A busca por dados online nunca esteve tão acirrada, e em 2025, o está no centro das atenções para quem quer extrair informações de forma inteligente e sem dor de cabeça. Seja você do time de vendas, do e-commerce ou só um apaixonado por dados como eu, já percebeu que raspador web não é mais só “pegar dados”—é fazer isso rápido, em grande escala e sem correr o risco de tomar bloqueio de IP. Com o mercado de raspador web projetado para saltar de US$ 7,48 bilhões em 2025 para quase US$ 38,4 bilhões até 2034 (), a concorrência está pegando fogo.
Mas aí vem o desafio: a web de hoje é um verdadeiro labirinto de conteúdos dinâmicos, armadilhas anti-bot e layouts que mudam toda hora. Já vi muito raspador quebrar a cara—geralmente por ignorar boas práticas ou subestimar o quanto as defesas anti-scraping evoluíram. Então bora mergulhar nas melhores práticas para garantir eficiência no raspador web com Node.js, com histórias reais, um toque de humor e dicas que funcionam no dia a dia.
Por que Node.js é a escolha certa para raspador web eficiente?
Se você já tentou raspar centenas (ou milhares) de páginas de uma vez, sabe que velocidade e concorrência são tudo. É aí que o Node.js brilha. Seu modelo assíncrono e não bloqueante de I/O foi feito para lidar com um volume gigante de requisições ao mesmo tempo—pensa nele como o multitarefa raiz da web (). Enquanto outras linguagens ficam esperando cada requisição terminar, o Node.js segue rodando seu event loop, gerenciando tudo como um verdadeiro malabarista.
Já vi Node.js deixar Python e Java para trás em cenários que exigem atualização em tempo real e extração em larga escala, principalmente quando os sites são cheios de JavaScript. Na real, já usam Node.js para backend e automação, tornando ele a tecnologia web mais popular do planeta.
Node.js vs. Outros frameworks de raspador web
Vamos comparar rapidinho como o Node.js se sai frente aos concorrentes:
| Framework | Pontos Fortes | Pontos Fracos | Melhores Usos |
|---|---|---|---|
| Node.js | Assíncrono, ótimo para concorrência, ecossistema npm gigante, JS nativo para sites dinâmicos | Pode consumir muita memória, callback hell (se não usar async/await) | Scraping em tempo real, sites JS pesados, microsserviços escaláveis |
| Python | Muitas libs (BeautifulSoup, Scrapy), sintaxe simples | Mais lento para alta concorrência, dificuldade com sites JS | HTML estático, pesquisa, prototipagem |
| Java | Tipagem forte, robusto para empresas | Verboso, menos flexível para scripts rápidos | Scraping em larga escala, uso corporativo |
| Go | Rápido, concorrência eficiente | Ecossistema menor, curva de aprendizado | Scraping de alta performance, baixa latência |
Para a maioria das empresas, Node.js é o equilíbrio perfeito: rápido, flexível e feito para a web moderna cheia de JavaScript ().
Como montar um ambiente robusto de raspador web com Node.js
Um raspador web de respeito começa com uma base bem feita. Olha como costumo organizar:
- Estrutura do projeto: Deixe tudo modular. Use pastas como
/src,/libse/config. Guarde informações sensíveis (chaves de API, proxies) em variáveis de ambiente comdotenv(). - Cliente HTTP: Use , ou para as requisições.
- Parsing de HTML: para HTML estático, ou Playwright para conteúdo dinâmico.
- Utilitários: Use para manipular dados, e ou para validação.
- Testes e lint: Mocha para testes, ESLint para manter o código redondo ().
Bibliotecas essenciais para raspador web com Node.js
- axios/got/node-fetch: Para requisições HTTP. Gosto do Axios pelo suporte a Promises e JSON nativo.
- Cheerio: Parser HTML rápido, estilo jQuery. Perfeito para páginas estáticas—processa em cerca de 0,5s ().
- Puppeteer/Playwright: Automação de navegador headless para sites dinâmicos. Mais lento (~4s por página), mas indispensável para conteúdo carregado via JavaScript ().
- dotenv: Para gerenciar variáveis de ambiente.
- csv-writer/jsonfile: Para exportar dados.
Como evitar armadilhas comuns no raspador web com Node.js
Já perdi as contas de quantos raspadores foram bloqueados, travaram ou geraram dados bagunçados. Fique ligado em:
- Ignorar robots.txt e Termos de Uso: Sempre confira antes de raspar. Ignorar pode dar ban no IP ou até dor de cabeça jurídica ().
- Sobrecarregar servidores: Não mande requisições em massa. Use delays aleatórios (1–3 segundos), controle a concorrência e evite agir como um robô acelerado ().
- Não tratar erros: Sempre envolva requisições em try/catch, trate erros HTTP e registre falhas. Refaça tentativas com backoff exponencial ().
- Esquecer headers de requisição: Use User-Agent realista e faça rotação. Adicione Accept-Language, Referer e outros headers para simular um navegador de verdade ().
Como driblar mecanismos anti-scraping
Sites modernos estão cheios de defesas anti-bot. Veja como contornar:
- Rotação de proxies/IPs: Use um pool de proxies e alterne IPs para evitar bloqueios ().
- Headers aleatórios: Altere User-Agent, Accept-Language e outros headers a cada requisição.
- Stealth em browser headless: Use plugins como
puppeteer-extra-plugin-stealthpara mascarar a automação. - Simule comportamento humano: Adicione delays aleatórios, movimentos de mouse, rolagem e até erros de digitação ().
Simulando comportamento humano em raspadores Node.js
Aqui a coisa fica divertida (e um pouco bizarra). Em vez de clicar e rolar tudo de uma vez, programe seu raspador para:
- Esperar intervalos aleatórios entre ações (
await page.waitForTimeout(randomDelay)) - Mover o mouse em pequenos movimentos irregulares (
page.mouse.move(x, y)) - Digitar com delays e até alguns erros (
page.type(selector, text, {delay: random(100,200)})) - Rolar a página de forma não linear
Essas técnicas aumentam muito as chances de sucesso em sites protegidos ().
Simplificando extração de dados complexos com Thunderbit
Agora, vamos ao que interessa: raspador web dá trabalho. Mas não precisa ser assim. Por isso criamos o .
Thunderbit é uma extensão Chrome de raspador web com IA que permite extrair dados de qualquer site usando linguagem natural. Basta clicar em “Sugerir Campos com IA”, deixar a IA identificar o que está na página e clicar em “Raspar”. É como ter um estagiário que nunca dorme e não pede aumento.
Melhor ainda, o Thunderbit oferece uma API para integrar direto aos seus fluxos Node.js. Em vez de escrever milhares de linhas de código, deixa o Thunderbit fazer o trabalho pesado—conteúdo dinâmico, subpáginas, paginação e tudo mais. Você só precisa puxar os dados estruturados (CSV, JSON ou direto para Google Sheets, Airtable, Notion) e seguir com seu dia ().
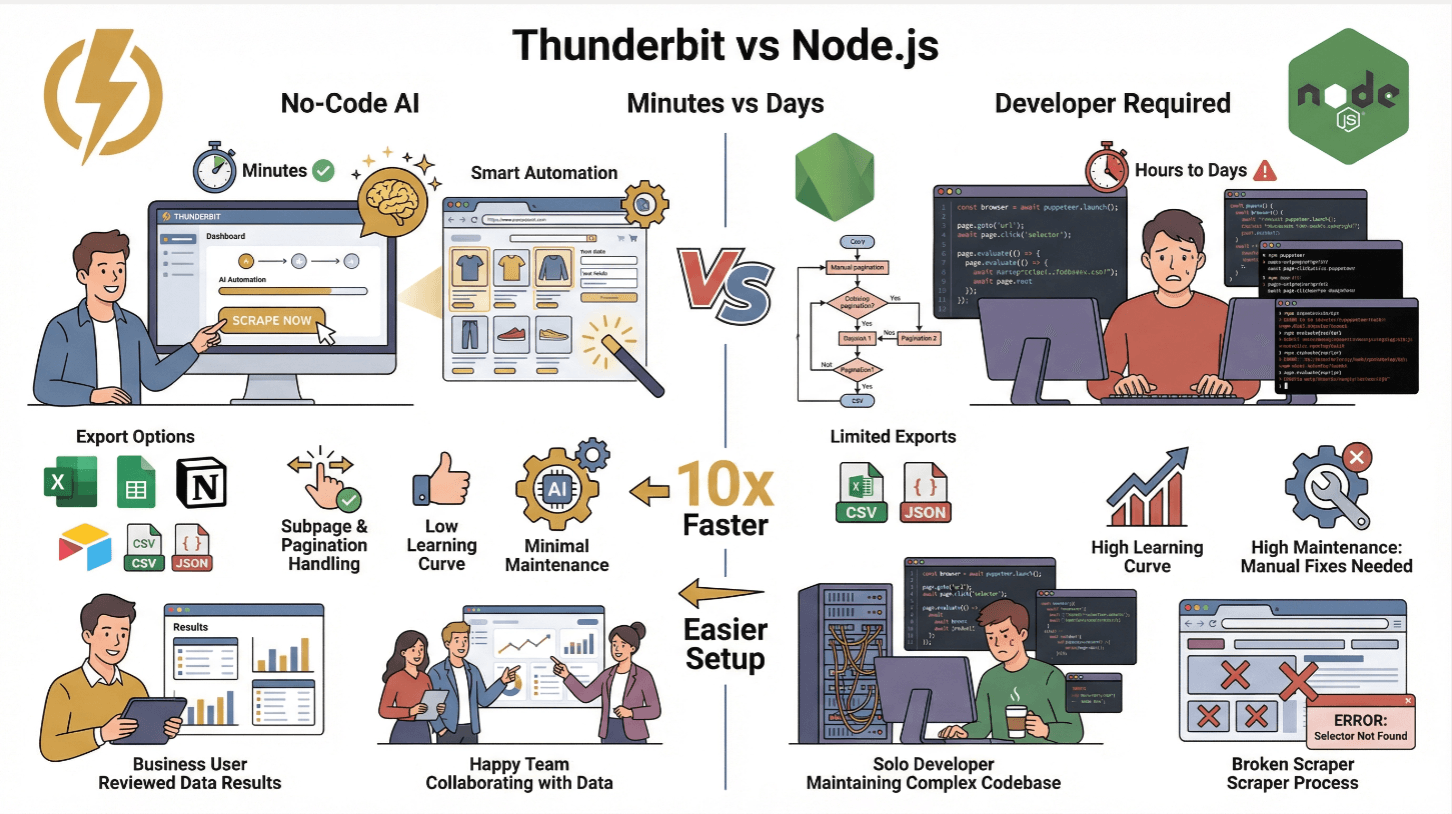
Thunderbit vs. Scraping tradicional com Node.js
| Recurso | Thunderbit | Node.js Tradicional |
|---|---|---|
| Tempo de configuração | Minutos (sem código) | Horas ou dias (codificação, testes) |
| Lida com conteúdo dinâmico | Sim (IA + navegador) | Sim (com Puppeteer/Playwright) |
| Subpáginas & Paginação | 1 clique | Requer codificação manual |
| Exportação de dados | Excel, Sheets, Notion, Airtable, CSV, JSON | CSV/JSON (código próprio) |
| Curva de aprendizado | Baixa (usuários de negócios) | Alta (desenvolvedores) |
| Manutenção | Mínima (IA se adapta) | Alta (ajustes manuais para mudanças nos sites) |
Thunderbit é perfeito para equipes não técnicas ou para quem quer pular a parte chata e focar nos insights. Para usuários avançados, a API do Thunderbit permite automação em larga escala ().
Combinando Cheerio e Puppeteer para conteúdo dinâmico
Essa é minha dupla favorita no Node.js. O fluxo é assim:
- Use o Puppeteer para carregar a página e executar o JavaScript (espere por
networkidlepara garantir que tudo foi carregado). - Pegue o HTML com
await page.content(). - Parseie com Cheerio: Jogue o HTML no Cheerio para uma extração rápida, estilo jQuery.
Essa abordagem híbrida junta o melhor dos dois mundos: o poder do Puppeteer para conteúdo dinâmico e a velocidade do Cheerio para parsing ().
Dica de performance: Selecione só os elementos que precisa. O Cheerio carrega todo o DOM na memória, então evite seletores amplos e faça cache dos resultados se for raspar as mesmas páginas várias vezes ().
Otimizando parsing de HTML e extração de dados
- Use seletores específicos: Fuja do
$('body *')—vá direto ao ponto. - Faça streaming de páginas grandes: Para HTMLs enormes, divida o trabalho ou use streaming.
- Cache do HTML renderizado: Se revisitar URLs, armazene o HTML para evitar requisições repetidas.
- Valide e limpe os dados: Use bibliotecas de validação para garantir qualidade ().
Como escalar e implantar raspadores Node.js na nuvem
Vai raspar em grande escala? Hora de subir para a nuvem.
- Dockerize seu raspador: Escreva um
Dockerfile, copie o código, instale dependências e defina o entrypoint. - Implante na nuvem: Use AWS EC2, Google Cloud Compute ou Azure VMs para tarefas simples. Para escala de verdade, use Kubernetes ou serviços gerenciados como AWS ECS/EKS, Google Cloud Run ou Azure Kubernetes Service ().
- Orquestre com Kubernetes: Rode múltiplos pods, escale conforme a demanda e distribua URLs com load balancers.
- Agende tarefas: Use schedulers na nuvem (CloudWatch Events, Cloud Scheduler) ou cron jobs para rodar scrapes em intervalos.
Em um caso real, aumentar de 5 para 10 pods no Kubernetes reduziu o tempo de scraping de 400 páginas de minutos para menos de um minuto ().
Monitoramento e autoescalonamento da infraestrutura de scraping
- Logs: Envie logs para CloudWatch, Stackdriver ou Datadog. Configure alertas para erros ou lentidão.
- Health checks: Use Prometheus e Grafana para métricas como páginas raspadas por minuto, taxas de erro e saúde dos pods.
- Autoescalonamento: Configure o HPA do Kubernetes para escalar pods conforme CPU ou número de requisições.
Sempre implemente tentativas com backoff exponencial para lidar com falhas temporárias ou bloqueios.
Boas práticas para armazenamento e pós-processamento dos dados
Depois de raspar, é hora de armazenar e tratar os dados:
- Tarefas pequenas: Exporte para CSV, JSON ou envie para Google Sheets, Airtable ou Notion (Thunderbit faz isso nativamente).
- Tarefas grandes: Use SQL (MySQL/PostgreSQL) para dados estruturados, ou NoSQL (MongoDB, DynamoDB) para esquemas flexíveis ().
- Armazenamento em nuvem: S3 ou Google Cloud Storage para arquivos brutos e backups.
- Limpeza de dados: Sempre valide campos, normalize formatos (datas, números) e remova duplicatas. Use validadores de esquema para garantir qualidade ().
Guarde tanto os dados brutos quanto os limpos—você pode precisar reprocessar ou depurar no futuro.
Conclusão: Resumo das melhores práticas para raspador web eficiente com Node.js
Pra fechar, anota aí os pontos principais:
- Aproveite o poder assíncrono do Node.js para scraping massivo e concorrente—especialmente em sites cheios de JavaScript.
- Combine as ferramentas certas: Use axios/got para requisições, Cheerio para HTML estático, Puppeteer para conteúdo dinâmico e misture para mais velocidade e flexibilidade.
- Evite armadilhas anti-bot: Rode proxies e headers, simule comportamento humano e respeite o robots.txt.
- Simplifique com Thunderbit: Para negócios ou prototipagem rápida, o permite extrair dados complexos com IA e integrar via API ao seu stack Node.js.
- Implemente em escala: Dockerize, orquestre com Kubernetes e monitore tudo para garantir confiabilidade.
- Armazene e limpe seus dados: Escolha o armazenamento ideal e sempre valide antes de usar.
A web não está ficando mais simples, mas com essas práticas, seus raspadores Node.js podem ser rápidos, confiáveis e sempre um passo à frente das defesas anti-bot. E se cansar de debugar seletores de madrugada, lembra: a IA do Thunderbit nunca dorme.
Quer aprender mais? Dá uma olhada no para conteúdos aprofundados ou experimente a para ver como o scraping pode ser fácil.
Perguntas Frequentes
1. Por que o Node.js é especialmente bom para raspador web em 2025?
O modelo assíncrono e orientado a eventos do Node.js permite lidar com milhares de requisições ao mesmo tempo, ideal para raspar grandes volumes de dados ou atualizações em tempo real. Seu ecossistema npm gigante e suporte nativo a JavaScript são perfeitos para sites modernos e dinâmicos ().
2. Como evitar bloqueios ao raspar com Node.js?
Use proxies rotativos, altere headers das requisições, controle o ritmo com delays aleatórios e simule comportamento humano (movimento do mouse, rolagem, digitação) com ferramentas como Puppeteer. Sempre respeite o robots.txt e os termos do site ().
3. Quando usar Cheerio ou Puppeteer no raspador Node.js?
Use Cheerio para parsing rápido de HTML estático (quando os dados estão no HTML bruto). Use Puppeteer para sites que carregam conteúdo dinamicamente via JavaScript. Para melhores resultados, use Puppeteer para renderizar a página e Cheerio para extrair os dados ().
4. Como o Thunderbit simplifica o raspador web com Node.js?
O Thunderbit permite extrair dados estruturados de qualquer site usando IA e comandos em linguagem natural—sem precisar programar. Ele lida com conteúdo dinâmico, subpáginas e paginação, e oferece API para integração com Node.js. Os dados podem ser exportados direto para Excel, Google Sheets, Airtable ou Notion ().
5. Qual a melhor forma de escalar e monitorar raspadores Node.js na nuvem?
Dockerize seu raspador, implante em Kubernetes ou serviços gerenciados na nuvem e use autoescalonamento para lidar com picos de demanda. Monitore logs e métricas com ferramentas como CloudWatch ou Prometheus e configure alertas para erros ou lentidão ().
Pronto para levar seu raspador web para outro nível? Teste o Thunderbit e garanta que seus raspadores sejam rápidos, discretos e sempre um passo à frente.
Saiba mais