O ritmo das notícias digitais hoje é, no mínimo, vertiginoso. A cada minuto, milhares de manchetes são publicadas, atualizadas ou discretamente editadas — em veículos tradicionais, blogs de nicho e feeds sociais.
Para pôr isso em perspectiva, a processa mais de 4 milhões de artigos de notícias por dia, enquanto o acompanha notícias em mais de 100 idiomas e atualiza o seu feed global a cada 15 minutos.
Para qualquer pessoa que trabalhe com media, pesquisa ou inteligência de negócio, tentar acompanhar este fluxo manualmente é como esvaziar um barco a afundar com uma chávena de café.
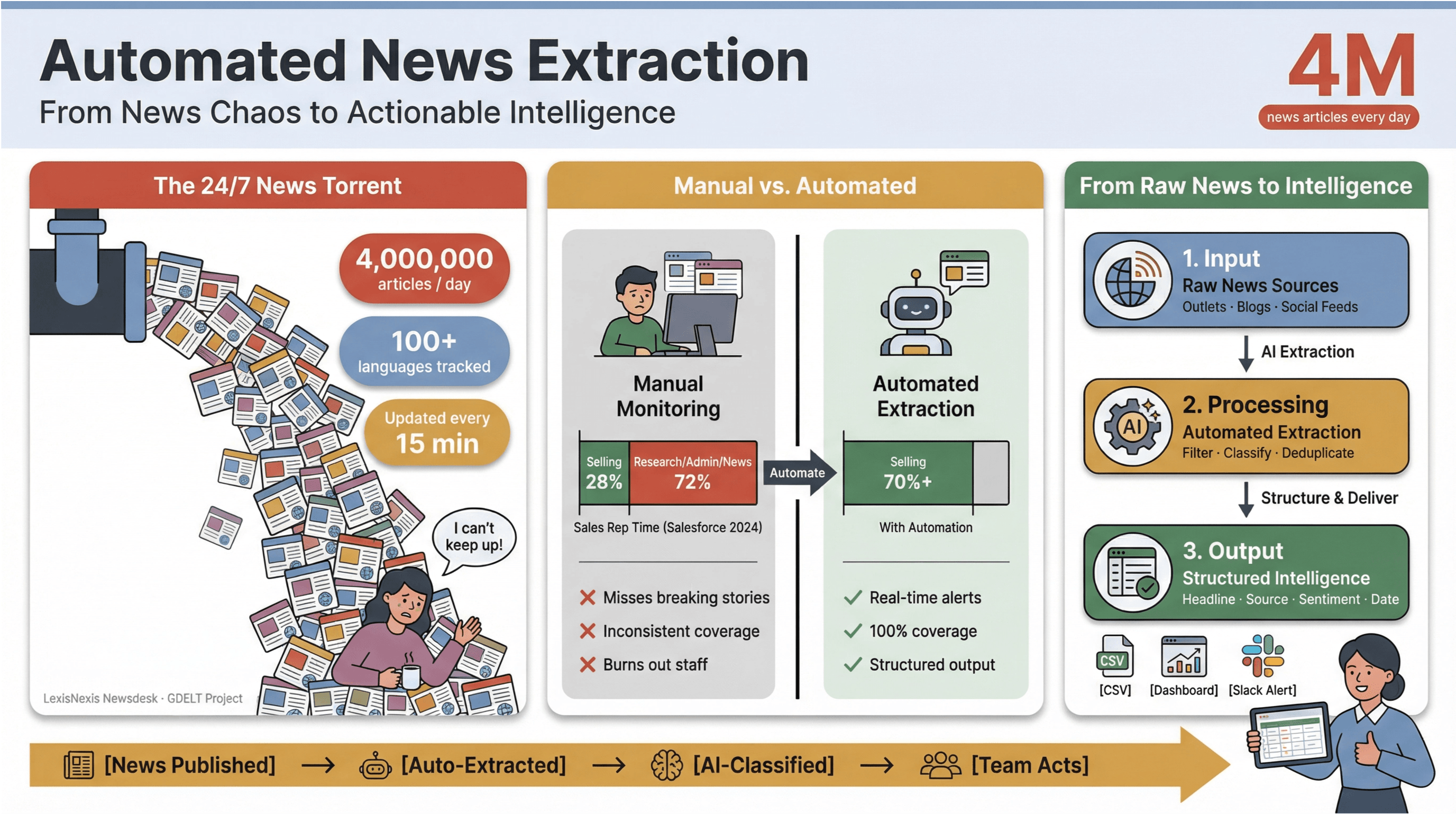
Já vi de perto como o acompanhamento manual de notícias consome tempo e recursos. As equipas de vendas passam menos de um terço da semana efetivamente a vender — — e o resto perde-se em pesquisa, tarefas administrativas e, claro, na troca infinita de separadores de notícias.
É por isso que a extração automatizada de notícias se tornou a arma secreta das equipas modernas: é a única forma de transformar o caos do ciclo de notícias 24/7 em inteligência estruturada e acionável — sem esgotar a equipa nem perder as histórias mais importantes.
Vamos perceber o que a extração automatizada de notícias significa realmente, porque é essencial para quem se preocupa com dados de notícias em tempo real e como montar um fluxo de trabalho robusto e em conformidade usando as melhores ferramentas (incluindo como a torna todo o processo surpreendentemente simples — até para quem não é técnico, como a minha mãe).
Extração automatizada de notícias: porque é essencial para as redações modernas
Extração automatizada de notícias é exatamente o que parece: usar software para recolher conteúdo de notícias automaticamente e transformá-lo em dados estruturados e pesquisáveis — pense em linhas e colunas em vez de páginas da web confusas ou PDFs. Na prática, isto significa monitorizar centenas (ou milhares) de fontes, extrair campos-chave como manchete, timestamp, autor e corpo do texto, e enviar esses dados para painéis, alertas ou análises posteriores — sem precisar de tocar em Ctrl+C/Ctrl+V.
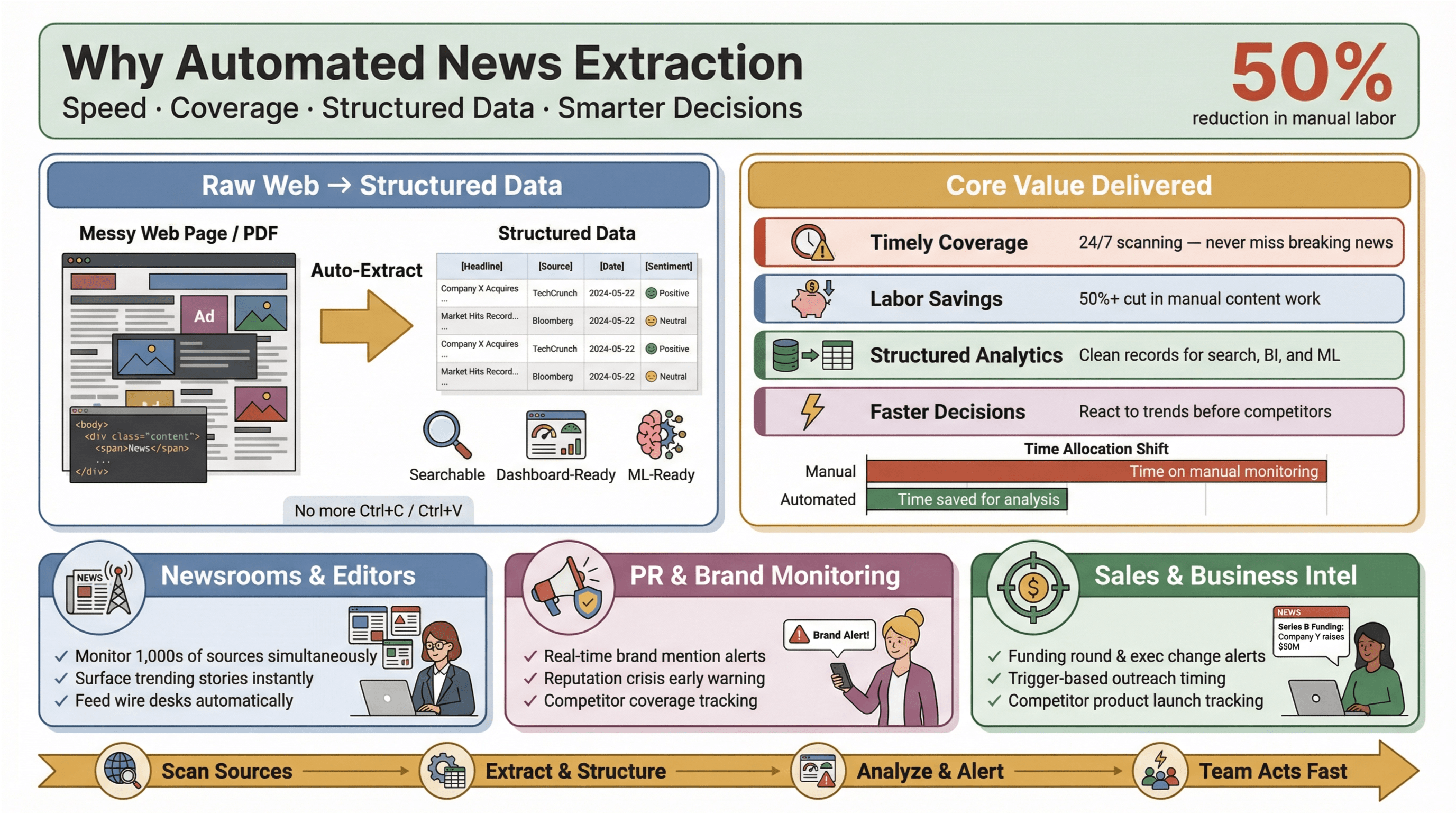 Porque é que isto importa? Porque, no cenário atual das notícias, velocidade é tudo. Quer seja editor de redação, responsável de PR a acompanhar menções à marca ou analista de negócio a seguir movimentos da concorrência, saber primeiro pode ser a diferença entre aproveitar uma oportunidade ou correr atrás do prejuízo. As ferramentas de extração automatizada permitem que até equipas pequenas entreguem muito acima da sua dimensão — reunindo dados de notícias em tempo real de toda a web, reduzindo o trabalho manual e destacando as histórias que realmente importam.
Porque é que isto importa? Porque, no cenário atual das notícias, velocidade é tudo. Quer seja editor de redação, responsável de PR a acompanhar menções à marca ou analista de negócio a seguir movimentos da concorrência, saber primeiro pode ser a diferença entre aproveitar uma oportunidade ou correr atrás do prejuízo. As ferramentas de extração automatizada permitem que até equipas pequenas entreguem muito acima da sua dimensão — reunindo dados de notícias em tempo real de toda a web, reduzindo o trabalho manual e destacando as histórias que realmente importam.
E o impacto é real: estudos mostram que a automação pode reduzir o trabalho manual em atualizações de conteúdo em pelo menos 50%, libertando tempo para análise a sério e tomada de decisão.
Valor central da extração automatizada de notícias no setor das notícias
Vamos ao lado prático. O que é que a extração automatizada de notícias entrega, na realidade, às redações e às equipas de negócio?
- Cobertura ampla e atempada: nada de perder notícias de última hora porque alguém se esqueceu de verificar um feed. As ferramentas automatizadas percorrem fontes 24/7, garantindo que não perde nada.
- Poupança de trabalho e custos: equipas pequenas e médias conseguem monitorizar tantas fontes quanto as grandes — sem precisar de contratar um exército de estagiários.
- Dados estruturados para análise: em vez de andar a vasculhar artigos desestruturados, recebe registos limpos e organizados, prontos para pesquisa, dashboards e machine learning.
- Decisões mais rápidas e inteligentes: dados de notícias em tempo real permitem reagir a mudanças de mercado, crises de PR ou tendências emergentes antes dos concorrentes.
Pense em PR e comunicação: plataformas como e posicionam o monitoramento de media em tempo real como essencial para proteger a reputação e agir rapidamente perante cobertura prejudicial. Em vendas, alertas de notícias em tempo real tornam-se “context cards” para prospeção — pense em rondas de investimento, troca de executivos ou lançamentos de produtos que acionam o contacto no momento certo.
Como escolher as ferramentas certas para web scraping de notícias em diferentes cenários
Nem todas as ferramentas de web scraping de notícias são iguais. A escolha certa depende dos seus objetivos, da sua familiaridade técnica e dos tipos de notícias que quer acompanhar. Aqui fica um framework para ajudar na decisão:
Avaliando facilidade de uso e acessibilidade
Para a maioria dos utilizadores de negócio e jornalistas, facilidade de uso é inegociável. Quer uma ferramenta que funcione à primeira, sem programação nem configuração complicada. Plataformas no-code e low-code como , e permitem criar scrapers visualmente — é só apontar, clicar e extrair.
A Thunderbit, em particular, destaca-se pelo seu processo em duas etapas: descreva o que quer, deixe a IA sugerir os campos e clique em “Scrape”. Até utilizadores sem conhecimentos técnicos conseguem montar um pipeline de dados de notícias em minutos, não em horas.
Considerações sobre segurança e privacidade de dados
Com grandes dados vem grande responsabilidade. As ferramentas de web scraping de notícias acedem muitas vezes a conteúdo sensível, por isso segurança e conformidade têm de estar no centro da atenção. Procure:
- Encriptação de dados (em trânsito e em repouso)
- Políticas de privacidade claras (a Thunderbit, por exemplo, declara que não vende dados de utilizadores e só acede ao conteúdo que escolher extrair)
- Permissões granulares (especialmente em extensões de navegador — verifique sempre que dados a ferramenta pode aceder)
- Conformidade com leis locais (GDPR, CCPA e, para utilizadores da UE, a )
Para ter ainda mais tranquilidade, escolha fornecedores de confiança, confirme as permissões da extensão e limite o acesso apenas ao que for necessário.
Adequando as ferramentas aos tipos de notícia e às necessidades do setor
Algumas ferramentas destacam-se em áreas específicas das notícias:
- Finanças: APIs como e oferecem clustering, análise de sentimento e deteção de eventos para notícias financeiras.
- Tecnologia e startups: o scraping personalizado com Thunderbit ou Octoparse permite visar blogs de nicho, press releases e listas de eventos.
- Política e políticas públicas: bases licenciadas como e oferecem acesso a fontes premium e arquivos históricos.
Se precisa de monitorizar uma combinação de fontes tradicionais, de nicho e internacionais — incluindo aquelas sem APIs — scrapers flexíveis movidos por IA, como a Thunderbit, são a melhor opção.
As vantagens exclusivas da Thunderbit para extração de dados de notícias em tempo real
Agora, vamos falar sobre o que faz da uma escolha de destaque para extração automatizada de notícias — especialmente se quer dados de notícias em tempo real sem dores de cabeça técnicas.
A Thunderbit é uma extensão Chrome de web scraper com IA criada para utilizadores de negócio, jornalistas e analistas que precisam de conteúdo de notícias atualizado e estruturado de qualquer site. Eis porque se tornou a minha favorita:
- Campos sugeridos por IA: a Thunderbit lê a página de notícias e sugere automaticamente as melhores colunas para extração — manchete, timestamp, autor, resumo e muito mais. Sem mexer em seletores nem templates.
- Scraping de subpáginas: precisa do artigo completo, e não só da manchete? A Thunderbit pode visitar cada link de notícia, extrair o texto completo, entidades e tags, e reunir tudo numa única tabela estruturada.
- Exportação em massa e atualizações instantâneas: exporte os seus dados de notícias diretamente para Excel, Google Sheets, Airtable ou Notion com um clique. Chega de maratonas de copiar e colar ou de lutas com CSV.
- Scraping agendado: configure execuções recorrentes (de hora a hora, diariamente ou em intervalos personalizados) para manter o seu pipeline de notícias sempre atualizado — ideal para notícias urgentes, monitorização de mercado ou pesquisa contínua.
- Adaptabilidade: a IA da Thunderbit adapta-se a mudanças de layout e a sites de notícias de cauda longa, por isso passa menos tempo a corrigir scrapers avariados e mais tempo a analisar dados.
Com mais de e nota 4,8 estrelas, é uma solução de confiança para equipas em todo o mundo em tudo, desde monitorização de PR até inteligência competitiva.
Deteção de campos orientada por IA e scraping de subpáginas
Um dos recursos mais fortes da Thunderbit é a sua deteção de campos orientada por IA. Basta clicar em “AI Suggest Fields” e a ferramenta varre a página de notícias — identificando campos-chave como título, data, autor e resumo. Pode ajustar ou adicionar campos personalizados (por exemplo, “marcar este artigo como ‘lucros’ se mencionar resultados trimestrais”), e a IA da Thunderbit trata do resto.
O scraping de subpáginas é um divisor de águas para notícias: extraia manchetes de uma página inicial ou de uma lista de secção e depois deixe a Thunderbit visitar cada URL de artigo para extrair a peça completa, entidades e até imagens. Isso significa que obtém registos de notícias completos e enriquecidos — prontos para pesquisa, dashboards ou análise posterior com IA.
Exportação em massa e atualizações instantâneas
A Thunderbit torna a exportação de dados de notícias muito simples. Com um clique, pode enviar o seu feed estruturado para Google Sheets, Airtable, Notion ou descarregar em CSV/Excel. Para equipas que vivem em folhas de cálculo ou ferramentas de BI, isto poupa imenso tempo.
E como a Thunderbit suporta scraping agendado, pode configurá-la para correr a cada hora, todos os dias ou em qualquer calendário personalizado — garantindo que os seus dados de notícias estão sempre atualizados. Nada de esperar que o Google Alerts indexe artigos dias depois.
Superando desafios operacionais em soluções de dados de notícias em tempo real
Mesmo com as melhores ferramentas, a extração de notícias em tempo real traz os seus próprios desafios. Veja como lidar com os mais comuns:
Gerindo latência e frescura dos dados
- Agende extrações com base na velocidade da notícia: para notícias urgentes, configure o scraper para correr a cada 15–30 minutos (alinhado com o ). Para temas mais lentos, uma execução diária ou de hora a hora pode ser suficiente.
- Monitorize o atraso entre publicação e captura: acompanhe a diferença entre o momento em que um artigo é publicado e quando o seu sistema o recolhe. Se o atraso aumentar, verifique bloqueios ou lentidão.
- Volte a extrair para “edições silenciosas”: os artigos de notícias são frequentemente atualizados após a publicação. Agende uma segunda extração 24 horas depois para captar correções ou edições discretas ().
Lidando com limites de API e variação das fontes
- Respeite as quotas de API: se usar APIs de notícias, tenha atenção aos limites de pedidos — distribua as chamadas ao longo do tempo e guarde resultados em cache sempre que possível ().
- Desduplicar e canonizar: histórias de notícias muitas vezes aparecem em várias URLs ou são atualizadas. Capture URLs canónicas e use hashes (por exemplo, título + data) para evitar duplicados ().
- Lidar com conteúdo dinâmico: em sites com infinite scroll ou lazy loading, use ferramentas que suportem renderização dinâmica e acompanhem mudanças de layout ().
Análise inteligente de dados de notícias: o papel da IA e do machine learning
Extrair notícias é só o primeiro passo. O verdadeiro valor vem de analisar e agir sobre esses dados — e é aí que IA e machine learning brilham.
- Extração de entidades: use NLP para identificar pessoas, organizações e locais mencionados em cada artigo ().
- Classificação de tópicos: marque automaticamente artigos por tema, sentimento ou urgência — criando dashboards e alertas mais inteligentes ().
- Agrupamento de eventos: agrupe histórias duplicadas ou relacionadas entre veículos, para ver o panorama geral — e não apenas uma enxurrada de manchetes quase idênticas.
- Personalização e segmentação: use dados de notícias em tempo real para segmentar públicos, melhorar a segmentação de anúncios ou recomendar conteúdo — aumentando o engagement e o ROI.
Por exemplo, equipas de PR usam análises de notícias em tempo real para detetar crises emergentes antes de se tornarem virais, enquanto equipas de vendas enriquecem listas de prospects com “eventos gatilho”, como rondas de investimento ou contratações executivas.
Checklist de melhores práticas para extração automatizada de notícias
Aqui está um checklist rápido para manter o seu pipeline de extração de notícias a funcionar sem problemas:
| Melhor prática | Porque é importante | Como implementar |
|---|---|---|
| Agende extrações frequentes | Minimiza o atraso dos dados e capta notícias de última hora | Ajuste a frequência à velocidade da notícia (por exemplo, a cada 15 min para temas rápidos) |
| Use extração orientada por IA | Adapta-se a mudanças de layout e reduz o tempo de configuração | Ferramentas como Thunderbit, Diffbot, Zyte API |
| Desduplique e canonize | Evita alertas duplicados e garante dados limpos | Capture URLs canónicas e use hashes para deduplicação |
| Monitorize a qualidade da extração | Deteta campos em falta, desvios ou falhas | Acompanhe a % de registos completos, a latência e as taxas de erro |
| Respeite limites legais e de conformidade | Evita risco jurídico e mantém a confiança | Prefira APIs/feeds oficiais, reveja os termos e minimize dados pessoais |
| Exporte para formatos estruturados | Permite análises posteriores | CSV, Excel, Sheets, Notion, Airtable |
| Agende novas extrações para edições | Capta alterações pós-publicação | Reavalie artigos após 24h/1 semana (modelo GDELT) |
| Proteja o seu pipeline | Protege dados sensíveis | Encriptação, controlos de acesso, ferramentas confiáveis |
Construindo um fluxo de trabalho robusto para extração automatizada de notícias
Pronto para criar a sua própria “caixa preta” para dados de notícias? Aqui vai um fluxo de trabalho passo a passo:
- Identifique as suas fontes: liste os sites de notícias, blogs ou APIs que quer monitorizar.
- Configure a extração: use a Thunderbit ou a ferramenta da sua preferência para definir os campos (o AI Suggest Fields facilita imenso).
- Agende as extrações: defina a frequência com base na velocidade da notícia — de hora a hora para breaking news, diariamente para temas mais lentos.
- Enriquecimento de subpáginas: para cada manchete, extraia o artigo completo para obter o texto, as entidades e as tags.
- Desduplicação e normalização: capture URLs canónicas, gere hashes dos registos e padronize os campos.
- Exportação e integração: envie os dados estruturados para Excel, Google Sheets, Airtable ou Notion para análise.
- Monitore e adapte: acompanhe a qualidade da extração, observe mudanças de layout e ajuste quando necessário.
- Mantenha a conformidade: reveja os termos, respeite o robots.txt e minimize dados pessoais.
Para visualizar o fluxo, pense assim:
Fontes → Extração (campos com IA) → Enriquecimento de subpáginas → Desduplicação → Exportação → Análise/Alertas → Monitorização
Conclusão e principais aprendizagens
A extração automatizada de notícias já não é um “bom ter” — é indispensável para qualquer pessoa que precise de se manter à frente num mundo em que as notícias surgem (e mudam) a cada minuto. Seguindo as melhores práticas e usando as ferramentas certas, pode transformar a torrente de notícias digitais num fluxo estável de inteligência estruturada e acionável.
Principais aprendizagens:
- A escala e a velocidade das notícias online exigem automação — o acompanhamento manual simplesmente não consegue acompanhar.
- As ferramentas de extração automatizada de notícias poupam tempo, reduzem custos e permitem que equipas pequenas tenham cobertura comparável à de organizações muito maiores.
- Escolher a ferramenta certa significa equilibrar facilidade de uso, segurança e adaptabilidade — a Thunderbit destaca-se pela simplicidade orientada por IA e pelas opções de exportação em tempo real.
- Estruture o seu fluxo em torno de frescura, desduplicação, conformidade e monitorização de qualidade para garantir dados de notícias fiáveis e acionáveis.
- IA e machine learning desbloqueiam ainda mais valor — com segmentação, personalização e tomada de decisão mais inteligentes.
Se ainda está a copiar e colar manchetes ou à espera que o Google Alerts apanhe o ritmo, é hora de evoluir. e veja como a extração automatizada de notícias pode ser simples. Para mais dicas, fluxos de trabalho e análises aprofundadas, consulte o .
FAQs
1. O que é a extração automatizada de notícias e como funciona?
A extração automatizada de notícias é o processo de usar software para recolher artigos de notícias e transformá-los em dados estruturados (como tabelas ou JSON) para análise, pesquisa ou alertas. Ferramentas como a Thunderbit usam IA para identificar campos-chave (manchete, timestamp, autor, texto do artigo) e extraí-los automaticamente de páginas da web ou APIs.
2. Porque é que os dados de notícias em tempo real são tão importantes para as empresas?
Os dados de notícias em tempo real permitem que as empresas reajam rapidamente a eventos de mercado, crises de PR ou movimentos da concorrência. Seja em vendas, PR ou pesquisa, ter notícias atualizadas significa tomar decisões mais rápidas e inteligentes e ficar à frente da concorrência.
3. Como é que a Thunderbit facilita o scraping de notícias para utilizadores sem perfil técnico?
A Thunderbit oferece um processo simples em duas etapas: descreva que dados quer e deixe a IA sugerir os campos. Com recursos como scraping de subpáginas e exportação instantânea para Excel ou Google Sheets, até utilizadores sem conhecimentos técnicos conseguem montar pipelines robustos de dados de notícias em minutos.
4. Quais são as considerações legais e de conformidade para web scraping de notícias?
Revise sempre os termos de serviço dos sites-alvo, prefira APIs ou feeds oficiais quando existirem e respeite as instruções do robots.txt. Evite extrair conteúdo com login obrigatório ou paywall sem permissão e minimize a recolha de dados pessoais para permanecer em conformidade com as leis de privacidade.
5. Como posso garantir que o meu fluxo de extração de notícias continua confiável ao longo do tempo?
Agende extrações regulares, monitorize a qualidade da extração e use ferramentas que se adaptem a mudanças de layout (como a extração orientada por IA da Thunderbit). Desduplique registos, acompanhe a latência entre publicação e extração e configure alertas para falhas ou campos em falta para manter o pipeline saudável e atualizado.
Saiba mais