
Otimizar consultas de listas do apollo não é só um capricho técnico — é quase um “modo sobrevivência” pra quem vive de dados de notícias em tempo real, extração automatizada de notícias ou rotinas de vendas e operações em ritmo acelerado. Já vi de perto como uma query lenta consegue transformar um dashboard bem montado num baita gargalo: time comercial travado em carregamento infinito e operações tendo que dar um jeitinho no Excel/Sheets. Num contexto em que , cada milissegundo conta.

Então, como fazer as consultas de lista do Apollo Client ficarem rápidas, estáveis e prontas pra escalar — especialmente quando você está raspando notícias, acompanhando leads ou alimentando dashboards críticos? Neste guia, vou juntar as melhores práticas que aprendi (e, em alguns casos, aprendi na marra): do desenho da query a cache, paginação e até integração com ferramentas no-code como o pra automatizar o trabalho pesado da extração de notícias. Seja você dev, PM ou a pessoa que todo mundo chama quando “o dashboard tá pesado”, aqui vai um manual bem direto de performance de listas no Apollo GraphQL.
Por que otimizar consultas de listas no Apollo? (apollo client list performance, optimize apollo list queries)
Sem rodeio: ninguém quer ficar esperando manchete ou lead carregar. Em ambiente de negócio — principalmente quando depende de ou dados em tempo real — query lenta no apollo não só irrita; ela custa dinheiro, atrasa decisão e empurra a galera de volta pro manual. O mostrou que trabalhadores de escritório gastam cerca de um terço do dia em tarefas de baixo valor, muitas vezes porque as ferramentas são lentas ou tudo fica espalhado.
O que costuma rolar quando as consultas de lista não são otimizadas:
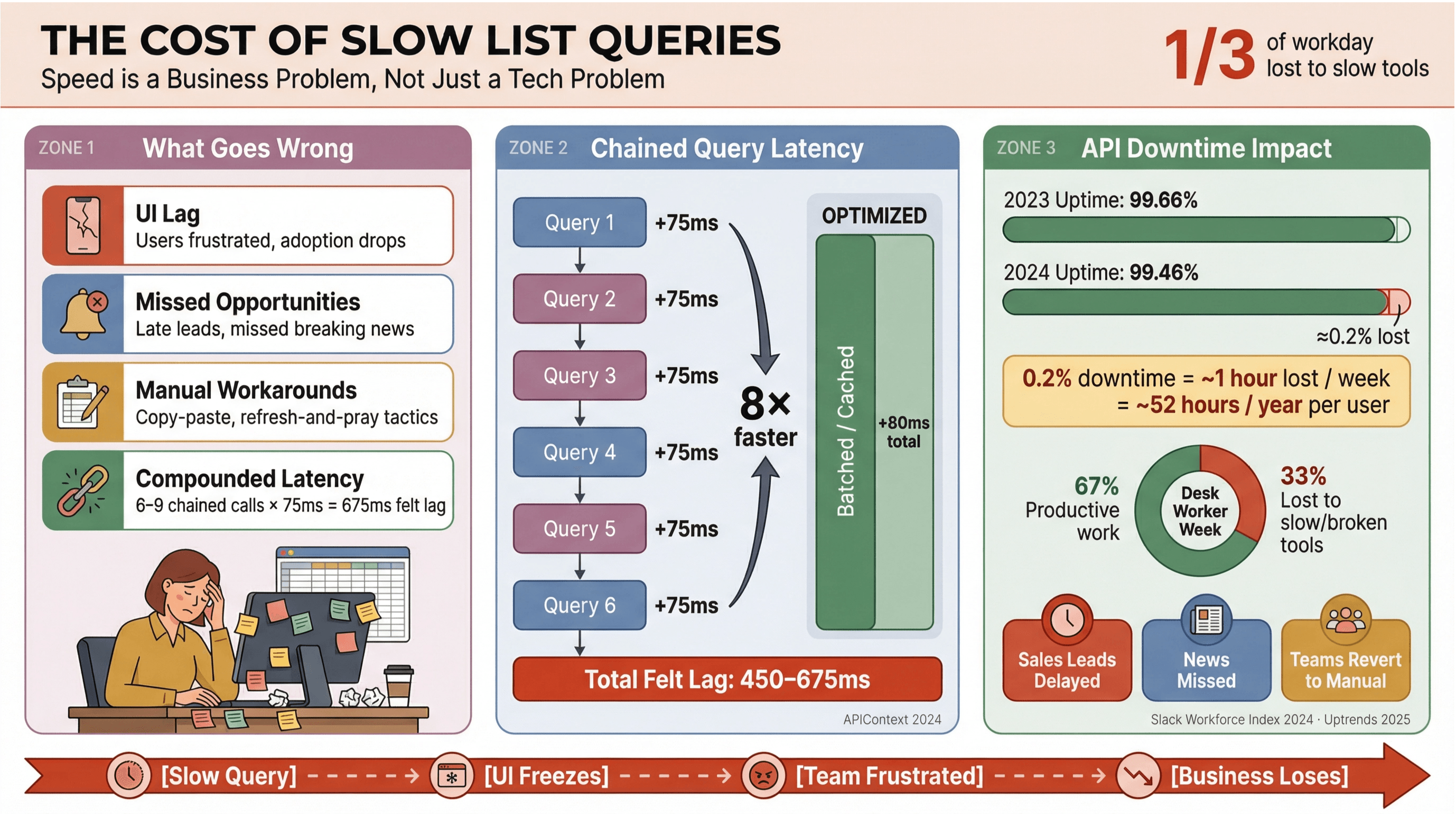
- UI arrastada: atraso visível, frustração e menos adoção.
- Oportunidade indo embora: em vendas ou monitoramento de notícias, segundos podem ser a diferença entre pegar um lead quente ou perder um breaking news.
- Gambiarras manuais: o time volta pro copiar/colar, planilha, ou o clássico “atualiza e reza”.
- Latência que vai somando: cada chamada lenta de API pesa — se seu fluxo dispara 6–9 queries dependentes, um atraso “bobo” de 75ms por chamada vira 450–675ms de lag percebido ().
E não é só velocidade. A , com o uptime médio caindo de 99,66% para 99,46% em só um ano — o que dá quase uma hora de produtividade perdida por semana em apps que usam muitas listas. Se o seu negócio depende de dados de notícias em tempo real, esse risco é grande demais pra ignorar.
Escolhendo a estrutura de dados e os campos certos (apollo graphql list best practices)
Um erro bem comum que eu vejo (e sim, eu também já caí nessa) é tratar query de lista como se fosse query de detalhe. No GraphQL, dá pra pedir exatamente o que você precisa — então aproveita. Trazer dado demais é inimigo da performance, principalmente em ferramentas de raspagem de notícias e dashboards em tempo real.
Ajustando os campos para extração automatizada de notícias
Pensa num feed de notícias. Você realmente precisa do texto completo do artigo, todas as tags, comentários e bio do autor na query de lista? Quase nunca. Olha a diferença:
Query de lista eficiente:
1query NewsFeed($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 cursor
5 node {
6 id
7 title
8 url
9 sourceName
10 publishedAt
11 }
12 }
13 pageInfo { endCursor hasNextPage }
14 }
15}Query de lista ineficiente (não faça isso):
1query NewsFeedTooHeavy($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 node {
5 id title url publishedAt
6 fullText
7 summary
8 entities { ... }
9 relatedArticles { ... }
10 }
11 }
12 }
13}A primeira é direta ao ponto — ótima pra ranquear, filtrar e renderizar linhas. A segunda? É uma query de detalhe fantasiada, puxando payload gigante e deixando tudo mais lento (, ).
Dica prática: use um modelo em dois níveis — na lista, só campos leves; e os detalhes pesados (texto completo, enriquecimento via NLP etc.) só quando o usuário abrir o item ou passar o mouse.
Usando o cache do Apollo Client para acelerar consultas (apollo client list performance)
O cache do Apollo Client é aquele “truque” que muda o jogo pra listas rápidas. Quando está bem configurado, ele ajuda a:
- Responder na hora a queries repetidas (sem ficar indo e voltando na rede)
- Diminuir carga no servidor e custo de API
- Deixar a navegação lisa (voltar/avançar) e troca de filtro sem engasgar
Mas cache não é milagre — precisa de configuração e um pouco de disciplina.
Definindo políticas de cache eficazes
O Apollo tem várias :
| Política | O que faz | Melhor uso em listas de notícias |
|---|---|---|
| cache-first | Lê do cache; busca na rede se não existir | Revisitar listas, trocar filtros, navegação voltar/avançar |
| network-only | Sempre busca na rede | Atualização manual, “últimas manchetes” |
| cache-and-network | Mostra cache primeiro e depois atualiza com a rede | Render rápido + atualização em segundo plano (ótimo para feeds) |
| no-cache | Sempre busca e não armazena no cache | Consultas sensíveis pontuais (raras em listas) |
Pra dados de notícias em tempo real, eu curto muito cache-and-network: entrega algo rápido e atualiza em segundo plano. Só fica esperto com “flicker” na UI se os itens mudarem de ordem quando atualizar ().
Dicas de configuração do cache:
- Use IDs estáveis (
idou_id) pra normalização (). - Ajuste tamanho do cache e garbage collection pra listas grandes ().
- Evite enfiar blobs enormes não normalizados em
ROOT_QUERY— isso pode travar o app ().
Implementando paginação e limitando a quantidade de itens (apollo graphql list best practices)
Se você carrega centenas ou milhares de notícias ou leads de uma vez, é pedir pra dar ruim. Paginação não é só UX — é requisito de performance.
O Apollo suporta paginação e . Comparando as duas:
| Tipo de paginação | Prós | Contras | Melhor para |
|---|---|---|---|
| Por offset | Simples, fácil de implementar | Pode pular/duplicar itens se os dados mudarem | Listas imutáveis ou pequenas |
| Por cursor | Estável, lida bem com mudanças | Um pouco mais complexa | Feeds de notícias, listas grandes |
Pra maioria dos feeds de notícias em tempo real ou listas de leads, paginação por cursor costuma ser a melhor pedida. Ela mantém consistência mesmo quando entram itens novos ou saem itens antigos ().
Dicas de paginação no Apollo:
- Configure
keyArgspra controlar as chaves de cache em campos paginados (). - Implemente uma função
mergepra juntar páginas no cache. - Use
fetchMorepra carregar páginas extras sem sobrescrever o que já veio.
Padrões práticos de paginação para ferramentas de raspagem de notícias
Uma UI típica de raspagem de notícias geralmente:
- Mostra as últimas 20–50 manchetes (só campos leves)
- Carrega mais ao rolar ou ao clicar em “próxima página”
- Busca detalhes só quando precisa
Resultado: UI rápida, API respirando e usuário rendendo mais.
Integrando o Thunderbit para extração automatizada de notícias
Agora, o ponto-chave: de onde sai esse dado de notícia estruturado? É aqui que entra o .
O Thunderbit é uma extensão Chrome de Raspador Web IA no-code que extrai manchetes, URLs, fontes, autores, datas de publicação, resumos e imagens de praticamente qualquer site — sem você precisar programar. Já vi times automatizarem o processo inteiro de extração de notícias com o Thunderbit, transformando páginas bagunçadas em dados limpos e organizados, prontos pra alimentar um banco de dados ou uma API GraphQL.
Combinando Thunderbit com Apollo para dados de notícias em tempo real
Um fluxo que eu gosto bastante pra times de vendas e operações que precisam de notícia sempre fresca:
- Camada de extração: use o do Thunderbit pra coletar dados estruturados em sites-alvo de forma agendada.
- Camada de armazenamento: salve os dados raspados num banco otimizado pra leitura rápida.
- Camada GraphQL: exponha um campo de lista
newsFeede um campo de detalhenewsArticle(id)na sua API. - Camada cliente: use Apollo Client pra buscar a lista (campos leves, paginada) e puxar detalhes só quando fizer sentido.
Esse pipeline “raspar → armazenar → consultar” garante que suas queries no apollo trabalhem com dados recentes e estruturados — sem copiar/colar e sem script frágil.
Bônus: o Thunderbit também consegue enriquecer suas listas com campos extras (tipo sentimento ou categoria) usando sugestões de campos com IA, deixando o feed mais esperto.
Guia passo a passo: otimizando consultas de listas no Apollo
Bora colocar em prática? Aqui vai meu checklist preferido pra otimizar query de lista no Apollo:
-
Enxugue suas queries
- Peça só os campos necessários pra renderizar a lista (título, URL, data/hora etc.).
- Jogue campos pesados (texto completo, imagens, enriquecimento) pra queries de detalhe.
-
Implemente paginação
- Use paginação por cursor em listas grandes ou dinâmicas.
- Configure
keyArgse funçõesmergepra manter o cache certinho.
-
Aproveite o cache do Apollo
- Normalize entidades com IDs estáveis.
- Escolha a fetch policy certa (
cache-and-networké excelente pra notícias). - Ajuste tamanho do cache e garbage collection conforme o volume.
-
Integre extração automatizada
- Use o Thunderbit pra automatizar a raspagem de notícias e manter os dados sempre atualizados.
- Exporte dados estruturados direto pro seu banco ou planilha.
-
Monitore e resolva problemas
- Use o pra inspecionar queries, cache e performance.
- Fique de olho em escritas grandes no cache, watched queries demais e travadinhas na UI.
- Acompanhe latência p95/p99 e taxa de erro (, ).
Monitoramento e troubleshooting de performance de queries
Os Devtools do Apollo salvam demais aqui. Dá pra:
- Ver queries ativas e o estado do cache
- Pegar queries duplicadas ou watchers em excesso
- Encontrar blobs grandes no cache ou falhas de normalização
Se você perceber UI lenta ou atualização demorando, cheque:
- Query de lista grande demais (enxuga)
- Normalização ruim no cache (arruma os IDs)
- Merge da paginação com problema (revê
keyArgsemerge)
E não esquece de medir tail latency (latência de cauda), não só média. É ali que o usuário sente a pancada.
Comparando abordagens tradicionais vs. extração de notícias com IA
Vamos falar a real: raspar notícia antes era sinônimo de script sob medida, browser headless e torcer pro site não mudar o layout. Hoje, com ferramentas guiadas por IA como o Thunderbit, dá pra automatizar — sem código e sem dor de cabeça.
| Abordagem | Pontos fortes | Limitações para usuários de negócio |
|---|---|---|
| Raspagem via scripts | Totalmente customizável, barata em escala | Alta manutenção, exige tempo de engenharia |
| Plataformas gerenciadas | Começo rápido, lidam com anti-bot | Ainda precisa de configuração, custo cresce com uso |
| Extração com IA (Thunderbit) | Lida com layouts bagunçados, sem código | Saída precisa de QA, integração com seu schema |
| Scrapers visuais no-code | Acessível para não engenheiros | Pode quebrar com mudanças de UI, escala limitada |
| Infra de proxy/unlocker | Contorna bloqueios, alto throughput | Ainda precisa de lógica de extração, riscos de compliance |
Nota legal: raspar dados públicos geralmente é legal, mas respeite sempre termos de uso e limites de requisição ().
Principais aprendizados: boas práticas para listas no Apollo GraphQL
Recapitulando o que mais importa:
- Otimize pra velocidade e clareza: queries de lista enxutas, paginação e cache bem usados.
- Estrutura manda: busque só o necessário — campos pesados ficam pra query de detalhe.
- Cache é parceiro: use normalização e fetch policies do Apollo pra servir dado na hora.
- Automatize a extração: ferramentas como o deixam raspagem e enriquecimento acessíveis pra qualquer pessoa.
- Monitore e evolua: Devtools e observabilidade ajudam a achar gargalo cedo.
Pra times de vendas, operações e notícias, isso vira menos tempo esperando, mais tempo agindo — e bem menos mensagem no Slack do tipo “por que isso tá tão lento?”.
Conclusão: próximos passos para otimizar suas consultas de listas no Apollo
Se você ainda está rodando query de lista pesada, sem paginação ou pouco amigável ao cache, é uma boa hora pra revisar. Começa simples: corta campos, adiciona paginação e ajusta o cache. Depois, sobe o nível integrando ferramentas de extração automatizada como o pra manter seus dados sempre atualizados e prontos pra ação.
Quer ir mais fundo? Dá uma olhada na , no ou entra na pra dicas reais e troubleshooting. E se você quer automatizar extração de notícias, testa o do Thunderbit — é um divisor de águas pra quem precisa de dados em tempo real sem dor de cabeça.
Boas consultas — e que suas listas carreguem antes do café esfriar.
FAQs
1. Por que as queries de lista do Apollo ficam lentas em dashboards de notícias em tempo real ou vendas?
As queries podem ficar lentas quando trazem dados demais, não usam paginação ou não estão bem cacheadas. Em fluxos de alta frequência, como monitoramento de notícias, pequenos atrasos se acumulam, gerando lag na UI e perda de produtividade.
2. Qual é a melhor forma de estruturar queries de lista no Apollo para extração automatizada de notícias?
Solicite apenas os campos necessários para renderizar a lista (por exemplo, título, URL e data/hora). Leve campos pesados (como texto completo do artigo ou imagens) para queries de detalhe e pagine os resultados para manter payloads pequenos e rápidos.
3. Como o cache do Apollo Client melhora a performance de listas?
O cache do Apollo guarda dados já buscados, permitindo respostas instantâneas em consultas repetidas. Com normalização correta e fetch policies adequadas (como cache-and-network), dá para acelerar muito as visualizações de lista e reduzir carga no servidor.
4. Como o Thunderbit ajuda na raspagem de notícias e na integração com Apollo?
O Thunderbit é um Raspador Web IA no-code que extrai dados de notícias estruturados de qualquer site. Você pode automatizar a extração e depois enviar esses dados para seu banco ou API GraphQL para uso com o Apollo Client.
5. Quais ferramentas posso usar para monitorar e resolver problemas de performance em queries de lista do Apollo?
O permite inspecionar queries, estado do cache e performance em tempo real. Combine com painéis de observabilidade (como New Relic ou Uptrends) para acompanhar latência e erros e iterar no desenho das queries.
Quer mais dicas sobre raspagem de dados, automação e fluxos em tempo real? Confira o para análises aprofundadas, tutoriais e novidades em produtividade com IA.
Saiba mais