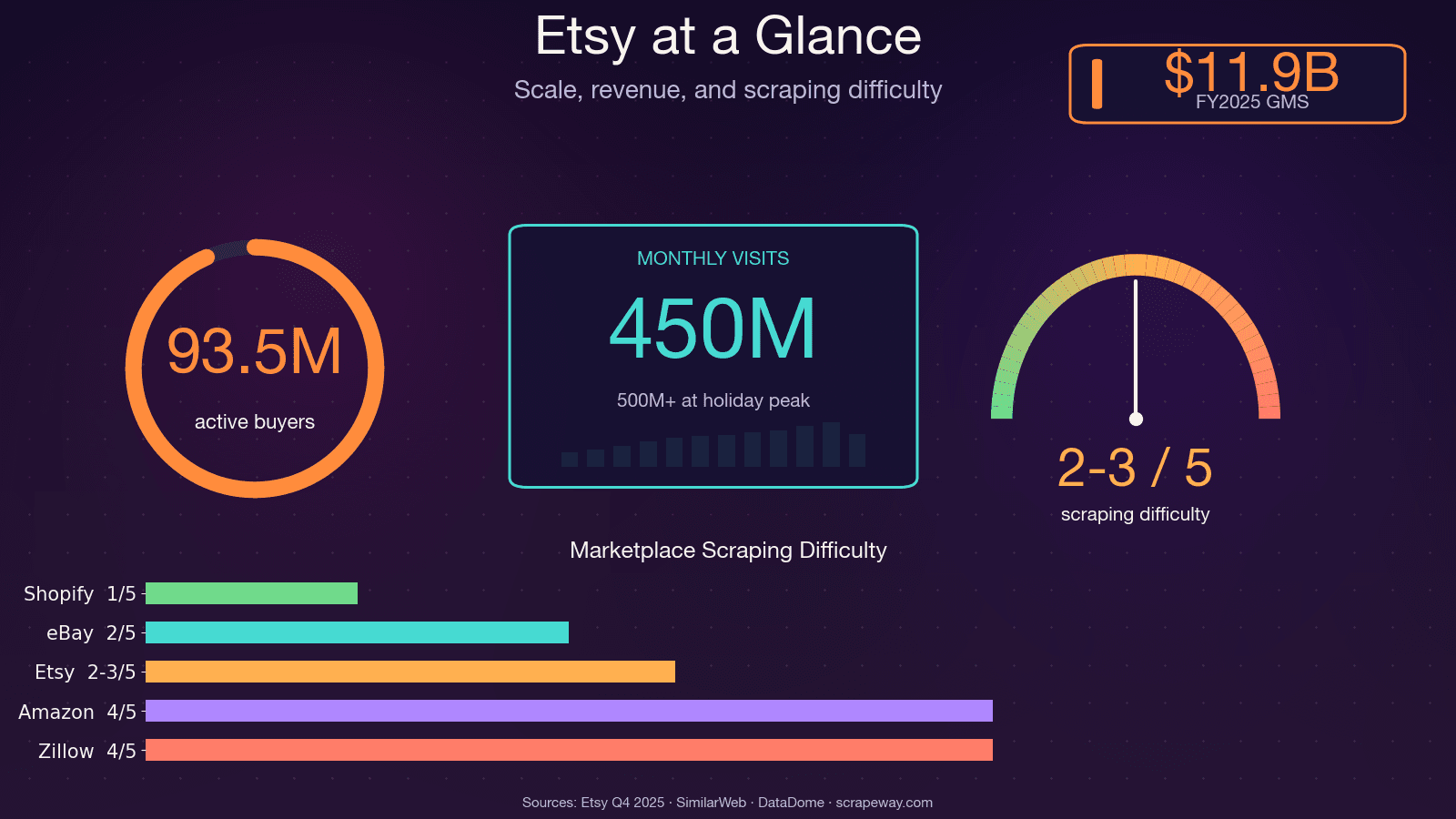
A Etsy tem mais de 100 milhões de anúncios ativos, 5,6 milhões de vendedores e cerca de 450 milhões de visitas mensais. É muita informação pública sobre preços, tendências, avaliações e concorrentes — e, se você já tentou reunir isso manualmente, sabe bem o quanto isso cansa.
Uma vez, passei um fim de semana tentando catalogar manualmente produtos de concorrentes para um projeto de pesquisa de mercado. No produto número 30, eu já estava questionando todas as decisões de vida que me levaram até aquela planilha. A verdade é que os dados da Etsy são incrivelmente valiosos para análise de preços, desenvolvimento de produto, descoberta de nichos e benchmarking de vendedores — mas só se você conseguir obtê-los em escala. É disso que trata este guia: um tutorial completo que mostra como raspar a Etsy com Python nos quatro principais tipos de página (resultados de busca, páginas de produto, páginas de loja e avaliações), além de orientações honestas sobre as defesas anti-bot da Etsy e uma alternativa sem código para quem prefere fugir da programação de vez.
O que significa raspar a Etsy com Python?
Web scraping, em termos simples, significa escrever código que visita páginas da web e extrai automaticamente os dados que você quer — nomes de produtos, preços, descrições, imagens, avaliações, detalhes da loja — e organiza tudo em um formato estruturado, como uma planilha ou banco de dados.
Python é a linguagem mais usada para esse tipo de trabalho. É amigável para iniciantes, tem uma comunidade enorme e oferece um ecossistema de bibliotecas muito forte para scraping: Requests (para buscar páginas), BeautifulSoup (para fazer o parse de HTML), Selenium e Playwright (para automação de navegador) e pandas (para organizar e exportar dados). O Python aparece com consistência entre as 3 linguagens mais populares na pesquisa anual de desenvolvedores do Stack Overflow, e suas bibliotecas de scraping estão entre as mais baixadas no PyPI.
Quando você raspa a Etsy, está puxando dados do HTML (e, às vezes, de JSON oculto) que a Etsy entrega ao seu navegador. Os tipos de dados que você pode extrair incluem:
- Nomes de produtos, preços, descrições, imagens e variações
- Informações do vendedor/loja (nome, número de vendas, localização, avaliação)
- Avaliações e texto completo dos comentários
- Listagens de resultados de busca, categorias e sinais de tendência
Por que raspar a Etsy? Casos reais que geram ROI
Raspar a Etsy não é só um exercício técnico — é uma vantagem competitiva. Seja você vendedor, gerente de produto ou analista de dados, ter dados estruturados da Etsy à mão pode impactar diretamente o resultado do negócio.
| Caso de uso | O que você raspa | Quem se beneficia | Impacto no negócio |
|---|---|---|---|
| Análise competitiva de preços | Resultados de busca + preços dos produtos | Operações de e-commerce, vendedores | Preço dinâmico pode aumentar a receita em média em 5–22% |
| Descoberta de nichos e tendências | Resultados de busca, listagens em alta | Fundadores, analistas | Identifique nichos em alta cedo (por exemplo, "preppy pajamas" teve crescimento de busca de +1.112%) |
| Desenvolvimento e melhoria de produto | Avaliações, detalhes do produto | Times de produto | Uma marca de utensílios de cozinha recuperou o posto de #1 Best Seller em 60 dias usando dados de sentimento das avaliações |
| SEO e pesquisa de palavras-chave | Resultados de busca, títulos/tags de produtos | Times de marketing | Identifique palavras-chave com alta demanda e baixa concorrência |
| Benchmarking de vendedores | Páginas de loja, contagem de vendas | Times de vendas, analistas | Monte listas de leads qualificados a US$ 0,01–0,10 por registro, contra listas compradas |
| Monitoramento de estoque | Disponibilidade de produtos | Operações de e-commerce | Reaja mais rápido a mudanças de estoque dos concorrentes |
Cada um desses casos de uso exige dados de diferentes tipos de página da Etsy — e é exatamente por isso que este tutorial cobre todos os quatro.
Economia de tempo: manual vs. automatizado
- Pesquisa manual na Etsy: 30–45 minutos por produto (50–75 horas para 100 produtos)
- Scraping automatizado: 100 anúncios em 2–5 minutos
- Scraping com IA é e pode chegar a 99,5% de precisão
API da Etsy vs. web scraping: qual escolher?
Antes de escrever uma única linha de código, vale perguntar: devo usar a API oficial da Etsy ou raspar o site diretamente? Essa é uma dúvida que aparece o tempo todo em fóruns, e a resposta depende dos dados de que você precisa.
O que a API da Etsy consegue e não consegue fazer
A Etsy oferece uma API v3 com autenticação OAuth 2.0. Ela funciona para acessar os dados da sua própria loja — anúncios, pedidos, recibos. Mas tem limitações reais:
- Dados de concorrentes: a API é, em grande parte, restrita à sua própria loja. Você não consegue puxar preços, vendas ou anúncios de outro vendedor.
- Avaliações: não existe um endpoint robusto para texto completo de avaliações em volume.
- Limites de taxa: por padrão, 10 requisições por segundo e 10.000 requisições por dia. O teto de offset é de 12.000 registros.
- Uso de IA/ML: é explicitamente rejeitado na análise do app.
- Documentação: as reclamações da comunidade são frequentes — exemplos ruins, endpoints descontinuados e suporte lento.
Quando web scraping é o melhor caminho
Se você precisa de inteligência competitiva, sentimento das avaliações, análise entre lojas ou dados além do que a API expõe, raspar é o caminho. A desvantagem: você vai enfrentar as defesas anti-bot da Etsy (mais sobre isso abaixo) e precisará investir em configuração.
Tabela comparativa: API vs. scraping vs. no-code
| Critério | API oficial da Etsy | Web scraping com Python | Thunderbit (sem código) |
|---|---|---|---|
| Acesso aos preços dos produtos | ✅ (campos limitados) | ✅ HTML/JSON-LD completo | ✅ IA extrai qualquer campo visível |
| Dados de avaliações | ❌ Não disponível em volume | ✅ Via endpoint/HTML de avaliações | ✅ Scraping de subpáginas |
| Dados da loja concorrente | ❌ Apenas sua própria loja | ✅ Qualquer loja pública | ✅ Qualquer loja pública |
| Autenticação necessária | ✅ OAuth 2.0 | ⚠️ Cookies para dados logados | ⚠️ Scraping no navegador para login |
| Risco anti-bot | Nenhum | ALTO (DataDome) | Tratado (nativo do navegador) |
| Tempo de configuração | Médio (chaves de API, OAuth) | Alto (código + proxies) | ~2 minutos |
Se você precisa de dados de concorrentes, avaliações ou análise entre lojas, a API simplesmente não cobre isso. É o diagnóstico honesto.
Escolha sua abordagem de scraping em Python antes de escrever qualquer linha de código
Uma pergunta que aparece o tempo todo no Reddit e no Stack Overflow: "Devo usar Requests + BeautifulSoup, Selenium, uma API de proxy ou outra coisa?" A resposta certa depende do seu nível, orçamento e caso de uso.
| Abordagem | Melhor para | Curva de aprendizado | Lida com JS? | Tratamento anti-bot | Custo |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | Desenvolvedores que querem controle total | Média | ❌ | Manual (headers, proxies) | Grátis + custo de proxy |
| Selenium / Playwright | Páginas pesadas em JS, fluxos de login | Alta | ✅ | Parcial (fingerprint do navegador) | Grátis + custo de proxy |
| Serviços de API de proxy | Escala + bypass anti-bot | Média | ✅ (via API) | ✅ Nativo | A partir de US$ 49/mês |
| Thunderbit (sem código) | Não desenvolvedores, extração rápida | Muito baixa | ✅ (nativo do navegador) | ✅ (sessão do navegador) | Plano gratuito disponível |
Se você quer controle total e se sente confortável com Python, vá de Requests + BeautifulSoup. Se precisa de renderização em JS ou fluxos de login, use Selenium. Se quer bypass anti-bot em escala, considere um serviço de proxy. E se você quer dados da Etsy sem escrever ou manter código, vale conhecer o Thunderbit — já já eu explico mais.
Como a Etsy reage: entendendo a proteção anti-bot do DataDome
A maioria dos guias de scraping vai dizer "basta usar um proxy" e seguir em frente. Isso não é suficiente para a Etsy. A Etsy usa o DataDome, um dos sistemas anti-bot mais agressivos da web. Um destaca a Etsy como caso de sucesso, observando que scrapers já representaram cerca de 1% dos custos computacionais da Etsy.
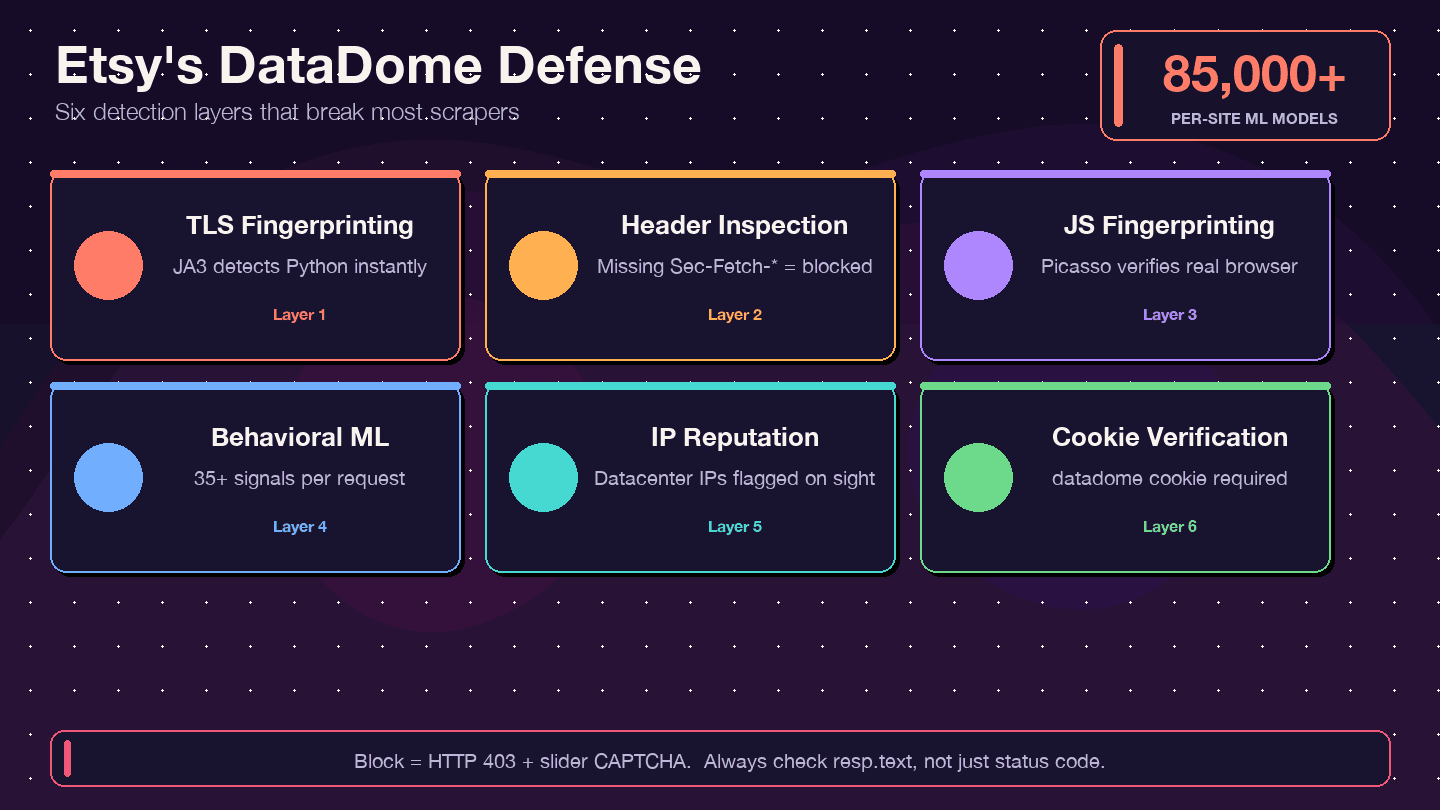
O que é o DataDome e como ele funciona?
O DataDome não verifica apenas seu endereço IP. Ele usa uma pilha de detecção em várias camadas:
- Fingerprint de TLS (JA3): a biblioteca
requestsdo Python tem uma assinatura TLS distinta que o DataDome identifica na hora. - Inspeção de headers/protocolo HTTP: verifica se os headers do navegador estão completos e coerentes — headers faltando ou fora de ordem são sinal de alerta.
- Fingerprint de JavaScript (protocolo Picasso): executa desafios em JS no navegador para confirmar que você é um usuário real.
- ML comportamental: analisa mais de 35 sinais por requisição, com mais de 85.000 modelos por site.
- Pontuação de reputação de IP: IPs de datacenter são sinalizados imediatamente.
- Verificação de cookies: o cookie
datadomeprecisa estar presente e válido.
Sinais de que você foi bloqueado (e como verificar)
Um dos problemas mais comuns: você recebe uma resposta 200 OK, mas o HTML na verdade é uma página de CAPTCHA, e não os dados que queria. Outros sinais:
- Erros 403 Forbidden
- Loops de redirecionamento
- O corpo da resposta contém um objeto JavaScript
ddou HTML de CAPTCHA com slider
Sempre inspecione o corpo da resposta, não só o código de status. Um teste rápido:
1if "captcha" in resp.text.lower() or "datadome" in resp.text.lower():
2 print("Bloqueado! Recebemos uma página de CAPTCHA em vez dos dados.")Headers e cookies que reduzem a detecção
Você não pode garantir que nunca será bloqueado, mas headers realistas e bom gerenciamento de cookies ajudam bastante:
1session = requests.Session()
2session.headers.update({
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/133.0.0.0 Safari/537.36",
4 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
5 "Accept-Language": "en-US,en;q=0.9",
6 "Accept-Encoding": "gzip, deflate, br",
7 "Sec-Ch-Ua": '"Chromium";v="133", "Not-A.Brand";v="99", "Google Chrome";v="133"',
8 "Sec-Ch-Ua-Mobile": "?0",
9 "Sec-Ch-Ua-Platform": '"Windows"',
10 "Sec-Fetch-Dest": "document",
11 "Sec-Fetch-Mode": "navigate",
12 "Sec-Fetch-Site": "none",
13 "Upgrade-Insecure-Requests": "1",
14})Também é importante:
- Persistir cookies entre requisições usando
requests.Session(). - Adicionar atrasos aleatórios (2–7 segundos) entre requisições.
- Simular uma cadeia de referenciadores: visite a homepage primeiro, depois a busca, depois as páginas de produto.
- Em escala, a rotação de proxies residenciais é essencial. IPs de datacenter são sinalizados quase instantaneamente.
Essas técnicas reduzem a detecção, mas não a eliminam. Para scraping de alto volume, você provavelmente vai precisar de um serviço de proxy ou de uma abordagem baseada em navegador.
Configurando seu ambiente Python para raspar a Etsy
Antes de começar:
- Dificuldade: intermediária
- Tempo necessário: ~30–60 minutos (configuração + primeiro scraping)
- O que você vai precisar: Python 3.8+, pip, um editor de código, navegador Chrome (para inspeção no DevTools)
Instale as dependências
Crie uma pasta de projeto, configure um ambiente virtual e instale as bibliotecas que você vai usar:
1mkdir etsy-scraper && cd etsy-scraper
2python -m venv venv
3source venv/bin/activate # No Windows: venv\Scripts\activate
4pip install requests beautifulsoup4 lxml pandas- requests — busca páginas da web
- beautifulsoup4 — faz parse de HTML
- lxml — parser de HTML mais rápido (opcional, mas recomendado)
- pandas — estrutura e exporta dados para CSV/Excel
Se você precisar de automação de navegador depois (para login ou páginas com muito JS), instale também:
1pip install seleniumEntenda a estrutura da página da Etsy antes de programar
Aqui vai uma dica que economiza muito tempo: a Etsy embute dados estruturados de produto dentro de tags <script type="application/ld+json"> na maioria das páginas. Esses dados em JSON-LD já vêm organizados — nome do produto, preço, avaliação, imagens — então você não precisa brigar com seletores CSS frágeis para cada campo.
Abra qualquer página de produto da Etsy, clique com o botão direito em "Exibir código-fonte da página" e procure por application/ld+json. Você vai encontrar um bloco com @type: Product contendo a maior parte dos dados de que precisa. As páginas de resultados de busca têm @type: ItemList.
Seletores CSS ainda são úteis como fallback (para dados que não estão em JSON-LD, como detalhes de frete ou texto de avaliação), mas o JSON-LD deve ser seu primeiro ponto de apoio.
Etapa 1: raspe os resultados de busca da Etsy com Python
Os resultados de busca são o ponto de partida da maioria dos projetos de scraping da Etsy — seja para monitorar um nicho, acompanhar preços dos concorrentes ou montar um banco de dados de produtos.
Monte a URL de busca
As URLs de busca da Etsy seguem este padrão:
1https://www.etsy.com/search?q=\{keyword\}&ref=pagination&page=\{page_number\}Para consultas com várias palavras, faça URL-encoding dos espaços (por exemplo, handmade+jewelry ou handmade%20jewelry). O parâmetro ref=pagination faz a requisição parecer mais com uma navegação real de navegador.
Outros parâmetros úteis: order (most_relevant, price_asc, price_desc, date_desc), min_price, max_price, ship_to, free_shipping=true. Cada página retorna 48 itens.
Envie a requisição e faça o parse do HTML
1import requests
2from bs4 import BeautifulSoup
3import json
4import time
5import random
6headers = {
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
10}
11def scrape_etsy_search(query, max_pages=3):
12 all_products = []
13 for page in range(1, max_pages + 1):
14 url = f"https://www.etsy.com/search?q=\{query\}&ref=pagination&page=\{page\}"
15 resp = requests.get(url, headers=headers, timeout=30)
16 if "captcha" in resp.text.lower():
17 print(f"Bloqueado na página \{page\}. Tente adicionar atrasos ou proxies.")
18 break
19 soup = BeautifulSoup(resp.text, "lxml")
20 for script in soup.find_all("script", type="application/ld+json"):
21 data = json.loads(script.string)
22 if data.get("@type") == "ItemList":
23 for item in data.get("itemListElement", []):
24 all_products.append({
25 "name": item.get("name"),
26 "url": item.get("url"),
27 "image": item.get("image"),
28 "price": item.get("offers", {}).get("price"),
29 "currency": item.get("offers", {}).get("priceCurrency"),
30 "position": item.get("position"),
31 })
32 time.sleep(random.uniform(2, 5))
33 return all_productsExtraia os dados das listagens do JSON-LD
O array itemListElement fornece o nome, a URL, a imagem, o preço e a moeda de cada anúncio. Se você também precisar das avaliações em estrelas ou da contagem de resultados (que nem sempre estão no JSON-LD), use seletores CSS como fallback:
- Card da listagem:
.v2-listing-card - Título:
h3.v2-listing-card__title - Preço:
span.currency-value - Link:
a.listing-link(href)
Lide com paginação
Percorra as páginas e adicione um atraso aleatório entre cada requisição. A Etsy geralmente retorna até 20–250 páginas, dependendo da consulta.
1results = scrape_etsy_search("handmade+jewelry", max_pages=5)
2print(f"Foram raspados {len(results)} produtos.")Para um scraping de 5 páginas, isso levou cerca de 20 segundos nos meus testes — em comparação com mais de 30 minutos de copiar e colar manualmente.
Etapa 2: raspe páginas de produto da Etsy com Python
Depois de obter uma lista de URLs de produtos a partir da busca, o próximo passo é coletar dados detalhados de cada página de anúncio.
Busque a página do produto
1def scrape_etsy_product(url):
2 resp = requests.get(url, headers=headers, timeout=30)
3 soup = BeautifulSoup(resp.text, "lxml")
4 for script in soup.find_all("script", type="application/ld+json"):
5 data = json.loads(script.string)
6 if data.get("@type") == "Product":
7 offers = data.get("offers", {})
8 price = offers.get("price") or offers.get("lowPrice")
9 rating_data = data.get("aggregateRating", {})
10 return {
11 "name": data.get("name"),
12 "description": data.get("description", "")[:500],
13 "brand": data.get("brand", {}).get("name") if isinstance(data.get("brand"), dict) else data.get("brand"),
14 "category": data.get("category"),
15 "price": price,
16 "currency": offers.get("priceCurrency"),
17 "availability": offers.get("availability"),
18 "rating": rating_data.get("ratingValue"),
19 "review_count": rating_data.get("reviewCount"),
20 "images": data.get("image", []),
21 "sku": data.get("sku"),
22 "material": data.get("material"),
23 }
24 return NoneLide com variações de preço
Alguns produtos têm um único offers.price. Outros (com variações como tamanho ou cor) usam offers.lowPrice e offers.highPrice. O código acima trata os dois casos ao cair de price para lowPrice.
Extraia campos adicionais com seletores CSS
Para dados que não estão em JSON-LD — informações de frete, opções de variação, detalhes completos do vendedor — você vai precisar de seletores CSS:
- Título:
h1[data-buy-box-listing-title] - Variações:
select[data-selector-id]oudiv[data-option-set] - Frete:
div.wt-text-captionperto da seção de frete
A troca é esta: JSON-LD é mais limpo e mais estável entre mudanças de layout. Seletores CSS são frágeis, mas cobrem mais campos.
Etapa 3: raspe páginas de lojas da Etsy com Python
Esta é a seção que a maioria dos guias concorrentes pula completamente — e talvez seja a mais valiosa para times de vendas e analistas competitivos.
Monte a URL da loja e busque a página
1def scrape_etsy_shop(shop_name):
2 url = f"https://www.etsy.com/shop/\{shop_name\}"
3 resp = requests.get(url, headers=headers, timeout=30)
4 soup = BeautifulSoup(resp.text, "lxml")
5 # Metadados da loja vindos do HTML (não estão no JSON-LD)
6 sales_el = soup.select_one("div.shop-sales-reviews a")
7 rating_el = soup.find("input", {"name": "initial-rating"})
8 location_el = soup.select_one("div.shop-location")
9 shop_data = {
10 "name": shop_name,
11 "sales": sales_el.text.strip() if sales_el else None,
12 "rating": rating_el["value"] if rating_el else None,
13 "location": location_el.text.strip() if location_el else None,
14 }
15 # Listagens do JSON-LD
16 listings = []
17 for script in soup.find_all("script", type="application/ld+json"):
18 data = json.loads(script.string)
19 if data.get("@type") == "ItemList":
20 for item in data.get("itemListElement", []):
21 listings.append({
22 "name": item.get("name"),
23 "url": item.get("url"),
24 "price": item.get("offers", {}).get("price"),
25 })
26 shop_data["listings"] = listings
27 return shop_dataO que você pode extrair das páginas de loja
O JSON-LD nas páginas de loja é @type: ItemList — ele cobre as listagens de produtos, mas não metadados de nível de loja, como número de vendas, localização ou avaliação. Para isso, você precisa de seletores CSS:
| Ponto de dados | Seletor | Observações |
|---|---|---|
| Nome da loja | h1 ou meta title | Normalmente no título da página |
| Total de vendas | div.shop-sales-reviews a | Texto como "12.345 vendas" |
| Avaliação em estrelas | valor de input[name="initial-rating"] | Numérico de 1 a 5 |
| Localização | div.shop-location | Cidade, país |
| Membro desde | div.shop-info | Texto com a data |
Dados de loja são especialmente valiosos para montar listas de leads, fazer benchmarking de concorrentes ou identificar os vendedores mais fortes em um nicho.
Etapa 4: raspe avaliações da Etsy com Python
As avaliações estão entre os dados mais valiosos — e mais complicados — da Etsy. O texto completo, as notas e as datas não aparecem no HTML inicial da página; eles carregam por meio de um endpoint interno de API.
Abordagem 1: descubra o endpoint interno de avaliações da Etsy
Abra uma página de produto no Chrome, abra o DevTools (F12), vá até a aba Network e role até a seção de avaliações. Você verá uma requisição POST para algo como:
1https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviewsEsse endpoint retorna fragmentos de HTML contendo os cards de avaliação. Para usá-lo, você precisa de:
- listing_id — o ID numérico da URL do produto
- shop_id — extraído do HTML da página do produto usando regex
- csrf_nonce — extraído de uma tag
<meta>da página
Extraia os IDs e o token CSRF
1import re
2def get_review_params(product_url):
3 resp = requests.get(product_url, headers=headers)
4 html = resp.text
5 listing_id = product_url.split("/")[-1].split("?")[0]
6 shop_id_match = re.search(r'"shopId"\s*:\s*(\d+)', html)
7 shop_id = shop_id_match.group(1) if shop_id_match else None
8 soup = BeautifulSoup(html, "lxml")
9 csrf_meta = soup.find("meta", {"name": "csrf_nonce"})
10 csrf = csrf_meta["content"] if csrf_meta else None
11 return listing_id, shop_id, csrfRaspe avaliações com paginação
1def scrape_reviews(listing_id, shop_id, csrf, max_pages=5):
2 session = requests.Session()
3 session.headers.update(headers)
4 all_reviews = []
5 for page in range(1, max_pages + 1):
6 payload = {
7 "specs": {
8 "deep_dive_reviews": {
9 "module_path": "neu/specs/deep_dive_reviews",
10 "listing_id": listing_id,
11 "shop_id": shop_id,
12 "page": page,
13 }
14 }
15 }
16 resp = session.post(
17 "https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews",
18 json=payload,
19 headers={"x-csrf-token": csrf, "Content-Type": "application/json"},
20 )
21 data = resp.json()
22 html_fragment = data.get("output", {}).get("deep_dive_reviews", "")
23 review_soup = BeautifulSoup(html_fragment, "lxml")
24 for card in review_soup.select("div.review-card"):
25 rating_el = card.find("input", {"name": "rating"})
26 text_el = card.select_one("div.wt-text-body")
27 user_el = card.select_one("a[data-review-username]")
28 date_el = card.select_one("p.wt-text-body-small")
29 all_reviews.append({
30 "rating": rating_el["value"] if rating_el else None,
31 "text": text_el.text.strip() if text_el else None,
32 "reviewer": user_el.text.strip() if user_el else None,
33 "date": date_el.text.strip() if date_el else None,
34 })
35 time.sleep(random.uniform(2, 5))
36 return all_reviewsAbordagem 2: parsear avaliações do HTML (fallback)
Se a abordagem via API falhar (por exemplo, por problemas com o token CSRF), você pode analisar a primeira página de avaliações diretamente no HTML da página do produto. A limitação: apenas o primeiro lote de avaliações está no HTML estático. Para mais, você precisa da API ou de uma ferramenta de automação de navegador como o Selenium.
Como lidar com dados que exigem login: raspando sua própria loja na Etsy
Esta é uma lacuna que nenhum outro tutorial cobre, mas é uma necessidade real — especialmente para vendedores da Etsy que querem extrair seus próprios pedidos, receita e estatísticas.
O problema: só o requests não consegue acessar o painel da Etsy porque ele não carrega os cookies da sua sessão de login.
Opção 1: Selenium com login manual e captura de cookies
Use o Selenium para abrir um navegador, fazer login manualmente (ou automatizar o login) e depois continuar raspando enquanto estiver autenticado:
1from selenium import webdriver
2driver = webdriver.Chrome()
3driver.get("https://www.etsy.com/signin")
4# Faça login manualmente na janela do navegador e então:
5input("Pressione Enter depois de fazer login...")
6cookies = driver.get_cookies()
7# Agora use driver.get() para navegar até as páginas do painel e rasparVocê também pode salvar os cookies da sessão do Selenium e reutilizá-los com requests.Session() para um scraping mais rápido e leve depois do login inicial.
Opção 2: exportar cookies do navegador para usar com Requests
Use uma extensão de navegador (como "EditThisCookie") para exportar os cookies ativos da sua sessão Etsy e depois carregá-los em uma sessão Requests:
1import requests
2session = requests.Session()
3# Adicione cookies exportados do seu navegador
4session.cookies.set("uaid", "YOUR_UAID_VALUE", domain=".etsy.com")
5session.cookies.set("user_prefs", "YOUR_USER_PREFS_VALUE", domain=".etsy.com")
6# ... adicione outros cookies de sessão conforme necessário
7resp = session.get("https://www.etsy.com/your/orders", headers=headers)O caminho fácil: o modo de scraping no navegador do Thunderbit
Como o roda dentro do seu navegador Chrome, ele herda automaticamente sua sessão ativa da Etsy. Sem código de autenticação, sem exportar cookies — basta navegar até o painel da Etsy e raspar. Isso é realmente útil para extrair pedidos, receita, estatísticas e outros dados exclusivos de vendedor, sem escrever nenhum script.
Exportando e usando seus dados raspados da Etsy
Salve em CSV ou JSON
1import pandas as pd
2df = pd.DataFrame(results)
3df.to_csv("etsy_products.csv", index=False, encoding="utf-8")
4df.to_json("etsy_products.json", orient="records", indent=2)Boas práticas: inclua timestamps nos nomes de arquivo, use codificação UTF-8 e trate caracteres especiais nos nomes dos produtos (os vendedores da Etsy adoram emojis e caracteres acentuados).
Exporte para Google Sheets, Airtable ou Notion
Para usuários de Python, bibliotecas como gspread (Google Sheets) ou a API do Airtable permitem enviar dados programaticamente. Mas, se você estiver usando o , todas as exportações — para Google Sheets, Excel, Airtable e Notion — são gratuitas e feitas com um clique. Sem chaves de API, sem configuração de OAuth.
Pule o código: como raspar a Etsy com o Thunderbit (alternativa sem código)
Nem todo mundo quer escrever scripts em Python, manter configurações de proxy ou depurar seletores CSS às 2h da manhã. Se esse é o seu caso, veja como obter dados da Etsy com o .
Instale a extensão do Thunderbit para Chrome
Acesse a e instale o Thunderbit. Crie uma conta gratuita — o plano grátis dá e todas as exportações são gratuitas.
Use o recurso de sugestão de campos por IA em qualquer página da Etsy
Navegue até uma página de busca, produto ou loja da Etsy. Clique em "AI Suggest Fields" na barra lateral do Thunderbit. A IA analisa a página e recomenda colunas — nome do produto, preço, avaliação, imagens, nome da loja, tags, informação de frete. Ajuste ou adicione colunas conforme necessário.
Clique em raspar e exportar
Clique em "Scrape" para extrair os dados da página atual. Para resultados em várias páginas, use o scraping de paginação do Thunderbit. Para enriquecer uma lista de URLs de produtos com detalhes de cada página (descrições, avaliações, frete), use o scraping de subpáginas — o Thunderbit visita cada link e puxa os dados extras automaticamente.
Exporte para Excel, Google Sheets, Airtable ou Notion — tudo grátis.
Quando o Thunderbit supera o Python para raspar a Etsy
- Sem configuração de proxy nem código anti-bot. O Thunderbit roda no seu navegador Chrome real, então herda sua sessão e parece um usuário normal para o DataDome.
- A IA se adapta automaticamente a mudanças de layout. Nada de seletores quebrados para consertar quando a Etsy atualiza o front-end.
- Ótimo para pesquisas pontuais, análise competitiva ou membros não técnicos do time. Se você só precisa de um conjunto rápido de dados, não precisa de ambiente Python.
- O scraping de subpáginas permite enriquecer uma lista de URLs de produtos com dados detalhados sem escrever loops aninhados.
Para um passo a passo, confira o .
Comparação de custo em 6 meses: Python vs. Thunderbit
| Fator | Python por conta própria | Thunderbit |
|---|---|---|
| Tempo de configuração | 8–20 horas | Menos de 5 minutos |
| Custo em 6 meses (incl. mão de obra, proxies) | US$ 2.720–9.450 | US$ 90–228 |
| Manutenção mensal | 4–10+ horas (atualizações de seletores = 80%+ de overhead) | 0–1 hora |
| Tratamento anti-bot | Proxies residenciais com custo 85x maior que créditos normais | Baseado no navegador, contorna o DataDome nativamente |
| Qualidade dos dados | Alta (com esforço) | Alta (orientada por IA) |
Não estou dizendo que Python é a escolha errada — se você precisa de controle total, lógica personalizada ou integração em um pipeline maior, código ainda é rei. Mas, para a maioria dos usuários de negócios que só querem dados da Etsy, a conta do ROI favorece uma ferramenta sem código.
Dicas legais e éticas para raspar a Etsy
Sempre me perguntam sobre legalidade em posts de scraping, então aqui vai a versão curta:
- Os Termos de Uso da Etsy proíbem explicitamente acesso automatizado. Ainda assim, a Etsy depende de aplicação técnica (DataDome) em vez de ações judiciais — não há ações conhecidas específicas da Etsy contra scrapers.
- Raspe apenas dados publicamente disponíveis. Não contorne autenticação nem acesse painéis privados de vendedores que não sejam seus.
- Use taxas razoáveis de requisição. Atrasos de 2–7 segundos entre requests, sem bombardear os servidores da Etsy.
- Respeite o
robots.txt. A Etsy permite páginas de busca, mas restringe alguns caminhos. - Trate dados pessoais com responsabilidade de acordo com leis de privacidade como a LGPD/GDPR.
- Consulte um advogado para projetos de scraping em escala comercial.
Para mais contexto, veja nosso post sobre — incluindo Meta v. Bright Data (2024), em que o scraping de dados públicos foi mantido.
Conclusão: principais aprendizados
Cobrimos bastante coisa aqui. O que eu quero que você leve daqui é o seguinte:
- Os dados estruturados em JSON-LD da Etsy tornam a extração mais limpa do que o parse de HTML puro para a maioria dos campos.
- O DataDome é um obstáculo real — use headers corretos, atrasos, gerenciamento de cookies e proxies residenciais para scraping em Python em escala.
- A API da Etsy é limitada. Se você precisa de avaliações, lojas concorrentes ou análise entre vendedores, scraping é o caminho prático.
- O Thunderbit oferece uma alternativa sem código que lida nativamente com anti-bot e autenticação — vale testar se você quer dados da Etsy sem manter scripts.
- Sempre faça scraping com responsabilidade e respeite os termos da Etsy.
Se quiser começar sem escrever código, . Ou use o código Python deste tutorial para criar seu próprio scraper personalizado — e que seus seletores nunca quebrem numa sexta-feira à tarde.
Para mais guias de scraping, confira nosso e o compilado dos .
FAQs
1. É legal raspar a Etsy com Python?
Raspar dados publicamente disponíveis é geralmente permitido segundo precedentes legais recentes (por exemplo, Meta v. Bright Data, hiQ v. LinkedIn). No entanto, os Termos de Uso da Etsy proíbem acesso automatizado, então sempre revise os ToS e o robots.txt antes de raspar. Para uso comercial ou em grande escala, consulte um advogado.
2. Posso raspar a Etsy sem ser bloqueado?
A Etsy usa o DataDome, um dos sistemas anti-bot mais difíceis que existem. Headers realistas, atrasos entre requisições, persistência de cookies e rotação de proxies residenciais ajudam a reduzir bloqueios. A abordagem nativa de navegador do Thunderbit evita a maioria das detecções, pois opera dentro da sua sessão real do Chrome.
3. A Etsy tem uma API que eu possa usar em vez de raspar?
Sim — a Etsy oferece uma API v3, mas ela é limitada principalmente aos dados da sua própria loja e não tem acesso robusto a avaliações. A maioria dos casos de inteligência competitiva e análise entre lojas exige scraping.
4. Quais bibliotecas Python eu preciso para raspar a Etsy?
No mínimo: requests, beautifulsoup4, pandas (para exportação) e json (nativo). Para páginas pesadas em JS ou que exigem login, adicione selenium. Para parse de HTML mais rápido, use lxml.
5. Como faço para raspar avaliações da Etsy especificamente?
As avaliações da Etsy carregam por meio de um endpoint interno de API (/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews). Você vai precisar extrair o ID do anúncio, o ID da loja e o token CSRF da página do produto e então fazer um POST para o endpoint com paginação. Como alternativa, você pode analisar o primeiro lote de avaliações diretamente no HTML da página do produto — ambas as abordagens são explicadas passo a passo neste tutorial.
Saiba mais