (Abordagens 1 e 2)
- Navegador Chrome (todas as abordagens)
- (Abordagem 3)
- Proxies residenciais dos EUA para scraping em grande escala (Abordagens 1 e 2)
Abordagem 1: extrair dados do Redfin com Python usando parsing de HTML (BeautifulSoup + Selenium)
Este é o caminho do "controle total". Você escreve os seletores, gerencia o navegador e trata os erros.
É a abordagem mais didática. Também é a mais frágil.
Passo 1: configurar seu ambiente Python
Crie um ambiente virtual e instale as bibliotecas necessárias:
1python -m venv redfin-scraper
2source redfin-scraper/bin/activate # No Windows: redfin-scraper\Scripts\activate
3pip install requests beautifulsoup4 selenium webdriver-manager pandas curl_cfficurl_cffi é essencial aqui — é ele que permite que suas requisições HTTP imitem a assinatura TLS de um Chrome real, em vez da assinatura padrão do Python requests que o Cloudflare bloqueia de imediato.
Passo 2: configurar headers e sessão do navegador
É aqui que a maioria dos iniciantes erra. Você precisa do conjunto completo de headers do Chrome, incluindo os Sec-Fetch-* que o Redfin/Cloudflare valida explicitamente:
1from curl_cffi import requests as curl_requests
2HEADERS = {
3 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/120.0.0.0 Safari/537.36",
6 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Fetch-Site": "none",
10 "Sec-Fetch-Mode": "navigate",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-User": "?1",
13}
14session = curl_requests.Session(impersonate="chrome120")
15session.headers.update(HEADERS)
16# Aqueça a sessão — obtenha os cookies cf_clearance e RF_BROWSER_ID
17session.get("https://www.redfin.com/")A etapa de aquecer a sessão é crítica — acessar uma URL profunda diretamente (sem cookies anteriores e sem Referer) reduz a pontuação da sessão no Cloudflare.
Comece sempre pela homepage.
Passo 3: extrair os resultados de busca do Redfin
Com a sessão aquecida, você pode buscar uma página de resultados por cidade e fazer o parsing dos cards. Seletores da geração atual (2024–2026):
1import time
2import random
3from bs4 import BeautifulSoup
4base_url = "https://www.redfin.com/city/17151/CA/San-Francisco"
5listings = []
6for page_num in range(1, 6): # Páginas 1-5
7 url = f"{base_url}/page-{page_num}" if page_num > 1 else base_url
8 resp = session.get(url)
9 if resp.status_code != 200:
10 print(f"Bloqueado na página {page_num}: HTTP {resp.status_code}")
11 break
12 soup = BeautifulSoup(resp.text, "html.parser")
13 cards = soup.select("[data-rf-test-id='property-card'], a.bp-Homecard")
14 for card in cards:
15 price_el = card.select_one("span.bp-Homecard__Price--value")
16 addr_el = card.select_one("a.bp-Homecard__Address")
17 stats = card.select("span.bp-Homecard__LockedStat--value")
18 listing = {
19 "price": price_el.text.strip() if price_el else None,
20 "address": addr_el.text.strip() if addr_el else None,
21 "beds": stats[0].text.strip() if len(stats) > 0 else None,
22 "baths": stats[1].text.strip() if len(stats) > 1 else None,
23 "sqft": stats[2].text.strip() if len(stats) > 2 else None,
24 "url": "https://www.redfin.com" + addr_el["href"] if addr_el else None,
25 }
26 listings.append(listing)
27 # Atraso aleatório entre 2 e 5 segundos
28 time.sleep(random.uniform(2, 5))
29print(f"{len(listings)} anúncios extraídos")Você deverá ver uma lista crescente de dicionários, cada um contendo preço, endereço, quartos/banheiros/metragem e a URL de detalhe de um imóvel em San Francisco. Se você obtiver 0 cards, verifique o código HTTP — um 403 significa que o Cloudflare te pegou, e provavelmente você vai precisar de proxies residenciais.
Passo 4: extrair páginas individuais de detalhes dos imóveis
Os resultados de busca mostram o básico. As páginas de detalhe trazem Redfin Estimate, ano de construção, HOA, histórico de vendas, informações do agente e fotos. Essas páginas exigem renderização JavaScript, então use Selenium:
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service
3from webdriver_manager.chrome import ChromeDriverManager
4from selenium.webdriver.common.by import By
5import time
6options = webdriver.ChromeOptions()
7options.add_argument("--headless=new")
8options.add_argument("--disable-blink-features=AutomationControlled")
9options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
10 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
11driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
12for listing in listings[:10]: # Enriquecer os 10 primeiros
13 driver.get(listing["url"])
14 time.sleep(random.uniform(3, 6)) # Aguarda a renderização do JS
15 try:
16 estimate_el = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='avmLdpPrice']")
17 listing["redfin_estimate"] = estimate_el.text.strip()
18 except:
19 listing["redfin_estimate"] = None
20 try:
21 year_built = driver.find_element(By.XPATH, "//span[contains(text(),'Year Built')]/following-sibling::span")
22 listing["year_built"] = year_built.text.strip()
23 except:
24 listing["year_built"] = None
25driver.quit()Depois desta etapa, seus 10 primeiros anúncios devem estar enriquecidos com valores de Redfin Estimate e ano de construção. Os seletores XPath são mais resilientes que CSS para esses campos aninhados de comodidades, mas ainda são frágeis — qualquer mudança no DOM pode quebrá-los.
Passo 5: lidar com bloqueios e erros
Implemente retry com backoff exponencial:
1import time
2def fetch_with_retry(session, url, max_retries=3):
3 for attempt in range(max_retries):
4 resp = session.get(url)
5 if resp.status_code == 200:
6 return resp
7 elif resp.status_code in (403, 429, 503):
8 wait = (2 ** attempt) + random.uniform(1, 3)
9 print(f"Bloqueado ({resp.status_code}). Tentando novamente em {wait:.1f}s...")
10 time.sleep(wait)
11 else:
12 print(f"Status inesperado: {resp.status_code}")
13 break
14 return NoneSinais de bloqueio: HTTP 403 com HTML do Cloudflare no corpo, HTTP 429 (limite de taxa explícito), corpo vazio ou "Error 1020 Access Denied" no conteúdo da página. Se isso acontecer com frequência, é hora de adicionar proxies residenciais ou mudar para a abordagem da API.
Abordagem 2: extrair dados do Redfin com Python usando a API oculta Stingray
Esta é a minha abordagem favorita. O frontend do Redfin conversa com uma API JSON interna em /stingray/api/home/details/*, e as respostas vêm como JSON limpo e tipado — sem necessidade de parsing de HTML.
Como descobrir os endpoints da API oculta do Redfin
Abra o Chrome DevTools → aba Network → filtre por Fetch/XHR → navegue até qualquer página de imóvel do Redfin. Você verá requisições para endpoints como:
api/home/details/initialInfo— resolve URL → propertyId, listingIdapi/home/details/aboveTheFold— preço, quartos, banheiros, metragem, fotos, status, agente, número do MLSapi/home/details/belowTheFold— comodidades, HOA, impostos, estacionamento, ano de construção, lote, históricoapi/home/details/avm— Redfin Estimate para imóvel anunciadoapi/home/details/owner-estimate— Redfin Estimate fora do mercadoapi/home/details/descriptiveParagraph— descrição de marketing
Para páginas de aluguel, o rentalId (um UUID de 36 caracteres) é extraído da URL da tag <meta property="og:image">.
Extraindo dados do imóvel via Stingray API
Há uma particularidade importante: as respostas JSON da Stingray vêm prefixadas pela string literal {}&& como medida anti-CSRF. Você precisa remover isso antes de fazer o parse:
1import json
2from curl_cffi import requests as curl_requests
3session = curl_requests.Session(impersonate="chrome120")
4session.headers.update(HEADERS)
5# Aqueça a sessão
6session.get("https://www.redfin.com/")
7# Busque uma página do imóvel para obter cookies e property ID
8property_url = "https://www.redfin.com/CA/San-Francisco/123-Main-St-94102/home/12345678"
9page_resp = session.get(property_url)
10# Agora acesse a Stingray API
11api_url = "https://www.redfin.com/stingray/api/home/details/aboveTheFold?propertyId=12345678"
12api_resp = session.get(api_url, headers={"Referer": property_url})
13# Remova o prefixo anti-CSRF
14payload = json.loads(api_resp.text.replace("{}&&", "", 1))
15# Extraia os dados estruturados
16listing_data = payload.get("payload", {})
17print(json.dumps(listing_data, indent=2))A resposta inclui campos tipados: preço como inteiro, quartos/banheiros como números, URLs de fotos em arrays, informações do agente em objetos aninhados. Sem BeautifulSoup, sem seletores CSS, sem adivinhação.
Vantagens e limitações da abordagem com API oculta
Vantagens:
- JSON já estruturado — muito mais limpo que parsing de HTML
- Mais rápido por requisição (payload menor, sem overhead de renderização)
- Menor risco de bloqueio (requisições com cara de API e headers corretos parecem mais naturais)
Limitações:
- Os endpoints podem mudar sem aviso — não existe documentação oficial
- O
robots.txtbloqueia explicitamente/stingray/para o user-agent curinga - Exige engenharia reversa para descobrir novos endpoints
- Ainda precisa de sessão aquecida e headers corretos para evitar o Cloudflare
A alternativa sem código: extrair dados do Redfin com a Thunderbit
Se você precisa dos dados do Redfin e não quer manter scripts Python — ou simplesmente quer resultados em cinco minutos — comece por aqui. Criamos a exatamente para isso: extração estruturada de dados de qualquer site, sem código.
Passo 1: instale a Thunderbit e acesse o Redfin
Instale a na Chrome Web Store. Abra o Redfin e vá até uma página de resultados — por exemplo, casas à venda em San Francisco.
Passo 2: clique em "AI Suggest Fields"
Clique no ícone da Thunderbit na barra do navegador e depois em "AI Suggest Fields." A IA lê a página do Redfin e sugere automaticamente colunas como "Address", "Price", "Beds", "Baths", "SqFt", "Property Type" e "Listing Photo" — já com os tipos de dados corretos atribuídos.
Você pode remover as colunas que não quer ou adicionar campos personalizados clicando em "+ Add Column" e descrevendo, em inglês simples, o que precisa (por exemplo, "listing agent name" ou "days on market").
Você verá uma prévia da tabela com as colunas configuradas, pronta para ser preenchida.
Passo 3: clique em "Scrape" e veja os dados entrarem
Clique no botão "Scrape". A Thunderbit processa os anúncios visíveis e preenche sua tabela. Para resultados paginados, ela cuida da paginação automaticamente — sem precisar programar loops.
Nos meus testes, uma tabela com 50 linhas é preenchida em cerca de 45 segundos. Dados estruturados, prontos para exportação.
Como a Thunderbit lida com as proteções anti-bot do Redfin
Como a Thunderbit roda no seu próprio navegador, ela herda seus cookies, sua sessão e a impressão digital do navegador já existente no Redfin. Para o Cloudflare, parece um usuário normal navegando no Redfin — porque, tecnicamente, é isso mesmo. Não há navegador headless, não há IP de datacenter, nem fingerprint TLS incompatível. Em páginas públicas, o modo de cloud scraping da Thunderbit pode processar 50 páginas por vez.
Isso é bem diferente de disparar requests de um script Python em um servidor.
Sua sessão no navegador já é confiável.
Extrair subpáginas do Redfin com a Thunderbit
Depois de extrair os resultados de busca, clique em "Scrape Subpages" para que a IA visite cada URL de detalhe do imóvel e enriqueça sua tabela com campos adicionais — Redfin Estimate, ano de construção, taxa do HOA, dados do agente, fotos do imóvel e histórico de vendas.
É o equivalente ao loop de Selenium com 40 linhas da Abordagem 1 — só que com um clique e zero manutenção.
Quando o Redfin muda seu DOM de homecardV2Price para span.bp-Homecard__Price--value, a IA se adapta. Seus seletores em Python, não.
Além do CSV: exporte dados do Redfin para Google Sheets, Airtable e Notion
A maioria dos tutoriais para em df.to_csv(). Isso serve para uma análise pontual. Mas, se você faz parte de um time imobiliário, precisa de dados vivos e colaborativos — não de arquivos estáticos esquecidos na área de trabalho de alguém.
Exportando com Python (gspread + Airtable API)
Google Sheets via gspread:
1import gspread
2import pandas as pd
3from gspread_dataframe import set_with_dataframe
4df = pd.DataFrame(listings)
5gc = gspread.service_account(filename="service_account.json")
6sh = gc.open("Redfin Listings")
7ws = sh.worksheet("Sheet1")
8ws.clear()
9set_with_dataframe(ws, df, include_index=False, resize=True)
10# Renderize fotos dos imóveis inline via fórmula IMAGE()
11image_col = df.columns.get_loc("image_url") + 1
12for row_idx, url in enumerate(df["image_url"], start=2):
13 ws.update_cell(row_idx, image_col, f'=IMAGE("{url}")')Atenção: o Sheets tem um limite rígido de 10 milhões de células por planilha, e a API permite . Use ws.batch_update() em vez de loops célula por célula para qualquer volume acima de algumas dezenas de linhas.
Airtable via pyairtable:
Mudança crítica de 2024: o Airtable . Agora você precisa usar Personal Access Tokens (PATs) — qualquer tutorial que ainda mostre api_key=... já não funciona.
1from pyairtable import Api
2api = Api("patXXXXXXXXXXXXXX.yyyyyyyyyyyyyyyyyyyy")
3table = api.table("appBaseId123", "Redfin Listings")
4records = [
5 {
6 "Address": row["address"],
7 "Price": row["price"],
8 "Beds": row["beds"],
9 "Photo": [{"url": row["image_url"]}], # O Airtable busca e hospeda novamente
10 }
11 for row in listings
12]
13created = table.batch_create(records, typecast=True)O limite de taxa do Airtable é de , com bloqueio de 30 segundos em caso de violação. O campo de anexo aceita payloads do tipo [{"url": ...}] — os servidores do Airtable buscam a URL, hospedam novamente em sua CDN e geram miniaturas automaticamente.
Exportando com a Thunderbit (1 clique para Sheets, Airtable e Notion)
A Thunderbit oferece exportação nativa com 1 clique para Google Sheets, Airtable e Notion — e aqui vai a parte da qual eu realmente me orgulho: as fotos dos imóveis são enviadas e renderizadas como imagens inline no Notion e no Airtable. Sem gambiarra com =IMAGE(), sem links quebrados de CDN. Você clica em "Export to Airtable" e seu time recebe um banco visual de imóveis com miniaturas para navegar no celular.
Para times imobiliários que fazem triagem visual de anúncios, essa é a diferença entre uma ferramenta útil e uma pilha de linhas CSV.
É legal extrair dados do Redfin? O que dizem os termos, robots.txt e a jurisprudência
Não sou advogado, e isto não é aconselhamento jurídico. Mas, depois de anos na área de extração de dados, posso dizer: "é legal?" é a pergunta que todo mundo faz e que a maioria dos tutoriais evita.
O robots.txt do Redfin
O do Redfin é detalhado. Pontos principais:
- Bots totalmente bloqueados:
peer39_crawler/1.0,AmazonAdBot,FireCrawlAgent— o Redfin cita explicitamente o popular serviço de scraping da era LLM - Destaques de
DisallowparaUser-agent: *:/stingray/(todo o namespace interno da API),/myredfin/,/api/v1/rentals/,/api/v1/properties/,/owner-estimate/ - Nenhuma diretiva
Crawl-delay:para nenhum user agent - Mais de 50 sitemaps declarados — sitemaps são a forma mais limpa e leve para o WAF enumerar URLs
Os Termos de Uso do Redfin
A diz: "You may not automatedly crawl or query the Services for any purpose or by any means... unless you have received prior express written permission."
Isso é um acordo do tipo browsewrap — aceitação pelo uso contínuo, e não por clique explícito. Os tribunais dos EUA historicamente olham com ceticismo para a aplicação de browsewrap contra usuários que não tiveram aviso real (veja Nguyen v. Barnes & Noble, 9th Cir. 2014).
Jurisprudência relevante (resumo)
- Van Buren v. United States (Suprema Corte, 2021): a cláusula "exceeds authorized access" do CFAA usa um teste de "portal aberto ou fechado". Usar uma porta aberta para um fim indesejado não é hacking federal.
- hiQ Labs v. LinkedIn (9th Cir., 2022): extrair dados públicos disponíveis não viola o CFAA. Mas a hiQ acabou pagando US$ 500 mil em um acordo por quebra de contrato — porque a empresa havia criado contas no LinkedIn e clicado em "I agree."
- Meta Platforms v. Bright Data (N.D. Cal., jan. 2024): o tribunal deu julgamento sumário a favor da Bright Data — scraping de dados públicos quando deslogado não tornava a Bright Data um "usuário" vinculado aos termos da Meta.
- X Corp. v. Bright Data (N.D. Cal., maio de 2024): o juiz Alsup rejeitou as alegações da X, entendendo que claims de lei estadual tentando controlar a cópia de conteúdo público eram preempted pelo Copyright Act.
Orientações práticas
- Extraia apenas dados publicamente acessíveis — nunca crie uma conta e depois faça scraping (isso cria exposição contratual de clickwrap)
- Respeite os limites de taxa — volumes agressivos fortalecem alegações de trespass to chattels
- Não redistribua dados brutos ou fotos em escala — o processo (ajuizado em julho de 2025, com danos potenciais acima de US$ 1 bilhão) é um lembrete de que copyright de fotos é coisa séria
- A abordagem da Thunderbit, baseada no navegador — rodando na sua própria sessão autenticada — está mais próxima de "navegação manual em velocidade de máquina" do que de um bot headless em datacenter, o que é a postura mais defensável sem usar uma API licenciada
Dicas e erros comuns
Algumas lições difíceis que aprendi construindo ferramentas de extração e observando milhares de usuários raspando sites imobiliários:
- Sempre aqueça a sessão. Acesse
redfin.com/antes de qualquer URL profunda. Acesso direto em URL profunda é o gatilho número 1 para desafios do Cloudflare. - Gire os User-Agents de forma realista. Não use só um — alterne entre 5 a 10 UAs atuais de Chrome/Firefox. Mas não troque demais (um User-Agent diferente a cada requisição parece suspeito).
- Remova duplicatas pelo ID do imóvel. A paginação do Redfin às vezes se sobrepõe. Extraia o
/home/{id}de cada URL e deduplicate antes de enriquecer. - Evite horários de pico se puder. Na minha experiência, madrugada e início da manhã no horário dos EUA sofrem menos escrutínio do WAF.
- Se receber 429, recue com backoff exponencial. Não tente de novo imediatamente — é assim que um rate limit leve vira banimento rígido de IP.
- Para projetos grandes (1.000+ páginas), reserve orçamento para proxies residenciais. IPs de datacenter (AWS, GCP, Azure, OVH) são bloqueados pelo sistema de reputação de ASN do Cloudflare. Você vai cair em Error 1020 quase de imediato.
Como escolher a melhor forma de extrair dados do Redfin
Então, qual abordagem escolher? Depende de quem você é e do que precisa.
Parsing de HTML (BeautifulSoup + Selenium): ideal para desenvolvedores que querem controle total, se sentem confortáveis mantendo seletores CSS e não se importam em refazer tudo quando o Redfin mudar o DOM. Conte com revisitar o código a cada 6–12 meses.
API escondida Stingray: ideal para desenvolvedores que precisam de JSON limpo e estruturado e conseguem lidar com engenharia reversa de endpoints não documentados. Menos manutenção que parsing de HTML, mas os endpoints podem mudar sem aviso. Lembre-se de que /stingray/ é explicitamente proibido no robots.txt.
Thunderbit (sem código): ideal para não desenvolvedores, projetos rápidos e equipes que precisam de dados contínuos do Redfin sem depender de engenheiros. A IA se adapta a mudanças de layout, a extração de subpáginas enriquece os dados com um clique e a exportação para , Airtable ou Notion já vem embutida. Se você é um time imobiliário que precisa de uma base viva de imóveis — e não de um CSV descartável — esse é o caminho com menos atrito.
Independentemente do caminho: entenda as defesas anti-bot do Redfin antes de começar, saiba quais campos você precisa, escolha um formato de exportação que se encaixe no fluxo do seu time e mantenha-se do lado certo das .
Pronto para experimentar o caminho sem código? O permite testar o scraping do Redfin e ver resultados em minutos. Para as abordagens em Python, os trechos de código acima são um ponto de partida funcional — basta adicionar proxies e paciência.
Perguntas frequentes
O Redfin tem uma API pública?
Não. O Redfin não oferece uma API pública oficial. A API oculta Stingray (/stingray/api/home/details/*) retorna JSON estruturado e é usada pelo próprio frontend do Redfin, mas ela não é oficial, não tem documentação, pode mudar sem aviso e é explicitamente proibida no robots.txt do Redfin. Wrappers open source como no PyPI fornecem acesso em Python, mas devem ser usados com consciência dos riscos.
Posso extrair dados do Redfin sem Python?
Sim. é uma extensão Chrome com IA que herda a sessão do seu navegador para maior resistência a anti-bot — basta instalar, abrir o Redfin, clicar em "AI Suggest Fields" e exportar para Excel, Google Sheets, Airtable ou Notion. Também existem outras ferramentas sem código e fornecedores de datasets prontos no mercado, caso queira explorar alternativas.
Com que frequência o Redfin muda o layout do site?
O histórico de issues no GitHub da comunidade mostra quebra de seletores CSS a cada 6–12 meses, aproximadamente. O Redfin já lançou duas gerações de DOM dos cards — a antiga (homecardV2Price, homeAddressV2) e a atual (bp-Homecard__Price--value, bp-Homecard__Address). Scrapers maduros tentam ambos em sequência.
Ferramentas baseadas em IA como a Thunderbit porque detectam campos pelo conteúdo, e não pelos seletores CSS.
Qual é o melhor tipo de proxy para extrair dados do Redfin?
Proxies residenciais dos EUA para scraping em grande escala — benchmarks da comunidade colocam a taxa de sucesso em torno de 80%. Proxies de datacenter caem no Error 1020 do Cloudflare quase imediatamente; faixas de IP da AWS, GCP, Azure e OVH estão bloqueadas. Proxies móveis têm a maior taxa de sucesso, mas custam de 5 a 10 vezes mais.
Para scraping pessoal em pequena escala (<100 páginas), headers corretos + impersonação com curl_cffi + atrasos de 2 a 5 segundos podem funcionar sem proxies.
Posso extrair dados de imóveis vendidos ou fora do mercado no Redfin?
Sim. Dados de imóveis vendidos e o Redfin Estimate fora do mercado (erro mediano de ) estão disponíveis nas páginas de detalhe usando as mesmas abordagens de scraping. Os campos diferem dos anúncios ativos: páginas fora do mercado expõem preço de venda, data de venda, histórico do imóvel e o endpoint owner-estimate, mas não têm preço de anúncio atual, dias no mercado nem informações de open house. O endpoint da Stingray API para estimativas fora do mercado é api/home/details/owner-estimate, e não api/home/details/avm.
Saiba mais