A internet está cheia de dados e todo mundo quer tirar o máximo proveito disso. Mas vamos falar a real: copiar informações manualmente de centenas de páginas é tão animador quanto ver a grama crescer (e tão produtivo quanto também). É aí que entra o raspador web node. Nos últimos anos, tenho visto cada vez mais times — vendas, operações, pesquisa de mercado, entre outros — apostando na automação para extrair insights valiosos da web em grande escala. Para você ter uma ideia, o mercado global de raspagem de dados deve ultrapassar , e não são só as gigantes de tecnologia surfando essa onda. De monitoramento de preços no e-commerce à geração de leads, saber usar web scraping node js virou uma habilidade essencial para quem quer se manter competitivo.
Se você já ficou na dúvida sobre como extrair dados de sites usando Node.js — ou por que o Node.js é tão eficiente para raspar páginas dinâmicas e cheias de JavaScript — este guia é pra você. Vou te mostrar o que é raspador web node, por que ele é importante para negócios e como criar seu próprio fluxo de raspagem do zero. E se você é do tipo “quero resultado pra ontem”, também vou mostrar como ferramentas como o podem economizar horas do seu tempo (e evitar muita dor de cabeça) automatizando tudo. Bora transformar a web na sua mina de ouro de dados? Então vem comigo.
O que é Raspador Web Node? Sua Porta de Entrada para Extração Automática de Dados
No fundo, raspador web node é usar o Node.js (aquele ambiente JavaScript que roda fora do navegador) para extrair informações automaticamente de sites. Imagina montar um robô super-rápido que visita páginas, lê o conteúdo e pega exatamente os dados que você precisa — seja preço de produtos, contatos ou as últimas notícias.
O processo é mais ou menos assim:
- Seu script em Node.js faz uma requisição HTTP para um site (igualzinho ao seu navegador).
- Ele recebe o HTML bruto da página.
- Com bibliotecas como Cheerio, faz o parsing do HTML e permite “consultar” a página para buscar dados específicos (tipo um ninja do jQuery).
- Para sites onde o conteúdo é carregado via JavaScript (pensa em web apps modernos e cheios de interação), você pode usar o Puppeteer para controlar um navegador de verdade em segundo plano, renderizar a página e capturar os dados depois que tudo carregar.
Por que Node.js? JavaScript é a linguagem da web, e o Node.js permite usar ela fora do navegador. Isso significa que você pode lidar tanto com sites estáticos quanto dinâmicos, automatizar interações mais complexas (como login ou cliques) e processar dados rapidinho. Fora que a arquitetura assíncrona e não bloqueante do Node facilita raspar várias páginas ao mesmo tempo — perfeito pra escalar a extração de dados.
Principais ferramentas do kit de raspagem web node:
- Axios: Faz requisições HTTP para buscar páginas.
- Cheerio: Faz o parsing e consulta do HTML em sites estáticos.
- Puppeteer: Automatiza um navegador real para lidar com sites dinâmicos ou interativos.
Se você imaginou um exército de navegadores coletando dados enquanto toma um café... não tá longe da realidade.
Por que o Raspador Web Node é Importante para Equipes de Negócios
Vamos ser práticos: raspagem web não é mais coisa só de hacker ou cientista de dados. É uma super ferramenta para negócios. Empresas de todos os tipos estão usando raspador web node para:
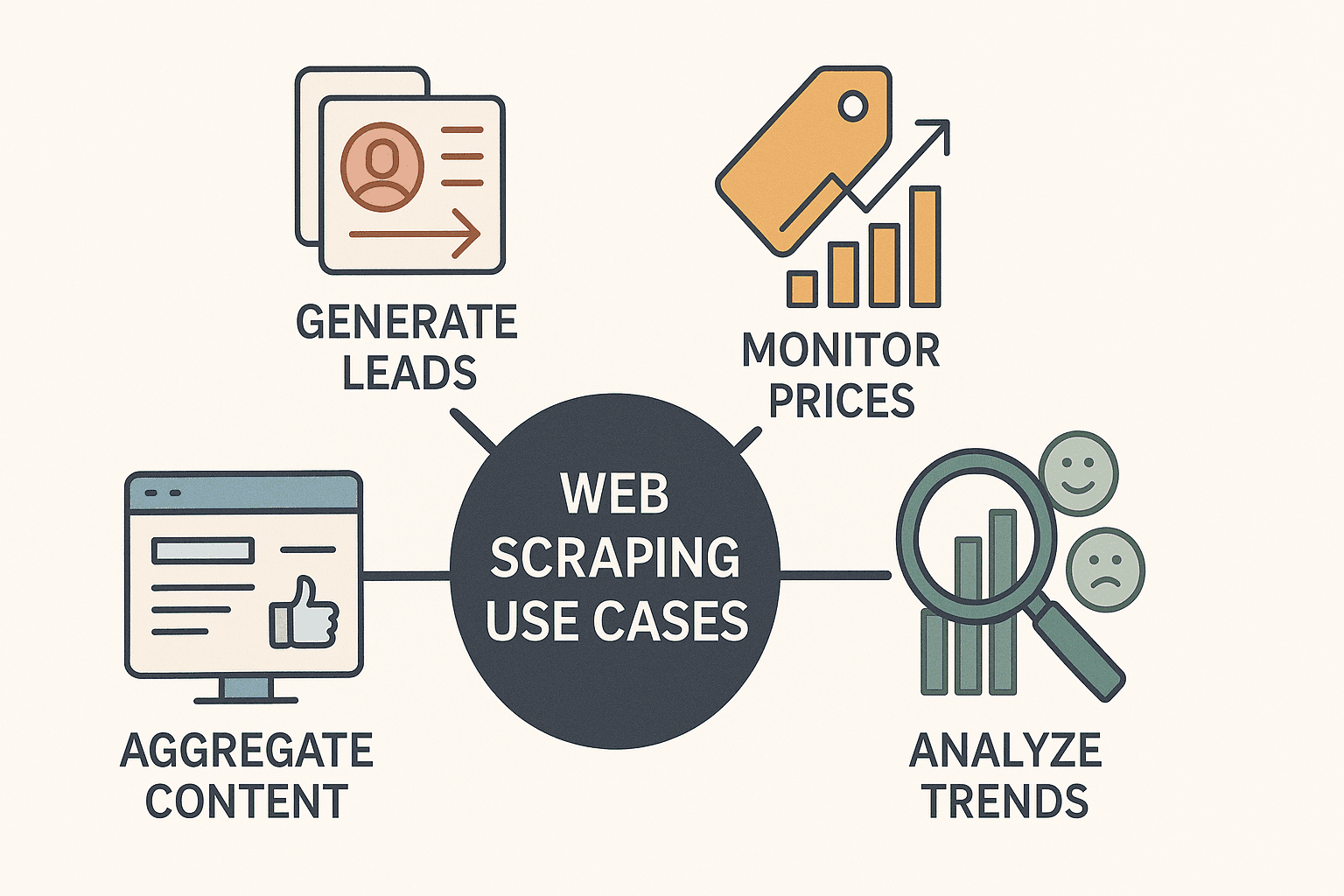
- Gerar leads: Coletar contatos em diretórios ou no LinkedIn para prospecção de vendas.
- Monitorar preços da concorrência: Acompanhar listagens de produtos e ajustar preços em tempo real (mais de fazem isso todo dia).
- Agregação de conteúdo: Criar painéis com notícias, avaliações ou menções em redes sociais.
- Analisar tendências de mercado: Raspar avaliações, fóruns ou vagas de emprego para identificar oportunidades e sentimentos.
E o melhor: o Node.js deixa tudo isso mais rápido, flexível e fácil de automatizar do que nunca. Como ele é assíncrono, dá pra buscar e processar dezenas (ou centenas) de páginas ao mesmo tempo, e por ser JavaScript, é perfeito para sites modernos.
Olha só alguns exemplos práticos:
| Caso de Uso | Descrição & Exemplo | Vantagem do Node.js |
|---|---|---|
| Geração de Leads | Raspar diretórios de empresas para e-mails, nomes e telefones. | Raspagem rápida e paralela; fácil integração com CRMs e APIs. |
| Monitoramento de Preços | Acompanhar preços da concorrência em sites de e-commerce. | Requisições assíncronas para várias páginas; fácil agendamento para checagens diárias/horárias. |
| Pesquisa de Tendências | Agregar avaliações, fóruns ou posts sociais para análise de sentimento. | Manipulação versátil de dados; ecossistema rico para processamento e limpeza de texto. |
| Agregação de Conteúdo | Reunir notícias ou posts de blogs em um único painel. | Atualizações em tempo real; integração fácil com ferramentas de notificação (Slack, e-mail etc.). |
| Análise da Concorrência | Raspar catálogos, descrições e avaliações de produtos de sites rivais. | Parsing de JavaScript para sites complexos; código modular para crawls em várias páginas. |
O Node.js é especialmente útil para raspar sites que usam muito JavaScript — coisa que Python e outras linguagens costumam penar. Com a configuração certa, você vai de “preciso desses dados” para “tá aqui minha planilha” em minutos.
Ferramentas Essenciais para Raspagem Web com Node: O que Você Precisa
Antes de botar a mão na massa, conheça as principais ferramentas do arsenal de raspagem com Node.js:
1. Axios (Cliente HTTP)

- O que faz: Busca páginas web enviando requisições HTTP.
- Quando usar: Sempre que precisar pegar o HTML bruto de uma página.
- Por que é bom: API simples baseada em Promises; lida fácil com redirecionamentos e cabeçalhos.
- Instale com:
npm install axios
2. Cheerio (Parser de HTML)

- O que faz: Faz parsing do HTML e permite usar seletores tipo jQuery para encontrar dados.
- Quando usar: Para sites estáticos, onde os dados já estão no HTML inicial.
- Por que é bom: Rápido, leve e muito familiar pra quem já usou jQuery.
- Instale com:
npm install cheerio
3. Puppeteer (Automação de Navegador Headless)

- O que faz: Controla um navegador Chrome real em segundo plano, permitindo interagir com páginas como um usuário.
- Quando usar: Para sites dinâmicos ou interativos (infinite scroll, login, pop-ups).
- Por que é bom: Pode clicar em botões, preencher formulários, rolar a página e extrair dados depois que tudo carregar.
- Instale com:
npm install puppeteer
Bônus: Tem outras ferramentas como Playwright (automação multi-navegador) e frameworks como Crawlee da Apify para fluxos mais avançados, mas pra começar, Axios, Cheerio e Puppeteer são o trio principal.
Pré-requisitos: Certifique-se de ter o Node.js instalado. Inicie um novo projeto com npm init -y e instale as bibliotecas acima.
Passo a Passo: Construindo Seu Primeiro Raspador Web Node do Zero
Vamos botar a mão na massa e criar um raspador simples. Vamos usar Axios e Cheerio para raspar dados de livros do site de demonstração .
Passo 1: Buscar o HTML da Página
1import axios from 'axios';
2import { load } from 'cheerio';
3const startUrl = 'http://books.toscrape.com/';
4async function scrapePage(url) {
5 const resp = await axios.get(url);
6 const html = resp.data;
7 const $ = load(html);
8 // ...extrair dados a seguir
9}Passo 2: Fazer Parsing e Extrair Dados
1$('.product_pod').each((i, element) => {
2 const title = $(element).find('h3').text().trim();
3 const price = $(element).find('.price_color').text().replace('£', '');
4 const stock = $(element).find('.instock').text().trim();
5 const ratingClass = $(element).find('p.star-rating').attr('class') || '';
6 const rating = ratingClass.split(' ')[1];
7 const relativeUrl = $(element).find('h3 a').attr('href');
8 const bookUrl = new URL(relativeUrl, startUrl).href;
9 console.log({ title, price, rating, stock, url: bookUrl });
10});Passo 3: Lidar com Paginação
1const nextHref = $('.next > a').attr('href');
2if (nextHref) {
3 const nextUrl = new URL(nextHref, url).href;
4 await scrapePage(nextUrl);
5}Passo 4: Salvar os Dados
Depois de coletar os dados, você pode salvar tudo em um arquivo JSON ou CSV usando o módulo fs do Node.
1import fs from 'fs';
2// Após finalizar a raspagem:
3fs.writeFileSync('books_output.json', JSON.stringify(booksList, null, 2));
4console.log(`Raspados ${booksList.length} livros.`);Pronto! Você já tem um raspador web node básico e funcional. Essa abordagem funciona super bem para sites estáticos, mas e quando a página depende de JavaScript?
Lidando com Páginas Dinâmicas: Usando Puppeteer com Node
Alguns sites escondem os dados atrás de camadas de JavaScript. Se você tentar raspar com Axios e Cheerio, pode acabar com uma página vazia ou faltando informações. É aí que o Puppeteer brilha.
Por que usar o Puppeteer? Ele abre um navegador de verdade (headless), carrega a página, espera todos os scripts rodarem e só então permite capturar o conteúdo renderizado — igualzinho a um usuário humano.
Exemplo de Script com Puppeteer
1import puppeteer from 'puppeteer';
2async function scrapeWithPuppeteer(url) {
3 const browser = await puppeteer.launch({ headless: true });
4 const page = await browser.newPage();
5 await page.goto(url, { waitUntil: 'networkidle2' });
6 await page.waitForSelector('.product_pod'); // Espera os dados carregarem
7 const data = await page.evaluate(() => {
8 let items = [];
9 document.querySelectorAll('.product_pod').forEach(elem => {
10 items.push({
11 title: elem.querySelector('h3').innerText,
12 price: elem.querySelector('.price_color').innerText,
13 });
14 });
15 return items;
16 });
17 console.log(data);
18 await browser.close();
19}Quando usar Cheerio/Axios ou Puppeteer:
- Cheerio/Axios: Rápido, leve, ideal para conteúdo estático.
- Puppeteer: Mais lento, mas essencial para páginas dinâmicas ou interativas (login, infinite scroll etc.).
Dica: Sempre tente Cheerio/Axios primeiro pela velocidade. Se faltar dados, aí sim parta para o Puppeteer.
Avançando: Paginação, Login e Limpeza de Dados com Node
Depois de dominar o básico, é hora de encarar cenários mais complexos.
Paginação
Percorra páginas detectando e seguindo links de "próxima" ou gerando URLs se seguirem um padrão.
1let pageNum = 1;
2while (true) {
3 const resp = await axios.get(`https://example.com/products?page=${pageNum}`);
4 // ...extrair dados
5 if (!hasNextPage) break;
6 pageNum++;
7}Automatizando Logins
Com o Puppeteer, você pode preencher formulários de login igualzinho a um usuário:
1await page.type('#username', 'meuUsuario');
2await page.type('#password', 'minhaSenha');
3await page.click('#loginButton');
4await page.waitForNavigation();Limpeza de Dados
Depois de raspar, limpe seus dados:
- Remova duplicatas (use Set ou filtre por chaves únicas).
- Formate números, datas e textos.
- Trate valores ausentes (preencha com null ou descarte registros incompletos).
Expressões regulares e métodos de string do JavaScript são ótimos aliados aqui.
Boas Práticas em Raspagem Web com Node: Evite Erros e Ganhe Eficiência
Raspar dados é poderoso, mas tem seus desafios. Veja como evitar as armadilhas mais comuns:
- Respeite o robots.txt e as políticas do site: Sempre confira se o site permite raspagem e evite áreas restritas.
- Controle a frequência das requisições: Não sobrecarregue o site com centenas de requisições por segundo. Adicione intervalos e aleatorize para simular comportamento humano ().
- Alterne user agents e IPs: Use cabeçalhos realistas e, para raspagem em larga escala, alterne IPs para evitar bloqueios.
- Trate erros com cuidado: Capture exceções, tente novamente requisições falhas e registre erros para depuração.
- Valide seus dados: Verifique campos ausentes ou malformados para identificar mudanças na estrutura do site.
- Escreva código modular e fácil de manter: Separe lógica de busca, parsing e salvamento. Use arquivos de configuração para seletores e URLs.
E o mais importante: raspe de forma ética. A web é um recurso compartilhado e ninguém gosta de bots abusivos.
Thunderbit vs. Raspador Node DIY: Quando Construir e Quando Usar uma Ferramenta
Agora, a dúvida: construir seu próprio raspador ou usar uma solução como o ?
Raspador Node.js DIY:
- Vantagens: Controle total, super personalizável, integra com qualquer fluxo.
- Desvantagens: Precisa saber programar, demanda tempo pra configurar e manter, quebra quando o site muda.
Raspador Web IA Thunderbit:
- Vantagens: Não precisa programar, detecção automática de campos por IA, lida com subpáginas e paginação, exportação instantânea pra Excel, Google Sheets, Notion e mais (). Sem manutenção — a IA se adapta automaticamente às mudanças do site.
- Desvantagens: Menos flexível pra fluxos super customizados ou complexos (mas cobre 99% dos casos de uso de negócios).
Veja um comparativo rápido:
| Aspecto | Raspador Node.js DIY | Raspador Web IA Thunderbit |
|---|---|---|
| Habilidade Técnica | Requer programação | Sem código, clique e use |
| Tempo de Configuração | Horas a dias | Minutos (IA sugere campos) |
| Manutenção | Constante (mudanças no site) | Mínima (IA se adapta automaticamente) |
| Conteúdo Dinâmico | Configuração manual do Puppeteer | Suporte nativo |
| Paginação/Subpáginas | Código manual | 1 clique para subpáginas/paginação |
| Exportação de Dados | Código manual para exportar | 1 clique para Excel, Sheets, Notion |
| Custo | Gratuito (tempo, proxies) | Plano gratuito, créditos por uso |
| Melhor Para | Desenvolvedores, lógica customizada | Usuários de negócios, resultados rápidos |
O Thunderbit é um salva-vidas para equipes de vendas, marketing e operações que precisam de dados pra ontem — sem esperar dias de programação e depuração. E pra desenvolvedores, é uma ótima forma de prototipar ou automatizar tarefas rotineiras sem reinventar a roda.
Conclusão & Principais Dicas: Sua Jornada com Raspador Web Node Começa Agora
Raspar dados com Node é sua chave pra acessar informações valiosas da web — seja pra criar listas de leads, monitorar preços ou impulsionar seu próximo projeto. Lembre-se:
- Node.js + Cheerio/Axios é ideal pra sites estáticos; Puppeteer é a escolha certa pra páginas dinâmicas e cheias de JavaScript.
- O impacto nos negócios é real: Empresas que usam raspagem web pra decisões baseadas em dados estão vendo resultados concretos, de até dobrar vendas internacionais.
- Comece simples: Monte um raspador básico e vá adicionando recursos como paginação, login automático e limpeza de dados conforme evolui.
- Use a ferramenta certa: Pra raspagem rápida, sem código e resultados instantâneos, o é imbatível. Pra fluxos customizados e integrados, scripts Node.js DIY dão controle total.
- Raspe com responsabilidade: Respeite as políticas dos sites, controle seus bots e mantenha seu código limpo e organizado.
Pronto pra começar? Experimente criar seu próprio raspador com Node.js ou e veja como a extração de dados pode ser simples. E se quiser mais dicas, acesse o pra tutoriais, novidades e tudo sobre raspagem com IA.
Boas raspagens — e que seus dados estejam sempre frescos, organizados e à frente da concorrência.
Perguntas Frequentes
1. O que é raspador web node e por que o Node.js é uma boa escolha?
Raspador web node é o processo de usar Node.js pra automatizar a extração de dados de sites. O Node.js se destaca porque lida com requisições assíncronas de forma eficiente e é ótimo pra raspar sites dinâmicos graças a ferramentas como o Puppeteer.
2. Quando devo usar Cheerio/Axios ou Puppeteer pra raspagem?
Use Cheerio e Axios pra sites estáticos, onde os dados já estão no HTML inicial. Use Puppeteer quando precisar raspar conteúdo carregado por JavaScript, interagir com a página (como login) ou lidar com infinite scroll.
3. Quais são os principais casos de uso de negócios pra raspador web node?
Os principais usos incluem geração de leads, monitoramento de preços da concorrência, agregação de conteúdo, análise de tendências de mercado e raspagem de catálogos de produtos. O Node.js torna essas tarefas rápidas e escaláveis.
4. Quais são os maiores desafios na raspagem web node e como evitá-los?
Os desafios mais comuns são bloqueios por sistemas anti-bot, mudanças na estrutura do site e qualidade dos dados. Evite-os controlando a frequência das requisições, alternando user agents/IPs, validando seus dados e escrevendo código modular.
5. Como o Thunderbit se compara a criar meu próprio raspador Node.js?
O Thunderbit oferece uma solução sem código, com IA que detecta campos, subpáginas e paginação automaticamente. É ideal pra quem quer resultados rápidos, enquanto scripts Node.js DIY são melhores pra desenvolvedores que precisam de personalização total ou integração com outros sistemas.
Pra mais dicas e inspiração, não deixe de visitar o e se inscrever no nosso pra tutoriais práticos.
Saiba Mais