

Sejamos sinceros — ninguém acorda animado para copiar e colar 500 linhas de preços de produtos numa folha de cálculo. (Se você acorda, tiro-lhe o chapéu pela resistência e recomendo uma boa munhequeira.) Quer trabalhe em vendas, operações ou esteja apenas a tentar manter a sua empresa um passo à frente da concorrência, provavelmente já sentiu na pele a dificuldade de lidar com dados de sites. O mundo de hoje vive de dados da web, e a procura por extração automatizada está a disparar — o mercado de software de web scraping deve ultrapassar US$ 11 bilhões até 2032.
Passei anos nos bastidores de SaaS e automação e já vi de tudo: de macros heroicas no Excel a scripts em Python remendados às 2 da manhã. Neste guia, vou mostrar como usar um parser html em Python para extrair dados do mundo real — sim, vamos sacar juntos as avaliações de filmes do IMDb — e também vou mostrar por que, em 2026, existe uma forma melhor: ferramentas com IA, como a Thunderbit, que permitem saltar o código e ir direto aos insights.
O que é um parser HTML e por que usar um em Python?
Comecemos pelo princípio: o que faz realmente um parser HTML? Pense nele como uma espécie de bibliotecário pessoal da web. Ele lê o código HTML desarrumado por trás de uma página e organiza tudo numa estrutura limpa, em forma de árvore. Assim, consegue extrair só os dados de que precisa — títulos, preços, links — sem se perder num mar de sinais de menor, maior e divs.
Python é a linguagem preferida para esta tarefa, e com razão. É legível, amigável para quem está a começar e tem um ecossistema enorme de bibliotecas para web scraping e parsing. Na verdade, Python é de longe a linguagem mais popular usada para web scraping, graças à sua curva de aprendizagem suave e ao forte apoio da comunidade.
O elenco de parsers HTML em Python
Aqui estão os principais nomes que vai encontrar ao fazer parsing de HTML em Python:
- BeautifulSoup: a escolha clássica e amigável para iniciantes. Continua a ser mantida ativamente — o
beautifulsoup44.14.3 foi lançado no PyPI no fim de 2025 — por isso os exemplos aqui não o estão a levar para uma biblioteca abandonada. - lxml: rápido e poderoso, com consultas avançadas.
- html5lib: extremamente tolerante com HTML desarrumado, tal como o navegador.
- PyQuery: permite usar seletores ao estilo jQuery em Python.
- HTMLParser: o parser embutido do Python — está sempre disponível, mas é um pouco básico.
Cada um tem as suas particularidades, mas todos ajudam a transformar HTML bruto em dados estruturados.
Principais casos de uso: como as empresas beneficiam dos parsers HTML em Python
A extração de dados da web não é só para quem trabalha com tecnologia ou ciência de dados. Tornou-se uma atividade central para empresas, especialmente em vendas e operações. Eis porquê:
| Caso de uso (setor) | Dados normalmente extraídos | Resultado para o negócio |
|---|---|---|
| Monitorização de preços (retalho) | Preços da concorrência, níveis de stock | Preços dinâmicos, margens melhores (fonte) |
| Inteligência sobre produtos da concorrência | Listagens, avaliações, disponibilidade | Identificar lacunas, gerar leads (fonte) |
| Geração de leads (vendas B2B) | Nomes de empresas, e-mails, contactos | Prospecção automatizada, crescimento do pipeline (fonte) |
| Sentimento de mercado (marketing) | Publicações sociais, avaliações, classificações | Feedback em tempo real, identificação de tendências (fonte) |
| Agregação de imóveis | Anúncios, preços, informações de agentes | Análise de mercado, estratégia de preços (fonte) |
| Inteligência para recrutamento | Perfis de candidatos, salários | Busca de talentos, benchmarking salarial (fonte) |
Resumindo: se ainda copia dados manualmente, está a deixar tempo e dinheiro em cima da mesa.
Conheça o kit de ferramentas de parser HTML em Python: comparação das bibliotecas mais populares
Vamos pôr as mãos na massa. Aqui fica uma comparação rápida das bibliotecas de parser HTML em Python mais populares, para escolher a ferramenta certa para o seu caso:
| Biblioteca | Facilidade de uso | Velocidade | Flexibilidade | Necessidade de manutenção | Ideal para |
|---|---|---|---|---|---|
| BeautifulSoup | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | Moderada | Iniciantes, HTML desarrumado |
| lxml | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Moderada | Velocidade, XPath, documentos grandes |
| html5lib | ⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ | Baixa | Parsing semelhante ao do navegador, HTML quebrado |
| PyQuery | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | Moderada | Fãs de jQuery, seletores CSS |
| HTMLParser | ⭐⭐⭐ | ⭐⭐⭐ | ⭐ | Baixa | Tarefas simples, embutidas no sistema |
BeautifulSoup: a escolha amigável para iniciantes
BeautifulSoup é o “hello world” do parsing HTML. A sintaxe é intuitiva, a documentação é excelente e ele tolera bem HTML feio ou malformado (saiba mais). O ponto fraco? Não é o mais rápido, sobretudo em páginas grandes ou complexas, e não oferece suporte nativo a seletores avançados como XPath.
lxml: rápido e poderoso
Se precisa de velocidade ou quer usar consultas XPath, o lxml é o seu aliado (detalhes). É construído sobre bibliotecas em C, por isso é extremamente rápido, mas pode ser mais chato de instalar e ter uma curva de aprendizagem mais alta.
Outras opções: html5lib, PyQuery e HTMLParser
- html5lib: faz parsing de HTML exatamente como o navegador — ótimo para marcações quebradas ou estranhas, mas é lento (comparação).
- PyQuery: permite usar seletores ao estilo jQuery em Python, o que é útil se vem do front-end (veja a documentação).
- HTMLParser: a opção nativa do Python — rápida e sempre disponível, mas menos completa.
Etapa 1: a configurar o seu ambiente de parser HTML em Python
Antes de fazer qualquer parsing, precisa de configurar o seu ambiente em Python. Eis como:
-
Instale o Python: descarregue em python.org se ainda não tiver.
-
Instale o pip: normalmente já vem com o Python 3.4+, mas pode confirmar executando
pip --versionno terminal. -
Instale as bibliotecas (vamos usar BeautifulSoup e requests neste tutorial):
pip install beautifulsoup4 requests lxmlbeautifulsoup4é o parser.requestspermite buscar páginas da web.lxmlé um parser rápido que o BeautifulSoup pode usar nos bastidores.
-
Verifique a instalação:
python -c "import bs4, requests, lxml; print('Tudo certo!')"
Dicas de resolução de problemas:
- Se aparecer um erro de permissão, tente
pip install --user ... - No Mac/Linux, talvez tenha de usar
python3epip3. - Se surgir “ModuleNotFoundError”, confirme a escrita e o ambiente Python.
Etapa 2: fazer o parsing da sua primeira página da web com Python
Vamos pôr as mãos na massa e extrair os 250 melhores filmes do IMDb. Vamos sacar os títulos, os anos e as notas.
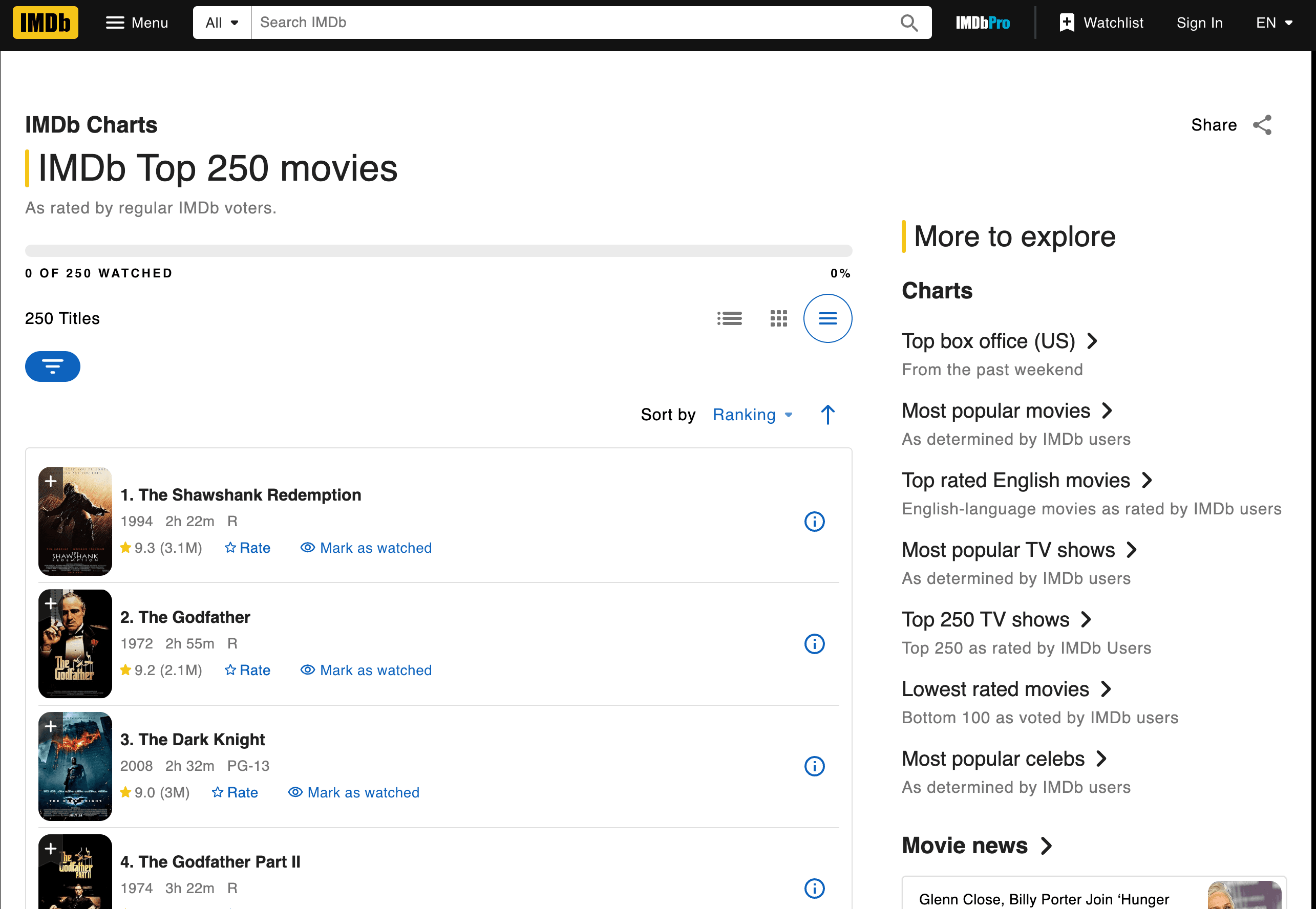
Buscar e fazer o parsing da página
Aqui fica um script passo a passo. Um aviso rápido antes de copiar: o IMDb redesenhou a página Top 250 em junho de 2023, por isso os antigos seletores td.titleColumn / td.ratingColumn que ainda vê em tutoriais antigos já não correspondem a nada. A marcação atual usa classes com prefixo ipc- geradas pelo sistema de componentes deles, e o IMDb reorganizou a página mais algumas vezes desde então (incluindo em meados de 2025), por isso vale a pena voltar a inspecionar tudo no DevTools sempre que regressar a este exemplo.
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/top/"
headers = {"User-Agent": "Mozilla/5.0"} # IMDb devolve marcação reduzida sem um UA real
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, "html.parser")
# Cada linha é um item de lista dentro do contentor do ranking
rows = soup.select("li.ipc-metadata-list-summary-item")
for i, row in enumerate(rows[:3], start=1):
title_el = row.select_one("h3.ipc-title__text")
year_el = row.select_one("span.cli-title-metadata-item")
rating_el = row.select_one("span.ipc-rating-star--rating")
title = title_el.get_text(strip=True) if title_el else None
# O texto do h3 vem como "1. Um Sonho de Liberdade" — remova o prefixo da posição
if title and ". " in title:
title = title.split(". ", 1)[1]
year = year_el.get_text(strip=True) if year_el else None
rating = rating_el.get_text(strip=True) if rating_el else None
print(f"{i}. {title} ({year}) -- Nota: {rating}")
O que está a acontecer aqui?
- Usamos
requests.get()para buscar a página (com umUser-Agentque parece real — o IMDb às vezes entrega uma versão simplificada a clientespython-requestssem identificação apropriada). BeautifulSoupfaz o parsing do HTML.- Vamos buscar cada linha de filme com
li.ipc-metadata-list-summary-iteme, depois, extrair o título (h3.ipc-title__text), o ano (span.cli-title-metadata-item) e a nota (span.ipc-rating-star--rating) de dentro dela comselect_one(). - Extraímos o texto do título, do ano e da nota, removendo o número de posição inicial (
"1. ") que o IMDb inclui no texto do título.
Se quiser algo mais durável do que andar a perseguir mudanças de nomes de classe a cada poucos meses, o IMDb também disponibiliza um bloco <script type="application/ld+json"> na mesma página com os mesmos dados em formato estruturado — pode analisá-lo com json.loads(soup.find("script", type="application/ld+json").string) e percorrer o array itemListElement. Essa é a abordagem que eu usaria em produção; a versão com seletores CSS acima é mais fácil de ensinar, mas também mais frágil.
Saída:
1. A Redenção de Shawshank (1994) -- Nota: 9.3
2. O Poderoso Chefão (1972) -- Nota: 9.2
3. Batman: O Cavaleiro das Trevas (2008) -- Nota: 9.0
Extrair dados: encontrar títulos, notas e mais
Como é que eu soube quais tags e classes usar? Inspecionei o HTML da página do IMDb (clique com o botão direito > Inspecionar elemento no navegador). Procure padrões — aqui, cada linha do filme fica dentro de um <li class="ipc-metadata-list-summary-item">, com o título dentro de <h3 class="ipc-title__text"> e a nota dentro de <span class="ipc-rating-star--rating">. Um cuidado importante: o IMDb já alterou esta marcação mais de uma vez (o layout td.titleColumn que ainda encontra em tutoriais antigos não funciona desde o redesenho de junho de 2023), por isso trate as strings exatas das classes como exemplos e volte a inspecionar tudo antes de executar o script.
Dica profissional: se estiver a extrair dados de outro site, comece sempre por inspecionar a estrutura HTML e identificar classes ou tags exclusivas.
Guardar e exportar os seus resultados
Vamos guardar os nossos dados num ficheiro CSV:
import csv
movies = []
for i in range(len(title_cells)):
title_cell = title_cells[i]
rating_cell = rating_cells[i]
title = title_cell.a.text
year = title_cell.span.text.strip("()")
rating = rating_cell.strong.text if rating_cell.strong else rating_cell.text
movies.append([title, year, rating])
with open('imdb_top250.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['Título', 'Ano', 'Nota'])
writer.writerows(movies)
Dicas de limpeza de dados:
- Use
.strip()para remover espaços em branco. - Trate dados em falta com verificações
if. - Para exportar para Excel, pode abrir o CSV no Excel ou usar
pandaspara escrever ficheiros.xlsx.
Etapa 3: lidar com mudanças no HTML e desafios de manutenção
É aqui que a coisa fica séria. Os sites adoram mudar o layout — às vezes só para deixar os scrapers a correr atrás do prejuízo (ou pelo menos parece isso). Se o IMDb trocar class="titleColumn" por class="movieTitle", o seu script de repente vai devolver resultados vazios. Já passei por isso, já debugei isso.
Quando os scripts falham: problemas do mundo real
Problemas comuns:
- Seletores não encontrados: o seu código não consegue localizar a tag/classe especificada.
- Resultados vazios: a estrutura da página mudou ou o conteúdo agora é carregado via JavaScript.
- Erros HTTP: o site adicionou medidas anti-bot.
Passos de resolução:
- Verifique se o HTML que está a analisar corresponde ao que aparece no navegador.
- Atualize os seus seletores para refletir a nova estrutura.
- Se o conteúdo for carregado dinamicamente, talvez precise de mudar para uma ferramenta de automação de navegador (como Selenium) ou encontrar um endpoint de API.
A verdadeira dor de cabeça? Se estiver a extrair dados de 10, 50 ou 500 sites diferentes, pode acabar a gastar mais tempo a corrigir scripts do que a analisar dados (veja relatos de programadores).
Etapa 4: escalar — os custos ocultos do parsing manual de HTML em Python
Suponha que queira extrair não só o IMDb, mas também Amazon, Zillow, LinkedIn e uma dúzia de outros sites. Cada um vai precisar do seu próprio script. E, sempre que um site mudar, volta ao editor de código.
Os custos ocultos:
- Trabalho de manutenção: alguns estimam que a manutenção custa 10x o valor da construção inicial.
- Infraestrutura: vai precisar de proxies, tratamento de erros e monitorização.
- Desempenho: escalar significa lidar com concorrência, limites de taxa e muito mais.
- Garantia de qualidade: mais scripts = mais pontos onde algo pode falhar.
Para equipas não técnicas, isto torna-se rapidamente insustentável. É como contratar uma equipa de estagiários para copiar e colar dados o dia inteiro — só que os estagiários são scripts em Python e ficam doentes sempre que um site muda.
Uma nota rápida sobre agentes de codificação com IA
Antes de chegarmos às ferramentas no-code, vale a pena mencionar um meio-termo que praticamente não existia quando a maioria dos tutoriais de “aprenda BeautifulSoup” foi escrita: os agentes de codificação com IA. Ferramentas como Claude Code ou Cursor aceitam sem dificuldade uma descrição em linguagem natural (“busque o Top 250 do IMDb, extraia título / ano / nota para um CSV”) e geram um script funcional com requests + BeautifulSoup de uma só vez, incluindo o tipo de limpeza de seletores que acabámos de fazer manualmente. Para fluxos de navegação em linguagem natural — fazer login, paginar, lidar com banners de cookies — uma biblioteca como Browser Use consegue controlar um navegador sem interface diretamente a partir de um prompt.
Mas elas não fazem os problemas difíceis desaparecerem. Limites de taxa, robots.txt, barreiras de login e defesas anti-bot continuam a ser o seu problema, e quando um seletor falha em silêncio (como aconteceu com o IMDb) ainda precisa de reconhecer o que o agente gerou e corrigir. Por isso, mesmo com um agente no circuito, entender o fluxo de trabalho de parser HTML neste tutorial é o que lhe permite depurar a saída em vez de ficar a olhar para listas vazias.
Para além dos parsers HTML em Python: conheça a Thunderbit, a alternativa com IA
Agora chegamos à parte entusiasmante. E se pudesse saltar o código, saltar a manutenção e simplesmente obter os dados de que precisa — não importa como o site mude?
É exatamente isso que construímos com a Thunderbit. É uma extensão de Chrome de Raspador Web IA que permite extrair dados estruturados de qualquer site em dois cliques. Sem Python, sem scripts, sem dores de cabeça.
Parsers HTML em Python vs. Thunderbit: lado a lado
| Aspeto | Parsers HTML em Python | Thunderbit (veja os preços) |
|---|---|---|
| Tempo de configuração | Alto (instalar, programar, depurar) | Baixo (instalar a extensão, clicar) |
| Facilidade de uso | Exige programação | Sem código — apontar e clicar |
| Manutenção | Alta (scripts quebram com frequência) | Baixa (a IA adapta-se automaticamente) |
| Escalabilidade | Complexa (scripts, proxies, infraestrutura) | Integrada (scraping na nuvem, tarefas em lote) |
| Enriquecimento de dados | Manual (escrever mais código) | Integrado (rotulagem, limpeza, tradução, subpáginas) |
Por que construir quando pode resolver o problema com IA?
Por que escolher IA para extração de dados da web?
O agente de IA da Thunderbit lê a página, entende a estrutura e adapta-se quando algo muda. É como ter um superestagiário que nunca dorme e nunca se queixa quando os nomes das classes mudam.
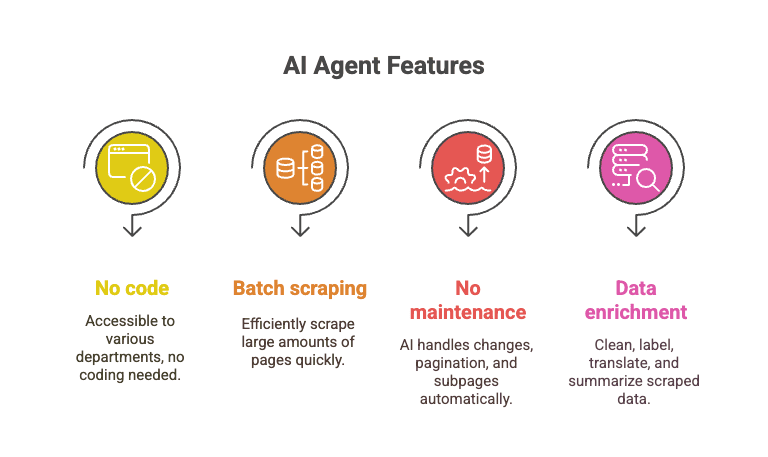
- Sem código: qualquer pessoa pode usar — vendas, operações, marketing, o que quiser.
- Scraping em lote: extraia mais de 10.000 páginas no tempo que levaria para depurar um único script em Python.
- Sem manutenção: a IA trata de mudanças de layout, paginação, subpáginas e muito mais.
- Enriquecimento de dados: limpe, rotule, traduza e resuma os dados enquanto extrai.
O outro lado do fluxo com BeautifulSoup que acabámos de ver é precisamente o tipo de fragilidade que encontramos com os seletores do IMDb acima — quando a página muda de sítio, o script devolve resultados vazios em silêncio, e você passa a tarde no DevTools em vez de olhar para os dados. Um scraper de IA no-code esconde essa etapa atrás da própria camada de inferência; isso é um trade-off real (está a confiar que a extração de outra pessoa está correta), não uma solução mágica.
Passo a passo: extrair as avaliações dos filmes do IMDb com a Thunderbit
Vamos ver como a Thunderbit trata da mesma tarefa no IMDb:
- Instale a extensão Thunderbit para Chrome.
- Aceda à página Top 250 do IMDb.
- Clique no ícone da Thunderbit.
- Clique em “Sugerir campos com IA”. A Thunderbit vai ler a página e recomendar colunas (Título, Ano, Nota).
- Revise ou ajuste as colunas, se necessário.
- Clique em “Extrair”. A Thunderbit vai puxar as 250 linhas instantaneamente.
- Exporte para Excel, Google Sheets, Notion ou CSV — você escolhe.
É isso. Sem código, sem depuração, sem momentos de “porque é que esta lista está vazia?”.
Quer ver na prática? Consulte o canal da Thunderbit no YouTube para tutoriais, ou leia o nosso guia passo a passo para extrair produtos da Amazon para outro exemplo real.
Conclusão: escolher a ferramenta certa para as suas necessidades de dados da web
Parsers HTML em Python como BeautifulSoup e lxml são poderosos, flexíveis e gratuitos. São ótimos para programadores que querem controlo total e não se importam de pôr as mãos na massa. Mas trazem uma curva de aprendizagem elevada, manutenção contínua e custos ocultos — especialmente à medida que as suas necessidades de scraping crescem.
Para utilizadores de negócio, equipas de vendas e qualquer pessoa que só queira os dados — não o código — ferramentas com IA como a Thunderbit são um verdadeiro alívio. Permitem extrair, limpar e enriquecer dados da web em escala, sem código e sem manutenção.
O meu conselho? Use Python se gosta de programar e precisa de personalização total. Mas, se valoriza o seu tempo — e a sua sanidade —, experimente a Thunderbit. Por que construir e andar a cuidar de scripts quando a IA pode fazer o trabalho pesado?
Quer aprender mais sobre web scraping, extração de dados e automação com IA? Explore mais tutoriais no blog da Thunderbit, como Como extrair dados de sites para o Excel usando IA ou As melhores ferramentas e softwares de web scraping em 2025.




