Um estudo baseado em crawl sobre como sites de alto tráfego estão publicando orientações legíveis por máquina para grandes modelos de linguagem, como são as primeiras implementações e por que medir a adoção exige mais do que contar respostas HTTP 200.
- Dataset:
data/llms_probe_results_top_10000.csv - Lista Tranco baixada: 6 de maio de 2026
- Escopo:
/llms.txte/llms-full.txtna raiz do site
Principais métricas
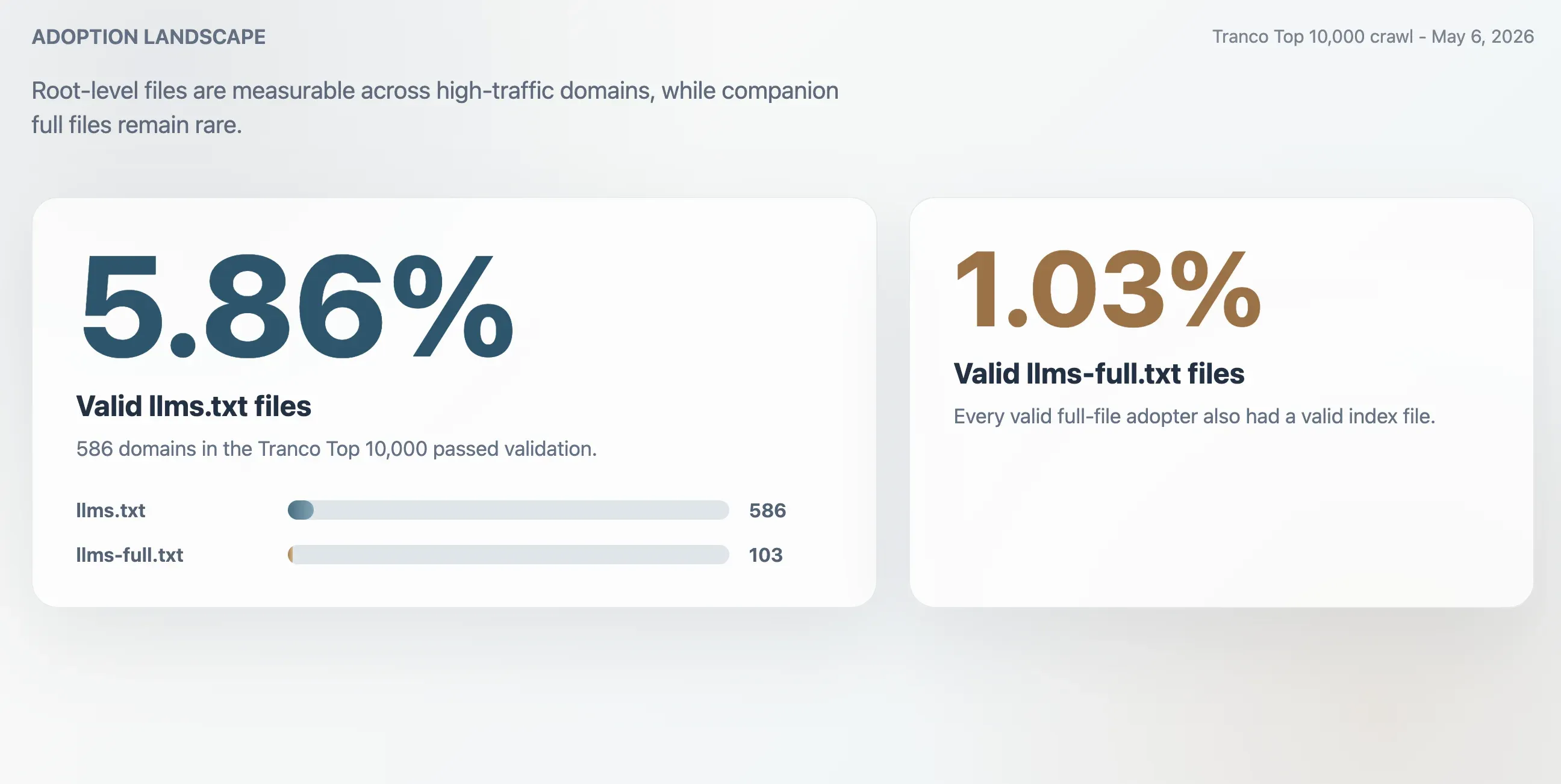
- 5,86%: adoção válida de
llms.txtentre os 10.000 domínios do Tranco, equivalente a 586 domínios. - 1,03%: adoção válida de
llms-full.txt, equivalente a 103 domínios. Todo site com um arquivo completo válido também tinha um arquivo de índice válido. - 63,51%: parcela das respostas HTTP 200 de
/llms.txtque falharam na validação. - 2,74x: superestimação aproximada se a adoção fosse medida apenas por respostas HTTP 200 brutas.
Resumo executivo
llms.txt ainda é uma convenção web inicial, mas já deixou de ser um experimento de nicho. Em um crawl de 6 de maio de 2026 sobre os 10.000 domínios do Tranco, este estudo encontrou 586 arquivos llms.txt válidos, para uma taxa observada de adoção de 5,86%. O arquivo complementar llms-full.txt era bem menos comum: 103 domínios tinham um arquivo completo válido, o que representa 1,03% de adoção.
A principal descoberta metodológica é que códigos de status são um péssimo proxy de adoção. O crawler encontrou 1.606 respostas HTTP 200 para /llms.txt, mas apenas 586 passaram na validação. As outras 1.020 eram, em sua maioria, redirecionamentos para destinos errados, páginas HTML genéricas, corpos vazios ou outras respostas inválidas. Um crawler ingênuo que contasse toda resposta 200 como adoção superestimaria a adoção válida em cerca de 2,74 vezes.
Entre os adotantes válidos, a qualidade da implementação é maior do que a narrativa de “apenas um placeholder” sugere. O arquivo válido mediano tinha cerca de 7,1 KB, 61,77% dos arquivos válidos tinham mais de 5 KB, 70,82% continham seis ou mais seções Markdown e 77,47% continham 11 ou mais links em Markdown. O conjunto de primeiros adotantes inclui Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog e Cloudinary.
llms.txté melhor entendido como um sinal explicativo e de navegação para sistemas de IA, não como substituto derobots.txt. Seu valor não está apenas em existir, mas em ajudar as máquinas a encontrar informações autoritativas, compactas e atualizadas.
Contexto: a web está adicionando sinais voltados à IA
Os sites há muito usam robots.txt para expressar preferências de rastreamento, sitemap.xml para melhorar a descoberta de URLs e dados estruturados para ajudar mecanismos de busca e plataformas a interpretar páginas. A IA generativa introduz um problema diferente. O conteúdo pode ser usado para treinamento, recuperação, resumo, navegação agentiva, assistência de código, suporte ao cliente e geração de respostas. Isso cria duas necessidades simultâneas: os editores querem mais controle sobre o uso automatizado, mas também querem que os sistemas de IA encontrem as informações canônicas corretas quando interagem com seus sites.
A , apresentada por Jeremy Howard em 2024, descreve o arquivo como um documento Markdown colocado na raiz do site para fornecer informações amigáveis para LLMs no momento da inferência. A proposta argumenta que páginas HTML costumam incluir navegação, anúncios, scripts e outros ruídos que dificultam o processamento por modelos de linguagem. Um arquivo Markdown conciso pode direcionar os modelos para as páginas, docs, APIs, exemplos, políticas e informações de produto mais importantes.
Pesquisas externas na web oferecem o pano de fundo mais amplo. O descreve um aumento rápido de restrições relacionadas à IA em robots.txt e nos termos de serviço, e argumenta que os mecanismos existentes de consentimento na web não foram projetados para reutilização de dados de IA em grande escala. O também tornou visíveis padrões de crawlers de IA e de robots.txt no nível dos 10.000 principais domínios. Nesse contexto, llms.txt fica do lado construtivo da sinalização para IA: não é “não rastreie isto”, mas sim “se você precisa entender este site, comece aqui”.
Evidências externas e o debate sobre adoção
O debate público em torno de llms.txt se divide entre duas posições. A visão otimista é que o arquivo oferece aos sistemas de IA um caminho mais limpo e eficiente até conteúdo autoritativo. A visão cética é que nenhum grande provedor de LLMs se comprometeu publicamente a usá-lo como sinal de ranqueamento, rastreamento ou citação, então os editores não devem esperar ganhos de tráfego apenas por publicá-lo. As três referências externas analisadas para esta atualização apontam para uma conclusão mais nuançada: llms.txt é uma infraestrutura útil, mas as evidências de impacto direto no tráfego ainda são limitadas e dependentes do contexto.
As referências externas de adoção estão mudando rapidamente
O relatou uma taxa de adoção de 0,3% entre os 1.000 principais sites em 22 de junho de 2025, ou 3 de 1.000 sites. A descrição fala em varredura automatizada mensal de domain.com/llms.txt, com validação que exclui redirecionamentos e respostas HTML. Essa metodologia é, em termos gerais, semelhante à abordagem conservadora de validação deste estudo.
A diferença nos resultados é grande: este estudo encontrou 75 arquivos llms.txt válidos entre os 1.000 principais do Tranco em 6 de maio de 2026, ou 7,50%. Os dois números não devem ser tratados como uma série temporal rígida, porque a fonte do ranking, os detalhes de implementação, a lógica de validação e o timing do crawl podem ser diferentes. Ainda assim, o contraste sugere que a adoção mudou de forma material entre meados de 2025 e maio de 2026, especialmente entre sites com forte presença de conteúdo para desenvolvedores, SaaS, cloud, segurança e documentação.
| Fonte | Snapshot | Amostra | Adoção válida relatada | Interpretação |
|---|---|---|---|---|
| Rankability | 22 de junho de 2025 | 1.000 principais sites | 0,3% | Benchmark público inicial mostrando adoção mínima em meados de 2025. |
| Este estudo | 6 de maio de 2026 | Top 1.000 do Tranco | 7,50% | Crawl mais recente mostrando adoção visível entre sites de alto tráfego. |
| Este estudo | 6 de maio de 2026 | Top 10.000 do Tranco | 5,86% | Amostra mais ampla mostrando que a adoção é mensurável, mas ainda não é mainstream. |
Os experimentos de tráfego continuam mistos
O publicou, em janeiro de 2026, uma análise de 10 sites que acompanhou cada site por 90 dias antes e 90 dias depois da implementação. O artigo relatou que dois sites tiveram aumentos de tráfego de IA de 12,5% e 25%, oito não mostraram melhora mensurável e um caiu 19,7%. A interpretação central foi de cautela causal: os dois casos aparentemente bem-sucedidos também lançaram novos templates, reformularam centros de recursos, adicionaram tabelas de comparação extraíveis, ganharam cobertura na imprensa, corrigiram problemas técnicos ou publicaram novos conteúdos em formato de FAQ. Nesse enquadramento, llms.txt documentou um trabalho mais forte de conteúdo e de tecnologia; não parece ter causado o crescimento sozinho.
O chegou a uma conclusão mais positiva a partir de uma observação menor, em nível de site. Ele comparou dois períodos de quatro meses no Yandex.Metrica após adicionar llms.txt e llms-full.txt. As sessões de referência vindas de LLMs subiram de 75 para 92, um aumento de 23%, enquanto o número de usuários subiu de 51 para 64. As sessões do Perplexity aumentaram de 29 para 55, enquanto as do ChatGPT caíram de 31 para 26. O mesmo post também observa que o tráfego total de referência cresceu mais rapidamente, de 160 para 290 sessões, então a participação das sessões de LLM caiu de 47% para 32%.
This paragraph contains content that cannot be parsed and has been skipped.
O que o debate esclarece
As evidências externas refinam a interpretação deste conjunto de dados. Um arquivo llms.txt bem estruturado pode reduzir o atrito de leitura por máquinas, especialmente para documentação de desenvolvedores, referências de API e conteúdo de base de conhecimento. Mas os casos mais fortes de tráfego ainda parecem depender de conteúdo útil, extraível, autoritativo e descobrível fora do arquivo. Por isso, a pergunta prática não é “llms.txt importa?” isoladamente. É se o arquivo faz parte de um sistema mais amplo de conteúdo legível por IA.
Interpretação atualizada:
llms.txtdeve ser implementado como infraestrutura de baixo custo voltada à IA. Não deve ser posicionado como substituto de melhor documentação, conteúdo estruturado, acessibilidade técnica, citações, links ou autoridade de marca.
Metodologia
Este estudo usou os 10.000 domínios do Tranco como amostra. O Tranco é um ranking de sites principais voltado para pesquisa, projetado para ser mais estável e resistente à manipulação do que muitas listas tradicionais. O arquivo-fonte do Tranco foi baixado em 6 de maio de 2026, com carimbo de Last-Modified de 5 de maio de 2026 às 22:17:59 GMT.
O crawler testou dois caminhos na raiz de cada domínio:
https://example.com/llms.txt, com fallback para HTTP quando necessário.https://example.com/llms-full.txt, com fallback para HTTP quando necessário.
Para cada teste, o crawler registrou código de status, URL final, método de busca, bytes de resposta, tipo de conteúdo, mensagem de erro, tempo decorrido e resultado da validação. Os corpos de resposta bem-sucedidos foram salvos em raw_llms_txt/ para revisão e análise secundária.
Regras de validação
Uma resposta só foi contada como arquivo válido se retornasse um corpo bem-sucedido e não parecesse um fallback genérico da web. O caminho da URL final precisava permanecer em /llms.txt ou /llms-full.txt. Corpos vazios foram rejeitados. Documentos HTML evidentes e shells de aplicativo foram rejeitados. O tipo de conteúdo foi tratado como evidência de apoio, e não como única regra, porque um pequeno número de arquivos válidos de aparência textual foi servido com tipos de conteúdo incomuns.
Panorama da adoção
O crawl encontrou 586 arquivos llms.txt válidos entre os 10.000 domínios do Tranco. Isso resulta em uma taxa de adoção válida de 5,86%. O arquivo complementar menor, llms-full.txt, estava presente e válido em 103 domínios, ou 1,03% da amostra.
| Métrica | Contagem | Participação no Top 10.000 |
|---|---|---|
| Domínios rastreados | 10.000 | 100,00% |
| Arquivos llms.txt válidos | 586 | 5,86% |
| Arquivos llms-full.txt válidos | 103 | 1,03% |
| Respostas HTTP 200 para /llms.txt | 1.606 | 16,06% |
| Respostas HTTP 200 rejeitadas como inválidas | 1.020 | 10,20% |
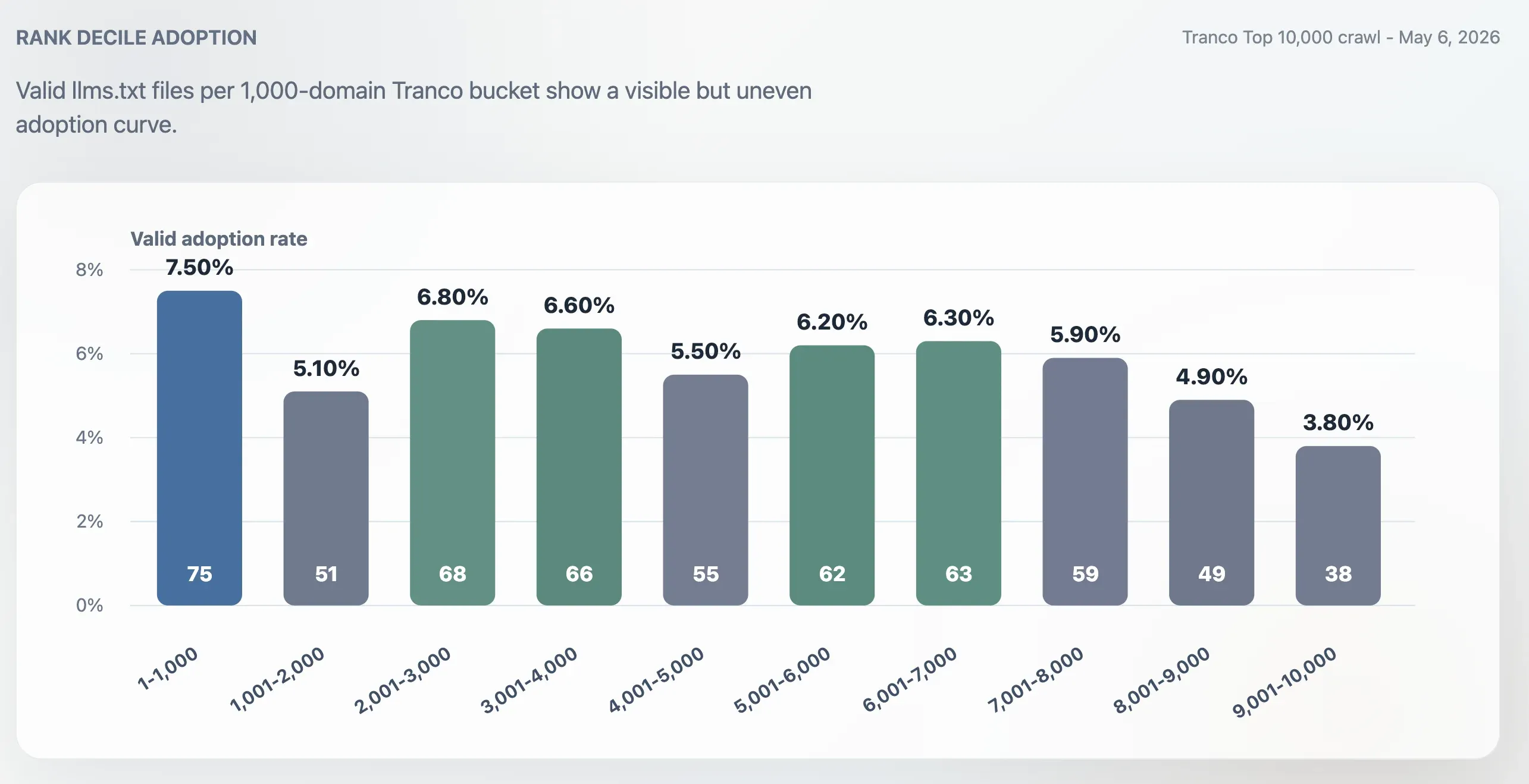
A adoção não é apenas concentrada no topo
A adoção foi maior no Top 1.000 do que no Top 10.000 completo, mas não ficou restrita aos maiores sites. A taxa de adoção no Top 1.000 foi de 7,50%. O último bloco de 1.000 domínios, entre as posições 9.001 e 10.000, caiu para 3,80%. O meio do ranking permaneceu ativo: os blocos 2.001-3.000, 3.001-4.000, 5.001-6.000 e 6.001-7.000 ficaram todos em torno de 6%.
Primeiros adotantes
O adotante válido mais bem classificado foi a Cloudflare, na posição 4 do Tranco. Outros adotantes bem ranqueados incluem Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink e OneSignal.
Esses adotantes não são aleatórios. Em geral, eles têm grandes superfícies de documentação, linhas de produto que exigem explicação, APIs ou ecossistemas de desenvolvedores, conteúdo de suporte, páginas de preços, material de segurança e privacidade e autoridade de marca suficiente para se preocupar com a forma como os sistemas de IA interpretam seus sites.
| Rank | Domínio | Tamanho do arquivo | Padrão observado |
|---|---|---|---|
| 4 | cloudflare.com | 4.225 B | Índice conciso de produto, desenvolvedor, empresa e preços. |
| 26 | azure.com | 47.037 B | Ferramentas para desenvolvedores, IA, compute, storage, segurança, monitoramento e recursos opcionais. |
| 28 | github.com | 27.108 B | Acesso programático, Copilot, MCP, API REST, Actions, repositórios e links da CLI. |
| 248 | stripe.com | 64.229 B | Pagamentos, Connect, Checkout, Billing, Tax, Atlas, Radar e docs para desenvolvedores. |
| 265 | salesforce.com | 1,02 MB | Catálogo massivo de produtos e links do Agentforce, sem títulos de seção Markdown. |
Categorias dos adotantes no Top 1.000
Este estudo classificou os 75 adotantes válidos no Top 1.000 do Tranco usando contexto de domínio, primeiros títulos, estrutura bruta do arquivo e palavras-chave de conteúdo. O maior grupo foi marketing, mídia e adtech, com 22,67%. Sites de cloud, desenvolvimento e infraestrutura responderam por 20,00%. Sites de SaaS, produtividade e operações de clientes responderam por 17,33%. Sites de segurança, identidade e privacidade responderam por 12,00%.
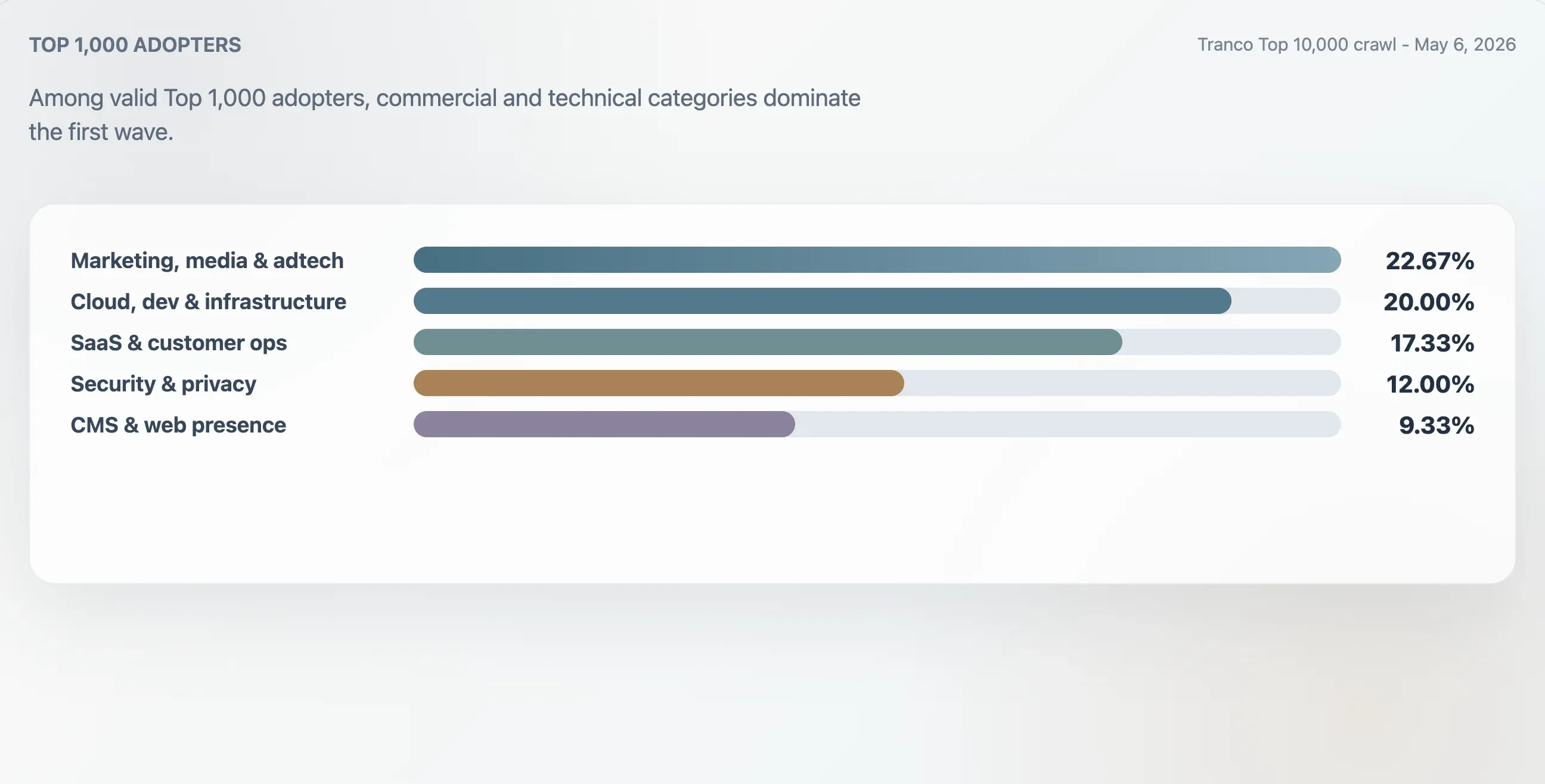
| Categoria | Domínios | Participação entre os adotantes do Top 1.000 | Pontuação mediana de qualidade | Links medianos |
|---|---|---|---|---|
| Marketing, mídia e adtech | 17 | 22,67% | 94 | 25 |
| Cloud, dev e infraestrutura | 15 | 20,00% | 94 | 62 |
| SaaS, produtividade e operações de clientes | 13 | 17,33% | 94 | 46 |
| Segurança, identidade e privacidade | 9 | 12,00% | 98 | 78 |
| CMS, hosting e presença web | 7 | 9,33% | 100 | 24 |
Padrões de TLD
Os domínios de topo não são rótulos de setor, mas funcionam como sinais direcionais úteis. Entre os TLDs com pelo menos 50 domínios na amostra, .io teve a maior taxa de adoção válida, com 14,44%. .com veio em seguida, com 8,19%. A menor adoção em .gov, .edu e .net sugere que a base inicial de adotantes é mais comercial e técnica do que institucional.
Qualidade de implementação
Adoção válida não significa qualidade uniforme de implementação. Alguns arquivos são índices concisos e bem seccionados. Alguns são majoritariamente texto corrido. Alguns são catálogos brutos de links. Alguns são placeholders quase vazios. Alguns são despejos de conteúdo de vários megabytes que podem estar completos, mas são caros para buscar e processar.
Entre os arquivos llms.txt válidos, 362 tinham mais de 5 KB, ou 61,77% dos adotantes válidos. O tamanho mediano do arquivo foi de cerca de 7,1 KB. O tamanho no P90 foi 156 KB, no P95 foi 356 KB, no P99 foi 2,54 MB, e o maior arquivo observado foi de 7,97 MB.
Sinais comuns de conteúdo
Uma varredura por palavras-chave em arquivos válidos mostrou que muitos sites não estão apenas publicando uma declaração; estão apontando os modelos para material operacionalmente útil. Termos de suporte ou ajuda apareceram em 70,31% dos arquivos válidos. Termos como blog, guia ou tutorial apareceram em 67,92%. Termos de segurança, privacidade, conformidade ou termos apareceram em 61,43%. Preços apareceram em 53,92%, documentação em 52,22%, termos de API em 33,96% e sinais de changelog ou release em 27,30%.
Pontuação de qualidade e arquétipos
Para ir além da presença e avaliar maturidade, este estudo criou uma pontuação leve de implementação. A pontuação considera tipo de conteúdo, tamanho do arquivo, estrutura Markdown, contagem de links, cobertura temática e sinais de alerta como ausência de títulos, falta de links em Markdown, tipos de conteúdo incomuns, arquivos minúsculos, arquivos muito grandes e comportamento de link-dump. Isso não é um padrão formal. É um modelo de pontuação de pesquisa para comparar implementações observadas.
Usando esse modelo, 416 arquivos válidos foram classificados como índices estruturados fortes, 107 como índices utilizáveis, 24 como finos ou irregulares, e 39 como simbólicos ou de baixa utilidade. Uma análise separada de arquétipos encontrou 296 índices estruturados, 113 arquivos de texto seccionado, 63 catálogos de links, 52 índices finos, 50 arquivos simbólicos ou placeholder e 12 despejos massivos de conteúdo.
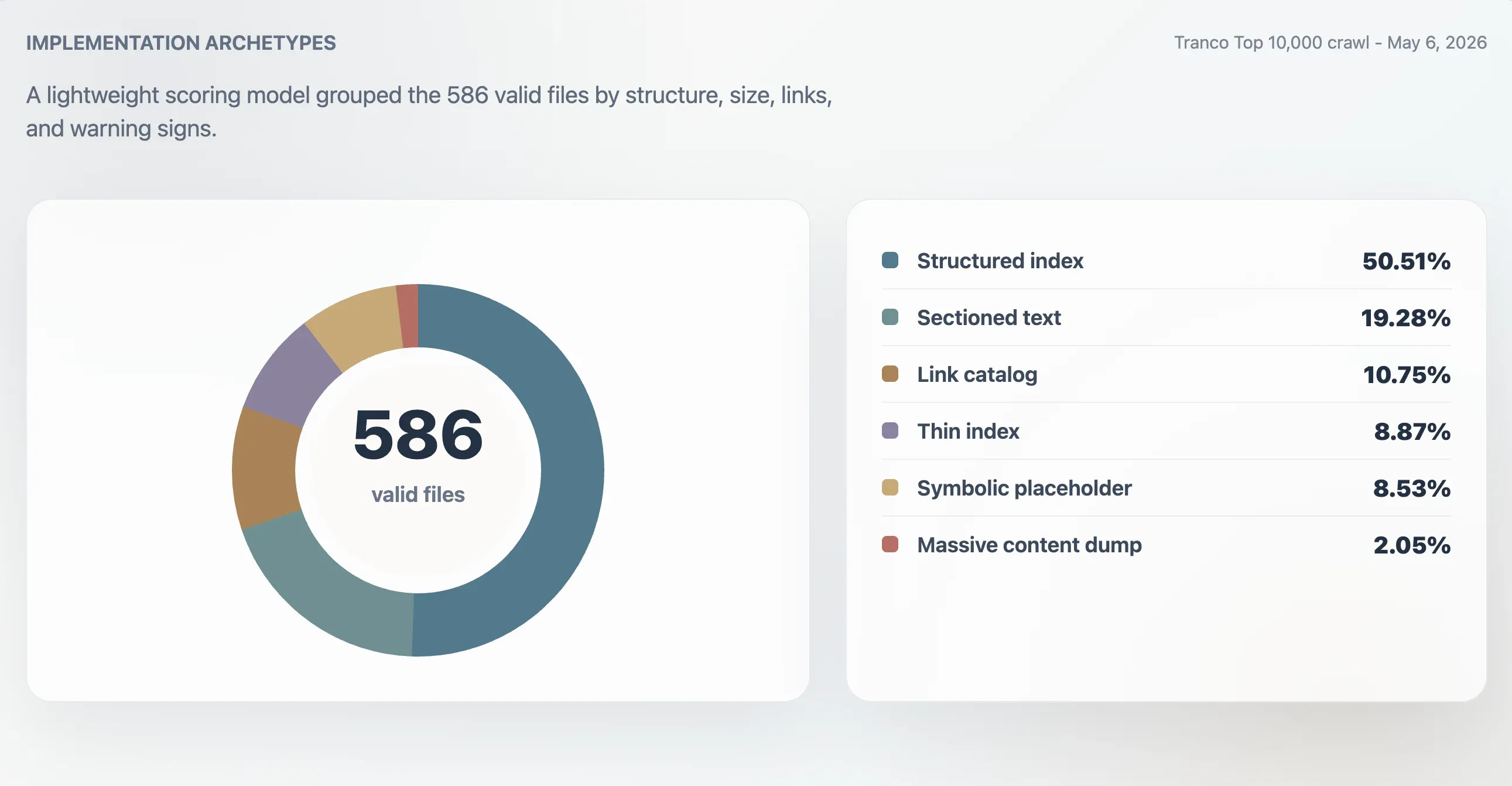
| Arquétipo | Domínios | Participação entre os arquivos válidos | Pontuação mediana | Tamanho mediano do arquivo | Links medianos |
|---|---|---|---|---|---|
| Índice estruturado | 296 | 50,51% | 98 | 11.241 B | 61,5 |
| Texto seccionado | 113 | 19,28% | 78 | 4.718 B | 0 |
| Catálogo de links | 63 | 10,75% | 86 | 4.160 B | 23 |
| Índice fino | 52 | 8,87% | 66 | 2.814 B | 0 |
| Simbólico ou placeholder | 50 | 8,53% | 27 | 15 B | 0 |
| Despejo massivo de conteúdo | 12 | 2,05% | 74 | 2,84 MB | 7.259,5 |
Os maiores adotantes têm implementações mais densas
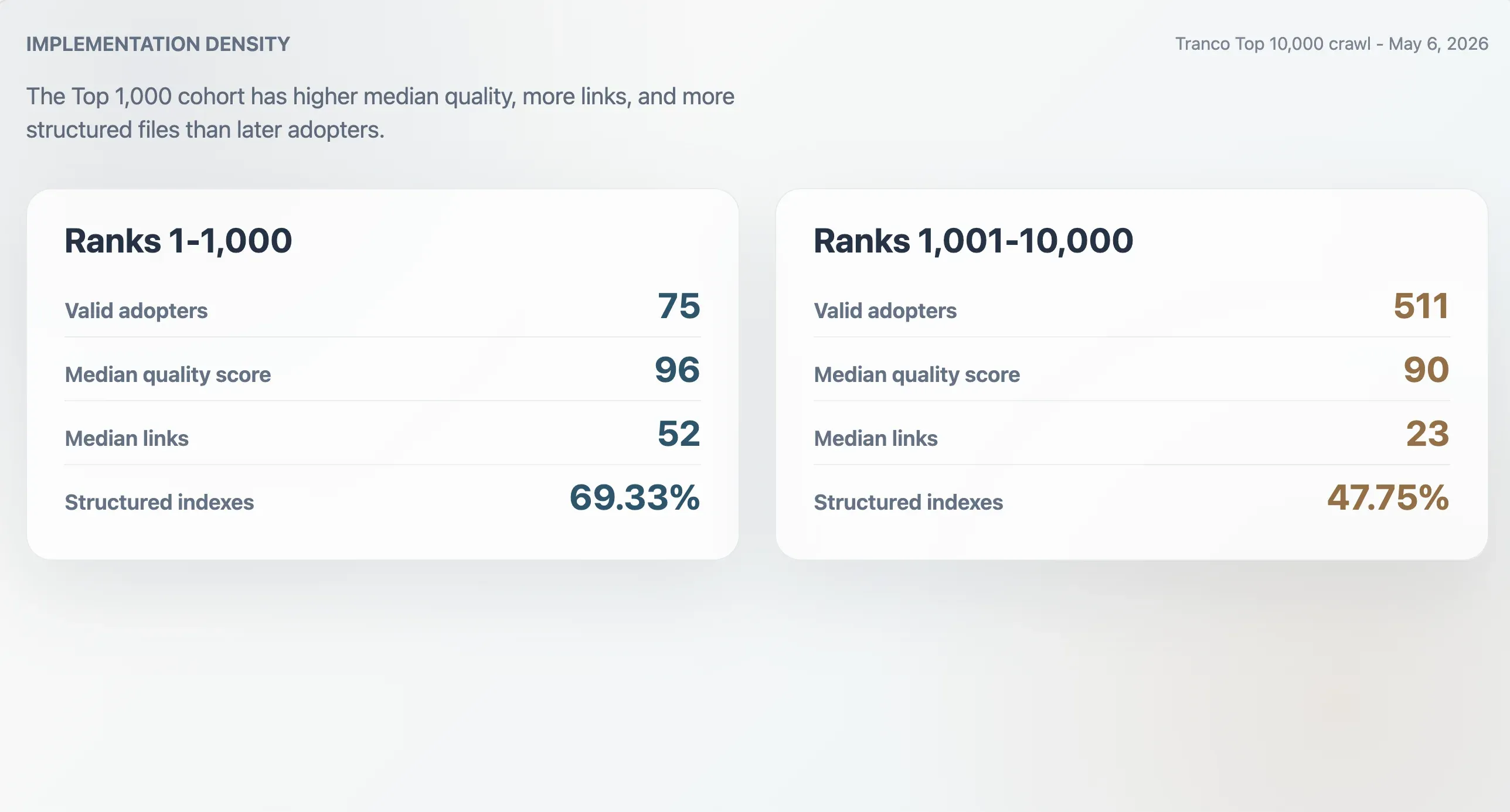
Os 75 adotantes válidos no Top 1.000 do Tranco tiveram pontuação mediana de qualidade de 96, tamanho mediano de arquivo de 9.068 bytes, contagem mediana de links em Markdown de 52 e contagem mediana de seções de 11. Os 511 adotantes ranqueados entre 1.001 e 10.000 tiveram medianas menores: pontuação 90, tamanho de arquivo de 6.506 bytes, 23 links em Markdown e 9 seções. Os adotantes do Top 1.000 também tinham mais probabilidade de ser índices estruturados: 69,33% contra 47,75% na coorte posterior.
O problema dos falsos positivos

O maior risco de medição é o dos falsos positivos. Dos 1.606 domínios que retornaram HTTP 200 para /llms.txt, 1.020 falharam na validação. O motivo inválido mais comum foi redirecionamento para destino errado, com 618 casos. Outras 367 respostas eram documentos HTML genéricos. Vinte e nove retornaram corpo vazio, e seis foram classificadas como outras respostas inválidas ou não categorizadas.
Isso importa porque muitos sites grandes encaminham caminhos desconhecidos para páginas de login, homepages, shells de aplicativo, páginas regionais, superfícies de consentimento ou fallbacks de marketing. Essas respostas podem parecer saudáveis para um crawler que olha apenas o código de status, mas não contêm nenhum sinal válido de llms.txt.
llms-full.txt: mais raro e mais desigual
O arquivo complementar llms-full.txt era bem menos comum do que llms.txt. O crawl encontrou 103 arquivos completos válidos, o que equivale a 17,58% dos adotantes válidos de llms.txt e a 1,03% da amostra total do Top 10.000.
As implementações com arquivo completo eram desiguais. Entre os 103 adotantes com dois arquivos, 57 tinham um llms-full.txt maior que o arquivo de índice, mas 46 tinham um arquivo completo não maior que o de índice ou um arquivo completo com menos de 100 bytes. A razão mediana entre o tamanho do arquivo completo e o do arquivo de índice foi 1,43, mas casos extremos foram muito maiores. O arquivo completo da Supabase era cerca de 7.139 vezes o tamanho do arquivo de índice. O arquivo completo de Made-in-China.com tinha 89,89 MB.
| Domínio | llms.txt | llms-full.txt | Razão |
|---|---|---|---|
| made-in-china.com | 4,49 MB | 89,89 MB | 20,0x |
| sendbird.com | 281,86 KB | 11,99 MB | 42,5x |
| taboola.com | 286,78 KB | 11,73 MB | 40,9x |
| supabase.co | 1,26 KB | 8,98 MB | 7.139,3x |
| neon.tech | 27,44 KB | 5,01 MB | 182,7x |
Recomendação: publique
llms-full.txtapenas quando o site já tiver um pipeline estável de documentação, disciplina de versionamento e um motivo claro para expor grandes volumes de conteúdo em um único arquivo legível por máquina.
llms.txt, robots.txt e sitemap.xml
llms.txt não deve ser tratado como um novo robots.txt. Ambos são arquivos legíveis por máquina na raiz, mas comunicam coisas diferentes. robots.txt é um sinal de preferência de rastreamento e controle de acesso. sitemap.xml é um sinal de descoberta de URLs. llms.txt é um sinal explicativo e de navegação.
| Sinal | Papel principal | Leitor típico | Interpretação neste estudo |
|---|---|---|---|
robots.txt | Declarar preferências de crawler e restrições por caminho. | Crawlers de busca, crawlers de IA, crawlers de arquivos, bots genéricos. | Sinal de governança e acesso. |
sitemap.xml | Listar URLs descobríveis para sistemas de indexação. | Motores de busca e pipelines de indexação. | Sinal de descoberta. |
llms.txt | Fornecer contexto compacto do site, links importantes, docs, APIs, exemplos e referências de políticas. | Aplicações de LLM, agentes de IA, ferramentas de desenvolvedor, sistemas de recuperação. | Sinal de explicação e navegação. |
Recomendações
Para sites que estão considerando llms.txt, as implementações mais fortes neste conjunto de dados e as evidências externas de tráfego sugerem um padrão pragmático:
- Publique
/llms.txtna raiz e mantenha-o acessível sem login, execução de JavaScript, barreiras de consentimento ou redirecionamentos fora do caminho. - Sirva-o como
text/plainoutext/markdownquando possível. - Comece com uma breve descrição do site e depois agrupe links por produto, documentação, API, preços, changelog, exemplos, suporte, políticas e recursos da empresa.
- Prefira links canônicos em vez de listas exaustivas de URLs.
- Evite arquivos simbólicos vazios; no máximo, eles são um sinal fraco.
- Evite dumps massivos e sem estrutura, a menos que exista um caso forte de consumo por máquina e um pipeline confiável de geração.
- Valide a URL final, o corpo da resposta, o tipo de conteúdo, a estrutura Markdown, a contagem de links e o tamanho do arquivo após a publicação.
As equipes também devem definir expectativas com cuidado. Os experimentos públicos disponíveis não provam que llms.txt aumente de forma independente o tráfego de referência vindo de IA. Se uma equipe quiser testar impacto de negócio, deve acompanhar em conjunto as referências de LLMs, as páginas citadas, as solicitações de bots, a frescura do índice e as mudanças de conteúdo. Um experimento útil compararia grupos de páginas pareadas, manteria atualizações de conteúdo constantes quando possível e separaria tráfego específico de plataformas como Perplexity, ChatGPT, Gemini, Claude e Bing/Copilot.
Limitações
Este é um instantâneo baseado em crawl, não uma verdade permanente. Os sites podem adicionar, remover ou alterar arquivos llms.txt a qualquer momento. Alguns domínios podem bloquear solicitações automatizadas ou se comportar de forma diferente conforme geografia, configuração de TLS, lógica de redirecionamento, user agent ou mitigação de bots. O estudo testou apenas arquivos na raiz e não procurou subdomínios nem caminhos não padronizados.
A pontuação de qualidade e os arquétipos são ferramentas de pesquisa, não rótulos oficiais de conformidade. A análise temática é baseada em palavras-chave e deve ser lida como direcional. O estudo não prova que alguma plataforma de IA específica atualmente leia, respeite ou use llms.txt em produção.
As evidências externas de tráfego revisadas nesta versão também têm limitações. A análise do Search Engine Land é mais forte como uma observação cautelosa multissite do que como um experimento randomizado. O resultado de Alimbekov é útil como estudo de caso transparente em nível de site, mas não tem grupo de controle e inclui um período em que o tráfego total de referência cresceu substancialmente. Essas referências ajudam a enquadrar o debate, mas não transformam este crawl em um estudo causal de tráfego.
Arquivos e reprodutibilidade
| Arquivo | Finalidade |
|---|---|
crawl_llms_txt.py | Crawler para /llms.txt e /llms-full.txt. |
analyze_llms_txt.py | Análise principal de adoção e geração de gráficos. |
deep_analyze_llms_txt.py | Análise secundária para decis de ranking, TLDs, sinais de tópicos, pontuações de qualidade, arquétipos e comportamento com dois arquivos. |
deep_dive_early_quality.py | Classificação dos primeiros adotantes e análise aprofundada da qualidade de implementação. |
data/llms_probe_results_top_10000.csv | Principal dataset de resultados do crawl. |
data/deep_analysis_top_10000.json | Resumo da análise secundária. |
data/deep_early_quality_analysis.json | Categorias de primeiros adotantes, comparação de coortes de qualidade, detalhes de arquétipos e estudos de caso. |
Fontes
- , Jeremy Howard, 2024.
- .
- .
- .
- , Data Provenance Initiative.
- .
- , Search Engine Land, janeiro de 2026.
- , Rankability, junho de 2025.
- , Renat Alimbekov.
Correções de metodologia, problemas no dataset e análises de acompanhamento são bem-vindos em support@thunderbit.com. Este relatório é publicado de forma independente de qualquer posição comercial da Thunderbit. Os dados deste relatório se sustentam por si só. — A equipe de pesquisa da Thunderbit, maio de 2026.