Resumo executivo
O fez uma pergunta de política: quantos dos sites mais visitados do mundo estão a dizer aos crawlers de IA o que eles podem e não podem fazer?
Este seguimento faz a pergunta operacional por trás disso: quão fiável é o robots.txt como a infraestrutura que agora está a ser chamada para carregar essa política?
A resposta é desconfortável. O robots.txt ainda funciona porque é público, barato, legível por máquina e já é compreendido pelos crawlers. Mas também está a ser usado para muito mais do que foi criado para fazer. Em 2026, o mesmo ficheiro de texto simples pode conter controlos de rastreio para SEO, índices de sitemap, extensões legadas de motores de busca, recusas de uso para treino de IA, vocabulário de política injetado pela Cloudflare, reservas de direitos de autor e linguagem jurídica orientada para disputas futuras.
Isto é dívida de configuração.
O conjunto de dados por trás deste relatório é o mesmo crawl do Tranco Top 10.000 usado no estudo original sobre crawlers de IA. Dos 10.000 domínios, 6.638 devolveram um robots.txt legível; outros 610 devolveram 404, que o protocolo trata como permissão implícita. Isto dá-nos 7.248 sites analisáveis para decisões de acesso de bots e 6.638 ficheiros concretos para analisar a complexidade de configuração.
Seis conclusões destacam-se:
-
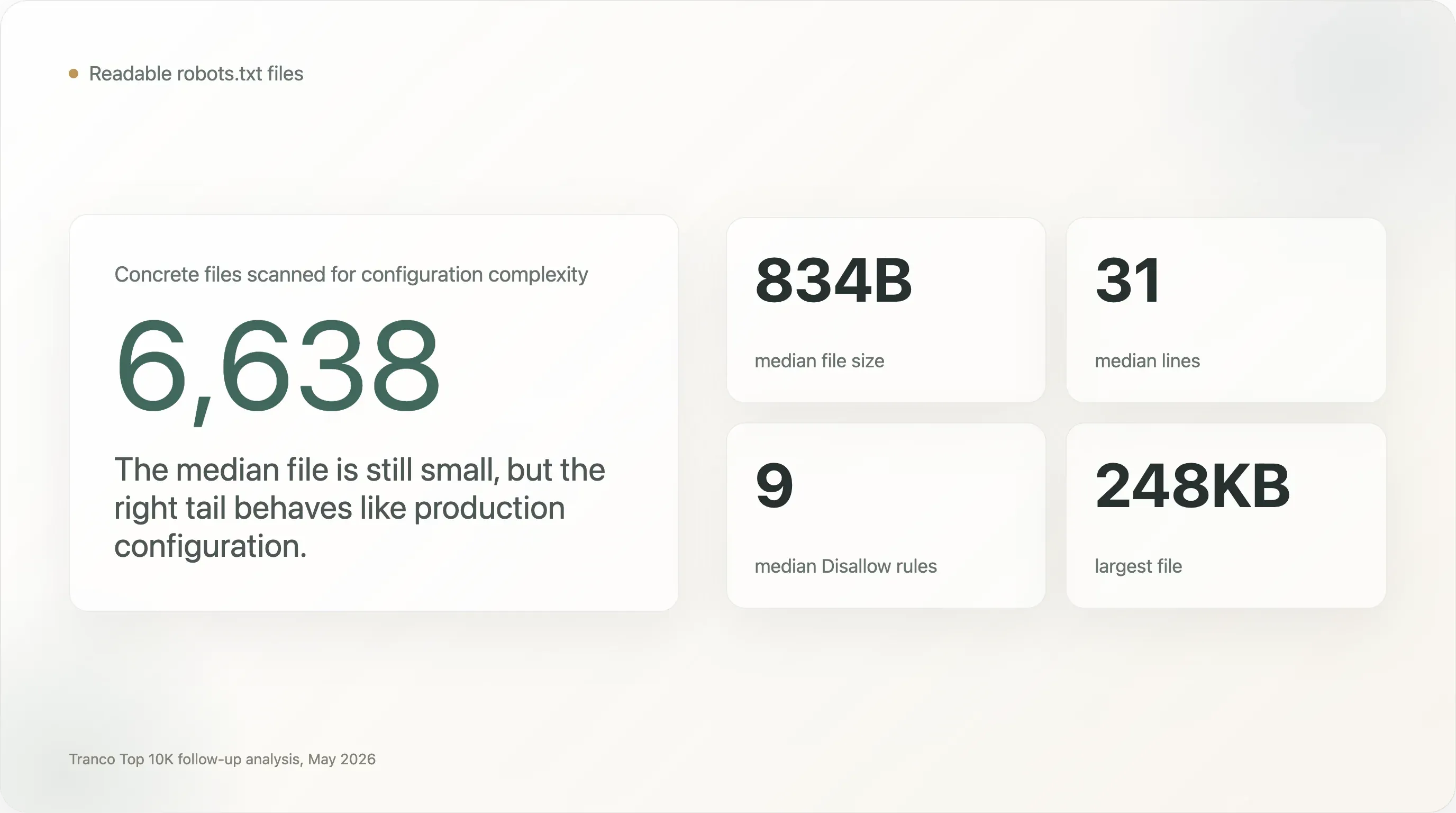
A maioria dos ficheiros
robots.txté pequena, mas a cauda direita é extremamente complexa. O ficheiro mediano tem apenas 834 bytes e 31 linhas. Mas 1.005 ficheiros têm pelo menos 5 KB, 273 têm pelo menos 20 KB e 28 têm pelo menos 100 KB. O maior ficheiro da amostra tem 248 KB. -
Centenas dos principais sites operam ficheiros que se parecem mais com configuração de produção do que com notas de política. O ficheiro mediano tem 9 diretivas
Disallow. Mas 707 sites têm pelo menos 100 regrasDisallow, 13 têm pelo menos 1.000, 240 nomeiam pelo menos 50 user agents e 110 nomeiam pelo menos 100 user agents. -
O desvio ao protocolo não é teórico. Entre os 6.638 ficheiros legíveis, 685 contêm
Crawl-delay, 303 contêmHost, 200 contêmClean-param, 9 contêmRequest-rate, 5 contêmVisit-timee 271 contêm linguagem do tipoContent-Signalda Cloudflare. Nem tudo isto faz parte do mesmo padrão limpo. É folclore acumulado de crawlers. -
O Googlebot é tratado como um cidadão especial. 562 domínios analisáveis bloqueiam pelo menos um crawler de pesquisa tradicional. Em 404 desses casos, o Googlebot é permitido enquanto pelo menos outro crawler de pesquisa é bloqueado. A discriminação contra crawlers de IA não surgiu num ecossistema neutro; o
robots.txtjá codificava uma hierarquia entre motores de busca. -
A política de IA torna a dívida mais visível. 1.377 ficheiros legíveis contêm linguagem de política de IA; 719 contêm linguagem sobre copyright, termos, licenciamento ou permissão; e 501 contêm as duas coisas. O ficheiro tornou-se ao mesmo tempo interface de máquina e artefacto jurídico. Isso é útil, mas frágil.
-
Os ficheiros mais arriscados nem sempre são os mais anti-IA. Ecommerce, viagens, redes sociais, finanças, academia e notícias produzem ficheiros complexos por motivos diferentes: controlo de orçamento de crawl, caminhos legados, conteúdo gerado por utilizadores, reservas de direitos e exceções específicas para bots. As regras de IA estão a ser sobrepostas a uma base já confusa.
A conclusão principal: o robots.txt continua a ser a superfície pública mais importante da web para política de crawlers, mas é uma base fraca para governação de IA de alto risco, a menos que o ecossistema padronize a identidade dos crawlers, o vocabulário de uso de IA e a auditabilidade da política.
Metodologia
Este relatório reaproveita o conjunto de dados da análise original da Thunderbit sobre política de crawlers de IA nos domínios Tranco Top 10.000.
Os materiais de entrada foram:
tranco_top10k.csv— a lista original dos 10 mil domínios do Tranco.out/fetch_meta.csv— status de busca, contagem de bytes, esquema, resultado de redirecionamento e metadados de erro.out/sites.csv— domínio, classificação, categoria, idioma e status dorobots.txt.out/site_meta.csv— uma linha analítica por site, incluindo classe de modelo, sinalizadores de bloqueio de IA, tamanho do ficheiro e campos de resumo da política de bots.out/bot_status.csv— uma linha por domínio e crawler, incluindo se o bot está bloqueado e se existe uma regra específica.raw_robots/— corpos em cache dorobots.txtpara os 6.638 sites que devolveram status200.
Para este seguimento, cada ficheiro robots.txt legível foi analisado para:
- tamanho do ficheiro e contagem de linhas;
- linhas ativas não comentadas;
- contagem de diretivas
User-agent,Disallow,AlloweSitemap; - diretivas legadas ou fora do núcleo, como
Crawl-delay,Host,Clean-param,Request-rateeVisit-time; - vocabulário da era da IA, incluindo
Content-Signal,llms.txt, AI, LLM, machine learning, TDM e2019/790; - vocabulário jurídico, como copyright, termos de serviço, licenciamento, permissão e linguagem de reserva de direitos;
- tratamento de crawlers de pesquisa para Googlebot, Bingbot, DuckDuckBot, Slurp, Baiduspider e YandexBot.
O relatório também define uma pontuação simples de dívida de configuração para triagem. Ela combina tamanho do ficheiro, contagem de user agents, contagem de Disallow, contagem de Allow, contagem de diretivas não padronizadas e a mistura de linguagem de política de IA e jurídica. A pontuação não pretende ser uma medida universal de correção. É uma forma de identificar ficheiros que provavelmente serão difíceis de manter, rever ou perceber.
Todas as tabelas e gráficos derivados estão incluídos na pasta de entrega.
Descoberta 1: o ficheiro mediano é simples; a cauda não é
O ficheiro robots.txt típico na web mais visitada ainda é pequeno.
Entre os 6.638 ficheiros legíveis:
| Métrica | Mediana | P90 | P95 | P99 | Máx. |
|---|---|---|---|---|---|
| Tamanho do ficheiro | 834 bytes | 6,7 KB | 15,8 KB | 76,0 KB | 248,3 KB |
| Linhas | 31 | 238 | 332 | 1.008 | 4.998 |
| Linhas ativas | 23 | 198 | 282 | 837 | 4.998 |
diretivas User-agent | 1 | 21 | 39 | 137 | 823 |
diretivas Disallow | 9 | 103 | 176 | 422 | 4.997 |
diretivas Allow | 1 | 17 | 33 | 69 | 890 |
Esta distribuição importa porque o robots.txt é muitas vezes discutido como se fosse uma declaração pequena:
1User-agent: *
2Disallow: /private/Esse modelo mental está errado para uma minoria significativa da web de elevado tráfego.
Neste conjunto de dados:
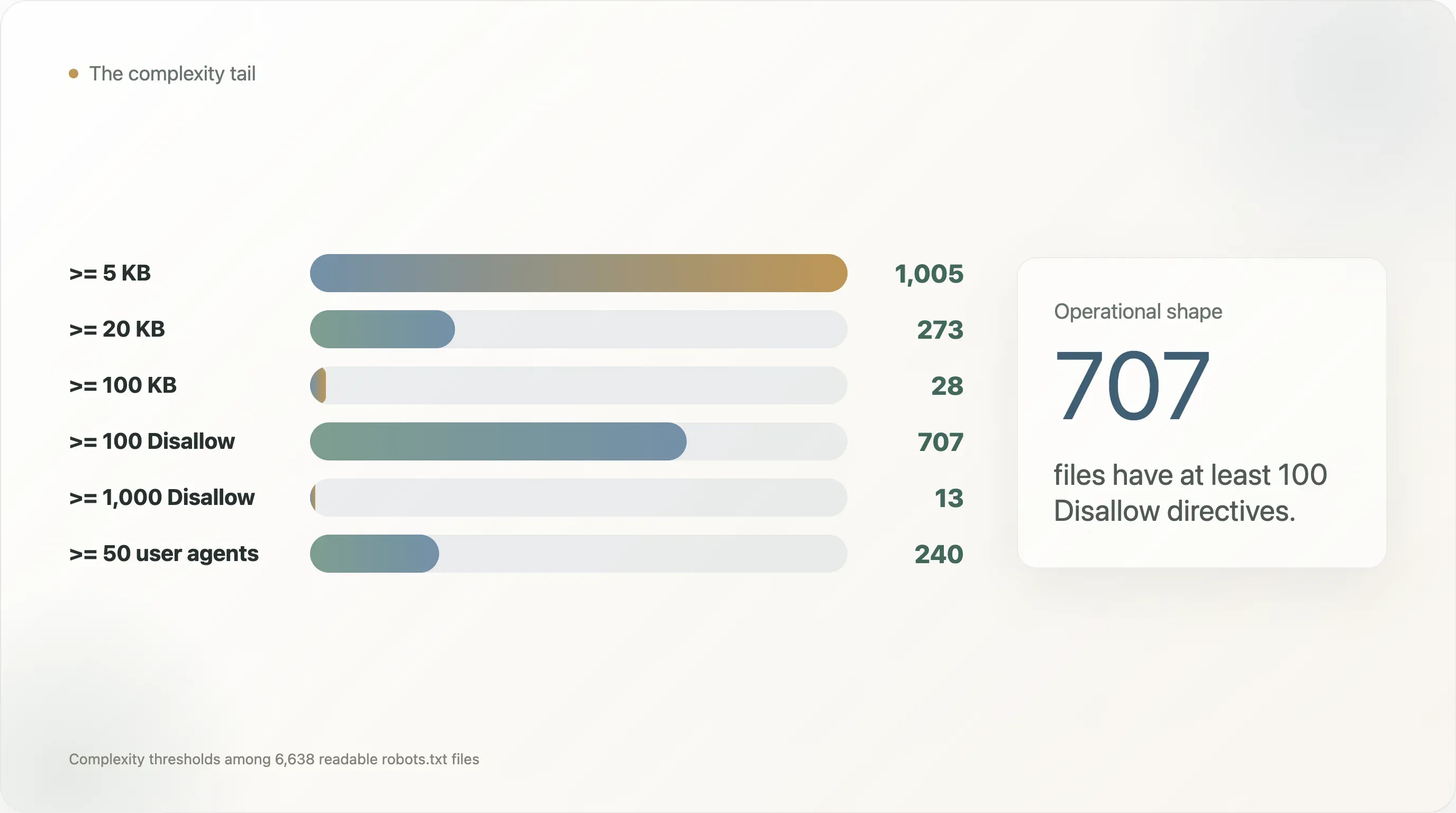
| Limiar de complexidade | Sites |
|---|---|
robots.txt maior ou igual a 5 KB | 1.005 |
| Maior ou igual a 20 KB | 273 |
| Maior ou igual a 100 KB | 28 |
Pelo menos 50 diretivas User-agent | 240 |
Pelo menos 100 diretivas User-agent | 110 |
Pelo menos 100 diretivas Disallow | 707 |
Pelo menos 1.000 diretivas Disallow | 13 |
Pelo menos 100 diretivas Allow | 40 |
Os ficheiros maiores e mais complexos não são curiosidades académicas. Pertencem a propriedades reais e de elevado tráfego:
| Domínio | Rank | Categoria | Bytes | User-agent | Disallow | Allow |
|---|---|---|---|---|---|---|
linkedin.com | 17 | social | 114.341 | 76 | 4.184 | 281 |
runescape.com | 5.226 | desconhecida | 113.393 | 1 | 4.997 | 0 |
academia.edu | 832 | academia | 57.384 | 63 | 2.044 | 227 |
etsy.com | 286 | ecommerce | 51.320 | 3 | 1.621 | 120 |
thepaper.cn | 9.395 | notícias | 56.867 | 1 | 1.496 | 0 |
opentable.com | 4.137 | desconhecida | 70.494 | 32 | 1.683 | 176 |
alfabank.ru | 2.625 | finanças | 73.158 | 2 | 1.566 | 133 |
Estes ficheiros estão mais perto de tabelas de encaminhamento de produção do que de slogans de política. Codificam anos de lançamentos de produto, caminhos legados, padrões de parâmetros bloqueados, exceções para crawlers, experiências de SEO, decisões de CDN e, agora, regras para crawlers de IA.
A cauda não é só uma história sobre IA. Dos 273 ficheiros com pelo menos 20 KB, 131 contêm linguagem de política de IA e 142 não contêm. Dos 707 ficheiros com pelo menos 100 diretivas Disallow, apenas 207 contêm linguagem de política de IA. Por outras palavras, a IA não criou o problema dos ficheiros grandes. Chegou depois de anos de operações normais da web já terem enchido o ficheiro com regras de caminho, referências de sitemap e exceções para crawlers.
Isto importa porque a capacidade de manutenção depende da forma, não apenas da intenção. Um ficheiro pequeno com um bloqueio direto de IA pode ser fácil de auditar. Um ficheiro de ecommerce ou viagens de 70 KB pode ser difícil de auditar mesmo que não diga nada sobre IA. O risco não é que todo o ficheiro grande esteja errado. O risco é que a política efetiva fique difícil demais para as pessoas responsáveis verificarem.
O risco operacional é direto: à medida que o robots.txt cresce, fica mais difícil para um editor, engenheiro de plataforma, advogado ou líder de SEO responder à pergunta básica: o que é que este ficheiro realmente permite?
Essa pergunta já não é trivial. Numa análise ao estilo RFC, um crawler pode corresponder a um grupo mais específico de user-agent em vez de User-agent: *; correspondências de caminho mais longas podem substituir as mais curtas; diretivas Allow e Disallow interagem por precedência; e regras genéricas de bloqueio total podem capturar acidentalmente novos crawlers que não existiam quando o ficheiro foi escrito.
Para um ficheiro de 30 linhas, uma pessoa pode raciocinar sobre isso. Para um ficheiro de 4.000 linhas com dezenas de bots nomeados, ninguém devia tentar.
Descoberta 2: o robots.txt está a carregar mais do que regras de rastreamento
O debate sobre crawlers de IA tornou o robots.txt politicamente visível, mas o ficheiro subjacente já vinha a acumular responsabilidades não relacionadas.
Um robots.txt moderno de um grande site pode incluir:
- controlos de caminho para crawlers;
- descoberta de sitemap;
- extensões específicas para motores de busca;
- dicas de taxa de crawl;
- dicas de canonicalização de host;
- dicas de limpeza de parâmetros de URL;
- vocabulário de política injetado pela CDN;
- texto de reserva de direitos de autor;
- recusas de uso para treino de IA;
- comentários jurídicos legíveis por humanos.
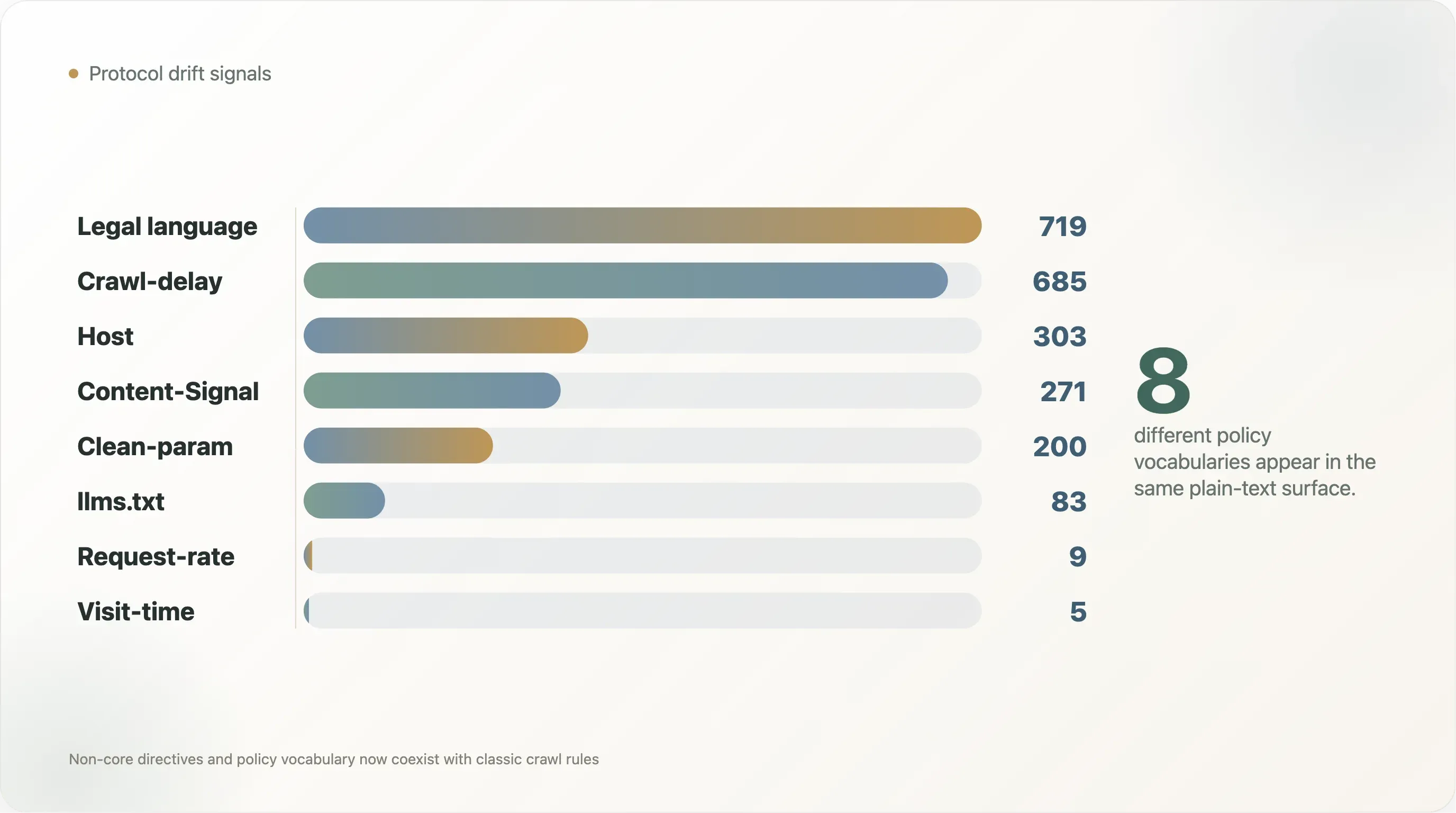
O conjunto de dados mostra claramente esta sobreposição.
| Sinal | Ficheiros | Participação nos ficheiros legíveis |
|---|---|---|
Crawl-delay | 685 | 10,3% |
Host | 303 | 4,6% |
Clean-param | 200 | 3,0% |
Content-Signal | 271 | 4,1% |
Request-rate | 9 | 0,1% |
Visit-time | 5 | 0,1% |
menção a llms.txt | 83 | 1,3% |
| Linguagem sobre copyright, termos, licenciamento ou permissão | 719 | 10,8% |
| Linguagem de política de IA | 1.377 | 20,7% |
Algumas destas diretivas são amplamente reconhecidas por crawlers específicos. Algumas são convenções legadas. Algumas são específicas de fornecedores. Algumas nem sequer são verdadeiras diretivas de crawler, mas linguagem jurídica ou de produto embutida em comentários.
É isto que o desvio do protocolo parece.
Crawl-delay é um bom exemplo. É familiar para muitos operadores de sites, mas o suporte é irregular entre os principais crawlers. Host e Clean-param estão historicamente associados ao comportamento do Yandex. Content-Signal faz parte do vocabulário de política da Cloudflare para a era da IA. llms.txt é um formato adjacente proposto para descoberta, não um padrão universalmente respeitado. Ainda assim, tudo isto aparece no mesmo tipo de ficheiro, muitas vezes ao lado das regras clássicas User-agent e Disallow.
Os números também mostram como convenções antigas e novas agora coexistem. Crawl-delay aparece em 685 ficheiros, mais do dobro dos 271 ficheiros com Content-Signal. Host aparece em 303 ficheiros e Clean-param em 200, refletindo sobretudo convenções da era dos motores de busca. llms.txt, apesar da discussão intensa em círculos de pesquisa com IA, é mencionado em apenas 83 ficheiros legíveis. A web em produção não está a convergir para um vocabulário único. Está a empilhar vocabulários.
O problema não é que qualquer extensão isolada esteja errada. O problema é que o ficheiro se tornou um contentor sem versão para vários sistemas de governação sobrepostos.
Isto cria três tipos de dívida:
- Dívida semântica. Diferentes crawlers podem interpretar o mesmo ficheiro de maneiras diferentes.
- Dívida de responsabilidade. Equipas de SEO, jurídico, infraestrutura, segurança e produto podem ter motivos para editar o ficheiro, mas talvez nenhuma equipa seja dona de toda a política.
- Dívida de auditoria. Um site pode publicar uma política que parece intencional enquanto apenas um parser consegue determinar o seu comportamento efetivo.
A IA torna isto mais importante porque os riscos mudaram. Quando uma dica legada de taxa de crawl é ignorada, o resultado pode ser tráfego extra. Quando uma recusa de uso para treino de IA é ambígua, o resultado pode tornar-se prova numa disputa de copyright ou licenciamento.
Descoberta 3: o ficheiro tornou-se ao mesmo tempo interface de máquina e artefacto jurídico
O relatório original sobre crawlers de IA mostrou que 17,0% dos sites analisáveis tinham escrito regras explícitas específicas para IA. Este seguimento observa o peso textual que essas políticas acrescentam.
Entre os 6.638 ficheiros robots.txt legíveis:
- 1.377 contêm linguagem de política de IA;
- 719 contêm linguagem sobre copyright, termos, licenciamento, direitos ou permissão;
- 271 contêm
Content-Signal; - 83 mencionam
llms.txt.
A sobreposição é onde a história fica mais interessante:
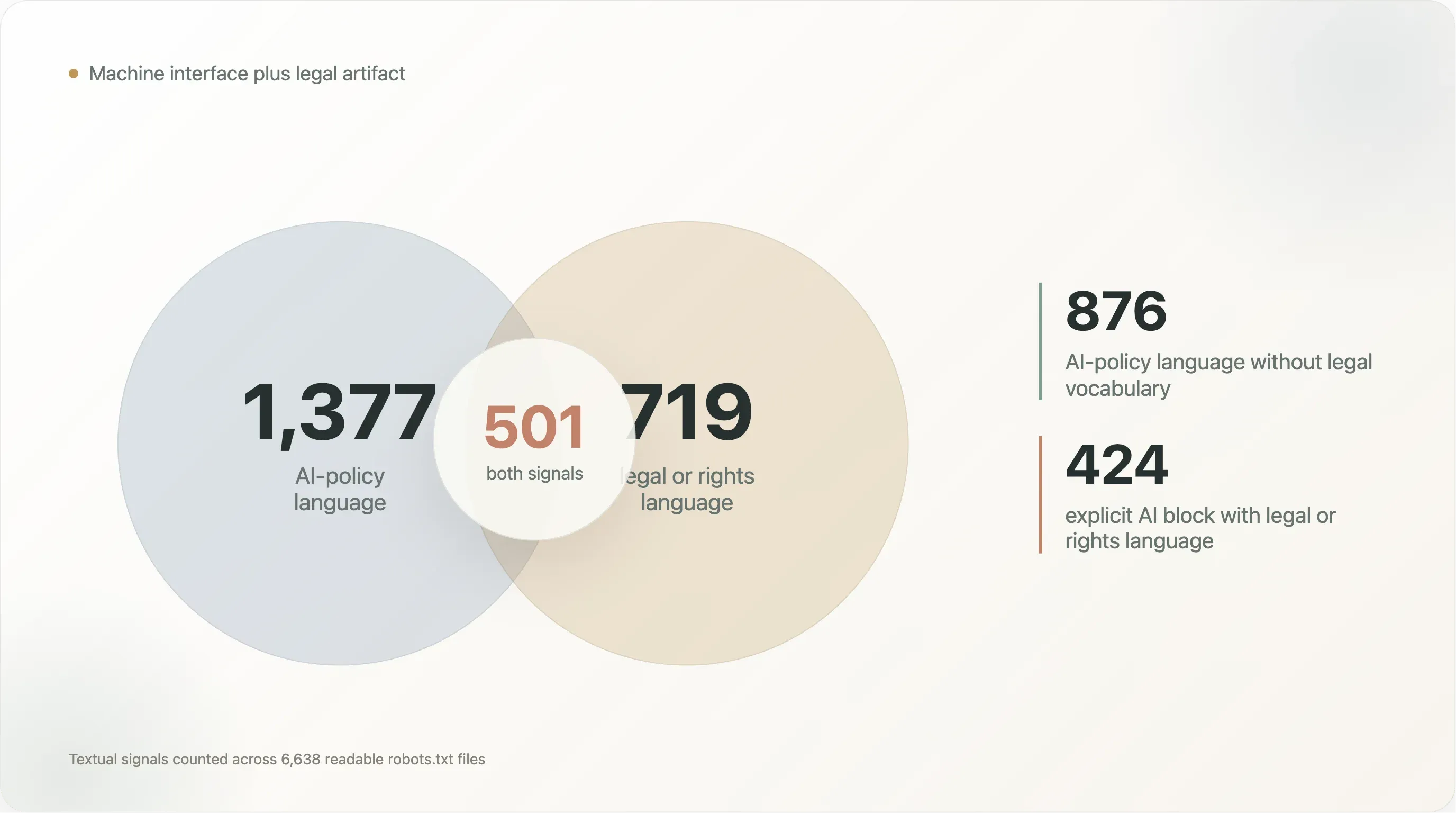
| Padrão textual | Ficheiros |
|---|---|
| Linguagem de política de IA e linguagem jurídica/de direitos | 501 |
| Linguagem de política de IA sem linguagem jurídica/de direitos | 876 |
| Linguagem jurídica/de direitos sem linguagem de política de IA | 218 |
Content-Signal com linguagem jurídica/de direitos | 242 |
| Bloqueio explícito de IA com linguagem jurídica/de direitos | 424 |
Isto é um novo tipo de ficheiro.
Um ficheiro robots.txt tradicional é dirigido a crawlers. Um ficheiro robots.txt com preâmbulo jurídico é dirigido a pelo menos quatro públicos ao mesmo tempo:
- operadores de crawler, que precisam de diretivas legíveis por máquina;
- fornecedores de pesquisa e IA, que precisam de sinais de política;
- advogados, que querem reserva explícita de direitos;
- futuros auditores, tribunais ou jornalistas, que podem ler os comentários como evidência de intenção.
Este design para múltiplos públicos explica por que razão alguns ficheiros agora parecem documentos de política. Mas também enfraquece a separação limpa entre o que um crawler pode analisar e o que um advogado quer declarar.
Os 876 ficheiros com linguagem de política de IA, mas sem vocabulário jurídico, são em grande parte ficheiros de política para máquinas: nomes de bots, blocos Disallow e linguagem de template. Os 501 ficheiros com linguagem de IA e jurídica ao mesmo tempo são diferentes. Estão a tentar ser instruções para crawlers e reservas de direitos ao mesmo tempo. Os 218 ficheiros com linguagem jurídica, mas sem vocabulário de IA, mostram que este padrão não começou com LLMs; o robots.txt já era usado para declarar termos, limites de permissão e reivindicações de direitos.
Por exemplo, um comentário pode dizer que machine learning é proibido, enquanto o bloco de diretivas real apenas desautoriza um subconjunto de user agents conhecidos. Um site pode afirmar direitos de forma ampla, mas nomear apenas alguns crawlers. Um template de CDN pode injetar vocabulário relacionado com IA num ficheiro cujo operador nunca escreveu manualmente a linguagem jurídica. Um site pode escrever uma regra ampla User-agent: * que bloqueia inadvertidamente futuros crawlers.
Do ponto de vista da governação, o robots.txt tornou-se atraente precisamente porque é público e legível por máquina. Mas quanto mais política ele carrega, mais as suas limitações importam:
- não há camada de autenticação a provar que uma política específica foi revista pelo titular dos direitos, em vez de herdada da infraestrutura;
- não há histórico nativo de versões;
- não há campo estruturado para uso pretendido, como treino, recuperação, indexação de pesquisa, resumo, cache ou avaliação de modelo;
- não há registo universal de identidades de crawlers de IA;
- não há mecanismo de aplicação.
Isto não torna o ficheiro inútil. Torna-o frágil.
A melhor interpretação é que o robots.txt está a tornar-se uma camada de aviso: uma declaração pública e inspecionável de preferência e intenção. Por si só, não é um sistema completo de gestão de direitos.
Descoberta 4: a pesquisa já era desigual antes da chegada da IA
Uma das descobertas mais fortes do relatório original foi que muitos publishers diferenciam entre crawlers de treino de IA e crawlers de pesquisa. Bloqueiam CCBot, GPTBot ou Google-Extended enquanto preservam a visibilidade no Google Search.
Este seguimento acrescenta um ponto diferente: os crawlers tradicionais de pesquisa também não são tratados de forma igual.
Verificámos seis crawlers de pesquisa:
- Googlebot;
- Bingbot;
- DuckDuckBot;
- Slurp;
- Baiduspider;
- YandexBot.
Entre os 7.248 sites analisáveis:
| Tratamento do crawler de pesquisa | Sites |
|---|---|
| Bloqueia pelo menos um crawler de pesquisa | 562 |
| Permite Googlebot, mas bloqueia pelo menos outro crawler de pesquisa | 404 |
| Bloqueia os seis crawlers de pesquisa verificados | 152 |
Os contadores de bots bloqueados não se distribuem de forma uniforme:
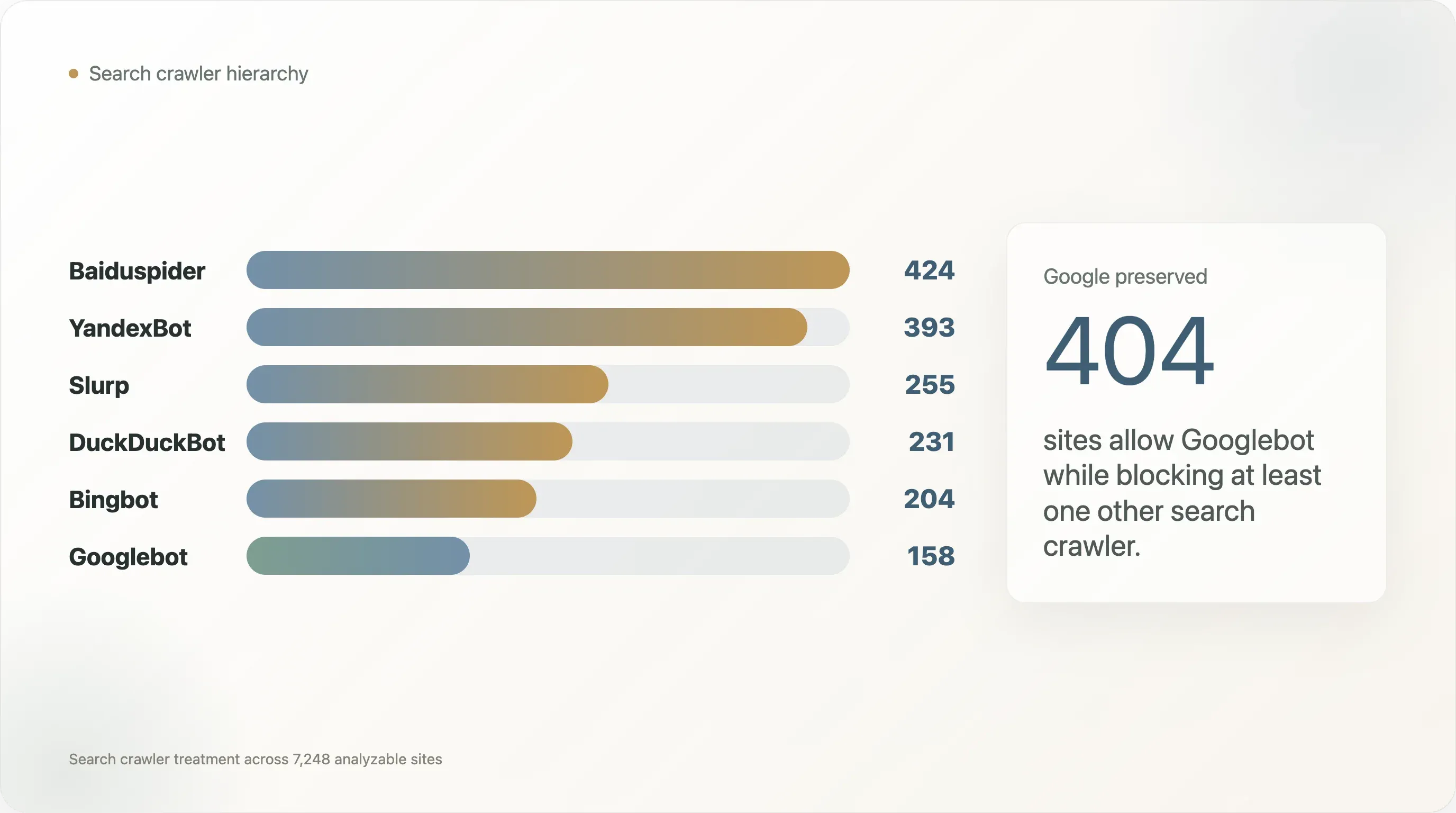
| Crawler de pesquisa | Sites que o bloqueiam |
|---|---|
| Baiduspider | 424 |
| YandexBot | 393 |
| Slurp | 255 |
| DuckDuckBot | 231 |
| Bingbot | 204 |
| Googlebot | 158 |
Googlebot é o crawler menos bloqueado neste conjunto. Baiduspider e YandexBot são bloqueados com muito mais frequência, e na maioria desses casos o Googlebot continua permitido. Entre os 404 sites que permitem Googlebot enquanto bloqueiam outro crawler de pesquisa, 269 bloqueiam Baiduspider e 240 bloqueiam YandexBot.
Os exemplos são de alto perfil:
| Domínio | Crawlers de pesquisa bloqueados enquanto Googlebot é permitido |
|---|---|
facebook.com | Baiduspider, YandexBot |
apple.com | Baiduspider |
twitter.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
netflix.com | DuckDuckBot, Slurp |
x.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
tiktok.com | Baiduspider |
baidu.com | Bingbot, DuckDuckBot, Slurp, YandexBot |
washingtonpost.com | YandexBot |
wsj.com | YandexBot |
bilibili.com | DuckDuckBot, Slurp, YandexBot |
temu.com | Slurp |
t-mobile.com | Baiduspider, YandexBot |
Isto importa para o debate sobre IA porque mostra que o robots.txt já não era um protocolo neutro de acesso universal antes da chegada dos crawlers de LLM. A web pública já tinha uma hierarquia:
- o Googlebot costuma ser preservado porque o tráfego de pesquisa do Google é demasiado valioso para arriscar;
- crawlers regionais ou de concorrentes são mais fáceis de bloquear;
- alguns sites tratam o acesso de crawlers de pesquisa como uma decisão por mercado ou por fornecedor.
Os crawlers de IA entraram num ecossistema em que o acesso diferenciado já era normal.
Isto torna a transição de política mais fácil de compreender. Um publisher que escreve "bloqueie Google-Extended, permita Googlebot" não está a inventar uma nova forma de discriminação. Está a aplicar um padrão antigo a uma nova classe de crawler: preservar distribuição, restringir extração.
A questão em aberto é se esse padrão antigo escala. Com pesquisa, havia apenas alguns crawlers economicamente importantes. Com IA, a identidade dos crawlers está fragmentada entre fornecedores de modelos, bots de recuperação, corretores de dados, crawlers académicos, agentes sintéticos de navegador e motores de busca ao nível da infraestrutura. O número de user agents nomeados continuará a crescer, a menos que o ecossistema se consolide num conjunto mais pequeno de sinais baseados em finalidade.
É assim que a dívida de configuração se acumula.
Descoberta 5: a complexidade varia por setor, mas não da mesma forma que as taxas de bloqueio de IA
O relatório original mostrou uma grande variação setorial no bloqueio de IA: notícias bloqueiam em taxas altas; telecom, governo e SaaS bloqueiam em taxas baixas.
A complexidade de configuração corta a web de outra forma.
Entre categorias selecionadas com ficheiros robots.txt legíveis suficientes para comparação útil:
| Categoria | n | Bytes medianos | Bytes P90 | Disallow mediano | Disallow P90 | User-agent mediano | User-agent P90 |
|---|---|---|---|---|---|---|---|
| ecommerce | 215 | 1.738 | 10.388 | 37 | 164 | 3 | 49 |
| viagens | 63 | 2.074 | 27.368 | 41 | 779 | 5 | 34 |
| notícias | 647 | 1.534 | 7.039 | 19 | 114 | 6 | 68 |
| finanças | 121 | 1.002 | 8.337 | 17 | 132 | 2 | 23 |
| academia | 253 | 839 | 3.959 | 14 | 75 | 1 | 11 |
| governo | 151 | 1.227 | 3.263 | 13 | 46 | 1 | 4 |
| SaaS | 368 | 485 | 12.606 | 4 | 56 | 1 | 10 |
| ferramentas de desenvolvimento | 119 | 273 | 9.255 | 3 | 58 | 1 | 10 |
P90 Disallow by category chart here<<<<<<<<<<<<<<<<<<<<<<<<<
Notícias são politicamente complexas porque escrevem regras explícitas de IA e texto jurídico. Mas ecommerce e viagens são operacionalmente complexos porque têm catálogos grandes, navegação facetada, páginas de resultados de pesquisa, filtros, caminhos de conta de utilizador e URLs parametrizados.
Esta distinção é importante.
Viagens é o exemplo mais claro. Tem apenas 63 ficheiros legíveis nesta fatia da categoria, mas o seu robots.txt P90 tem 27,4 KB e a sua contagem P90 de Disallow é 779, muito acima de notícias. Isto não significa que os sites de viagens tenham uma política de IA mais desenvolvida. Significa que têm mais superfícies nas quais os operadores de crawler podem desperdiçar orçamento por acidente: pesquisas por datas, páginas de disponibilidade, paginação de avaliações, fluxos de reserva, combinações de filtros e caminhos de inventário localizados.
SaaS é o tipo oposto de surpresa. O seu ficheiro mediano tem apenas 485 bytes, mas o ficheiro P90 sobe para 12,6 KB. A maioria dos sites SaaS é aberta e leve; um subconjunto menor carrega ficheiros longos de controlo de caminhos, muitas vezes porque documentação, superfícies de início de sessão, rotas de aplicação e páginas de marketing vivem sob o mesmo domínio.
Notícias ficam no meio do caminho operacionalmente, mas perto do topo politicamente. A sua contagem P90 de User-agent é 68, maior do que ecommerce, viagens, finanças, academia, governo, SaaS e ferramentas de desenvolvimento nesta tabela. Isso é sinal de política específica por bot, e não apenas de higiene de caminhos.
O robots.txt de um publisher pode ser complexo por causa de política de direitos. O de um marketplace pode ser complexo por causa da gestão do orçamento de crawl. O de uma universidade pode ser complexo porque milhares de caminhos legados se acumularam sob um único domínio. O de uma plataforma social pode ser complexo porque precisa de expor algumas superfícies e suprimir outras em grande escala.
A política de IA é colocada sobre tudo isto. Não substitui os motivos existentes que tornam um ficheiro complexo.
Isto ajuda a explicar por que razão a governação de robots.txt na era da IA não pode ser resolvida com uma lista de bloqueio universal. Os ficheiros subjacentes têm trabalhos diferentes:
- sites de ecommerce gerem caminhos duplicados e superfícies de inventário;
- sites de viagens gerem listagens, calendários, avaliações e páginas de pesquisa dinâmicas;
- sites de notícias gerem copyright, arquivos e postura de licenciamento;
- sites de SaaS e de ferramentas de desenvolvimento muitas vezes querem visibilidade em IA;
- governos geralmente precisam de acesso público, mas ainda podem ter sistemas sensíveis a excluir;
- plataformas sociais gerem conteúdo gerado por utilizadores, superfícies de perfil e preocupações com abuso.
A mesma regra para um crawler de IA significa coisas diferentes em cada ambiente.
Descoberta 6: um índice de dívida de configuração identifica risco de revisão, não falha moral
Esta análise criou uma pontuação simples de dívida de configuração para identificar ficheiros robots.txt que provavelmente serão difíceis de rever.
A pontuação pondera:
- tamanho do ficheiro;
- número de diretivas
User-agent; - número de diretivas
Disallow; - número de diretivas
Allow; - número de diretivas não essenciais;
- presença de linguagem de política de IA;
- mistura de bloqueio explícito de IA e linguagem jurídica ou de copyright.
Isto não é uma pontuação de correção. Um ficheiro de alta complexidade pode ser perfeitamente intencional. Um ficheiro de baixa complexidade ainda pode estar errado. O objetivo é triagem: se um ficheiro é grande, carregado de política, específico para bots e cheio de exceções, merece uma disciplina de revisão mais forte.
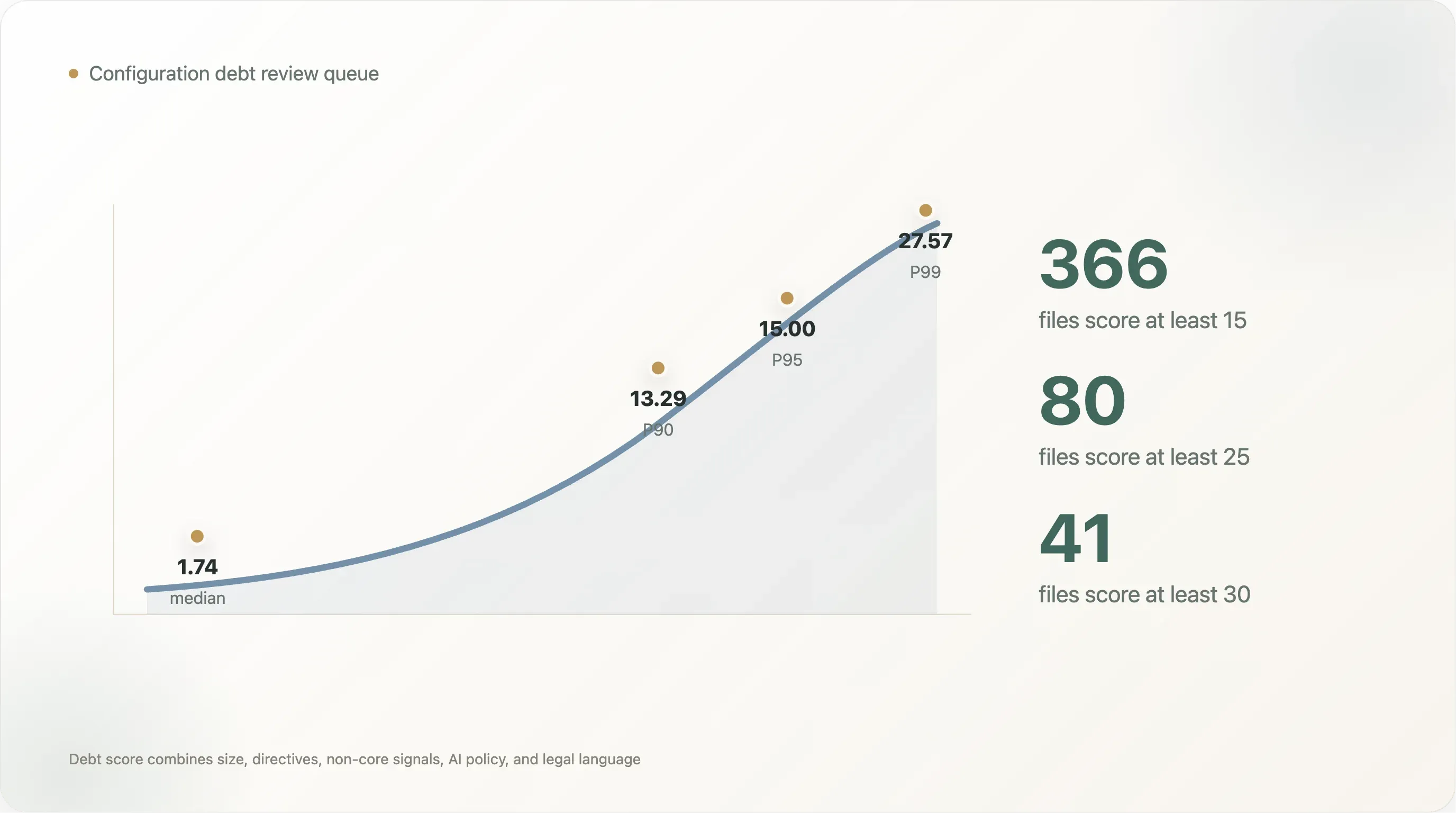
A distribuição da pontuação é acentuada. O ficheiro legível mediano pontua 1,74. O P90 é 13,29, o P95 é 15,00 e o P99 é 27,57. Apenas 366 ficheiros pontuam pelo menos 15, 80 pontuam pelo menos 25 e 41 pontuam pelo menos 30. Esta é a fila de revisão prática: nem todo o site precisa de um projeto de governação, mas a cauda superior precisa.
A visão por categoria também mostra por que um único rótulo de "bloqueador de IA" é simplista demais:
| Categoria | Pontuação mediana | Pontuação P90 |
|---|---|---|
| viagens | 4,92 | 28,94 |
| busca | 2,97 | 24,23 |
| social | 2,25 | 15,00 |
| notícias | 4,91 | 14,92 |
| finanças | 1,67 | 12,61 |
| SaaS | 0,98 | 11,85 |
| ecommerce | 3,88 | 10,87 |
| governo | 1,57 | 6,38 |
Viagens e busca têm as maiores pontuações P90 porque uma minoria de ficheiros se torna muito grande e carregada de regras. Notícias tem uma das maiores pontuações medianas porque a linguagem de política e o tratamento específico por bot são mais comuns em toda a categoria. Ecommerce tem uma contagem mediana alta de Disallow, mas a sua pontuação de dívida P90 é menor do que a de viagens porque a complexidade está mais concentrada em regras de caminho do que em sinais mistos de política e linguagem jurídica.
Os ficheiros com maior pontuação neste conjunto de dados incluem:
| Domínio | Porque a pontuação é alta |
|---|---|
linkedin.com | Ficheiro muito grande, milhares de regras de caminho, muitos user agents nomeados, linguagem explícita de política de IA |
lnkd.in | A mesma superfície de política da infraestrutura de encurtamento de links do LinkedIn |
fragrantica.com | Centenas de blocos de user-agent nomeados mais linguagem de política de IA |
sovcombank.ru | Centenas de blocos de user-agent e linguagem jurídica/de política |
academia.edu | Grande matriz de allow/disallow e política explícita de bloqueio de IA |
opentable.com | Grande conjunto de regras de caminho, muitas diretivas de sitemap, superfície de política relacionada com IA |
etsy.com | Ficheiro grande de controlo de caminhos de ecommerce com mais de 1.600 regras Disallow |
runescape.com | Quase 5.000 diretivas Disallow sob um único grupo de user-agent |
Estes ficheiros não devem ser ridicularizados por serem complexos. A complexidade muitas vezes reflete necessidades reais de negócio. Mas mostram por que razão a política de robots.txt merece a mesma disciplina de engenharia que outras configurações de produção:
- a responsabilidade deve ser explícita;
- as alterações devem ser revistas;
- secções geradas devem ser identificadas;
- comentários jurídicos devem ser separados das diretivas de máquina sempre que possível;
- casos de teste devem confirmar o acesso esperado de bots críticos;
- o histórico de versões deve ser preservado;
- nomes antigos de bots devem ser descontinuados ou documentados;
- treino de IA, recuperação por IA, indexação de pesquisa e arquivamento devem ser tratados como finalidades separadas.
O último ponto é o mais importante. A gramática atual é centrada em user-agent: pede aos operadores que nomeiem bots. A necessidade na era da IA é centrada em finalidade: pede aos operadores que digam quais usos são permitidos.
Não é a mesma coisa.
É por causa desta incompatibilidade que listas de bloqueio mais longas não envelhecerão bem. Um publisher pode adicionar hoje GPTBot, ClaudeBot, CCBot, Google-Extended, Bytespider, Applebot-Extended e PerplexityBot, mas o próximo nome de crawler, agente de recuperação ou corretor de dados pode aparecer amanhã. Uma política baseada em finalidade permitiria que o site dissesse "indexação de pesquisa sim, treino de IA não, recuperação iniciada pelo utilizador talvez" sem transformar o robots.txt numa agenda de bots.
O que isto significa para a governação de IA
O debate público muitas vezes apresenta o robots.txt como algo significativo ou obsoleto. Os dados sugerem uma resposta mais prática:
o robots.txt é significativo, mas está sobrecarregado.
É significativo porque grandes sites o usam, os crawlers conseguem analisá-lo e as escolhas de política ficam visíveis para investigadores, jornalistas, fornecedores e tribunais. O relatório original descobriu que 17,0% dos principais sites analisáveis tinham regras deliberadas específicas para IA. Isto não é ruído simbólico.
Está sobrecarregado porque o ficheiro agora precisa de expressar mais do que acesso de bots:
- "Não treinem com este conteúdo."
- "Podem usar este conteúdo para indexação de pesquisa."
- "Podem usar este conteúdo para recuperação em tempo real."
- "Não podem criar conjuntos de dados em cache."
- "Esta reserva jurídica aplica-se ao abrigo da lei da UE sobre text and data mining."
- "Este site gerido por CDN envia
Content-Signal: ai-train=no." - "Este site quer Googlebot, mas não YandexBot."
- "Este site tem 1.000 caminhos legados de URL que não devem ser rastreados."
A gramática não foi concebida para tantas tarefas.
Três mudanças reduziriam esta dívida:
-
A identidade do crawler precisa de um registo. Os operadores de sites não deviam ter de manter uma lista sempre crescente de
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Applebot-Extended,Bytespider,OAI-SearchBot,ChatGPT-Usere muitos outros. Sem um registo, a política estará sempre atrás do comportamento dos crawlers. -
O uso de IA precisa de vocabulário estruturado. Treino, recuperação, indexação, resumo, revenda de conjuntos de dados, avaliação de modelo e navegação iniciada pelo utilizador são usos diferentes. Expressá-los através de nomes de user-agent específicos de fornecedores é frágil.
-
A política precisa de ser auditável. A web precisa de uma forma de distinguir reservas de direitos escritas manualmente de padrões herdados da CDN, templates gerados pelo CMS, regras legadas antigas e bloqueios gerais acidentais. A distinção importa para confiança e para litígios.
Nada disto significa substituir o robots.txt de um dia para o outro. O melhor caminho é a sobreposição: manter o robots.txt como superfície de descoberta e compatibilidade, mas padronizar políticas legíveis por máquina adjacentes para usos específicos de IA.
llms.txt é uma tentativa nesse sentido, mas a sua adoção neste conjunto de dados ainda é mínima: apenas 83 ficheiros legíveis mencionam isso. Content-Signal é mais visível porque a Cloudflare pode distribuí-lo pela infraestrutura, e todos os 271 ficheiros com Content-Signal nesta varredura também correspondiam à linguagem de política de IA. Ainda assim, distribuição não é o mesmo que consenso. Uma solução duradoura provavelmente precisa da maquinaria tediosa da padronização: campos claros, semântica clara, compromissos dos crawlers e conjuntos públicos de testes.
Conclusão
A disputa sobre crawlers de IA transformou o robots.txt num artefacto de governação. Isso é ao mesmo tempo útil e arriscado.
Útil, porque o ficheiro é público. Os investigadores podem auditá-lo. Os publishers podem alterá-lo. Os crawlers podem respeitá-lo. Os tribunais podem lê-lo. Os fornecedores de infraestrutura podem implementá-lo em escala.
Arriscado, porque está a carregar demasiado.
O ficheiro robots.txt mediano no Tranco Top 10K ainda é pequeno o suficiente para ser compreendido. Mas a longa cauda da web de elevado tráfego está cheia de ficheiros grandes, antigos, em camadas, específicos de fornecedores e juridicamente carregados. Centenas de sites mantêm agora configurações de robots.txt que são melhor entendidas como sistemas de política de produção do que como simples dicas para crawlers.
A lição central não é que o robots.txt falhou. É que a web o promoveu sem o refatorar.
Se a política de acesso de IA vai depender de declarações públicas legíveis por máquina, o próximo passo não é outra lista de bloqueio mais longa. É uma infraestrutura melhor de política: permissões baseadas em finalidade, identidade estável de crawlers, modelos passíveis de revisão e trilhos de auditoria.
Até lá, a camada de governação de IA da web pública continuará apoiada num ficheiro de texto que nunca foi feito para carregar tanto peso.
Notas de reprodutibilidade
A pasta de entrega inclui:
source_data/analysis.json— métricas agregadas originais.source_data/site_meta.csv— tabela analítica original por site.source_data/bot_status.csv— tabela original de política por domínio e bot.source_data/fetch_meta.csv— metadados originais de busca.source_data/sites.csv— tabela original de domínio/categoria/status.derived_data/robots_complexity_by_site.csv— métricas de complexidade por site geradas para este relatório.derived_data/search_bot_treatment.csv— matriz de tratamento de crawlers de pesquisa.derived_data/category_complexity_summary.csv— resumo de complexidade por categoria.derived_data/top_config_debt_sites.csv— principais sites pela pontuação de triagem descrita acima.derived_data/summary_metrics.json— todas as métricas principais citadas neste relatório.
Correções de metodologia, problemas no conjunto de dados e análises de seguimento são bem-vindos em support@thunderbit.com. Este relatório é publicado de forma independente de qualquer posição comercial que a Thunderbit mantenha; construímos um raspador web com IA e temos interesse estrutural em que o robots.txt continue a ser um contrato significativo e legível por máquina na web pública. Os dados neste relatório falam por si. — Equipa de investigação da Thunderbit, maio de 2026.