A maioria dos artigos de "análise do octoparse" na internet é, para dizer com delicadeza, pouco confiável. Vários usuários no Reddit e no Trustpilot relatam ter sido abordados pelo Octoparse para escrever avaliações pagas de 5 estrelas — e, depois que você sabe disso, qualquer texto elogioso começa a parecer diferente. Eu trabalho na Thunderbit, então tenho interesse nessa disputa. Mas também passo bastante tempo pesquisando, testando e comparando ferramentas de web scraping — não só as nossas, mas o mercado inteiro. Para esta análise, juntei notas do G2, Capterra e Trustpilot, cruzei reclamações reais de usuários no Reddit e em fóruns e testei o Octoparse de forma independente. O objetivo: entregar uma avaliação honesta e específica sobre onde o Octoparse funciona, onde ele falha, quanto ele realmente custa e quando vale mais a pena usar outra solução. Se você trabalha com vendas, ecommerce, marketing ou simplesmente precisa extrair dados da web sem programar em Python, esta é a análise que eu gostaria de ter encontrado quando comecei a pesquisar.
O que é o Octoparse? Visão rápida para usuários de negócios
O Octoparse é uma ferramenta de web scraping sem código, baseada em desktop. Você instala no Windows ou no macOS, aponta para um site e usa um construtor visual de fluxo de trabalho, com cliques, para dizer quais dados devem ser extraídos. Sem programação — pelo menos, essa é a promessa.
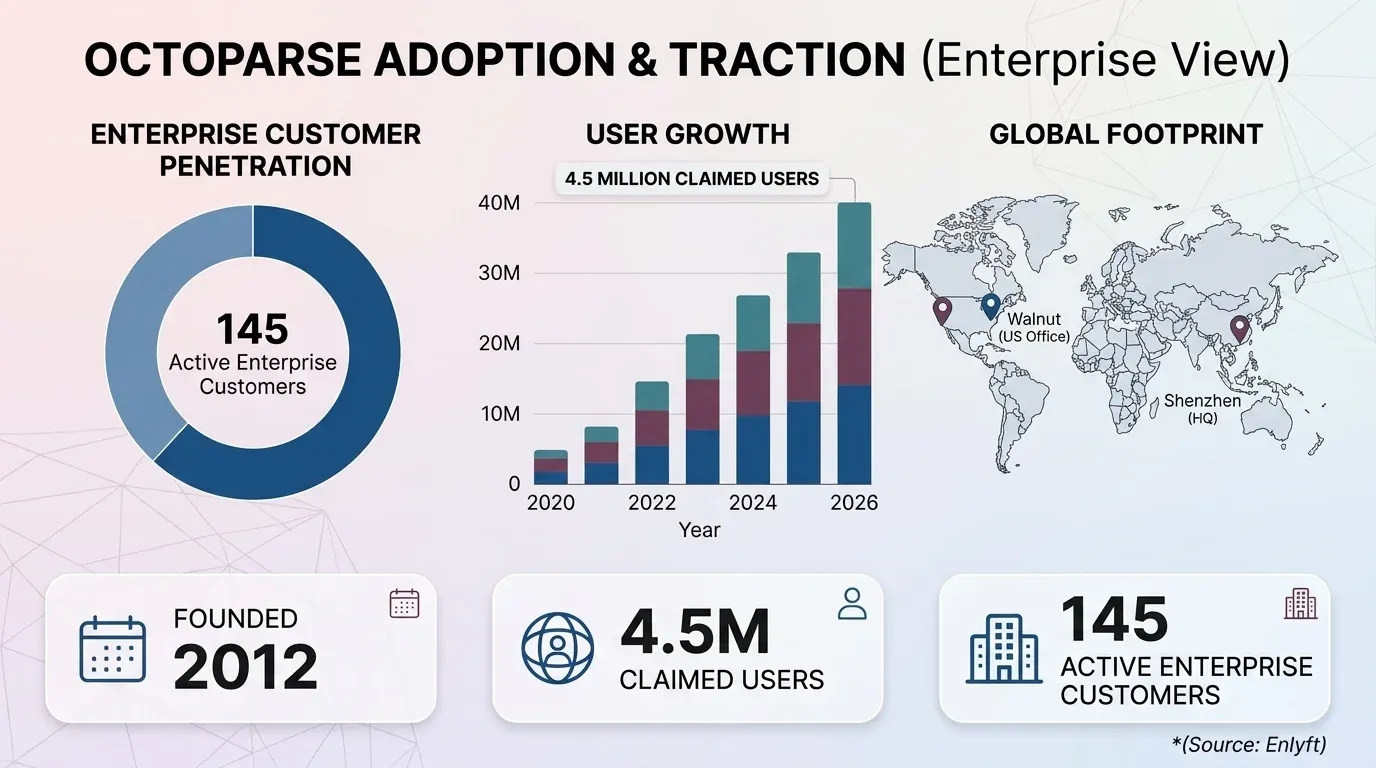
Nos bastidores, o Octoparse gera seletores XPath com base nos seus cliques e depois executa esses seletores localmente (na sua máquina) ou na nuvem (nos servidores do Octoparse). Ele exporta dados para Excel, CSV, JSON e bancos de dados (MySQL, SQL Server, PostgreSQL) e — nos planos pagos — Google Sheets, Dropbox e S3. A empresa, Octopus Data Inc., foi em Shenzhen, na China, com escritório nos EUA em Walnut, Califórnia. Eles afirmam ter no mundo todo, embora rastreadores independentes como a Enlyft indiquem que o número de clientes corporativos ativos esteja mais perto de ~145.
O público-alvo inclui pesquisadores de mercado, equipes de ecommerce, profissionais de geração de leads e qualquer pessoa que precise de dados estruturados da web sem escrever código. A versão atual é 8.9.0 (março de 2026).
Esse é o pitch de elevador. A pergunta real é: ele entrega mesmo?
Dá para confiar nas avaliações do Octoparse? O problema das reviews incentivadas
Antes de falar de recursos e pontos de falha, há algo importante sobre o cenário de avaliações do Octoparse. Ele não é limpo.
Um avaliador no Trustpilot disse ter sido contatado diretamente pelo Octoparse:
"Você teria interesse nesta oferta? [15 dias extras no seu Plano Basic por uma avaliação 5 estrelas no Trustpilot]. Fiquei muito ofendido com a tentativa de manipular a nota no TrustPilot. Uma empresa séria, com um ótimo produto, não precisaria fazer isso."
Isso viola as próprias diretrizes do Trustpilot. No Capterra, muitas avaliações aparecem claramente marcadas como "Incentivized review" — o fornecedor convidou o usuário a avaliar em troca de um pequeno incentivo. Isso é permitido pelas regras do Capterra, mas naturalmente infla as notas. Notei que a segunda página de avaliações do Capterra mostrava — uma taxa de 92% de cinco estrelas — com blocos de comentários publicados em poucos dias e linguagem curta e padronizada.
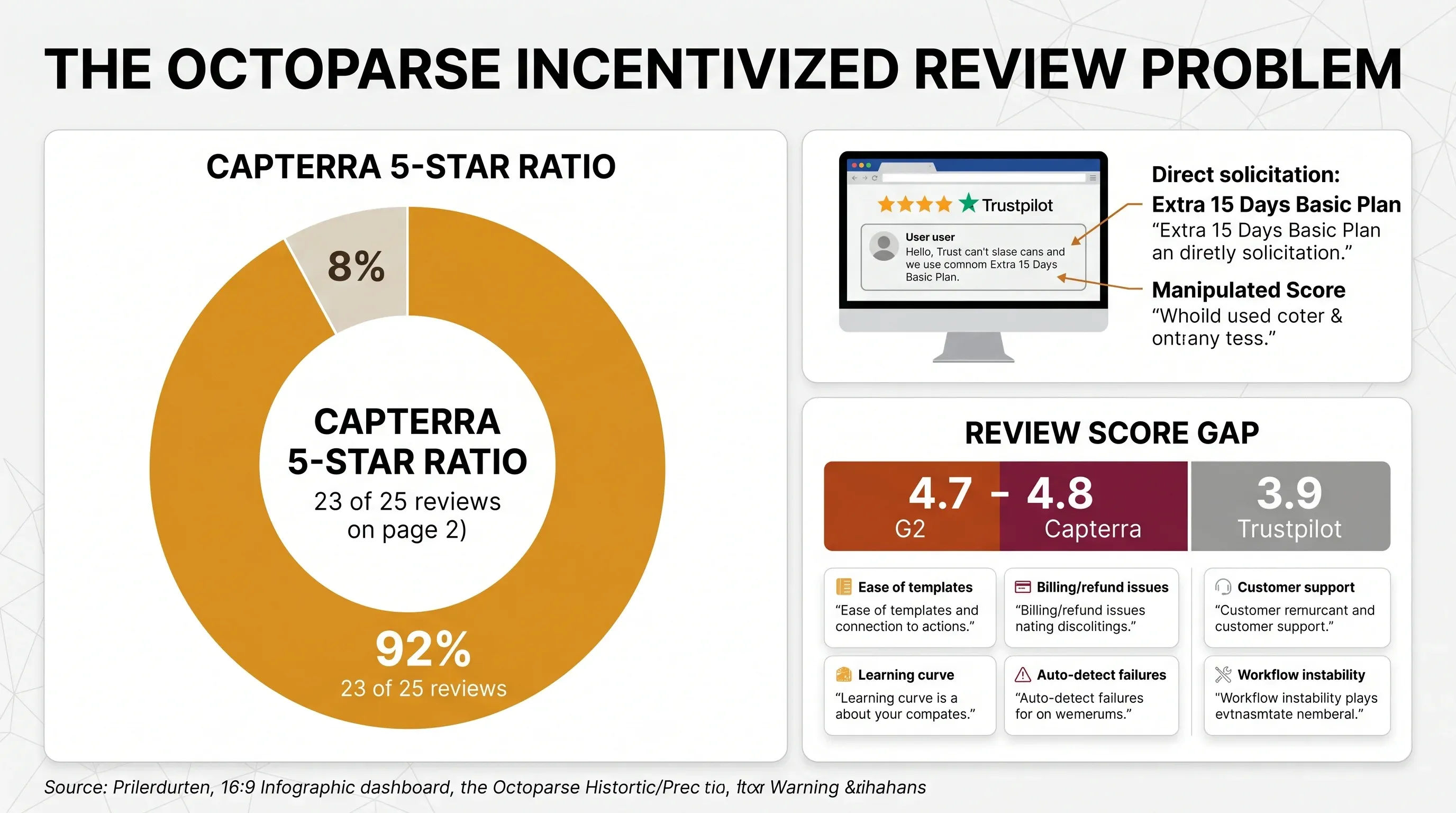
O resultado: uma diferença de quase um ponto inteiro entre as plataformas curadas e aquela em que as avaliações incentivadas são sinalizadas.
| Plataforma de avaliação | Nota | # de avaliações | Tema positivo principal | Tema negativo principal |
|---|---|---|---|---|
| G2 | 4,7–4,8/5 | 40–52 | Facilidade dos templates | Instabilidade do fluxo de trabalho |
| Capterra | 4,7/5 | 106 | Extração em nuvem | Problemas de cobrança/reembolso |
| Trustpilot | 3,9/5 | ~91 | Atendimento ao cliente | Falhas no auto-detect, disputas de reembolso |
| TrustRadius | 7,0/10 | 13 | Conjunto de recursos | Curva de aprendizado |
Citação positiva representativa (G2):
"Antes disso, eu honestamente evitava web scraping porque não conseguia encontrar uma solução que não exigisse habilidades técnicas ou programação. Mas o Octoparse fez parecer possível."
Citação negativa representativa (Trustpilot):
"Não merece nenhuma estrela. Tente cancelar essa conta gratuita? Boa sorte. As instruções fornecidas estão erradas — a função para cancelar não existe."
Não estou dizendo que toda avaliação positiva é falsa. Mas, se você estiver lendo análises do Octoparse em outros lugares, confira se a pessoa recebeu incentivo — e dê mais peso às notas sem filtro do Trustpilot.
Análise do Octoparse: o que realmente funciona bem (os pontos fortes)
É justo reconhecer: o Octoparse não é golpe — é um produto real, com forças reais. Veja o que ele faz bem.
Construtor visual de fluxo de trabalho
O coração do Octoparse é a interface de arrastar e clicar. Você abre uma URL no navegador embutido, clica nos dados desejados e o Octoparse gera automaticamente os seletores XPath. O editor de fluxo mostra um diagrama: Ir para a página → Loop → Extrair → Paginar. Para alguém que nunca escreveu uma linha de código, isso é um salto real em relação a scripts Python.
Na prática, raspagens simples de uma única página — como extrair uma tabela de nomes e preços de produtos — podem ser configuradas em menos de 10 minutos. A visualização do navegador integrado torna a seleção de elementos intuitiva: você clica, ele destaca, você confirma.
Templates prontos de tarefas
O Octoparse mantém uma biblioteca com para sites populares: Amazon, eBay, Google Maps, LinkedIn, Twitter/X, Indeed, Zillow, Yelp e muitos outros. Os templates já vêm configurados — sem necessidade de montar seletores manualmente. Para tarefas recorrentes e comuns em sites conhecidos, isso economiza bastante tempo.
Alguns templates são gratuitos com planos pagos; os templates premium usam um modelo de pagamento por resultado, entre .
Extração em nuvem e agendamento
Os planos pagos permitem executar tarefas nos servidores em nuvem do Octoparse, sem sobrecarregar seu computador. O agendamento pode ser por hora, diário, semanal ou personalizado. Para equipes que precisam de raspagens recorrentes e sem supervisão — como monitoramento diário de preços — isso é uma vantagem real. A concorrência em nuvem varia de 3–6 nós (Standard) para 20 (Professional) e 40+ (Enterprise).
Opções de exportação de dados
O Octoparse oferece exportação para Excel, CSV, JSON, HTML, XML e conexões diretas com bancos de dados (MySQL, SQL Server, PostgreSQL, Oracle). Google Sheets, Google Drive, Dropbox e S3 ficam disponíveis nos planos Professional. O acesso à API começa no Standard. Isso cobre a maioria dos fluxos de trabalho empresariais.
Análise do Octoparse: onde ele realmente trava (os pontos fracos)
Agora vem a parte que nenhuma avaliação incentivada vai contar. Cataloguei os modos de falha específicos e reproduzíveis que usuários reais enfrentam — não “contras” genéricos, mas cenários concretos com evidências em fóruns.
Bloqueios de Cloudflare e anti-bot
Esta é a reclamação grave mais comum. no Reddit, Capterra e Trustpilot descrevem o Octoparse falhando ao ultrapassar o Cloudflare e outras proteções anti-bot.
O cenário: você configura um fluxo para um site protegido por Cloudflare. Clica em “Run”. O resultado vem vazio ou aparece uma página de erro. O Octoparse adicionou a opção "Bypass Cloudflare with credit" a partir da versão 8.7.2, mas ela custa — e tentativas malsucedidas ainda consomem créditos.
"Eles não conseguiram resolver meu problema de negócio. Eu queria analisar/extrair um site específico e o serviço do Octoparse não conseguiu passar pela tecnologia anti-bot do Cloudflare." — Jason K., CTO, software,
Testes independentes colocam a taxa de sucesso abaixo de 60% em plataformas modernas como o LinkedIn. Para extrair dados do Google Maps, são necessários proxies residenciais porque o Google bloqueia IPs de datacenter de forma agressiva.
Para contexto, a Thunderbit lida com isso de forma diferente: nosso modo de scraping em nuvem usa rotação de IP integrada, e o modo de scraping no navegador roda na sua própria sessão do Chrome (então o site vê seu login e seus cookies reais, não um bot de datacenter).
O auto-detect deixa passar dados relevantes
O recurso Auto-detect do Octoparse deveria escanear uma página e identificar automaticamente os campos corretos. Na prática, testes independentes encontraram resultados consistentes em apenas 43% dos sites, com precisão de apenas 45% em conteúdo dinâmico ou pesado em JavaScript. Cerca de 15% dos dados extraídos precisaram de limpeza manual.
O cenário: você usa o Auto-detect numa página de produtos. Ele encontra o nome do produto, mas ignora o preço, ou então captura conteúdo irrelevante da barra lateral em vez da grade principal. No fim, você acaba ajustando os seletores XPath manualmente — o que desmonta a promessa de “sem código”.
Loops e paginação quebram sem aviso
O Octoparse mantém só para problemas de paginação e rolagem. Um deles se chama literalmente "Pagination Loop issue — The extraction stops after 3 pages."
O cenário: você está extraindo uma loja Shopify com rolagem infinita. O fluxo trava depois de 3 páginas porque o gatilho de rolagem falha. Não há mensagem de erro clara — a tarefa simplesmente para de gerar dados. O usuário precisa depurar a lógica manualmente, ajustando o tempo de rolagem, o XPath do botão "Next" ou alternando entre os modos Variable List e Fixed List.
"O XPath de paginação gerado automaticamente pode nem sempre funcionar bem." — Central de Ajuda oficial do Octoparse
Os fluxos quebram quando o layout do site muda
Como o Octoparse usa seletores XPath/CSS fixos, qualquer mudança no front-end do site alvo pode quebrar o fluxo inteiro — muitas vezes sem aviso, gerando conjuntos de dados vazios sem notificação.
"O Octoparse usa principalmente caminhos xpath de children/children/children, o que me parece menos robusto do que localizações com atributos específicos." — F.S., CEO, varejo,
"Toda vez que os concorrentes atualizavam seus sites, nossos fluxos quebravam." — dono de ecommerce,
Testes independentes mostraram que 73% das falhas de scrapers acontecem porque os seletores de elementos quebram após atualizações do site. Dados do setor indicam que ferramentas tradicionais de scraping exigem manutenção constante — scripts falham em poucas semanas conforme os sites mudam.
É aqui que ferramentas com IA, como a Thunderbit, levam vantagem estrutural: nossa IA lê a página do zero a cada vez, então não há seletores frágeis para reconstruir quando o layout muda.
A curva de aprendizado é mais íngreme do que o prometido
Apesar do marketing de “sem código”, o Octoparse exige 15–20 horas para alcançar um domínio básico e 40–60 horas para criar fluxos avançados. Montar fluxos de várias etapas (lista → página de detalhe, login, conteúdo via AJAX) ainda exige entender estrutura HTML, XPath e Regex quando o Auto-detect falha.
"Apesar de ter uma interface muito intuitiva, são necessárias várias horas de tentativa e erro antes que você consiga dominá-la completamente." — Juan Carlos R., diretor de programas de mestrado,
| Modo de falha | Severidade | Menções em fóruns | Estatística-chave |
|---|---|---|---|
| Curva de aprendizado / complexidade | MÉDIA | ~20–25 | 15–20 h para domínio básico |
| Bloqueio anti-bot / Cloudflare | ALTA | ~15–20 | <60% de sucesso em plataformas modernas |
| Paginação / rolagem infinita | MÉDIA-ALTA | ~12–18 | Mais de 7 artigos de ajuda dedicados |
| Falhas do Auto-detect | MÉDIA-ALTA | ~10–15 | 43% de taxa consistente de sucesso |
| Falhas de extração em nuvem | MÉDIA-ALTA | ~10–15 | Mais de 5 artigos de ajuda sobre o assunto |
| Problemas de cobrança / cancelamento | MÉDIA | ~10–12 | Diferença entre Trustpilot 3,9 e G2/Capterra 4,7 |
| Quebra de fluxo/XPath | MÉDIA | ~8–12 | 73% das falhas por quebra de seletor |
O custo real do Octoparse: despesas ocultas além da página de preços
A maioria das análises só tira print da tabela de preços. O custo real do Octoparse é bem mais alto — e mais difícil de prever.
Preço dos planos básicos
O próprio site do Octoparse publica valores conflitantes em páginas diferentes (a Central de Ajuda diz uma coisa, a página de preços diz outra). Aqui estão os números mais citados:
| Plano | Mensal | Anual (por mês) | Tarefas | Nós de nuvem | Limite de exportação |
|---|---|---|---|---|---|
| Free | $0 | $0 | 10 | Nenhum | 50 mil linhas/mês, 10 mil/exportação |
| Standard | $119 | ~ $100 | 100 | 3–6 | Ilimitado |
| Professional | $199 | ~ $151 | 250 | 20 | Ilimitado |
| Enterprise | Personalizado ($600–1.000+) | Personalizado | 750+ | 40+ | Ilimitado |
A camada gratuita é apenas local, sem nuvem, sem agendamento e sem templates. Para uso real em negócios, você está olhando para um mínimo de $119/mês.
Custos ocultos de extras
Aqui é onde o susto no orçamento aparece.
| Extra | Custo | O que você precisa saber |
|---|---|---|
| Proxies residenciais | $3 por GB | Necessários para sites com anti-bot |
| Resolução de CAPTCHA (Cloudflare) | $1,50 por 1.000 | Tentativas falhadas ainda consomem créditos |
| Resolução de CAPTCHA (outros) | $0,80 por 1.000 | Tentativas falhadas ainda consomem créditos |
| Templates por resultado | $0,001–$3 por 1.000 resultados | Templates premium não estão no plano base |
| Configuração de crawler personalizado | A partir de $399 (único) | A equipe do Octoparse monta seu scraper |
| Serviço de dados | A partir de $599 (único) | Entrega de dados completa |
Vale reforçar o problema dos créditos de CAPTCHA: a própria documentação do Octoparse confirma que . Se forem necessárias 3 tentativas para resolver um único CAPTCHA, você paga pelas 3.
Análises independentes estimam que os custos de extras aumentam a conta base em 40–60%. Uma fatura mensal realista para uma equipe que faz scraping de verdade fica entre $200 e $400/mês, mesmo no plano Standard.
Esgotamento de créditos e dados duplicados
O Octoparse na própria central de ajuda. Rodar a mesma tarefa várias vezes acumula duplicados porque o Octoparse armazena os resultados de cada execução juntos, sem deduplicação automática. Créditos e banda são consumidos mesmo quando as páginas não retornam dados úteis.
Disputas de reembolso e cancelamento
Este é o ponto que explica a diferença entre as notas no Trustpilot e no Capterra. descrevem cobranças após tentativa de cancelamento ou pedidos de reembolso negados.
"Fui cobrado em $119 mesmo tendo tentado só uma vez e não funcionado, e a empresa recusou o reembolso." — avaliador do Trustpilot
"Fique atento: cancelar pelo site nem sempre cancela de fato, então você acaba sendo cobrado e depois eles não querem reembolsar o primeiro mês!" — avaliador do Trustpilot
A janela de reembolso de 5 dias recebeu críticas independentes: "Uma janela de avaliação de 5 dias para uma ferramenta de scraping que exige configuração de fluxo... não é uma política de reembolso. É uma formalidade."
Comparação do custo total de propriedade
Aqui está a tabela que nenhuma outra análise do Octoparse traz:
| Componente de custo | Octoparse Standard | Octoparse Professional | Thunderbit Free | Thunderbit Pro |
|---|---|---|---|---|
| Preço mensal base | $119 | $199 | $0 | $9/mês (anual) / $15/mês |
| Rotação de proxy/IP integrada | ❌ (extra, $3/GB) | ❌ (extra, $3/GB) | ✅ (scraping em nuvem) | ✅ |
| Tratamento de CAPTCHA | ❌ (extra, $0,80–$1,50/1K) | ❌ (extra) | ✅ (integrado) | ✅ |
| Exportação de dados (Excel, Sheets etc.) | Incluída | Incluída | ✅ Grátis | ✅ Grátis |
| Política de reembolso | ⚠️ Janela de 5 dias, contestada | ⚠️ Janela de 5 dias, contestada | — | — |
Octoparse vs. alternativas: comparação honesta lado a lado
Toda “análise do Octoparse” concorrente o compara com exatamente uma alternativa — o próprio produto deles. Aqui está a comparação multidimensional que realmente ajuda na decisão.
| Dimensão | Octoparse | ParseHub | Apify | Bright Data | Thunderbit |
|---|---|---|---|---|---|
| Complexidade de configuração | Média (construtor visual) | Média (visual) | Alta (actors/código) | Alta (foco em desenvolvedores) | Baixa (IA em 2 cliques) |
| Extração com IA | ❌ Baseada em regras | ❌ Baseada em regras | Parcial (actors) | ❌ | ✅ IA sugere campos |
| Lida com mudanças de layout | ❌ Reconstrução manual | ❌ Reconstrução manual | Varia | ❌ | ✅ IA relê a página |
| Velocidade do scraping em nuvem | Moderada | Lenta | Rápida | Rápida | Rápida (50 páginas em paralelo) |
| Anti-bot/Cloudflare | ⚠️ Proxies extras | ⚠️ Limitado | ✅ Proxy integrado | ✅ Avançado | ✅ Modos cloud + navegador |
| Utilidade do plano gratuito | Limitada (10 tarefas, só local) | Teste de 14 dias | $5 grátis/mês | Sem plano grátis | 6 páginas grátis |
| Melhor para | Raspagens recorrentes de médio porte | Raspagens simples e pontuais | Desenvolvedores / automação | Pipelines de dados corporativos | Usuários de negócios / extração rápida |
Octoparse vs. ParseHub
Ambos são scrapers visuais, sem código, com interfaces parecidas. O ParseHub roda em um motor Chromium completo, o que lida com conteúdo renderizado em JavaScript (React, Angular, Vue) de forma mais confiável. Ele também inclui rotação de IP nos planos pagos — sem o extra de $3/GB.
O problema: o ParseHub é 2,5x mais caro na entrada ($189/mês vs. ~ $119/mês), não tem nenhum template pronto (contra mais de 469 do Octoparse) e tem um volume de avaliações bem menor (16 no Capterra contra 106). Um usuário relatou que ele "consumia todo o meu CPU e RAM (16GB)".
Nenhum dos dois usa IA para extração — ambos são baseados em regras e quebram quando os layouts mudam.
Octoparse vs. Apify
Apify é uma ferramenta fundamentalmente diferente. É voltada para desenvolvedores, construída em torno de "Actors" (módulos prontos ou personalizados em código), com mais de 6.000 Actors no marketplace. É totalmente baseada em nuvem — sem aplicativo desktop — e suporta código personalizado em JavaScript e Python.
O Apify supera o Octoparse em todas as notas do Capterra (Facilidade de uso: 4,7 vs. 4,4; Funcionalidade: 4,7 vs. 4,5; Custo-benefício: 4,6 vs. 4,4), com 4x mais volume de avaliações (427 vs. 106). O plano gratuito oferece $5/mês em créditos da plataforma com acesso total à nuvem — muito mais útil do que o plano gratuito local do Octoparse.
O problema: o Apify não é para usuários sem perfil técnico. Se você não lê código ou não tem um desenvolvedor na equipe, ele não é a melhor escolha.
Octoparse vs. Bright Data
Bright Data é infraestrutura de dados de nível corporativo: mais de 150 milhões de IPs residenciais em 195 países, certificações SOC2/ISO 27001, mais de 120 APIs de scraping mantidas. Ele conquistou a nota perfeita de 10,0/10 do G2 em coleta de dados.
Só que é outra faixa de investimento. O uso relevante começa em $499/mês (plano Growth), tornando-o 3–5x mais caro que o Octoparse. Para a maioria das equipes pequenas, isso será exagero.
Octoparse vs. Thunderbit
A Thunderbit é o que construímos na para resolver exatamente os problemas descritos acima. É uma com IA. Você clica em "AI Suggest Fields", a IA lê a página e sugere a estrutura das colunas, e depois você clica em "Scrape". Dois cliques. Pronto.
Principais diferenças:
- Sem fluxos para construir ou manter. A IA lê a página do zero a cada vez — sem seletores frágeis que quebram quando o site atualiza.
- Lida automaticamente com paginação e subpáginas. Paginação com clique e rolagem infinita funcionam sem configuração manual de loop. A raspagem de subpáginas com um clique enriquece a tabela com dados de páginas de detalhe.
- Scraping em nuvem e no navegador. O modo em nuvem processa 50 páginas em paralelo para sites públicos. O modo navegador roda na sua sessão do Chrome para sites que exigem login — sem precisar comprar proxies separados.
- Exportação gratuita. Excel, Google Sheets, Airtable, Notion — .
A Thunderbit foi criada para usuários de negócios sem perfil técnico que querem dados rápido, sem manter uma infraestrutura de scraping.
Estrutura de decisão: quando usar o Octoparse e quando usar outra solução
As discussões em fóruns mostram que os usuários não estão apenas perguntando "O Octoparse é bom?" — estão perguntando "O Octoparse é a ferramenta certa para O MEU caso?" Aqui vai a orientação baseada em cenário que nenhuma outra análise oferece.
Use o Octoparse se...
- Você precisa de extração agendada na nuvem em sites estáveis e bem estruturados
- Está disposto a investir 15–20+ horas aprendendo o construtor visual de fluxo de trabalho
- Extrai dados de alguns sites populares cobertos por templates (Amazon, Google Maps)
- Aceita a realidade dos custos extras (custo efetivo de $200–400/mês para uso sério)
Use a Thunderbit em vez disso se...
- Você é um usuário de negócios sem perfil técnico (vendas, ecommerce, marketing)
- Quer extração sugerida por IA sem montar ou manter fluxos de trabalho
- Extrai sites variados ou de cauda longa, com layouts diferentes entre páginas
- Precisa enriquecer subpáginas com um clique
- Quer exportar gratuitamente para Excel, Google Sheets, Airtable ou Notion
- Precisa extrair sites com login (o scraping no navegador da Thunderbit usa sua sessão)
Use Apify ou Bright Data se...
- Você é desenvolvedor ou tem recursos de desenvolvimento na equipe
- Precisa de infraestrutura de proxy em escala corporativa
- Está confortável com automação baseada em código ou Actors
- O bypass de anti-bot em escala é crítico
Crie um scraper personalizado se...
- Você tem habilidades em Python e precisa de controle total
- Performance importa (scripts personalizados podem ser 3–5x mais rápidos que ferramentas sem código)
- Você extrai repetidamente de uma única fonte e quer máxima personalização
Um usuário em fórum resumiu sem rodeios: "Fui aprender a fazer meu próprio webscraper e o meu é muito melhor."
Contrate um freelancer se...
- Você tem um projeto pontual com requisitos complexos de anti-bot ($500–$5.000 é o típico, no Upwork)
- Não tem tempo para aprender nenhuma ferramenta e precisa de resultado rápido
Como a Thunderbit resolve os principais problemas do Octoparse
Isto não é uma propaganda genérica. Cada ponto abaixo mapeia diretamente para um modo de falha que documentei acima.
Extração com IA: sem fluxos para construir ou manter
Clique em "AI Suggest Fields" e a IA lê a página, sugerindo colunas e tipos de dados. Clique em "Scrape" — pronto em 2 cliques. Sem seletores XPath, sem depuração de fluxo, sem manutenção quando o layout muda. Se quiser entender melhor como isso funciona na prática, veja nosso .
Adaptação automática ao layout
A IA da Thunderbit relê a página do zero a cada raspagem. Não existem seletores frágeis que quebrem quando o site atualiza o front-end. Isso é especialmente útil para sites de cauda longa e páginas de nicho com layouts não padronizados — exatamente os cenários em que a abordagem baseada em XPath do Octoparse mais falha.
Paginação e raspagem de subpáginas integradas
A Thunderbit lida com paginação por clique e rolagem infinita sem configuração manual de loop. A raspagem de subpáginas com um clique permite que a IA visite cada página de detalhe e enriqueça a tabela automaticamente — sem lógica de workflow. Para saber como isso se compara a outras ferramentas, veja nosso ranking de .
Opções de scraping na nuvem e no navegador
O scraping em nuvem para sites públicos processa 50 páginas em paralelo, com mais rapidez. O scraping no navegador para sites que exigem login roda na sua própria sessão do Chrome — o site vê seus cookies e sua sessão reais, não um bot de datacenter. Não há necessidade de comprar proxies separados.
Exportação gratuita para suas ferramentas
Exporte para Excel, Google Sheets, Airtable e Notion — totalmente grátis. Baixe como CSV ou JSON. Não há paywall para tirar seus dados da ferramenta. Você também pode ou em poucos cliques.
Veredicto final: o Octoparse vale a pena?
O Octoparse é uma ferramenta competente — para um tipo específico de usuário. Se você precisa de extração agendada na nuvem de sites estáveis e bem estruturados, e está disposto a investir tempo para aprender o construtor de fluxos e manter as tarefas quando os sites mudarem, ele pode funcionar. A biblioteca de templates é um diferencial real para sites populares.
Mas os custos ocultos são reais. Extras de proxy, créditos para CAPTCHA (inclusive em tentativas falhadas), consumo de créditos com dados duplicados e uma janela de reembolso de 5 dias que mal chega a ser uma política — tudo isso se soma rapidamente. As disputas de cobrança documentadas no Trustpilot são um sinal de alerta sério para qualquer comprador empresarial. E o problema das avaliações incentivadas significa que você não pode confiar nas notas que vê na maioria das plataformas.
Para usuários de negócios sem perfil técnico — equipes de vendas captando leads, operações de ecommerce monitorando preços, equipes de marketing coletando dados da concorrência — a curva de aprendizado e o custo de manutenção do Octoparse são difíceis de justificar. As 15–20 horas para chegar ao básico, as quebras de fluxo quando os sites atualizam, as falhas silenciosas na paginação — são horas que poderiam ser usadas em trabalho de verdade.
É por isso que construímos a Thunderbit do jeito que construímos: com IA, extração em 2 cliques, sem fluxos para manter e exportação gratuita.
Não é a ferramenta certa para todo cenário. Se você é desenvolvedor construindo um pipeline de dados em produção, vale olhar para Apify ou para um scraper personalizado. Mas, para o usuário de negócios que só precisa de dados de uma página web — de forma confiável, rápida e sem curva de aprendizado — é a solução que eu escolheria.
Experimente a gratuitamente ou confira os para comparar planos. E, se quiser ver na prática, o tem tutoriais para casos de uso comuns.
Perguntas frequentes
O Octoparse é gratuito?
Sim, o Octoparse tem um plano gratuito — mas ele é limitado a 10 tarefas, 2 execuções locais simultâneas, sem extração em nuvem, sem agendamento e sem templates. A exportação fica limitada a 10.000 linhas por exportação e 50.000 registros por mês. Para qualquer uso empresarial real, você vai precisar de um plano pago a partir de $119/mês.
O Octoparse é seguro e legal de usar?
Extrair dados publicamente disponíveis é, em geral, legal, mas você deve sempre verificar os Termos de Serviço e o robots.txt do site-alvo. O Octoparse, por si só, é um software legítimo. A maior preocupação para muitos usuários é a transparência na cobrança — vários avaliadores relatam dificuldade para cancelar assinaturas e conseguir reembolso. Antes de assinar, entenda bem a janela de reembolso de 5 dias e a taxa de ~4% da processadora aplicada a reembolsos aprovados.
O Octoparse funciona no Mac?
Sim, o Octoparse agora oferece versão para macOS (compatível com Intel e Apple Silicon). No entanto, algumas fontes independentes sugerem que a versão para Mac pode ter menos recursos que a versão para Windows — historicamente, o construtor visual era exclusivo do Windows, e usuários de Mac ficavam limitados ao painel em nuvem. Confira o conjunto de recursos atual antes de decidir.
Qual é a melhor alternativa ao Octoparse?
Depende do seu caso. Para usuários de negócios sem perfil técnico que querem extração rápida com IA: . Para desenvolvedores que querem uma plataforma baseada em código com um grande marketplace de Actors: Apify. Para equipes corporativas que precisam de infraestrutura avançada de proxy: Bright Data. Para máximo controle com Python: crie um scraper personalizado com Scrapy ou Playwright. Para um projeto pontual: contrate um freelancer no Upwork.
Por que as avaliações do Octoparse são tão diferentes entre plataformas?
A diferença entre as notas do Octoparse no G2/Capterra (~4,7) e no Trustpilot (~3,9) é amplamente explicada por avaliações incentivadas. Há registros de o Octoparse solicitar avaliações pagas de 5 estrelas no Trustpilot, e muitas avaliações do Capterra estão marcadas como incentivadas. As notas sem filtro do Trustpilot — e as reclamações específicas sobre cobrança e reembolso lá — são um sinal mais confiável da experiência real do usuário.
Saiba mais