
Na semana passada, passei uma tarde inteira tentando fazer um agente de IA preencher um formulário de fornecedor em um portal com login obrigatório. Na terceira hora, eu já estava encarando um erro de "Connection Refused", minha VPS tinha ficado sem memória e eu estava seriamente pensando em fazer tudo manualmente.
Essa experiência é, basicamente, o kit inicial da automação de navegador com OpenClaw. A ferramenta consegue navegar por páginas, extrair dados, preencher formulários e encadear fluxos complexos usando instruções em linguagem natural — algo realmente impressionante. Mas é justamente a distância entre "isso parece incrível" e "isso realmente funciona na minha máquina" que trava a maioria das pessoas.
Eu passei bastante tempo dos dois lados dessa barreira, tanto construindo ferramentas de automação na Thunderbit quanto testando o que o ecossistema open source tem a oferecer. Este guia é o que eu gostaria de ter encontrado: um passo a passo real de configuração, a escolha do modo de navegador que confunde todo mundo, um caminho nativo para Windows (porque WSL não deveria ser pré-requisito), um guia de sobrevivência contra bots, exemplos reais de saída, erros comuns com correções práticas e uma visão honesta de quando o OpenClaw é a ferramenta certa — e quando ele é exagero.
Experimente a Thunderbit para extrair dados da web sem esforço
Extraia dados de qualquer site com IA Get Started Free
O que é a automação de navegador com OpenClaw?
OpenClaw é uma plataforma gratuita e open source de agente de IA (licença MIT) que pode controlar um navegador por você. Em vez de escrever scripts em Selenium ou código em Puppeteer, você descreve em linguagem natural o que quer fazer — "Acesse esta página e extraia todos os nomes e preços dos produtos" — e a IA descobre como executar. Ela usa um sistema de snapshots numerados em que o agente identifica os elementos da página, atribui números de referência e interage com eles passo a passo.
A arquitetura tem três partes — por isso a configuração envolve mais do que simplesmente instalar uma extensão:
- Gateway (VPS/servidor): o "cérebro" que processa suas instruções e se conecta aos LLMs. Por padrão, roda na porta 18789.
- Node Host (máquina local): um intermediário que permite ao Gateway enviar instruções ao seu Chrome local. Conectado por um túnel seguro, como o Tailscale.
- Extensão do Chrome (Browser Relay): dá ao agente controle direto sobre abas do navegador no seu navegador real.
Outras portas incluem o Control Service (18791), o CDP Relay (18792) e o CDP do navegador gerenciado (18800–18899, com suporte a até 100 perfis paralelos).
Sim, são muitas peças. Mas, quando você entende o papel de cada uma, a configuração faz sentido. Pense como um carrinho de controle remoto: o Gateway é o controle, o Node Host é o sinal de rádio e a Extensão do Chrome é o carrinho em si.

Por que a automação de navegador com OpenClaw importa para equipes de negócios
Profissionais do conhecimento chegam a gastar até 60% do tempo em tarefas administrativas de rotina, em vez de trabalho de maior valor, incluindo 1,8 hora por dia apenas procurando e reunindo informações. A Smartsheet descobriu que mais de 40% dos trabalhadores passam pelo menos um quarto da semana em tarefas manuais e repetitivas. Só a digitação manual de dados custa às empresas americanas uma estimativa de $8.500 por funcionário por ano.
Esse é o problema que a automação de navegador com OpenClaw foi feita para resolver. Na prática, ela se encaixa em fluxos de trabalho de negócios bem específicos:
| Caso de uso | O que o OpenClaw faz | Resultado para o negócio |
|---|---|---|
| Geração de leads | Extrai contatos de diretórios e páginas de empresas | Pipeline de vendas preenchido mais rápido |
| Monitoramento de preços da concorrência | Navega diariamente por páginas de produtos e extrai preços | Inteligência competitiva em tempo real |
| Preenchimento de formulários / entrada de dados | Preenche formulários web repetitivos (CRM, portais, inscrições) | Horas economizadas por semana |
| Monitoramento de conteúdo | Verifica blogs concorrentes, vagas e press releases | Sinais antecipados da concorrência |
| QA / testes | Percorre fluxos da web para verificar se funcionam | Menos experiências quebradas para o usuário |
O mercado de agentes de IA chegou a $7,38 bilhões em 2025, quase dobrando em relação aos $3,7 bilhões de 2023, e 88% das organizações já usam automação com IA em pelo menos uma função. Já não é mais uma categoria de nicho.
Chromium em sandbox vs. Browser Relay vs. Chrome Remote Debugging: escolhendo o modo certo
Escolher o modo errado de navegador é, na minha experiência, a maior fonte de frustração para quem está começando com OpenClaw. Já vi pessoas perderem horas depurando problemas de conexão que teriam sido evitados se tivessem escolhido outro modo logo de início. O OpenClaw oferece três formas de conexão, e cada uma tem trade-offs reais:
- Chromium em sandbox (perfil gerenciado): o OpenClaw abre seu próprio navegador headless no servidor. Sem sessões de login, rápido, pouca configuração — mas mais fácil de ser detectado por sistemas anti-bot.
- Browser Relay (sessão existente): um node host na sua máquina local retransmite instruções da VPS para o seu Chrome real. Suporta sessões de login e cookies e herda a impressão digital do seu navegador.
- Chrome Remote Debugging (CDP remoto): conecta a navegadores remotos via URL WebSocket. Acesso total à sessão, porém com a maior complexidade de configuração. Funciona com provedores em nuvem como Browserless ou Browserbase.

Tabela comparativa: os três modos de navegador
| Fator | Chromium em sandbox | Browser Relay | CDP remoto |
|---|---|---|---|
| Suporte a login | ❌ Não (perfil novo) | ✅ Sim (sessões reais) | ✅ Sim (pré-autenticado) |
| Risco anti-bot | ⚠️ Médio-alto | ✅ Baixo (impressão digital real) | ✅ Baixo (gerenciado pelo provedor) |
| Velocidade | ✅ Rápido | ⚠️ Mais lento (retransmissão pela rede) | ⚠️ Varia |
| Complexidade de configuração | Baixa | Média | Alta |
| Suporte completo a recursos | ✅ Sim (todos os recursos) | ⚠️ Limitado (sem batch, sem interceptação de downloads) | Depende do provedor |
| Melhor para | Páginas públicas, extrações rápidas | Sites com login, preenchimento de formulários | Infra em nuvem, monitoramento contínuo |
Fluxograma de decisão: qual modo você deve escolher?
Passe por estas perguntas na ordem:
- "Você precisa estar logado?" — Não → Chromium em sandbox. Sim → próxima pergunta.
- "O site tem proteção anti-bot pesada?" — Sim → Browser Relay (a impressão digital do seu navegador real reduz a detecção). Não → Browser Relay ou CDP remoto.
- "Você precisa de uma sessão persistente e sempre ativa (por exemplo, monitorar um dashboard 24/7)?" — Sim → CDP remoto com um provedor em nuvem. Não → Browser Relay.
Mapeamento de cenários reais:
- Extrair anúncios públicos da Amazon → Chromium em sandbox
- Preencher um formulário de CRM atrás de login → Browser Relay
- Monitorar um dashboard interno de analytics 24 horas por dia → CDP remoto com Browserless/Browserbase
Escolha certo aqui e você vai economizar horas de depuração. Sério.
Antes de começar
- Dificuldade: intermediária (é preciso ter conforto com CLI)
- Tempo necessário: 45–75 minutos para a configuração completa; 10–15 minutos por etapa
- O que você vai precisar: uma VPS (mínimo de 2 GB de RAM, 4 GB recomendado), Node.js v22.12.0+ , uma conta no Tailscale (gratuita), navegador Chrome e paciência
Passo 1: colocar o OpenClaw para rodar em uma VPS (ou localmente)
A VPS é onde fica o "cérebro" do OpenClaw. Há dois caminhos para colocá-lo em funcionamento:
Opção A: hospedagem VPS com um clique
Alguns provedores oferecem imagens do OpenClaw pré-configuradas:
| Provedor | Preço inicial | Observações |
|---|---|---|
| Hostinger | A partir de US$ 6,99/mês | Imagem pré-configurada |
| Tencent Cloud Lighthouse | A partir de ~US$ 0,08/ano (promoção) | Recomendado 2 núcleos/4 GB |
| Hetzner | A partir de US$ 4,09/mês (CX22) | Melhor custo-benefício; instalação manual |
| DigitalOcean | A partir de US$ 4/mês | Instalação manual |
| Vultr | A partir de US$ 3,50/mês | Instalação manual |
Opção B: instalação manual via CLI
# Instalar via npm (requer Node.js v22.12.0+)
npm install -g openclaw
# Executar o assistente de onboarding
openclaw onboard
# Gerar token do gateway (salve este token — você vai precisar dele no node host)
openclaw doctor --generate-gateway-token
# Validar a configuração
openclaw doctor --fix
Especificações mínimas: 2 GB de RAM (trava com 1 GB), 4 GB recomendado. Cada instância de navegador headless consome de 400 a 800 MB em repouso. Se você estiver usando Docker, defina shm_size: '2gb' — isso é crucial para a estabilidade.
Depois desta etapa, você deve ter o OpenClaw rodando e um token do Gateway salvo em algum lugar seguro. (Eu guardo o meu em um gerenciador de senhas. Não o perca.)
Passo 2: configurar o Tailscale para conectar a VPS e a máquina local
O Tailscale cria um túnel privado e criptografado entre sua VPS e seu dispositivo local, para que as instruções do navegador não fiquem expostas na internet pública. Considerando que o OpenClaw teve 512 vulnerabilidades apontadas pela Kaspersky no início de 2026, pular essa etapa não é uma boa ideia.
# Na VPS
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up --ssh=true
# Anote o IP da VPS no Tailscale (100.x.x.x)
# Configure o Gateway para escutar na rede Tailscale
openclaw config set gateway.listen "100.x.x.x:18789"
Instale o Tailscale na sua máquina local em tailscale.com/download. Os dois dispositivos devem usar a mesma conta do Tailscale.
Alternativas se o Tailscale não for sua praia:
| Fator | Tailscale | Cloudflare Tunnel | WireGuard |
|---|---|---|---|
| Tempo de configuração | 5 min | 10–15 min | 20–30 min |
| Custo | Grátis (uso pessoal) | Grátis | Grátis |
| Traversia de NAT | Automática | Automática | Manual |
Agora você já deve conseguir fazer ping no IP da VPS no Tailscale a partir da sua máquina local. Se não conseguir, verifique se os dois dispositivos estão na mesma conta do Tailscale.
Passo 3: instalar o Node Host no seu dispositivo local
O node host retransmite as instruções do navegador do Gateway da VPS para o seu Chrome local — é o tradutor entre servidor e navegador.
# Instalar o pacote do node host
npm install -g @openclaw/node-host
# Definir o token do gateway do Passo 1
export OPENCLAW_GATEWAY_TOKEN="your-token-here"
# Iniciar o node host, apontando para o IP do Tailscale da VPS
openclaw node install --host 100.x.x.x --port 18789
# Aprovar a conexão do lado da VPS
openclaw node approve <node-id>
Você deve ver uma confirmação de que o node está conectado e aprovado. Se a etapa de aprovação travar, reinicie o processo do Gateway na VPS.
Passo 4: instalar a extensão do OpenClaw para Chrome
A extensão dá ao agente controle direto sobre as abas do navegador. Você também pode encontrá-la na Chrome Web Store pesquisando por "OpenClaw Browser Relay."
# Instalar os arquivos da extensão
openclaw browser extension install
# Ou fazer manualmente:
# 1. Abra chrome://extensions
# 2. Ative o "Developer mode" (alternância no canto superior direito)
# 3. Clique em "Load unpacked" → selecione o diretório da extensão
# 4. Fixe na barra de ferramentas
# 5. Confirme se o selo mostra "ON"
Se o selo mostrar "ON", está tudo certo. Se continuar em "OFF", pule para a seção de solução de problemas abaixo.
Passo 5: executar sua primeira tarefa de automação de navegador com OpenClaw
Abra uma aba de destino e, pela interface de chat do OpenClaw, tente algo simples:
Acesse https://books.toscrape.com e extraia o título e o preço de todos os livros da página
Fluxo esperado: instrução enviada → o agente tira um snapshot (identifica os elementos da página com referências numeradas) → o agente extrai os dados → a saída estruturada é retornada em JSON ou CSV.
Uma dica da prática: comece com prompts bem simples. Excesso de detalhes pode confundir a IA — adicione mais informação só se o agente interpretar errado a instrução inicial.
Para 20 livros na primeira página, espere algo em torno de 30 a 60 segundos. Se os dados estruturados voltarem, sua configuração de automação de navegador com OpenClaw está funcionando.
Automação de navegador com OpenClaw no Windows: o caminho nativo de configuração
A maioria dos guias do OpenClaw pressupõe macOS ou Linux. Se você está no Windows, provavelmente já percebeu isso. Um usuário de fórum resumiu bem: "muitas soluções pareciam fazer sentido em teoria, mas nenhuma foi pensada para Windows nativo."
Aqui está o que realmente funciona.
Opção A: Chrome Remote Debugging no Windows (caminho nativo recomendado)
A abordagem nativa mais confiável para Windows. Abra o PowerShell e inicie o Chrome com depuração remota ativada:
& "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Se o Chrome não estiver nesse caminho, tente:
# Verificar locais alternativos
Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse
# Ou verificar o AppData
& "$env:LOCALAPPDATA\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Depois, configure o OpenClaw para conectar via CDP remoto definindo cdpUrl como ws://localhost:9222 no seu arquivo openclaw.json.
Opção B: Docker Desktop como alternativa no Windows
Se o caminho nativo der problema, o Docker Desktop no Windows pode executar um contêiner Chromium headless:
docker run -d --name openclaw-browser -p 9222:9222 --shm-size=2g browserless/chrome
# Aponte o OpenClaw para: cdpUrl: "ws://localhost:9222"
Isso adiciona outra camada de complexidade, mas é mais estável para alguns usuários. Funciona, embora não seja elegante.
Catálogo de erros específicos do Windows
| Erro | Causa | Correção (PowerShell) |
|---|---|---|
| Porta 9222 já está em uso | Outra sessão do DevTools está aberta | `Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess |
| Binário do Chrome não encontrado | Caminho incorreto | Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse |
| Conexão Tailscale recusada | Firewall do Windows bloqueando | New-NetFirewallRule -DisplayName "OpenClaw" -Direction Inbound -LocalPort 18789 -Protocol TCP -Action Allow |
| Erros de permissão do npm | Não está executando como administrador | Execute o PowerShell como Administrador ou use nvm-windows |
Todos os comandos acima são do PowerShell, não bash. É só copiar e colar.
Guia de sobrevivência contra bots para automação de navegador com OpenClaw
Detecção de bots é a principal frustração para quem usa automação de navegador com OpenClaw. O Chromium padrão do OpenClaw não tem medidas nativas de stealth — sites o detectam pelo sinalizador WebDriver, dimensões da tela, fingerprint de fontes e reputação do IP. Já vi agentes serem bloqueados em segundos em alguns sites.
Mas existe uma estratégia em camadas. Comece pela correção mais simples e avance só se precisar.
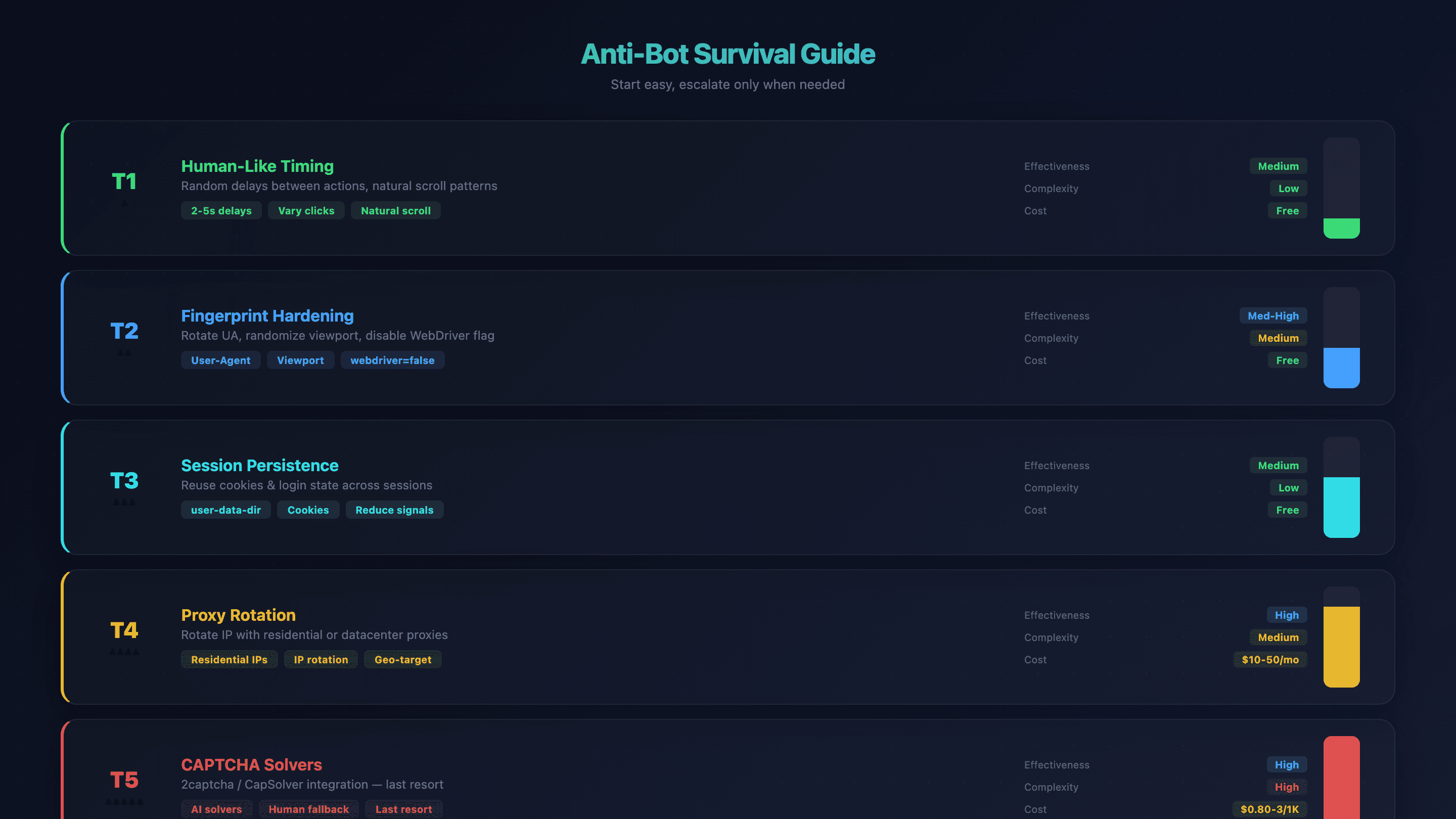
Nível 1: timing e comportamento mais humanos
Adicione atrasos aleatórios entre as ações nos prompts. Em vez de disparar cliques na velocidade de máquina, instrua o agente: "aguarde de 2 a 5 segundos entre cada clique". A IA já varia o tempo em certa medida, mas instruções explícitas ajudam.
Efetividade: média | Complexidade: baixa | Custo: grátis
Nível 2: fortalecimento da impressão digital
Altere strings de user-agent, randomize o tamanho da viewport e deixe o OpenClaw desativar automaticamente o sinalizador navigator.webdriver (via --disable-blink-features=AutomationControlled).
# Definir headers personalizados
openclaw browser set headers --headers-json '{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"}'
# Randomizar viewport
openclaw browser set viewport 1366 768
# Definir fuso horário e localidade
openclaw browser set timezone America/New_York
openclaw browser set locale en-US
Para uma camada mais profunda de anti-detecção, a comunidade recomenda Camoufox (um navegador anti-detect baseado em Firefox com spoofing de fingerprint em nível de engine C++).
Efetividade: média-alta | Complexidade: média | Custo: grátis
Nível 3: persistência de sessão
Use user-data-dir para manter cookies e estado de login entre sessões. Isso reduz sinais de "navegador novo", que acionam sistemas anti-bot.
openclaw config set browser.profiles.persistent.userDataDir "/path/to/chrome-profile"
openclaw config set browser.profiles.persistent.cdpPort 18802
Efetividade: média | Complexidade: baixa | Custo: grátis
Nível 4: rotação de proxy
Quando timing e fingerprint não bastam, troque seu endereço IP. Proxies residenciais são mais difíceis de detectar; proxies de datacenter são mais rápidos e baratos.
export OPENCLAW_BROWSER_PROXY="http://user:pass@proxy.example.com:8080"
Observação: a configuração de proxy no nível do navegador ainda é um pedido de recurso (GitHub Issue #8079). No momento, os proxies precisam ser definidos no nível do sistema operacional ou da variável de ambiente.
| Provedor | Residencial | Datacenter | Melhor para |
|---|---|---|---|
| Bright Data | US$ 4–8,40/GB | US$ 0,43–0,60/GB | Empresas, qualidade máxima |
| Oxylabs | US$ 6–8/GB | US$ 0,48–5/GB | Extração em grande escala |
| Decodo (Smartproxy) | US$ 4–5,50/GB | US$ 0,70–5/GB | Orçamentos médios |
| IPRoyal | US$ 5–7/GB | -- | Opção econômica |
| DataImpulse | US$ 1/GB | -- | Menor custo |
Efetividade: alta | Complexidade: média | Custo: US$ 10–50/mês
Nível 5: resolvedores de CAPTCHA
Último recurso. Integre serviços como 2captcha ou CapSolver.
| Serviço | reCAPTCHA v2 | Cloudflare Turnstile | Latência |
|---|---|---|---|
| 2Captcha | US$ 2,99/1K | US$ 2,99/1K | 15–45 s (resolvedores humanos) |
| CapSolver | US$ 0,80–1,50/1K | US$ 0,80/1K | 0,5–10 s (IA) |
O FlareSolverr (bypass open source para Cloudflare) é descrito como pouco confiável em 2025–2026 devido ao aumento das defesas da Cloudflare.
Efetividade: alta | Complexidade: alta | Custo: US$ 0,80–3/1K resoluções
Tabela-resumo anti-bot
| Técnica | Efetividade | Complexidade | Custo |
|---|---|---|---|
| Timing humano | Média | Baixa | Grátis |
| Fortalecimento de fingerprint | Média-alta | Média | Grátis |
| Persistência de sessão | Média | Baixa | Grátis |
| Rotação de proxy | Alta | Média | US$ 10–50/mês |
| Solvers de CAPTCHA | Alta | Alta | US$ 0,80–3/1K resoluções |
Para usuários que batem repetidamente em barreiras anti-bot e só precisam dos dados: a extração em nuvem da Thunderbit lida com anti-bot automaticamente em sites públicos — sem configuração de proxy, sem ajuste de fingerprint. É uma abordagem fundamentalmente diferente (a IA lê o site a cada execução por meio de infraestrutura em nuvem gerenciada) que contorna toda a guerra anti-bot para tarefas padrão de extração de dados.
Saída real: o que a automação de navegador com OpenClaw realmente produz
Antes de investir 45–75 minutos de configuração, você provavelmente quer ver como fica o resultado final. Faz sentido — aqui estão três exemplos de fluxo de trabalho com saída real.
Exemplo 1: web scraping — extraindo dados de produtos
Prompt: "Acesse https://books.toscrape.com e extraia o título e o preço de todos os livros da página"
Saída (primeiras 5 linhas):
| Título | Preço |
|---|---|
| A Light in the Attic | £51.77 |
| Tipping the Velvet | £53.74 |
| Soumission | £50.10 |
| Sharp Objects | £47.82 |
| Sapiens: A Brief History of Humankind | £54.23 |
Tempo decorrido: ~45 segundos para 20 linhas (uma única página). A paginação exigiu uma instrução de acompanhamento: "Clique no botão Next e repita por 5 páginas." Total: ~100 linhas em cerca de 3 minutos.
Exemplo 2: automação de formulários — preenchendo um formulário web com vários campos
Cenário: preencher um formulário de consulta de fornecedor com nome da empresa, dados de contato e interesse em produtos.
O agente tira um snapshot do formulário, identifica cada campo pelo número de referência e os preenche em sequência. Antes: campos vazios. Depois: todos os campos preenchidos, com mensagem de confirmação exibida. Menus suspensos ou caixas de seleção também são tratados pelo sistema de snapshot — o agente "vê" as opções e escolhe a correta.
Tempo decorrido: ~30 segundos para um formulário com 6 campos.
Exemplo 3: paginação — extraindo dados de várias páginas
Resultado inicial: 20 linhas da página 1. Depois de instruir "clique em Next e repita por todas as páginas": 1.000 linhas em 50 páginas em books.toscrape.com. O agente detecta o botão "Next" pelo snapshot e clica em loop.
Tempo decorrido: ~12 minutos para o conjunto completo de 1.000 linhas.
Lado a lado: a mesma tarefa de extração na Thunderbit
Para o mesmo exemplo de books.toscrape.com, veja como fica o fluxo na Thunderbit:
- Instale a Extensão do Chrome da Thunderbit (~30 segundos)
- Acesse a página
- Clique em "AI Suggest Fields" → a IA detecta Título, Preço, Disponibilidade e Avaliação
- Clique em "Scrape" → 20 linhas extraídas
- Use os controles de paginação → todas as páginas são extraídas
- Exporte para o Google Sheets (grátis)
Tempo total: cerca de 3 minutos do zero até os dados exportados, sem VPS, sem CLI e sem configuração.
O ponto não é que uma ferramenta seja "melhor". A ferramenta certa depende do que você realmente quer fazer.
Experimente a extensão Thunderbit para Chrome
Quando a automação de navegador com OpenClaw é exagero (e o que usar no lugar)
O OpenClaw se destaca em automações complexas, com várias etapas e comportamento agentivo — fluxos atrás de login, encadeando ações de navegador com comandos de shell, funcionando 24/7 em uma VPS. Mas, se o objetivo é "extrair dados de produtos de uma página de listagem" ou "coletar e-mails de um diretório", toda a estrutura de VPS + Tailscale + node host provavelmente é sofisticada demais.
Já vi pessoas investirem mais de 60 minutos de configuração para uma tarefa que leva 2 minutos com uma ferramenta mais simples. Não é uma boa troca.

A ferramenta certa para o trabalho: tabela comparativa
| Fator | Automação de navegador com OpenClaw | Thunderbit |
|---|---|---|
| Tempo de configuração | 45–75 min (VPS + Tailscale + node host) | ~2 min (instalação da extensão Chrome) |
| Exige programação | CLI + prompts em linguagem natural | Zero — clique em "AI Suggest Fields" → "Scrape" |
| Tratamento anti-bot | Manual (proxy, configuração de fingerprint) | Extração em nuvem integrada |
| Navegação em sites com login | ✅ Browser Relay / depuração remota | ✅ Modo de extração via navegador |
| Enriquecimento de subpáginas | Script personalizado por fluxo | Extração de subpáginas com 1 clique |
| Execuções agendadas / 24×7 | Baseado em VPS, sempre ativo | Scheduled scraper integrado |
| Custo mensal | US$ 8–14 (uso hobby) até US$ 110–280 (uso intenso) | US$ 0 (plano gratuito) até US$ 15/mês |
| Carga de manutenção | Alta (atualizações, VPS, depuração) | Quase zero — a IA se adapta a mudanças de layout |
| Melhor para | Fluxos agentivos complexos, pipelines personalizados | Extração de dados, preenchimento de formulários, geração de leads, monitoramento de preços |
Direcionamento por caso de uso
- Você precisa de fluxos agentivos em várias etapas que encadeiam ações do navegador com comandos de shell, apps de mensagens e bancos de dados → OpenClaw é a escolha certa.
- Você precisa extrair dados de sites, preencher formulários ou monitorar preços sem tocar em terminal → Thunderbit vai te levar até lá muito mais rápido. Você também pode conferir o canal da Thunderbit no YouTube para demonstrações rápidas.
- Você precisa de um script leve para um endpoint de API específico → um simples script em Python com requests pode ser tudo o que você precisa.
Esse é, de verdade, o raciocínio que uso quando alguém do meu time pergunta "qual ferramenta devo usar para isso?"
Erros comuns na automação de navegador com OpenClaw e como corrigir
Salve esta seção. Ela está organizada por sintoma para você encontrar a solução com Ctrl+F.
"Connection Refused" ou o Node Host não conecta
Causas prováveis (verifique nesta ordem):
- Tailscale não está rodando nos dois dispositivos → execute
tailscale statusem ambos - O Gateway não foi configurado para escutar na rede Tailscale (continua em localhost) →
openclaw config set gateway.listen "100.x.x.x:18789" - IP incorreto → confirme com
tailscale ip -4 - Firewall bloqueando a porta 18789 →
sudo ufw allow 18789/tcp(Linux) ou adicione uma regra no Windows Firewall
O selo da extensão continua em "OFF" ou a aba não é detectada
- A extensão não foi carregada em Developer mode →
chrome://extensions→ ative o Developer mode → recarregue - O node host não está rodando → reinicie com
openclaw node start - Conflito com instância do Chrome → feche todas as instâncias do Chrome, abra novamente e recarregue a extensão
O agente retorna dados vazios ou incorretos
- A página não carregou totalmente: instrua o agente a "aguardar 3 segundos após navegar antes de extrair". Muitas SPAs precisam de tempo para renderizar.
- Bloqueio anti-bot: verifique se você está recebendo uma página de CAPTCHA em vez do conteúdo real. Troque de Chromium em sandbox para Browser Relay.
- Snapshot desatualizado: peça ao agente para "tirar um novo snapshot" — os números de referência ficam obsoletos após a navegação.
"Port 9222 Already in Use"
Comum quando o Chrome DevTools ou outra ferramenta de automação já está usando a porta.
# macOS/Linux
lsof -i :9222 | grep LISTEN
kill -9 <PID>
# Windows PowerShell
Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force
A VPS fica sem memória
Cada instância de navegador headless usa de 400 a 800 MB de RAM. Rodar várias simultaneamente pode derrubar uma VPS pequena.
Correções:
- Desative carregamento de imagens/CSS/fontes:
openclaw browser network route --abort "**/*.{png,jpg,gif,css,woff2}" - Limite as instâncias simultâneas ao que sua RAM suporta
- Defina
shm_size: '2gb'nas configurações do Docker - Ative hibernação de sessão:
OPENCLAW_HIBERNATE_AFTER=300 - Faça upgrade para uma VPS com 4 GB+ de RAM se precisar de mais folga
Dicas para manter sua automação de navegador com OpenClaw funcionando sem problemas
Algumas boas práticas que aprendi ao longo do tempo rodando essas configurações:
- Desative imagens, folhas de estilo e fontes em tarefas de extração apenas de dados. Isso reduz bastante o uso de recursos e acelera tudo.
- Reutilize instâncias do navegador em vez de abrir uma nova para cada tarefa. Instâncias novas custam caro em RAM e geram mais sinais anti-bot.
- Comece com prompts simples. Acrescente detalhes só se o agente interpretar errado. Explicar demais pode confundir a IA em vez de ajudar.
- Monitore o uso de recursos da VPS (CPU, RAM) e aumente a capacidade antes de atingir o limite. Uma VPS travada às 2 da manhã não é nada divertida de depurar.
- Mantenha o OpenClaw e a extensão do Chrome atualizados — mas teste as atualizações primeiro em um ambiente de staging. O OpenClaw lança cerca de 13 versões por mês, e nem todas são suaves.
- Para tarefas recorrentes e contínuas (verificações diárias de preço, coletas semanais de leads), o scheduled scraper da Thunderbit permite definir intervalos em linguagem natural e esquecer a manutenção da VPS.
Considerações éticas e legais
Breve, mas importante. Respeite o robots.txt (formalizado como padrão IETF em RFC 9309), limite a taxa de requisições, revise os termos de serviço dos sites-alvo e trate dados pessoais de acordo com o GDPR e as leis de privacidade. O precedente hiQ v. LinkedIn (2022) estabeleceu que extrair dados públicos acessíveis não viola o CFAA, mas isso não significa que vale tudo. Usar automação de forma responsável protege você e sua empresa. Para saber mais sobre o tema, confira nosso guia sobre implicações legais do web scraping.
Conclusão
A automação de navegador com OpenClaw é uma opção poderosa para fluxos web complexos e com várias etapas, controlados em linguagem natural. O que mais importa é isto:
- Escolha o modo de navegador certo logo de início (Sandbox, Relay, CDP remoto) — essa única decisão economiza horas de depuração.
- Usuários de Windows têm um caminho viável, mas precisam seguir comandos específicos do Windows e ficar atentos a firewall e caminhos de arquivos.
- O tratamento anti-bot é um desafio real — comece com as técnicas mais simples (timing, fingerprint) e aumente a complexidade só quando necessário.
- Veja a saída antes de se comprometer. Se o que você precisa é apenas dados estruturados de uma página de listagem, uma ferramenta no-code como a Thunderbit resolve em minutos, sem manutenção.
- Reserve orçamento para manutenção. O OpenClaw lança cerca de 13 versões por mês, os custos de VPS acumulam e depurar faz parte do pacote.
Se você quiser tentar o caminho mais simples primeiro, a Thunderbit oferece um plano gratuito — instale a extensão, extraia uma página e veja se isso atende ao seu caso de uso antes de investir em uma VPS completa. Se decidir seguir com o OpenClaw, salve este guia. Você provavelmente vai precisar do catálogo de erros mais cedo ou mais tarde — e que suas instâncias de navegador nunca fiquem sem RAM.
Perguntas frequentes
Qual é a diferença entre o OpenClaw Sandbox Chromium e o Browser Relay?
O Sandbox Chromium executa um navegador headless no servidor — é rápido e exige pouca configuração, mas cria um perfil novo a cada vez (sem sessões de login) e é mais fácil de ser detectado por sistemas anti-bot. O Browser Relay encaminha as instruções para o seu Chrome real na máquina local, então ele suporta logins, herda a impressão digital real do navegador e é mais difícil para os sites identificarem como automação. A troca é que o Browser Relay é mais lento por causa da retransmissão de rede e tem algumas limitações de recursos (sem ações em lote, sem interceptação de downloads).
Posso rodar a automação de navegador com OpenClaw no Windows sem WSL?
Sim, mas com ressalvas. O caminho nativo mais confiável no Windows é o Chrome Remote Debugging via PowerShell (chrome.exe --remote-debugging-port=9222). O Docker Desktop é uma alternativa se isso não funcionar bem. O suporte nativo completo ao Node Host no Windows ainda pode ter arestas — consulte a documentação atual e esteja preparado para problemas específicos do Windows, como bloqueios de firewall e diferenças no caminho do binário. Todos os comandos na seção de Windows deste guia são PowerShell, não bash.
Como lidar com CAPTCHAs na automação de navegador com OpenClaw?
Comece reduzindo o risco de detecção: adicione timing humano, fortaleça a impressão digital do navegador e use persistência de sessão para evitar sinais de navegador novo. Se os CAPTCHAs persistirem, integre um serviço solucionador como 2captcha (US$ 2,99/1K resoluções) ou CapSolver (US$ 0,80–1,50/1K, com IA). Para sites públicos em que você só precisa dos dados, a extração em nuvem da Thunderbit lida com anti-bot automaticamente, sem qualquer configuração de proxy ou CAPTCHA.
A automação de navegador com OpenClaw é gratuita?
O OpenClaw em si é open source (licença MIT) e gratuito. No entanto, executá-lo exige infraestrutura — uma VPS de US$ 4–15/mês, além de serviços opcionais como rotação de proxy (US$ 10–50/mês) ou solvedores de CAPTCHA (pagos por resolução). O custo mensal total varia de US$ 8–14 para uso hobby até US$ 110–280 para cargas pesadas de automação. Em comparação, o plano gratuito da Thunderbit cobre extração básica sem custos de infraestrutura.
O que devo fazer se meu agente OpenClaw continuar retornando resultados vazios?
Três coisas para checar, nesta ordem: primeiro, a página pode não ter carregado completamente — instrua o agente a "aguardar 3 segundos após navegar antes de extrair". Segundo, você pode estar batendo em uma barreira anti-bot — se o agente estiver "vendo" uma página de CAPTCHA em vez do conteúdo real, troque Chromium em sandbox por Browser Relay. Terceiro, as referências do snapshot podem estar obsoletas — peça ao agente para "tirar um novo snapshot" após qualquer navegação. Se nada disso funcionar, verifique o uso de memória da VPS — uma instância de navegador travada pode retornar resultados vazios sem aviso.
Experimente a Thunderbit para extrair dados da web mais rapidamente Get Started Free




