

Quem trabalha com dados sabe: a web de 2025 é terra de ninguém. Num minuto você está de olho no preço do concorrente, no outro já topou com JavaScript que carrega na marra e barreira anti-bot que parece nível de chefe de videogame. Depois de anos montando ferramenta de automação para time de vendas e operações, falo com tranquilidade: web scraping deixou de ser um truque de poucos e virou competência de base para qualquer empresa. Quando 90% das empresas tomam decisão estratégica olhando dados, e o volume de informação online dispara quase 193% em apenas quatro anos, saber transformar essa bagunça toda em insight prático é o que separa quem puxa a fila de quem fica correndo atrás.

Só que vamos combinar uma coisa: scraping não é mais o que era. Aquele tempo de pegar HTML estático com meia dúzia de linhas de Python já era. Agora o jogo é outro — conteúdo que aparece dinamicamente, rolagem que nunca acaba e sistema anti-bot cada vez mais esperto. Não importa se você está começando agora ou já quer dar um upgrade na sua stack: este guia reúne as melhores práticas, as ferramentas e os jeitos de trabalhar para mandar bem em scraping com Python em 2025 — e ainda mostra como acelerar tudo com IA usando ferramentas como o Thunderbit.
Extraia dados de qualquer site usando IA Get Started Free
Do Básico ao Avançado: Fundamentos do Scraping com Python
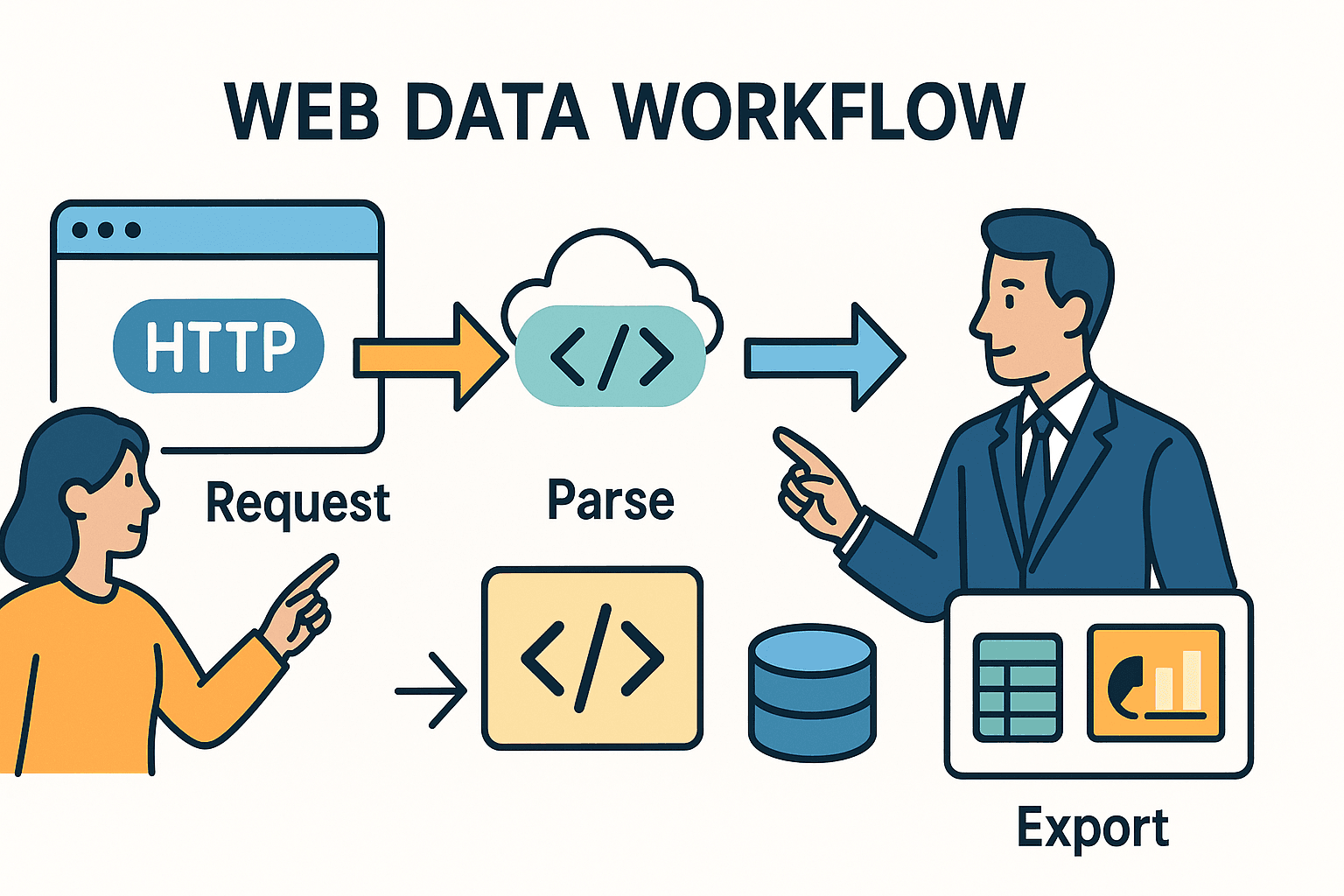
Vamos começar do zero. No fundo, raspador web é automatizar aquilo que você faria na mão dentro do navegador: abrir uma página, achar a informação e guardar para usar depois. Em Python, o caminho costuma ser este:
- Fazer uma requisição HTTP (exatamente o que o navegador faz por baixo dos panos).
- Analisar o HTML para localizar os dados que interessam.
- Exportar ou processar esses dados — seja para planilha, banco de dados ou dashboard.
O pulo do gato está nas ferramentas que você escolhe (e nos perrengues que vai enfrentar), e isso muda conforme a complexidade do site e o seu objetivo.
Scraping com Python: Como Funciona
Imagina o scraping como pedir para um bibliotecário buscar um jornal e, depois, pegar uma tesoura e recortar só as matérias que você quer. A biblioteca requests do Python é o bibliotecário — ela traz o HTML. O BeautifulSoup é a tesoura — recorta e extrai só o que importa.
E se o jornal vier escrito com tinta invisível (oi, JavaScript!) ou as matérias estiverem espalhadas em várias edições? Aí você chama ferramenta mais parruda — ou um empurrãozinho de IA.
Comparando as Principais Ferramentas
Segue um panorama das principais ferramentas de scraping em Python e quando lançar mão de cada uma:
| Ferramenta/Biblioteca | Quando Usar... | Vantagens | Desvantagens |
|---|---|---|---|
| Requests + BeautifulSoup | Páginas estáticas ou tarefas pequenas | Simples, rápido, ótimo para quem está começando. Controle total. | Não dá conta de JavaScript nem de grandes volumes de dados. |
| Scrapy | Projetos grandes, muitos sites/páginas | Alta performance, crawling embutido, assíncrono, pipelines e tratamento de erros robusto. | Aprendizado mais puxado, configuração inicial trabalhosa. |
| Selenium/Playwright | Páginas com JavaScript, login ou ações do usuário | Extrai tudo o que o navegador mostra. Dá conta de conteúdo dinâmico, logins e rolagem. | Mais lento, consome mais recursos, deploy mais complicado. |
| Thunderbit (IA) | Dados não estruturados, PDFs, imagens ou sem código | A IA detecta os campos sozinha, lida com subpáginas, exporta para Excel/Sheets, zero programação. | Menos personalizável em casos muito específicos, uso por créditos. |
Para a maioria das empresas, começar com requests e BeautifulSoup resolve direitinho sites simples e estáticos. Se a tarefa cresce ou complica, o Scrapy é o caminho. E quando o bicho pega — conteúdo dinâmico, anti-bot ou dados bagunçados — ferramentas de IA como o Thunderbit salvam o dia.
Experimente o Raspador Web IA Thunderbit gratuitamente
Mapeando o Terreno: Passo a Passo para Scraping Complexo
Como sair do “eu queria esses dados” e chegar num raspador robusto, que aguenta tranco? Olha o meu passo a passo, testado no campo de batalha:
1. Inspecione e Entenda o Site-Alvo
Antes de sair codando, abra as Ferramentas do Desenvolvedor do navegador (F12 ou botão direito > Inspecionar) e localize os dados no HTML. Estão numa tabela? Em <div>s? Tem alguma chamada de API trazendo JSON? Volta e meia o caminho mais curto está bem na sua frente.
Dica: se, ao clicar em “próxima página” ou “carregar mais”, pipoca uma requisição de rede trazendo JSON, na maioria das vezes dá para esquecer o HTML e ir direto nessa API com Python.
2. Faça um Protótipo em Uma Página
Comece pequeno. Use requests para buscar uma página e BeautifulSoup para puxar alguns campos. Imprima o resultado. Se levar bloqueio ou faltar dado, tente adicionar headers (tipo um User-Agent de navegador) ou veja se o conteúdo vem por JavaScript (se for o caso, pula para o passo 3).
3. Lide com Conteúdo Dinâmico e Paginação
Se os dados não estão no HTML, provavelmente vêm via JavaScript. O que fazer:
- Automação de Navegador: use Selenium ou Playwright para abrir a página, esperar carregar e capturar o HTML já renderizado.
- Chamada de API: fuce as requisições XHR na aba de rede. Achou um endpoint devolvendo JSON? Replique essa chamada com
requests. - Paginação: para dados espalhados em várias páginas, faça um loop pelos números de página ou siga os links “Próximo”. Para rolagem infinita, use Selenium para rolar a página ou simule as chamadas de API que a rolagem dispara.
4. Tratamento de Erros e Boas Práticas
Site nenhum é fã de raspador. Para não levar bloqueio:
- Respeite o
robots.txt: sempre dê uma olhada emexample.com/robots.txtpara ver caminhos proibidos e delays. - Limite de Taxa: use
time.sleep()entre as requisições. Se orobots.txtpedirCrawl-delay: 5, espere no mínimo 5 segundos. - User-Agent Personalizado: identifique seu raspador de forma educada (ex.:
"MeuRaspador/1.0 (seu@email.com)"). - Lógica de Retentativa: envolva as requisições em try/except. Falhou, tenta de novo; tomou HTTP 429 (Muitas Requisições), pisa no freio.
5. Extraia e Limpe os Dados
Use BeautifulSoup ou os seletores do Scrapy para puxar os campos. Tire os espaços em branco, converta preço em número, ajuste datas e valide tudo. Para grandes volumes, deixe o pandas cuidar da limpeza e da deduplicação.
6. Scraping de Subpáginas
Volta e meia o ouro está nas páginas de detalhe. Extraia uma lista de links e visite um por um para colher mais dados. Em Python, é só iterar pelas URLs e buscar cada página. No Thunderbit, você usa o recurso “Raspar Subpáginas” — a IA visita cada subpágina e turbina seu dataset.
7. Exporte e Automatize
Exporte os dados já limpos para CSV, Excel, Google Sheets ou banco de dados. Para tarefas que se repetem, agende seu script com cron, Airflow ou (se for Thunderbit) configure uma raspagem agendada na nuvem em linguagem natural (“toda segunda-feira às 9h”).
Como Extrair Dados de Sites para Excel usando IA Get Started Free
Thunderbit: Quando a IA Potencializa seu Scraping com Python
Sem rodeios: tem hora que nem o melhor código Python dá conta de dado desestruturado ou protegido. É justamente aí que entra o Thunderbit.
Como o Thunderbit Complementa o Python
O Thunderbit é uma extensão do Chrome com IA que lê páginas web (ou PDFs, imagens etc.) e devolve dados estruturados — sem você escrever uma linha. Veja como eu uso junto com Python:
- Para Dados Não Estruturados: caiu na minha mão um PDF, uma imagem ou um site com HTML caótico? Solto a IA do Thunderbit em cima. Ela extrai tabela de PDF, texto de imagem e até sugere os campos sozinha.
- Para Subpáginas e Etapas Múltiplas: o recurso “Raspar Subpáginas” do Thunderbit poupa um tempão. Extraio uma página de listagem, deixo a IA visitar cada detalhe e juntar os resultados — sem precisar montar loop aninhado nem ficar gerenciando estado.
- Para Exportação: o Thunderbit manda direto para Excel, Google Sheets, Notion ou Airtable. Depois, importo esses dados para o meu pipeline Python e sigo com análise ou relatório.
Exemplo Prático: Python + Thunderbit em Ação
Digamos que eu esteja monitorando anúncios de imóveis. Uso Python e Scrapy para coletar as URLs dos anúncios em vários sites. Só que um deles solta os detalhes apenas em PDF para download. Em vez de escrever um parser de PDF do zero, mando os arquivos para o Thunderbit, deixo a IA extrair as tabelas e exporto para CSV. Aí junto tudo no Python e faço uma análise de mercado completa.
Outro caso: montar uma lista de leads para vendas. Uso Python para raspar as URLs das empresas e o Thunderbit para extrair e-mails e telefones (recursos gratuitos!) de cada site — sem precisar de regex.
Extraia Dados Não Estruturados com Thunderbit IA
Construindo um Fluxo de Scraping Sustentável: Do Código ao Pipeline
Um script de uma vez só resolve o problema do dia, mas quase toda demanda de scraping nas empresas é recorrente. Veja como eu estruturo um fluxo que se sustenta e escala:
O Framework CCCD: Rastrear, Coletar, Limpar, Depurar
- Rastrear: reúna todas as URLs-alvo (de sitemaps, páginas de busca ou listas).
- Coletar: extraia os dados de cada URL (com Python, Thunderbit ou os dois juntos).
- Limpar: normalize, deduplique e valide os dados.
- Depurar/Monitorar: registre cada execução, trate os erros e configure alertas para falhas ou anomalias.
Pensa nisso como um pipeline:
URLs → [Rastreador] → [Raspador] → [Limpador] → [Exportador] → [Plataforma de Negócios]
Agendamento e Monitoramento
- Com Python: use cron, Airflow ou agendadores na nuvem para rodar os scripts de tempos em tempos. Registre as saídas e dispare alerta por e-mail ou Slack quando der erro.
- Com Thunderbit: use o agendador embutido — é só digitar “toda segunda-feira às 9h” e o Thunderbit roda a raspagem na nuvem e exporta os dados para onde você quiser.
Documentação e Repasse
Mantenha o código sob controle de versão (Git), documente o fluxo e garanta que pelo menos mais uma pessoa saiba rodar ou atualizar o pipeline. Em fluxos mistos Python/Thunderbit, deixe anotado qual ferramenta cuida de cada site e para onde vão os dados (ex.: “Thunderbit raspa o Site C para o Google Sheets, Python junta tudo toda semana”).
Ética e Conformidade: Scraping Responsável em 2025
Com grande poder de scraping vem grande responsabilidade. Veja como agir de forma ética e dentro da lei:
Robots.txt e Limite de Taxa
- Confira o robots.txt: sempre olhe o robots.txt do site para ver caminhos proibidos e delays. Use o
robotparserdo Python para automatizar a checagem. - Scraping Educado: coloque intervalos entre as requisições, principalmente se houver
Crawl-delay. Nunca martele o site com acessos em rajada. - User-Agent: identifique seu raspador de forma honesta. Não se passe por Googlebot nem por outro navegador.
Privacidade de Dados e Conformidade
- GDPR/CCPA: se for coletar dado pessoal (nome, e-mail, telefone), siga as leis de privacidade. Extraia só o necessário, proteja os dados e esteja pronto para apagá-los se alguém pedir.
- Termos de Uso: não raspe áreas protegidas por login sem permissão. Muitos ToS proíbem acesso automatizado — furar isso pode dar ban ou até virar caso jurídico.
- Apenas Dados Públicos: fique só na informação pública. Não tente acessar dado privado, protegido por direito autoral ou sensível.
Checklist de Conformidade
- Conferiu o robots.txt para regras e delays
- Colocou limite de taxa e User-Agent personalizado
- Raspa só dado público e não sensível
- Trata dado pessoal conforme a lei
- Não viola ToS nem direito autoral
Erros Comuns e Dicas de Depuração: Tornando seu Scraping Robusto
Até o melhor raspador encara pepino. Veja os mais comuns — e como eu costumo destravar cada um:
| Tipo de Erro | Sintoma/Mensagem | Dica de Depuração |
|---|---|---|
| HTTP 403/429/500 | Bloqueio, limite de taxa ou erro no servidor | Cheque os headers, reduza a velocidade, alterne IPs ou use proxies. Respeite os delays de crawling. |
| Dados Ausentes/NoneType | Dado não encontrado no HTML | Imprima e inspecione o HTML. Pode ter mudado a estrutura ou ser página de bloqueio. |
| Dados Renderizados em JS | Dado ausente no HTML estático | Use Selenium/Playwright ou ache a chamada de API por trás. |
| Problemas de Parsing/Codificação | Erro de unicode, caractere estranho | Defina a codificação correta, use .text ou html.unescape(). |
| Duplicatas/Inconsistências | Dado repetido ou desencontrado | Deduplique por ID único ou URL. Valide a integridade dos campos. |
| Anti-Bot/CAPTCHA | Página de CAPTCHA ou login obrigatório | Pise no freio, use automação de navegador ou recorra ao Thunderbit/IA nos casos mais cabeludos. |
Fluxo de Depuração:
- Imprima o HTML bruto sempre que algo der errado.
- Use as DevTools do navegador para comparar o que o script vê com o que o navegador mostra.
- Registre cada etapa — URLs, códigos de status, número de itens extraídos.
- Teste num conjunto pequeno antes de escalar.
Projetos Avançados: Coloque o Scraping em Prática
Bora pôr a mão na massa? Olha umas ideias de projeto bem reais:
1. Painel de Monitoramento de Preços para E-commerce
Extraia preço e estoque da Amazon, eBay e Walmart. Encare o anti-bot, o conteúdo dinâmico e exporte todo dia para o Google Sheets para acompanhar tendência. Use modelos instantâneos do Thunderbit para ter resultado rápido.
2. Agregador de Vagas de Emprego
Junte anúncios do Indeed e de sites de nicho. Extraia título, empresa, localização e data. Lide com paginação e tire as duplicatas pelo ID da vaga. Agende execuções diárias e exporte para o Airtable.
3. Extrator de Contatos para Geração de Leads
Com uma lista de URLs de empresas, extraia e-mails e telefones das páginas inicial e de contato. Use regex no Python ou os extratores gratuitos do Thunderbit para resultado na hora. Exporte para Excel e entregue ao time de vendas.
4. Comparador de Anúncios Imobiliários
Extraia anúncios do Zillow e do Realtor.com para uma região específica. Normalize endereços e preços, compare tendências e visualize tudo no Google Sheets.
5. Monitor de Menções em Redes Sociais
Acompanhe menções de marcas no Reddit usando a API JSON. Some a contagem de posts, analise sentimento e exporte a série temporal para insights de marketing.
Conclusão: O Essencial do Scraping com Python em 2025
Recapitulando os pontos-chave:
- Raspador web está mais importante do que nunca para inteligência de negócio, vendas e operações. A web é um baú de tesouro — para quem sabe garimpar.
- Python é seu canivete suíço: comece simples com
requestseBeautifulSoup, escale com Scrapy e use automação de navegador nos sites dinâmicos. - Ferramentas de IA como o Thunderbit são seu trunfo para scraping sem código, dado complexo ou desestruturado. Misture Python e IA para eficiência máxima.
- Boas práticas fazem diferença: inspecione primeiro, escreva código modular, trate os erros, limpe os dados e automatize o fluxo.
- Conformidade não é opcional: sempre confira o robots.txt, respeite as leis de privacidade e raspe de forma ética.
- Seja adaptável: a web muda — monitore seus raspadores, depure com frequência e esteja pronto para ajustar a rota.
O futuro do raspador web é híbrido, ético e voltado ao negócio. Iniciante ou veterano, siga aprendendo, mantenha a curiosidade e deixe os dados impulsionarem o seu próximo grande resultado.
Apêndice: Recursos e Ferramentas para Scraping com Python
Aqui vai a minha lista de cabeceira para estudar e sair de qualquer perrengue:
- Documentação do Requests – HTTP para humanos, com tudo o que você precisa.
- Documentação do BeautifulSoup – Aprenda a destrinchar HTML feito gente grande.
- Documentação do Scrapy – Para scraping em larga escala e em produção.
- Selenium com Python / Playwright para Python – Para automação de navegador e conteúdo dinâmico.
- Extensão Thunderbit para Chrome – O Raspador Web IA mais fácil para empresas.
- Blog do Thunderbit – Tutoriais, estudos de caso e melhores práticas de scraping com IA.
- Guia Legal da AIMultiple – Para ficar por dentro de conformidade e ética.
- Stack Overflow / Reddit r/webscraping** – Comunidade para tirar dúvida e achar solução.
E se quiser ver como o Thunderbit facilita sua vida no scraping, dá um pulo no nosso canal no YouTube para conferir demonstrações e tutoriais.
Perguntas Frequentes
1. Qual a melhor biblioteca Python para raspador web em 2025?
Para página estática e tarefa pequena, requests + BeautifulSoup continua sendo a dupla imbatível. Para scraping em larga escala ou multipáginas, o Scrapy é o ideal. Para conteúdo dinâmico, use Selenium ou Playwright. E para dado desestruturado ou complicado, ferramentas de IA como o Thunderbit são indispensáveis.
2. Como lidar com site dinâmico ou pesado em JavaScript?
Use uma ferramenta de automação de navegador como Selenium ou Playwright para renderizar a página e extrair os dados. Ou, então, inspecione a aba de rede para achar as chamadas de API que devolvem JSON — geralmente raspar por aí é mais fácil e confiável.
3. Raspador web é legal?
Raspar dado público costuma ser permitido nos EUA, mas sempre confira o robots.txt, respeite os termos do site e siga leis de privacidade como GDPR/CCPA. Nunca raspe informação privada, protegida por direito autoral ou sensível.
4. Como automatizar e agendar fluxos de scraping?
Para script Python, use cron, Airflow ou agendadores na nuvem. Para automação sem código, o Thunderbit tem agendamento embutido — é só descrever o cronograma em português e deixar rodando na nuvem.
5. O que fazer se meu raspador parar de funcionar?
Primeiro, veja se a estrutura do site mudou ou se você levou bloqueio (HTTP 403/429). Inspecione o HTML, atualize os seletores, diminua a frequência das requisições e cheque as medidas anti-bot. Se o problema persistir, experimente os recursos de IA do Thunderbit ou parta para automação de navegador.
Boas raspagens — que seus dados estejam sempre limpos, em conformidade e prontos para uso. Se quiser ver como o Thunderbit entra no seu fluxo, baixe a extensão para Chrome e experimente. E, para mais dicas, o Blog do Thunderbit está sempre de portas abertas.
Experimente o Raspador Web IA Thunderbit gratuitamente Get Started Free




