
Todo tutorial de fetch em Node.js ensina você a fazer await fetch(url) e encerra o assunto por aí. Só que, no seu app em produção, um erro 500 é engolido em silêncio, uma requisição fica pendurada por 90 segundos sem timeout, e você perde uma sexta-feira à noite tentando depurar algo que deveria ser óbvio.
Tenho construído ferramentas internas e pipelines de dados na há algum tempo, e posso dizer com segurança: a distância entre “o fetch funciona no meu tutorial” e “o fetch funciona em produção” é onde mora a maior parte da dor. Um desenvolvedor no Reddit resumiu isso perfeitamente: “when you go into production, you realise you need something more resilient than the native fetch.”
Outro confessou: “Worked for 3 years as a web developer, TIL the fetch API's catch block is NOT for HTTP errors.” Este guia cobre as cinco coisas que a maioria dos tutoriais deixa de fora — a armadilha dos erros, timeouts com AbortController, lógica de retry, reutilização de conexão e quando ir além do fetch para extração estruturada de dados. Se você já teve uma chamada fetch falhando em silêncio em produção, este texto é para você.
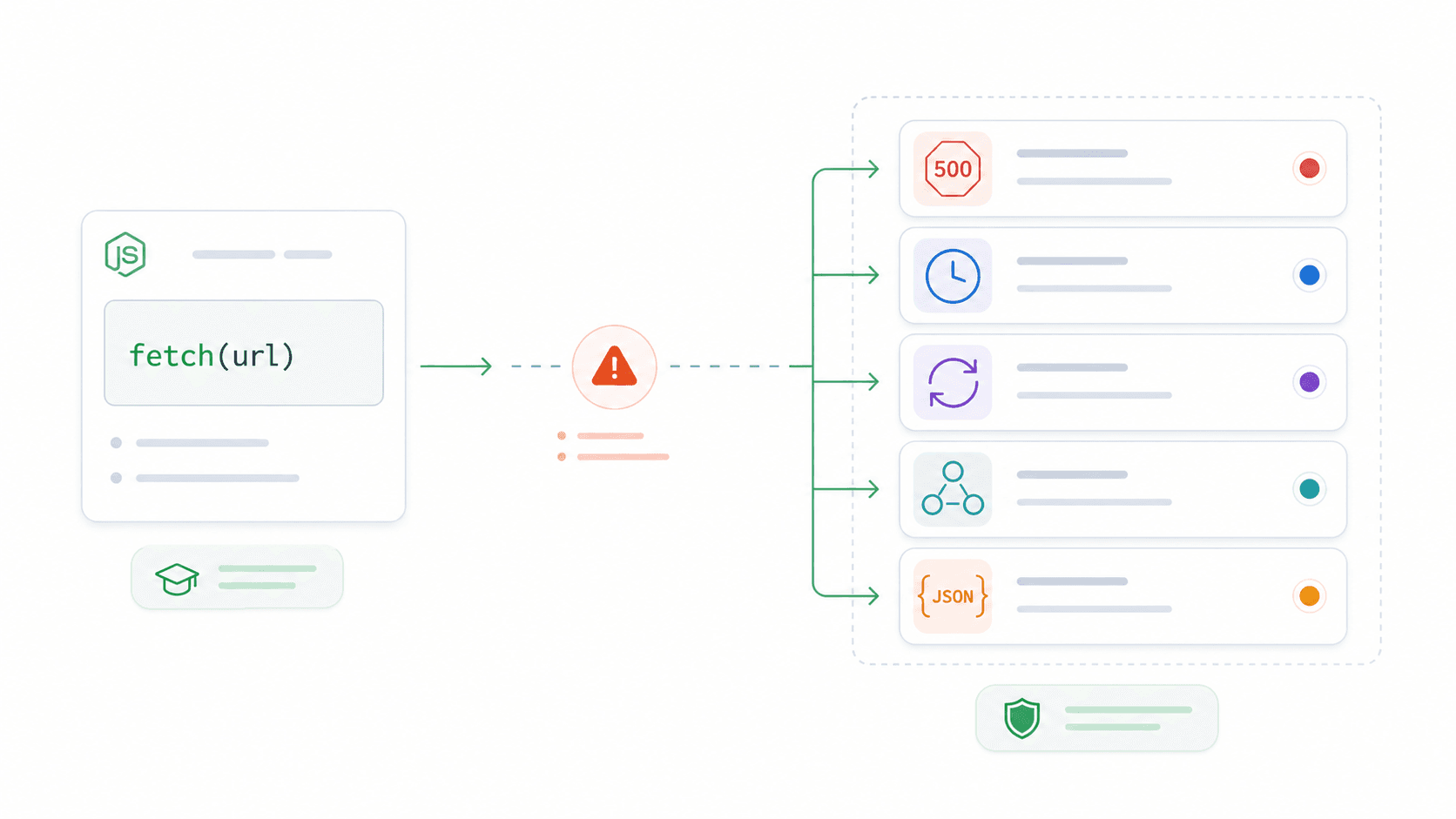
O que é a API Fetch do Node.js?
A API Fetch do Node.js é a forma nativa e compatível com navegador de fazer requisições HTTP (GET, POST, PUT, DELETE etc.) a partir do Node.js — sem instalar Axios, node-fetch ou qualquer outro pacote. Se você já usou fetch() no navegador, já conhece a sintaxe. Agora a mesma API funciona no servidor.
Aqui vai uma versão resumida da evolução:
| Marco | Versão do Node | O que aconteceu |
|---|---|---|
| Flag experimental do fetch | v17.5.0 / v16.15.0 | fetch adicionado atrás de --experimental-fetch |
| Fetch global padrão | v18.0.0 | fetch experimental disponível globalmente, com Undici Undici |
| Fetch estável | v21.0.0 | Deixou de ser experimental |
| Base de produção em 2026 | v22 LTS / v24 LTS | Recomendado para produção; v20 agora está EOL |
Nos bastidores, o fetch do Node é alimentado por Undici — um cliente HTTP de alta performance criado especificamente para Node.js. Ele não depende do antigo módulo http embutido. Na prática, isso significa que você ganha uma API HTTP moderna, baseada em Promise, que funciona do mesmo jeito no código do navegador, no backend Express, em funções serverless e em scripts de linha de comando.
Por que a API Fetch do Node.js importa para os seus projetos
Antes do Node 18, todo projeto novo começava com o mesmo ritual: npm install axios ou npm install node-fetch. Em 2026, se o seu projeto roda em um Node LTS mantido, requisições HTTP básicas não exigem nenhuma dependência. Isso é uma vitória real para o tamanho do bundle, para a segurança da cadeia de suprimentos e para o onboarding — desenvolvedores front-end e back-end finalmente compartilham a mesma API.
Aqui é onde o fetch nativo brilha:
| Cenário | Por que o fetch nativo funciona bem | Cuidado em produção |
|---|---|---|
| Backend Express/Fastify chamando APIs REST | async/await familiar, sem dependência | Adicione timeout e verificações de response.ok |
| Funções serverless (Lambda, Vercel etc.) | Menor superfície de cold start, sem instalação de pacote | Mantenha o timeout abaixo do limite máximo da plataforma |
| Scripts de CLI e automações | GET/POST simples, sem configuração do projeto | Adicione retry/backoff para APIs instáveis |
| Entrega ou encaminhamento de webhooks | Métodos e cabeçalhos HTTP padrão | Não faça retry às cegas em POSTs não idempotentes |
| Relatórios e dashboards | Bom para puxar JSON de APIs | Use paginação e pool de conexões em loops |
| Comunicação entre microservices | Funciona para chamadas HTTP internas simples | Considere Got ou o próprio Undici para retry, hooks ou HTTP/2 |
Para projetos novos em Node 22+, o fetch nativo é o padrão sensato — a menos que você saiba que precisa de recursos que ele não oferece (interceptadores, retry embutido, HTTP/2 etc.). Os números de download do npm mostram um cenário em transição: , mas grande parte disso é legado e dependências transitivas. , , e . A tendência é clara: o fetch nativo é a nova base, e clientes de terceiros ficam para necessidades específicas.
Fetch nativo vs node-fetch vs Axios vs Got vs Ky: a matriz de decisão de 2026
A pergunta mais comum que vejo em fóruns de desenvolvedores: “Qual cliente HTTP devo usar no Node.js?” Um usuário do Reddit resumiu bem: “why import a library…when the language/framework has functionality built in?” É um ponto justo — mas a resposta depende do que você precisa.
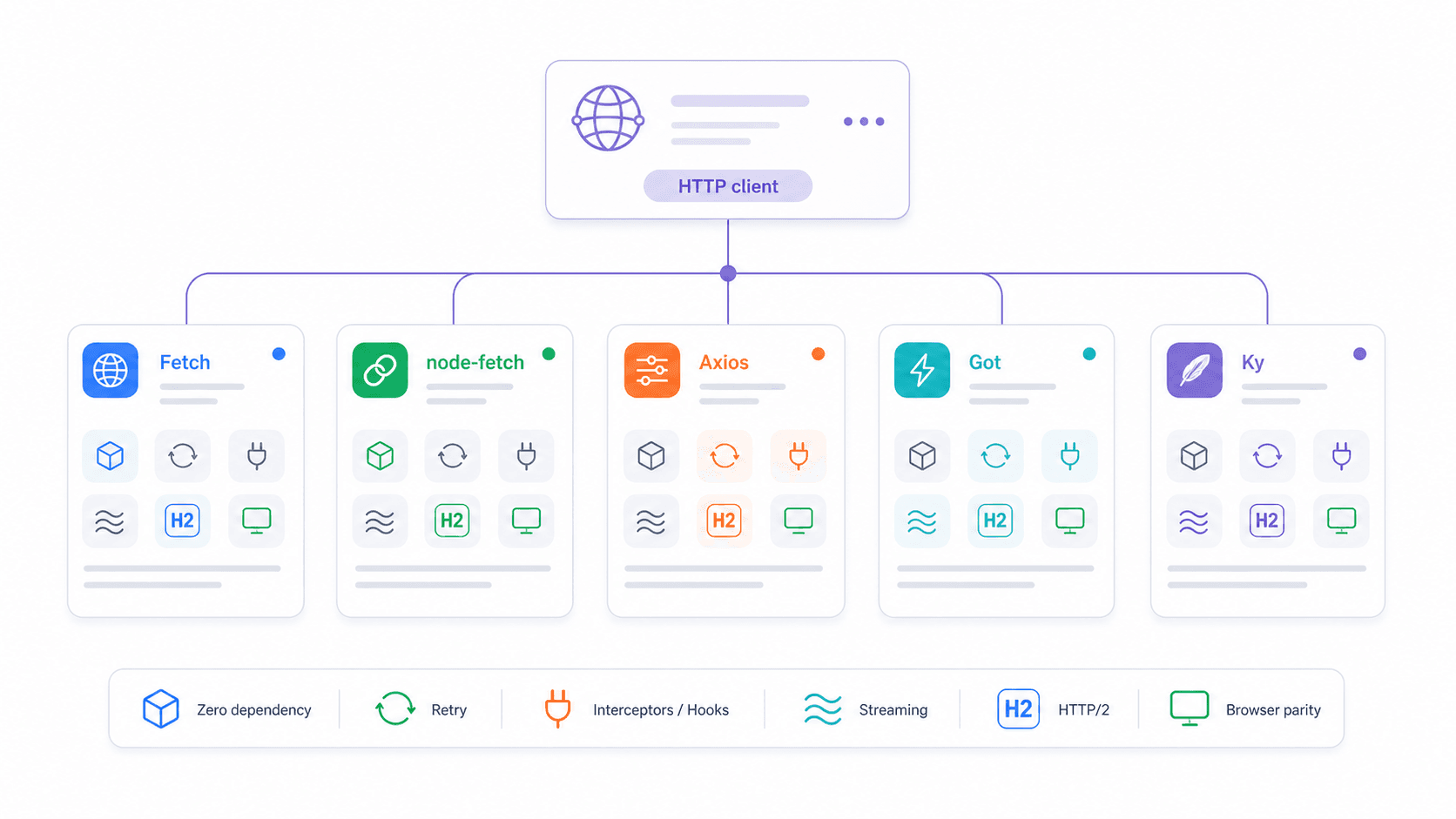
| Recurso | fetch nativo | node-fetch v3 | axios | got v15 | ky v2 |
|---|---|---|---|---|---|
| Versão do Node.js | ≥18 (recomendado 22/24 LTS) | ≥12.20 | Amplo | ≥22 | ≥22 |
| Instalação necessária | Não | Sim | Sim | Sim | Sim |
| Suporte ESM + CJS | Ambos (global) | Só ESM (v3) | Ambos | Só ESM | Só ESM |
| Rejeita automaticamente em 4xx/5xx | Não | Não | Sim | Sim | Sim |
| Retry embutido | Não | Não | Não | Sim | Sim |
| Interceptadores de requisição | Não | Não | Sim | Sim (hooks) | Sim (hooks) |
| Suporte a streaming | Web ReadableStream | Sim | Limitado | Streams nativas do Node, fortes | Baseado em fetch |
| Peso do bundle/instalação | 0 KB | ~107 KB, 3 deps | ~2,8 MB, 4 deps | ~355 KB, 12 deps | ~405 KB, 0 deps |
| Suporte a HTTP/2 | Via dispatcher do Undici | Não | Não | Sim | Não (wrapper de fetch) |
Uma nota rápida sobre a dor ESM/CJS: o node-fetch v3 é apenas ESM, o que quebrou muitos projetos que usavam require(). O fetch nativo é global — funciona tanto em arquivos CJS quanto ESM, sem malabarismos de importação. Se você está preso no node-fetch v2 por causa do CommonJS, o fetch nativo resolve isso de vez.
E sobre as preocupações iniciais de estabilidade: sim, houve bugs reais na implementação inicial do fetch no Node 18. Um desenvolvedor no Reddit comentou: “Had a wild bug with native node 18 fetch recently so had to convert our app.” Isso foi em 2023. Em 2026, com Node 22 e 24 LTS, esses problemas já foram resolvidos. O fetch nativo está pronto para produção.
Quando vale ficar com o fetch nativo
Use fetch nativo quando:
- Seu projeto roda em Node 22 LTS ou Node 24 LTS.
- As requisições são chamadas REST diretas (GET, POST, PUT, DELETE).
- Você aceita criar um pequeno wrapper para
response.ok, parsing de JSON, timeouts e retry. - Quer zero superfície de dependências e menos preocupação com supply chain.
- Valoriza paridade entre as APIs do navegador e do servidor.
- Está em ambientes serverless ou edge, onde APIs nativas são preferidas.
Quando Axios, Got ou Ky fazem mais sentido
Axios é a escolha certa quando o seu time depende de interceptadores de requisição/resposta (por exemplo, renovação automática de token de autenticação, cabeçalhos por tenant, logging centralizado), quando você quer rejeição padrão em erros HTTP ou quando precisa de compatibilidade com runtimes Node mais antigos.
Got foi feito para serviços Node de alto throughput que precisam de retry embutido, hooks, fases avançadas de timeout, streams, helpers de paginação, sockets Unix, fluxos com proxy/cache ou suporte a HTTP/2. É o canivete suíço do trabalho HTTP apenas em Node.
Ky é o ponto ideal se você gosta da simplicidade do fetch, mas quer menos boilerplate — ele adiciona retry, timeout, hooks e HTTPError em um pacote pequeno e sem dependências.
Como fazer requisições GET com a API Fetch do Node.js
Uma requisição GET com async/await fica assim:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts/1');
2const post = await response.json();
3console.log(post.title);
4// → "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"E a versão em cadeia com .then(), se você preferir:
1fetch('https://jsonplaceholder.typicode.com/posts/1')
2 .then(response => response.json())
3 .then(post => console.log(post.title))
4 .catch(error => console.error(error));As duas funcionam. Mas nenhuma delas ainda é segura para produção (já chegamos nisso).
Leitores de response que você precisa conhecer:
| Método | Quando usar |
|---|---|
response.json() | O servidor retorna JSON |
response.text() | O servidor retorna HTML, texto simples, CSV, Markdown |
response.arrayBuffer() | Você precisa de dados binários (imagens, arquivos) |
response.body | Você precisa de processamento em streaming/por blocos |
Um padrão melhor — que de fato verifica erros:
1async function getPost(id) {
2 const response = await fetch(`https://jsonplaceholder.typicode.com/posts/$\{id\}`);
3 if (!response.ok) {
4 throw new Error(`HTTP $\{response.status\} $\{response.statusText\}`);
5 }
6 return response.json();
7}
8const post = await getPost(1);
9console.log(post.title);Essa linha if (!response.ok) é a diferença entre um tutorial e código de produção. E isso nos leva à maior armadilha.
Como enviar requisições POST com a API Fetch do Node.js
Requisições POST seguem a mesma estrutura — você só define o método, os cabeçalhos e o corpo:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts', {
2 method: 'POST',
3 headers: {
4 'Content-Type': 'application/json',
5 },
6 body: JSON.stringify({
7 title: 'Guia do Node fetch',
8 body: 'Fetch em produção precisa de tratamento de erros.',
9 userId: 1,
10 }),
11});
12if (!response.ok) {
13 throw new Error(`HTTP $\{response.status\}`);
14}
15const created = await response.json();
16console.log(created.id); // → 101Enviando outros tipos de requisição (PUT, DELETE, PATCH)
PUT, PATCH e DELETE usam a mesma estrutura, mudando apenas o valor de method:
1// PUT — substituição completa
2await fetch('https://jsonplaceholder.typicode.com/posts/1', {
3 method: 'PUT',
4 headers: { 'Content-Type': 'application/json' },
5 body: JSON.stringify({ id: 1, title: 'Substituído', body: 'Substituição completa', userId: 1 }),
6});
7// PATCH — atualização parcial
8await fetch('https://jsonplaceholder.typicode.com/posts/1', {
9 method: 'PATCH',
10 headers: { 'Content-Type': 'application/json' },
11 body: JSON.stringify({ title: 'Atualização parcial' }),
12});
13// DELETE
14await fetch('https://jsonplaceholder.typicode.com/posts/1', {
15 method: 'DELETE',
16});A armadilha do body-parser no Express: Se você estiver enviando JSON para um servidor Express e req.body vier como undefined, a correção quase sempre é esta: use express.json(), não express.urlencoded(). O servidor precisa do middleware express.json() antes da rota para interpretar corpos com Content-Type: application/json. Essa é uma das perguntas mais comuns no sobre Express, e ela pega muita gente toda vez.
1import express from 'express';
2const app = express();
3app.use(express.json()); // ← É isso que você precisa para corpos JSON em POST
4app.post('/api/posts', (req, res) => {
5 res.json({ received: req.body });
6});A armadilha do fetch() que quebra apps em produção
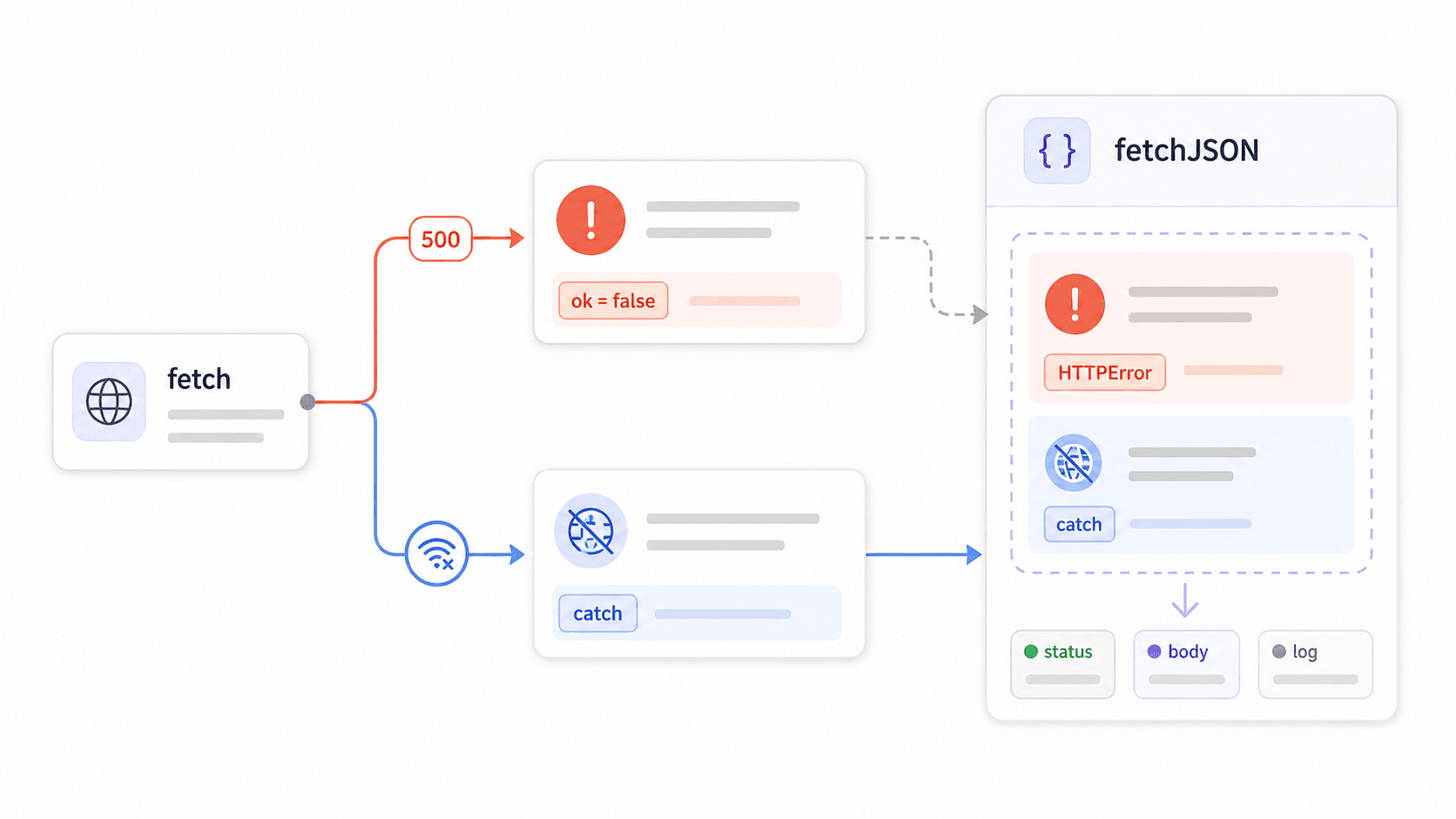
É daqui que vêm a maioria dos bugs de fetch em produção.
fetch() não rejeita a Promise em erros HTTP 4xx ou 5xx. Ele só rejeita em falhas de rede — erro de DNS, sem internet, requisições abortadas. Se o servidor retornar um 403 Forbidden ou um 500 Internal Server Error, o fetch considera isso uma resposta bem-sucedida. Seu bloco .catch() nunca roda. Seu try/catch nunca captura isso. Seu código simplesmente processa o que o servidor enviou.
deixa isso claro, mas a maioria dos tutoriais passa por cima. O resultado? Código assim parece correto, mas engole erros em silêncio:
1try {
2 const response = await fetch('https://api.example.com/private');
3 const data = await response.json(); // ← Isso roda até em um 403
4 console.log('Parece ter funcionado:', data);
5} catch (error) {
6 // Só falhas em nível de rede caem aqui
7 console.error('Capturado:', error);
8}Uma visão rápida do que cada padrão realmente captura:
| Padrão | Captura erros de rede | Captura 4xx/5xx | Faz parse de JSON com segurança | Reutilizável |
|---|---|---|---|---|
Bruto .then(res => res.json()) | Sim (via .catch()) | Não | Sem proteção de content-type | Não |
try/catch com await fetch() | Sim | Não | Sem proteção de content-type | Não |
if (!res.ok) manual por chamada | Sim | Sim | Depende de cada chamada | Parcial |
Wrapper fetchJSON() personalizado | Sim | Sim | Sim | Sim |
Crie um wrapper reutilizável fetchJSON()
Crie um wrapper. Importe em todo lugar. Pare de copiar e colar if (!response.ok) em cada arquivo:
1export class HTTPError extends Error {
2 constructor(message, { status, statusText, url, body }) {
3 super(message);
4 this.name = 'HTTPError';
5 this.status = status;
6 this.statusText = statusText;
7 this.url = url;
8 this.body = body;
9 }
10}
11export async function fetchJSON(url, options = {}) {
12 const response = await fetch(url, {
13 headers: {
14 Accept: 'application/json',
15 ...options.headers,
16 },
17 ...options,
18 });
19 const contentType = response.headers.get('content-type') || '';
20 const isJSON = contentType.includes('application/json');
21 const body = isJSON ? await response.json().catch(() => null) : await response.text();
22 if (!response.ok) {
23 throw new HTTPError(`HTTP $\{response.status\} $\{response.statusText\}`, {
24 status: response.status,
25 statusText: response.statusText,
26 url: response.url,
27 body,
28 });
29 }
30 return body;
31}Agora, quando o servidor retornar um 403:
1try {
2 const data = await fetchJSON('https://api.example.com/private');
3} catch (error) {
4 if (error instanceof HTTPError) {
5 console.error(`O servidor retornou $\{error.status\}:`, error.body);
6 } else {
7 console.error('Falha de rede ou outra falha:', error);
8 }
9}O erro carrega o código de status, o corpo da resposta e a URL — tudo o que você precisa para logs, alertas ou mensagens ao usuário. Importe isso uma vez e use em todo lugar.
AbortController e timeouts: o padrão de produção para a API Fetch do Node.js
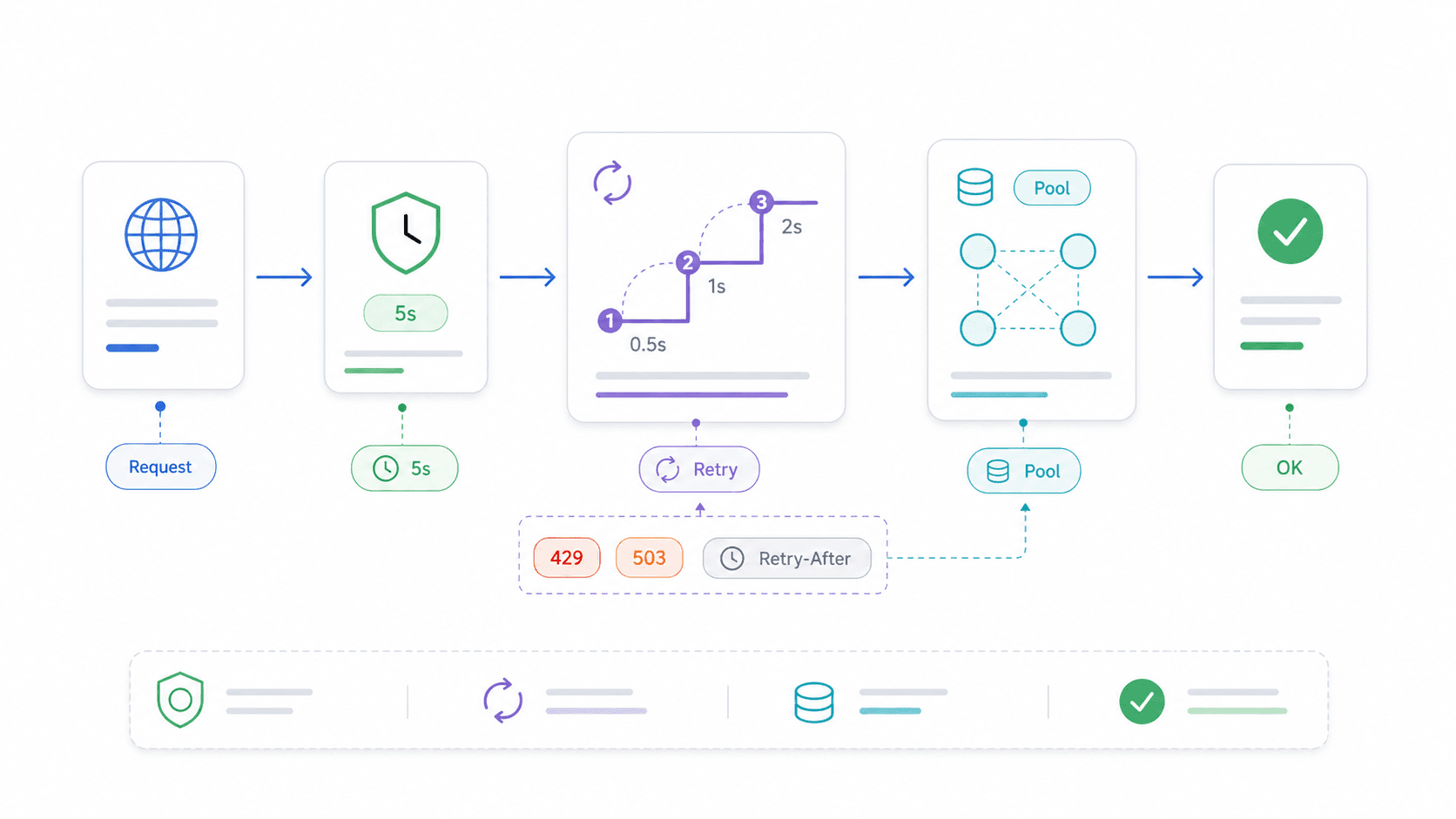
Sem timeout, uma chamada fetch fica pendurada indefinidamente quando o servidor remoto para de responder. Sua rota Express trava. Sua Lambda consome todo o orçamento de execução. Seu script simplesmente... fica ali.
Olhei os primeiros resultados de busca: nenhum tutorial de fetch específico para Node.js cobre cancelamento de requisição ou timeouts. E, no entanto, timeouts estão entre os principais motivos para desenvolvedores continuarem com Axios ou Got. Um tópico no Reddit tem literalmente o título “Node fetch does not timeout”.
Usando AbortSignal.timeout() (Node 18.11+)
A abordagem mais simples — uma opção a mais:
1try {
2 const response = await fetch('https://api.example.com/data', {
3 signal: AbortSignal.timeout(5000), // 5 segundos
4 });
5 if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
6 const data = await response.json();
7 console.log(data);
8} catch (error) {
9 if (error.name === 'TimeoutError') {
10 console.error('A requisição estourou o tempo limite após 5 segundos.');
11 } else {
12 throw error;
13 }
14}Observação: AbortSignal.timeout() lança um TimeoutError, não um AbortError. Esse é um detalhe que até alguns desenvolvedores experientes confundem.
Timeout manual com AbortController
Para ter mais controle — ou se você precisar cancelar uma requisição com base na ação do usuário, e não apenas em um timer:
1const controller = new AbortController();
2const timeout = setTimeout(() => controller.abort(), 5000);
3try {
4 const response = await fetch('https://api.example.com/data', {
5 signal: controller.signal,
6 });
7 const data = await response.json();
8 console.log(data);
9} catch (error) {
10 if (error.name === 'AbortError') {
11 console.error('A requisição foi abortada manualmente.');
12 } else {
13 throw error;
14 }
15} finally {
16 clearTimeout(timeout);
17}Lidando com AbortError vs TimeoutError
Essa diferença importa para logs e mensagens ao usuário:
| Caminho de abortamento | Nome do erro no bloco catch |
|---|---|
AbortSignal.timeout(ms) | TimeoutError |
controller.abort() | AbortError |
| Falha de DNS/rede | Normalmente TypeError: fetch failed |
Aqui vai um cenário prático — uma rota Express que chama uma API externa e precisa responder em até 3 segundos:
1app.get('/dashboard', async (req, res, next) => {
2 try {
3 const data = await fetchJSON('https://api.example.com/report', {
4 signal: AbortSignal.timeout(3000),
5 });
6 res.json(data);
7 } catch (error) {
8 if (error.name === 'TimeoutError') {
9 res.status(504).json({ error: 'A API de origem excedeu o tempo limite' });
10 return;
11 }
12 next(error);
13 }
14});Sem esse padrão, uma API de origem lenta bloquearia toda a rota até o cliente desistir.
Lógica de retry e reutilização de conexão: tornando a API Fetch do Node.js pronta para produção
O fetch nativo não tem retry embutido. Uma oscilação de rede ou um 503 transitório significa que a requisição simplesmente falha. Para a maioria das operações de leitura em produção, isso não é aceitável.
Um wrapper de retry composable com backoff exponencial
Isto é intencionalmente curto — cerca de 10 linhas de lógica real:
1const wait = ms => new Promise(resolve => setTimeout(resolve, ms));
2export async function fetchWithRetry(url, options = {}, retries = 2) {
3 for (let attempt = 0; ; attempt++) {
4 try {
5 const response = await fetch(url, options);
6 if (response.ok || ![408, 429, 500, 502, 503, 504].includes(response.status)) {
7 return response;
8 }
9 if (attempt >= retries) return response;
10 } catch (error) {
11 if (attempt >= retries) throw error;
12 }
13 await wait(250 * 2 ** attempt); // 250ms, 500ms, 1000ms...
14 }
15}Quando fazer retry — e quando não fazer
- Faça retry: requisições GET e HEAD idempotentes, status transitórios (408, 429, 500, 502, 503, 504), falhas momentâneas de rede.
- Não faça retry: requisições POST não idempotentes que criam registros, cobram dinheiro ou disparam efeitos colaterais — a menos que você use idempotency keys.
- Respeite Retry-After: para 429 (limite de taxa) e 503 (serviço indisponível), verifique o cabeçalho
Retry-Afterantes de voltar a tentar.
Se você preferir não criar sua própria lógica de retry, é um wrapper de fetch leve que adiciona retry, timeout, hooks e HTTPError pronto de fábrica — sem dependências.
Reutilização de conexão com Agent e Pool do Undici
Para loops de alto throughput — raspar centenas de páginas, chamar uma API em lote, fazer polling de um serviço — reutilizar conexões TCP economiza bastante tempo. Cada nova conexão significa uma nova consulta DNS, handshake TCP e, no caso de HTTPS, negociação TLS.
Como o fetch do Node é alimentado por Undici, você pode passar um dispatcher personalizado:
1import { Agent } from 'undici';
2const agent = new Agent({
3 keepAliveTimeout: 10_000,
4 keepAliveMaxTimeout: 60_000,
5});
6const response = await fetch('https://api.example.com/data', {
7 dispatcher: agent,
8});Para ainda mais controle com uma origem específica:
1import { Pool } from 'undici';
2const pool = new Pool('https://api.example.com', { connections: 10 });
3const response = await fetch('https://api.example.com/data', {
4 dispatcher: pool,
5});
6// Quando terminar:
7await pool.close();Os mostram que reutilização e pool de conexões podem melhorar drasticamente o throughput — undici - dispatch marcou cerca de 22.234 req/seg, contra cerca de 5.904 req/seg do undici - fetch no benchmark local deles. Os números do mundo real variam, mas a direção é clara: se você faz muitas requisições para a mesma origem, pooling importa.
Mais uma coisa: sempre consuma ou cancele os corpos de resposta. Corpos não consumidos podem causar vazamentos de recursos nos internos HTTP do Node.
Responses em streaming com a API Fetch do Node.js
Downloads de arquivos grandes, feeds JSON em blocos, server-sent events, saída de LLM — esses são casos em que esperar a resposta completa antes de processar desperdiça tempo e memória. Streaming permite tratar os dados conforme eles chegam.
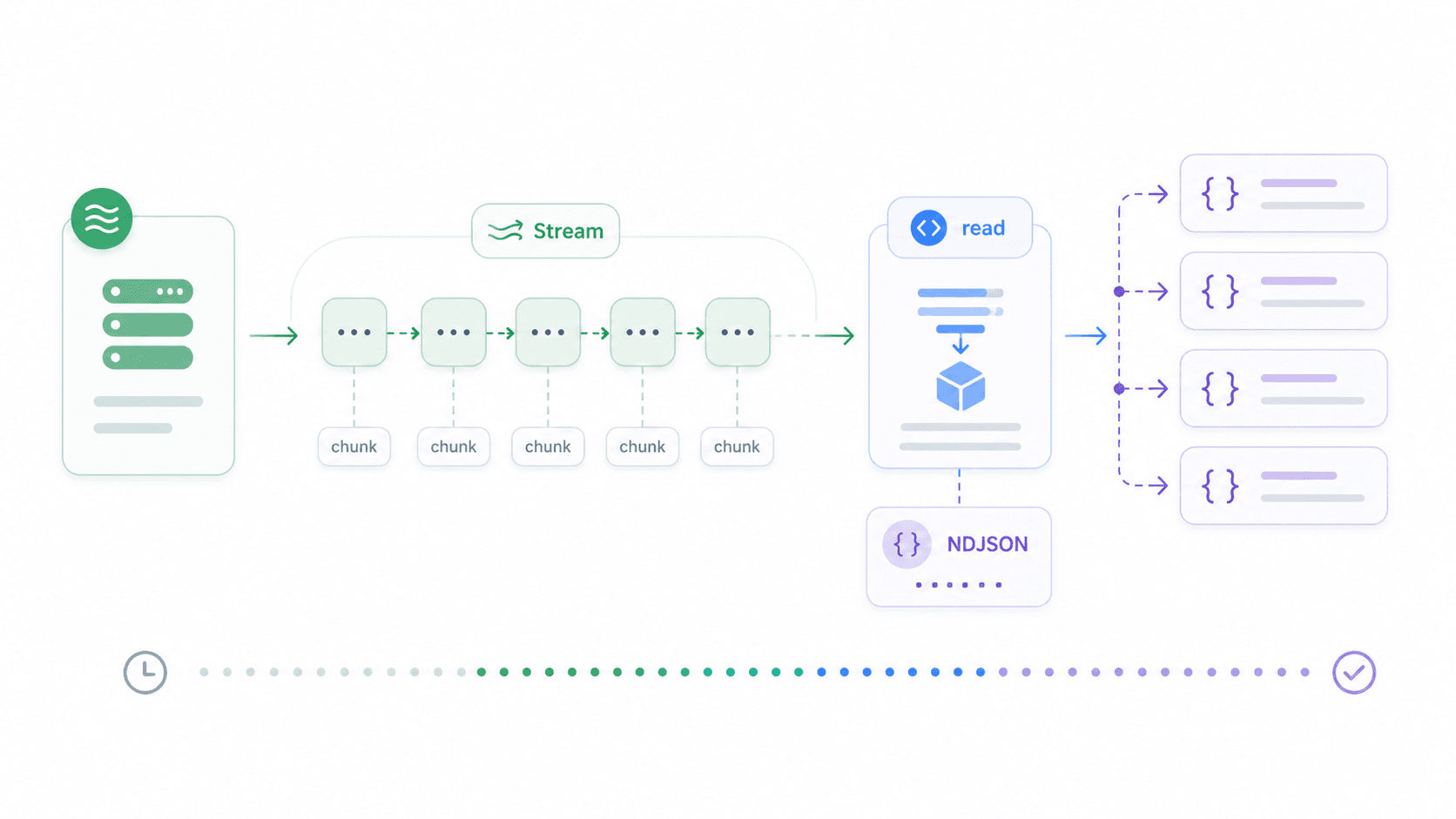
Node 18+ inclui ReadableStream compatível com navegador. Veja como fazer streaming de uma resposta JSON delimitada por novas linhas e processar cada linha à medida que chega:
1const response = await fetch('https://example.com/large-file.ndjson');
2if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
3const reader = response.body.getReader();
4const decoder = new TextDecoder();
5let buffer = '';
6while (true) {
7 const { value, done } = await reader.read();
8 if (done) break;
9 buffer += decoder.decode(value, { stream: true });
10 let newlineIndex;
11 while ((newlineIndex = buffer.indexOf('\n')) >= 0) {
12 const line = buffer.slice(0, newlineIndex).trim();
13 buffer = buffer.slice(newlineIndex + 1);
14 if (line) {
15 const item = JSON.parse(line);
16 console.log('Processado:', item.id);
17 }
18 }
19}Para streaming de texto mais simples (por exemplo, enviar a saída de um LLM para stdout):
1const response = await fetch('https://example.com/stream');
2const reader = response.body.getReader();
3const decoder = new TextDecoder();
4for (;;) {
5 const { value, done } = await reader.read();
6 if (done) break;
7 process.stdout.write(decoder.decode(value, { stream: true }));
8}Streaming é uma área em que o fetch nativo e o Got se destacam. O suporte a streaming do Axios é mais limitado.
Quando o fetch() atinge seus limites: web scraping estruturado com APIs
Em algum momento, o fetch deixa de ser o gargalo. O verdadeiro problema vira: “Tenho HTML — e agora?”
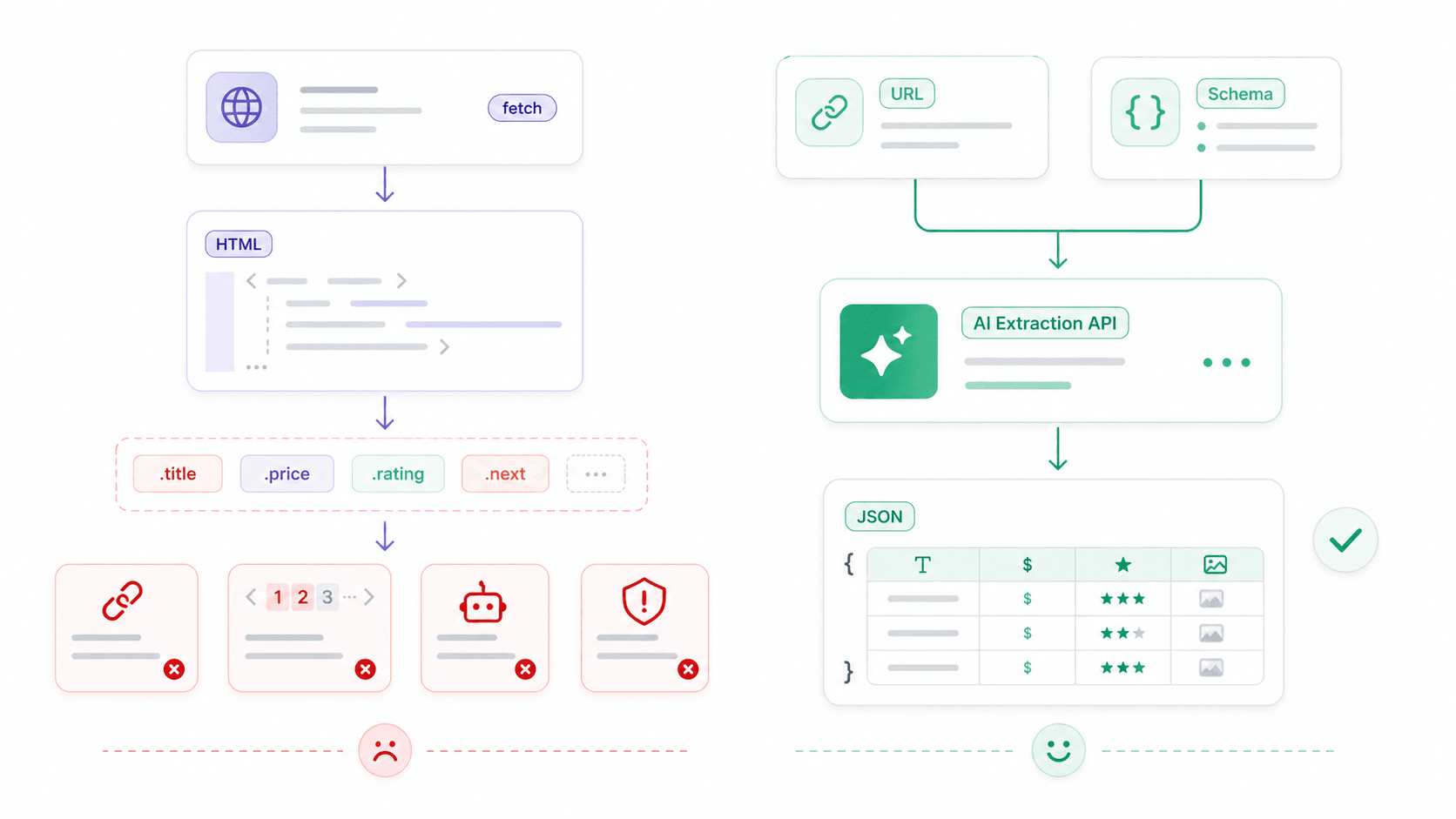
Fetch é um cliente HTTP — ele recupera bytes, texto, JSON ou HTML. Ele não sabe o que é um cartão de produto, um preço, uma avaliação ou uma tabela de contatos. Para web scraping estruturado, a pilha bruta típica é assim:
fetch()para baixar o HTML- Cheerio (ou similar) para selecionar elementos com seletores CSS
- Lógica personalizada de paginação
- Renderização em JavaScript quando as páginas são client-side
- Tratamento de proxy/anti-bot/CAPTCHA
- Manutenção de seletores sempre que o layout do site muda
Aqui vai um exemplo típico de fetch + Cheerio — cerca de 15 linhas para extrair títulos de produtos:
1import * as cheerio from 'cheerio';
2const response = await fetch('https://example-store.com/products');
3if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
4const html = await response.text();
5const $ = cheerio.load(html);
6const products = $('.product-card')
7 .map((_, el) => ({
8 name: $(el).find('.product-title').text().trim(),
9 price: $(el).find('.price').text().trim(),
10 url: new URL($(el).find('a').attr('href'), response.url).href,
11 }))
12 .get();
13console.log(products);Isso funciona para páginas estáveis com HTML previsível. Mas fica frágil rapidamente — conteúdo renderizado em JavaScript, nomes de classes que mudam, medidas anti-bot e paginação aumentam a complexidade.
A Open API da Thunderbit: de HTML bruto a dados estruturados em uma chamada
É aqui que outro tipo de ferramenta passa a fazer sentido. Na , construímos uma camada de API que cuida das partes complicadas — renderização JavaScript, proteção anti-bot, mudanças de layout — para que você possa se concentrar nos dados que realmente quer.
Distill API (POST /distill): converte qualquer URL em Markdown limpo. Útil para alimentar LLMs, construir bases de conhecimento ou fazer análise de conteúdo — sem precisar de parser HTML.
Extract API (POST /extract): defina um JSON Schema descrevendo os dados estruturados que você quer (nome do produto, preço, avaliação) e a IA extrai isso. Sem seletores CSS, sem quebrar quando o layout muda.
Aqui está a mesma tarefa de scraping de produtos usando a Extract API da Thunderbit — chamada com fetch nativo:
1const response = await fetch('https://openapi.thunderbit.com/openapi/v1/extract', {
2 method: 'POST',
3 headers: {
4 Authorization: `Bearer $\{process.env.THUNDERBIT_API_KEY\}`,
5 'Content-Type': 'application/json',
6 },
7 body: JSON.stringify({
8 url: 'https://example-store.com/products',
9 renderMode: 'basic',
10 schema: {
11 type: 'object',
12 properties: {
13 products: {
14 type: 'array',
15 items: {
16 type: 'object',
17 properties: {
18 name: { type: 'string', description: 'Nome do produto' },
19 price: { type: 'string', description: 'Preço exibido do produto' },
20 rating: { type: 'number', description: 'Avaliação média dos clientes' },
21 },
22 required: ['name', 'price'],
23 },
24 },
25 },
26 required: ['products'],
27 },
28 }),
29});
30if (!response.ok) throw new Error(`Thunderbit API: $\{response.status\}`);
31const result = await response.json();
32console.log(result.data);A comparação: ~15 linhas de fetch + Cheerio (mais seletores frágeis) contra uma única chamada de API que devolve JSON limpo. Para jobs em lote, a Thunderbit suporta até 50 URLs por chamada de extração em lote e até 100 URLs por chamada de distill em lote.
A Thunderbit não substitui o fetch — o fetch é o transporte. A Thunderbit é a camada de extração que você usa quando o parsing de HTML bruto vira o problema de verdade. Se quiser ver os preços, o oferece 600 unidades de API para experimentar, e os planos pagos começam em US$ 6/mês. Você também pode conferir a para extração sem código diretamente no navegador.
Para saber mais sobre abordagens de scraping estruturado, nossos guias sobre , e cobrem fluxos de trabalho específicos em detalhe.
Referência rápida: folha de cola da API Fetch do Node.js
Esta seção foi feita para ser salva nos favoritos. Volte aqui quando precisar de um padrão para copiar e colar.
| Padrão | Trecho |
|---|---|
| GET básico | const res = await fetch(url); const data = await res.json(); |
| POST básico | await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload) }); |
| Verificação de erro HTTP | if (!res.ok) throw new Error(\HTTP ${res.status}`);` |
| Timeout (simples) | await fetch(url, { signal: AbortSignal.timeout(5000) }); |
| Abortamento manual | const c = new AbortController(); setTimeout(() => c.abort(), 5000); await fetch(url, { signal: c.signal }); |
| Status para retry | Faça retry em 408, 429, 500, 502, 503, 504. Não faça retry de POST às cegas. |
| Wrapper JSON | Use fetchJSON() para checar ok, analisar content type e lançar HTTPError. |
| Pool de conexão | import { Pool } from 'undici'; const pool = new Pool(origin, { connections: 10 }); fetch(url, { dispatcher: pool }); |
| Stream de blocos | const reader = res.body.getReader(); loop over await reader.read() |
| Extração estruturada | Use a Extract API da Thunderbit quando o objetivo for obter campos de uma página web, e não HTML bruto. |
Conclusão e principais aprendizados
O fetch nativo no Node.js está pronto para produção em 2026 — não precisa de node-fetch em projetos novos, nem de uma dependência padrão do Axios. Mas o fetch() puro, sozinho, não é uma estratégia HTTP de produção.
As cinco coisas que a maioria dos tutoriais pula — e que este guia cobriu:
- A armadilha dos erros:
fetch()não lança em 4xx/5xx. Sempre verifiqueresponse.okou use um wrapper comofetchJSON(). - Timeouts: use
AbortSignal.timeout()para casos simples.AbortSignal.timeout()lançaTimeoutError;controller.abort()manual lançaAbortError. - Lógica de retry: não vem embutida. Adicione backoff exponencial para requisições idempotentes e falhas transitórias. Ou use Ky para retry no estilo fetch pronto de fábrica.
- Reutilização de conexão: para loops de alto throughput, use
AgentouPooldo Undici via a opçãodispatcher. - Extração estruturada: quando você precisa de dados de páginas web, e não apenas HTML bruto, considere uma API de extração como a Thunderbit em vez de manter seletores CSS frágeis.
A matriz de decisão em uma frase: use fetch nativo na maioria dos projetos, Axios para interceptadores, Got para retry embutido e HTTP/2, Ky para um fetch com melhores padrões e a API da Thunderbit quando seus scripts de scraping baseados em fetch ficarem complexos demais para manter.
Teste os padrões deste guia. E, se quiser ver como a Thunderbit lida com extração estruturada, o é um bom lugar para começar — ou veja uma demonstração no .
FAQs
1. O fetch já vem integrado ao Node.js ou preciso instalá-lo?
O fetch vem integrado ao Node.js 18 e posteriores — sem necessidade de instalação. Ele se tornou estável no Node 21 e é totalmente suportado no Node 22 LTS e no Node 24 LTS. Para versões mais antigas do Node, você pode usar o pacote npm node-fetch, mas projetos novos devem mirar uma versão LTS mantida.
2. O fetch lança erro em respostas 404 ou 500?
Não. O fetch só rejeita a Promise em falhas de rede (erro de DNS, falta de conexão, requisições abortadas). Respostas HTTP como 404, 403 e 500 são resolvidas normalmente com response.ok === false. Você precisa verificar response.ok ou response.status explicitamente — ou usar um wrapper como a função fetchJSON() mostrada neste guia.
3. Como adiciono timeout ao fetch no Node.js?
A forma mais simples é AbortSignal.timeout(ms), disponível no Node 18.11+: await fetch(url, { signal: AbortSignal.timeout(5000) }). Isso lança um TimeoutError se a requisição exceder 5 segundos. Para mais controle, crie um AbortController manualmente e chame controller.abort() dentro de um setTimeout. Capture AbortError para o padrão manual e TimeoutError para AbortSignal.timeout().
4. Posso usar fetch para web scraping no Node.js?
Sim, mas o fetch só retorna HTML bruto. Você vai precisar de um parser como Cheerio para extrair elementos específicos, além de lógica personalizada para paginação, páginas renderizadas em JavaScript e medidas anti-bot. Para extração estruturada de dados em escala — quando você quer JSON limpo com nomes de produtos, preços ou informações de contato — considere a , que usa IA para retornar dados estruturados sem seletores CSS ou código dependente do layout.
5. Devo migrar do Axios para o fetch nativo em 2026?
Para projetos novos em Node 22+, o fetch nativo é um ótimo padrão. Ele não tem dependências, usa Promise e compartilha a mesma API do fetch do navegador. Mantenha o Axios se você depende de interceptadores de requisição/resposta, rejeição padrão para erros HTTP ou compatibilidade com versões mais antigas do Node. Ambos são escolhas válidas — a decisão depende dos recursos que o seu projeto realmente usa.
Saiba mais