
A internet virou uma verdadeira floresta de imagens — são bilhões de fotos subindo todos os dias, abastecendo desde vitrines de e-commerce até memes que viralizam em segundos. Se você trabalha com vendas, marketing ou pesquisa, já deve ter sentido na pele o perrengue de coletar imagens uma por uma. Eu mesmo já fiquei preso naquele ciclo infinito do “clicar com o botão direito e salvar como”, pensando: não tem um jeito mais esperto de fazer isso? Tem sim! Hoje, com raspadores de imagens em Python e ferramentas sem código como o , baixar imagens em massa de sites ficou muito mais fácil.
Neste guia, vou te mostrar como usar Python para raspar imagens da web, como lidar com sites dinâmicos e por que juntar Python com Thunderbit pode ser a combinação perfeita. Seja para montar um catálogo de produtos, analisar concorrentes ou simplesmente dar fim ao copia-e-cola, aqui você vai encontrar dicas práticas, exemplos de código e até umas risadas no caminho.
O que é um Raspador de Imagens em Python?
Um raspador de imagens em Python nada mais é do que um script ou ferramenta que acessa sites automaticamente, identifica arquivos de imagem (tipo aqueles nas tags <img>) e faz o download direto pro seu computador. Em vez de salvar cada foto manualmente, o Python faz todo o trabalho pesado — acessa as páginas, lê o HTML e baixa tudo de uma vez ().
Quem usa raspador de imagens em Python? Praticamente todo mundo que precisa de muitas imagens, rápido:
- Times de e-commerce: Baixam fotos de produtos de fornecedores para montar catálogos.
- Pessoal de marketing: Coletam imagens de redes sociais para campanhas ou análise de tendências.
- Pesquisadores: Criam bancos de dados para projetos de IA/ML ou estudos acadêmicos.
- Corretores de imóveis: Juntam fotos de imóveis para anúncios ou análise de mercado.
Pensa no raspador de imagens em Python como aquele estagiário digital que não cansa e não se distrai com meme de gato.
Por que usar Python para raspar imagens da web?
 Python é tipo o canivete suíço da raspagem de dados. Olha só por que ele é tão usado pra coletar imagens:
Python é tipo o canivete suíço da raspagem de dados. Olha só por que ele é tão usado pra coletar imagens:
- Ecossistema cheio de bibliotecas: Ferramentas como Requests, BeautifulSoup e Selenium resolvem desde HTML simples até sites cheios de JavaScript ().
- Fácil de aprender: A sintaxe é tranquila e tem tutorial e fórum de sobra na internet.
- Flexível e escalável: Dá pra raspar uma página ou milhares, automatizar downloads e até processar as imagens depois.
- Economiza tempo e dinheiro: Um teste mostrou que baixar 100 imagens com Python leva uns 12 minutos, contra 2 horas fazendo na mão ().
Veja alguns exemplos de uso no dia a dia:
| Caso de Uso | Problema Manual | Vantagem do Raspador Python |
|---|---|---|
| Catalogação de produtos | Horas de copia-e-cola | Baixe milhares de imagens em minutos |
| Análise de concorrentes | Detalhes perdidos, lento | Compare imagens em massa lado a lado |
| Pesquisa de tendências | Dados incompletos | Colete grandes amostras de imagens |
| Construção de dataset IA/ML | Rotulagem cansativa | Automatize coleta e preparação |
| Anúncios imobiliários | Dados desatualizados | Centralize e atualize fotos facilmente |
Ferramentas essenciais para raspagem de imagens com Python
Vamos ao kit básico do Python pra raspar imagens:
| Biblioteca | O que faz | Melhor para | Prós | Contras |
|---|---|---|---|---|
| Requests | Busca páginas e imagens via HTTP | Sites estáticos | Simples, rápido | Não analisa HTML, sem suporte a JS |
| BeautifulSoup | Analisa HTML para encontrar tags <img> | Extrair URLs de imagens | Fácil de usar, tolerante | Não suporta JS |
| Scrapy | Framework completo de raspagem/crawling | Projetos grandes | Assíncrono, exportação nativa | Curva de aprendizado maior |
| Selenium | Automatiza navegador (lida com JS, scroll) | Sites dinâmicos/com JS | Roda JS, simula usuário | Mais lento, exige configuração |
| Pillow (PIL) | Processa imagens após download | Verificação/edição de imagens | Redimensiona, converte, verifica | Não raspa, só processa imagens |
Quando usar cada uma?
- Para a maioria dos sites estáticos:
requests + BeautifulSoupresolve. - Para sites dinâmicos (scroll infinito, galerias JS):
Seleniumé o caminho. - Para projetos grandes e repetitivos:
Scrapytraz estrutura e velocidade. - Para processar imagens:
Pilloworganiza tudo depois do download.
Passo a passo: como baixar imagens de um site usando Python
Bora colocar a mão na massa! Veja como usar Python pra baixar imagens de um site estático.
Preparando o ambiente Python
Primeiro, garanta que o Python 3 está instalado. Depois, crie um ambiente virtual (opcional, mas vale a pena):
1python3 -m venv venv
2source venv/bin/activate # No Windows: venv\Scripts\activateInstale as bibliotecas necessárias:
1pip install requests beautifulsoup4Encontrando e extraindo URLs de imagens
Abra o site no navegador. Clique com o botão direito e escolha “Inspecionar” pra achar as tags <img> — é nelas que estão as imagens.
Veja um exemplo de script pra buscar e extrair URLs de imagens:
1import requests
2from bs4 import BeautifulSoup
3from urllib.parse import urljoin
4import os
5url = "https://example.com"
6response = requests.get(url)
7soup = BeautifulSoup(response.text, "html.parser")
8img_tags = soup.find_all("img")
9img_urls = [urljoin(url, img.get("src")) for img in img_tags if img.get("src")]Dica: Alguns sites usam data-src ou srcset pra carregar imagens sob demanda. Fique de olho nesses atributos também.
Baixando e salvando as imagens
Vamos salvar as imagens numa pasta:
1os.makedirs("images", exist_ok=True)
2for i, img_url in enumerate(img_urls):
3 try:
4 img_resp = requests.get(img_url, headers={"User-Agent": "Mozilla/5.0"})
5 if img_resp.status_code == 200:
6 file_ext = img_url.split('.')[-1].split('?')[0]
7 file_name = f"images/img_{i}.{file_ext}"
8 with open(file_name, "wb") as f:
9 f.write(img_resp.content)
10 print(f"Downloaded {file_name}")
11 except Exception as e:
12 print(f"Failed to download {img_url}: {e}")Dicas pra organizar:
- Nomeie os arquivos com base em IDs de produtos ou títulos das páginas, se der.
- Use subpastas pra separar categorias ou fontes.
- Verifique duplicatas antes de salvar (compare URLs ou use hashes).
Erros comuns e como resolver
- Imagens sumindo? Podem ser carregadas via JavaScript — veja a próxima seção.
- Requisições bloqueadas? Use um User-Agent realista e adicione
time.sleep()entre os downloads. - Downloads duplicados? Mantenha uma lista de URLs ou nomes de arquivos já baixados.
- Erros de permissão? Veja se o script tem acesso de escrita na pasta de destino.
Raspando imagens de páginas dinâmicas e com JavaScript
Tem site que complica — carrega imagens via JavaScript, tem scroll infinito ou botão de “carregar mais”. Veja como lidar com eles usando Selenium.
Usando Selenium para conteúdo dinâmico
Primeiro, instale o Selenium e um driver de navegador (tipo ChromeDriver):
1pip install seleniumBaixe o e coloque no seu PATH.
Veja um script básico com Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3import time
4import os
5driver = webdriver.Chrome()
6driver.get("https://example.com/gallery")
7# Role até o final da página pra carregar mais imagens
8last_height = driver.execute_script("return document.body.scrollHeight")
9while True:
10 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
11 time.sleep(2) # Espera as imagens carregarem
12 new_height = driver.execute_script("return document.body.scrollHeight")
13 if new_height == last_height:
14 break
15 last_height = new_height
16img_elements = driver.find_elements(By.TAG_NAME, "img")
17img_urls = [img.get_attribute("src") for img in img_elements if img.get_attribute("src")]
18os.makedirs("dynamic_images", exist_ok=True)
19for i, img_url in enumerate(img_urls):
20 # (Lógica de download igual ao exemplo anterior)
21 pass
22driver.quit()Dicas avançadas:
- Use
WebDriverWaitpra esperar as imagens carregarem. - Se o site exige clique pra mostrar imagens, use
element.click().
Alternativas: Ferramentas como Playwright (com suporte a Python) podem ser mais rápidas e confiáveis pra sites mais chatos ().
Alternativa sem código: raspando imagens de sites com Thunderbit
Nem todo mundo quer mexer com código ou instalar driver de navegador. É aí que entra o — uma extensão de Chrome com IA que permite extrair imagens de sites de forma simples, sem precisar programar nada.
Como extrair imagens com Thunderbit
- Instale o Thunderbit: Baixe a .
- Abra o site desejado: Entre na página com as imagens que você quer.
- Inicie o Thunderbit: Clique no ícone da extensão pra abrir a barra lateral.
- AI Sugere Campos: Clique em “AI Sugere Campos” — a IA do Thunderbit analisa a página e detecta automaticamente as imagens, criando uma coluna “Imagem” pra você ().
- Raspe: Clique em “Raspar”. O Thunderbit coleta todas as imagens, até de subpáginas ou scroll infinito.
- Exporte: Baixe os URLs das imagens ou os arquivos direto pra Excel, Google Sheets, Notion, Airtable ou CSV — sem custo extra, até no plano gratuito.
Bônus: O Extrator de Imagens gratuito do Thunderbit pega todos os URLs de imagens de uma página com um clique ().
Por que o Thunderbit é sensacional:
- Não precisa saber nada de código ou HTML.
- Lida sozinho com conteúdo dinâmico, subpáginas e paginação.
- Exportação instantânea e ilimitada (até no plano grátis).
- A IA se adapta se o site mudar — sem dor de cabeça pra manter.
Combinando Python e Thunderbit: o melhor dos dois mundos
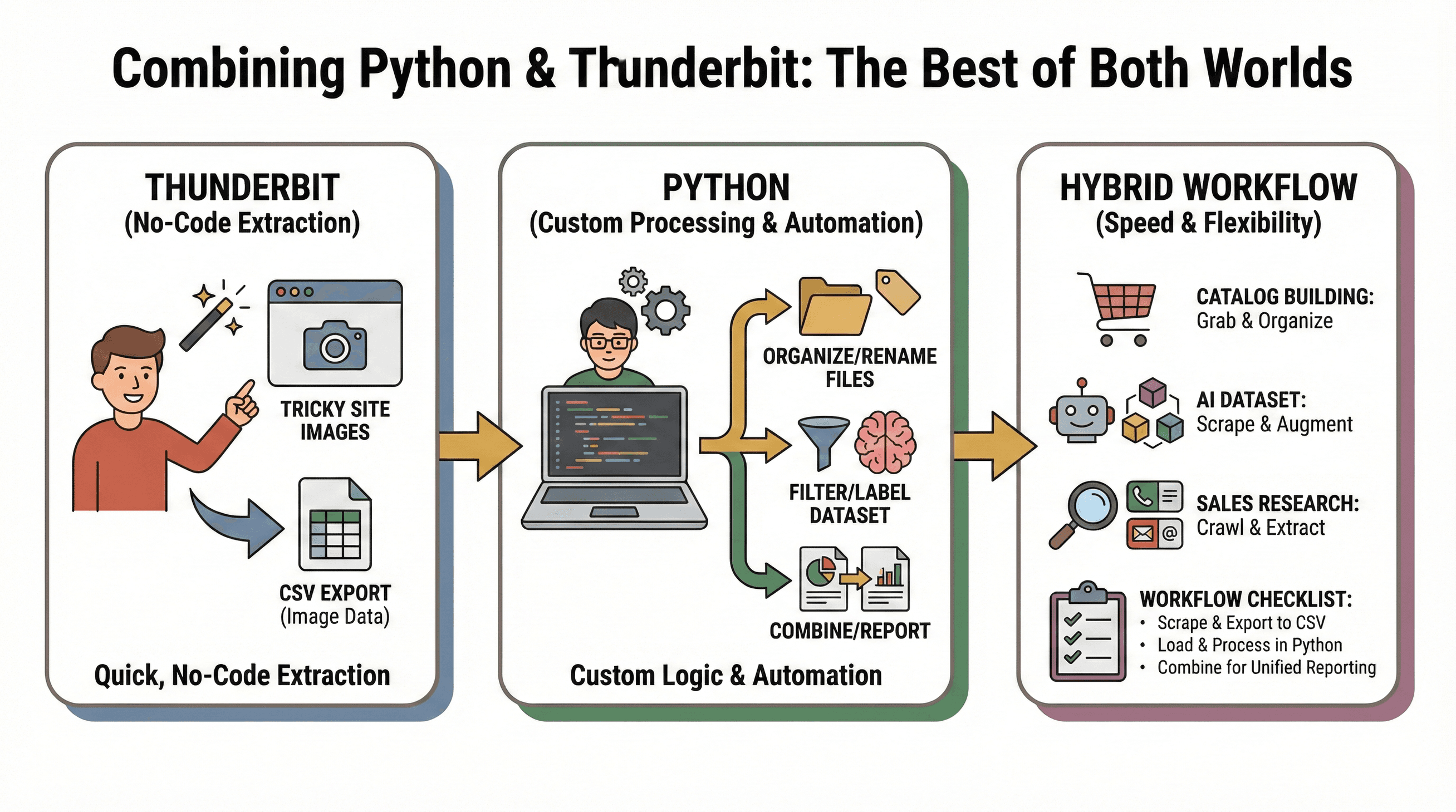 Aqui vai meu fluxo de trabalho favorito: use o Thunderbit pra extrair imagens rapidinho, sem código, e Python pra processar ou automatizar do seu jeito.
Aqui vai meu fluxo de trabalho favorito: use o Thunderbit pra extrair imagens rapidinho, sem código, e Python pra processar ou automatizar do seu jeito.
Exemplos de uso:
- Montar catálogos: Use o Thunderbit pra coletar imagens de um site complicado, depois organize, renomeie ou processe os arquivos com Python.
- Criar datasets pra IA: O Thunderbit raspa imagens de várias fontes; scripts em Python filtram, rotulam ou aumentam o dataset.
- Pesquisa de vendas: Python percorre uma lista de URLs de empresas; Thunderbit extrai imagens, e-mails ou telefones de cada site.
Checklist do fluxo de trabalho:
- Use o Thunderbit pra raspar imagens e exportar pra CSV.
- Carregue o CSV no Python pra análise ou automação.
- Una dados de várias fontes pra relatórios completos.
Esse jeito híbrido te dá velocidade, flexibilidade e capacidade pra encarar qualquer desafio de raspagem de imagens na web.
Dicas e melhores práticas para raspagem de imagens com Python
Problemas comuns:
- Requisições bloqueadas: Use um User-Agent, adicione intervalos e respeite o
robots.txt. - Imagens sumindo: Veja se o conteúdo é carregado via JS — use Selenium ou Thunderbit.
- Downloads duplicados: Controle URLs já baixados ou use hashes dos arquivos.
- Arquivos corrompidos: Use Pillow pra checar as imagens depois do download.
Boas práticas:
- Organize as imagens em pastas claras (por site, categoria ou data).
- Use nomes de arquivos descritivos (ID do produto, título da página).
- Filtre imagens irrelevantes (anúncios, ícones) conferindo tamanho ou dimensões.
- Sempre confira direitos autorais e termos de uso antes de raspar imagens ().
Comparando soluções de raspagem de imagens em Python: código vs. sem código
Veja um comparativo lado a lado das opções:
| Critério | Python (Requests/BS) | Selenium (Python) | Thunderbit (No-Code) |
|---|---|---|---|
| Facilidade de uso | Média (exige código) | Difícil (código + automação) | Muito fácil (clique, IA) |
| Conteúdo dinâmico | Não | Sim | Sim |
| Tempo de setup | Maior (instalar, codar) | Longo (drivers, código) | Muito curto (instalar extensão) |
| Escalabilidade | Manual (pode paralelizar) | Lento (navegador) | Alta (raspagem em nuvem, 50 páginas de uma vez) |
| Manutenção | Alta (scripts quebram se o site muda) | Alta | Baixa (IA se adapta automaticamente) |
| Opções de exportação | Personalizado (CSV, BD) | Personalizado | Um clique para Excel, Sheets, Notion, etc. |
| Custo | Gratuito (open source) | Gratuito | Plano grátis, pago para alto volume |
Resumo: Se você curte programar e quer controle total, Python é imbatível. Pra velocidade, simplicidade e sites dinâmicos, Thunderbit salva o dia. A maioria das equipes se dá bem usando os dois juntos.
Conclusão & principais aprendizados
A explosão de imagens na web faz com que dados visuais sejam cada vez mais valiosos — e difíceis de organizar. Raspadores de imagens em Python dão poder e flexibilidade pra automatizar downloads, enquanto ferramentas sem código como o Thunderbit tornam a raspagem acessível pra todo mundo.
Principais aprendizados:
- Use Python (Requests + BeautifulSoup) pra sites estáticos e fluxos personalizados.
- Use Selenium pra páginas dinâmicas e cheias de JavaScript.
- Use Thunderbit pra extração rápida e sem código — especialmente em sites chatos ou quando precisa exportar imagens pra Excel, Google Sheets ou Notion na hora.
- Combine os dois pra um fluxo de trabalho perfeito: Thunderbit pra coleta, Python pra processamento e automação.
Pronto pra turbinar sua raspagem de imagens? Teste um script simples em Python ou e veja quanto tempo você economiza. Pra mais dicas e tutoriais, dá uma olhada no e no .
Boas raspagens — e que suas pastas de imagens fiquem sempre em ordem!
Perguntas frequentes
1. O que é um raspador de imagens em Python?
É um script ou ferramenta que acessa sites automaticamente, encontra arquivos de imagem (geralmente em tags <img>) e faz o download pro seu computador. Assim, você não precisa salvar cada imagem na mão.
2. Quais bibliotecas Python são melhores pra raspar imagens da web?
As mais populares são Requests (pra buscar páginas), BeautifulSoup (pra analisar HTML), Selenium (pra conteúdo dinâmico) e Pillow (pra processar imagens depois do download).
3. Como raspar imagens de sites com JavaScript ou scroll infinito?
Use Selenium pra automatizar o navegador, rolar a página e extrair URLs das imagens depois que tudo carregar. O Thunderbit também lida com conteúdo dinâmico usando IA.
4. Existe uma forma sem código de raspar imagens de sites?
Sim! O Thunderbit é uma extensão de Chrome sem código que usa IA pra detectar e extrair imagens de qualquer site. É só clicar e exportar pra Excel, Google Sheets, Notion ou Airtable.
5. Posso combinar Python e Thunderbit pra raspagem de imagens?
Com certeza. Use o Thunderbit pra extração rápida e sem código e Python pra processamento avançado ou automação. Exporte os dados do Thunderbit e processe com scripts Python pra unir o melhor dos dois mundos.
Saiba mais