
Os web crawlers são os heróis anônimos da internet. Toda vez que você procura uma receita nova, confere o preço atual do seu tênis favorito ou compara hotéis para as próximas férias, tem boa chance de um web crawler já ter passado por ali antes, coletando e organizando em silêncio a informação que aparece na sua tela. Aliás, estima-se que perto da metade de todo o tráfego da internet já seja gerado por bots e crawlers, e não por humanos — estudos recentes do setor colocam a fatia dos bots entre 49% e 51%. É isso mesmo: enquanto você dorme, esses batedores digitais mapeiam a web sem parar, garantindo que a informação do mundo esteja a só um clique de distância.
Mas, afinal, o que são web crawlers? Por que eles são tão importantes para empresas, pesquisadores e para qualquer pessoa que dependa de dados atualizados? E como ferramentas modernas como o Thunderbit tornaram o web crawling acessível para todo mundo, e não só para desenvolvedores ou gigantes da tecnologia? Como alguém que passou anos construindo ferramentas de automação e IA, vi de perto os web crawlers saírem de "aranhas" misteriosas para virarem peças essenciais do dia a dia dos negócios. Bora mergulhar no assunto e desmistificar o universo dos web crawlers — o que são, como funcionam e por que eles são a base de um acesso mais inteligente aos dados em 2026.
Os web crawlers são os batedores de dados da internet
Extraia dados de qualquer site com IA Get Started Free
Então, o que são web crawlers, na prática? No fundo, os web crawlers (também conhecidos como spiders ou bots) são programas automatizados que navegam de forma sistemática pela internet, visitando uma página de cada vez e coletando informação pelo caminho. Pense neles como os estagiários de pesquisa mais incansáveis do mundo — só que nunca dormem, nunca reclamam e conseguem visitar milhões de páginas num único dia.
Um web crawler começa com uma lista de endereços web (os chamados "seeds"), visita cada um deles e depois segue os links que encontra para descobrir páginas novas. Conforme vai explorando, ele copia conteúdo, indexa dados e monta um mapa de um panorama web que muda o tempo todo (Cloudflare). É assim que buscadores como o Google sabem o que existe na web, e é assim que sites de comparação de preços ou ferramentas de pesquisa de mercado mantêm os dados em dia.
Em poucas palavras: os web crawlers são os batedores que deixam a internet pesquisável, comparável e acionável.
As muitas caras dos web crawlers: tipos e funções principais
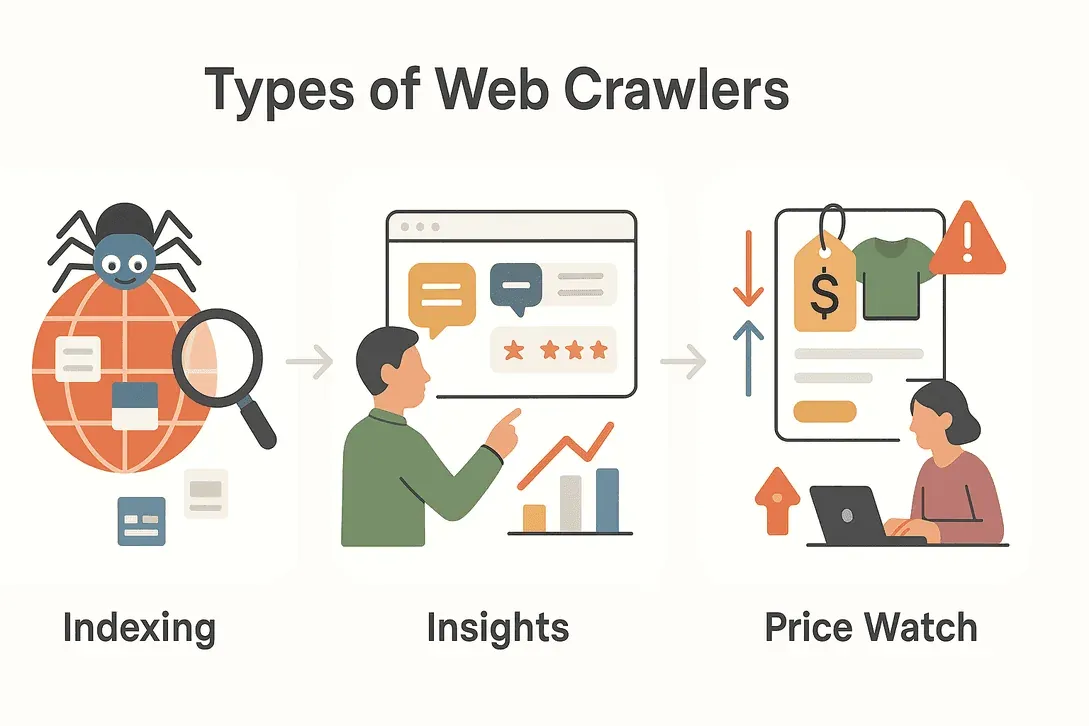 Nem todo web crawler faz a mesma coisa. Dependendo da missão, existem vários tipos, cada um com a sua especialidade. Aqui vai um resumão dos principais que você vai encontrar:
Nem todo web crawler faz a mesma coisa. Dependendo da missão, existem vários tipos, cada um com a sua especialidade. Aqui vai um resumão dos principais que você vai encontrar:
| Tipo | Função Principal | Caso de Uso Típico |
|---|---|---|
| Crawlers de Buscadores | Indexar a web para os resultados de busca | Googlebot, Bingbot indexando sites novos |
| Crawlers de Data Mining | Reunir grandes conjuntos de dados para análise | Pesquisa de mercado, estudos acadêmicos |
| Crawlers de Monitoramento de Preços | Acompanhar preços e disponibilidade de produtos | Comparação de preços em e-commerce, precificação dinâmica |
| Crawlers de Agregação de Conteúdo | Reunir artigos, notícias ou posts para agregar | Portais de notícias, curadoria de conteúdo |
| Crawlers de Geração de Leads | Extrair contatos e dados de empresas | Prospecção comercial, diretórios B2B |
Vamos olhar alguns deles com mais calma:
Crawlers de buscadores
Quando você digita uma pergunta no Google, está contando com o trabalho dos crawlers dos buscadores. Esses bots varrem a web 24 horas por dia, descobrindo páginas novas, atualizando as antigas e indexando conteúdo para que ele apareça nos resultados de busca. Sem crawlers, os buscadores estariam navegando no escuro — sem jeito de saber o que é novo, o que mudou ou nem mesmo o que existe (TechTarget).
Crawlers de data mining e pesquisa de mercado
Empresas e pesquisadores usam crawlers para juntar montanhas de dados para análise. Quer saber quantas vezes a marca de um concorrente é citada online? Ou acompanhar o que as pessoas estão achando do lançamento de um produto novo? Os crawlers de data mining conseguem vasculhar fóruns, avaliações, redes sociais e muito mais, transformando a web caótica em insights estruturados (DataHut).
Crawlers de monitoramento de preços e acompanhamento de produtos
No mundo acelerado do e-commerce, preços e detalhes de produtos mudam o tempo todo. Os crawlers de monitoramento de preços ficam de olho nos concorrentes e avisam as empresas sobre queda de preço, mudança de estoque ou lançamento novo. Isso abre caminho para estratégias de precificação dinâmica e ajuda as empresas a se manterem competitivas (AIMultiple).
Por que os web crawlers são essenciais para o acesso moderno a dados
Vamos ser sinceros: a internet é grande demais para os humanos darem conta de tudo na mão. Hoje já são mais de 1,4 bilhão de sites (e a conta não para de crescer), com cerca de um milhão de sites novos surgindo todo dia. Os web crawlers tornam possível:
- Escalar a coleta de dados: visitar milhões de páginas em horas, e não em meses.
- Ficar sempre atualizado: monitorar de forma contínua mudanças, conteúdo novo ou notícia de última hora.
- Acessar informação dinâmica e em tempo real: reagir a mudanças de mercado, variações de preço ou assuntos em alta na hora em que acontecem.
- Viabilizar decisões orientadas por dados: dar suporte a tudo, de buscadores a pesquisa de mercado, gestão de risco e modelagem financeira (DEV Community).
Num mundo em que os dados são a espinha dorsal da estratégia digital das empresas, os web crawlers são os motores que mantêm esse fluxo rodando.
Casos de uso comuns de web crawlers em diferentes setores
Web crawler não é coisa só de gigante da tecnologia ou de buscador. Veja como diferentes setores usam isso na prática:
| Setor | Caso de Uso | Benefício |
|---|---|---|
| Vendas | Geração de leads | Montar listas segmentadas de clientes em potencial a partir de diretórios |
| E-commerce | Monitoramento de preços | Acompanhar preço, estoque e mudanças de produtos da concorrência |
| Marketing | Agregação de conteúdo | Selecionar notícias, artigos e menções nas redes sociais |
| Imobiliário | Agregação de anúncios de imóveis | Reunir anúncios de várias fontes |
| Viagens | Comparação de tarifas e hotéis | Monitorar preço, disponibilidade e políticas |
| Finanças | Monitoramento de risco | Acompanhar notícias, documentos e sentimento para investimentos |
Exemplo real:
Uma imobiliária usa crawlers para coletar detalhes de imóveis, fotos e comodidades de vários sites de anúncios, oferecendo aos clientes uma visão unificada e atualizada do mercado (DataHut).
Uma equipe de e-commerce configura crawlers para monitorar SKU e preços da concorrência, ajustando a estratégia em tempo real (AIMultiple).
Como funcionam os web crawlers: visão geral passo a passo
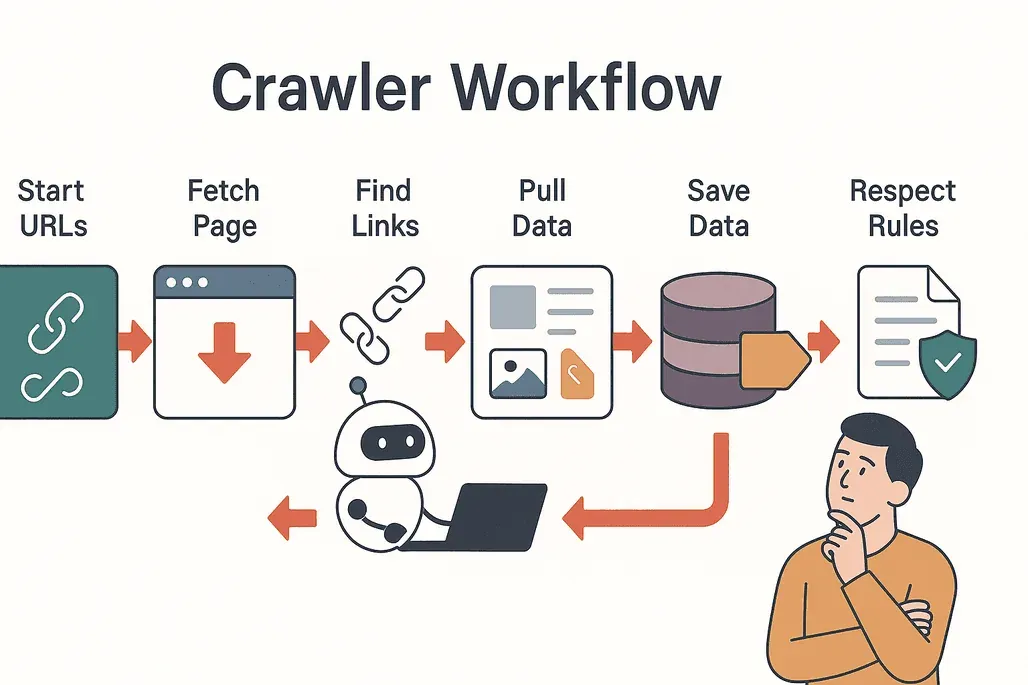 Vamos desmistificar o processo. É assim que um web crawler típico funciona:
Vamos desmistificar o processo. É assim que um web crawler típico funciona:
- Começa com os seeds: o crawler arranca com uma lista de URLs de partida.
- Visita e coleta: entra em cada página e baixa o conteúdo.
- Extrai os links: o crawler encontra todos os links da página.
- Segue os links: adiciona os links novos, que ainda não visitou, à sua fila.
- Extrai os dados: a informação relevante (texto, imagens, preços etc.) é copiada e estruturada.
- Salva os resultados: os dados vão para um banco de dados ou são exportados para análise.
- Respeita as regras: o crawler confere o arquivo
robots.txtde cada site para saber o que é permitido, fugindo das áreas restritas (Cloudflare).
Boas práticas:
- Faça crawls com educação (não sobrecarregue os servidores).
- Respeite a privacidade e os limites legais.
- Evite conteúdo duplicado e requisições desnecessárias.
Desafios e cuidados ao usar web crawlers
O web crawling nem sempre é um mar de rosas. Veja alguns obstáculos comuns:
- Carga no servidor: requisições demais podem deixar um site lento ou até derrubá-lo.
- Conteúdo duplicado: os crawlers podem revisitar as mesmas páginas ou ficar presos em loops.
- Privacidade e legalidade: nem todo dado está liberado para uso livre — confira sempre os termos de serviço e as leis de privacidade.
- Barreiras técnicas: alguns sites usam CAPTCHAs, conteúdo dinâmico ou recursos anti-bot para barrar crawlers (DEV Community).
Dicas para dar certo:
- Use um ritmo de crawl respeitoso.
- Fique de olho em mudanças na estrutura do site.
- Mantenha-se por dentro das regras de proteção de dados.
Thunderbit: deixando os web crawlers ao alcance de todo mundo
Aqui é onde a coisa fica interessante. Tradicionalmente, montar um web crawler significava escrever código, mexer em configurações e gastar horas resolvendo problema. Mas com o Thunderbit, a gente virou esse jogo de cabeça para baixo.
O Thunderbit é uma extensão de Chrome de Raspador Web com IA, feita para usuários de negócios — sem precisar programar. Veja o que faz ele se destacar:
- Instruções em linguagem natural: é só descrever os dados que você quer ("Pega todos os nomes e preços de produto desta página") que a IA do Thunderbit cuida do resto.
- Sugestões de campos com IA: clique em "AI Suggest Fields" e o Thunderbit lê a página, recomendando as melhores colunas para extrair.
- Extração de subpáginas: precisa de mais detalhes? O Thunderbit visita cada subpágina (como página de detalhes de produto ou perfil do LinkedIn) e enriquece o conjunto de dados sozinho.
- Modelos instantâneos: para sites populares (Amazon, Zillow, Shopify etc.), use os modelos prontos e extraia com um clique.
- Exportação fácil: mande os dados direto para Excel, Google Sheets, Airtable ou Notion — sem passo extra.
- Exportação de dados grátis: baixe os resultados em CSV ou JSON, de graça.
O Thunderbit é usado por mais de 100.000 usuários no mundo todo, de equipes de vendas a gente de e-commerce e profissionais do mercado imobiliário.
Teste o Thunderbit AI Web Scraper de graça
Thunderbit vs. web crawlers tradicionais
Vamos ver como o Thunderbit se compara à abordagem tradicional:
| Funcionalidade | Thunderbit | Crawlers Tradicionais |
|---|---|---|
| Tempo de Configuração | 2 cliques (a IA cuida da configuração) | Horas/dias (configuração manual, programação) |
| Conhecimento Técnico Necessário | Nenhum (instruções em linguagem simples) | Alto (programação, seletores, scripts) |
| Flexibilidade | Funciona em qualquer site, se adapta a mudanças | Quebra quando o layout muda |
| Extração de Subpáginas | Integrada, sem configuração extra | Exige scripting manual |
| Opções de Exportação | Excel, Sheets, Airtable, Notion, CSV, JSON | Normalmente só CSV/JSON |
| Manutenção | A IA se adapta sozinha | Correções manuais frequentes |
Com o Thunderbit, você não precisa ser desenvolvedor nem gastar horas afinando configuração. É só apontar, clicar e deixar a IA fazer o trabalho pesado (Thunderbit Blog).
Como começar com web crawlers usando o Thunderbit
Pronto para experimentar? Veja como começar com o Thunderbit em poucos minutos:
- Instale a extensão de Chrome do Thunderbit.
- Abra o site em que você quer fazer crawl.
- Clique no ícone do Thunderbit e selecione "AI Suggest Fields". A IA vai recomendar colunas com base no conteúdo da página.
- Ajuste os campos, se precisar, e clique em "Scrape". O Thunderbit extrai os dados, inclusive das subpáginas, se você quiser.
- Exporte os resultados para Excel, Google Sheets, Airtable, Notion ou baixe em CSV/JSON.
O que é Data Scraping e como fazer em 2025 Get Started Free
É só isso — sem script, sem código, sem dor de cabeça. Seja para acompanhar preços, montar uma lista de leads ou agregar notícias, o Thunderbit transforma a maioria das tarefas do dia a dia de web crawling em algo que até quem não programa resolve numa tarde.
Conclusão: os web crawlers são a chave para um acesso mais inteligente aos dados
Os web crawlers são os motores invisíveis que movem o nosso mundo digital, deixando a informação acessível, pesquisável e acionável para todo mundo. De buscadores a equipes de vendas, passando por e-commerce e mercado imobiliário, os crawlers viraram ferramentas essenciais para qualquer pessoa que precise de dados confiáveis e atualizados.
E graças a ferramentas modernas com IA como o Thunderbit, você não precisa ser programador para aproveitar todo esse poder. Com só alguns cliques, qualquer pessoa transforma a web num recurso estruturado e acionável — alimentando decisões mais inteligentes e abrindo novas oportunidades.
Ficou curioso para ver o que os web crawlers podem fazer pelo seu negócio? Baixe o Thunderbit e comece hoje a explorar os dados escondidos da web. Para mais dicas e análises a fundo, dá uma olhada no Thunderbit Blog.
Teste o Raspador Web com IA Get Started Free
Perguntas frequentes
1. O que é exatamente um web crawler?
Um web crawler é um programa automatizado (às vezes chamado de spider ou bot) que navega de forma sistemática pela internet, visitando páginas web, seguindo links e coletando informação para indexação ou análise.
2. Qual é a diferença entre web crawlers e web scrapers?
Os web crawlers foram pensados para descobrir e mapear grandes pedaços da web, em geral seguindo links de uma página para outra. Já os web scrapers focam em extrair dados específicos de páginas-alvo. Muitas ferramentas modernas (como o Thunderbit) juntam as duas funções.
3. Por que os web crawlers são importantes para as empresas?
Os web crawlers permitem que as empresas acessem informação atualizada em escala — seja para monitorar preço da concorrência, agregar conteúdo ou montar listas de leads. Eles dão suporte a decisões em tempo real e ajudam as empresas a se manterem competitivas.
4. É legal usar web crawlers?
Em geral, o web crawling é legal quando feito de forma responsável e de acordo com os termos de serviço e as políticas de privacidade do site. Confira sempre o arquivo robots.txt do site e respeite as regras de proteção de dados.
5. Como o Thunderbit facilita o web crawling?
O Thunderbit usa IA para automatizar a configuração, a escolha dos campos e a extração de dados. Com instruções em linguagem natural e modelos instantâneos, qualquer pessoa consegue fazer crawl e extrair dados de sites — sem programação nem conhecimento técnico. Dá para exportar os dados direto para Excel, Google Sheets, Airtable ou Notion e usar na hora.
Saiba mais




