Deixe-me dizer uma coisa: se eu ganhasse um dólar toda vez que alguém me enviasse um PDF cheio de “dados importantes” e esperasse que eu o transformasse magicamente numa planilha, provavelmente já teria dinheiro para café para a vida toda — e talvez para algumas extensões extras do Chrome. PDFs estão por todo lado: contratos de vendas, catálogos de produtos, artigos de pesquisa, faturas, enfim. Mas, quando chega a hora de realmente usar os dados dentro desses ficheiros? Aí é que começa a diversão (leia-se: as dores de cabeça).
Passei por isso na prática — a copiar, colar, reformular e, às vezes, simplesmente a desistir quando a formatação saía do controlo ou as imagens e os links desapareciam no ar. Mas aqui vai a boa notícia: o mundo do PDF scraping mudou drasticamente, sobretudo com a ascensão das ferramentas com IA. Se está farto de passar horas a voltar a escrever números ou a enlouquecer com tabelas partidas, está no sítio certo. Vamos mergulhar no universo do PDF scraping, perceber porque é que isto importa e como ferramentas como estão a tornar tudo isto finalmente indolor.
O que é PDF Scraping? Entendendo o básico da extração de dados de PDF
Vamos começar pelo básico: PDF scraping é só uma forma sofisticada de dizer “extrair dados estruturados de ficheiros PDF — automaticamente”. Um Raspador PDF é uma ferramenta (software, extensão ou serviço) que vai buscar a informação que interessa — texto, tabelas, imagens, links, enfim — e a coloca num formato que realmente dá para usar, como Excel, Google Sheets ou uma base de dados.
Mas há um detalhe: PDFs não são como páginas web ou ficheiros do Excel. Parecem mais impressos digitais, feitos para ter o mesmo aspeto em qualquer lugar, e não para serem facilmente desmontados por um computador. Alguns PDFs têm texto selecionável; outros são apenas imagens digitalizadas (que exigem OCR — reconhecimento ótico de caracteres); e a formatação pode variar muito. Por isso, fazer scraping de um PDF não é só copiar texto — é decifrar um puzzle de layouts, fontes e, por vezes, até metadados ocultos.
O que dá para extrair de um PDF?
- Texto simples (parágrafos, títulos etc.)
- Tabelas (pense em: finanças, especificações de produtos, dados de pesquisas)
- Imagens e gráficos (gráficos, logos, assinaturas digitalizadas)
- Hiperlinks e referências (URLs incorporadas, citações)
- Dados de formulários (campos de formulários preenchíveis)
- Metadados (autor, título, data de criação, tags)
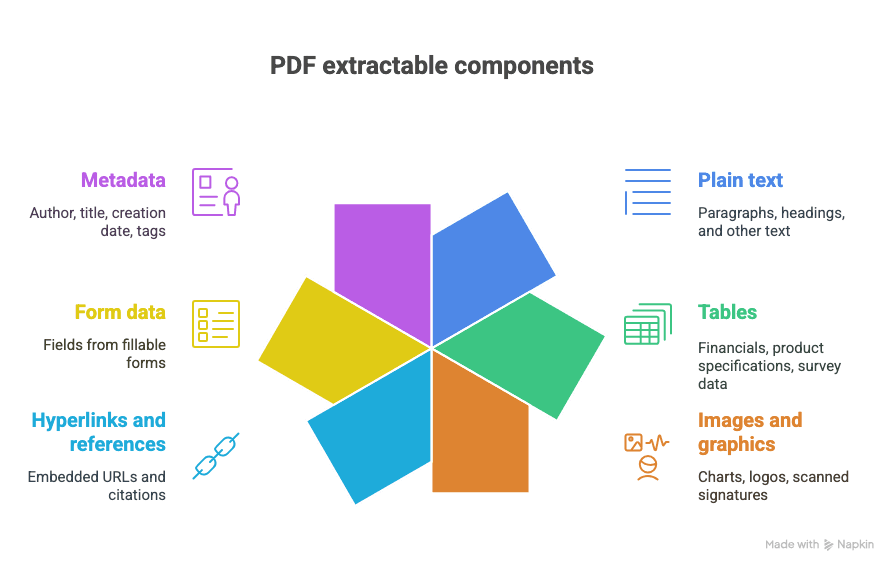
E sim, às vezes tudo isto vem misturado num único documento gloriosamente caótico.
Por que o PDF Scraping importa: casos de uso reais e benefícios para negócios
Então, por que razão se preocupar em fazer scraping de PDFs? Porque toda a gente usa este formato, e os dados dentro dele costumam ser críticos para o negócio. É aqui que o PDF scraping brilha:
| Caso de uso | Esforço manual | Com um Raspador PDF | Economia de tempo e redução de erros |
|---|---|---|---|
| Extração de leads de vendas | Horas a copiar contactos de propostas ou PDFs de eventos, com risco de perder leads | Traz todos os leads instantaneamente para uma folha de cálculo | 80–90% mais rápido, menos erros |
| Dados de produtos para e-commerce | Dias a introduzir especificações de produtos a partir de PDFs de fornecedores, com caos na formatação | Extração em massa para CSV ou Sheets | +95% de tempo poupado, dados consistentes |
| Análise de dados de pesquisa | Semanas a transcrever tabelas de artigos académicos, com elevado risco de erros de digitação | Extrai tabelas, referências e até texto digitalizado | 80% de tempo poupado, mais precisão |
Vamos pôr alguns números nisto:
- são criados todos os anos.
- usam PDF como formato principal para partilhar informação.
- A administração manual em formato digital (como a introdução de dados de PDFs) consome .
- Ferramentas automatizadas podem reduzir as taxas de erro de .
Se trabalha com vendas, e-commerce ou investigação, automatizar a extração de dados de PDF não é apenas um extra — é uma vantagem competitiva.
Métodos tradicionais de PDF Scraping: desafios e limitações
Sejamos honestos: as formas antigas de extrair dados de PDFs… não são grande coisa. Veja o que a maioria de nós já experimentou (e por que isso é tão frustrante):

1. Copiar e colar manualmente
- Pontos de dor: A formatação fica toda baralhada, as tabelas viram uma confusão, as imagens e os links desaparecem, e sobra uma dor de cabeça daquelas.
- Custo de trabalho: Alto. Se tiver 5.000 PDFs, mesmo a demorar 1 minuto por ficheiro, isso dá mais de 80 horas da sua vida que nunca vai recuperar.
- Taxa de erro: 5–10%. Erros de digitação, linhas perdidas, eliminações acidentais — já passei por isso.
2. Converter para Word/Excel e depois limpar tudo
- Pontos de dor: Às vezes resulta em documentos simples, mas layouts complexos ou tabelas acabam por ficar baralhados. Ainda é preciso arrumar a confusão.
- Imagens/links: Normalmente perdem-se na conversão.
- Extração direcionada: Esqueça — recebe o documento inteiro, não apenas o que precisa.
3. Scripts personalizados (Python etc.)
- Pontos de dor: É preciso saber programar (ou ter alguém disponível). Cada novo formato de PDF exige ajustes no script. PDFs digitalizados? Boa sorte.
- Manutenção: Alta. Sempre que um fornecedor muda o modelo da fatura, o script parte.
- Escalabilidade: Não é para os fracos de coração — nem para quem não é técnico.
4. Conversores online
- Pontos de dor: São práticos para tarefas pontuais, mas é preciso enviar documentos sensíveis para um servidor de terceiros (olá, problemas de compliance). Controlo limitado sobre o que vai ser extraído.
- Formatação: Funciona ou não funciona. Pode acabar a gastar mais tempo a corrigir do que aquilo que poupou.
Em resumo: os métodos tradicionais são lentos, dão erros com facilidade e não escalam. É por isso que tantas equipas simplesmente “convivem com o problema” — mas a um custo enorme de produtividade.
Soluções modernas para PDF Scraping: do código às ferramentas no-code
Felizmente, já não estamos presos à Idade das Trevas. O panorama explodiu com opções de PDF scraping mais inteligentes, rápidas e fáceis de usar.
1. Bibliotecas de código (para programadores)
- Exemplos: , , .
- Pontos fortes: Super flexíveis, podem ser automatizadas para grandes lotes, gratuitas (open source).
- Pontos fracos: Configuração demorada, exigem conhecimentos de programação, frágeis (partem com novos formatos), suporte limitado a OCR/imagens.
2. Conversores online de PDF
- Exemplos: , , .
- Pontos fortes: Sem configuração, fáceis para quem não é técnico, rápidos para tarefas pequenas.
- Pontos fracos: Personalização limitada, preocupações com privacidade, erros de formatação, limites de tamanho de ficheiro/páginas.
3. Raspadores de PDF com IA
- Exemplos: , Nanonets, Docparser.
- Pontos fortes: Não exige programação, lida com texto/tabelas/imagens/links, a IA sugere o que extrair, suporta tarefas em lote, integra com Sheets/Notion/Airtable.
- Pontos fracos: Alguns têm limites de créditos/páginas, podem exigir ligação à internet, e documentos mais complexos podem ter uma curva de aprendizagem.
Comparando ferramentas de PDF scraping: qual abordagem combina com as suas necessidades?
| Ferramenta/Método | Configuração | Ideal para | Extrai | Personalizável? | Custo |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Moderada (interface/código) | Tabelas em PDFs | Tabelas | Em parte | Grátis |
| PDFMiner | Exige programação | PDFs com muito texto | Texto | Sim (código) | Grátis |
| PyPDF2 | Exige programação | Texto simples/metadados | Texto, metadados | Sim (código) | Grátis |
| Smallpdf/Conversores online | Nenhuma (baseado na web) | Conversões rápidas | Documento inteiro (Word/Excel) | Não | Freemium |
| Thunderbit | Instalação em 2 cliques | Utilizadores de negócio, equipas | Texto, tabelas, imagens, links | Sim (prompts de IA) | Freemium (US$ 16,5/mês no Pro) |
Conheça o Thunderbit: a extensão Chrome de raspagem de PDF com IA
Agora, vamos falar da ferramenta que tornou a minha vida — e a de muitos utilizadores de negócio — muito mais fácil: .
O que torna o Thunderbit diferente?
- Extração em 2 cliques: Abra um PDF no Chrome, clique na extensão do Thunderbit e deixe a IA fazer o resto.
- Sugestões de campos com IA: A funcionalidade “AI Suggest Fields” do Thunderbit lê o seu PDF e recomenda as colunas que provavelmente quer (como “Nome”, “Email”, “Preço” etc.).
- Lida com imagens, links e tabelas: Não é só texto simples — o Thunderbit consegue extrair imagens, hiperlinks e até executar OCR em documentos digitalizados.
- Prompts personalizados: Precisa apenas de números de telefone ou especificações de produtos? Adicione uma instrução personalizada e o Thunderbit foca-se exatamente nisso.
- Exporta para todo o lado: Envie os dados diretamente para Excel, Google Sheets, Airtable ou Notion. Acabou o malabarismo com CSV.
- Extração em lote e de subpáginas: Tem uma lista de PDFs ou links? O Thunderbit processa tudo de uma vez.
- Fiabilidade nível empresarial: Concebido para precisão, privacidade e fluxos de trabalho do mundo real.
Em resumo, é como ter um estagiário digital que realmente gosta de fazer introdução de dados — e nunca se cansa.
Como extrair dados de um PDF usando o Thunderbit: guia passo a passo
Pronto para ver como isto pode ser fácil? Veja como uso o Thunderbit para transformar PDFs em dados estruturados e úteis:
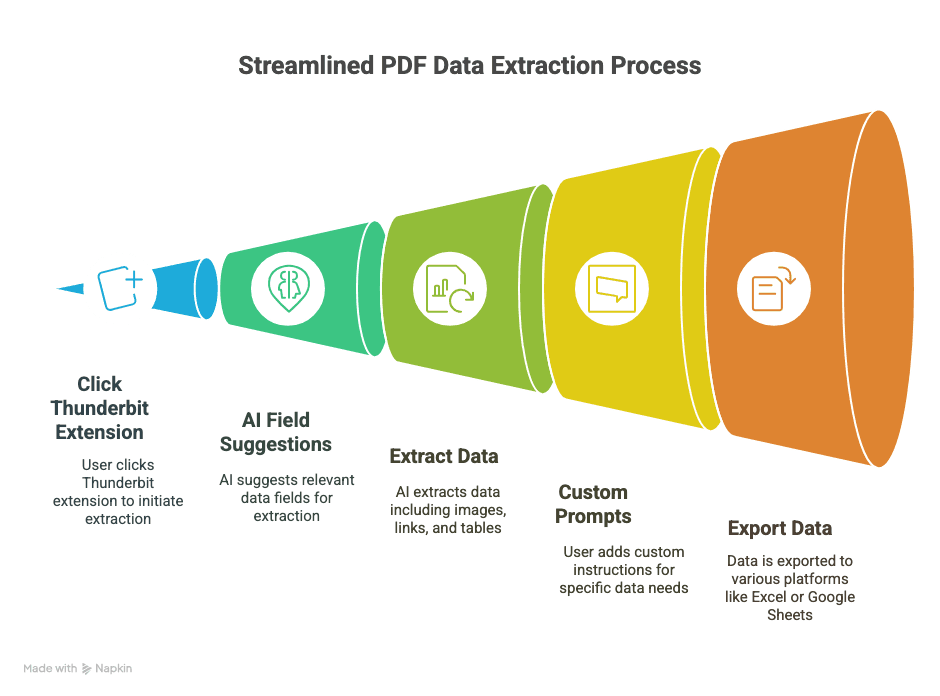
1. Instale o Thunderbit
- Descarregue a .
- Registe-se (conta Google ou email — demora segundos).
2. Abra o seu PDF no Chrome
- Abra um PDF através de um link da web ou arraste um PDF local para um separador do Chrome.
3. Abra o Thunderbit no PDF
- Clique no ícone do Thunderbit na barra de ferramentas do navegador.
- Selecione “AI Web Scraper” — o Thunderbit detetará o PDF e ficará pronto para trabalhar.
4. Deixe a IA sugerir os campos
- Clique em “AI Suggest Columns”.
- A IA do Thunderbit analisa o PDF e recomenda colunas (como “Data”, “Valor”, “Nome do contacto” etc.).
- Pré-visualize os dados extraídos numa tabela diretamente na extensão.
5. Personalize, se necessário
- Mude o nome das colunas, apague as que sobrarem ou adicione as suas próprias (por exemplo, “Prazo da garantia” ou “URL do produto”).
- Para dados mais complicados, selecione texto no PDF para ensinar a IA sobre o que pretende.
6. Escolha o formato de exportação
- Escolha entre CSV, Google Sheets, Airtable ou Notion.
- Autorize a ligação do Thunderbit (configuração única).
7. Faça o scraping e exporte
- Clique em “Scrape” ou “Export”.
- O Thunderbit processa o PDF e envia os dados para onde quiser — normalmente em segundos.
É isso. Sem código, sem copiar e colar, sem drama.
Dicas para uma extração precisa de dados de PDF com o Thunderbit
- Revise os campos sugeridos pela IA: a IA é inteligente, mas uma vista de olhos rápida garante que está a obter exatamente o que precisa.
- Lide com tabelas complexas: em tabelas de várias páginas ou com formatação estranha, use a pré-visualização para identificar problemas e ajustar as colunas conforme necessário.
- Extraia imagens/links: se o PDF tiver esses campos, inclua-os — o Thunderbit também consegue capturá-los.
- PDFs digitalizados: o OCR integrado do Thunderbit é bom, mas quanto mais limpo for o scan, melhores os resultados.
- Prompts personalizados: quer apenas emails ou números de telefone? Adicione um comando como “Extraia todos os endereços de email” e o Thunderbit vai focar-se nisso.
PDF scraping avançado: extraindo imagens, links e dados personalizados
O Thunderbit não serve só para texto simples. Veja como pode aproveitar ainda mais os seus PDFs:
- Imagens: extraia logos, gráficos ou qualquer elemento visual incorporado. O Thunderbit também consegue aplicar OCR ao texto dentro das imagens.
- Hiperlinks: extraia todas as URLs ou referências — ótimo para artigos académicos ou currículos.
- Tipos de dados personalizados: use prompts de IA para extrair só o que precisa (por exemplo, “Encontre todos os SKUs de produtos e os respetivos preços”).
- Resumos e categorização: adicione uma coluna e peça ao Thunderbit para resumir uma secção ou categorizar dados em tempo real.
Analisando dados de PDF para necessidades específicas de negócios
- Vendas: extraia apenas as informações de contacto de um lote de propostas.
- E-commerce: puxe especificações, preços e imagens de catálogos de fornecedores.
- Pesquisa: capture tabelas, referências e até gere resumos de artigos académicos.
E, depois de ter os dados, estruture tudo para análise fácil no Excel, Google Sheets ou Notion — o Thunderbit faz o trabalho pesado, e você fica só com os resultados.
Exportando e usando seus dados de PDF: da extração à ação
Tirar os dados do PDF é só o começo. Veja como fazer isso trabalhar a seu favor:
- Opções de exportação: CSV, Excel, Google Sheets, Airtable, Notion — escolha a sua favorita.
- Dicas de formatação: use as definições de tipo de coluna do Thunderbit (número, data, texto) para ter dados limpos e prontos para análise.
- Integração com fluxos de trabalho: ligue os dados exportados a CRMs, sistemas de inventário ou painéis de análise.
- Colaboração: partilhe folhas Google ou bases do Airtable com a equipa — toda a gente trabalha com os mesmos dados atualizados.
O melhor de tudo? Chega de andar a enviar folhas de cálculo por email de um lado para o outro ou de se perguntar se alguma linha ficou para trás.
Erros comuns em PDF scraping e como evitá-los
Mesmo com as melhores ferramentas, alguns problemas podem aparecer. Aqui está o que aprendi — às vezes da forma mais difícil:
- Erros de OCR: scans desfocados ou fontes estranhas podem confundir até o melhor OCR. Tente usar os PDFs mais limpos possível e confirme os campos críticos.
- Layouts complexos: tabelas com várias colunas ou aninhadas podem exigir um pouco de orientação manual — use a seleção manual ou os prompts do Thunderbit.
- Tipos de dados: números com vírgulas ou datas em formatos estranhos? Defina o tipo de coluna antes de exportar ou limpe depois no Excel/Sheets.
- Limites de tamanho/páginas: PDFs enormes? Divida-os em partes mais pequenas ou use o modo na nuvem do Thunderbit para tarefas em lote.
- “Alucinação” da IA: raro, mas às vezes a IA pode adivinhar o nome de uma coluna ou preencher dados em falta. Revise sempre o resultado, especialmente quando houver números importantes.
- Revisão manual: para dados críticos, faça uma validação rápida — ferramentas automáticas são precisas, mas um olhar humano nunca faz mal.
E, se ficar preso, o suporte e a comunidade do Thunderbit estão lá para ajudar.
Conclusão e principais aprendizados: fazendo o PDF scraping funcionar para o seu negócio
Vamos fechar por aqui. Extrair dados de PDFs costumava ser um pesadelo — lento, propenso a erros e simplesmente aborrecido. Mas, com ferramentas modernas como , agora isso é rápido, preciso e — atrevo-me a dizer — quase agradável.
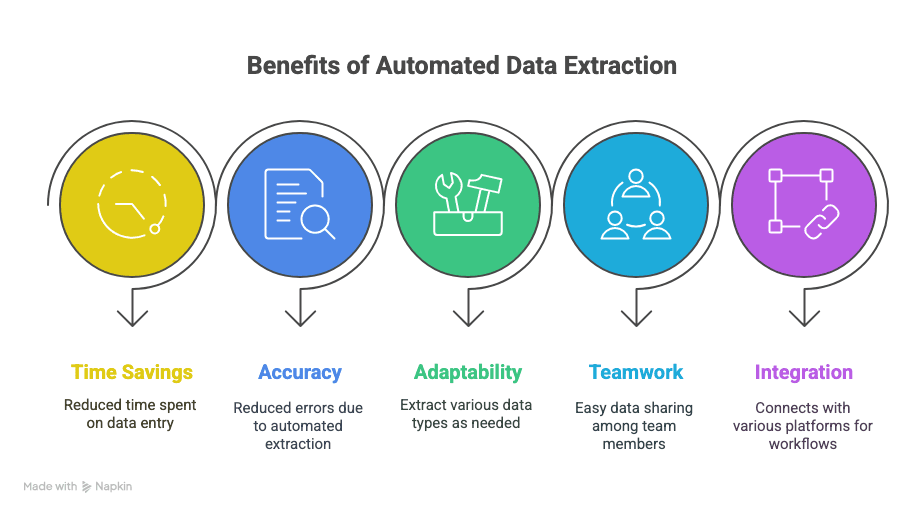
O que ganha:
- Tempo de volta: horas — ou até semanas — poupadas na introdução manual de dados.
- Menos erros: a extração automatizada significa menos erros de digitação e menos linhas perdidas.
- Flexibilidade: extraia exatamente o que precisa — texto, tabelas, imagens, links, enfim.
- Colaboração: partilhe dados instantaneamente com a sua equipa, onde quer que estejam.
- Fluxos de trabalho mais inteligentes: integre com Sheets, Notion, Airtable e muito mais.
Pronto para testar? Descarregue a , experimente-a no seu próximo PDF e veja como a vida pode ficar mais fácil. O seu eu do futuro — e o seu túnel cárpico — vão agradecer.
Para mais dicas e guias, consulte o ou aprofunde em .
Vamos transformar estas dores de cabeça com PDF em ganhos de produtividade — um clique de cada vez.
Shuai Guan, Cofundador e CEO, Thunderbit