
A internet está crescendo num ritmo tão acelerado que chega a ser difícil de acreditar. Em 2024, já passamos da marca de 1,1 bilhão de sites, com 149 zettabytes de dados circulando (e a previsão é bater 181 ZB no ano que vem). É informação demais — até cardápio de pizzaria entra na conta! Mas olha só: só uns 4% do conteúdo online é indexado pelos buscadores. O resto está na chamada “deep web”, invisível para as buscas comuns. E aí, como é que buscadores e empresas navegam nesse mar de dados? É aí que entra o web crawler.
Neste guia, vou te mostrar o que é web crawling, como funciona e por que é importante — não só para quem é da área de tecnologia, mas para qualquer pessoa que queira aproveitar o potencial dos dados online. Também vou explicar a diferença entre web crawling e web scraping (acredite, não é tudo igual), trazer exemplos práticos e apresentar soluções tanto para quem programa quanto para quem não entende nada de código (incluindo minha favorita, o Thunderbit). Seja você um curioso ou um profissional querendo tirar mais proveito da web, este conteúdo é pra você.
O que é um Web Crawler? Entendendo o Básico sobre Web Crawling
Vamos simplificar: um web crawler (também chamado de spider, bot ou rastreador de sites) é um programa automático que navega pela internet de forma organizada, acessando páginas e seguindo links para descobrir novos conteúdos. Imagina um robô bibliotecário que começa com uma lista de livros (URLs), lê cada um e segue todas as referências para encontrar ainda mais livros. É assim que um crawler trabalha — só que, em vez de livros, ele lida com páginas da web, e a “biblioteca” é a internet toda.
O básico do funcionamento é:
- Começa com uma lista de URLs (os “seeds” ou sementes)
- Visita cada página, baixando o conteúdo (HTML, imagens, etc.)
- Acha os links nessas páginas e coloca na fila para visitar depois
- Repete o processo — acessando novos links, descobrindo mais páginas, e por aí vai
A principal função de um web crawler é descobrir e catalogar páginas. Para buscadores, os crawlers copiam o conteúdo das páginas e mandam para serem indexadas e analisadas. Em outros casos, crawlers mais específicos podem extrair dados (aí entra o web scraping — já já explico melhor).
Resumo importante:
Web crawling serve para mapear e encontrar páginas na web, não só coletar dados. É a base de como buscadores como Google e Bing sabem o que existe online.
Como Funciona um Mecanismo de Busca? O Papel dos Crawlers
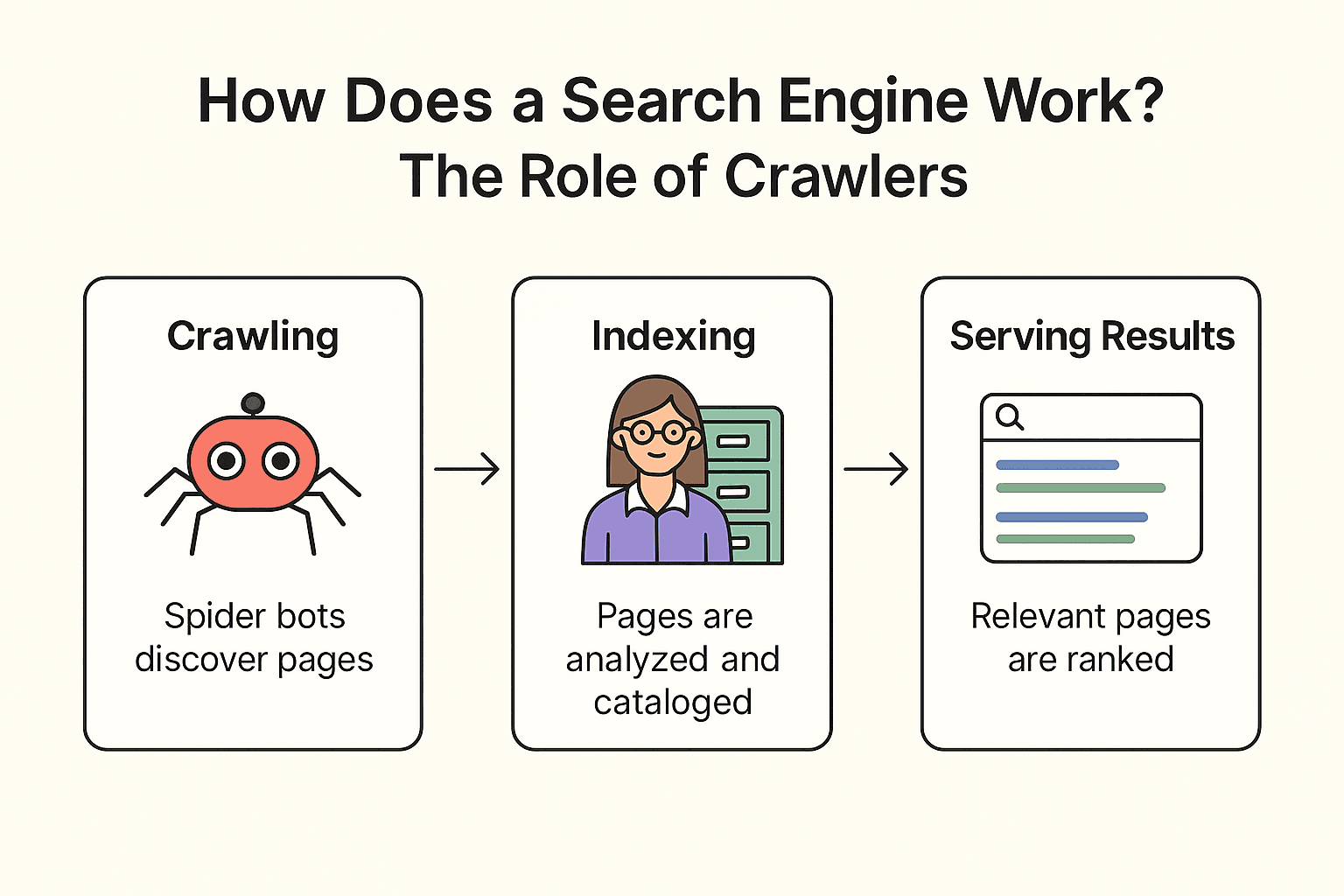
Mas afinal, como o Google (ou Bing, ou DuckDuckGo) realmente funciona? O processo tem três etapas: crawling, indexação e exibição dos resultados (documentação oficial do Google).
Vamos usar uma analogia com bibliotecas (quem não curte um exemplo com livros?):
-
Crawling:
O buscador manda seus “spider bots” (tipo o Googlebot) para explorar a web. Eles começam por páginas conhecidas, capturam o conteúdo e seguem os links para achar novas páginas — como um bibliotecário que verifica cada estante e segue as referências dos livros para encontrar outros títulos.
-
Indexação:
Depois de encontrar uma página, o buscador analisa o conteúdo, entende do que se trata e guarda as informações principais num catálogo digital gigante (o índice). Nem toda página entra — algumas são ignoradas se estiverem bloqueadas, forem de baixa qualidade ou duplicadas.
-
Exibição dos Resultados:
Quando você pesquisa “melhor pizzaria perto de mim”, o buscador consulta as páginas relevantes no índice e as classifica com base em centenas de fatores (palavras-chave, popularidade, atualidade, etc.). O resultado? Uma lista organizada de páginas pra você acessar.
Curiosidade:
Os buscadores não rastreiam todas as páginas da web. Páginas protegidas por login, bloqueadas pelo robots.txt ou sem links apontando pra elas podem nunca ser descobertas. Por isso, empresas costumam enviar seus URLs ou sitemaps direto pro Google.
Web Crawling vs. Web Scraping: Qual a Diferença?
Aqui está um ponto importante. Muita gente usa “web crawling” e “web scraping” como se fossem a mesma coisa, mas são diferentes.
| Aspecto | Web Crawling (Rastreamento) | Web Scraping |
|---|---|---|
| Objetivo | Descobrir e indexar o máximo de páginas possível | Extrair dados específicos de uma ou mais páginas |
| Analogia | Bibliotecário catalogando todos os livros da biblioteca | Estudante copiando só os trechos importantes de alguns livros |
| Resultado | Lista de URLs ou conteúdo das páginas (para indexação) | Base de dados estruturada (CSV, Excel, JSON) com informações selecionadas |
| Usado por | Mecanismos de busca, auditores de SEO, arquivadores web | Equipes de vendas, marketing, pesquisa, etc. |
| Escala | Massiva (milhões/bilhões de páginas) | Focada (dezenas, centenas ou milhares de páginas) |
Veja uma comparação visual aqui.
Resumindo:
- Web crawling serve para encontrar páginas (mapear a web)
- Web scraping serve para extrair os dados que você precisa dessas páginas (colocando numa planilha, por exemplo)
A maioria dos profissionais de negócios (especialmente em vendas, e-commerce ou marketing) está mais interessada em scraping — pegar dados organizados para análise — do que em rastrear a web toda. O crawling é essencial para buscadores e grandes projetos de descoberta, enquanto o scraping é focado na extração de dados específicos.
Por Que Usar um Web Crawler? Aplicações Práticas para Empresas
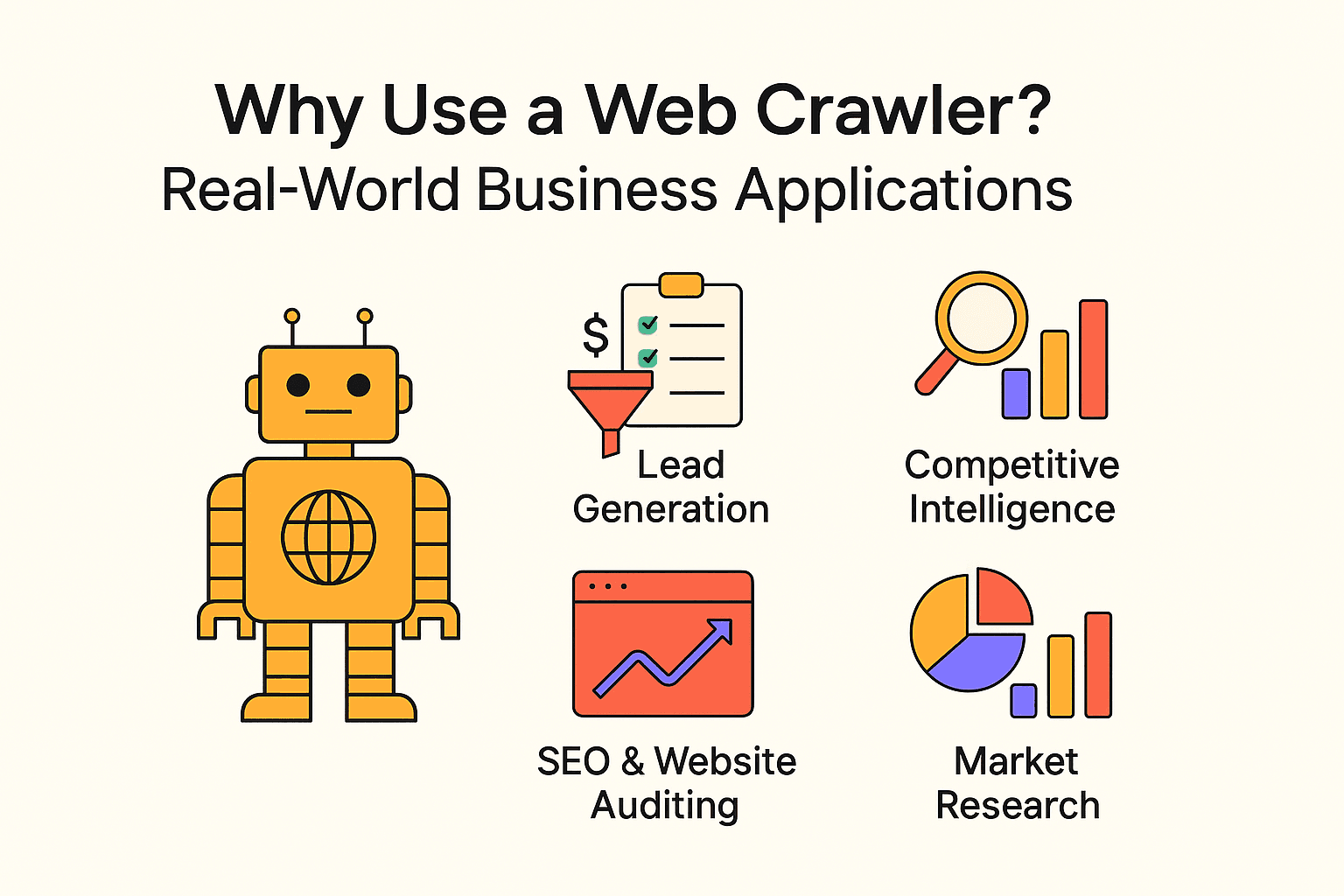
Web crawling não é só coisa de buscador. Empresas de todos os tamanhos usam crawlers e raspadores para conseguir insights valiosos e automatizar tarefas repetitivas. Veja alguns exemplos reais:
| Aplicação | Usuário-Alvo | Benefício Esperado |
|---|---|---|
| Geração de Leads | Equipes de vendas | Automatizar a prospecção, alimentar o CRM com leads atualizados |
| Inteligência Competitiva | Varejo, e-commerce | Monitorar preços, estoque e mudanças de produtos dos concorrentes |
| SEO & Auditoria de Sites | Marketing, equipes de SEO | Encontrar links quebrados, otimizar a estrutura do site |
| Agregação de Conteúdo | Mídia, pesquisa, RH | Reunir notícias, vagas de emprego ou bases de dados públicas |
| Pesquisa de Mercado | Analistas, equipes de produto | Analisar avaliações, tendências ou sentimentos em larga escala |
- O Groupon dobrou seus leads recebidos automatizando a geração de leads com web crawling.
- 82% das empresas de e-commerce e 71% das instituições financeiras dependem de web scraping para tomar decisões.
- O web scraping pode reduzir em até 90% os custos de infraestrutura e 60% do tempo em relação à coleta manual de dados.
Resumindo: Se você não está aproveitando dados da web, pode apostar que seus concorrentes estão.
Como Criar um Web Crawler em Python: O Que Você Precisa Saber
Se você já tem alguma experiência com programação, Python é a linguagem mais usada para criar crawlers sob medida. O básico é:
- Usar requests para acessar páginas web
- Usar BeautifulSoup para analisar o HTML e extrair links/dados
- Criar laços (ou recursão) para seguir links e rastrear mais páginas
Vantagens:
- Máxima flexibilidade e controle
- Permite lógica complexa, fluxos personalizados e integração com bancos de dados
Desvantagens:
- Precisa saber programar
- Dá trabalho manter: se o site mudar o layout, o script pode quebrar
- Você mesmo tem que lidar com bloqueios, atrasos e erros
Exemplo simples de crawler em Python:
Aqui vai um script básico que coleta frases e autores de quotes.toscrape.com:
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com/page/1/>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
print(f"{text} --- {author}")
Para rastrear várias páginas, é só adicionar lógica para achar o botão “Next” e repetir até acabar.
Erros comuns:
- Ignorar o robots.txt ou os intervalos de acesso (não seja essa pessoa)
- Ser bloqueado por sistemas anti-bot
- Cair em loops infinitos (tipo calendários que nunca terminam)
Passo a Passo: Como Construir um Web Crawler Simples em Python
Se quiser colocar a mão na massa, segue um roteiro básico pra criar seu próprio crawler.
Passo 1: Preparando o Ambiente Python
Primeiro, garanta que o Python está instalado. Depois, instale as bibliotecas necessárias:
pip install requests beautifulsoup4
Se der algum erro, confira a versão do Python (python --version) e se o pip está funcionando.
Passo 2: Escrevendo a Lógica Principal do Crawler
O padrão básico é:
import requests
from bs4 import BeautifulSoup
def crawl(url, depth=1, max_depth=2, visited=None):
if visited is None:
visited = set()
if url in visited or depth > max_depth:
return
visited.add(url)
print(f"Crawling: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extrair links
for link in soup.find_all('a', href=True):
next_url = link['href']
if next_url.startswith('http'):
crawl(next_url, depth + 1, max_depth, visited)
start_url = "<http://quotes.toscrape.com/>"
crawl(start_url)
Dicas:
- Limite a profundidade do rastreamento para evitar loops infinitos
- Mantenha uma lista de URLs visitados para não repetir páginas
- Respeite o robots.txt e adicione intervalos (time.sleep(1)) entre os acessos
Passo 3: Extraindo e Salvando Dados
Para salvar os dados, você pode escrever em um arquivo CSV ou JSON:
import csv
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Quote', 'Author'])
# Dentro do loop do crawler:
writer.writerow([text, author])
Ou usar o módulo json do Python para exportar em JSON.
Pontos de Atenção e Boas Práticas para Web Crawling
Web crawling é uma ferramenta poderosa, mas exige responsabilidade (e cuidado para não ser bloqueado). Veja como agir do jeito certo:
- Respeite o robots.txt: Sempre confira e siga as regras do arquivo robots.txt do site. Ele mostra o que não pode ser acessado.
- Aja com cautela: Adicione intervalos entre os acessos (pelo menos alguns segundos). Não sobrecarregue os servidores.
- Limite o escopo: Rastreie só o necessário. Defina limites de profundidade e domínio.
- Identifique-se: Use um User-Agent descritivo.
- Siga a lei: Não extraia dados privados ou sensíveis. Foque em informações públicas.
- Seja ético: Não copie sites inteiros nem use dados para spam.
- Teste devagar: Comece com um rastreamento pequeno e só aumente se tudo estiver funcionando bem.
Para mais dicas, dá uma olhada neste guia de boas práticas.
Quando Optar pelo Web Scraping: Thunderbit para Usuários de Negócios
Extraia dados de qualquer site usando IA Get Started Free
Minha opinião sincera: a não ser que você precise construir um buscador ou mapear toda a estrutura de um site, a maioria dos profissionais de negócios se dá melhor usando ferramentas de web scraping.
É aí que entra o Thunderbit. Como cofundador e CEO, posso ser suspeito, mas realmente acredito que o Thunderbit é a forma mais fácil para quem não é técnico extrair dados da web.
Por que escolher o Thunderbit?
- Configuração em dois cliques: Clique em “Sugerir Campos com IA” e depois em “Extrair” — pronto.
- IA integrada: O Thunderbit lê a página e sugere automaticamente as melhores colunas para extrair (nomes de produtos, preços, imagens, etc.).
- Suporte a múltiplas páginas e PDFs: Extraia dados de páginas atuais, listas de URLs ou até de arquivos PDF.
- Exportação flexível: Baixe em CSV/JSON ou envie direto para Google Sheets, Airtable ou Notion.
- Sem necessidade de código: Se você sabe usar um navegador, sabe usar o Thunderbit.
- Rastreamento de subpáginas: Precisa de mais detalhes? O Thunderbit pode visitar subpáginas e enriquecer seus dados automaticamente.
- Agendamento: Programe extrações recorrentes em linguagem natural (ex: “toda segunda-feira às 9h”).
Teste a extensão Thunderbit para Chrome gratuitamente
Quando usar um crawler tradicional?
Se o objetivo é mapear um site inteiro (tipo criar um índice de busca ou sitemap), o crawler é a escolha certa. Mas se você só quer dados organizados de páginas específicas (como listas de produtos, avaliações ou contatos), o scraping é mais rápido, simples e eficiente.
Conclusão & Principais Aprendizados
Resumindo:
- Web crawling é como buscadores e grandes projetos de dados descobrem e mapeiam a web. Foco em abrangência — encontrar o máximo de páginas possível.
- Web scraping foca na profundidade — extrair os dados específicos que você precisa dessas páginas. Para a maioria dos negócios, scraping é o que importa.
- Você pode programar seu próprio crawler (Python é ótimo pra isso), mas exige tempo, conhecimento e manutenção.
- Ferramentas sem código e com IA como o Thunderbit tornam a extração de dados acessível para todos — sem precisar programar.
- Boas práticas são essenciais: Sempre rastreie e extraia dados de forma ética, respeite as regras dos sites e use as informações com responsabilidade.
Se você está começando, escolha um projeto simples — por exemplo, extrair preços de produtos ou coletar leads de um diretório. Experimente uma ferramenta como o Thunderbit para resultados rápidos, ou brinque com Python se quiser aprender a fundo.
A web é uma mina de ouro de informações. Com a abordagem certa, você pode descobrir insights valiosos, economizar tempo e manter seu negócio sempre à frente.
Comece a extrair dados com o Thunderbit
FAQ
- Qual a diferença entre web crawling e web scraping?
Crawling serve para encontrar e mapear páginas. Scraping extrai dados específicos delas. Crawling = descoberta; scraping = extração.
- Web scraping é legal?
Extrair dados públicos geralmente é permitido, desde que você respeite o robots.txt e os termos de uso. Evite conteúdos privados ou protegidos por direitos autorais.
- Preciso programar para extrair dados de sites?
Não. Ferramentas como o Thunderbit permitem extrair dados com poucos cliques e IA — sem código.
- Por que o Google não indexa toda a web?
Porque grande parte está atrás de logins, paywalls ou bloqueios. Só cerca de 4% é realmente indexado.
Leituras recomendadas
- FreeCodeCamp – Web Scraping com Python e BeautifulSoup
- Tutorial Oficial do Scrapy
- Real Python – Como usar Selenium e Python para Web Scraping
- Apify Academy: Web Scraping e Automação
Experimente o Raspador Web IA Get Started Free




