O Craigslist ainda recebe cerca de em ~700 sites locais — e continua sem uma API pública. Se você quer dados estruturados desses anúncios de apartamentos, carros usados, vagas de emprego ou gigs, fazer scraping é basicamente a única saída.
Só que o sistema anti-bot do Craigslist é duro de verdade. Ele não usa Cloudflare nem DataDome — ele roda seu próprio limitador de taxa baseado em nginx, refinado ao longo de mais de uma década. Se você vacilar, leva um 403 seco antes do segundo café. Passei bastante tempo testando diferentes abordagens contra as defesas do Craigslist, e este guia é o resultado: um tutorial em Python atualizado para 2025, aplicável a qualquer categoria, que cobre o método de extração via JSON-LD (a maior melhoria em relação aos guias antigos), estratégias honestas para evitar banimento, o cenário legal e uma alternativa sem código para quem só quer os dados sem escrever uma linha.
O que Significa Fazer Scraping do Craigslist com Python?
Fazer web scraping no Craigslist significa usar scripts em Python para visitar páginas do Craigslist de forma programática, extrair os dados estruturados de que você precisa — títulos, preços, descrições, imagens, localizações, datas de publicação — e salvar tudo em uma planilha, banco de dados ou arquivo JSON.
Python é a linguagem mais usada para isso por causa do ecossistema de bibliotecas. Com requests, BeautifulSoup, lxml e curl_cffi, você monta um scraper funcional do Craigslist em menos de 100 linhas. A comunidade é enorme, então quando o Craigslist muda algo (e ele muda), normalmente já tem alguém com a solução na mão.
O ponto principal é este: o Craigslist . A única interface programática oficial é a Bulk Posting Interface (BAPI), e ela é só de escrita — permite que anunciantes pagos e aprovados publiquem anúncios, não recuperá-los. Todo produto de “Craigslist API” que você vê em plataformas de terceiros é um scraper não oficial, não um endpoint autorizado. Se você quer dados em volume, precisa fazer scraping.
Por que Fazer Scraping do Craigslist? Casos de Uso Reais
O Craigslist não é só um lugar para achar sofá usado. É um conjunto de dados enorme, atualizado o tempo todo, em dezenas de verticais. Veja quem realmente se beneficia ao extrair esses dados:
| Caso de uso | Quem se beneficia | O que é extraído |
|---|---|---|
| Monitoramento de preços de apartamentos e aluguel | Corretores, locatários, empresas PropTech | Preço, metragem, quartos, bairro, latitude/longitude |
| Análise do mercado de carros usados | Concessionárias, apps de consumo, pesquisadores | Preço, marca, modelo, ano, odômetro, condição |
| Pesquisa do mercado de trabalho | Recrutadores, economistas do trabalho, analistas de força de trabalho | Título, remuneração, tipo de contratação, data de publicação |
| Geração de leads | Equipes de vendas, prestadores de serviço | Informações de contato, nome da empresa, área de atendimento |
| Precificação competitiva | Prestadores locais, operações de ecommerce | Preço do serviço, descrição, regiões atendidas |
O exemplo acadêmico mais citado é o — cerca de 500 mil anúncios de carros usados nos EUA com 26 variáveis, que serviu de base para dezenas de artigos, incluindo um estudo de 2024 no ResearchGate sobre a dinâmica do mercado de carros usados nos EUA. Fundos hedge compraram dados agregados de aluguel do Craigslist para pesquisa de tendências de preço. E equipes de vendas usam as categorias de serviços e gigs com frequência para geração de leads.
A conta é simples: 8 horas copiando e colando na mão versus cerca de 10 minutos com um scraper bem feito.
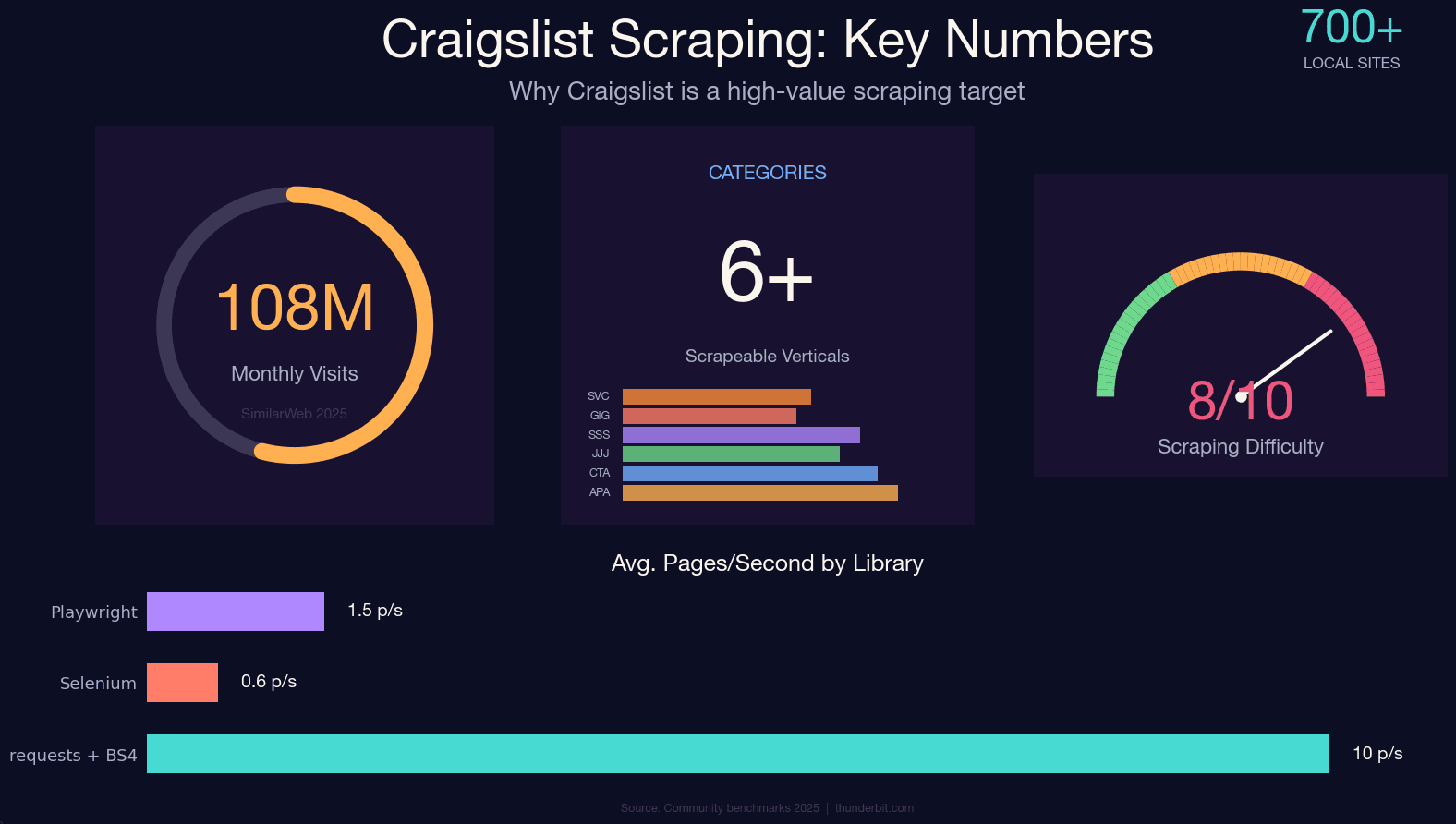
Fazer Scraping do Craigslist com Python: Todas as Categorias, Não Só Carros
Quase todo guia de scraping do Craigslist que encontrei cobre só carros à venda — o que é como escrever um tutorial do Google que aborda apenas pesquisa de imagens. O Craigslist tem dezenas de categorias, e os padrões de URL mudam conforme a seção.
A estrutura é sempre: https://{cidade}.craigslist.org/search/{slug_da_categoria}
Troque o subdomínio da cidade e o slug, e você passa a raspar uma vertical completamente diferente. Aqui vai uma tabela de referência com as categorias mais populares (verificado em abril de 2025):
| Categoria | Slug da URL | Campos típicos para extrair |
|---|---|---|
| Apartamentos / Moradia | /search/apa | Preço, metragem, quartos, localização, política para pets |
| Carros e caminhões | /search/cta | Preço, marca, modelo, ano, odômetro |
| Vagas | /search/jjj | Título, empresa, salário, tipo de contratação |
| Serviços | /search/bbb | Título, descrição, telefone, região |
| Gigs | /search/ggg | Título, remuneração, data, categoria |
| À venda (geral) | /search/sss | Título, preço, condição, localização |
Você também pode combinar parâmetros de consulta para filtrar resultados:
| Parâmetro | Finalidade | Exemplo |
|---|---|---|
query | Palavra-chave no texto | ?query=studio |
min_price / max_price | Faixa de preço | &min_price=1500&max_price=3000 |
hasPic | Apenas anúncios com imagens | &hasPic=1 |
postedToday | Últimas 24 horas | &postedToday=1 |
sort | Ordenação | &sort=priceasc |
s | Deslocamento da paginação (120 por página) | ?s=120 |
Então uma URL como https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1 retorna apartamentos em Nova York entre US$ 1.500 e US$ 3.000 com fotos. Todo scraper em Python deste guia funciona em todas essas categorias — é só trocar o slug.
Seletores HTML do Craigslist em 2025: Antigo vs. Novo (e o Atalho via JSON)
O principal motivo pelo qual scrapers do Craigslist quebram é a mudança na estrutura do HTML. Se você estiver seguindo um tutorial de 2022 que manda usar .result-row ou .result-info, seu scraper já era.
O Craigslist reescreveu a marcação dos resultados de busca em 2023–2024. Os nomes antigos de classe ainda existem dentro de novos contêineres, mas apontar para eles no topo da árvore DOM retorna lista vazia. Veja o que mudou:
| Elemento | Seletor legado (pré-2024) | Seletor atual (2025) |
|---|---|---|
| Contêiner do anúncio | .result-info | .cl-search-result |
| Link do título | .result-title | .posting-title a |
| Preço | .result-price | .priceinfo |
| Metadados (área) | .result-hood | .meta |
Mas aqui está a grande sacada — e a que separa um scraper realmente atualizado em 2025 de todo o resto: você nem precisa analisar o HTML dos resultados de busca.
O Craigslist agora embute cada anúncio visível dentro de uma tag <script id="ld_searchpage_results"> como dados estruturados em JSON-LD. Um único requests.get() retorna o schema.org ItemList completo com todos os anúncios da página — título, preço, moeda, localização, URL da imagem, link da página de detalhes. Sem renderização de JavaScript. Sem fragilidade de seletor CSS.
A abordagem JSON-LD é mais rápida, mais estável e muito menos propensa a quebrar quando o Craigslist mexe na interface. É o método usado por todo repositório GitHub mantido ativamente, e é o que vamos usar no tutorial abaixo.
Uma observação: o bloco JSON-LD está — apartamentos (apa), itens à venda (sss), carros (cta), moradia (hhh). Ele costuma estar ausente ou limitado em vagas (jjj), gigs (ggg), comunidade (ccc) e serviços (bbb), porque esses anúncios não têm preços no schema.org/Offer. Nesses casos, volte para o caminho HTML com .cl-search-result.
Escolhendo Seu Stack em Python: Requests + BS4 vs. Selenium vs. Playwright
Essa é a pergunta que aparece em todo fórum de scraping: “Qual biblioteca eu devo usar?” No caso do Craigslist, a resposta é mais direta do que na maioria dos sites.
| Fator | requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|
| Velocidade | 5–15 páginas/seg (limitada pela rede) | 0,3–1 página/seg | 0,5–2 páginas/seg |
| Conteúdo renderizado por JS | Não | Sim | Sim |
| Memória | ~30–60 MB | ~400–700 MB | ~300–500 MB |
| Complexidade de configuração | Baixa | Média | Média |
| Resistência a anti-bot | Baixa (precisa de headers/proxies) | Média (navegador real) | Média-Alta |
| Melhor caso de uso no Craigslist | Resultados de busca (JSON-LD) | Páginas de detalhe com conteúdo dinâmico | Scraping assíncrono em larga escala |
| Curva de aprendizado | Amigável para iniciantes | Moderada | Moderada |
As páginas do Craigslist são renderizadas no servidor. O bloco JSON-LD já vem no HTML inicial. Não há desafio em JavaScript no caminho de leitura. Todo usa requests + BeautifulSoup ou Scrapy. Nenhum usa Selenium ou Playwright. Isso não é coincidência — frameworks de automação de navegador somam centenas de MB de memória, uma perda de 10 a 100 vezes em velocidade e uma impressão digital mais visível, sem trazer benefício.
Minha recomendação:
- requests + BS4: comece por aqui. Combina perfeitamente com a extração via JSON-LD e atende 95% das necessidades de scraping do Craigslist.
- Selenium: só se você precisar interagir com conteúdo dinâmico em páginas de detalhes específicas (o que é raro no Craigslist).
- Playwright: se você estiver escalando para milhares de páginas com concorrência assíncrona — mas, sinceramente, o gargalo do Craigslist é o limitador de taxa, não a vazão da biblioteca.
Cobrimos a comparação entre e também um resumo das em posts separados, caso você queira o panorama completo.
A Alternativa Sem Código: Faça Scraping do Craigslist Sem Escrever Python
Uma pausa rápida antes do código — esta seção é para quem não é desenvolvedor. Corretores, times de vendas, gestores de operações — se você só quer os dados e não quer escrever Python, existe um caminho mais rápido.
é um web scraper com IA que funciona como extensão do Chrome. Ele consegue extrair dados do Craigslist em cerca de 2 cliques, sem código. O fluxo é este:
- Acesse qualquer página de resultados do Craigslist (apartamentos, carros, vagas — qualquer categoria).
- Clique em "AI Suggest Fields" na barra lateral do Thunderbit. A IA lê a página e detecta automaticamente colunas como título do anúncio, preço, localização e link.
- Clique em "Scrape" — os dados são extraídos em segundos.
- Use o Subpage Scraping para visitar a página de detalhes de cada anúncio e enriquecer seus dados com descrições completas, telefones, imagens e atributos.
- Exporte direto para Google Sheets, Excel, Airtable ou Notion — totalmente grátis.
Para necessidades recorrentes — por exemplo, monitoramento diário de preços de apartamentos ou capturas semanais de vagas — o Scheduled Scraper do Thunderbit permite descrever a rotina em linguagem natural e executar tudo automaticamente. Sem cron jobs, sem configuração de servidor.
O Thunderbit também lida com medidas anti-bot por meio do modo Cloud Scraping, então você não precisa se preocupar com rotação de proxies ou montagem de headers. Se quiser testar, pegue a e veja por conta própria.
Se você quer controle total e personalização, continue lendo o passo a passo em Python.
Passo a Passo: Como Fazer Scraping do Craigslist com Python (Tutorial Completo)
- Dificuldade: Intermediária
- Tempo necessário: ~30 minutos (configuração + primeiro scraping)
- O que você vai precisar: Python 3.8+, navegador Chrome (para inspecionar páginas), um terminal
Passo 1: Configure Seu Ambiente Python
Instale as bibliotecas necessárias:
1pip install requests beautifulsoup4 lxmllxml é opcional, mas acelera bastante o parsing do BeautifulSoup. Se você encontrar problemas de fingerprint TLS mais adiante (falamos disso na seção anti-ban), também pode instalar curl_cffi:
1pip install curl_cffiSeu bloco de importação:
1import requests
2from bs4 import BeautifulSoup
3import json
4import csv
5import time
6import randomAgora você deve ter um ambiente Python limpo, com todas as dependências instaladas.
Passo 2: Monte a URL do Craigslist para Qualquer Categoria
Construa a URL de destino dinamicamente usando cidade + slug da categoria + filtros opcionais:
1from urllib.parse import urlencode
2BASE = "https://{city}.craigslist.org/search/{slug}"
3def build_url(city, slug, **params):
4 return f"{BASE.format(city=city, slug=slug)}?{urlencode(params)}"
5# Exemplo: apartamentos em Nova York, de 1500 a 3000, com fotos
6url = build_url("newyork", "apa", min_price=1500, max_price=3000, hasPic=1)
7print(url)
8# https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1Troque "apa" por "cta" (carros), "jjj" (vagas), "bbb" (serviços) ou qualquer slug da tabela acima. Troque "newyork" por "sfbay", "chicago", "losangeles", etc.
Passo 3: Busque a Página e Extraia o JSON Embutido
Envie uma requisição GET com headers apropriados e depois faça o parse do bloco JSON-LD:
1HEADERS = {
2 "User-Agent": (
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.craigslist.org/",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "same-origin",
14 "Upgrade-Insecure-Requests": "1",
15}
16session = requests.Session()
17r = session.get(url, headers=HEADERS, timeout=20)
18r.raise_for_status()
19soup = BeautifulSoup(r.text, "html.parser")
20tag = soup.select_one("script#ld_searchpage_results")
21data = json.loads(tag.text) if tag else {"itemListElement": []}Se tag for None, o bloco JSON-LD não está presente para essa categoria — nesse caso, faça fallback para o parsing do HTML (veja a tabela de seletores acima). Para apartamentos, carros e itens à venda, o bloco JSON-LD costuma estar lá de forma confiável.
Passo 4: Transforme os Dados dos Anúncios em Registros Estruturados
Itere pelos itens JSON e extraia os campos de que precisa:
1listings = []
2for entry in data["itemListElement"]:
3 item = entry["item"]
4 offers = item.get("offers", {}) or {}
5 addr = (offers.get("availableAtOrFrom") or {}).get("address", {})
6 listings.append({
7 "name": item.get("name"),
8 "url": offers.get("url"),
9 "price": offers.get("price"),
10 "currency": offers.get("priceCurrency"),
11 "locality": addr.get("addressLocality"),
12 "region": addr.get("addressRegion"),
13 "image": item.get("image"),
14 })
15print(f"Encontrados {len(listings)} anúncios")Você deve ver algo como “Encontrados 120 anúncios” (o Craigslist mostra 120 resultados por página). Alguns anúncios podem retornar None para preço se o anunciante não tiver informado — trate isso com cuidado na lógica posterior.
Passo 5: Raspe as Páginas de Detalhe para Obter Dados Mais Ricos
Os resultados de busca entregam apenas informações resumidas. Para descrições completas, atributos (quartos, metragem, política para pets), coordenadas de latitude/longitude e imagens, você precisa visitar a URL de detalhes de cada anúncio.
1def fetch_detail(url, session):
2 r = session.get(url, headers=HEADERS, timeout=20)
3 r.raise_for_status()
4 s = BeautifulSoup(r.text, "html.parser")
5 body = s.select_one("#postingbody")
6 mp = s.select_one("#map")
7 return {
8 "description": body.get_text("\n", strip=True) if body else None,
9 "attributes": [x.get_text(" ", strip=True)
10 for x in s.select("p.attrgroup span, div.attrgroup .attr")],
11 "lat": mp.get("data-latitude") if mp else None,
12 "lng": mp.get("data-longitude") if mp else None,
13 "images": [img["src"] for img in s.select("div.gallery img")],
14 }
15for item in listings:
16 item.update(fetch_detail(item["url"], session))
17 time.sleep(random.uniform(3, 6)) # essencial: jitter anti-banO time.sleep(random.uniform(3, 6)) não é opcional. Se você pular essa etapa, provavelmente vai levar um 403 em poucas dezenas de requisições. As páginas de detalhes são renderizadas no servidor com seletores estáveis (#titletextonly, #postingbody, #map) que praticamente não mudam desde ~2017 — uma das poucas coisas no Craigslist que realmente são confiáveis.
Passo 6: Lide com a Paginação para Raspar Todos os Resultados
O Craigslist usa o parâmetro de deslocamento ?s=120 para paginação. Cada página mostra 120 resultados, e o deslocamento máximo normalmente é 2999.
1def iter_all(city, slug, max_pages=25, **filters):
2 for page in range(max_pages):
3 offset = page * 120
4 url = build_url(city, slug, s=offset, **filters)
5 r = session.get(url, headers=HEADERS, timeout=20)
6 r.raise_for_status()
7 soup = BeautifulSoup(r.text, "html.parser")
8 tag = soup.select_one("script#ld_searchpage_results")
9 if not tag:
10 break
11 data = json.loads(tag.text)
12 items = data.get("itemListElement", [])
13 if not items:
14 break
15 for entry in items:
16 item = entry["item"]
17 offers = item.get("offers", {}) or {}
18 yield {
19 "name": item.get("name"),
20 "url": offers.get("url"),
21 "price": offers.get("price"),
22 }
23 time.sleep(random.uniform(2.5, 5.0))Não tente raspar milhares de páginas em sequência rápida. O limitador de taxa do Craigslist é por IP, e a vazão sustentável com um único IP fica por volta de 0,3–0,5 requisições/segundo, independentemente da biblioteca usada. Esse teto é imposto pelo Craigslist, não pelo Python.
Passo 7: Exporte os Dados do Craigslist para CSV, JSON ou Google Sheets
Salve os resultados:
1# CSV
2with open("craigslist.csv", "w", newline="", encoding="utf-8") as f:
3 w = csv.DictWriter(f, fieldnames=listings[0].keys())
4 w.writeheader()
5 w.writerows(listings)
6# JSON
7with open("craigslist.json", "w", encoding="utf-8") as f:
8 json.dump(listings, f, indent=2, ensure_ascii=False)Se você preferir pular totalmente o código de exportação, o Thunderbit oferece exportação gratuita direto do navegador para Google Sheets, Excel, Airtable ou Notion. Mas, em pipelines Python, CSV e JSON são os formatos padrão. Você também pode mandar os dados direto para o pandas para análise ou para um banco de dados com sqlite3.
Como Evitar Ser Banido ao Fazer Scraping do Craigslist com Python
A maioria dos tutoriais passa batido por esta parte. O sistema anti-bot do Craigslist é customizado, não uma solução de prateleira, e tem algumas particularidades.

Use Headers de Requisição Realistas
O Craigslist valida a ordem e a completude dos headers. Uma requisição sem Sec-Fetch-Dest ou com um User-Agent desatualizado é sinalizada antes mesmo de chegar ao conteúdo. O conjunto completo de headers do Chrome 120+ (mostrado no Passo 3) é o mínimo. Alterne o User-Agent por sessão entre 5–10 strings recentes de Chrome/Firefox para desktop — mas não mude no meio da sessão, porque isso parece artificial.
A ausência dos headers Sec-Fetch-* é, disparado, a razão mais comum para bloqueios instantâneos em scrapers iniciantes.
Adicione Atrasos Aleatórios Entre as Requisições
O consenso da comunidade em (ScrapingBee, Scraperly, Oxylabs, Multilogin) converge para intervalos aleatórios de 2–5 segundos entre buscas e 3–6 segundos entre páginas de detalhe. Intervalos fixos entregam comportamento de bot. Use time.sleep(random.uniform(2, 5)) — nunca time.sleep(2).
Rode Proxies (Se Estiver Fazendo Scraping em Escala)
O Craigslist pré-bloqueia faixas inteiras de IPs da AWS, GCP e Azure. Proxies de datacenter geralmente morrem na primeira requisição. Para qualquer volume acima de algumas centenas de páginas, você vai precisar de proxies residenciais rotativos, trocados a cada 20–30 requisições. Proxies móveis têm o menor risco de detecção, mas custam US$ 8–30/GB.
| Tipo de proxy | Risco de detecção no Craigslist | Custo (2025) |
|---|---|---|
| Datacenter | Muito alto — geralmente bloqueado na primeira requisição | US$ 0,50–2/GB |
| Residencial rotativo | Baixo — recomendado | US$ 5–15/GB |
| Móvel | O mais baixo | US$ 8–30/GB |
O modo Cloud Scraping do Thunderbit cuida da rotação de proxies automaticamente, caso você prefira não gerenciar isso sozinho.
Trate CAPTCHAs com Elegância
CAPTCHAs no Craigslist são raros no caminho de leitura — aparecem principalmente nos fluxos de publicação ou resposta. Se um aparecer: faça uma pausa de pelo menos 60 segundos, troque o IP, limpe os cookies e reduza a velocidade. CAPTCHAs persistentes são sinal de que sua cadência está agressiva demais, não um enigma a ser forçado com um resolvedor.
Respeite os Limites e Implemente Backoff
O Craigslist retorna 403 (não 429) quando você estoura o limite de taxa. Um 403 significa que o IP atual entrou em lista de bloqueio — não adianta insistir sem pensar. Troque o IP, mude o UA e aguarde.
1from requests.adapters import HTTPAdapter
2from urllib3.util.retry import Retry
3retry = Retry(
4 total=5,
5 backoff_factor=1.5, # 1,5, 3, 6, 12, 24s
6 status_forcelist=[429, 500, 502, 503, 504],
7 allowed_methods={"GET"},
8 respect_retry_after_header=True,
9)
10adapter = HTTPAdapter(max_retries=retry)
11session.mount("https://", adapter)Mais uma dica: relatos da comunidade apontam consistentemente 2h–6h da manhã no horário local da cidade alvo como a janela mais segura para scraping, com cerca de 30–40% menos bloqueios do que durante o dia.
Fingerprinting TLS — a Armadilha Oculta
A camada anti-bot do Craigslist inspeciona o ClientHello TLS. A biblioteca requests do Python (baseada em OpenSSL) tem um fingerprint JA3 que não bate com o de nenhum navegador real. Um User-Agent perfeito combinado com um fingerprint TLS incompatível é uma discrepância detectável. A solução é usar com impersonate="chrome124", que emula o handshake TLS do Chrome:
1from curl_cffi import requests as cffi_requests
2r = cffi_requests.get(url, headers=HEADERS, impersonate="chrome124")Se você estiver recebendo 403 sem explicação, mesmo com IP residencial limpo e headers corretos, o fingerprint TLS é quase certamente o culpado.
robots.txt, Termos de Uso e Scraping Ético no Craigslist
A maioria dos guias ignora isso por completo ou esconde uma linha solta no FAQ. Considerando que o Craigslist venceu uma sentença de contra um scraper (RadPad, 2017), esse tema merece mais do que uma nota de rodapé.
O que o robots.txt do Craigslist Realmente Diz
O é surpreendentemente curto. Ele tem um único bloco User-agent: * com apenas sete caminhos proibidos:
1Disallow: /reply
2Disallow: /fb/
3Disallow: /suggest
4Disallow: /flag
5Disallow: /mf
6Disallow: /mailflag
7Disallow: /eafOs sete são endpoints interativos/de alteração de estado: responder, denunciar, sugerir, enviar por e-mail. As páginas de anúncios (/search/..., URLs de posts individuais) não estão proibidas. Não há diretiva Crawl-delay, embora o Craigslist imponha algo equivalente via bloqueio de IP.
Os subdomínios das cidades publicam sitemaps — por exemplo, https://newyork.craigslist.org/sitemap/index.xml — que são o caminho oficialmente descobrível para os anúncios.
Precedentes Legais: Os Casos que Importam
Craigslist v. 3Taps (2013, acordo em 2015): a 3Taps raspou anúncios do Craigslist e os revendia. Quando o Craigslist enviou uma notificação de cessação e bloqueou seus IPs, a 3Taps contornou o bloqueio com proxies rotativos. O tribunal entendeu que contornar bloqueios de IP após revogação explícita configurava acesso “sem autorização” sob o CFAA. A 3Taps .
Meta v. Bright Data (2024): uma decisão mais recente concluiu que os termos de uso da Meta não podem proibir scraping de dados públicos quando o usuário está deslogado. O tribunal considerou que o scraper deslogado estava “na mesma posição de um visitante”. Esta é a decisão mais importante para scrapers de 2024–2025 — se você nunca cria uma conta no Craigslist, nunca faz login e acessa só páginas públicas, talvez os termos não sejam executáveis contra você como contrato.
Conclusão prática: o risco sob o CFAA cai bastante após Van Buren (2021) e hiQ v. LinkedIn (2022) para páginas publicamente acessíveis. Mas ações de direito estadual (trespass-to-chattels, misappropriation) continuam possíveis — foi isso que levou tanto o acordo da 3Taps quanto a sentença de US$ 60,5 milhões no caso RadPad.
Isto é conteúdo informativo, não aconselhamento jurídico. Se você for fazer scraping comercial do Craigslist, fale com um advogado.
Checklist Prático de Scraping Ético
- ✅ Respeite todos os
Disallowdo robots.txt — especialmente os sete endpoints de ação - ✅ Fique bem abaixo de 1.000 páginas por período de 24 horas por IP (os termos do Craigslist atribuem acima desse limite como indenização liquidada)
- ✅ Permaneça deslogado — nunca crie uma conta do Craigslist para scraping
- ✅ Nunca contorne bloqueios de IP com proxies depois de um bloqueio explícito (foi isso que derrubou a 3Taps)
- ✅ Adicione atrasos entre requisições — no mínimo 2–5 segundos
- ✅ Não faça scraping de dados de contato pessoais para spam
- ✅ Não redistribua dados brutos do Craigslist nem os apresente como sua própria plataforma
- ✅ Use os dados para pesquisa legítima, análise ou uso pessoal
- ✅ Prefira sitemaps publicados em vez de crawling agressivo sempre que possível
- ✅ Remova PII (e-mails, telefones) na ingestão, se você for armazenar os dados
Escrevemos um guia mais profundo sobre as caso você queira o panorama completo.
Python vs. Sem Código: Qual Abordagem é a Certa para Você?
| Fator | Python (requests + BS4) | Thunderbit (Sem código) |
|---|---|---|
| Tempo de configuração | 30–60 min (instalar, escrever código) | 2 minutos (instalar extensão do Chrome) |
| Habilidade técnica necessária | Python intermediário | Nenhuma |
| Personalização | Controle total sobre lógica, campos e fluxo | A IA detecta os campos automaticamente; o usuário pode ajustar |
| Escala | Ilimitada (com proxies, agendamento) | Scheduled Scraper para tarefas recorrentes |
| Tratamento anti-ban | Manual (headers, atrasos, proxies, TLS) | Embutido (Cloud Scraping) |
| Opções de exportação | CSV, JSON (você implementa) | Google Sheets, Excel, Airtable, Notion — grátis |
| Melhor para | Desenvolvedores, cientistas de dados, pipelines personalizados | Equipes de vendas, corretores, gestores de operações |
Use Python se você precisa de personalização completa, pretende integrar com um pipeline maior de dados ou quer entender exatamente o que acontece por baixo dos panos. Use se quiser resultados rápidos sem escrever ou manter código. Ambos funcionam. A escolha depende do seu caso de uso e de onde você prefere gastar seu tempo: no terminal ou no navegador.
Conclusão
O Craigslist é uma fonte rica e constantemente atualizada de dados sobre imóveis, carros, vagas, serviços, gigs e muito mais — e, sem uma API pública, o scraping é a única forma de obter dados estruturados em escala. A abordagem de 2025 que realmente funciona: extrair o JSON-LD embutido dos resultados de busca (em vez de seletores CSS frágeis), usar requests + BeautifulSoup (em vez de Selenium), adicionar headers realistas com campos Sec-Fetch-*, randomizar atrasos e usar proxies residenciais se você for além de algumas centenas de páginas.
O método JSON-LD é, disparado, a maior melhoria em relação aos guias antigos. Ele é mais rápido, mais resistente a mudanças de layout e não exige renderização de JavaScript. Combine isso com as estratégias anti-ban acima e você evita os 403 que derrubam a maioria dos scrapers.
Se você preferir pular o código por completo, a consegue raspar qualquer categoria do Craigslist em poucos cliques e exportar direto para a planilha ou banco de dados de sua preferência. Se quiser se aprofundar, nossos guias sobre e cobrem os fundamentos com mais detalhe.
FAQs
É legal fazer scraping do Craigslist?
Os Termos de Uso do Craigslist proíbem scraping automatizado e incluem uma cláusula de indenização liquidada (US$ 0,25 por página acima de 1.000/dia). No entanto, decisões judiciais recentes — especialmente Meta v. Bright Data (2024) e hiQ v. LinkedIn (2022) — reduziram a responsabilidade pelo CFAA no scraping deslogado de dados publicamente disponíveis. Ainda existe risco de ações sob direito estadual (trespass-to-chattels), principalmente em redistribuição comercial. Respeite o robots.txt, permaneça deslogado, adicione atrasos e não redistribua dados brutos. Isto é informação geral, não aconselhamento jurídico.
O Craigslist tem uma API pública?
Não. O Craigslist oferece apenas uma Bulk Posting Interface (BAPI) de escrita para anunciantes pagos e aprovados. Não existe API pública de leitura, portal de desenvolvedor nem uma camada com limite de taxa para recuperação de dados. Todo produto de “Craigslist API” que você encontra em plataformas de terceiros é um scraper não oficial.
Por que meu scraper do Craigslist vive quebrando?
Quase sempre por causa de mudanças na estrutura do HTML. O Craigslist reescreveu a marcação dos resultados de busca em 2023–2024, e guias que usam seletores antigos como .result-row ou .result-info já não funcionam. Troque para o método JSON-LD embutido (analisando script#ld_searchpage_results) para uma abordagem muito mais resiliente. Verifique também se seus headers incluem campos Sec-Fetch-* — a ausência deles dispara bloqueios instantâneos.
Posso fazer scraping do Craigslist sem Python?
Sim. A extensão de Chrome do Thunderbit com IA funciona em qualquer página do Craigslist — apartamentos, carros, vagas, serviços. Clique em "AI Suggest Fields" para detectar colunas automaticamente, clique em "Scrape" para extrair os dados e exporte para Google Sheets, Excel, Airtable ou Notion gratuitamente. Sem código, sem configuração, sem gerenciamento de proxies.
Com que frequência posso fazer scraping do Craigslist sem ser banido?
Com um IP residencial único, a vazão sustentável fica em torno de 0,3–0,5 requisições por segundo, com atrasos aleatórios de 2–5 segundos entre páginas. Fique abaixo de 1.000 páginas por período de 24 horas por IP para evitar tanto banimentos quanto o limite de indenização liquidada nos termos do Craigslist. Fazer scraping fora do horário de pico (2h–6h da manhã no horário local da cidade alvo) reduz as taxas de bloqueio em cerca de 30–40%. Para volumes maiores, alterne proxies residenciais a cada 20–30 requisições.
Saiba mais