

Algumas pessoas colecionam selos. Outras colecionam tênis. Mas, se você trabalha com vendas, marketing, e-commerce ou operações em 2026, há grandes chances de estar colecionando algo um pouco mais… digital. Dados da web. E não só um pouco — as empresas agora gastam, em média, US$ 5 milhões por ano com coleta de dados da web, e o web scraping já virou uma ferramenta padrão em várias áreas, da estratégia ao atendimento ao cliente (fonte).
Com essa explosão na demanda, dois nomes aparecem sem parar em tutoriais de scraping em Python e projetos de dados empresariais: Playwright e Selenium. Ambos começaram como ferramentas de automação de navegador para testes, mas hoje são os frameworks preferidos de quem quer transformar a web em dados estruturados e acionáveis. Só que há um detalhe: escolher entre eles não é só uma decisão técnica — é decidir qual ferramenta faz mais sentido para suas necessidades reais de scraping. E, se você não é desenvolvedor ou só quer resultados rápidos, existe um caminho ainda mais fácil (dica: sem escrever uma única linha de Python). Vamos lá.
De ferramentas de teste a potências de web scraping: entendendo Playwright e Selenium
Vamos preparar o terreno. Selenium existe desde 2004 e é o velho confiável da automação de navegadores. Criado originalmente para testers de QA, ele permite controlar navegadores como Chrome, Firefox e até Internet Explorer (para quem gosta de viver perigosamente). Playwright, por outro lado, surgiu em 2020 com apoio da Microsoft e trouxe uma abordagem moderna para automação de navegador — pense nele como o irmão mais novo e mais rápido do Selenium.
As duas ferramentas permitem escrever scripts (geralmente em Python) que abrem um navegador, acessam um site, clicam em botões, preenchem formulários e — o mais importante para nós — extraem dados. Embora tenham nascido no teste automatizado, hoje são a base do web scraping em tudo, de monitoramento de preços a geração de leads (fonte). A popularidade deles não se limita a desenvolvedores: cada vez mais profissionais de negócios estão arregaçando as mangas para criar seus próprios scrapers — ou pelo menos tentando.
Mas aqui está a virada: quando você está extraindo dados, suas prioridades mudam. Você passa a se importar menos com cobertura de testes e mais com conseguir os dados com confiabilidade, evitar bloqueios e não passar o fim de semana depurando erros em Python. É aí que entram as diferenças reais entre Playwright e Selenium.
Principais diferenças: Playwright vs. Selenium para web scraping

Vamos direto ao ponto: Playwright e Selenium conseguem fazer scraping de sites, mas brilham em cenários diferentes.
- Selenium é o veterano. Funciona com quase todos os navegadores e linguagens, tem uma comunidade enorme e é uma excelente escolha para extrair dados de sites antigos e estáticos, com layouts previsíveis.
- Playwright é o novato com recursos modernos. Ele foi projetado para sites dinâmicos de hoje, cheios de JavaScript, com ferramentas nativas para lidar com logins, pop-ups, rolagem infinita e muito mais. Também é mais rápido e mais fácil de configurar, especialmente para quem usa Python.
Mas não precisa acreditar só em mim — vamos detalhar ponto a ponto.
Tabela comparativa de recursos: Playwright vs. Selenium
| Recurso | Selenium | Playwright |
|---|---|---|
| Suporte a linguagens | Python, Java, C#, JS, Ruby e mais | Python, JS/TS, Java, C# |
| Suporte a navegadores | Chrome, Firefox, Edge, Safari, IE, Opera | Chromium (Chrome/Edge), Firefox, WebKit |
| Complexidade da configuração | Precisa de driver do navegador e configuração manual | Um comando instala tudo |
| Velocidade/desempenho | Mais lento, consome mais recursos | Geralmente mais rápido em páginas pesadas em JS; assíncrono e concorrente por design |
| Tratamento de conteúdo dinâmico | Esperas manuais, mais código necessário | Auto-waits, lida facilmente com sites pesados em JS |
| Evasão de anti-bot | Mais fácil de detectar, precisa de complementos | Stealth embutido, melhor em imitar usuários |
| Ferramentas de depuração | Básicas (Selenium IDE, capturas de tela) | Inspector, gravação de vídeo, codegen |
| Suporte da comunidade | Enorme, maduro, cheio de tutoriais | Cresce rápido, documentação moderna, devs ativos |
| Fluxo de trabalho para Python Scraper | Mais configuração, mais boilerplate | Mais fluido, menos código, mais fácil para iniciantes |
Como escolher a ferramenta certa: quando usar Playwright ou Selenium para web scraping
Então, qual dos dois você deve escolher para o seu próximo projeto de scraping? Aqui vai minha visão, depois de anos criando ferramentas de automação e ajudando equipes a extrair dados do faroeste da web.
- Selenium é a melhor opção se:
- O site que você vai extrair é mais antigo — pense em HTML estático, pouco JavaScript e sem pop-ups sofisticados.
- Você precisa dar suporte a navegadores diferentes ou incomuns (olá, Internet Explorer) ou integrar com sistemas legados.
- Quer o conforto de uma comunidade gigante e de respostas infinitas no Stack Overflow.
- Já conhece Selenium de projetos de teste.
- Playwright é a escolha certa se:
- O site é moderno, dinâmico e cheio de JavaScript (pense em e-commerce, redes sociais ou qualquer coisa que faça a ventoinha do notebook disparar).
- Você precisa fazer login, navegar por abas, lidar com rolagem infinita ou encarar pop-ups.
- Quer começar rápido, com menos configuração e menos código.
- Está cansado de espalhar
time.sleep(5)por todo lado e quer que a ferramenta cuide do timing para você.
Aqui vai uma regra simples: se sua primeira tentativa de extrair um site com Selenium envolve muitos momentos de “por que isso não está carregando?”, provavelmente já é hora de testar Playwright.
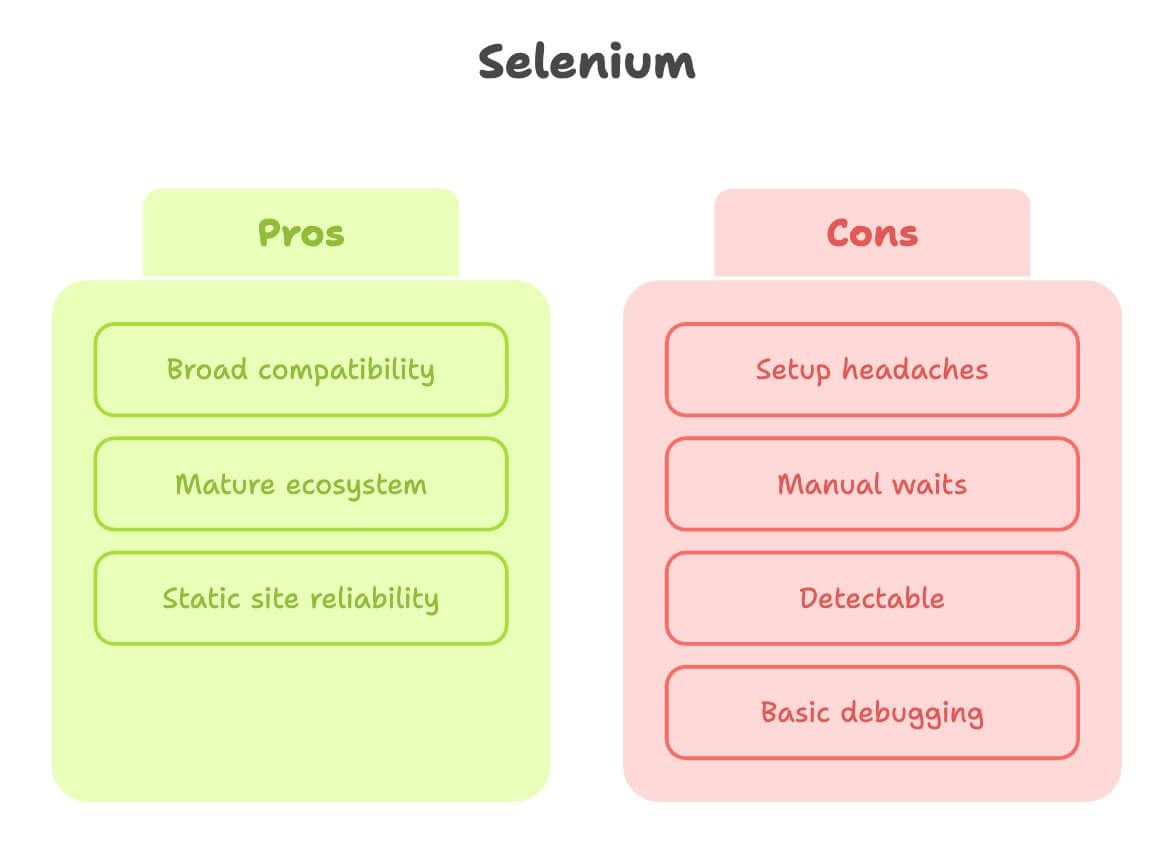
Selenium para web scraping: pontos fortes e limitações
Vamos dar o devido valor ao Selenium. Ele é o avô da automação de navegadores e, para muitos trabalhos de scraping, simplesmente funciona.
Pontos fortes:
- Ampla compatibilidade: funciona com quase todos os navegadores e linguagens.
- Ecossistema maduro: toneladas de tutoriais, perguntas e respostas e plugins.
- Ótimo para sites estáticos: se a página não muda muito, o Selenium é extremamente confiável.
Limitações:
- Dor de cabeça na configuração: você precisa baixar e configurar um driver do navegador (como o ChromeDriver) e mantê-lo atualizado. Iniciantes costumam travar nessa etapa (fonte).
- Espera manual: conteúdo dinâmico? Você vai acabar escrevendo várias esperas explícitas ou, pior, vários
sleepaleatórios. - Mais fácil de detectar: muitos sites conseguem identificar navegadores controlados por Selenium e bloqueá-los, especialmente em servidores na nuvem.
- Depuração básica: não há gravação de vídeo nem inspector interativo nativos.
Em resumo, o Selenium é perfeito para sites simples e estáveis — mas pode parecer empurrar uma pedra morro acima em páginas modernas e interativas.
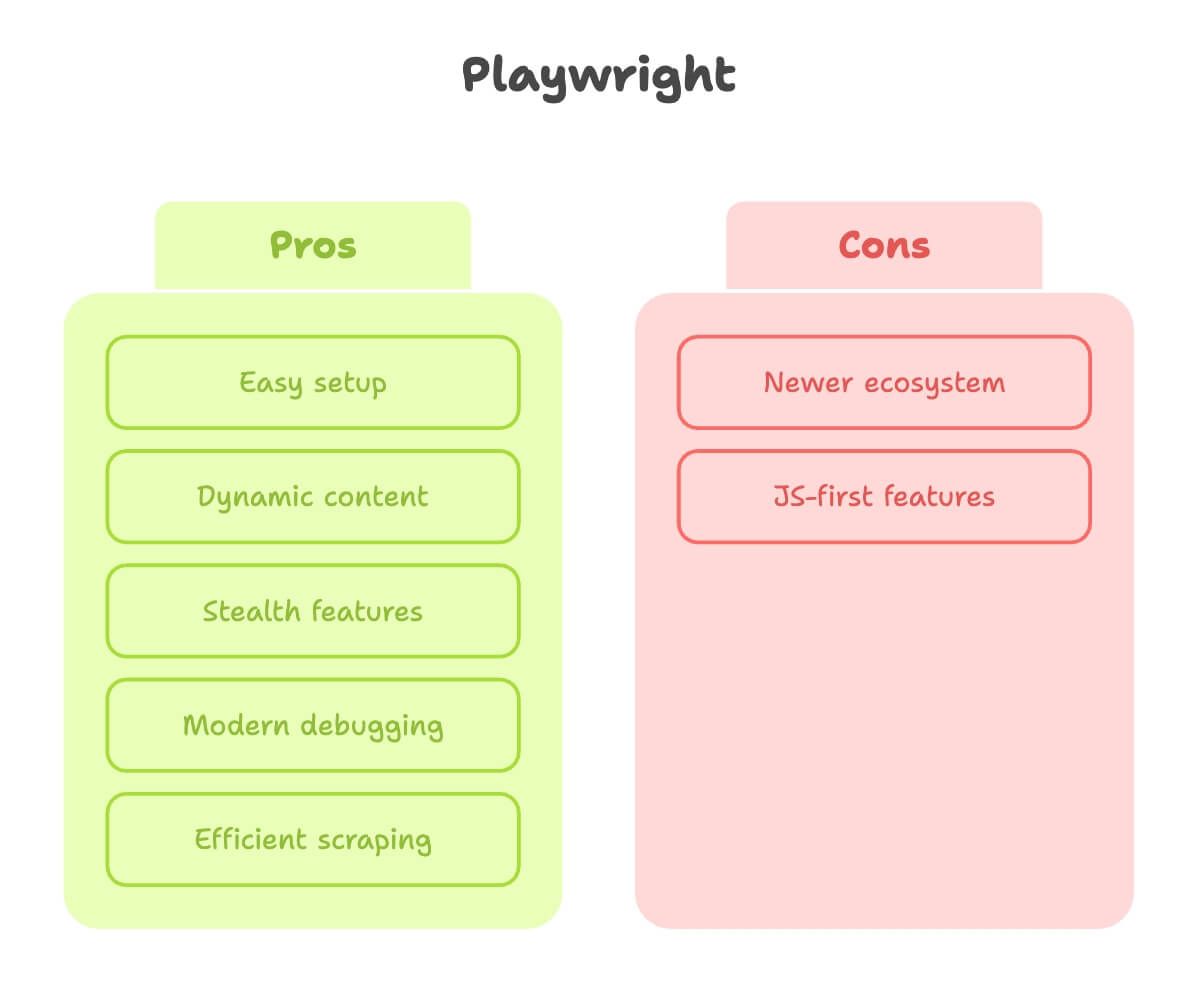
Playwright para web scraping: pontos fortes e limitações
Agora, vamos falar de Playwright. Como alguém que passou muito tempo lidando com as duas ferramentas, posso dizer que o Playwright parece ter sido criado por pessoas que realmente sofreram com web scraping.
Pontos fortes:
- Configuração fácil: um
pip install, um comando e pronto. Sem drama de driver. - Lida com conteúdo dinâmico: faz auto-wait dos elementos, então você não precisa adivinhar quando a página está pronta (fonte).
- Recursos de stealth: imita melhor usuários reais, com modo stealth embutido e suporte a múltiplos contextos (ótimo para extrair dados como vários “usuários” ao mesmo tempo).
- Depuração moderna: Inspector, gravação de vídeo e até geração de código a partir dos cliques manuais.
- Mais rápido e eficiente: especialmente para raspar muitas páginas ou executar em paralelo.
Limitações:
- Ecossistema mais novo: há um pouco menos de tutoriais, embora essa diferença esteja diminuindo rapidamente.
- Alguns recursos são mais voltados para JavaScript: a maior parte funciona em Python, mas às vezes você encontra algo melhor documentado em JS.
No fim das contas: Playwright é minha escolha padrão para qualquer site que seja nem um pouco dinâmico, ou quando quero resultados rápidos sem brigar com a configuração.
Evasão de anti-bot: qual Python Scraper lida melhor com sites modernos?
Vamos tocar no ponto sensível: ser bloqueado. Em web scraping, a parte mais difícil não é escrever código — é garantir que o site não feche a porta na sua cara.
- Selenium: logo de cara, é mais fácil de detectar. Os sites conseguem identificar a flag
webdriver, user agents headless e outros sinais típicos. Existem alternativas (como o undetected-chromedriver), mas elas exigem configuração extra e vivem correndo atrás da tecnologia anti-bot (fonte). - Playwright: traz recursos de stealth embutidos, como ocultar automaticamente as marcas de automação, suportar múltiplos contextos de navegador e esperar interações mais parecidas com as de um usuário real. Não é mágica, mas tende a te deixar menos bloqueado na primeira tentativa.
Mas a verdade é esta: nenhuma das duas ferramentas é totalmente imune a mecanismos anti-bot. Para scraping de alto risco (pense em lançamentos de tênis ou sites de ingressos), você ainda vai precisar usar proxies, rotacionar IPs e talvez até resolver CAPTCHAs. O Playwright só torna tudo um pouco menos doloroso.
Experiência do desenvolvedor: configuração, curva de aprendizado e depuração
Vamos falar da experiência real de começar — especialmente se você é iniciante ou só quer resolver o trabalho sem precisar de um doutorado em Python.
- Selenium:
- Configuração: instale Python, instale Selenium, baixe o driver correto do navegador, coloque no PATH e torça para ter acertado as versões. (Já vi mais gente travar na etapa do driver do que no scraping em si.)
- Curva de aprendizado: há muitos recursos, mas também muito código legado e tutoriais desatualizados.
- Depuração: basicamente
print, capturas de tela e torcer para dar certo. O Selenium IDE existe, mas é básico.
- Playwright:
- Configuração:
pip install playwright, depoisplaywright install. Pronto. - Curva de aprendizado: documentação moderna, muitos exemplos e uma API que parece mais “humana” — dá para selecionar elementos por texto, função ou até placeholder.
- Depuração: o Inspector permite avançar pelo script, acompanhar o navegador e até gravar vídeos das execuções de scraping (fonte).
- Configuração:
Se você quer ver resultados rapidamente e gastar menos tempo com configuração e troubleshooting, o Playwright é o vencedor claro. O Selenium é ótimo se você já está confortável com suas particularidades ou precisa da ampla compatibilidade dele.
Passo a passo: construindo seu primeiro web scraper em Python com Playwright ou Selenium
Vamos ver, na prática, como seria construir um scraper com cada ferramenta — sem código, só os passos.
Playwright (Python):
- Instale Playwright e os navegadores:
pip install playwright+playwright install - Abra o navegador: inicie Chromium, Firefox ou WebKit (headless ou visível).
- Acesse a página: use
page.goto("<https://example.com>") - Espere o conteúdo: o Playwright faz auto-wait dos elementos até carregarem.
- Extraia os dados: use seletores amigáveis para humanos (como
get_by_text,locator("span.price")). - Lide com paginação ou subpáginas: percorra páginas ou clique em links — o Playwright facilita executar várias páginas em paralelo.
- Exporte os dados: salve em CSV, Excel ou banco de dados.
- Depure: use o Inspector ou gravação de vídeo se algo sair do controle.
Selenium (Python):
- Instale o Selenium:
pip install selenium - Baixe o driver do navegador: (por exemplo, ChromeDriver para o Chrome) e coloque no PATH.
- Abra o navegador: inicie Chrome, Firefox ou outro navegador.
- Acesse a página:
driver.get("<https://example.com>") - Espere o conteúdo: adicione manualmente esperas explícitas (
WebDriverWait) ou, se quiser arriscar,time.sleep. - Extraia os dados: use
find_elementoufind_elements(seletores CSS/XPath). - Lide com paginação ou subpáginas: percorra URLs ou clique em botões, mas você mesmo vai precisar gerenciar timing e navegação.
- Exporte os dados: salve em CSV, Excel ou banco de dados.
- Depure: em geral, de forma manual — observe o navegador, imprima o HTML ou tire capturas de tela.
Percebe a diferença? O Playwright é um pouco mais “plug and play” para sites modernos.
Além do código: web scraping sem código com o Thunderbit AI Web Scraper
Extraia dados de qualquer site usando IA Get Started Free
Agora, sejamos honestos. Nem todo mundo quer virar guru de Python só para obter uma tabela de preços de produtos ou uma lista de leads. Talvez você trabalhe com vendas, marketing, imobiliário ou operações e só queira os dados — agora. É aí que entra o Thunderbit.
Como cofundador do Thunderbit, vi de perto quantos usuários de negócios só querem pular a parte do código e ir direto ao que importa. Então criamos uma extensão do Chrome com IA que permite extrair qualquer site em dois cliques — sem Python, sem drivers, sem depuração.
Como o Thunderbit funciona
- Acesse o site que deseja extrair.
- Clique em “AI Suggest Fields”. A IA do Thunderbit analisa a página e recomenda os campos de dados (como nome do produto, preço, imagem, avaliação).
- Clique em “Scrape”. Instantaneamente, você recebe uma tabela estruturada com os dados.
- Exporte para Excel, Google Sheets, Airtable, Notion, CSV ou JSON. Pronto.
Sem mexer em seletores, sem tentativa e erro, sem código. É tão fácil quanto pedir comida por delivery (e, sejamos sinceros, provavelmente mais rápido do que esperar o pedido chegar).
Experimente o Thunderbit AI Web Scraper gratuitamente
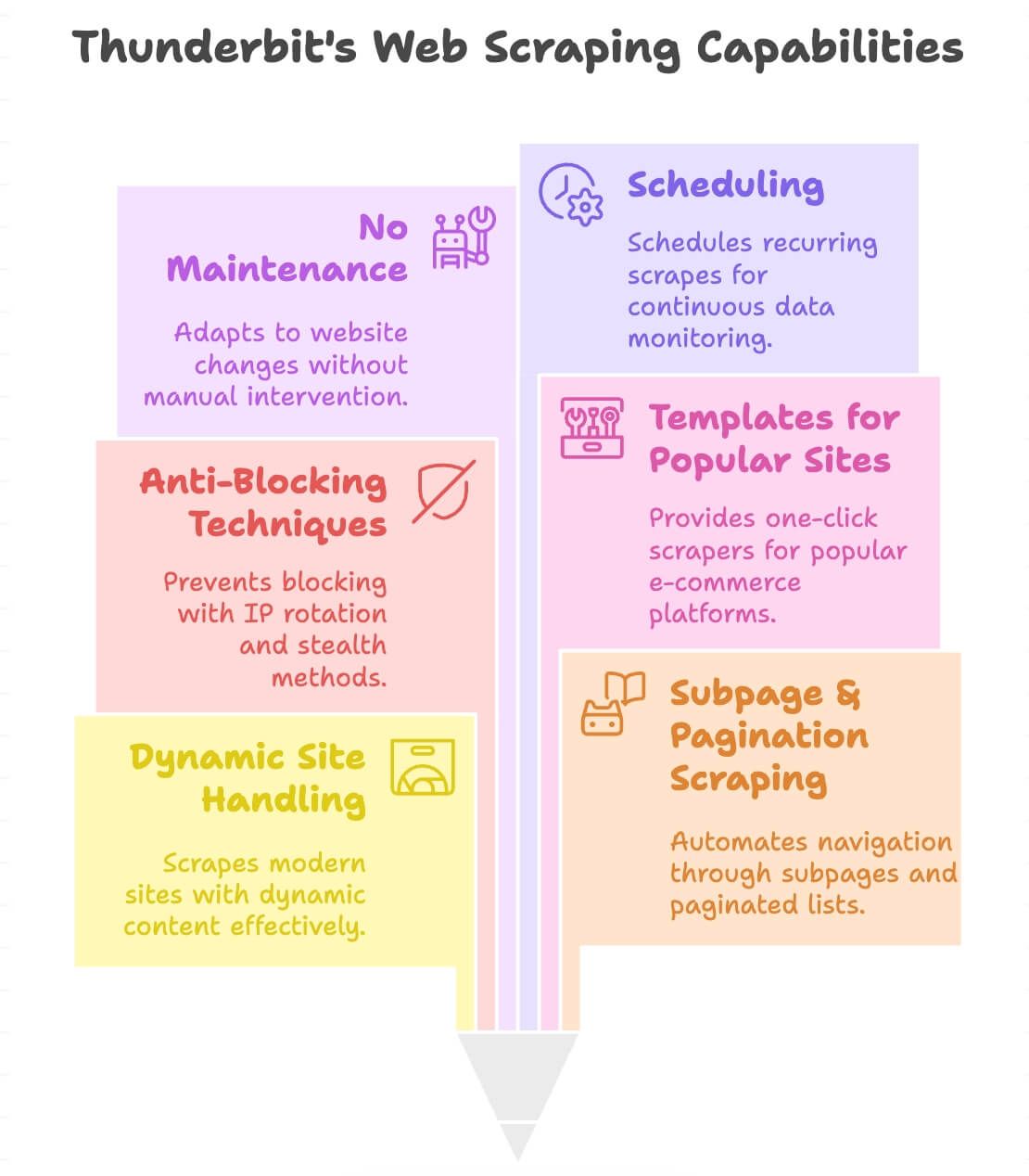
O que torna o Thunderbit diferente?
- Lida com sites dinâmicos: extrai dados de e-commerce modernos, diretórios e até sites com rolagem infinita ou pop-ups.
- Scraping de subpáginas e paginação: clica automaticamente em páginas de produto ou listas paginadas para capturar todos os dados de que você precisa.
- Proteção contra bloqueio embutida: usa rotação de IPs no backend e técnicas de stealth, então você tem menos chance de ser bloqueado.
- Modelos para sites populares: scrapers de um clique para Amazon, eBay, Shopify, Zillow e muito mais (veja nosso blog para detalhes).
- Menos manutenção: quando o layout de um site muda, a passada de “AI Suggest Fields” geralmente redetecta os campos, então muitas vezes basta rodar novamente a etapa de sugestão em vez de reconstruir tudo do zero.
- Agendamento: configure extrações recorrentes para monitoramento contínuo (por exemplo, checagens diárias de preços).
- Suporte a 55 idiomas: extraia e traduza dados de praticamente qualquer lugar.
E o melhor? Você não precisa saber nada de HTML, CSS ou Python. Se consegue usar um navegador, consegue usar o Thunderbit.
Qual solução de web scraping é a certa para você?
Vamos encerrar com um guia rápido de decisão:
| Sua situação | Melhor ferramenta |
|---|---|
| Extraindo um site estático e simples; não se importa com configuração | Selenium |
| Extraindo um site moderno e dinâmico; quer resultados rápidos | Playwright |
| Precisa dar suporte a navegadores ou linguagens legados | Selenium |
| Quer configuração fácil, depuração moderna e menos código | Playwright |
| Não é desenvolvedor; quer dados agora, sem código e sem configuração | Thunderbit |
| Precisa extrair várias páginas, subpáginas ou agendar tarefas | Thunderbit |
| Quer exportar direto para Excel, Sheets, Notion, Airtable | Thunderbit |
| Odeia depurar erros em Python | Thunderbit |
Se você é desenvolvedor ou gosta de mexer com código, Playwright e Selenium são duas opções poderosas. Mas, se o seu objetivo é colocar dados em uma planilha o mais rápido possível, o Thunderbit vai economizar horas — talvez até dias — de trabalho.
Comece a usar o Thunderbit AI Web Scraper
Conclusão: web scraping rápido e confiável — do seu jeito
O web scraping se popularizou, e com razão: as empresas precisam de dados para competir, e precisam deles agora. Playwright e Selenium evoluíram de simples ferramentas de teste para frameworks essenciais de scraping, cada um com seus pontos fortes. Selenium é o velho confiável para sites estáticos e configurações legadas; Playwright é a escolha moderna e veloz para páginas dinâmicas e interativas.
Mas aqui vai meu conselho sincero, depois de anos trabalhando com SaaS, automação e IA: se você não quer código, não perca tempo brigando com drivers, seletores e truques anti-bot. Com o AI Web Scraper da Thunderbit, você pode sair de “preciso desses dados” para “aqui está meu arquivo Excel” em minutos — não dias.
Então, seja você um profissional de Python ou um usuário de negócios que só quer resultado, existe uma solução de scraping que combina com suas necessidades — e com a sua paciência. Experimente, veja o que funciona no seu fluxo de trabalho e lembre-se: o melhor scraper é aquele que entrega os dados de que você precisa com o mínimo de dor de cabeça.
E se algum dia você se pegar depurando um erro de driver do Selenium às 2 da manhã, saiba que o Thunderbit ainda estará aqui, pronto para extrair em dois cliques. Boa extração.
Quer saber mais sobre scraping sem código, extração de dados com IA e como o Thunderbit pode ajudar sua equipe? Confira nosso blog ou comece hoje mesmo com a extensão Thunderbit para Chrome.
P.S. Se você ainda não tem certeza de qual ferramenta usar, ou quer ver o Thunderbit em ação, passe no nosso canal do YouTube para demos, dicas e, de vez em quando, uma piada sobre web scraping. (Sim, nós temos essas.)
Leituras adicionais:




