Se o seu scraper do Glassdoor funcionava muito bem em 2022 e agora só devolve erros 403, você não está sozinho. Fórum atrás de fórum repete a mesma dúvida: "Alguém sabe por que esse scraper não funciona mais?"
A resposta curta: o Glassdoor mudou tudo. A Recruit Holdings incorporou o Glassdoor ao Indeed em julho de 2025, demitiu e endureceu tanto a camada anti-bot que scrapers comuns, com Selenium ou requests, são bloqueados antes mesmo de carregar o primeiro byte de HTML. Em fevereiro de 2026, os logins do Glassdoor passaram a ser tratados inteiramente pelo Indeed Login — então qualquer tutorial que dependa de um formulário de login específico do Glassdoor já nasce quebrado na origem. Enquanto isso, a plataforma ainda reúne em . Esses dados são valiosíssimos para benchmarking de RH, inteligência competitiva e prospecção comercial — se você conseguir acessá-los. Este guia é a versão que funciona depois de todas essas mudanças, cobrindo os três tipos de dados do Glassdoor (vagas, avaliações e salários) em um só lugar. Vou mostrar a abordagem com Python usando código de 2025 que realmente funciona, explicar exatamente o que te bloqueia e como contornar, e ainda apresentar um atalho sem código para quem prefere pular toda a parte de engenharia.
Por que fazer scraping do Glassdoor com Python em 2025?
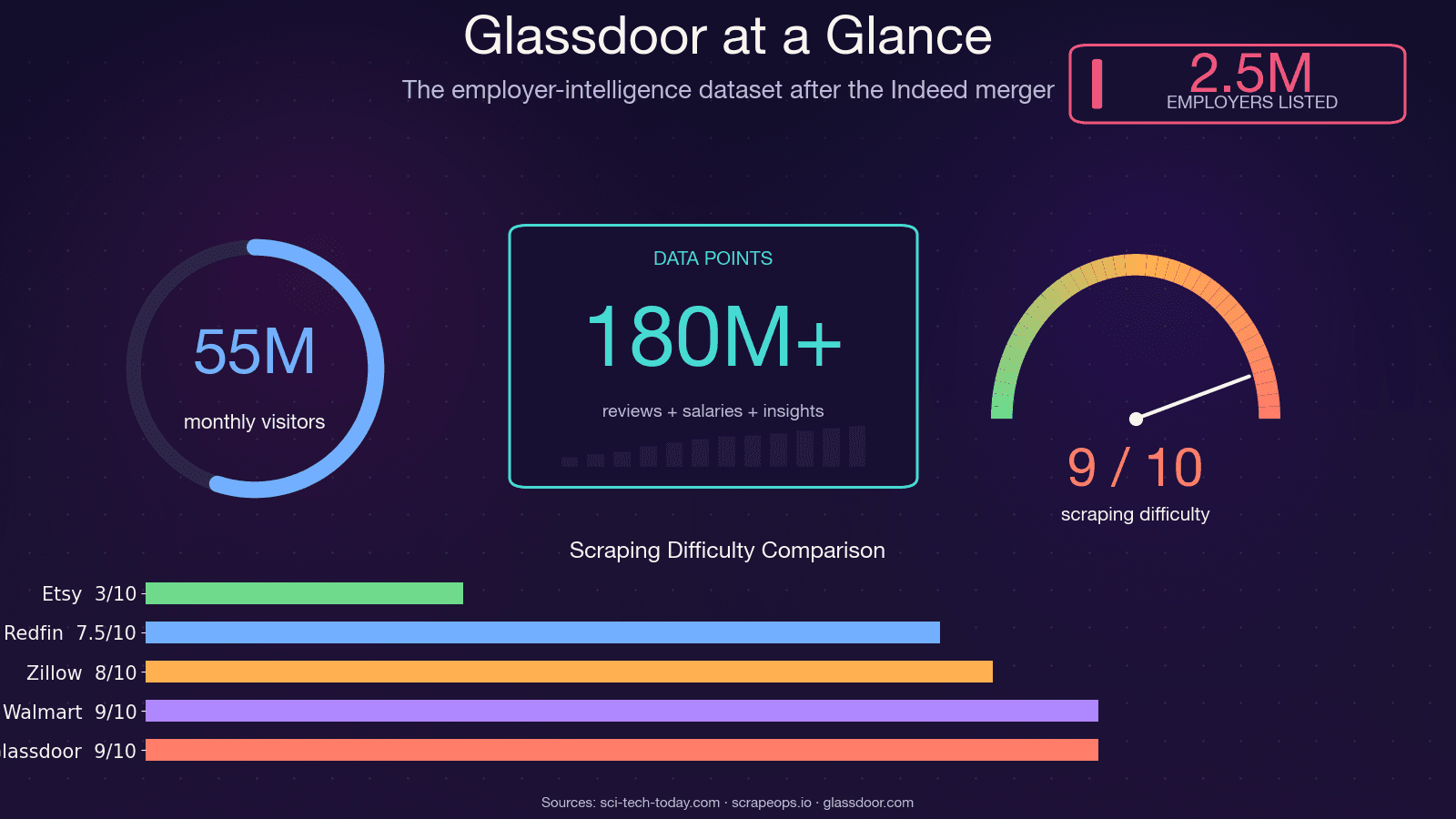
O Glassdoor não é só um site de vagas. Ele é uma das bases de inteligência sobre empregadores mais ricas da web — usada por cerca de e recebendo algo em torno de 55 milhões de visitantes únicos por mês. Os dados por trás dessas páginas alimentam decisões reais em várias áreas.
Veja como diferentes equipes usam os dados do Glassdoor na prática:
| Caso de uso | Tipo de dado necessário | Quem se beneficia |
|---|---|---|
| Benchmark salarial | Faixas salariais, tamanho das amostras | RH, Total Rewards, Operações |
| Monitoramento de contratação da concorrência | Vagas publicadas, velocidade de postagem | Vendas, Estratégia, VC/Corp Dev |
| Acompanhamento da marca empregadora | Texto de avaliações, tendências de nota, aprovação do CEO | RH, Marketing, Comunicação |
| Geração de leads (empresas em crescimento) | Vagas + informações da empresa | Times de vendas, SDRs |
| Pesquisa de mercado/acadêmica | Os três tipos | Analistas, Consultores, Pesquisadores |
Quando o BLS não conseguiu publicar os dados de empregos durante a paralisação do governo em outubro de 2025, a equipe de Economic Research do próprio Glassdoor usando o próprio banco de dados. É assim que analistas institucionais enxergam esses dados hoje.
O Python continua sendo a linguagem preferida porque o ecossistema é imbatível — Playwright para automação de navegador, parsel/lxml para parsing, curl_cffi para contornar fingerprint TLS, além de uma comunidade enorme que compartilha padrões que funcionam. O problema não é o Python. O problema é que o Glassdoor ficou muito mais difícil de raspar.
Se você quiser uma alternativa sem código para extrair dados do Glassdoor, o Thunderbit pode ajudar a capturar vagas, avaliações e páginas de salário sem precisar criar e manter uma stack Python personalizada.
Quais dados do Glassdoor você realmente consegue extrair?
A maioria dos tutoriais só cobre vagas. Mas a demanda dos usuários — com base em threads de fórum, issues no GitHub e perguntas no Reddit que acompanhei — é maior justamente para os dois tipos de dados que quase ninguém ensina: avaliações e salários. Abaixo está o panorama completo do que dá para extrair em cada categoria.
Vagas
O tipo de dado mais acessível. Você pode capturar: cargo, nome da empresa, localização, estimativa salarial, nota da empresa, data da postagem, selo de candidatura fácil e link da vaga. As vagas ficam parcialmente disponíveis sem login, embora o Glassdoor possa exibir um popup de login depois de algumas páginas.
Avaliações da empresa
Aqui a análise de employer brand fica interessante. Os campos que podem ser extraídos incluem: nota geral, subnotas (equilíbrio vida pessoal/trabalho, cultura e valores, diversidade e inclusão, oportunidades de carreira, remuneração e benefícios, alta liderança), texto de prós, texto de contras, cargo do avaliador, data da avaliação e status de emprego. O texto completo da avaliação exige autenticação — você vê um trecho, mas os prós/contras completos ficam bloqueados.
Dados salariais
O tipo de dado mais pedido — e também o mais frustrante. Você pode extrair: cargo, faixa salarial base, faixa de remuneração total, número de relatos salariais e localização. Mas as páginas de salário são totalmente protegidas por login e, às vezes, o Glassdoor ainda adiciona um fluxo de "contribua para desbloquear", em que você precisa informar seu próprio salário antes de ver os dados dos outros. Nenhum tutorial concorrente traz código funcional para isso — vamos resolver aqui.
O que precisa de login e o que não precisa
Esta tabela evita que você descubra da pior forma quais páginas vão retornar dados vazios:
| Tipo de dado | Disponível sem login? | Observações |
|---|---|---|
| Títulos de vagas e informações básicas | Em geral, sim | Um popup pode aparecer após algumas páginas |
| Descrições completas das vagas | Parcial | Muitas vezes bloqueadas após 2–3 visualizações |
| Avaliações completas da empresa | Não — requer login | O trecho aparece, o texto completo fica bloqueado |
| Dados salariais | Não — requer login | Também pode exigir "contribuir para desbloquear" |
Por que o seu scraper antigo do Glassdoor provavelmente quebrou
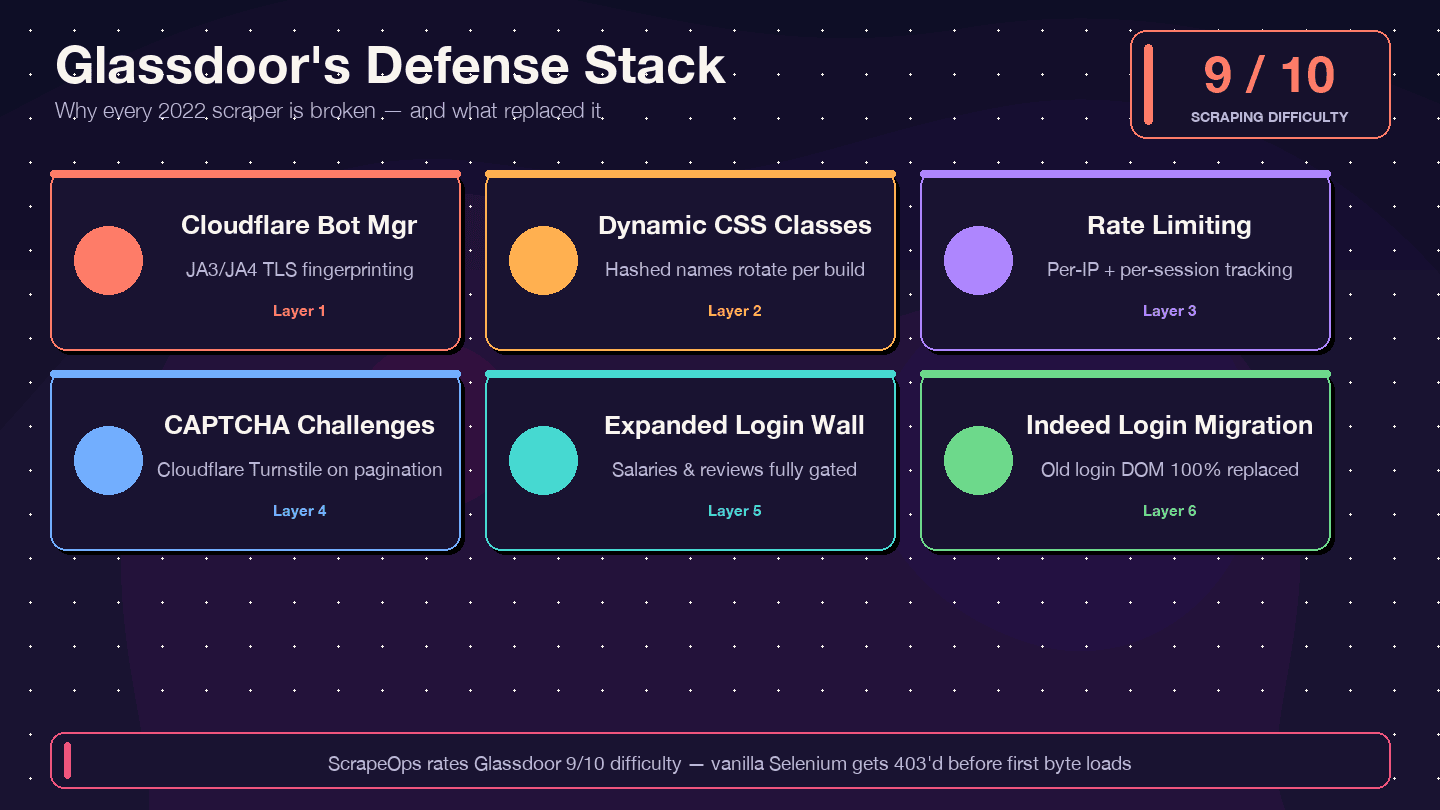
Vou ser direto: se você estiver copiando código de um tutorial de 2021–2023, ele não vai funcionar. O scraper Selenium legado mais estrelado do Glassdoor no GitHub (, cerca de 1,4 mil estrelas) tem mais de 12 issues abertas sem resposta — incluindo "Glassdoor new UI design", "Cloudflare anti-bot protection" e "NoSuchElementException". O repositório, na prática, foi abandonado. O . O e 8/10 para a dificuldade de contornar as proteções.
Veja o que mudou e por que o código antigo quebra:
| Camada de defesa | O que mudou | Impacto nos scrapers antigos |
|---|---|---|
| Cloudflare Bot Management | Fingerprinting JA3/JA4 mais rigoroso desde 2024 | Scripts básicos com requests/Selenium recebem 403 imediatamente |
| Nomes de classes CSS dinâmicos | Os nomes das classes são randomizados a cada build | Seletores CSS antigos de tutoriais quebram sem avisar |
| Limite de requisições + rastreamento de sessão | Restrições mais duras por IP e por sessão | Scrapers são bloqueados depois de poucas páginas |
| Desafios CAPTCHA (provavelmente Cloudflare Turnstile) | Mais frequentes, especialmente na paginação | Navegadores headless acionam desafios |
| Parede de login ampliada | Mais tipos de página exigem autenticação | Páginas de salário e avaliações voltam vazias |
| Migração para Indeed Login (fev. 2026) | O formulário de login do Glassdoor foi totalmente substituído | Qualquer código apontando para o antigo DOM de login está morto |
O traz um aviso explícito: "Glassdoor is known for its high blocking rate, so if you get None values while running the Python code, it's likely you're getting blocked." E um é bem direto: "Simple HTTP requests with requests or httpx get blocked instantly."
As contramedidas que vou mostrar — Patchright (um fork furtivo do Playwright), seletores de atributo data-test, proxies residenciais rotativos e sessões autenticadas persistentes — foram pensadas especificamente para lidar com cada uma dessas camadas.
API do Glassdoor vs. scraping com Python: escolha o caminho certo primeiro
Vários tópicos em fórum perguntam "É melhor usar a API do Glassdoor?" — e a resposta é: não dá.
A . O portal de desenvolvedores ainda existe tecnicamente, mas . Nunca houve um endpoint público para avaliações — o scraper de MatthewChatham foi criado justamente "porque o Glassdoor não tem uma API para reviews". E não existe caminho de migração para avaliações ou salários dentro da Publisher API do Indeed.
Aqui está a comparação honesta:
| Fator | Glassdoor Partner API v1 | Scraping com Python | Thunderbit (sem código) |
|---|---|---|---|
| Acesso | Fechado para novos solicitantes | Aberto (você implementa) | Extensão do Chrome |
| Vagas | Limitado/descontinuado | Disponível com esforço | Disponível |
| Avaliações da empresa | Nunca existiu publicamente | Sim (exige login) | Sim (via Browser Mode) |
| Dados salariais | Nunca existiu publicamente | Sim (exige login) | Sim |
| Limites de taxa | Não documentados | Você controla o ritmo | Baseado em créditos |
| Esforço de configuração | Não dá para registrar novos apps | De horas a dias | ~2 minutos |
| Manutenção | N/A | Alta (mudanças no HTML quebram o código) | Baixa (a IA sugere os campos de novo) |
Se você precisa de avaliações ou salários — e a maioria das pessoas lendo isso precisa — scraping com Python ou uma ferramenta sem código é a única opção realista.
Antes de começar
- Dificuldade: Intermediária (você deve se sentir confortável com Python e terminal)
- Tempo necessário: ~30–60 minutos para a configuração completa; ~10 minutos por tipo de dado depois disso
- O que você vai precisar:
- Python 3.10+ (recomendado 3.11 ou 3.12)
- Navegador Chrome instalado
- Uma conta Glassdoor (gratuita — necessária para dados de salário e avaliação)
- Proxies residenciais rotativos (para raspar mais do que algumas páginas)
- Opcional: se você quiser seguir pelo caminho sem código
Ferramentas e bibliotecas para raspar o Glassdoor com Python em 2025
O cenário de ferramentas mudou bastante. Veja o que realmente funciona contra as defesas atuais do Glassdoor.
Por que o Patchright é a melhor escolha para o Glassdoor
é um fork furtivo do Playwright que corrige o vazamento Runtime.Enable via CDP — o motivo técnico específico pelo qual o Playwright puro falha em sites protegidos pela Cloudflare. Ele usa exatamente a mesma API do Playwright, então, se você conhece Playwright, você já sabe usar Patchright. A versão 1.58.2 (março de 2026) é a atual e segue em manutenção ativa.
Comparando com as alternativas:
- Playwright puro: É detectado na página de login do Glassdoor por causa do vazamento Runtime.Enable
- Selenium + undetected-chromedriver: a última versão do undetected-chromedriver saiu em fevereiro de 2024 — praticamente uma tecnologia legada. O mostrou que ele "falhou em todos os domínios do nosso teste"
- requests + BeautifulSoup: Não renderiza JavaScript e é bloqueado imediatamente pelo fingerprint TLS da Cloudflare
- : Excelente para o caminho rápido (10–20x mais rápido que um navegador) quando as páginas trazem
__NEXT_DATA__no HTML inicial, mas não lida com login nem desafios intermediários
Bibliotecas de apoio
- parsel (1.11.0) ou lxml (6.0.4): parsing de HTML/XPath rápido
- csv ou pandas: exportação de dados
- asyncio: scraping assíncrono para paginação mais rápida
Proxies: apenas residenciais
A camada Cloudflare do Glassdoor desafia agressivamente ASNs de datacenter. . O preço inicial fica em torno de (promocional) ou US$ 3,00/GB na . Para scraping em produção, reserve algo entre US$ 3 e US$ 8/GB, dependendo do volume.
Atrasos aleatórios entre requisições (mínimo de 3–8 segundos, 5–15 segundos em execuções mais longas) são essenciais, independentemente da qualidade do proxy.
Etapa 1: configurar seu ambiente Python
Crie a pasta do projeto e instale a stack recomendada:
1mkdir glassdoor-scraper && cd glassdoor-scraper
2python3.11 -m venv .venv
3source .venv/bin/activate
4pip install --upgrade pip
5# Stack principal
6pip install patchright==1.58.2 parsel==1.11.0
7# Instalar binários do navegador
8patchright install chromium
9# Opcional: caminho rápido para extração de __NEXT_DATA__
10pip install "curl_cffi==0.15.0"Você deve ver o Patchright baixando um binário do Chromium. Se patchright install chromium falhar, verifique se há espaço em disco suficiente (~300 MB) e se sua versão do Python é 3.10+.
Etapa 2: iniciar o Patchright e navegar até o Glassdoor
Este é o padrão básico de inicialização que funciona contra a camada Cloudflare do Glassdoor:
1from patchright.sync_api import sync_playwright
2import random, time
3with sync_playwright() as p:
4 browser = p.chromium.launch(
5 headless=False, # headless ainda é mais detectável
6 channel="chrome", # use o Chrome real, não o Chromium empacotado
7 )
8 context = browser.new_context(
9 viewport={"width": 1440, "height": 900},
10 locale="en-US",
11 timezone_id="America/New_York",
12 user_agent=(
13 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
14 "AppleWebKit/537.36 (KHTML, like Gecko) "
15 "Chrome/134.0.0.0 Safari/537.36"
16 ),
17 )
18 page = context.new_page()
19 page.goto(
20 "https://www.glassdoor.com/Job/new-york-data-engineer-jobs-"
21 "SRCH_IL.0,8_IC1132348_KO9,22.htm"
22 )
23 # Fechar o overlay de login — o conteúdo ainda está no DOM
24 page.add_style_tag(content="""
25 #HardsellOverlay, .LoginModal { display: none !important; }
26 body { overflow: auto !important; position: initial !important; }
27 """)
28 page.wait_for_selector("[data-test='jobListing']")
29 print("Página carregada — vagas visíveis.")Alguns pontos importantes aqui. O parâmetro channel="chrome" faz o Patchright usar o binário do Chrome instalado localmente, em vez do Chromium empacotado — isso gera uma impressão digital de navegador mais autêntica. O truque add_style_tag oculta o modal de login do Glassdoor (chamado #HardsellOverlay) sem precisar clicar em nada. O que "todo o conteúdo ainda está lá, ele só está coberto pelo overlay" — o HTML contém os dados independentemente de o modal estar visível.
Você deve ver uma janela do Chrome abrir, navegar até a página de busca de vagas do Glassdoor e exibir os cards das vagas sem o popup de login atrapalhando a visualização.
Etapa 3: raspar vagas do Glassdoor
Identificar seletores estáveis
O Glassdoor randomiza os nomes das classes CSS em cada build — então o seletor .jobCard_xyz123 de um tutorial de 2023 vai retornar nada silenciosamente hoje. Em vez disso, use atributos data-test, que são uma convenção interna de QA do Glassdoor e permanecem estáveis entre deploys.
Aqui está a referência de seletores para os campos das vagas:
| Campo | Seletor |
|---|---|
| Container do card da vaga | [data-test="jobListing"] |
| Título da vaga | [data-test="job-title"] |
| Link da vaga | a[data-test="job-link"] |
| Nome da empresa | [data-test="employer-name"] |
| Localização | [data-test="emp-location"] |
| Faixa salarial | [data-test="detailSalary"] |
| Nota da empresa | [data-test="rating"] |
| Data da postagem | [data-test="job-age"] |
| Próxima página | [data-test="pagination-next"] |
Extrair os dados das vagas
1from parsel import Selector
2import csv, random, time
3def scrape_jobs(page, max_pages=5):
4 all_jobs = []
5 for page_num in range(1, max_pages + 1):
6 html = page.content()
7 sel = Selector(text=html)
8 cards = sel.css('[data-test="jobListing"]')
9 if not cards:
10 print(f"Página {page_num}: nenhum card encontrado — possível bloqueio ou mudança de seletor.")
11 break
12 for card in cards:
13 job = {
14 "title": card.css('[data-test="job-title"]::text').get("").strip(),
15 "company": card.css('[data-test="employer-name"]::text').get("").strip(),
16 "location": card.css('[data-test="emp-location"]::text').get("").strip(),
17 "salary": card.css('[data-test="detailSalary"]::text').get("").strip(),
18 "rating": card.css('[data-test="rating"]::text').get("").strip(),
19 "link": card.css('a[data-test="job-link"]::attr(href)').get(""),
20 "posted": card.css('[data-test="job-age"]::text').get("").strip(),
21 }
22 if job["link"] and not job["link"].startswith("http"):
23 job["link"] = "https://www.glassdoor.com" + job["link"]
24 all_jobs.append(job)
25 print(f"Página {page_num}: extraídas {len(cards)} vagas")
26 # Paginação
27 next_btn = page.query_selector('[data-test="pagination-next"]')
28 if next_btn and page_num < max_pages:
29 next_btn.click()
30 time.sleep(random.uniform(3, 8))
31 page.wait_for_selector("[data-test='jobListing']")
32 else:
33 break
34 return all_jobsSalvar em CSV
1def save_to_csv(jobs, filename="glassdoor_jobs.csv"):
2 if not jobs:
3 print("Nenhuma vaga para salvar.")
4 return
5 keys = jobs[0].keys()
6 with open(filename, "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=keys)
8 writer.writeheader()
9 writer.writerows(jobs)
10 print(f"Salvas {len(jobs)} vagas em {filename}")Uma observação sobre limites de paginação: o Glassdoor limita os resultados de busca a cerca de 30 páginas, independentemente do total disponível. Se você precisar de mais cobertura, use filtros (localização, tipo de vaga, faixa salarial) para dividir cada busca, em vez de tentar avançar além desse limite.
Nos meus testes, raspar 5 páginas de vagas (cerca de 75 vagas) levou em torno de 45 segundos com atrasos aleatórios. Fazer a mesma coisa manualmente levaria pelo menos 20 minutos de copiar e colar.
Etapa 4: raspar avaliações de empresas no Glassdoor
Esta é a seção que nenhum outro tutorial traz com código funcional. As avaliações são onde mora a verdadeira inteligência sobre empregadores — análise de sentimento, sinais de cultura, alertas de gestão.
Ir para a página de avaliações
As URLs de avaliações seguem este padrão: /Reviews/{Empresa}-Reviews-E{id}.htm. Você pode descobrir o ID da empresa pesquisando a companhia no Glassdoor e conferindo a URL.
1def navigate_to_reviews(page, company_reviews_url):
2 page.goto(company_reviews_url)
3 page.add_style_tag(content="""
4 #HardsellOverlay, .LoginModal { display: none !important; }
5 body { overflow: auto !important; position: initial !important; }
6 """)
7 page.wait_for_selector('[data-test="review"]', timeout=15000)O endpoint BFF oculto (o caminho mais limpo)
Aqui está a maior descoberta da minha pesquisa: as avaliações do Glassdoor têm uma API JSON interna funcional que dispensa totalmente o parsing de HTML. O documenta esse endpoint, e ele é muito mais confiável do que raspar o DOM.
1import json, re, requests
2def get_review_ids(page):
3 """Extrai employerId e dynamicProfileId do HTML da página de avaliações."""
4 html = page.content()
5 sel = Selector(text=html)
6 script_text = sel.xpath(
7 "//script[contains(text(), 'profileId')]/text()"
8 ).get("")
9 employer_match = re.search(r'"employer"\s*:\s*(\{[^}]+\})', script_text)
10 if employer_match:
11 meta = json.loads(employer_match.group(1))
12 return meta.get("id"), meta.get("profileId")
13 return None, None
14def fetch_reviews_bff(page, employer_id, profile_id, max_pages=5):
15 """Chama o endpoint BFF interno do Glassdoor para obter dados estruturados de avaliações."""
16 all_reviews = []
17 cookies = {c["name"]: c["value"] for c in page.context.cookies()}
18 for pg in range(1, max_pages + 1):
19 payload = {
20 "applyDefaultCriteria": True,
21 "employerId": employer_id,
22 "dynamicProfileId": profile_id,
23 "employmentStatuses": ["REGULAR", "PART_TIME"],
24 "language": "eng",
25 "onlyCurrentEmployees": False,
26 "page": pg,
27 "pageSize": 10,
28 "sort": "DATE",
29 "textSearch": "",
30 }
31 resp = requests.post(
32 "https://www.glassdoor.com/bff/employer-profile-mono/employer-reviews",
33 json=payload,
34 cookies=cookies,
35 headers={"Content-Type": "application/json"},
36 )
37 if resp.status_code != 200:
38 print(f"BFF retornou {resp.status_code} na página {pg}")
39 break
40 data = resp.json()
41 reviews = data.get("data", {}).get("employerReviews", {}).get("reviews", [])
42 total_pages = data.get("data", {}).get("employerReviews", {}).get("numberOfPages", 1)
43 for r in reviews:
44 all_reviews.append({
45 "title": r.get("summary", ""),
46 "rating": r.get("ratingOverall"),
47 "pros": r.get("pros", ""),
48 "cons": r.get("cons", ""),
49 "author_role": r.get("jobTitle", {}).get("text", ""),
50 "date": r.get("reviewDateTime", ""),
51 "recommend": r.get("isRecommend"),
52 })
53 print(f"Página de avaliações {pg}/{total_pages}: {len(reviews)} avaliações obtidas")
54 if pg >= total_pages:
55 break
56 time.sleep(random.uniform(3, 6))
57 return all_reviewsO endpoint BFF entrega JSON limpo com todos os campos das avaliações — sem parsing de HTML, sem quebra por mudança de seletor CSS. Você precisa dos cookies de sessão de um contexto autenticado do Playwright (coberto na Etapa 6) e precisa extrair primeiro o employerId e o dynamicProfileId do HTML da página de avaliações.
Seletores HTML alternativos para avaliações
Se o endpoint BFF mudar ou se você preferir parsing do DOM, estes são os seletores data-test mais estáveis:
| Campo | Seletor |
|---|---|
| Container da avaliação | [data-test="review"] |
| Título | [data-test="review-title"] |
| Nota geral | [data-test="overall-rating"] |
| Prós | [data-test="pros"] |
| Contras | [data-test="cons"] |
| Data | [data-test="review-date"] |
| Cargo do autor | [data-test="author-jobTitle"] |
Etapa 5: raspar dados salariais do Glassdoor
As páginas de salário são totalmente protegidas por login. Você precisa de uma sessão autenticada (Etapa 6) antes que qualquer código aqui retorne dados reais.
Ir para a página de salário
As URLs de salário seguem o padrão: /Salary/{Empresa}-Salaries-E{id}.htm, com paginação em _P{n}.htm.
1def scrape_salaries(page, salary_url, max_pages=3):
2 all_salaries = []
3 for pg in range(1, max_pages + 1):
4 url = salary_url if pg == 1 else salary_url.replace(".htm", f"_P{pg}.htm")
5 page.goto(url)
6 page.add_style_tag(content="""
7 #HardsellOverlay { display: none !important; }
8 body { overflow: auto !important; position: initial !important; }
9 """)
10 time.sleep(random.uniform(3, 7))
11 html = page.content()
12 sel = Selector(text=html)
13 items = sel.css('[data-test="salary-item"]')
14 if not items:
15 print(f"Página de salário {pg}: nenhum item — possível bloqueio por login ou bloqueio.")
16 break
17 for item in items:
18 salary = {
19 "job_title": item.css('[class*="SalaryItem_jobTitle__"]::text').get("").strip(),
20 "salary_range": item.css('[class*="SalaryItem_salaryRange__"]::text').get("").strip(),
21 "count": item.css('[class*="SalaryItem_salaryCount__"]::text').get("").strip(),
22 }
23 all_salaries.append(salary)
24 print(f"Página de salário {pg}: extraídos {len(items)} registros")
25 return all_salariesRepare no padrão de correspondência por prefixo [class*="SalaryItem_jobTitle__"]. A página de salários do Glassdoor usa nomes de classes com hash de CSS modules (por exemplo, SalaryItem_jobTitle__XWGpT), em que o sufixo muda a cada deploy. O prefixo permanece estável — o hash, não. Nunca fixe o nome completo da classe no código.
Etapa 6: ultrapassar a barreira de login do Glassdoor
Essa é a parte crítica que libera os dados salariais e o texto completo das avaliações. A estratégia: fazer login uma vez manualmente em um navegador visível, salvar o estado autenticado da sessão e reutilizá-lo em todas as execuções seguintes de scraping.
Salvar sua sessão autenticada
Execute este script uma vez. Ele abre uma janela do Chrome, acessa a página de login do Glassdoor (que agora redireciona para o Indeed Login) e espera você fazer login manualmente:
1import asyncio
2from pathlib import Path
3from patchright.async_api import async_playwright
4STATE_FILE = Path("glassdoor_state.json")
5async def login_and_save():
6 async with async_playwright() as p:
7 browser = await p.chromium.launch(headless=False, channel="chrome")
8 context = await browser.new_context(
9 viewport={"width": 1366, "height": 800},
10 locale="en-US",
11 )
12 page = await context.new_page()
13 await page.goto("https://www.glassdoor.com/profile/login_input.htm")
14 print("Faça login na janela do navegador e depois pressione Enter aqui...")
15 input()
16 await context.storage_state(path=str(STATE_FILE))
17 print(f"Sessão salva em {STATE_FILE}")
18 await browser.close()
19asyncio.run(login_and_save())Depois que você fizer login e pressionar Enter, o Patchright salva todos os cookies e o local storage em glassdoor_state.json. Esse arquivo contém seu gdId, GSESSIONID, cf_clearance e tokens de autenticação.
Reutilizar a sessão no scraping
Toda execução posterior carrega o estado salvo — sem necessidade de novo login manual:
1async def scrape_with_auth(target_url):
2 async with async_playwright() as p:
3 browser = await p.chromium.launch(headless=True, channel="chrome")
4 context = await browser.new_context(
5 storage_state="glassdoor_state.json"
6 )
7 page = await context.new_page()
8 await page.goto(target_url)
9 await page.add_style_tag(
10 content="#HardsellOverlay{display:none!important}"
11 )
12 await page.wait_for_load_state("networkidle")
13 html = await page.content()
14 await browser.close()
15 return htmlA sessão salva normalmente dura de 20 a 30 minutos de uso ativo antes de o Glassdoor pedir validação novamente. Para execuções mais longas, crie uma verificação: se uma página que deveria ter dados retornar zero resultados, rode novamente o script de login para atualizar o arquivo de estado.
Detectar e dispensar o popup de login
Em páginas parcialmente bloqueadas (como vagas que mostram os dados, mas cobrem tudo com um modal), a injeção de CSS mostrada nas etapas anteriores funciona:
1page.add_style_tag(content="""
2 #HardsellOverlay, .LoginModal { display: none !important; }
3 body { overflow: auto !important; position: initial !important; }
4""")Isso só funciona quando o HTML já contém os dados por trás do overlay. Para páginas totalmente protegidas no servidor (salários, páginas profundas de avaliações), a sessão autenticada da Etapa 6 é o único caminho.
Dicas para manter seu scraper do Glassdoor funcionando
O Glassdoor atualiza o front-end com frequência. Veja como tornar seu scraper mais resiliente.
Prefira atributos data-test em vez de nomes de classe
O Glassdoor randomiza os nomes das classes CSS, mas tende a manter os atributos data-test estáveis. Sempre prefira [data-test="jobListing"] em vez de .jobCard_abc123. Quando data-test não existir (como nos campos salariais), use o padrão de prefixo: [class*="SalaryItem_jobTitle__"].
Rode proxies e randomize atrasos
Use proxies residenciais rotativos — IPs de datacenter são desafiados quase de imediato. Adicione atrasos aleatórios de 3–8 segundos entre carregamentos de página (5–15 segundos em execuções maiores). Se puder, evite raspar durante o horário comercial dos EUA, quando a detecção comportamental da Cloudflare é mais agressiva.
Monitore quebras
Inclua uma checagem simples no seu scraper: se uma página que deveria conter dados retornar zero registros extraídos, trate isso como falha de seletor (não como conjunto vazio) e emita um alerta. Rode um pequeno teste de scraping toda semana para detectar quebras cedo — o Glassdoor faz deploy de mudanças no front-end sem aviso.
Use o caminho rápido com __NEXT_DATA__ quando possível
O Glassdoor é uma aplicação Next.js + Apollo GraphQL. Muitas páginas trazem uma tag <script id="__NEXT_DATA__"> com o cache completo do GraphQL em JSON. Analisar isso é muito mais resistente do que raspar o DOM e :
1import json
2def extract_next_data(html):
3 sel = Selector(text=html)
4 raw = sel.css("script#__NEXT_DATA__::text").get()
5 if raw:
6 return json.loads(raw)["props"]["pageProps"].get("apolloCache", {})
7 return NoneIsso retorna o cache estruturado do Apollo com todos os campos de vagas, avaliações e salários — sem precisar de seletores CSS. É a estratégia de extração mais resiliente disponível, já que usa os mesmos dados que alimentam o front-end React do Glassdoor.
Pule o código: raspe o Glassdoor com Thunderbit (sem precisar de Python)
Nem todo mundo que lê este guia é desenvolvedor. Times de RH, recrutadores, analistas de operações comerciais e pesquisadores de mercado também precisam dos dados do Glassdoor — e não deveriam ter que administrar contextos do Playwright e rotação de proxies para isso.
é uma extensão de Chrome de AI Web Scraper que extrai os mesmos dados de vagas, avaliações e salários sem escrever uma linha de código. Eu trabalho na equipe do Thunderbit, então já deixo isso transparente — mas o motivo de estar incluindo a ferramenta aqui é simples: ela resolve, de forma real, os dois maiores problemas do scraping do Glassdoor.
Como o Thunderbit funciona no Glassdoor
O fluxo é de dois cliques:
- Abra qualquer página do Glassdoor no Chrome (busca de vagas, avaliações da empresa, página de salários)
- Clique em AI Suggest Fields na barra lateral do Thunderbit — a IA lê o DOM da página e sugere colunas (cargo, empresa, nota, faixa salarial, prós, contras etc.)
- Clique em Scrape — os dados são extraídos para uma tabela sem seletores CSS nem código de automação de navegador
O Thunderbit tem um que extrai mais de 23 campos por empresa em uma única execução. Para vagas, avaliações ou salários, o fluxo genérico de AI Suggest Fields atende qualquer URL do Glassdoor.
Como lidar com a barreira de login sem código
Essa é a vantagem estrutural do Thunderbit especificamente para o Glassdoor. O Browser Mode roda dentro da sua própria sessão do Chrome — se você já estiver logado no Glassdoor no Chrome, o Thunderbit herda esses cookies automaticamente. A barreira de login que bloqueia scrapers no servidor simplesmente deixa de ser um problema. Nada de gerenciar cookies, contextos persistentes ou código de sessão.
Scraping de subpáginas para enriquecimento
Comece por uma lista (por exemplo, 30 empresas vindas de uma busca), deixe o Thunderbit enumerar as linhas e depois ative o para visitar a página de avaliações ou salários de cada empresa e enriquecer a tabela com descrições completas, texto de avaliações ou detalhes salariais.
Exportar para ferramentas de negócio
Ao contrário de scripts Python que geram CSV ou JSON, o Thunderbit exporta diretamente para Google Sheets, Airtable, Notion ou Excel — grátis em todos os planos. Isso é especialmente útil para times que precisam compartilhar e analisar dados em conjunto.
Python vs. Thunderbit: quando usar cada um
| Cenário | Abordagem recomendada |
|---|---|
| Construir um pipeline recorrente de dados | Python + Patchright |
| Pesquisa pontual ou projeto pequeno de equipe | Thunderbit |
| Precisa de controle programático sobre cada campo | Python |
| Não é desenvolvedor, mas precisa dos dados do Glassdoor hoje | Thunderbit |
| Raspar mais de 1.000 páginas em uma única execução | Python + proxies |
| Raspar 30 empresas com enriquecimento | Ambos funcionam — Thunderbit é mais rápido para configurar |
O preço do Thunderbit começa no plano gratuito (6 páginas/mês), com o para 3.000 créditos. Com 1 crédito por linha de saída (2 créditos para scraping de subpágina), isso dá cerca de 33 execuções de 30 empresas enriquecidas por mês.
É legal raspar o Glassdoor?
Vou ser breve e objetivo. Os do Glassdoor proíbem explicitamente scraping automatizado: "You may not use any robot, spider, scraper... to access the Services for any purpose without our express written permission."
Mas o cenário jurídico é mais nuanceado do que uma única cláusula de ToS:
- (N.D. Cal., jan. 2024): o tribunal entendeu que, se você nunca faz login, você nunca concordou com os Termos de Serviço, e o scraping de conteúdo público sem login não viola esse acordo
- hiQ Labs v. LinkedIn (9ª Circuito): a CFAA não se aplica à coleta automatizada de dados publicamente acessíveis — mas contas falsas e scraping com login são outra história
- Van Buren v. United States (Suprema Corte, 2021): restringiu o conceito de "exceeds authorized access" sob a CFAA
A conclusão prática: raspar vagas públicas sem fazer login fica em uma zona legal comparativamente mais segura. Já raspar com uma sessão autenticada significa que você aceitou os Termos de Serviço no cadastro, e eles proíbem isso explicitamente. Isso vale tanto para scripts Python quanto para o Browser Mode do Thunderbit.
Boas práticas éticas que valem independentemente da abordagem:
- Limite a taxa bem abaixo da velocidade humana de navegação
- Não raspe nem revenda informações pessoais identificáveis de avaliadores
- Respeite as diretrizes do robots.txt
- Extraia apenas os campos de que você realmente precisa
Conclusão: qual método é certo para você?
Este guia cobriu os três tipos de dados do Glassdoor — vagas, avaliações e salários — com código funcional de 2025 que leva em conta a migração para o Indeed Login, o Cloudflare Bot Management e a rotação de nomes de classes CSS modules que quebrou todos os tutoriais antigos.
Aqui está o framework de decisão:
| Sua situação | Melhor caminho |
|---|---|
| Desenvolvedor montando um pipeline de dados | Python + Patchright (siga o passo a passo acima) |
| Pesquisa pontual ou coletas pequenas recorrentes | Thunderbit (sem código, baseado no navegador) |
| Só precisa de vagas básicas em pequena escala | Verifique primeiro se o acesso à API do Glassdoor ainda existe (provavelmente não) |
| Precisa especificamente de dados salariais ou de avaliações | Tem que usar scraping com Python ou Thunderbit — a API nunca cobriu isso |
| Equipe sem desenvolvedores que precisa compartilhar dados | Thunderbit → exportar para Google Sheets |
As defesas do Glassdoor continuarão evoluindo. Os seletores vão quebrar. Novos desafios vão surgir. Salve este guia nos favoritos — e, se quiser um olhar mais profundo sobre ferramentas e técnicas de web scraping, confira nossos posts sobre , e . Você também pode assistir a tutoriais no .
Perguntas frequentes
1. Dá para raspar o Glassdoor sem fazer login?
Sim, para a maioria dos dados de vagas e para as notas gerais das empresas. Não, para detalhamento completo de salários ou texto integral de avaliações além das primeiras páginas. O #HardsellOverlay é um modal apenas em CSS — o HTML subjacente ainda contém os dados da primeira página — mas conteúdos mais profundos ficam protegidos no servidor pela parede de "give-to-get" do Glassdoor.
2. Qual biblioteca Python funciona melhor para raspar o Glassdoor em 2025?
Patchright (um fork furtivo do Playwright) é a recomendação padrão. Ele corrige o vazamento Runtime.Enable CDP que existe no Playwright puro e que a Cloudflare verifica explicitamente. Para páginas de listagem que trazem __NEXT_DATA__ no HTML inicial, curl_cffi com impersonate="chrome124" é 10–20x mais rápido, mas não lida com páginas protegidas por login.
3. Como evitar bloqueio ao raspar o Glassdoor?
Use Patchright ou rebrowser-playwright (não o Playwright puro nem Selenium). Alterne proxies residenciais — IPs de datacenter são desafiados quase imediatamente. Adicione atrasos aleatórios de 3–8 segundos entre páginas. Persista cookies (gdId, cf_clearance, GSESSIONID) entre requisições. Espere uma janela de sessão de 20–30 minutos antes de ser desafiado novamente.
4. Existe uma API do Glassdoor que eu possa usar em vez de scraping?
Na prática, não. A antiga Partner API está , nunca existiu um endpoint público de avaliações, e não há caminho de migração dentro da Publisher API do Indeed. Scraping ou uma ferramenta sem código como o Thunderbit são as únicas opções práticas para avaliações e dados salariais.
5. Com que frequência os scrapers do Glassdoor quebram?
Frequentemente. O Glassdoor faz deploy de mudanças no front-end sem aviso, e os hashes dos nomes das classes CSS modules mudam a cada build. As estratégias mais estáveis são: (1) seletores de atributo data-test, (2) o blob JSON __NEXT_DATA__ e (3) o endpoint interno BFF de avaliações. Inclua uma checagem de zero resultados e rode um pequeno teste semanal para identificar quebras cedo.
Saiba mais