

A raspagem web deixou de ser uma habilidade de nicho para se tornar um superpoder indispensável para quem trabalha com vendas, operações ou pesquisa de mercado. Com o volume de dados na web disparando — a criação global de dados aumentou em quase 193% de 2019 a 2023 — não é surpresa que 81% das empresas agora tratem os dados como o “coração” da tomada de decisão. Mas há um problema: 95% das organizações dizem que lidar com dados não estruturados (como HTML confuso) é um grande desafio. Já vi muitas equipas afogadas em maratonas de copiar e colar, tentando transformar informação de sites em folhas de cálculo — acredite, não é bonito.
Extrair dados de qualquer site usando IA Get Started Free
É aqui que entra o BeautifulSoup em Python. Neste tutorial prático, vou mostrar como usar o BeautifulSoup para raspagem web, com um exemplo real em Python que pode adaptar às necessidades do seu negócio. E, como o meu foco é trabalhar de forma mais inteligente — e não mais pesada — também vou mostrar como combinar o BeautifulSoup com o Thunderbit, o nosso Raspador Web IA, para acelerar o seu fluxo de trabalho e obter dados mais limpos e estruturados — independentemente do seu nível de programação.
O que é o BeautifulSoup e por que usá-lo para raspagem web?
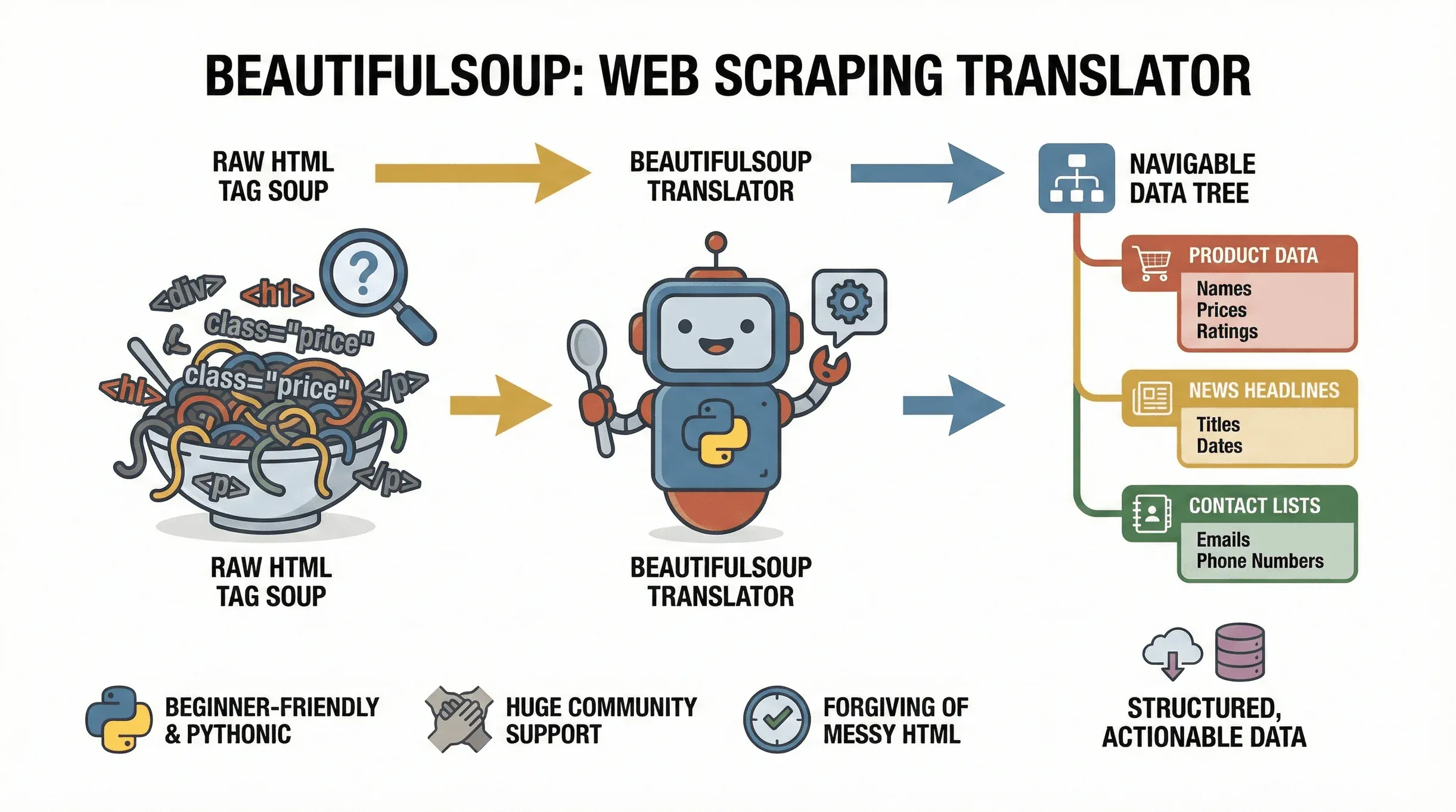 Vamos começar pelo básico. O BeautifulSoup é uma biblioteca Python que facilita a análise de documentos HTML e XML. Pense nele como um tradutor: pega no “tag soup” de uma página web e transforma-o numa árvore navegável, para que possa encontrar, extrair e manipular facilmente os dados de que precisa. O projeto continua a ser mantido ativamente — o
Vamos começar pelo básico. O BeautifulSoup é uma biblioteca Python que facilita a análise de documentos HTML e XML. Pense nele como um tradutor: pega no “tag soup” de uma página web e transforma-o numa árvore navegável, para que possa encontrar, extrair e manipular facilmente os dados de que precisa. O projeto continua a ser mantido ativamente — o beautifulsoup4 4.14.3 foi lançado no PyPI no fim de 2025 — por isso, tudo o que aprender aqui continua atual. Quer esteja a recolher preços de produtos num e-commerce, a reunir títulos de notícias ou a raspar diretórios de empresas em busca de leads, o BeautifulSoup é a ferramenta certa para transformar páginas web em dados estruturados e acionáveis.
Porque é que é tão popular? Para começar, é extremamente amigável para iniciantes. O BeautifulSoup tolera bem HTML desorganizado (e, convenhamos, a web está cheia dele), e a sua sintaxe em Python faz com que passe do zero à raspagem em apenas algumas linhas de código. Também tem um suporte enorme, com milhões de downloads e uma comunidade vasta — por isso, se ficar bloqueado, a ajuda está a uma pesquisa no Google de distância.
Casos de uso comuns do BeautifulSoup incluem:
- Extrair nomes de produtos, preços e avaliações de páginas de e-commerce
- Recolher títulos, autores e datas de publicação de sites de notícias
- Analisar tabelas ou diretórios (como listas de empresas ou contactos)
- Reunir e-mails ou números de telefone de sites de anúncios
- Monitorizar atualizações (alterações de preço, novas vagas de emprego etc.)
Se os seus dados estão em HTML estático, o BeautifulSoup é o seu melhor amigo para raspagem web.
As vantagens exclusivas do BeautifulSoup para raspagem web
Existem muitas bibliotecas Python de raspagem web por aí — então por que escolher o BeautifulSoup? Veja como ele se compara à concorrência:
- Simplicidade: o BeautifulSoup é leve e fácil de aprender. Não precisa de montar uma estrutura inteira nem de escrever muito código repetitivo. É perfeito para tarefas rápidas e pontuais ou para quem está a começar.
- Tolerância: consegue lidar com HTML quebrado ou malformado, algo mais comum do que parece.
- Flexibilidade: não fica preso a uma arquitetura rígida de crawling. Basta alimentar a ferramenta com HTML e extrair o que precisa.
- Integração: o BeautifulSoup funciona muito bem com outras bibliotecas Python, como
requests(para obter páginas),csv(para guardar dados) epandas(para análise de dados).
Como se compara a outras ferramentas?
| Ferramenta | Ideal para | Vantagens | Desvantagens |
|---|---|---|---|
| BeautifulSoup | Análise de HTML estático, iniciantes | Simples, configuração rápida, tolerante, flexível | Não é ideal para sites com muito JavaScript |
| Scrapy | Tarefas assíncronas em grande escala | Poderoso, escalável, crawling integrado | Curva de aprendizagem mais íngreme, mais configuração |
| Selenium | Conteúdo dinâmico/JavaScript | Interage com JS, preenche formulários, clica em botões | Mais lento, mais pesado, consome mais recursos |
Se está a começar ou precisa de analisar rapidamente páginas estáticas, o BeautifulSoup é o “canivete suíço” da raspagem web (medium.com). Para sites mais complexos ou dinâmicos, talvez valha a pena combiná-lo com Selenium ou Scrapy — mas o BeautifulSoup é a melhor forma de aprender os fundamentos.
Configurando o seu ambiente Python para BeautifulSoup
Pronto para começar? Veja como configurar o seu ambiente:
-
Instale o Python: descarregue a versão mais recente em python.org.
-
Crie um ambiente virtual (opcional, mas recomendado):
python -m venv venv source venv/bin/activate # No Windows: venv\Scripts\activate -
Instale o BeautifulSoup e as dependências:
pip install beautifulsoup4 requests lxml html5libbeautifulsoup4: a biblioteca principalrequests: para obter páginas weblxmlouhtml5lib: analisadores HTML mais rápidos e/ou mais fiáveis
-
Dicas de resolução de problemas:
- Se aparecer o erro “pip not found”, tente
pip3oupy -m pip. - No Mac/Linux, talvez seja necessário usar
sudopor questões de permissões. - Se estiver no Windows, confirme que o Python foi adicionado ao PATH.
- Se aparecer o erro “pip not found”, tente
Para verificar a sua configuração, execute este teste rápido:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Se vir <title>Example Domain</title>, está tudo certo (Thunderbit Blog).
Um exemplo passo a passo de Beautiful Soup em Python
Vamos a um exemplo real de python beautiful soup. Imagine que quer extrair as últimas manchetes de notícias de um site público. Veja como fazer:
1. Buscar a página web
import requests
from bs4 import BeautifulSoup
url = "https://www.bbc.com/news"
response = requests.get(url)
html = response.text
2. Analisar o HTML
soup = BeautifulSoup(html, "html.parser")
3. Inspecionar a estrutura do HTML
Abra as Ferramentas de Programador do navegador (clique com o botão direito → Inspecionar) e procure as tags que contêm as manchetes. Em muitos sites de notícias, os títulos estão em tags <h3> com classes específicas.
Por exemplo, poderá ver:
<h3 class="gs-c-promo-heading__title">Título da Manchete</h3>
4. Extrair os dados
headlines = soup.find_all("h3", class_="gs-c-promo-heading__title")
for h in headlines:
print(h.get_text(strip=True))
Isto vai mostrar todas as manchetes da página.
5. Guardar os dados em CSV
Vamos guardar essas manchetes para análise posterior:
import csv
with open("headlines.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["manchete"])
for h in headlines:
writer.writerow([h.get_text(strip=True)])
Agora tem um ficheiro CSV pronto para Excel ou Google Sheets.
Entendendo a estrutura HTML para extrair dados com eficiência
Antes de escrever qualquer código, inspecione sempre o HTML da página. Veja como:
- Abra as Ferramentas de Programador: clique com o botão direito na página e selecione “Inspecionar”.
- Encontre os dados: passe o rato sobre os elementos para ver quais as tags que contêm as informações desejadas (por exemplo, manchetes, preços, autores).
- Observe as tags e classes: procure identificadores exclusivos como
class="product-title"ouid="main-content". - Teste os seus seletores: use os métodos
.find(),.find_all()ou.select()do BeautifulSoup para localizar esses elementos.
Dica profissional: use soup.prettify() para imprimir uma versão legível do HTML no terminal do Python.
Extraindo e estruturando dados com BeautifulSoup
Vamos supor que quer extrair títulos e autores de uma página de blogue:
articles = soup.find_all("article")
data = []
for article in articles:
title = article.find("h2").get_text(strip=True)
author = article.find("span", class_="author").get_text(strip=True)
data.append({"title": title, "author": author})
Agora tem uma lista de dicionários — perfeita para exportar para CSV ou fazer análises mais aprofundadas.
Pode extrair links, imagens ou qualquer atributo desta forma:
for link in soup.find_all("a"):
print(link.get("href"))
Ou imagens:
for img in soup.find_all("img"):
print(img.get("src"))
Guardando os dados extraídos: de Python para Excel ou CSV
Depois de os seus dados estarem estruturados, exportar é fácil. Veja como fazer isso com o módulo csv:
import csv
with open("articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
Ou, se preferir o pandas:
import pandas as pd
df = pd.DataFrame(data)
df.to_csv("articles.csv", index=False)
df.to_excel("articles.xlsx", index=False)
Use sempre a codificação UTF-8 para evitar problemas com caracteres estranhos, especialmente quando lidar com dados internacionais.
Estudo de caso: raspando dados de um site de notícias com BeautifulSoup
Vamos ver um exemplo prático de python beautiful soup: extrair títulos de artigos, autores e datas de publicação de um site de notícias.
Suponha que quer raspar a CNN para obter dados de artigos:
import requests
from bs4 import BeautifulSoup
import csv
url = "https://edition.cnn.com/world"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
articles = soup.find_all("article")
data = []
for article in articles:
title_tag = article.find("h3")
date_tag = article.find("span", class_="date")
author_tag = article.find("span", class_="author")
title = title_tag.get_text(strip=True) if title_tag else ""
date = date_tag.get_text(strip=True) if date_tag else ""
author = author_tag.get_text(strip=True) if author_tag else ""
data.append({"title": title, "date": date, "author": author})
with open("cnn_articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "date", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
Este script vai buscar os artigos mais recentes, extrair título, data e autor, e guardá-los num CSV — assumindo que a marcação atual da CNN ainda corresponda às tags acima. Os grandes sites de notícias mudam frequentemente os nomes das classes e a estrutura do DOM, por isso volte a inspecionar a página antes de usar isto em dados de produção. A estrutura (<article> como contentor, seguido de find nas tags-filhas) é o padrão mais duradouro; nomes específicos de classes como "date" e "author" são apenas exemplos que deve ajustar ao que a página real estiver a mostrar hoje.
Melhorando o seu fluxo de trabalho: combinando BeautifulSoup com Thunderbit
Agora, vamos falar sobre como tornar o seu fluxo de raspagem ainda mais eficiente. O Thunderbit é uma extensão do Chrome de raspagem web com IA que elimina as suposições da extração de dados. Com o Thunderbit, pode:
- Usar “AI Suggest Fields”: o Thunderbit lê a página e sugere automaticamente quais os campos de dados a extrair — sem precisar de vasculhar o HTML ou ajustar seletores.
- Raspar subpáginas: o Thunderbit pode seguir links para subpáginas (como páginas individuais de produtos ou artigos) e enriquecer o seu conjunto de dados com detalhes extra.
- Exportar instantaneamente: envie os seus dados diretamente para Excel, Google Sheets, Airtable ou Notion com um clique.
- Lidar com paginação: o Thunderbit consegue raspar dados em várias páginas (incluindo rolagem infinita).
- Agendar raspagens: configure tarefas recorrentes para manter os seus dados sempre atualizados.
Aqui vai um fluxo híbrido de que gosto muito:
- Comece com o Thunderbit: abra o site de destino, clique no ícone do Thunderbit e deixe o “AI Suggest Fields” identificar as colunas certas (como título, autor e data).
- Exporte os dados: descarregue os resultados em CSV ou envie-os para o Google Sheets.
- Use o BeautifulSoup para processamento personalizado: se precisar de fazer análises mais profundas (como limpeza de texto, deduplicação ou combinação com outras fontes), carregue o CSV exportado no Python e use BeautifulSoup ou pandas para o pós-processamento.
Esta combinação oferece o melhor dos dois mundos: a rapidez e a deteção de campos com IA do Thunderbit, além da flexibilidade do BeautifulSoup para lógica personalizada.
Experimente gratuitamente o Raspador Web IA do Thunderbit
Velocidade e qualidade dos dados: por que usar Thunderbit e BeautifulSoup juntos?
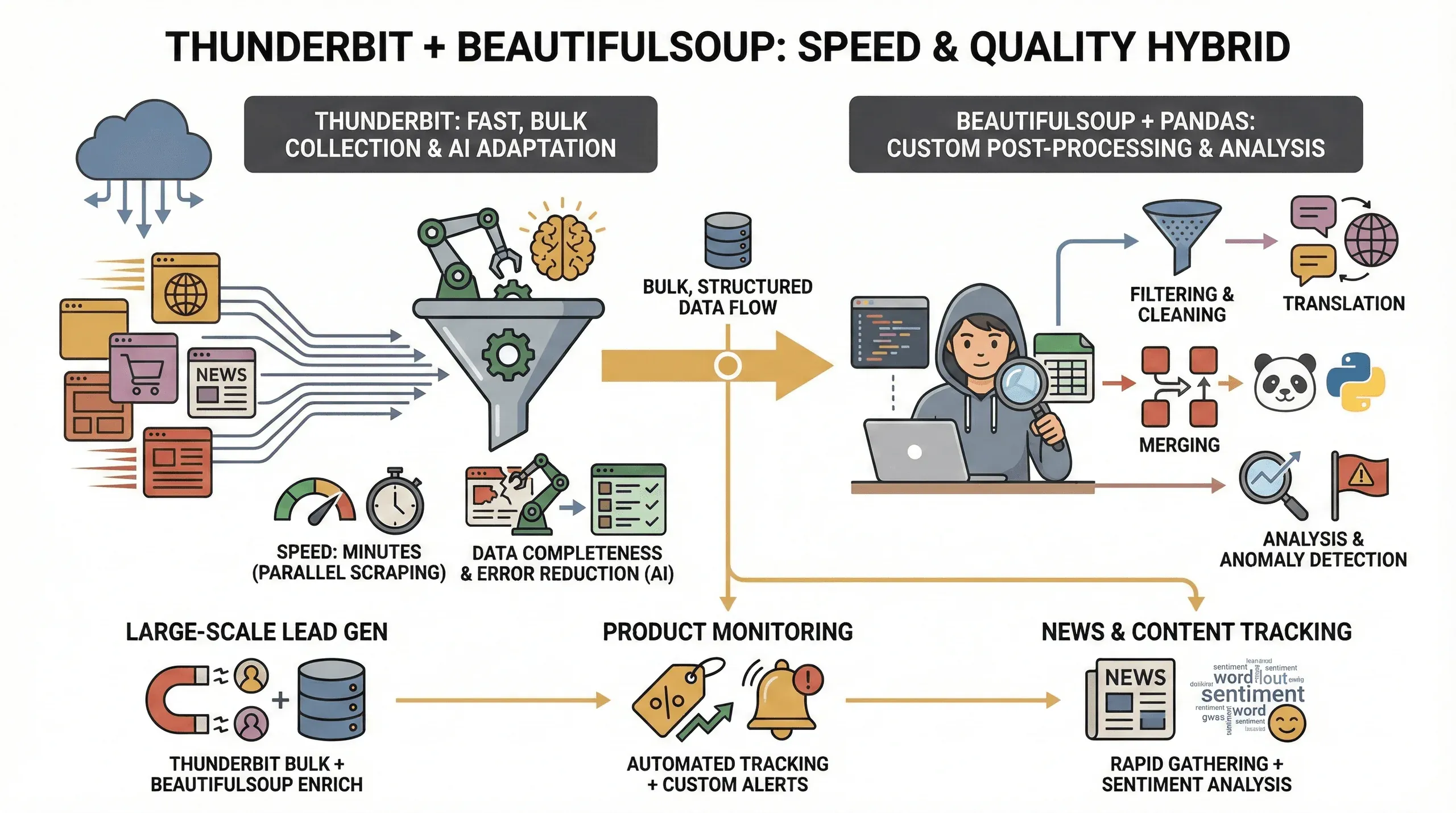 Por que usar as duas ferramentas? Foi isto que descobri:
Por que usar as duas ferramentas? Foi isto que descobri:
- Velocidade: o Thunderbit pode raspar dezenas de páginas em paralelo (até 50 de cada vez no modo na nuvem), por isso recebe os dados em minutos, não em horas.
- Completude dos dados: a IA do Thunderbit adapta-se a mudanças de layout e consegue extrair dados estruturados até de sites complicados, reduzindo a hipótese de campos em falta.
- Redução de erros: nada de scripts partidos quando um nome de classe muda — a IA do Thunderbit reavalia a página a cada execução.
- Pós-processamento personalizado: para necessidades avançadas (como filtragem, tradução ou junção de conjuntos de dados), BeautifulSoup e pandas dão-lhe controlo total.
Esta abordagem híbrida é especialmente valiosa para:
- Geração de leads em grande escala: use o Thunderbit para captar os dados em volume e depois o BeautifulSoup para os limpar e enriquecer.
- Monitorização de produtos: o Thunderbit trata da raspagem repetitiva, enquanto o BeautifulSoup permite analisar tendências ou identificar anomalias.
- Acompanhamento de notícias e conteúdo: reúna artigos rapidamente com o Thunderbit e depois use Python para análise de sentimento ou extração de palavras-chave.
Solução de problemas comuns em raspagem web com BeautifulSoup
Experimente a extensão Chrome do Thunderbit Extraia qualquer site com IA em 2 cliques. Get Started Free
A raspagem web nem sempre é simples — aqui ficam algumas armadilhas comuns e como as resolver:
- Conteúdo dinâmico: se um site carregar dados com JavaScript (rolagem infinita, AJAX), o BeautifulSoup sozinho não vai ver isso. Use Selenium ou o modo de navegador do Thunderbit nesses casos.
- Medidas anti-bot: alguns sites bloqueiam pedidos automatizados. Tente definir um cabeçalho User-Agent personalizado, adicione atrasos entre pedidos ou use a raspagem na nuvem do Thunderbit para contornar bloqueios simples.
- Alterações na estrutura do HTML: se o seu script deixar de funcionar de repente, provavelmente o HTML do site mudou. Inspecione a página novamente e atualize os seus seletores. A IA do Thunderbit pode ajudar aqui, adaptando-se automaticamente.
- Dados em falta: confirme sempre se os elementos existem antes de chamar
.get_text(). Use.get()em vez de[]para atributos, evitando KeyErrors. - Problemas de codificação: guarde os ficheiros em UTF-8 para lidar com caracteres especiais.
E, acima de tudo, respeite sempre o robots.txt e os termos de serviço do site. Faça raspagem de forma responsável — ninguém gosta de um robô mal-educado.
Conclusão e principais aprendizagens
A raspagem web com BeautifulSoup é uma das competências mais práticas que pode aprender no mundo orientado por dados de hoje. Veja o que cobrimos neste tutorial de raspagem web com BeautifulSoup:
- BeautifulSoup é o ponto de partida ideal para analisar HTML estático e extrair dados estruturados com Python.
- A configuração é simples — basta instalar Python, pip e algumas bibliotecas.
- Inspecionar o HTML é essencial para chegar aos dados certos.
- Exportar para CSV/Excel torna os seus dados imediatamente utilizáveis para análise de negócios.
- Combinar com o Thunderbit traz deteção de campos com IA, raspagem mais rápida e exportações mais fáceis — perfeito para utilizadores de negócios e pessoas que não programam.
- Fluxos híbridos (Thunderbit para extração em massa, BeautifulSoup para processamento personalizado) oferecem a melhor combinação de velocidade, qualidade de dados e flexibilidade.
Se quer elevar o seu nível em raspagem web, experimente as duas ferramentas: teste um script simples com BeautifulSoup e veja o quanto consegue acelerar com o Raspador Web IA do Thunderbit. E, para mais guias práticos, consulte o Blog do Thunderbit.
Boa raspagem — e que os seus dados estejam sempre limpos, estruturados e prontos para agir.
Experimente o Raspador Web IA do Thunderbit Get Started Free
FAQs
1. O que é o BeautifulSoup e para que serve?
BeautifulSoup é uma biblioteca Python para analisar documentos HTML e XML. Ajuda-o a extrair dados de páginas web e a transformá-los em formatos estruturados, como listas ou tabelas, sendo ideal para projetos de raspagem web.
2. Como o BeautifulSoup se compara ao Selenium e ao Scrapy?
O BeautifulSoup é leve e fácil de usar em páginas HTML estáticas. O Selenium é melhor para raspar sites dinâmicos, com muito JavaScript, enquanto o Scrapy é uma estrutura completa para raspagem assíncrona em grande escala. O BeautifulSoup é a melhor escolha para iniciantes e tarefas rápidas.
3. Posso usar BeautifulSoup e Thunderbit em conjunto?
Com certeza. O Thunderbit consegue identificar e extrair rapidamente campos de páginas usando IA, e pode usar o BeautifulSoup para pós-processamento personalizado ou análises mais profundas dos dados exportados.
4. Quais são os desafios mais comuns na raspagem web com BeautifulSoup?
Os problemas mais comuns incluem lidar com conteúdo dinâmico, enfrentar medidas anti-bot e adaptar-se a mudanças na estrutura do HTML. Usar os recursos de IA do Thunderbit ou o modo de navegador pode ajudar a ultrapassar muitos destes desafios.
5. Como exporto para Excel ou CSV os dados raspados com BeautifulSoup?
Pode usar o módulo csv nativo do Python ou a biblioteca pandas para gravar os dados extraídos em ficheiros CSV ou Excel. Use sempre codificação UTF-8 para lidar com caracteres especiais e garantir compatibilidade com ferramentas de folha de cálculo.
Pronto para testar por si? Descarregue a Extensão Chrome do Thunderbit e comece hoje mesmo a raspar de forma mais inteligente. Para mais tutoriais e dicas, visite o Blog do Thunderbit.
Saiba mais




