Deixa eu te contar como tudo começou pra mim nesse universo de SaaS e automação, numa época em que “rastreamento web” parecia coisa de filme de ficção científica ou passatempo de aranha em dia de folga. Hoje em dia, o rastreamento web é o motor por trás de tudo: do Google Search até aquele site de comparação de preços que você consulta antes de comprar qualquer coisa. A internet é um organismo vivo, e todo mundo — de devs a times de vendas — quer colocar as mãos nos dados. Mas aqui está o segredo: apesar do Python ter facilitado muito a vida de quem quer criar rastreadores, a maioria só quer mesmo os dados, sem precisar virar expert em cabeçalho HTTP ou entender como o JavaScript é renderizado.
É aí que a coisa fica interessante. Como cofundador da , vi de perto a explosão da demanda por dados web em todos os setores. O pessoal de vendas quer leads fresquinhos, quem trabalha com e-commerce precisa monitorar preços da concorrência, e o marketing está sempre atrás de insights de conteúdo. Só que nem todo mundo tem tempo (ou paciência) pra virar ninja em Python. Então bora entender o que é um rastreador web python, por que ele é importante e como ferramentas com IA como Thunderbit estão mudando o jogo — tanto pra empresas quanto pra devs.
Web Crawler Python: O Que É e Por Que Faz Diferença?
Vamos acabar com uma confusão clássica: rastreador web e raspador web não são a mesma coisa. Muita gente mistura os termos, mas eles são tão diferentes quanto um robô aspirador e um aspirador tradicional (ambos limpam, mas cada um do seu jeito).
- Rastreadores Web são tipo exploradores digitais. Eles navegam e indexam páginas, seguindo links de uma pra outra — igual o Googlebot mapeando a internet.
- Raspadores Web são os coletores de dados. Eles pegam informações específicas das páginas, como preços, contatos ou textos de artigos.

Quando falamos em “web crawler python”, normalmente estamos falando de usar Python pra criar esses bots que navegam e, às vezes, extraem dados da web. Python virou queridinho porque é fácil de aprender, tem biblioteca pra tudo e — sejamos sinceros — ninguém quer sofrer escrevendo rastreador em Assembly.
Por Que Rastrear e Extrair Dados Web é Tão Valioso?
Por que tanta gente se importa com rastreamento e raspagem de dados? Porque dado web é o novo ouro — só que, em vez de garimpar, você programa (ou, como veremos, só clica em alguns botões).
Olha só pra que serve:
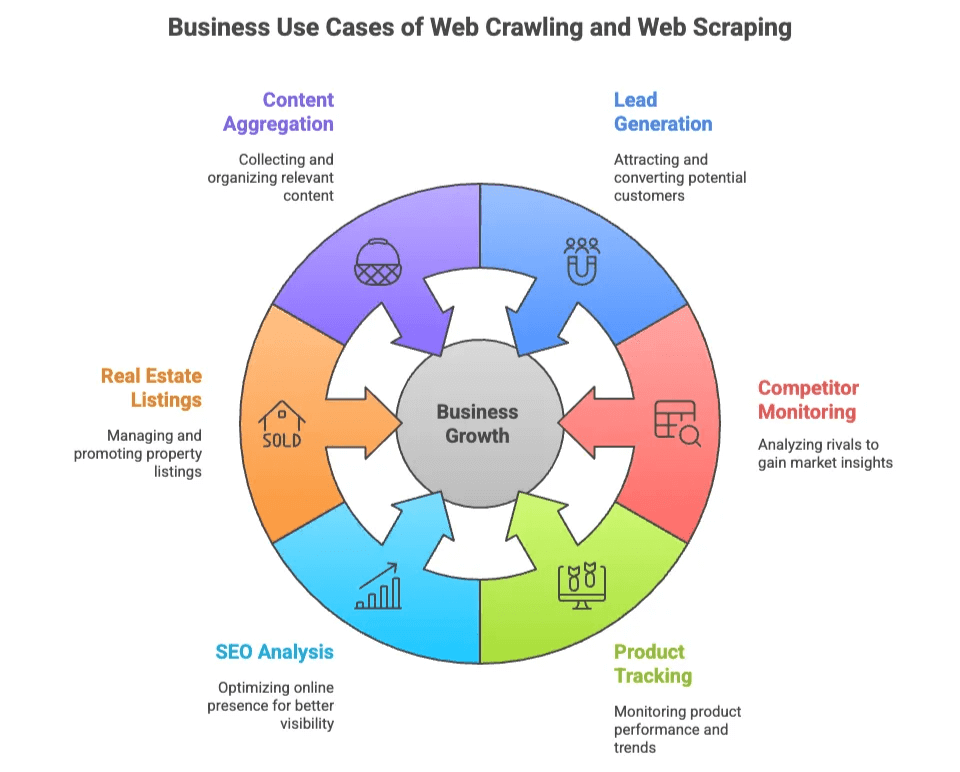
| Caso de Uso | Quem Usa | Valor Gerado |
|---|---|---|
| Geração de Leads | Vendas, Marketing | Criação de listas segmentadas de potenciais clientes a partir de diretórios e redes sociais |
| Monitoramento de Concorrentes | E-commerce, Operações | Acompanhar preços, estoque e lançamentos em sites rivais |
| Acompanhamento de Produtos | E-commerce, Varejo | Monitorar mudanças em catálogos, avaliações e notas |
| Análise de SEO | Marketing, Conteúdo | Analisar palavras-chave, meta tags e backlinks para otimização |
| Listagens Imobiliárias | Corretores, Investidores | Agregar dados de imóveis e contatos de proprietários de várias fontes |
| Agregação de Conteúdo | Pesquisa, Mídia | Coletar artigos, notícias ou posts de fóruns para insights |
O melhor é que tanto quem é técnico quanto quem não é pode se beneficiar. Devs criam rastreadores sob medida pra projetos complexos, enquanto o pessoal de negócio só quer os dados prontos — de preferência sem nem saber o que é seletor CSS.
As Bibliotecas Python Mais Usadas pra Rastreamento Web: Scrapy, BeautifulSoup e Selenium
Python virou padrão no rastreamento web por causa de três bibliotecas que todo mundo ama (ou odeia, dependendo do dia).
| Biblioteca | Facilidade de Uso | Velocidade | Suporte a Conteúdo Dinâmico | Escalabilidade | Melhor Para |
|---|---|---|---|---|---|
| Scrapy | Média | Rápida | Limitado | Alta | Rastreamentos grandes e automatizados |
| BeautifulSoup | Fácil | Média | Nenhum | Baixa | Parsing simples, projetos pequenos |
| Selenium | Mais difícil | Lenta | Excelente | Baixa-Média | Páginas com muito JavaScript, interativas |
Vamos ver o que cada uma tem de especial.
Scrapy: O Framework Completo pra Rastreamento em Python
Scrapy é tipo o canivete suíço do rastreamento web python. É um framework robusto, perfeito pra quem quer rastrear milhares de páginas, fazer várias requisições ao mesmo tempo e exportar tudo pra pipelines de dados.
Por que a galera curte:
- Faz rastreamento, parsing e exportação de dados tudo junto.
- Suporte nativo pra concorrência, agendamento e pipelines.
- Ideal pra projetos que precisam de escala.
Mas… Scrapy tem uma curva de aprendizado. Como um dev comentou, é “overkill se você só precisa raspar algumas páginas” (). Tem que entender seletores, processamento assíncrono e, às vezes, até proxies e técnicas anti-bot.
Como funciona o Scrapy:
- Você define um Spider (a lógica do rastreador).
- Configura os pipelines de itens (pra processar os dados).
- Roda o rastreamento e exporta os dados.
Se você quer rastrear a web igual o Google, Scrapy é o caminho. Se só precisa de uma lista de e-mails, talvez seja demais.
BeautifulSoup: Simples e Leve pra Parsing Web
BeautifulSoup é o “olá mundo” do parsing web. Leve, fácil de usar, perfeita pra quem tá começando ou pra projetos pequenos.
Por que o pessoal gosta:
- Muito fácil de aprender e usar.
- Ótima pra extrair dados de páginas estáticas.
- Boa pra scripts rápidos.
Mas… BeautifulSoup não rastreia — só faz parsing. Você precisa usar algo como requests pra buscar as páginas e criar sua própria lógica pra seguir links ou lidar com várias páginas ().
Se você tá começando no rastreamento web, BeautifulSoup é uma porta de entrada tranquila. Só não espere que ela resolva JavaScript ou grandes volumes.
Selenium: Pra Páginas Dinâmicas e Cheias de JavaScript
Selenium é o rei da automação de navegador. Ele controla Chrome, Firefox ou Edge, clica em botões, preenche formulários e — o mais importante — renderiza páginas cheias de JavaScript.

Por que é poderoso:
- Consegue “ver” e interagir com páginas igual um usuário real.
- Lida com conteúdo dinâmico e dados carregados via AJAX.
- Essencial pra sites que exigem login ou simulação de ações humanas.
Mas… Selenium é lento e pesado. Ele abre um navegador completo pra cada página, o que pode travar seu PC em rastreamentos grandes (). E ainda tem que cuidar de drivers de navegador e esperar o carregamento do conteúdo.
Selenium é a escolha quando você precisa acessar sites que parecem intransponíveis pra raspadores comuns.
Os Perrengues de Criar e Rodar um Rastreador Web Python
Agora, vamos falar da parte menos glamourosa do rastreamento web python. Já perdi as contas de quantas horas gastei depurando seletores e driblando bloqueios anti-bot. Olha só os principais desafios:
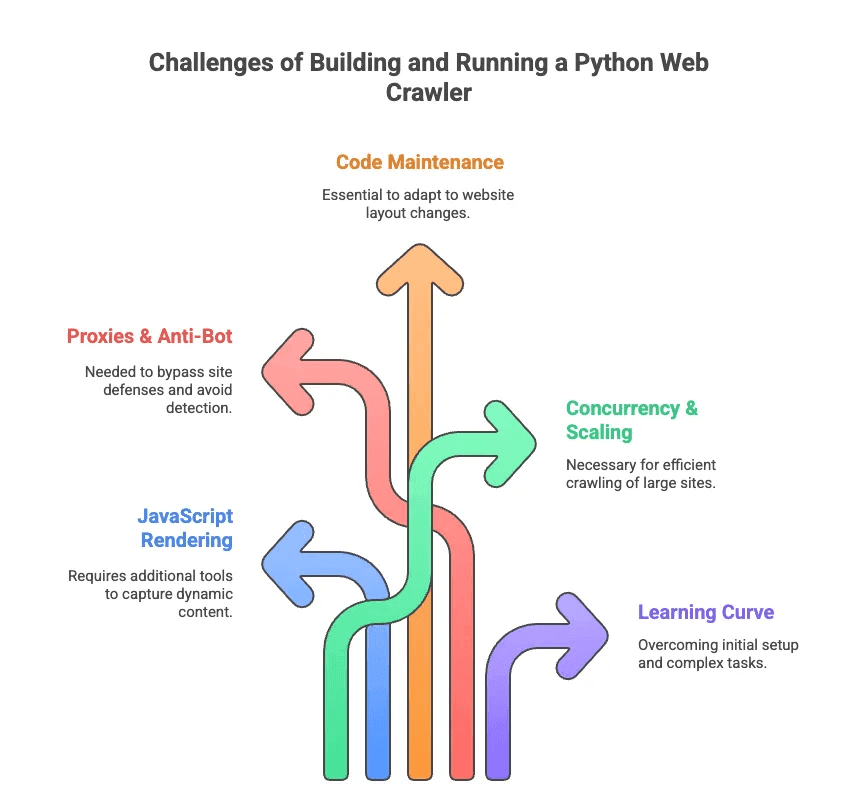
- Renderização de JavaScript: A maioria dos sites modernos carrega conteúdo de forma dinâmica. Scrapy e BeautifulSoup não enxergam esses dados sem plugins extras.
- Proxies & Anti-Bot: Sites não gostam de ser rastreados. Tem que rotacionar proxies, simular agentes de usuário e, às vezes, resolver CAPTCHAs.
- Manutenção de Código: Sites mudam de layout o tempo todo. Seu scraper pode quebrar de um dia pro outro, exigindo ajustes nos seletores ou na lógica.
- Concorrência & Escalabilidade: Vai rastrear milhares de páginas? Prepare-se pra gerenciar requisições assíncronas, tratamento de erros e pipelines de dados.
- Curva de Aprendizado: Pra quem não é dev, só instalar Python e as dependências já é um desafio. Lidar com paginação ou login então, nem se fala.
Como um engenheiro comentou, criar scrapers personalizados muitas vezes parece exigir “um PhD em configuração de seletores” — não é o que o pessoal de vendas ou marketing espera fazer ().
Raspador Web IA vs. Rastreador Web Python: O Novo Jeito de Extrair Dados
E se você só quer os dados, sem dor de cabeça? Aí entra o Raspador Web IA. Ferramentas como a foram feitas pra quem quer resultado, não pra quem quer programar. Elas usam IA pra ler páginas, sugerir quais dados extrair e cuidar de toda a parte chata (paginação, subpáginas, anti-bot) nos bastidores.
Olha a comparação:
| Recurso | Rastreador Web em Python | Raspador Web IA (Thunderbit) |
|---|---|---|
| Configuração | Código, bibliotecas, ajustes | Extensão Chrome em 2 cliques |
| Manutenção | Atualizações e depuração manuais | IA se adapta às mudanças do site |
| Conteúdo Dinâmico | Precisa de Selenium ou plugins | Renderização integrada no navegador/nuvem |
| Anti-Bot | Proxies, agentes de usuário | IA e nuvem contornam bloqueios |
| Escalabilidade | Alta (com esforço) | Alta (nuvem, raspagem paralela) |
| Facilidade de Uso | Para desenvolvedores | Para todos |
| Exportação de Dados | Código ou scripts | 1 clique para Sheets, Airtable, Notion |
Com Thunderbit, você não precisa se preocupar com requisições HTTP, JavaScript ou proxies. Só clicar em “IA Sugerir Campos”, deixar a IA identificar o que é importante e clicar em “Raspar”. É tipo ter um mordomo digital de dados.
Thunderbit: O Raspador Web IA de Nova Geração pra Todo Mundo
Vamos aos detalhes. O Thunderbit é uma feita pra deixar a extração de dados tão fácil quanto pedir delivery. Olha o que faz a diferença:
- Detecção de Campos com IA: A IA do Thunderbit lê a página e sugere quais campos (colunas) extrair — chega de adivinhar seletor CSS ().
- Suporte a Páginas Dinâmicas: Funciona tanto em páginas estáticas quanto em sites cheios de JavaScript, graças aos modos de raspagem no navegador e na nuvem.
- Subpáginas & Paginação: Precisa de detalhes de cada produto ou perfil? O Thunderbit navega automaticamente por subpáginas e coleta tudo pra você ().
- Templates Adaptáveis: Um template de raspador pode se ajustar a diferentes estruturas de página — não precisa refazer tudo quando o site muda.
- Contorno de Anti-Bot: A IA e a infraestrutura em nuvem ajudam a driblar bloqueios comuns.
- Exportação de Dados: Manda os dados direto pro Google Sheets, Airtable, Notion ou baixa como CSV/Excel — sem taxa extra, até no plano gratuito ().
- Limpeza de Dados com IA: Resuma, categorize ou traduza dados automaticamente — chega de planilha bagunçada.
Exemplos práticos:
- Times de vendas extraem listas de prospects de diretórios ou LinkedIn em minutos.
- Gestores de e-commerce monitoram preços e mudanças de produtos sem esforço manual.
- Corretores agregam listagens e contatos de imóveis de vários sites.
- Marketing analisa conteúdo, palavras-chave e backlinks pra SEO — tudo sem escrever uma linha de código.
O fluxo do Thunderbit é tão simples que até meus amigos que não são da área de tecnologia usam — e aprovam. Só instalar a extensão, abrir o site, clicar em “IA Sugerir Campos” e pronto. Pra sites populares como Amazon ou LinkedIn, já tem template pronto — um clique e já era ().
Quando Usar Rastreador Web Python ou Raspador Web IA
Então, vale a pena criar um rastreador web python ou usar Thunderbit? Minha opinião sincera:
| Cenário | Rastreador Web em Python | Raspador Web IA (Thunderbit) |
|---|---|---|
| Precisa de lógica personalizada ou escala massiva | ✔️ | Talvez (modo nuvem) |
| Integração profunda com outros sistemas | ✔️ (com código) | Limitado (via exportação) |
| Usuário não técnico, precisa de resultado rápido | ❌ | ✔️ |
| Mudanças frequentes no layout do site | ❌ (atualização manual) | ✔️ (IA se adapta) |
| Sites dinâmicos/com muito JS | ✔️ (com Selenium) | ✔️ (nativo) |
| Projetos pequenos, orçamento apertado | Talvez (grátis, mas demanda tempo) | ✔️ (plano gratuito, sem barreira) |
Use rastreadores em Python se:
- Você é dev e quer controle total.
- Precisa rastrear milhões de páginas ou criar pipelines de dados personalizados.
- Não se importa com manutenção e depuração constantes.
Use Thunderbit se:
- Quer os dados agora, sem semanas de programação.
- Trabalha com vendas, e-commerce, marketing ou imóveis e só precisa do resultado.
- Não quer lidar com proxies, seletores ou bloqueios anti-bot.
Ainda tá na dúvida? Segue o checklist:
- Tem experiência com Python e web? Se sim, testa Scrapy ou Selenium.
- Só quer os dados, rápido e limpo? Thunderbit é a escolha.
Conclusão: Liberando o Poder dos Dados da Web — A Ferramenta Certa pra Cada Perfil
Rastreamento e raspagem de dados web viraram habilidades essenciais no mundo dos dados. Mas sejamos sinceros: nem todo mundo quer virar especialista em rastreamento. Ferramentas como Scrapy, BeautifulSoup e Selenium são poderosas, mas exigem tempo e manutenção.
Por isso fico tão empolgado com a chegada dos raspadores web IA como o . Criamos o Thunderbit pra democratizar o acesso aos dados da web — não só pra devs. Com detecção de campos por IA, suporte a páginas dinâmicas e fluxos sem código, qualquer pessoa pode extrair os dados que precisa em minutos.
Seja você dev que curte programar ou alguém de negócio que só quer o resultado, existe uma ferramenta ideal pra você. Pense nas suas necessidades, seu conhecimento técnico e o prazo. E se quiser ver como extrair dados pode ser fácil, — seu eu do futuro (e sua planilha) vão agradecer.
Quer se aprofundar? Dá uma olhada nos guias do , como ou . Bons rastreamentos — e boas raspagens!
Perguntas Frequentes
1. Qual a diferença entre um Rastreador Web Python e um Raspador Web?
Um rastreador web python serve pra explorar e indexar páginas seguindo links — ótimo pra mapear a estrutura de sites. Já um raspador web extrai dados específicos dessas páginas, tipo preços ou e-mails. Rastreadores mapeiam a internet; raspadores pegam o que interessa pra você. Muitas vezes, os dois trabalham juntos em fluxos de extração de dados com Python.
2. Quais bibliotecas Python são melhores pra criar um Rastreador Web?
As mais populares são Scrapy, BeautifulSoup e Selenium. Scrapy é rápida e escalável pra projetos grandes; BeautifulSoup é amigável pra iniciantes e ótima pra páginas estáticas; Selenium é ideal pra sites cheios de JavaScript, mas é mais lenta. A escolha depende do seu conhecimento técnico, tipo de conteúdo e tamanho do projeto.
3. Tem um jeito mais fácil de pegar dados da web sem programar um Rastreador Web Python?
Tem sim — o Thunderbit é uma extensão Chrome com IA que permite extrair dados da web em dois cliques. Sem código, sem configuração. Ele detecta campos automaticamente, lida com paginação e subpáginas e exporta pra Sheets, Airtable ou Notion. Perfeito pra vendas, marketing, e-commerce ou imóveis que só querem dados limpos — rapidinho.
Saiba Mais: