A internet está cheia de informações e, vamos combinar, ninguém quer ficar perdendo tempo copiando e colando milhares de produtos ou vagas de emprego na mão. É aí que entra o web scraping, uma habilidade cada vez mais indispensável para quem trabalha com vendas, operações, ecommerce e muitos outros setores. Python, com sua linguagem fácil e bibliotecas poderosas, virou o queridinho de quem quer criar um bom raspador web. Para ter uma ideia, mais de já usam Python, disparado na frente das outras linguagens.
Só que tem um porém: mesmo sendo eficiente, o scraping com Python pode assustar quem está começando — e até quem já tem experiência sofre com sites dinâmicos, bloqueios anti-bot e dados bagunçados. Por isso, preparei este tutorial passo a passo. Vamos partir do zero, montar juntos um exemplo de raspador web em Python e mostrar como você pode unir Python a ferramentas com IA, tipo o , para raspar dados de um jeito muito mais esperto. Seja para automatizar a geração de leads, monitorar preços da concorrência ou organizar dados da web em uma planilha, aqui você encontra dicas práticas (e uns aprendizados que só quem já apanhou sabe).
Web Scraping em Python: Comece do Jeito Certo
Vamos pelo começo. Web scraping nada mais é do que automatizar a coleta de dados de sites. Em vez de copiar tudo na mão, um raspador acessa a página, lê o HTML e pega só o que interessa — tipo preços, contatos ou avaliações. Para empresas, isso significa acesso rápido a dados para prospecção, monitoramento de preços ou pesquisas de mercado, tudo em tempo real ().
Passo 1: Instale o Python
Primeiro, você precisa do Python 3. Dá para baixar a versão mais nova direto do . No Windows, é só rodar o instalador e marcar a opção “Add Python to PATH”. No Mac, pode usar o com brew install python ou baixar direto. Depois de instalar, abra o terminal (ou Prompt de Comando) e digite:
1python --versionou
1python3 --versionSe aparecer algo tipo Python 3.11.0, está tudo certo.
Passo 2: Crie um Ambiente Virtual
O ambiente virtual serve para deixar as dependências do seu projeto organizadas e evitar bagunça com outros projetos Python. No diretório do seu projeto, rode:
1# No macOS/Linux
2python3 -m venv .venv
3# No Windows
4py -m venv .venvAtive o ambiente com:
- macOS/Linux:
source .venv/bin/activate - Windows:
.venv\Scripts\activate
Assim, tudo que você instalar fica só nesse projeto ().
Passo 3: Instale as Bibliotecas Básicas
Você vai precisar de alguns pacotes essenciais:
- Requests: Para buscar páginas web.
- BeautifulSoup (bs4): Para analisar o HTML.
- Scrapy: Para raspagens mais avançadas e em grande escala.
Instale com:
1pip install requests beautifulsoup4 scrapy- Requests facilita as requisições HTTP.
- BeautifulSoup ajuda a encontrar e extrair dados do HTML.
- Scrapy é um framework completo para raspar muitos sites, tratar erros e exportar dados.
Se você está começando, Requests + BeautifulSoup já resolvem. Scrapy é para projetos maiores.
Passo 4: Organize sua Pasta de Projeto
Deixe tudo arrumadinho! Crie uma pasta para o projeto e, dentro dela, coloque seus scripts, arquivos de dados e o ambiente virtual. Seu “eu” do futuro vai agradecer.
Exemplo de raspador web em Python: Estrutura Básica
Vamos criar um raspador simples juntos. A ideia é buscar uma página, analisar o HTML e extrair alguns dados. Olha só um exemplo comentado usando :
1import requests
2from bs4 import BeautifulSoup
3URL = "https://example.com"
4response = requests.get(URL)
5response.raise_for_status() # Dá erro se não for 200 OK
6soup = BeautifulSoup(response.text, "html.parser")
7# Pega todas as tags de parágrafo
8paragraphs = soup.find_all('p')
9for idx, p in enumerate(paragraphs, start=1):
10 print(f"Parágrafo {idx}: {p.get_text()}")O que está rolando aqui?
- Importamos as bibliotecas.
- Buscamos a página com
requests.get. - Analisamos o HTML com BeautifulSoup.
- Pegamos todas as tags
<p>e mostramos o texto.
Erros comuns:
- Não checar
response.status_code(sempre confira se é 200 OK). - Tentar acessar
.get_text()em um objetoNone(caso o elemento não exista). - Esquecer de ativar o ambiente virtual (os imports podem falhar).
Essa estrutura — importar, buscar, analisar, extrair e mostrar — é a base da maioria dos raspadores em Python.
Usando Python para Raspar Páginas Web: Passo a Passo
Vamos detalhar o passo a passo para uma tarefa real de scraping.
1. Inspecione o Site
Abra o navegador, clique com o botão direito no dado que você quer e escolha “Inspecionar”. Isso abre as Ferramentas do Desenvolvedor e mostra o HTML. Procure por tags, classes ou IDs únicos que identifiquem os dados que você quer ().
2. Busque a Página
Use Requests para pegar o HTML:
1headers = {"User-Agent": "Mozilla/5.0"}
2response = requests.get(URL, headers=headers)
3response.raise_for_status()Colocar um User-Agent ajuda a evitar bloqueios simples contra bots.
3. Analise o HTML
1soup = BeautifulSoup(response.text, "html.parser")4. Ache e Extraia os Dados
Suponha que você esteja raspando vagas de emprego, cada uma em um <div class="job-card">:
1job_cards = soup.find_all('div', class_='job-card')
2for card in job_cards:
3 title = card.find('h2', class_='title').get_text(strip=True)
4 company = card.find('h3', class_='company').get_text(strip=True)
5 print(title, company)Você pode usar .find(), .find_all() ou .select() com seletores CSS para buscas mais avançadas.
5. Lide com Múltiplos Itens (Listas)
Percorra a lista de containers (produtos, vagas, etc.), extraindo os campos necessários. Guarde tudo em uma lista de dicionários para facilitar a exportação.
6. Solução de Problemas
- Se os resultados vierem vazios, revise seus seletores — pode ser que a classe mudou ou o conteúdo é carregado via JavaScript.
- Imprima
response.text[:500]para conferir se o HTML retornado é o esperado.
Exemplo de raspador web em Python: Salvando e Exportando Dados
Depois de coletar os dados, é hora de salvar. Veja as opções mais comuns:
Exibir no Console
Ótimo para testes rápidos, mas não para projetos de verdade.
Salvar em CSV
1import csv
2data = [
3 {"Name": "Alice", "Age": 25},
4 {"Name": "Bob", "Age": 30},
5]
6with open("output.csv", "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=["Name", "Age"])
8 writer.writeheader()
9 writer.writerows(data)Exportar para Excel
Se você tiver pandas e openpyxl instalados:
1import pandas as pd
2df = pd.DataFrame(data)
3df.to_excel("output.xlsx", index=False)Salvar em Banco de Dados
Para necessidades simples, o SQLite já vem com o Python:
1import sqlite3
2conn = sqlite3.connect("scraped_data.db")
3cursor = conn.cursor()
4cursor.execute("CREATE TABLE IF NOT EXISTS people (name TEXT, age INTEGER)")
5for row in data:
6 cursor.execute("INSERT INTO people VALUES (?, ?)", (row["Name"], row["Age"]))
7conn.commit()
8conn.close()Quando usar cada um?
- CSV: Ideal para planilhas e compartilhamento fácil.
- Excel: Para relatórios mais organizados e com várias abas.
- Banco de dados: Para projetos grandes ou que rodam sempre.
Sempre use encoding="utf-8" para evitar problemas com acentuação ().
Thunderbit e Python: Deixando seu Web Scraping Muito Mais Potente
 Agora, bora falar do , a extensão de Chrome com IA que está mudando o jogo do web scraping para empresas.
Agora, bora falar do , a extensão de Chrome com IA que está mudando o jogo do web scraping para empresas.
O que faz o Thunderbit ser diferente?
- Sugestão de Campos com IA: O Thunderbit analisa a página e já sugere quais colunas de dados extrair — sem precisar inspecionar HTML ou criar seletores.
- Fluxo de Trabalho Intuitivo: Só abrir a extensão, deixar a IA sugerir os campos, clicar em “Raspar” e pronto.
- Raspagem de Subpáginas: O Thunderbit consegue visitar páginas de detalhes (tipo páginas de produtos ou perfis) e enriquecer seu conjunto de dados com informações extras.
- Exportação Flexível: Baixe seus dados em CSV, Excel ou exporte direto para Google Sheets, Notion ou Airtable ().
Como o Thunderbit soma com o Python?
Imagina que você precisa raspar um site de ecommerce complicado, cheio de JavaScript e login. Scripts tradicionais em Python podem travar, mas o Thunderbit — rodando direto no navegador — tira isso de letra. Depois de raspar, é só exportar os dados e usar Python para análises, relatórios ou automações.
Exemplo prático:
- Use o Thunderbit para raspar listagens de produtos (incluindo imagens, preços e avaliações) de um site dinâmico.
- Exporte para CSV.
- Use Python para analisar tendências, cruzar com outros dados ou automatizar alertas.
Essa combinação resolve até os desafios mais chatos do scraping — não importa seu nível de programação.
Como Garantir Precisão e Estabilidade no seu Raspador Web em Python
Web scraping não é só sair pegando dados — é garantir que você está pegando as informações certas, do jeito certo. Veja como manter seu raspador funcionando direitinho:
1. Lide com Mudanças no Site
Sites mudam o HTML toda hora. Escreva seletores resistentes — prefira IDs únicos ou classes estáveis em vez de posições frágeis de tags.
2. Use Tratamento de Erros
Coloque suas requisições e parsing dentro de blocos try/except:
1import time
2for attempt in range(3):
3 try:
4 response = requests.get(url, timeout=10)
5 response.raise_for_status()
6 break
7 except Exception as e:
8 if attempt < 2:
9 time.sleep(5)
10 else:
11 print(f"Falhou após 3 tentativas: {e}")3. Altere o User-Agent e Use Proxies
Muitos sites bloqueiam scripts que parecem bots. Troque o User-Agent e, para raspagens grandes, use proxies para não tomar bloqueio de IP ().
4. Respeite o robots.txt e Seja Ético
Sempre confira o robots.txt e os termos de uso do site. Raspe só dados públicos, evite informações pessoais e não sobrecarregue os servidores ().
5. Faça Logs e Monitore
Use o módulo logging do Python para registrar erros e sucessos. Se seu raspador roda sozinho, configure alertas para falhas ou dias sem resultados.
Como a IA do Thunderbit Turbina o Web Scraping em Python
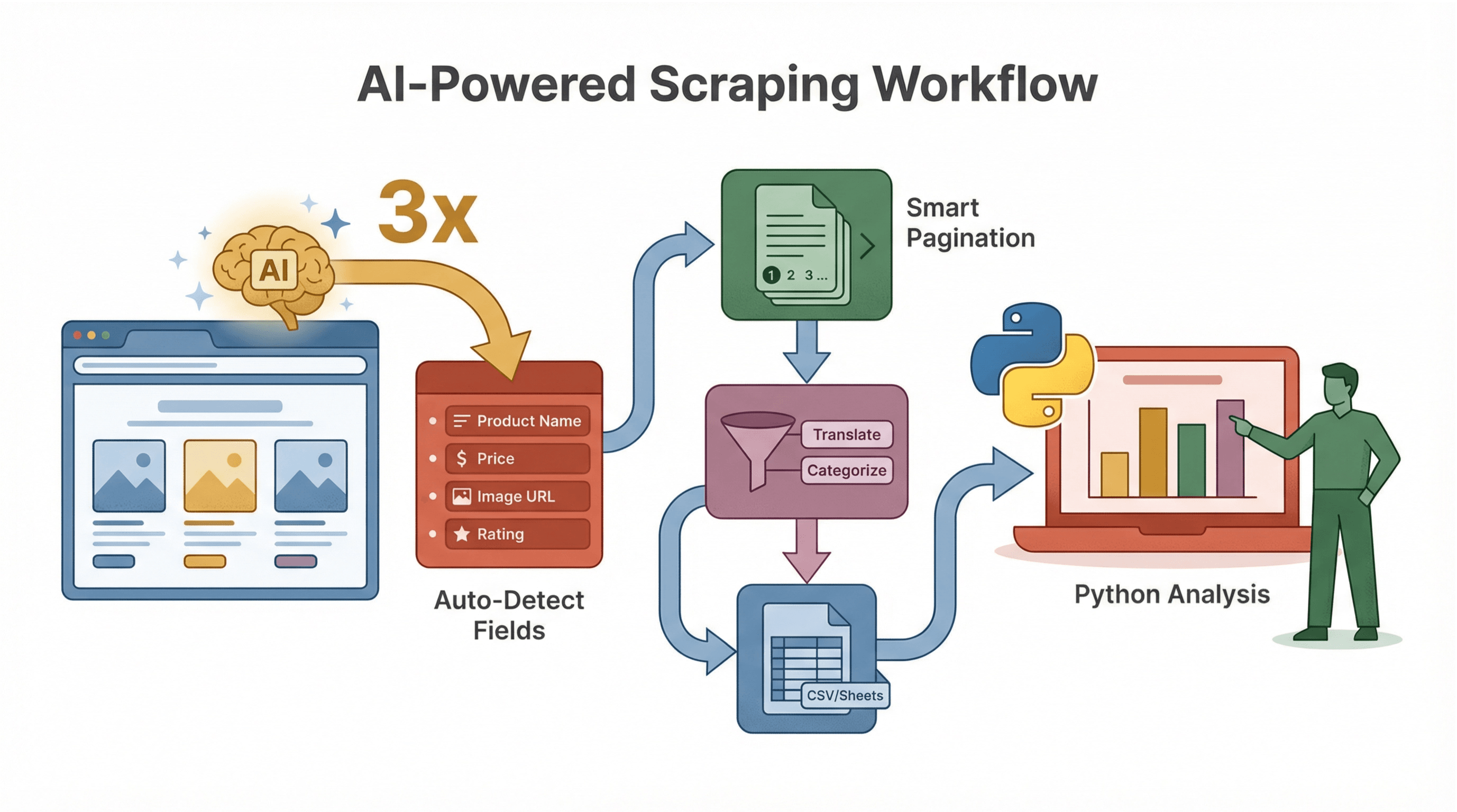 O Thunderbit vai além do básico — ele deixa todo o processo mais inteligente e rápido.
O Thunderbit vai além do básico — ele deixa todo o processo mais inteligente e rápido.
Esquema de Dados Sugerido por IA
A IA do Thunderbit sugere na hora quais campos extrair, poupando o trabalho de inspecionar HTML e criar seletores. Por exemplo, em uma página de produto, pode identificar automaticamente “Nome do Produto”, “Preço”, “URL da Imagem” e outros.
Subpáginas e Paginação
A IA do Thunderbit percebe quando tem páginas de detalhes ou várias páginas de resultados, e raspa tudo — sem precisar de código extra. Isso é essencial para ecommerce, imóveis ou geração de leads.
Limpeza e Enriquecimento de Dados com IA
Quer traduzir, resumir ou categorizar dados enquanto raspa? O Thunderbit permite adicionar prompts de IA a cada campo, para, por exemplo, rotular avaliações como “Positiva” ou “Negativa”, ou extrair só o valor numérico de um preço.
Exemplo de Fluxo de Trabalho
- Use o Thunderbit para raspar e estruturar seus dados (com campos sugeridos pela IA).
- Exporte para CSV ou Google Sheets.
- Use Python para analisar, visualizar ou automatizar ações.
Esse fluxo é perfeito para equipes onde nem todo mundo programa — o Thunderbit cuida da raspagem, o Python faz o trabalho pesado.
Exemplo de raspador web em Python: Dicas Avançadas e Problemas Comuns
Quer ir além? Olha só umas dicas de quem já está na estrada:
Raspando Conteúdo Dinâmico
Muitos sites modernos usam JavaScript para carregar dados. Se Requests + BeautifulSoup não trouxerem nada ou vierem incompletos, tente:
- Selenium ou Playwright: Automatize um navegador de verdade para renderizar a página e extrair o HTML.
- Procure por APIs: Muitas vezes, os dados vêm de chamadas de API em segundo plano (geralmente retornando JSON). Use a aba Network do navegador para achar esses endpoints — é muito mais fácil de raspar!
Lidando com Paginação
Percorra as páginas mudando o parâmetro da URL (ex: ?page=2). Ou use o BeautifulSoup para achar o link “Próxima” e seguir até acabar.
Agendando Raspagens
Use a biblioteca schedule do Python ou um cron job para rodar seu raspador automaticamente. Ou use o agendamento do Thunderbit para uma solução sem código.
Problemas Comuns
- CAPTCHAs: Diminua a frequência das requisições, use proxies ou soluções com intervenção humana.
- Problemas de Codificação: Sempre coloque
encoding="utf-8"ao salvar arquivos. - Bloqueios de IP: Use proxies, troque o User-Agent e respeite limites de acesso.
Conclusão & Principais Aprendizados
Dominar o web scraping com Python não precisa ser um bicho de sete cabeças. Comece pelo básico:
- Monte seu ambiente e instale as bibliotecas principais.
- Inspecione o site-alvo e planeje seus seletores.
- Escreva um script simples para buscar, analisar e extrair dados.
- Exporte os resultados no formato que faz mais sentido para você.
Com o tempo, una Python a ferramentas com IA como o para encarar tarefas mais complexas, dinâmicas ou de grande volume. Os recursos de IA do Thunderbit — como sugestões de campos, raspagem de subpáginas e exportação instantânea — economizam horas de trabalho manual e permitem que até quem não programa participe.
Lembre-se: os melhores raspadores são confiáveis, éticos e feitos com o objetivo final em mente. Seja você de vendas, ecommerce ou apaixonado por dados, o web scraping pode abrir um mundo de oportunidades — é só começar pequeno, evoluir e nunca parar de aprender.
Quer se aprofundar? Dá uma olhada no para mais tutoriais, ou teste a e veja o scraping com IA na prática.
Perguntas Frequentes
1. Qual o jeito mais fácil de começar a fazer web scraping com Python?
Instale o Python 3, depois use as bibliotecas Requests e BeautifulSoup para buscar e analisar páginas web. Comece com sites simples e vá avançando conforme pegar prática.
2. Como lidar com sites que usam JavaScript para carregar dados?
Para sites que dependem muito de JavaScript, use ferramentas de automação de navegador como Selenium ou Playwright, ou procure por chamadas de API no painel Network do navegador que retornem dados estruturados (tipo JSON).
3. Qual a melhor forma de exportar dados raspados para uso empresarial?
CSV é o formato mais universal (abre no Excel, Google Sheets, etc.), mas você também pode exportar para Excel, JSON ou bancos de dados como SQLite. O Thunderbit também permite exportação direta para Google Sheets, Notion e Airtable.
4. Como evitar bloqueios ao fazer scraping?
Troque o User-Agent, use proxies para raspagens grandes, respeite limites de acesso e sempre confira o robots.txt do site. Evite raspar dados pessoais ou sensíveis.
5. Como o Thunderbit facilita o web scraping para quem não programa?
O Thunderbit usa IA para sugerir campos de dados, lidar com subpáginas e paginação, e exportar dados estruturados em poucos cliques — sem precisar de código. É perfeito para quem quer resultado rápido e confiável sem complicação técnica.
Pronto para automatizar sua coleta de dados? Teste o de graça e leve seu web scraping para outro patamar com IA.
Saiba Mais