

Em algum momento, lá pela quinquagésima vez que copiei e colei uma vaga do Indeed para uma planilha, comecei a questionar minhas escolhas de carreira. Se você já tentou extrair dados estruturados do Indeed de forma programática, conhece a piada: o erro 403 não é um bug — é um recurso do sistema de defesa do Indeed.
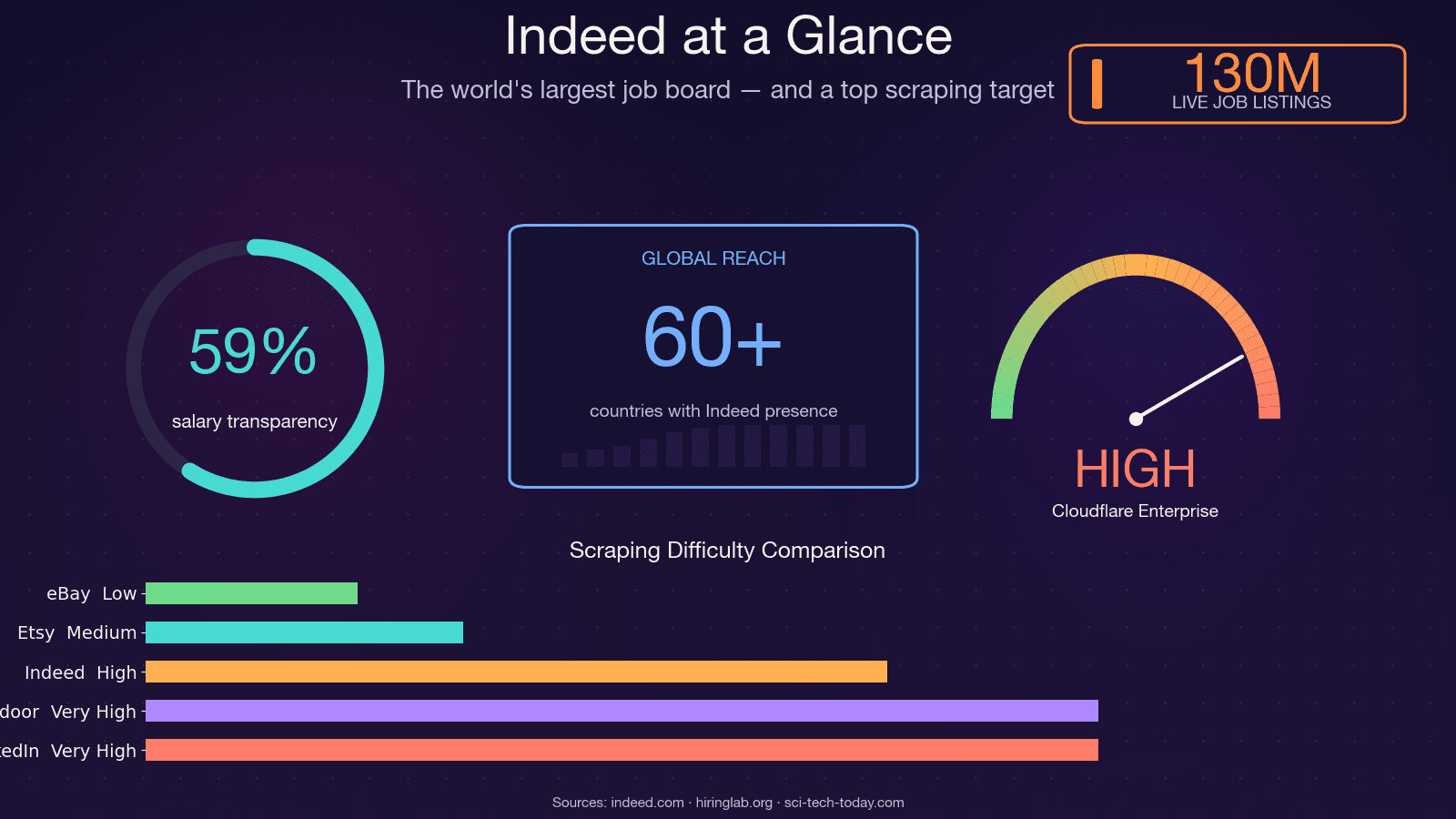
O Indeed é o maior site de vagas do mundo, com cerca de 350 milhões de visitantes únicos mensais, 130 milhões de vagas anunciadas a qualquer momento e operação em mais de 60 países. Isso o torna uma das fontes mais ricas de dados do mercado de trabalho no planeta — e uma das mais difíceis de fazer scrape. O scraper de código aberto JobFunnel (com milhares de estrelas no GitHub) foi literalmente arquivado pelo mantenedor em dezembro de 2025, depois de anos perdendo a guerra contra bots. Nas palavras do próprio mantenedor: "Todos os usuários conseguem fazer scrape de algumas vagas, mas rapidamente são atingidos por CAPTCHA, e a extração falha, não retornando vagas." Outro colaborador relatou ter recebido um CAPTCHA logo na primeira requisição. Então, sim — este não é um alvo trivial de scraping. Neste guia, vou mostrar todos os métodos práticos para fazer scrape do Indeed com Python, mostrar como realmente sobreviver ao bloqueio 403 e — para quem preferir pular toda a depuração — demonstrar uma alternativa sem código usando Thunderbit.
O que significa fazer scrape do Indeed com Python?
Web scraping, em essência, é a extração automática de dados estruturados de páginas da web. Quando falamos em fazer scrape do Indeed com Python, queremos dizer escrever um script que visita as páginas de resultados de busca e as páginas de detalhes das vagas do Indeed, lê o HTML subjacente (ou os dados incorporados) e extrai campos como título da vaga, empresa, localização, salário e descrição para um formato útil — CSV, banco de dados, Google Sheets.
As bibliotecas Python mais usadas para isso são Requests (para chamadas HTTP), BeautifulSoup (para análise de HTML) e Selenium ou Playwright (para automação de navegador). Mas o Indeed não é um site estático simples. Ele é um híbrido: HTML renderizado no servidor com um bloco JSON incorporado, protegido por Cloudflare Bot Management. Isso significa que o seu scraper precisa lidar com conteúdo renderizado por JavaScript, nomes de classes CSS que mudam e proteções agressivas contra bots — tudo isso antes de você analisar um único título de vaga.
Também não existe uma API oficial, gratuita e somente leitura do Indeed em 2026. A antiga Publisher Jobs API foi descontinuada por volta de 2020, e o que restou é apenas para empregadores (Job Sync, Sponsored Jobs). Então, fazer scraping ou pagar por um fornecedor terceirizado de dados são as únicas opções realistas.
Por que fazer scrape dos dados de vagas do Indeed?
O caso de negócio para fazer scrape do Indeed é simples: navegar manualmente por milhares de anúncios é impraticável, e os dados dentro dessas vagas têm valor real.
| Caso de uso | Quem se beneficia | Exemplo |
|---|---|---|
| Geração de leads | Equipes de vendas e recrutamento | Criar listas de empresas contratando com dados de contato |
| Pesquisa do mercado de trabalho | Analistas, equipes de RH | Identificar habilidades em alta e faixas salariais por região |
| Inteligência competitiva | Empregadores, agências de recrutamento | Monitorar padrões de contratação e ofertas salariais da concorrência |
| Automação pessoal de busca de emprego | Candidatos | Agrupar vagas que correspondam aos seus critérios em diferentes locais |
| Dados de treinamento para modelos de ML | Cientistas de dados | Criar modelos de previsão salarial a partir de histórico de vagas |
A própria pesquisa do Indeed Hiring Lab confirma que os dados de anúncios acompanham de perto os números do BLS JOLTS e podem servir como um indicador quase em tempo real das condições do mercado de trabalho nos EUA. Fundos de hedge usam a velocidade de publicação de vagas como um sinal de dados alternativos. Equipes de RH comparam remuneração usando faixas salariais coletadas por scraping. E recrutadores criam listas de prospecção a partir de empresas que estão contratando ativamente.
Uma observação prática: os dados salariais no Indeed estão melhorando, mas ainda são incompletos. Em meados de 2025, cerca de 59% das vagas nos EUA incluíam informações salariais, mas apenas cerca de 22% informavam um valor exato — o restante eram faixas. Toda análise salarial baseada em dados do Indeed precisa levar essa escassez em conta.
Como escolher o método para fazer scrape do Indeed com Python
Não existe uma única maneira "certa" de fazer scrape do Indeed. A melhor abordagem depende do seu nível de habilidade, da quantidade de dados de que você precisa e do quanto de manutenção você está disposto a aceitar. Testei os quatro principais métodos e aqui está a comparação:
| Critério | BS4 + Requests | Selenium | JSON oculto (window.mosaic) | Sem código (Thunderbit) |
|---|---|---|---|---|
| Dificuldade | Iniciante | Intermediário | Intermediário-avançado | Nenhuma (2 cliques) |
| Velocidade | Rápido | Lento (renderização no navegador) | Rápido | Rápido (scraping na nuvem) |
| Conteúdo renderizado por JS | Não | Sim | Sim (dados incorporados) | Sim |
| Resistência a anti-bot | Baixa | Média (detectável) | Média-alta | Alta (tratada automaticamente) |
| Manutenção quando o HTML muda | Alta (seletores quebram) | Alta | Média (estrutura JSON mais estável) | Nenhuma (IA se adapta) |
| Melhor para | Protótipos rápidos | Páginas dinâmicas, conteúdo com login | Dados estruturados em volume | Não desenvolvedores, resultados rápidos |
Este guia passa por cada método. Se você é desenvolvedor Python, vai querer ler as seções de BS4, JSON oculto e Selenium. Se você não programa (ou só está cansado de depurar erros 403), pule direto para a seção do Thunderbit.
Antes de começar
- Dificuldade: Iniciante a intermediário (seções em Python); nenhuma (seção Thunderbit)
- Tempo necessário: ~20–60 minutos para configurar Python e fazer o primeiro scrape; ~2 minutos com Thunderbit
- O que você vai precisar: Python 3.9+, um editor de código, navegador Chrome e (para o caminho sem código) a extensão Thunderbit para Chrome
Configurando seu ambiente Python para fazer scrape do Indeed
Antes de escrever qualquer código de scraping, deixe seu ambiente pronto.
Instale as bibliotecas necessárias
Crie um ambiente virtual e instale os pacotes de que você vai precisar:
python -m venv indeed_env
source indeed_env/bin/activate # No Windows: indeed_env\Scripts\activate
# Para a abordagem HTTP + parsing
pip install requests beautifulsoup4 lxml httpx
# Para a abordagem de JSON oculto (recomendada)
pip install curl_cffi parsel tenacity
# Para a abordagem de automação de navegador
pip install selenium
Algumas observações:
curl_cffié o padrão de 2026 para fazer scrape de sites protegidos por Cloudflare. Ele imita impressões TLS reais de navegador, algo querequestsehttpxpuros não conseguem fazer. Mais adiante explico por que isso importa na seção de anti-bot.- Selenium 4.6+ vem com o Selenium Manager, então você não precisa mais baixar manualmente o ChromeDriver — ele gerencia o binário do navegador automaticamente.
- Use
lxmlcomo backend de parsing do BeautifulSoup. Ele é cerca de 1,5x mais rápido do que ohtml.parserda biblioteca padrão.
Crie a estrutura do seu projeto
Mantenha simples:
indeed_scraper/
├── scraper.py
├── requirements.txt
└── output/
Todos os exemplos de código abaixo usam scraper.py como base.
Como fazer scrape do Indeed com Python usando BeautifulSoup
Esta é a abordagem para iniciantes: use requests para buscar a página e BeautifulSoup para analisar o HTML. É a mais rápida de configurar, mas também a mais frágil no Indeed.
Passo 1: monte a URL de busca do Indeed
As URLs de busca do Indeed seguem um padrão previsível:
https://www.indeed.com/jobs?q=<query>&l=<location>&start=<offset>
Por exemplo, buscando por "data analyst" em "Austin, TX" a partir da primeira página:
from urllib.parse import urlencode
params = {
"q": "data analyst",
"l": "Austin, TX",
"start": 0,
}
url = f"https://www.indeed.com/jobs?{urlencode(params)}"
print(url)
# https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX&start=0
O Indeed pagina em incrementos de 10, com limite máximo de 1.000 resultados (start <= 990). Qualquer offset acima de 990 retorna silenciosamente a mesma página.
Passo 2: envie uma requisição HTTP com os headers corretos
O Indeed bloqueia imediatamente requisições com strings padrão de user-agent do Python. Você precisa de headers realistas:
import requests
headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "https://www.indeed.com/",
}
response = requests.get(url, headers=headers, timeout=30)
print(response.status_code)
Se você receber 200, por enquanto está tudo certo. Se receber 403, o Cloudflare identificou você. (Mais adiante explico como sobreviver a isso.)
Passo 3: analise as vagas no HTML
Use BeautifulSoup para selecionar os elementos dos cards de vaga. Dê preferência aos atributos data-testid — eles são mais estáveis do que os nomes de classes CSS aleatórios do Indeed:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, "lxml")
cards = soup.find_all("div", attrs={"data-testid": "slider_item"})
jobs = []
for card in cards:
title_el = card.find("h2", class_="jobTitle")
title = title_el.get_text(strip=True) if title_el else None
company = card.find(attrs={"data-testid": "company-name"})
location = card.find(attrs={"data-testid": "text-location"})
link = title_el.find("a")["href"] if title_el and title_el.find("a") else None
jobs.append({
"title": title,
"company": company.get_text(strip=True) if company else None,
"location": location.get_text(strip=True) if location else None,
"url": f"https://www.indeed.com{link}" if link else None,
})
print(f"Encontradas {len(jobs)} vagas")
Passo 4: trate a paginação
Percorra as páginas incrementando o parâmetro start:
import time, random
all_jobs = []
for page in range(0, 50, 10): # Primeiras 5 páginas
params["start"] = page
url = f"https://www.indeed.com/jobs?{urlencode(params)}"
response = requests.get(url, headers=headers, timeout=30)
# ... analisar como acima ...
all_jobs.extend(jobs)
time.sleep(random.uniform(3, 6))
Limitações dessa abordagem
Vou ser direto: BS4 + Requests é o método mais fraco para o Indeed em 2026. O requests puro usa a biblioteca TLS da stdlib do Python, que produz uma impressão JA3 que o Cloudflare identifica imediatamente como "não é um navegador". Ele também não suporta HTTP/2, que é o protocolo servido pelo Indeed. É bem provável que você seja bloqueado depois de algumas páginas. E os seletores CSS? O Indeed troca nomes de classes como css-1m4cuuf e jobsearch-JobComponent-embeddedBody-1n0gh5s com frequência — então qualquer seletor que dependa deles é uma bomba-relógio.
Use este método para protótipos rápidos em uma única página. Para qualquer coisa em escala, use a abordagem de JSON oculto.
Como fazer scrape do Indeed com Python usando dados JSON ocultos
Este é o método que eu recomendo para a maioria dos desenvolvedores Python. Em vez de analisar elementos HTML frágeis, você extrai dados estruturados de uma variável JavaScript incorporada no código-fonte da página do Indeed: window.mosaic.providerData["mosaic-provider-jobcards"].
Cada campo de que você precisa — título da vaga, empresa, localização, salário, chave da vaga, data da publicação, indicador de remoto — já está nesse bloco JSON. Não é necessário executar JavaScript. O esquema está estável pelo menos desde 2023, o que o torna muito mais resiliente do que seletores DOM.
Passo 1: busque o HTML da página
Use curl_cffi em vez de requests — ele imita impressões TLS reais de navegador, o que é essencial para sobreviver ao Cloudflare:
from curl_cffi import requests as cffi_requests
response = cffi_requests.get(
"https://www.indeed.com/jobs?q=python+developer&l=Remote&start=0",
impersonate="chrome124",
headers={
"Accept-Language": "en-US,en;q=0.9",
"Referer": "https://www.indeed.com/",
},
timeout=30,
)
print(response.status_code, len(response.text))
Por que curl_cffi? Ele é uma binding Python sobre o curl-impersonate, que reproduz exatamente o ClientHello TLS, o frame HTTP/2 SETTINGS e a ordem dos headers de navegadores reais. É o único cliente HTTP Python ativamente mantido que derrota ao mesmo tempo JA3/JA4 e a impressão HTTP/2 da Akamai em uma única chamada. Os alvos de impersonação suportados incluem chrome120, chrome124, chrome131, variantes do Safari e do Edge.
Passo 2: extraia o JSON com uma expressão regular
O bloco JSON fica embutido em uma tag <script>. Extraia-o com regex:
import re, json
MOSAIC_RE = re.compile(
r'window\.mosaic\.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});',
re.DOTALL,
)
match = MOSAIC_RE.search(response.text)
if match:
data = json.loads(match.group(1))
results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
print(f"Encontradas {len(results)} vagas no JSON oculto")
else:
print("JSON oculto não encontrado — possível bloqueio ou mudança na página")
Passo 3: extraia os campos das vagas no JSON
Cada item em results contém mais dados do que o que aparece visualmente na página:
jobs = []
for job in results:
jobs.append({
"jobkey": job["jobkey"],
"title": job["title"],
"company": job.get("company"),
"location": job.get("formattedLocation"),
"remote": job.get("remoteLocation"),
"salary": (job.get("salarySnippet") or {}).get("text"),
"posted": job.get("formattedRelativeTime"),
"job_type": job.get("jobTypes"),
"easy_apply": job.get("indeedApplyEnabled"),
"url": f"https://www.indeed.com/viewjob?jk={job['jobkey']}",
})
O JSON frequentemente inclui estimativas salariais, atributos de taxonomia (tags de habilidades) e avaliações da empresa que nem sempre aparecem no HTML renderizado.
Passo 4: faça scrape de várias páginas
Use tierSummaries no JSON para entender a contagem total de resultados e depois faça o loop:
import time, random
all_jobs = []
for start in range(0, 50, 10): # Primeiras 5 páginas
url = f"https://www.indeed.com/jobs?q=python+developer&l=Remote&start={start}&sort=date"
response = cffi_requests.get(
url,
impersonate="chrome124",
headers={"Accept-Language": "en-US,en;q=0.9", "Referer": "https://www.indeed.com/"},
timeout=30,
)
match = MOSAIC_RE.search(response.text)
if match:
data = json.loads(match.group(1))
results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
all_jobs.extend([{
"jobkey": j["jobkey"],
"title": j["title"],
"company": j.get("company"),
"location": j.get("formattedLocation"),
"salary": (j.get("salarySnippet") or {}).get("text"),
"url": f"https://www.indeed.com/viewjob?jk={j['jobkey']}",
} for j in results])
time.sleep(random.uniform(3, 7))
print(f"Total: {len(all_jobs)} vagas extraídas")
Por que o JSON oculto é mais resiliente
A estrutura window.mosaic.providerData muda com menos frequência do que os nomes de classes CSS. Você obtém dados limpos e estruturados sem precisar analisar HTML bagunçado. Ainda assim, você continua precisando de mitigação anti-bot (headers, atrasos, proxies) — que cobriremos a seguir.
Como fazer scrape do Indeed com Python usando Selenium
Selenium é a abordagem de automação de navegador. É útil quando você precisa interagir com a página — clicar em painéis de detalhes da vaga, lidar com conteúdo protegido por login ou extrair descrições carregadas dinamicamente que não estão no HTML inicial.
Quando usar Selenium em vez de clientes HTTP
- O Indeed carrega parte do conteúdo dinamicamente (descrições completas no painel lateral direito)
- Você precisa fazer scrape de páginas que exigem estado de sessão ou login
- Você está fazendo scraping em pequena escala, em que velocidade não é crítica
Visão rápida
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
# options.add_argument("--headless=new") # Headless é mais detectável — use com cautela
driver = webdriver.Chrome(options=options)
driver.get("https://www.indeed.com/jobs?q=data+engineer&l=New+York")
time.sleep(3)
cards = driver.find_elements(By.CSS_SELECTOR, "[data-testid='slider_item']")
for card in cards:
try:
title = card.find_element(By.CSS_SELECTOR, "h2.jobTitle").text
company = card.find_element(By.CSS_SELECTOR, "[data-testid='company-name']").text
location = card.find_element(By.CSS_SELECTOR, "[data-testid='text-location']").text
print(f"{title} | {company} | {location}")
except Exception:
continue
driver.quit()
Limitações
Selenium é lento — cada página exige renderização completa no navegador. O Chrome em modo headless é detectável pelo sistema anti-bot do Indeed (o Cloudflare verifica navigator.webdriver, strings de fornecedor WebGL, contagem de plugins e muito mais). Até mesmo o undetected-chromedriver só adia a detecção; ele não a impede para sempre. E, assim como no BS4, seus seletores quebram quando o Indeed atualiza a interface.
Na maioria dos casos, a abordagem de JSON oculto entrega os mesmos dados mais rápido e com menos manutenção. Reserve o Selenium para casos extremos em que você realmente precise de um navegador.
Como evitar erros 403 ao fazer scrape do Indeed com Python
Esta é a seção mais importante. Se você chegou aqui depois de uma busca frustrante no Google, está no lugar certo.
Por que o Indeed bloqueia seu scraper
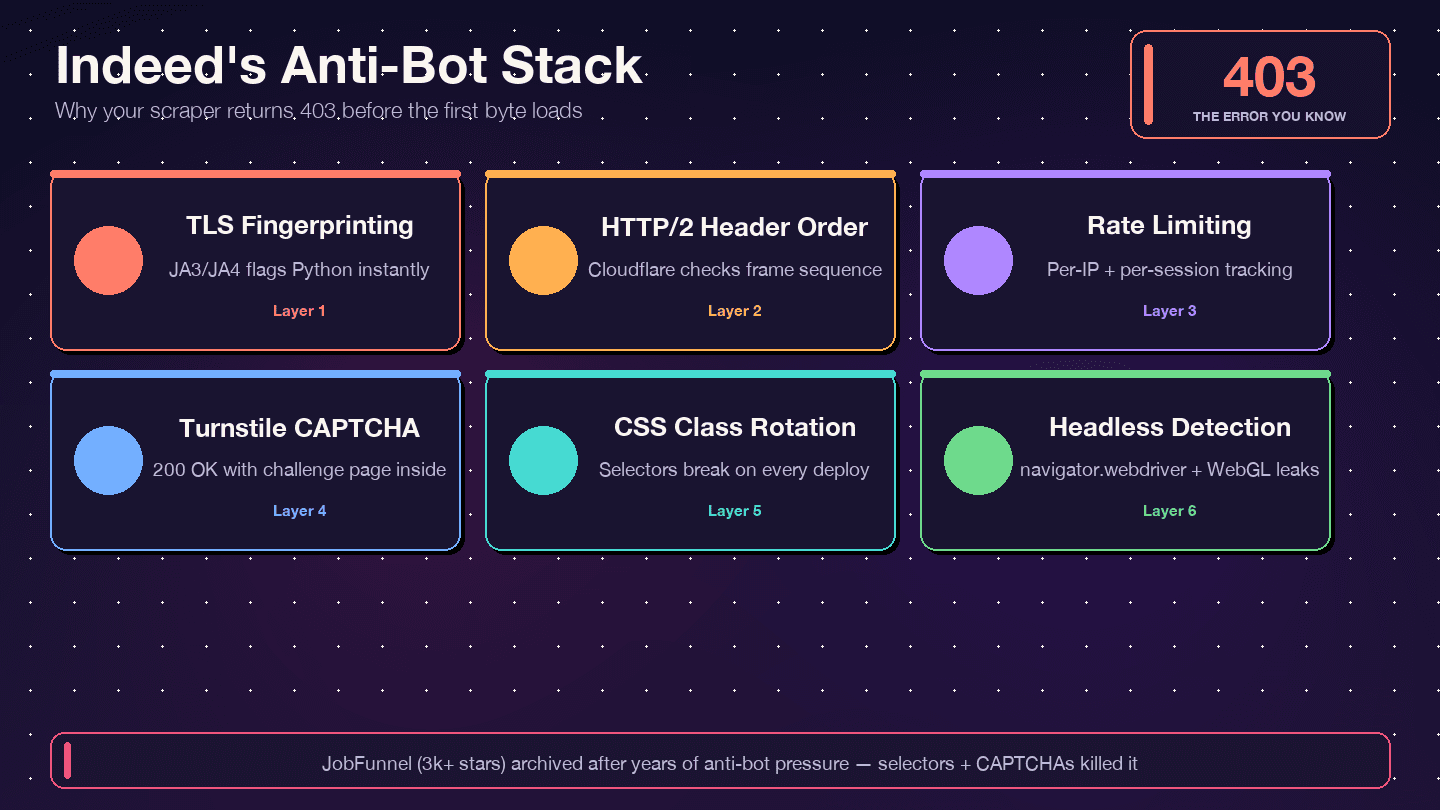
O Indeed usa Cloudflare Bot Management junto com Cloudflare Turnstile — não DataDome, não PerimeterX. Os headers da resposta confirmam isso: server: cloudflare, cf-ray e o cookie de bot management __cf_bm. O Cloudflare inspeciona sua impressão TLS (JA3/JA4), a ordem dos headers HTTP/2, padrões de requisição e sinais de comportamento de navegador. Se qualquer um desses elementos parecer não humano, você recebe 403, 429, 503 ou — o caso mais traiçoeiro — um 200 OK com uma página de desafio do Turnstile em vez dos dados reais da vaga.
Alterne o User-Agent e os headers da requisição
Um único User-Agent estático é o caminho mais rápido para ser bloqueado. Alterne entre uma lista de strings atuais e realistas. Importante: os campos de versão menor do Chrome estão travados em 0.0.0 desde a redução do User-Agent — não invente versões menores diferentes de zero, ou os anti-bots vão sinalizar.
import random
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.3800.97",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 "
"(KHTML, like Gecko) Version/17.4 Safari/605.1.15",
]
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Referer": "https://www.indeed.com/",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
}
Também garanta que seus Client Hints sec-ch-ua correspondam à versão do UA. Um sec-ch-ua: "Chrome";v="131" ao lado de um User-Agent dizendo Chrome 145 é um sinal de alerta imediato.
Adicione atrasos aleatórios entre as requisições
Intervalos fixos chamam atenção de sistemas de detecção de padrões. Use jitter aleatório:
import time, random
# Entre cada requisição
time.sleep(random.uniform(3, 6))
# Em caso de retry após bloqueio
def backoff_sleep(attempt):
base = 4
sleep_time = base * (2 ** attempt) + random.uniform(0, 2)
time.sleep(min(sleep_time, 60))
O consenso prático de ScrapeOps e WebScraping.AI é de 3–6 segundos entre requisições por IP, com um teto rígido de cerca de 100 requisições por IP por sessão antes de rotacionar.
Use rotação de proxies
Este é o fator mais importante para o sucesso. Proxies de datacenter de faixas AWS/GCP conseguem algo em torno de 5–15% de sucesso em alvos Cloudflare Enterprise — praticamente inúteis no Indeed. Proxies residenciais, combinados com o fingerprint TLS correto, sobem para 80–95% de sucesso.
PROXIES = [
"http://user:pass@us.residential.example:7777",
"http://user:pass@us.residential.example:7778",
"http://user:pass@us.residential.example:7779",
]
proxy = random.choice(PROXIES)
response = cffi_requests.get(
url,
impersonate="chrome124",
headers=headers,
proxies={"https": proxy},
timeout=30,
)
Em 2026, o preço de proxies residenciais fica em torno de $4–8,50 por GB, dependendo do fornecedor e do nível de compromisso. Para o Indeed especificamente, comece com um pool pequeno e aumente conforme necessário.
Trate com elegância os códigos 403, 429 e 503
Não tente simplesmente repetir de forma cega. Códigos diferentes significam coisas diferentes:
def fetch_with_retry(url, proxy_pool, max_retries=5):
for attempt in range(max_retries):
proxy = random.choice(proxy_pool)
headers["User-Agent"] = random.choice(USER_AGENTS)
try:
r = cffi_requests.get(
url,
impersonate=random.choice(["chrome124", "chrome120", "edge101"]),
headers=headers,
proxies={"https": proxy},
timeout=30,
)
# Verifique o caso traiçoeiro de "200 com desafio"
if r.status_code == 200 and "cf-turnstile" not in r.text and "Just a moment" not in r.text:
return r
if r.status_code == 403:
print(f"403 — bloqueado. Trocando proxy, tentativa {attempt + 1}")
elif r.status_code == 429:
print(f"429 — limite de taxa atingido. Reduzindo a velocidade.")
elif r.status_code == 503:
print(f"503 — servidor sobrecarregado ou desafio JS.")
backoff_sleep(attempt)
except Exception as e:
print(f"Erro na requisição: {e}")
backoff_sleep(attempt)
raise RuntimeError(f"Falha após {max_retries} tentativas: {url}")
O caso de 200 com desafio é o mais traiçoeiro. Sempre procure no corpo da resposta por cf-turnstile ou Just a moment antes de tratar um 200 como sucesso.
A alternativa mais fácil: deixe o Thunderbit cuidar do anti-bot para você
Para usuários que não querem montar e manter pools de proxies, rotação de headers e impersonação de fingerprint TLS, o scraping em nuvem do Thunderbit lida automaticamente com CAPTCHAs, rotação de proxies e proteções anti-bot. Sem configuração de proxy, sem curl_cffi, sem bibliotecas para resolver CAPTCHA. É o caminho de menor resistência quando você só precisa dos dados.
Por que seu scraper do Indeed continua quebrando (e como consertar)
A barreira 403 é a dor aguda. A dor crônica é a manutenção — scrapers que funcionam hoje quebram na semana seguinte, retornando silenciosamente dados vazios ou resultados desatualizados.
Como o Indeed quebra seus seletores
O Indeed alterna nomes de classes CSS de forma agressiva. O guia da Bright Data avisa explicitamente que classes como css-1m4cuuf e css-1rqpxry "parecem ser geradas aleatoriamente — provavelmente no momento da compilação." Testes A/B fazem com que sessões diferentes vejam layouts diferentes. E reestruturações de DOM acontecem sem aviso.
A história do JobFunnel é instrutiva. Um colaborador relatou: "CaptchaBuster conseguiu mitigar o captcha com sucesso, e o motivo de ainda não conseguir fazer scrape da página [é] o uso de seletores desatualizados do BeautifulSoup." O scraper não estava bloqueado — estava analisando os elementos errados.
Estratégia: prefira JSON oculto em vez de análise do DOM
O bloco window.mosaic.providerData está estável em termos de esquema desde pelo menos 2023. O caminho metaData.mosaicProviderJobCardsModel.results[] continua sendo o canônico em 2026. Seletores DOM quebram mensalmente. Extração de JSON quebra anualmente, se quebrar.
Estratégia: use atributos de dados em vez de nomes de classe
Quando precisar tocar no DOM, mire atributos funcionais:
| Seletor | Finalidade |
|---|---|
[data-testid="slider_item"] | Contêiner de cada card de vaga |
[data-testid="job-title"] ou h2.jobTitle > a | Link do título da vaga |
[data-testid="company-name"] | Nome do empregador |
[data-testid="text-location"] | Texto da localização |
data-jk="<jobkey>" em cada card | O gancho mais estável — inalterado desde 2019 |
Adicione verificações de asserção para detectar seletores obsoletos
Nunca deixe seu scraper rodar silenciosamente com zero resultados. Adicione uma verificação após cada busca:
results = parse_hidden_json(html)
assert len(results) > 0, (
f"O Indeed retornou um conjunto vazio em start={start} — "
"possível bloqueio, CAPTCHA ou mudança de seletor. "
f"Primeiros 500 caracteres da resposta: {html[:500]}"
)
Registre os primeiros 500–2000 caracteres da resposta bruta em caso de falha. Assim você consegue ver imediatamente se recebeu um desafio do Turnstile, uma tela de login ou uma mudança de esquema. Execute um teste de fumaça diário em CI com uma consulta fixa (por exemplo, q=python&l=remote) que valide a obtenção de resultados não nulos.
A alternativa com IA: scrapers que nunca quebram
A IA do Thunderbit lê a estrutura da página do zero a cada execução — ela não depende de seletores codificados nem de padrões regex. Quando o Indeed muda o HTML, o Thunderbit se adapta automaticamente. Isso resolve diretamente a carga de manutenção que os usuários em fóruns citam constantemente como sua maior frustração. Se você já acordou com uma mensagem no Slack dizendo "o scraper está devolvendo linhas vazias de novo", sabe o valor de não precisar consertar isso.
Faça scrape do Indeed sem escrever Python: a alternativa sem código
Todo guia concorrente presume que você vai escrever código Python. Mas os dados dos fóruns contam outra história. Os usuários dizem coisas como "é simplesmente muito difícil, com bugs e erros constantes" e alguns sugerem contratar alguém no Fiverr só para conseguir os dados. Se isso parece com você, esta seção é sua rota de fuga.
Como fazer scrape do Indeed com Thunderbit (passo a passo)
Passo 1: Instale a extensão Thunderbit para Chrome na Chrome Web Store. Você pode começar grátis.
Passo 2: Acesse uma página de resultados de busca do Indeed no navegador — por exemplo, https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX.
Passo 3: Clique no ícone do Thunderbit na barra de ferramentas do navegador e depois clique em "Sugerir Campos com IA." A IA do Thunderbit varre a página e detecta automaticamente colunas como Título da Vaga, Empresa, Localização, Salário, URL da Vaga e Data da Publicação. Você pode revisar e ajustar os campos sugeridos — remover colunas de que não precisa ou adicionar campos personalizados descrevendo o que quer em linguagem natural.
Passo 4: Clique em "Scrape." O Thunderbit extrai os dados da página e os exibe em uma tabela estruturada. Você verá linhas de vagas com os campos configurados.
Enriqueça com scraping de subpáginas
Depois de fazer scrape da página de listagem, clique em "Scrape Subpages" para que o Thunderbit visite cada página individual de detalhes da vaga. Ele extrai descrições completas, qualificações, benefícios e links de candidatura — sem configuração adicional. É o equivalente a escrever um segundo scraper em Python para visitar cada URL /viewjob?jk=<jobkey>, só que com um clique.
Trate a paginação automaticamente
O Thunderbit lida automaticamente com a paginação baseada em cliques do Indeed. Não é necessário construir manualmente URLs de offset nem escrever loops de paginação. Ele navega pelas páginas e agrega os resultados.
Exporte para suas ferramentas favoritas
Exporte os dados extraídos para CSV, Excel, Google Sheets, Airtable ou Notion — completamente grátis. Sem precisar escrever código com csv.writer() ou pandas.to_csv().
Quando usar Python vs. Thunderbit
| Cenário | Melhor ferramenta |
|---|---|
| Pipelines de dados personalizados, automação agendada via cron/Airflow | Python |
| Integração em uma base de código maior | Python |
| Lógica de parsing altamente personalizada | Python |
| Pesquisa pontual ou análise de mercado | Thunderbit |
| Membros da equipe sem perfil técnico precisam dos dados | Thunderbit |
| Obter os dados agora sem depurar erros 403 | Thunderbit |
| Enriquecimento de subpáginas sem configuração | Thunderbit |
Comparação de tempo: configuração em Python + depuração anti-bot = horas a dias (especialmente na primeira vez). Thunderbit = menos de 2 minutos para os mesmos dados. Não estou dizendo que Python está errado — estou dizendo que depende do que você precisa.
Fazer scraping do Indeed é legal? O que você precisa saber
Nenhum dos guias mais bem ranqueados sobre scraping do Indeed aborda a legalidade, o que é surpreendente dado o quanto a pergunta "scraping do Indeed é legal?" aparece em fóruns. Isto não é aconselhamento jurídico, mas aqui está o cenário.
Os termos de serviço do Indeed
Os Termos de Uso do Indeed (indeed.com/legal) não contêm uma cláusula geral de "proibição de scraping". A única proibição explícita de automação está na Seção A.3.5, que veda "o uso de qualquer automação, script ou bot para automatizar o processo Indeed Apply." Isso é algo bem específico do fluxo de candidatura, não da leitura passiva de vagas públicas. O principal mecanismo de aplicação do Indeed é técnico — desafios do Cloudflare, bloqueio de IP, fingerprint de dispositivo — e não judicial.
Precedentes jurídicos relevantes
O caso americano mais citado é hiQ Labs v. LinkedIn. O 9º Circuito entendeu em abril de 2022 que fazer scraping de dados publicamente acessíveis "provavelmente não viola o CFAA" (Computer Fraud and Abuse Act). No entanto, a hiQ acabou depois responsabilizada por violação contratual porque seus funcionários criaram perfis falsos no LinkedIn e aceitaram os Termos de Uso.
Mais recentemente, Meta v. Bright Data (N.D. Califórnia, jan. 2024) gerou uma decisão ainda mais clara. O juiz Chen entendeu que os Termos do Facebook e Instagram "não proíbem o scraping de dados públicos quando o usuário está desconectado". A Meta desistiu voluntariamente das demais alegações no mês seguinte.
robots.txt do Indeed
O robots.txt do Indeed desautoriza amplamente /jobs/ e /job/ para o User-agent: * padrão, mas permite explicitamente que Googlebot e Bingbot acessem /viewjob? — as páginas individuais de detalhes da vaga. Os crawlers de treinamento de IA (GPTBot, CCBot, anthropic-ai) são fortemente restringidos. robots.txt não é juridicamente vinculativo nos EUA, mas respeitá-lo é uma boa prática e uma evidência de boa-fé.
Diretrizes práticas para um scraping responsável
- Faça scrape apenas de dados publicamente disponíveis — nunca faça login, nunca crie contas falsas
- Respeite limites de taxa: 1 requisição a cada 3–6 segundos por IP, concorrência de um dígito
- Não republicar dados extraídos como se fosse seu próprio quadro de vagas
- Use os dados para pesquisa pessoal ou interna, não para revenda comercial sem permissão
- Descarte ou faça hash de PII de que você não precise; defina um limite de retenção para dados que tangenciam informações pessoais
- Se você operar em escala ou na UE/Reino Unido, consulte um advogado — as obrigações de transparência do Artigo 14 do GDPR se aplicam a dados pessoais extraídos
O espectro de risco: automação de busca de emprego pessoal fica na faixa mais baixa. Revenda comercial em larga escala dos dados do Indeed fica na faixa mais alta.
Conclusão e principais pontos
Fazer scrape do Indeed com Python é possível, mas não é um projeto de fim de semana que você configura e esquece. A proteção Cloudflare do Indeed, os seletores que mudam e as medidas agressivas anti-bot significam que você precisa abordar isso com as ferramentas certas e as expectativas certas.
O que eu destacaria de tudo isso:
- O Indeed é a fonte mais rica de dados do mercado de trabalho na web — 350 milhões de visitantes mensais, 130 milhões de vagas — mas reage com força contra scrapers.
- A extração de JSON oculto (
window.mosaic.providerData) é a abordagem Python mais resiliente. O esquema está estável há anos, enquanto seletores CSS quebram todo mês. curl_cfficom impersonação de navegador é o cliente HTTP padrão de 2026 para sites protegidos por Cloudflare.requestsehttpxpuros são bloqueados só pela impressão TLS.- Use sempre headers rotativos, atrasos aleatórios e proxies residenciais para evitar erros 403. Proxies de datacenter são quase inúteis contra o Cloudflare Enterprise.
- Adicione verificações de asserção para saber imediatamente quando os seletores quebram ou quando você está recebendo uma página de desafio em vez dos dados da vaga.
- Para usuários não técnicos ou para quem só quer resultado rápido, Thunderbit oferece um caminho sem código e com IA que se adapta automaticamente às mudanças do site — sem proxies, sem depuração, sem manutenção.
Se quiser experimentar o caminho sem código, o Thunderbit oferece um plano gratuito para você testar no Indeed sem compromisso. E, se for seguir pela rota Python, os exemplos de código acima são um ótimo ponto de partida — só lembre que a resistência anti-bot precisa ser tratada como preocupação de primeira classe, não como detalhe secundário.
Para saber mais sobre abordagens e ferramentas de web scraping, confira nossos guias sobre como fazer web scrape com Python, as melhores ferramentas automatizadas de web scraping e web scraping sem ser bloqueado. Você também pode assistir a tutoriais no canal do Thunderbit no YouTube.
Experimente o Thunderbit para Extrair Dados do Indeed Mais Rápido Get Started Free
Perguntas frequentes
Quais bibliotecas Python são melhores para fazer scrape do Indeed?
Para requisições HTTP, curl_cffi é a melhor escolha em 2026 — ele imita impressões TLS reais de navegador, o que é essencial para contornar o Cloudflare. httpx com HTTP/2 é uma alternativa razoável para alvos menos protegidos. Para parsing de HTML, BeautifulSoup4 com lxml continua sendo o padrão. Para automação de navegador, Playwright (com playwright-stealth) ou undetected-chromedriver funcionam, embora ambos estejam cada vez mais detectáveis. A abordagem de regex para JSON oculto (window.mosaic.providerData) evita a necessidade de parsing pesado por completo.
Por que continuo recebendo erros 403 ao fazer scrape do Indeed?
O Indeed usa Cloudflare Bot Management, que inspeciona sua impressão TLS (JA3/JA4), a ordem dos headers HTTP/2, padrões de requisição e comportamento do navegador. Se você estiver usando requests puro, sua impressão TLS já identifica você como um script Python — o 403 vem antes mesmo de os headers serem lidos. Corrija isso migrando para curl_cffi com impersonação de navegador, rotacionando strings realistas de User-Agent, adicionando atrasos aleatórios (3–6 segundos) e usando proxies residenciais. Verifique também o caso de "200 com desafio do Turnstile" — procure marcadores cf-turnstile no corpo da resposta.
Posso fazer scrape do Indeed sem programar?
Sim. Ferramentas como Thunderbit permitem extrair vagas do Indeed em poucos cliques — instale a extensão do Chrome, acesse uma página de busca do Indeed, clique em "Sugerir Campos com IA" e depois em "Scrape." A IA do Thunderbit detecta automaticamente campos como título da vaga, empresa, localização e salário. Ele trata paginação, enriquecimento de subpáginas (descrições completas) e proteções anti-bot automaticamente. Exporte para CSV, Google Sheets, Airtable ou Notion gratuitamente.
Com que frequência o Indeed muda a estrutura HTML?
O Indeed troca regularmente nomes de classes CSS (por exemplo, css-1m4cuuf, strings aleatórias com hash) e reestrutura elementos DOM sem aviso. Testes A/B fazem com que diferentes usuários vejam layouts diferentes ao mesmo tempo. A abordagem de JSON oculto (window.mosaic.providerData) é significativamente mais estável — o esquema permanece consistente desde pelo menos 2023. Quando for necessário usar seletores DOM, prefira atributos data-testid e data-jk (chave da vaga) em vez de classes CSS.
É legal fazer scrape do Indeed?
O scraping de URLs públicas do Indeed quando o usuário está desconectado provavelmente não gera responsabilidade sob o CFAA nos EUA, com base na decisão do 9º Circuito em hiQ v. LinkedIn (2022) e na decisão Meta v. Bright Data (2024). Os Termos de Uso do Indeed proíbem especificamente automatizar o processo de candidatura, não a leitura passiva de vagas públicas. Ainda assim, faça scraping com responsabilidade: não faça login, não crie contas falsas, respeite limites de taxa, não republicue os dados como se fossem seu próprio quadro de vagas e trate com cuidado quaisquer dados pessoais (nomes de recrutadores, e-mails) sob GDPR/CCPA. Para operações em escala comercial, consulte um advogado.
Saiba mais
- Como Fazer Web Scraping Sem Ser Bloqueado em Python
- Web Scraping em Python: Evite Bloqueios com o Uso Inteligente de Proxies
- Como Escrever um Web Scraper com Python: Do Início ao Fim
- Como Extrair Dados de um Site Usando Python com Eficiência
- Como Extrair Dados com Python: Um Tutorial para Iniciantes




