O Google encerrou a API do Flights lá em 2018, mas os preços das passagens continuam mexendo sem parar — numa única rota doméstica. Se você quer acesso programático a esses dados, a extração de dados é praticamente o único caminho.
Passei um bom tempo testando formas diferentes de coletar dados de voos no Google, e o cenário mudou bastante — principalmente depois que o Google lançou o SearchGuard em janeiro de 2025. Neste guia, vou te mostrar como montar um extrator em Python funcional para o Google Flights usando Playwright, explicar como driblar as barreiras anti-bot que travam a maioria das pessoas e, depois, transformar tudo isso em um rastreador automático de preços com alertas. Se você preferir pular o código, também vou mostrar uma alternativa sem programação usando que entrega o mesmo resultado em cerca de dois minutos.
Por que usar Python para extrair dados do Google Flights?
O Google Flights domina as buscas por voos. A visibilidade móvel nos EUA , ultrapassando todas as principais OTAs. O mercado de metabusca de viagens por trás disso foi avaliado em , com crescimento anual composto de 30,2%. Mesmo assim, desde que a API QPX Express foi , não existe um jeito oficial de acessar esses dados programaticamente.
Ao mesmo tempo, os preços dos voos oscilam para o mesmo itinerário, com uma diferença média de cerca de US$ 20 entre a tarifa mais baixa e a mais alta. Companhias como a Delta usam 77 faixas tarifárias para precificação dinâmica. A passagem média de ida e volta nos EUA no início de 2026 ficou em US$ 408, com as tarifas .
Plataforma dominante, sem API e com preços voláteis. É por isso que extrair dados do Google Flights com Python virou um dos projetos mais populares no GitHub e em fóruns de viagem.
Veja quem se beneficia e de que forma:
| Tipo de usuário | Caso de uso | Principal benefício |
|---|---|---|
| Viajantes individuais | Acompanhar preços de rotas específicas ao longo do tempo | Economizar em média US$ 50 por voo |
| Agências de viagem | Inteligência competitiva de preços | Monitoramento em tempo real da paridade tarifária |
| Equipes de viagens corporativas | Otimização de custos entre rotas | Economia de 10% a 30% em viagens corporativas |
| Desenvolvedores | Criar apps de comparação de tarifas | Acesso programático aos dados de preço |
| Pesquisadores | Análise da volatilidade de preços das companhias aéreas | Pesquisa acadêmica e de mercado |
Usuários em fóruns são diretos sobre o motivo de terem recorrido à extração: "O Google Flights API foi descontinuado e eu deveria usar web scraping" é um sentimento que aparece o tempo todo. E o retorno compensa — ao analisar mais de 5 bilhões de cotações por dia, enquanto os dados de 2026 da Expedia mostram que reservar com 8 a 15 dias de antecedência economiza cerca de .
Que dados você pode extrair do Google Flights?
A página de resultados do Google Flights traz um conjunto de dados surpreendentemente rico. Normalmente, é possível obter:
- Nome da companhia aérea (e logotipo)
- Horário de partida e código do aeroporto
- Horário de chegada e código do aeroporto
- Duração total do voo
- Número de escalas e detalhes das conexões (aeroporto, duração, se é pernoite)
- Preço da passagem (específico por moeda)
- Emissões de CO2 (kg CO2e, com diferença percentual em relação a voos típicos)
- Classe da viagem, número do voo, modelo da aeronave
- Especificação de espaço para as pernas
- Recursos adicionais (Wi‑Fi, tomadas, streaming de mídia)
- Indicador de nível de preço (baixo/normal/alto)
- Avisos de atraso ("Frequentemente atrasado em mais de 30 min")
A disponibilidade dos dados varia conforme a rota, a data e o tipo de passagem (só ida ou ida e volta). Veja como fica um único registro de voo extraído em JSON:
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}Configurando seu ambiente Python
Antes de escrever qualquer código de extração, você vai precisar de alguns itens básicos.
Pré-requisitos:
- Nível de dificuldade: Intermediário
- Tempo necessário: cerca de 1 a 2 horas para seguir o tutorial completo
- O que você vai precisar: Python 3.7+, conhecimentos básicos de Python e um navegador baseado em Chrome
Instale as bibliotecas necessárias
Vamos usar Playwright para automação de navegador (o Google Flights é 100% renderizado em JavaScript — requisições HTTP estáticas não retornam nada útil), além de alguns auxiliares:
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — automação de navegador headless, lida com renderização em JavaScript e mecanismos nativos de espera
- playwright-stealth — reduz sinais comuns de detecção de bots
- pandas — para análise de dados e exportação para CSV depois
Por que Playwright em vez de Selenium ou requests
O Google Flights não funciona só com requests + BeautifulSoup — o conteúdo da página é renderizado totalmente por JavaScript. Você precisa de um navegador de verdade.
| Recurso | Playwright | Selenium | requests + BS4 |
|---|---|---|---|
| Renderização de JS | Suporte total | Suporte total | Nenhum |
| Velocidade | 42% mais rápido no geral | Base | N/A para este caso |
| Suporte assíncrono | Nativo | Apenas sequencial | N/A |
| Uso de memória | 30% menor | Maior | Mínimo |
| Bypass de detecção de bot | Bom (com stealth) | Mais fácil de detectar | N/A |
O Playwright é mais rápido, mais moderno e tem suporte melhor para async. Para o Google Flights, é a escolha mais clara.
Passo a passo: como extrair dados do Google Flights com Python
Esta é a parte central do tutorial. Vamos construir o extrator passo a passo.
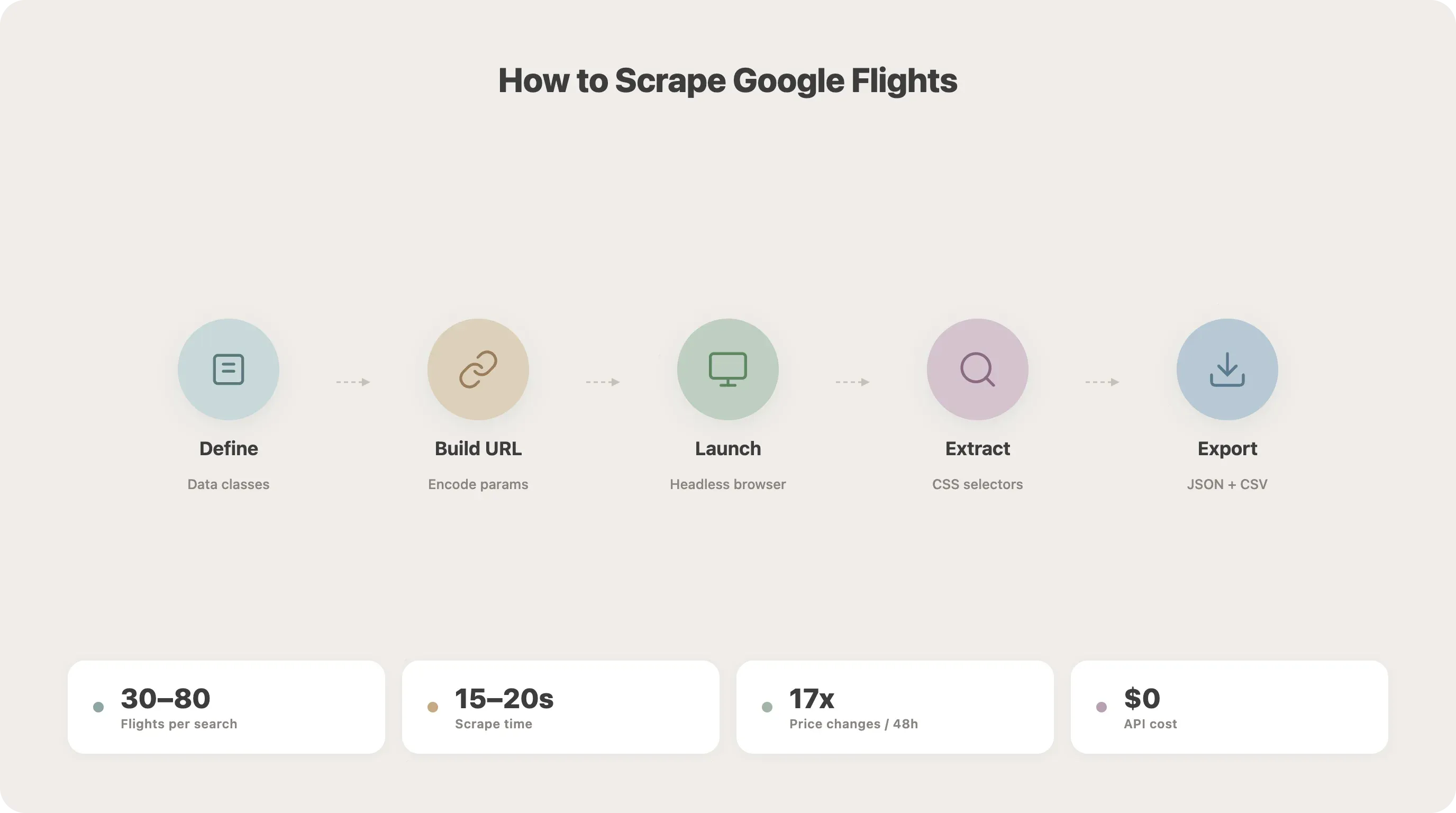
Passo 1: Defina suas classes de dados
Comece estruturando seus parâmetros de busca e os dados do voo com dataclasses do Python. Isso mantém o código organizado e facilita futuras expansões.
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # ex.: "SFO"
6 destination: str # ex.: "JFK"
7 departure_date: str # ex.: "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" ou "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""Cada campo corresponde diretamente ao que vamos extrair da página. Ter essa estrutura desde o começo evita ter que lidar com dicionários bagunçados depois.
Passo 2: Entenda a estrutura da URL do Google Flights
O Google Flights codifica os parâmetros de busca usando Protobuf em Base64 no parâmetro de URL tfs. Você pode tentar reverter essa codificação ou seguir um caminho mais simples: montar uma URL em linguagem natural.
O método mais simples usa este formato de busca:
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USDSe quiser mais controle, você pode gerar URLs programaticamente:
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"A alternativa — reverter a codificação Protobuf — dá mais precisão, mas quebra quando o Google altera o formato interno. Bibliotecas como no GitHub usam decodificação Protobuf para evitar a análise de HTML por completo, mas essa é uma abordagem mais avançada.
Passo 3: Inicie o navegador e acesse o Google Flights
Aqui está a configuração com Playwright. Vamos usar playwright-stealth para reduzir o risco de detecção desde o início.
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # Pré-defina o cookie de consentimento para pular o pop-up
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()Estamos rodando em modo headless para produção (mude para headless=False ao depurar), definindo uma viewport e um user agent realistas e pré-configurando o cookie SOCS para pular o pop-up de consentimento — mais detalhes na seção anti-bot.
Passo 4: Vá para os resultados da busca
Carregue a URL construída e espere os resultados dos voos aparecerem:
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # Aguarde o carregamento dos resultados
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )Se ocorrer timeout aqui, normalmente significa que o pop-up de consentimento bloqueou a página (veja a correção com cookie no Passo 3) ou que o Google está exibindo um CAPTCHA. Vamos cobrir os dois cenários na seção anti-bot.
Passo 5: Carregue todos os resultados de voo
O Google Flights oculta resultados extras atrás do botão "Mostrar mais voos". Você precisa clicar nele repetidamente até que todos os voos fiquem visíveis:
1 # Clique em "Mostrar mais voos" até carregar todos os resultados
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 breakEsse loop clica no botão, espera 2 segundos para os novos resultados renderizarem e para quando o botão não estiver mais visível. Nos meus testes, a maioria das rotas tem de 1 a 3 páginas de resultados.
Passo 6: Extraia os dados do voo com seletores CSS
Agora vamos analisar os dados reais de voo na página carregada. Aqui estão os seletores (verificados em abril de 2026 — veja a seção de manutenção abaixo para entender por que essa data importa):
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # Nome da companhia aérea
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # Horário de partida
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # Horário de chegada
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # Duração
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # Escalas
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # Preço
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # Emissões de CO2
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flightsAviso importante: classes como pIav2d, sSHqwe e FpEdX são geradas pelo Closure Compiler do Google e podem mudar a qualquer compilação. Já os seletores baseados em aria-label tendem a ser mais estáveis. Vou cobrir uma estratégia completa de manutenção abaixo.
Passo 7: Salve os resultados em JSON ou CSV
Por fim, salve os dados extraídos com um timestamp (isso é essencial para o rastreamento de preços depois):
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # Também salva como CSV
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"Scraped {len(flights)} flights")
25asyncio.run(main())Rode isso e você deve ver um flights.json e um flights.csv com os resultados. Nos meus testes, uma busca SFO-JFK normalmente retorna de 30 a 80 opções de voo e leva cerca de 15 a 20 segundos para concluir.
Guia de sobrevivência anti-bot para extrair dados do Google Flights
A maioria dos tutoriais para por aqui. A maioria dos extratores quebra aqui. O Google lançou o , e isso derrubou quase todos os scrapers de SERP da noite para o dia. O Google descreve a solução como "o resultado de dezenas de milhares de horas de trabalho e milhões de dólares em investimento". O Google Flights recebe nota para extração.
Nenhum artigo concorrente aprofunda esse ponto, mas essa é a principal razão pela qual os scrapers deixam de funcionar. Veja o que você está enfrentando e como lidar com isso.

Atrasos aleatórios entre requisições
A defesa mais simples contra limitação de taxa. Duas linhas de código, eficácia média:
1import time
2import random
3time.sleep(random.uniform(3, 7))Adicione isso entre as navegações de página. Intervalos fixos (como exatamente 5 segundos toda vez) são um sinal de alerta — use valores aleatórios.
Rotação de User-Agent
Enviar a mesma string de user-agent em todas as requisições é um indício fácil de detectar. Alterne entre uma lista:
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)Bypass de detecção em modo headless
O Google verifica o sinal navigator.webdriver e outros indícios de automação. A biblioteca playwright-stealth cobre a maioria deles, mas você também deve definir os argumentos de inicialização mostrados no Passo 3. Os principais flags:
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]Isso já passa pela detecção básica. O SearchGuard vai além — monitora velocidade do mouse, tempo entre teclas e padrões de rolagem — mas, para volumes moderados, o modo stealth com atrasos realistas costuma ser suficiente.
Rotação de proxy: datacenter vs. residencial
Para algo além de algumas buscas, você vai precisar de proxies. A diferença importa:
Proxies residenciais saem cerca de ao extrair dados de sites protegidos. Preços de provedores em 2026: Smartproxy a partir de US$ 7/GB, Bright Data US$ 8,40/GB e Oxylabs US$ 8/GB.
Adicione um proxy ao Playwright assim:
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)Como lidar com o pop-up de consentimento de cookies
Usuários relatam com frequência que o pop-up "Aceito os termos" bloqueia o acesso: "primeiro o Google vai mostrar o pop-up 'I agree to terms and conditions'." A forma mais limpa de resolver isso é pré-configurar o cookie SOCS (mostrado no Passo 3). Se não funcionar, clique no botão manualmente:
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # Não há pop-upObservação: o texto do botão muda conforme o idioma — "Alle akzeptieren" em alemão, "Tout accepter" em francês.
Referência rápida anti-bot
| Técnica | Dificuldade | Eficácia | Precisa de código? |
|---|---|---|---|
| Atrasos aleatórios (2–7s) | Baixa | Média | 2 linhas |
| Rotação de user-agent | Baixa | Média | 5 linhas |
| Bypass de detecção headless | Média | Alta | Argumentos de inicialização do Playwright |
| Plugin playwright-stealth | Média | 60–80% em sites básicos | pip install |
| Rotação de proxy (datacenter) | Média | Média | Configuração |
| Rotação de proxy (residencial) | Média | 85–95% de sucesso | Configuração |
| Pré-configuração de consentimento (SOCS) | Baixa | Obrigatório | 1 linha |
Como referência de segurança, mantenha intervalos de 10 a 20 segundos entre requisições com rotação de IP. Os limites do Google ficam em torno de 100 requisições por minuto por IP antes de surgir um erro 429, e volumes sustentados acima de 1.000 requisições por dia por IP podem gerar bloqueios temporários.
Por que seus seletores do Google Flights continuam quebrando (e como corrigir)
Esse é, de longe, o maior ponto de dor. Threads em fóruns estão cheias de variações como "tudo o que recebo são 14 listas vazias". Todo tutorial entrega seletores. Nenhum explica por que eles quebram.
Por que os seletores do Google Flights mudam
Tudo se resume a três fatores:
-
Ofuscação com Closure Compiler. O Google usa para gerar nomes de classe como
BVAVmfeYMlIzpor meio degoog.setCssNameMapping(). Eles mudam a cada compilação — às vezes semanalmente. -
Testes A/B. Usuários diferentes veem estruturas HTML diferentes ao mesmo tempo. Seu scraper pode funcionar na sua máquina e falhar para alguém em outra região.
-
Diferenças de localidade. Usuários da UE veem termos, layouts e até campos de dados diferentes dos usuários dos EUA.
Escreva seletores mais resilientes
Prefira seletores ligados ao significado, não à aparência:
1# Frágil — quebra em toda compilação
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# Mais resistente — ligado a rótulos de acessibilidade
4dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# Também resistente — correspondência por texto
6more_btn = page.locator('button:has-text("Show more flights")')Hierarquia de estabilidade dos seletores (do mais estável ao menos estável):
- Atributos
aria-label— ligados à acessibilidade, raramente mudam - Atributos
data-*— adicionados explicitamente para funcionalidade - Atributos
role— papéis ARIA são semânticos - Seletores baseados em texto — correspondem ao conteúdo visível
- Correspondência parcial de classe — por exemplo,
[class*="price"] - Nomes completos de classes ofuscadas — evite sempre que possível
Adicione uma função de validação
Não deixe seletores quebrados produzirem dados vazios em silêncio. Detecte isso cedo:
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"Campo ausente '{field_name}' — os seletores podem precisar de atualização"
11 )
12 valid = False
13 return validExecute isso em cada voo extraído. Se começarem a aparecer avisos, é hora de inspecionar a página e atualizar seus seletores.
Estratégia de manutenção dos seletores
- Verifique os seletores mensalmente, ou imediatamente se a qualidade da saída cair
- Mantenha os seletores em um dicionário de configuração separado para facilitar ajustes
- Os seletores deste artigo foram verificados pela última vez em abril de 2026
- Considere a biblioteca como alternativa — ela usa decodificação Protobuf em vez de seletores CSS, evitando esse problema quase por completo (embora também tenha sua própria fragilidade quando o Google altera os formatos internos de dados)
De uma extração pontual a um rastreador automático de preços do Google Flights
A maioria dos tutoriais termina em "salvar em JSON". O título deste artigo fala em "alertas de preço". Hora de entregar isso.
![]()
Agende seu extrator para rodar automaticamente
Opção 1: biblioteca schedule do Python (a mais simples e compatível com várias plataformas):
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)Opção 2: cron job (Linux/Mac):
1# Executa às 6h e às 18h todos os dias
20 6,18 * * * cd /path/to/scraper && python scraper.pyOpção 3: Agendador de Tarefas do Windows — crie uma tarefa básica para executar python scraper.py no horário desejado.
A contrapartida: todas essas opções exigem uma máquina sempre ligada. Se você rodar isso em um notebook que entra em suspensão, vai perder execuções.
Armazene o histórico de preços
Em vez de sobrescrever um arquivo JSON, passe a adicionar os dados em um banco SQLite:
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()Depois de uma semana de coletas duas vezes por dia, você já terá dados suficientes para começar a identificar tendências.
Analise tendências de preço e configure alertas
Encontre a opção mais barata no histórico:
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"Mais barato: US${cheapest['price_usd']:.0f} em "
13 f"{cheapest['scrape_date']} ({cheapest['airline']})"
14)Dispare um alerta por e-mail quando o preço cair abaixo do seu limite:
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"Alerta de queda de preço! {route}: US${price:.0f} "
6 f"(abaixo do seu limite de US${threshold:.0f})"
7 )
8 msg["Subject"] = f"Oferta de voo: {route} por US${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# Após cada coleta, verifique se há promoções
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")Frequência recomendada de coleta: duas vezes por dia é suficiente para acompanhar preços pessoais e reduz o risco de detecção. A cada 4 a 6 horas, se você estiver monitorando para um negócio. De hora em hora só durante períodos curtos de promoção, e temporariamente.
O caminho mais fácil: o Scheduled Scraper do Thunderbit
Se gerenciar cron jobs, servidor ligado e configuração de proxy parece infraestrutura demais para manter, o resolve o mesmo caso de uso sem esse peso. Você descreve o intervalo de coleta em linguagem simples, informa as URLs do Google Flights e o extrator roda automaticamente na infraestrutura em nuvem do Thunderbit — com tratamento anti-bot embutido e exportação direta para . Não substitui totalmente a abordagem em Python (você perde personalização), mas para o caso específico de "quero uma planilha com rastreamento de preços", é o caminho mais rápido. Você pode testar no .
Quando Python é exagero: formas sem código de extrair dados do Google Flights
Depois de montar tudo isso, vou ser sincero: são muitas peças móveis. Nem todo mundo precisa desse nível de controle. Seletores quebram, proxies precisam de rotação, cron jobs exigem monitoramento. Se o seu objetivo é simplesmente "colocar preços de voos em uma planilha com regularidade", existem opções mais rápidas.
Comparação: Python feito por conta própria vs. serviços de API vs. Thunderbit
| Abordagem | Tempo de configuração | Código necessário | Lida com anti-bot | Agendamento | Custo |
|---|---|---|---|---|---|
| Playwright DIY (este tutorial) | 1–2 horas | Python (intermediário) | Configuração manual | Manual (cron) | Grátis + custos de proxy |
| Endpoint Google Flights do SerpApi | 15 min | Apenas chamadas de API | Já tratado | Via API | Cerca de US$ 50+/mês |
| Extensão Chrome do Thunderbit | 2 min | Nenhum | Extração em nuvem | Agendamento integrado | Plano grátis disponível |
Um ponto sobre o SerpApi: o Google , alegando que o volume de requisições aumentou 25.000% em dois anos. Esse nível de incerteza jurídica vale ser considerado se você estiver avaliando provedores de API.
Como o Thunderbit extrai dados do Google Flights
Abra os resultados da sua busca no Google Flights no Chrome, clique no botão "AI Suggest Fields" do Thunderbit — a IA lê a página e sugere colunas como companhia aérea, preço, horário de partida e escalas — revise os campos sugeridos e clique em "Scrape". Os resultados aparecem em uma tabela que você pode exportar para Excel, Google Sheets, Airtable ou Notion — tudo no .
Para o caso específico de rastreamento de preços, o Scheduled Scraper do Thunderbit e o (capaz de processar 50 páginas ao mesmo tempo) substituem toda a infraestrutura de cron + proxy + servidor.
Python oferece controle total e personalização ilimitada. Thunderbit oferece velocidade e zero manutenção. Escolha de acordo com seu objetivo real. Se quiser aprender mais sobre abordagens sem código, confira nosso guia sobre .

É legal extrair dados do Google Flights? O que você precisa saber
Usuários de fóruns perguntam isso com frequência: "extrair dados do Google Flights diretamente viola os termos de serviço do Google". É uma preocupação justa — principalmente porque a API foi descontinuada e não existe uma alternativa oficial sancionada.
Violação dos termos vs. responsabilidade legal
Os Termos de Serviço do Google (atualizados em 22 de maio de 2024) dizem que o usuário não deve "acessar ou usar os Serviços ou qualquer conteúdo por meio de métodos automatizados (como robôs, spiders ou scrapers)". Violar os termos é uma quebra contratual (matéria civil) — não é a mesma coisa que cometer um crime.
O precedente jurídico mais importante: hiQ v. LinkedIn (Nono Circuito, 2022) estabeleceu que extrair dados publicamente disponíveis não viola o Computer Fraud and Abuse Act (CFAA). No entanto, o caso terminou em acordo, e o processo do Google contra o SerpApi em dezembro de 2025 usa outra teoria jurídica — a Seção 1201 da DMCA (circunvenção de medidas de proteção tecnológicas) — que pode ser mais séria.
Boas práticas para extração responsável
- Limite a taxa de requisições — intervalos de 10 a 20 segundos com rotação de IP
- Não colete dados pessoais — preços de voos são dados agregados exibidos publicamente
- Não contorne CAPTCHAs programaticamente (essa é a área de risco da DMCA)
- Use os dados para pesquisa pessoal, não para criar um produto comercial concorrente sem licenciamento adequado
- Considere APIs oficiais quando houver disponibilidade
Fontes alternativas de dados
Se a extração parecer arriscada demais para o seu caso, há opções legítimas de API:
| Provedor | Custo | Plano grátis | Observações |
|---|---|---|---|
| SerpApi | US$ 75–US$ 3.750+/mês | 250 buscas/mês | JSON direto do Google Flights (sob escrutínio jurídico) |
| Kiwi Tequila | Grátis (modelo de afiliado) | Ilimitado | Melhor para startups e testes |
| Amadeus | Pagamento conforme uso | 2.000 requisições/mês | Mais de 400 companhias aéreas, com capacidade de reserva |
| Skyscanner | Personalizado | Requer aprovação | 52 mercados, 30 idiomas |
Escrevemos um detalhamento mais completo sobre se você quiser uma visão mais ampla.
Conclusão e principais aprendizados
Foi bastante coisa. O que importa é o seguinte:
- Python + Playwright é a abordagem mais flexível para extrair dados do Google Flights, mas exige manutenção contínua
- As medidas anti-bot (atrasos, rotação de user-agent, proxies residenciais) não são opcionais — são essenciais para a confiabilidade, principalmente depois do SearchGuard
- Os seletores quebram com frequência — use
aria-labele seletores baseados em texto sempre que possível, valide a saída e mantenha uma rotina de revisão - Automatize com
scheduleou cron para transformar uma extração pontual em um rastreador de preços real, com histórico e alertas por e-mail - oferece uma alternativa sem código, com agendamento integrado, extração em nuvem e tratamento anti-bot — ideal se seu objetivo é uma planilha de rastreamento de preços, e não um projeto de programação
- Respeite os limites legais — limite a taxa, colete apenas dados públicos e considere alternativas de API para uso comercial
Pegue o código deste tutorial ou instale a para seguir pelo caminho mais rápido. De qualquer forma, você vai passar a monitorar preços de voos em vez de atualizar o Google Flights manualmente.
Para mais técnicas de scraping em Python, confira nossos guias sobre e .
Perguntas frequentes
1. Posso extrair dados do Google Flights sem Python?
Sim. Serviços de API como SerpApi e Kiwi Tequila fornecem dados estruturados de voos por chamadas de API (sem necessidade de automação de navegador). Para uma abordagem totalmente sem código, a pode extrair resultados do Google Flights diretamente do navegador, com campos sugeridos por IA e exportação com um clique.
2. O Google bloqueia a extração de dados de voos?
O Google usa detecção de bots (SearchGuard), CAPTCHAs e limitação de taxa. Com medidas anti-bot adequadas — atrasos aleatórios, rotação de user-agent, proxies residenciais e configurações stealth no navegador — você consegue manter a extração confiável em volumes moderados. Veja a seção anti-bot acima para técnicas e limites específicos.
3. Com que frequência devo extrair o Google Flights para rastreamento de preços?
Duas vezes por dia, em horários aleatórios, é suficiente para acompanhar preços pessoais e mantém baixo o risco de detecção. Para monitoramento de negócios, a cada 4 a 6 horas com rotação de proxy. Evite coletas de hora em hora, exceto durante promoções de curta duração — isso aumenta bastante a chance de bloqueio.
4. Existe uma API gratuita do Google Flights?
A API oficial Google QPX Express foi . Não existe um substituto oficial gratuito. A opção gratuita mais próxima é a (modelo de afiliado, buscas ilimitadas). O SerpApi oferece 250 buscas grátis por mês. Para a maioria dos usuários, a extração direta ou uma ferramenta sem código como o Thunderbit é o caminho mais prático.
5. Por que meus seletores CSS do Google Flights continuam retornando dados vazios?
O Google usa o Closure Compiler para gerar nomes de classe ofuscados que mudam a cada compilação. Testes A/B e diferenças de localidade também fazem a estrutura HTML variar entre usuários. A solução: use atributos aria-label e seletores baseados em texto em vez de nomes de classe, adicione uma função de validação para detectar falhas cedo e revise seus seletores mensalmente. Veja a seção de manutenção de seletores para uma estratégia detalhada.
Saiba mais