A maioria dos tutoriais sobre scraping no eBay dura, no máximo, uns três meses. Eu sei disso porque, na Thunderbit, vimos desenvolvedores passarem por uma sequência de trechos quebrados, seletores CSS desatualizados e repositórios no GitHub que “funcionavam” — até pararem em silêncio, depois de duas reformulações do eBay.
o eBay reúne cerca de — o maior conjunto de dados de precificação de cauda longa na web aberta depois da Amazon. Esses dados alimentam tudo, de precificação para revendedores até inteligência competitiva. Mas acessar isso de forma programática é um alvo em movimento: o frontend em React do eBay muda classes CSS o tempo todo, testes A/B entregam estruturas de DOM diferentes para usuários diferentes, e o Akamai Bot Manager fica entre você e o HTML. Este guia traz código em Python que funciona hoje, explica por que os scrapers quebram para que você construa soluções resilientes, compara com sinceridade a decisão entre API do eBay e scraping, e mostra uma saída sem código quando Python não compensa a configuração.
O que significa fazer scraping do eBay com Python?
Fazer web scraping do eBay com Python significa escrever scripts que baixam páginas do eBay de forma programática, interpretam o HTML (ou JSON oculto) e extraem dados estruturados — títulos, preços, informações do vendedor, datas de venda, detalhes de variantes — em um formato realmente útil, como CSV, planilha ou banco de dados.
Você pode fazer scraping de vários tipos de páginas do eBay:
- Resultados de busca (por exemplo, todos os anúncios de "AirPods Pro")
- Páginas individuais de produto (especificações completas, imagens, dados do vendedor)
- Anúncios vendidos/concluídos (preços e datas reais de transação)
- Perfis de vendedores e avaliações
Python é a linguagem preferida para esse trabalho. Seu ecossistema — Requests, BeautifulSoup, lxml, pandas — facilita buscar páginas, analisar HTML e organizar dados. Ainda assim, há uma diferença importante entre raspar o HTML do site e usar a API oficial do eBay — e isso eu explico a seguir.
Por que raspar o eBay? Casos de uso reais para equipes de negócios
Se você está lendo isto, provavelmente já tem um motivo. Mesmo assim, vale ancorar a discussão em valor de negócio concreto, porque o retorno dos dados do eBay é realmente impressionante. A Bain constatou que uma em milhares de empresas. A McKinsey atribui à precificação dinâmica no varejo.
Os casos de uso que mais vejo:
| Caso de uso | Dados necessários | Resultado para o negócio |
|---|---|---|
| Monitoramento de preços e repricing | Preços de anúncios ativos, frete, condição | Preço competitivo, proteção de margem |
| Análise da concorrência | Mix de produtos, promoções, condições de frete | Posicionamento estratégico, lacunas de sortimento |
| Pesquisa de mercado e identificação de tendências | Velocidade dos anúncios, tendências por categoria, padrões de demanda | Identificação de novos produtos, previsão de demanda |
| Precificação para revenda / avaliação | Preços de venda, datas de venda, condição | Valor justo de mercado, decisões de compra |
| Análise de sentimento | Avaliações, notas, política de devolução | Insights sobre qualidade do produto e satisfação do cliente |
| Geração de leads | Perfis de vendedores, informações da loja, dados de contato | Prospecção B2B para vendedores de alto GMV |
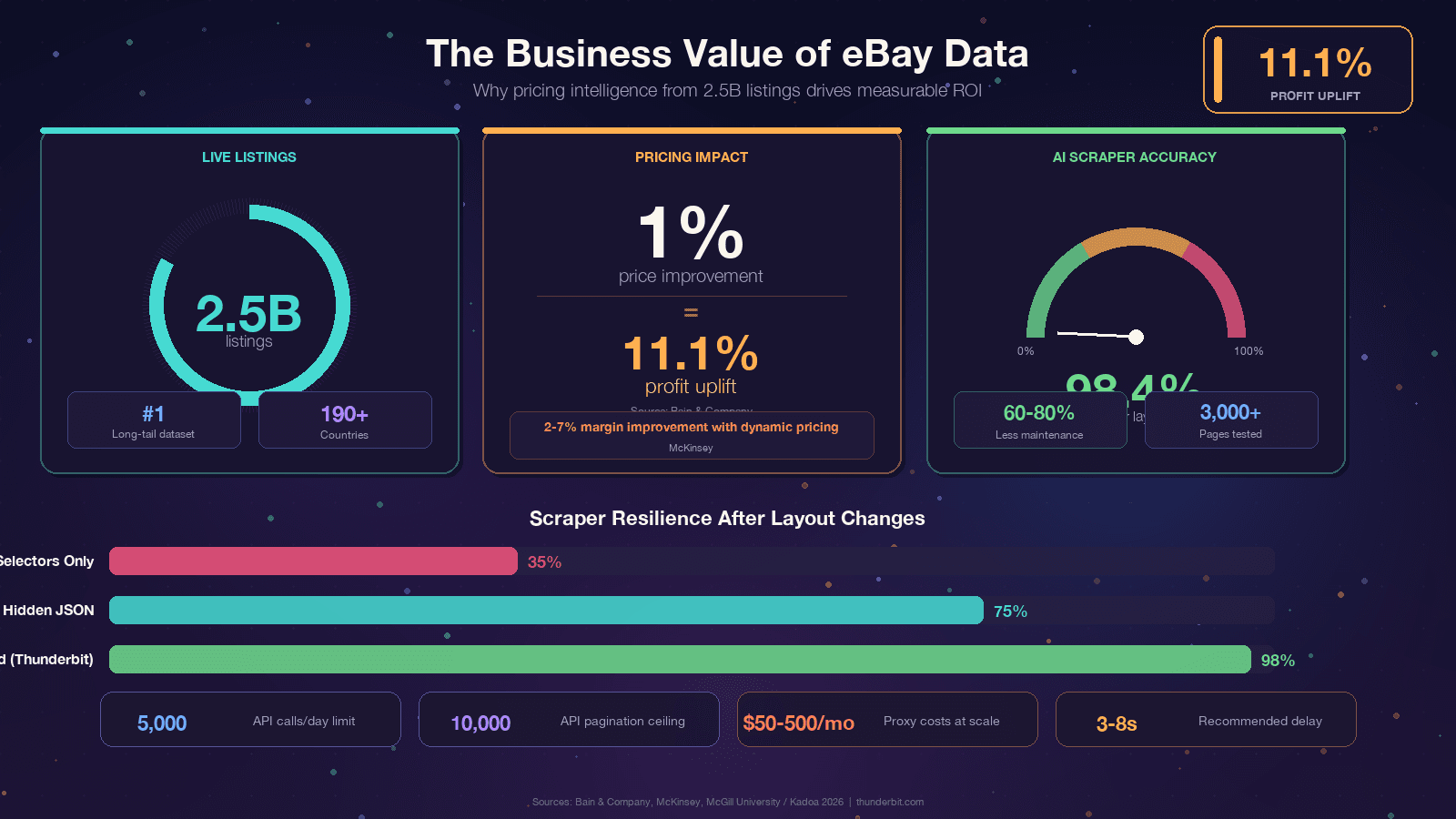
O ponto em comum é simples: o eBay tem os dados, mas eles estão presos dentro de páginas web.
Scraping é o que transforma isso em vantagem competitiva.
API oficial do eBay vs. web scraping em Python: qual escolher?
Essa é a pergunta que eu queria ver respondida com mais honestidade em muitos tutoriais. O eBay oferece APIs oficiais — principalmente a — e muita gente se pergunta se vale usar a API ou raspar direto. A resposta depende totalmente dos dados de que você precisa.
| Critério | API Browse/Finding do eBay | Web scraping em Python |
|---|---|---|
| Anúncios vendidos/concluídos | Limitado — a Marketplace Insights API existe, mas o acesso costuma ser negado | Acesso completo via parâmetros de URL LH_Sold=1&LH_Complete=1 |
| Limites de requisição | 5.000 chamadas/dia no plano básico | Gerenciado por você (depende de proxy) |
| Campos de dados | Pré-definidos (título, preço, categoria, básicos do vendedor) | Tudo o que estiver visível na página (avaliações, especificações completas, matriz de variantes) |
| Complexidade de configuração | OAuth 2.0, registro de app, chaves de API | pip install + código |
| Estabilidade | Endpoints estáveis | Quebra quando o HTML muda |
| Custo | Há plano gratuito, pago para alto volume | Código grátis, mas custo de proxy em escala |
| Dados de variantes/MSKU | Parcial — muitas vezes só o SKU pai | Completo (via parsing de JSON oculto) |
| Profundidade de paginação | limite rígido de 10.000 itens | Teoricamente ilimitado |
Uma observação rápida: a antiga Finding API (que incluía findCompletedItems) foi . Se você usa ebaysdk-python ou qualquer biblioteca que consulte o módulo Finding, ela está quebrada em produção neste momento.
Minha recomendação: use a Browse API para consultas estruturadas, estáveis e de volume moderado em anúncios ativos. Use scraping em Python quando precisar de preços de itens vendidos, avaliações, dados de variantes ou qualquer campo que a API não exponha. Muitas equipes usam as duas abordagens.
Ferramentas e bibliotecas necessárias para raspar o eBay com Python
Antes de escrever qualquer código, aqui está o kit. Você não precisa de um navegador headless para a maioria das páginas do eBay — os dados já vêm embutidos no HTML renderizado no servidor.
| Biblioteca | Finalidade |
|---|---|
requests ou httpx | Cliente HTTP para baixar páginas do eBay |
curl_cffi | Cliente HTTP com fingerprint TLS de navegador real (essencial para contornar o Akamai) |
beautifulsoup4 | Parser de HTML para extração com seletores CSS |
lxml | Backend de parsing rápido para BeautifulSoup |
jmespath | Linguagem de consulta para analisar blocos JSON aninhados |
pandas | Manipulação de dados e exportação para CSV/Excel |
gspread | Integração com Google Sheets |
Instale tudo em uma linha:
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadUse Python 3.11+ — o pandas 3.0 exige 3.10+ e o 3.11 traz ganhos de 10–60% de velocidade em tarefas limitadas por I/O.
Uma biblioteca merece destaque: curl_cffi é a atualização mais impactante que um scraper do eBay em 2026 pode adotar. O eBay usa , e o principal vetor de detecção do Akamai é o fingerprint TLS. O requests puro envia um JA3 com cara de Python, que é sinalizado na hora. O curl_cffi imita o handshake TLS de um Chrome real, o que resolve cerca de 90% dos alvos protegidos pelo Akamai sem precisar de navegador headless.
Passo a passo: como raspar resultados de busca do eBay com Python
Este é o tutorial principal. Vamos raspar páginas de resultados de busca do eBay para anúncios de produtos.
- Nível: iniciante–intermediário
- Tempo necessário: cerca de 30 minutos para a primeira extração funcional
- O que você vai precisar: Python 3.11+, as bibliotecas acima, um terminal e uma URL de busca do eBay
Passo 1: configure seu projeto em Python
Crie um diretório de projeto e instale as dependências:
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasCrie um arquivo chamado scrape_ebay.py. Esse é o seu espaço de trabalho.
Passo 2: monte a URL de busca do eBay
A estrutura da URL de busca do eBay é simples. O parâmetro principal é _nkw (keyword):
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # itens por página: 60, 120 ou 240 (240 pode acionar filtros anti-bot)
7 "_pgn": "1", # número da página
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1Outros parâmetros úteis:
LH_BIN=1— somente Buy It Now_sacat=175673— categoria específica_sop=12— ordenar por melhor correspondência (10 = menor preço+frete, 13 = mais recentes)LH_Complete=1&LH_Sold=1— anúncios vendidos/concluídos (cobertos em uma seção dedicada abaixo)
Passo 3: envie a requisição e trate a resposta
Aqui é onde o curl_cffi faz diferença. Um requests.get() simples muitas vezes retorna 403 do Akamai. Com curl_cffi, imitamos um navegador Chrome real:
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Status {r.status_code}, tentando novamente em {sleep_for:.1f}s...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" Erro na requisição: {e}, tentando novamente...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"Falha após {max_retries} tentativas: {url}")O backoff exponencial com jitter é importante — intervalos fixos de espera também viram fingerprint de bot.
Passo 4: faça o parsing dos anúncios na página de busca
o eBay está em migração entre dois layouts de resultados de busca. Um scraper resiliente precisa dar conta dos dois:
| Campo | Layout antigo | Novo layout |
|---|---|---|
| Contêiner do card | li.s-item | li.s-card ou div.su-card-container |
| Título | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Preço | span.s-item__price | .s-card__price |
O código de parsing que cobre os dois layouts:
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # Título — tenta os dois layouts
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # Ignora o card fantasma "Shop on eBay"
11 if not title or "Shop on eBay" in title:
12 continue
13 # Preço
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # Imagem
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # Frete
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return resultsA armadilha do primeiro card fantasma é um clássico. Em muitas páginas do eBay, o primeiro li.s-item é um placeholder oculto com o título "Shop on eBay" e sem preço real. Sempre filtre isso.
Passo 5: trate a paginação para raspar várias páginas
o eBay pagina via o parâmetro _pgn. O link da próxima página usa a.pagination__next:
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Raspando página {page_num}: {url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" Nenhum resultado na página {page_num}, encerrando.")
12 break
13 all_results.extend(results)
14 print(f" Encontrados {len(results)} anúncios (total: {len(all_results)})")
15 # Pausa educada — 3 a 8 segundos com jitter
16 time.sleep(random.uniform(3, 8))
17 return all_resultsO jitter aleatório de 3 a 8 segundos não é opcional.
a camada Akamai do eBay sinaliza qualquer sequência sustentada acima de 1 req/s a partir de um único IP.
Passo 6: exporte os dados para CSV ou JSON
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"Exportados {len(df)} anúncios para CSV e JSON.")Agora você deve ter uma planilha limpa com anúncios do eBay. Na minha máquina, raspar 3 páginas (360 anúncios) levou cerca de 45 segundos, incluindo as pausas.
Como raspar páginas de detalhes de produtos do eBay com Python
Os resultados de busca dão um resumo. As páginas de detalhes do produto trazem o que importa: descrições completas, score de feedback do vendedor, especificações do item, carrossel de imagens e dados de variantes.
Fazendo parsing de uma página individual de anúncio
As páginas de item do eBay ficam em /itm/<ITEM_ID>. O caminho de extração mais estável é JSON-LD — o eBay incorpora um bloco de schema Product que sobrevive à quase todas as mudanças de CSS:
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — caminho de extração mais estável
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. Fallbacks em CSS para campos que não estão no JSON-LD
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. Especificações do item
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemO padrão aqui — JSON-LD primeiro, fallbacks em CSS depois — é a chave para construir scrapers que não quebram a cada trimestre. Já já eu explico melhor.
Como raspar variantes de produtos no eBay (dados MSKU)
Alguns anúncios do eBay têm várias variantes — cores diferentes, tamanhos diferentes, capacidades de armazenamento diferentes. O DOM visível mostra apenas uma faixa de preço como "$899 a $1.099" até o usuário clicar em uma opção. O preço real por variante fica em um objeto JavaScript oculto chamado MSKU.
Essa é uma área em que a API do eBay só entrega dados parciais (SKU pai), o que faz do scraping a melhor opção.
1import re, json
2def extract_variants(html):
3 # A correspondência não gulosa é crucial — o .+ guloso engole a página inteira
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusEsse (.+?) não guloso na regex é justamente onde todo scraper de eBay tropeça. O .+ guloso engole tudo até a última ocorrência de "QUANTITY" na página, gerando JSON inválido. Já vi esse bug em pelo menos três tutoriais que “funcionavam”.
Como raspar anúncios vendidos e concluídos do eBay com Python
Este é o caso de uso que realmente justifica o scraping em vez da API. Dados de itens vendidos — o que de fato foi transacionado, por quanto e em que data — são o padrão-ouro para pesquisa de mercado, precificação de revenda e avaliações. A Browse API do eBay não oferece isso explicitamente. A tecnicamente oferece, mas o acesso é uma liberação limitada e .
Os parâmetros de URL que você precisa são LH_Complete=1 (anúncios concluídos) e LH_Sold=1 (restringe aos realmente vendidos). Você precisa passar os dois. Usar apenas LH_Sold=1 em algumas categorias faz o sistema voltar silenciosamente para anúncios ativos — esse é o erro mais comum da comunidade.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Raspando página de vendidos {page_num}...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # Inclui apenas itens realmente vendidos (preço verde POSITIVE)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # anúncio concluído sem venda — ignore
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # Extrai a data da venda
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldA diferença-chave no HTML: itens vendidos mostram o preço em verde (dentro de um wrapper .POSITIVE), enquanto anúncios concluídos sem venda mostram o preço em vermelho riscado. Sempre filtre pela classe .POSITIVE.
Por que os scrapers do eBay quebram (e como construir soluções resilientes)
Se o seu scraper do eBay parou de funcionar, você está em boa companhia. Esse é o problema nº 1 em toda discussão de scraping do eBay que eu já li. A questão não é se seu scraper vai quebrar — é quando.
Por que isso acontece:
- O eBay usa renderização com React e classes geradas dinamicamente que mudam em cada deploy
- Testes A/B entregam estruturas de DOM diferentes para usuários diferentes (o layout duplo
s-item/s-cardé um exemplo real agora) - Reformulações periódicas do site alteram a aninhamento do HTML, mesmo quando os dados continuam iguais
- Seletores antigos como
#itemTitlee#prcIsumforam removidos há anos, mas ainda aparecem em tutoriais
Como diz o : "O verdadeiro desafio do web scraping no eBay é lidar com as mudanças nos seletores CSS. O eBay atualiza o frontend com frequência, quebrando scrapers que dependem de nomes de classe específicos."
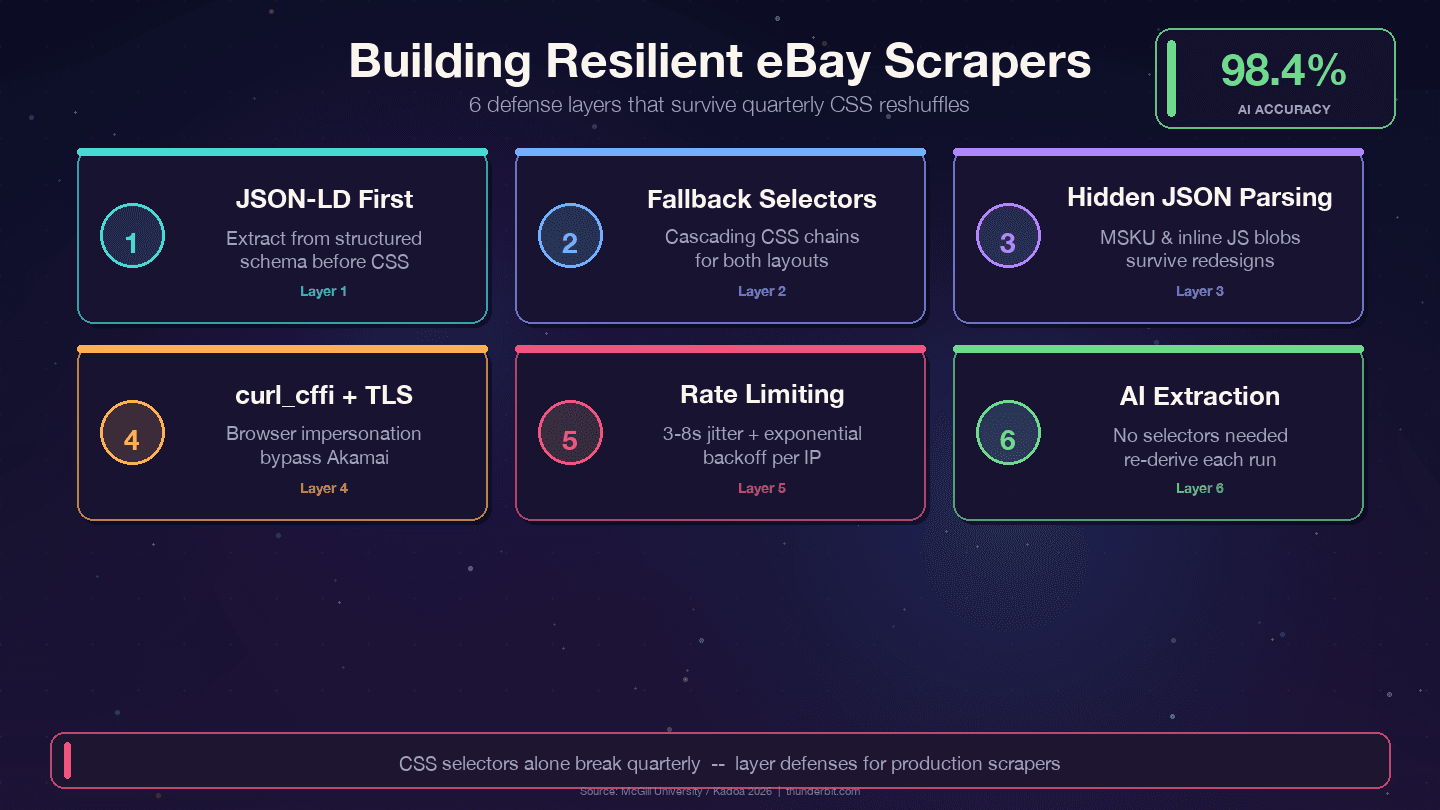
Estratégias de defesa para scrapers do eBay duradouros
Quatro estratégias que resistem às reformulações trimestrais do eBay:
1. Priorize JSON-LD em vez de seletores CSS. O eBay incorpora dados estruturados do schema Product em cada página de item. A camada de dados muda muito menos que a camada de apresentação — designers refatoram classes CSS a cada trimestre, mas campos de backend como price, name e seller estão ligados a APIs internas e quase nunca trocam de nome.
2. Use seletores de fallback em cascata. Nunca dependa de um único seletor CSS. Sempre ofereça alternativas:
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. Analise blocos JSON ocultos. O objeto de variantes MSKU e os dados inline em JavaScript sobrevivem a mudanças de CSS porque são gerados no servidor. Extrair com regex de tags <script> dá mais trabalho no começo, mas reduz muito a manutenção.
4. Registre falhas de seletores. Adicione monitoramento para saber quando um seletor para de encontrar algo, e não apenas que o dado ficou vazio:
1if title is None:
2 print(f"AVISO: seletor de título falhou para {url}")5. Use curl_cffi com impersonação de navegador. Isso lida com o fingerprint TLS do Akamai sem exigir navegador headless.
A alternativa com IA: sem manutenção de seletores
Se você está cansado de remendar seletores a cada poucos meses, existe uma abordagem fundamentalmente diferente. Ferramentas como a usam IA para ler a página do zero a cada execução e derivar a lógica de extração em tempo real. Um estudo da Universidade McGill testou scrapers baseados em IA contra scrapers baseados em seletores em 3.000 páginas e descobriu que , com benchmarks do setor apontando .
| Abordagem | Quebra quando o eBay muda o HTML? | Esforço de manutenção |
|---|---|---|
| Seletores CSS hardcoded | Sim, trimestralmente | Alto — correções contínuas |
| Extração de JSON oculto / JSON-LD | Raramente | Baixo |
| Scraping com IA (Thunderbit) | Não — a IA redescobre os seletores a cada execução | Nenhum |
Mais adiante eu explico o fluxo da Thunderbit em detalhes. Por agora, a conclusão é: se você vai manter um scraper por meses, vale investir em extração baseada em JSON e seletores de fallback. Se você não quer manter seletores, a abordagem com IA merece atenção.
Automatizando raspagens recorrentes do eBay para monitoramento de preços
Uma raspagem única é útil. Mas monitoramento de preços, controle de estoque e análise de concorrência exigem coleta recorrente de dados. Todo artigo de concorrente que eu li menciona monitoramento de preços como caso de uso, mas quase nenhum mostra como automatizar isso de fato.
Opção 1: cron jobs (Linux/macOS) ou Agendador de Tarefas (Windows)
A abordagem mais simples. Envolva seu script em um cron job. Use sempre o caminho absoluto do Python do seu venv — o cron roda com um ambiente mínimo:
1crontab -e
2# Todos os dias às 08:15
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1No Windows, use PowerShell:
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $TIsso exige uma máquina sempre ligada, e você mesmo gerencia proxies e medidas anti-bot.
Opção 2: funções em nuvem (serverless)
AWS Lambda ou Google Cloud Functions permitem rodar scrapers sem servidor dedicado. Exige mais configuração — você precisa empacotar dependências, lidar com timeouts (o Lambda limita a 15 minutos) e ainda gerenciar proxies. Mas elimina manutenção de servidor.
Opção 3: agendamento sem código com Thunderbit
O recurso permite descrever o intervalo em linguagem natural (por exemplo, “todo dia às 8h”), inserir URLs do eBay e clicar em Agendar. Ele roda na nuvem com tratamento anti-bot embutido.
| Abordagem | Esforço de configuração | Precisa de servidor? | Lida com anti-bot? |
|---|---|---|---|
| Cron + script Python | Médio | Sim (máquina sempre ligada) | Você gerencia proxies |
| Função em nuvem (Lambda) | Alto | Não (serverless) | Você gerencia proxies |
| Scheduled Scraper da Thunderbit | Baixo (descreva em palavras) | Não (baseado em nuvem) | Embutido |
Para armazenar dados de scrapes recorrentes, um banco SQLite local é a resposta certa para histórico de preços. Use ON CONFLICT ... DO UPDATE (não INSERT OR REPLACE, que ):
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);Não quer programar? Como raspar o eBay em 2 minutos com Thunderbit
Passei 2.000 palavras em código Python. Agora quero ser honesto sobre quando você não precisa dele.
Se você é um usuário de negócios fazendo uma pesquisa de mercado pontual, um revendedor comparando preços ou uma equipe de e-commerce que precisa dos dados hoje sem um sprint de desenvolvimento, Python é exagero. A configuração, a manutenção de seletores, o gerenciamento de proxy — tudo isso é muito trabalho para algo como “só preciso desses 200 anúncios em uma planilha”.
Como a Thunderbit raspa o eBay (passo a passo)
- Instale a — não precisa de cartão de crédito.
- Abra qualquer página de resultados de busca ou produto do eBay no Chrome.
- Clique em "AI Suggest Fields" na barra lateral da Thunderbit. A IA lê a página e sugere colunas: Título, Preço, Condição, Frete, Vendedor, Avaliação.
- Clique em "Scrape". A extensão percorre a paginação e preenche a tabela de dados. Especificamente para o eBay, a Thunderbit tem que funcionam com um clique.
- Exporte para Google Sheets, Airtable, Notion, CSV, JSON ou Excel — grátis.
O processo inteiro leva menos de 2 minutos.
Eu cronometrei.
Enriquecimento de subpáginas: obtenha dados da página de detalhes sem código extra
Depois de raspar uma página de resultados, a Thunderbit pode visitar a página de detalhes de cada anúncio e adicionar campos extras — especificações completas, informações do vendedor, descrição, todas as imagens. Isso substitui as mais de 20 linhas de código Python para scraping de subpáginas que escrevemos antes por um único clique.
Quando ainda faz sentido usar Python
Python vence quando você precisa de:
- Scraping em grande escala (dezenas de milhares de páginas por execução)
- Lógica de parsing altamente personalizada ou transformação de dados
- Integração com pipelines de dados já existentes (Airflow, dbt, Kafka)
- Controle fino de TLS/sessão para trabalhos avançados anti-bot
- Economia unitária — em milhões de linhas, uma stack mantida pode ser melhor do que um SaaS por créditos
Para a maioria dos projetos pontuais ou de médio porte, a Thunderbit é mais rápida e simples. Para pipelines de produção em escala, Python oferece controle total.
Dicas para evitar bloqueios ao raspar o eBay com Python
A camada Akamai do eBay é real. O que realmente funciona na prática:
- Use
curl_cfficomimpersonate="chrome124"— essa é a maior melhoria em relação aorequestspuro - Alterne strings de User-Agent usando uma lista de versões atuais de navegadores (Chrome 143, Firefox 124, Safari 26)
- Adicione atrasos aleatórios de — intervalos fixos denunciam bot
- Use proxies residenciais ou rotativos para qualquer coisa além de algumas dezenas de páginas. IPs de datacenter (AWS, GCP, DigitalOcean) são identificados rapidamente pelo Akamai.
- Respeite o
robots.txt— a maioria das URLs filtradas de busca é explicitamente Disallowed; páginas de item (/itm/<id>) não são - Lide com CAPTCHAs com elegância — detecte e tente novamente com outro IP, ou use um serviço de resolução de CAPTCHA
- Não sobrecarregue o servidor. O precedente diz que invasão por bens móveis se aplica quando o scraping degrada de fato os servidores. Ficar em 1 req/s por IP mantém você longe desse limite.
Para uso comercial de alto volume, considere usar a Browse API para anúncios ativos e scraping direcionado apenas para comparáveis vendidos e dados que a API não expõe. Essa abordagem híbrida é mais limpa técnica e juridicamente.
É legal fazer scraping do eBay com Python?
Não sou advogado, e este post não é सलाह jurídica. Então vou ser breve.
O cenário legal mudou a favor do scraping de dados publicamente disponíveis. Os precedentes-chave:
- (9ª Cir., 2022): raspar dados publicamente acessíveis não viola o CFAA
- Van Buren v. United States (Suprema Corte dos EUA, 2021): restringiu a cláusula de "exceeds authorized access" do CFAA
- (N.D. Calif., 2024): scraping sem login não viola os termos da plataforma porque o scraper não é um "usuário"
Dito isso, a atualização de proíbe explicitamente "agentes buy-for-me, bots orientados por LLM ou qualquer fluxo ponta a ponta que tente realizar pedidos sem revisão humana". A linha é clara: scraping apenas de leitura em páginas públicas é defensável; automatizar checkout não é.
Boas práticas: raspe apenas dados visíveis publicamente. Não crie contas falsas nem burle telas de login. Não revenda em massa imagens de anúncios protegidas por direitos autorais. E consulte assessoria jurídica para projetos em escala comercial.
Conclusão e principais aprendizados
Python é a forma mais flexível de raspar o eBay, mas exige manutenção contínua conforme o HTML do site muda. O framework de decisão é este:
- Use a Browse API do eBay para consultas estáveis, estruturadas e de volume moderado em anúncios ativos
- Use scraping em Python para anúncios vendidos, avaliações, dados de variantes e qualquer campo que a API não expõe
- Use se quiser dados do eBay sem escrever ou manter código
O código deste guia prioriza resiliência: extração de JSON-LD primeiro, seletores CSS em cascata depois, parsing de JSON oculto para variantes. Essa abordagem em camadas faz seu scraper sobreviver à próxima reformulação do frontend do eBay.
Se quiser testar a rota sem código, o permite experimentar nas páginas do eBay agora mesmo. E se quiser ver como funciona o , ele está a um clique de distância.
Para mais conteúdo sobre ferramentas de web scraping, confira nossos guias sobre , e . Você também pode assistir aos tutoriais no .
Perguntas frequentes
1. Posso fazer scraping do eBay gratuitamente com Python?
Sim. Todas as bibliotecas (Requests, BeautifulSoup, curl_cffi, pandas) são gratuitas e open source. Os custos aparecem em escala — proxies residenciais para alto volume normalmente custam de US$ 50 a US$ 500/mês, dependendo da banda. Para projetos pequenos (algumas centenas de páginas), você pode raspar do seu IP residencial com limitação de taxa cuidadosa.
2. Como raspar itens vendidos e anúncios concluídos do eBay com Python?
Adicione LH_Complete=1&LH_Sold=1 aos parâmetros da URL de busca. Você precisa dos dois — LH_Sold=1 sozinho, em algumas categorias, cai silenciosamente em anúncios ativos. Filtre os resultados verificando a classe CSS .POSITIVE no elemento de preço, que indica uma venda real em vez de um anúncio expirado sem venda.
3. O eBay bloqueia web scraping?
o eBay usa o Akamai Bot Manager, que detecta scrapers principalmente por fingerprint TLS e análise comportamental. Chamadas simples com requests muitas vezes retornam 403. Usar curl_cffi com impersonação de navegador, alternar User-Agents e adicionar atrasos aleatórios de 3 a 8 segundos entre requisições resolve a maioria dos bloqueios. Proxies residenciais ajudam em escala.
4. Devo usar a API do eBay ou web scraping?
Use a Browse API para consultas estáveis e de volume moderado em anúncios ativos (até 5.000 chamadas/dia). Use scraping quando precisar de histórico de preços de itens vendidos, dados completos de variantes/MSKU, avaliações ou qualquer campo que a API não exponha. A Marketplace Insights API tecnicamente fornece dados de vendidos, mas o acesso é restrito e .
5. Qual é a forma mais fácil de raspar o eBay sem programar?
A usa IA para ler páginas do eBay, sugerir colunas de dados e extrair anúncios com um clique. Ela lida com paginação, enriquecimento de subpáginas e exportação para Google Sheets, Excel, Airtable ou Notion. Os tornam tudo ainda mais rápido para casos de uso comuns.
Saiba mais