

Meu painel do OpenRouter já mostrava US$ 47 gastos antes do almoço numa terça-feira. Eu tinha feito talvez uma dúzia de tarefas de programação — nada absurdo, só algumas refatorações e correções de bugs. Foi aí que percebi que os padrões do OpenClaw estavam, sem alarde, roteando cada interação, inclusive os pings de heartbeat em segundo plano, pelo Claude Opus, a mais de US$ 15 por milhão de tokens.
Se você já passou por sustos parecidos — e, pelos fóruns, muita gente passou (“já estou gastando 40 dólares e nem uso tanto assim”, escreveu um usuário) — este guia mostra o processo completo de auditoria e otimização que usei para cortar meu gasto mensal em cerca de 90%. Não é só “trocar por um modelo mais barato”, mas sim desmontar de forma sistemática para onde os tokens realmente vão, como monitorá-los, quais modelos econômicos realmente aguentam trabalho agentic de verdade e três configurações prontas para copiar e colar que você pode usar hoje. Todo o processo levou uma tarde.
O que é o uso de tokens do OpenClaw (e por que ele é tão alto por padrão)?
Tokens são a unidade de cobrança de toda interação de IA no OpenClaw. Pense neles como pequenos blocos de texto — algo em torno de 4 caracteres em inglês por token. Cada mensagem que você envia, cada resposta que recebe, cada processo em segundo plano que dispara: tudo é cobrado em tokens.
O problema é que os padrões do OpenClaw são ajustados para máxima capacidade, não para menor custo. Logo de cara, o modelo principal vem definido como anthropic/claude-opus-4-5 — a opção mais cara disponível. Pings de heartbeat? Também rodam no Opus. Subagentes criados para tarefas paralelas? Também em Opus. Usar Opus para um ping de heartbeat é como contratar um neurocirurgião para colar um curativo. Tecnicamente competente, mas absurdamente caro.
A maioria dos usuários não percebe que está pagando tarifa premium por tarefas triviais de bastidor. A configuração padrão praticamente assume que você quer o melhor modelo para tudo, o tempo todo — e cobra de acordo.
Por que reduzir o uso de tokens do OpenClaw economiza mais do que dinheiro
O benefício mais óbvio é a redução de custos. Mas há ganhos secundários que se acumulam com o tempo.
Modelos mais baratos costumam ser mais rápidos. O Gemini 2.5 Flash-Lite roda em cerca de 214 tokens por segundo contra cerca de 51 do Opus — isso é uma melhora de 4x em velocidade em cada interação. O GPT-OSS-120B no Cerebras chega a 1.917 tokens por segundo, algo em torno de 35x mais rápido que o Opus. Em um loop agentic com mais de 50 rodadas de chamadas de ferramentas, essa diferença de velocidade significa concluir em minutos em vez de ficar preso aos dolorosos 13,6 segundos até o primeiro token do Opus em cada ida e volta.
Você também ganha mais margem antes de bater limites de taxa, menos sessões estranguladas e espaço para escalar o uso sem escalar sua ansiedade com a conta.
Economia projetada em diferentes perfis de uso:
| Perfil de usuário | Gasto mensal estimado (padrão) | Após otimização completa | Economia mensal |
|---|---|---|---|
| Leve (~10 consultas/dia) | ~$100 | ~$12 | ~88% |
| Moderado (~50 consultas/dia) | ~$500 | ~$90 | ~82% |
| Intenso (~200+ consultas/dia) | ~$1.750 | ~$220 | ~87% |
Isso não é hipotético. Um desenvolvedor documentou uma queda de $600–750/mês para $3–4/dia — um corte real de 90% — combinando roteamento de modelos com as correções para vazamentos ocultos que veremos adiante neste guia.
Anatomia do uso de tokens do OpenClaw: para onde cada token realmente vai
Essa é a parte que a maioria dos guias de otimização pula, e justamente a mais importante. Você não consegue consertar o que não enxerga.
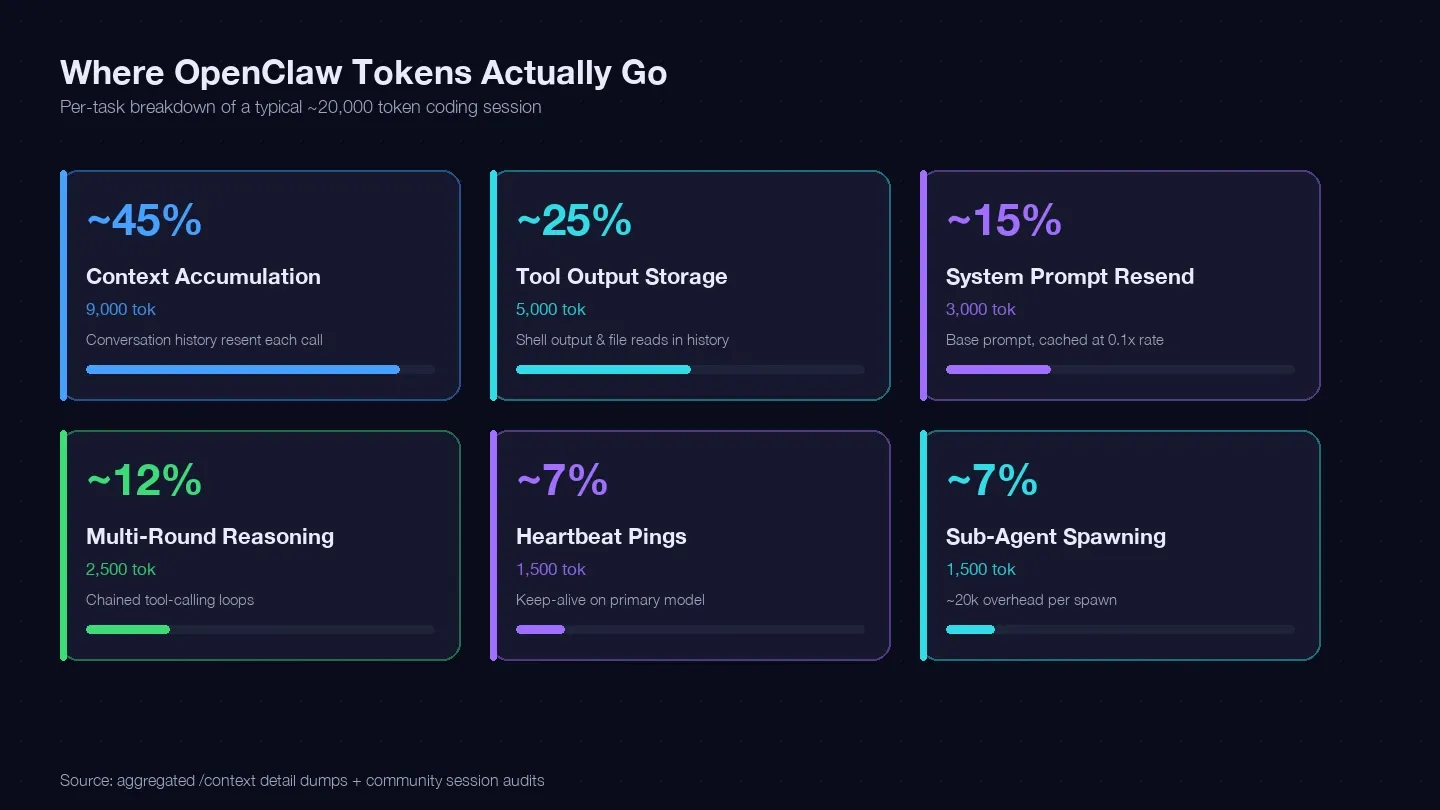
Auditei várias sessões e cruzei os dados com o guia de otimização de custos da LaoZhang e dumps da comunidade /context para montar um livro-razão de tokens de uma tarefa típica de programação. Eis onde cerca de 20.000 tokens realmente foram parar:
| Categoria de token | % típico do total | Exemplo (1 tarefa de programação) | Dá para controlar? |
|---|---|---|---|
| Acúmulo de contexto (histórico da conversa reenviado a cada chamada) | ~40–50% | ~9.000 tokens | Sim — /clear, /compact, sessões mais curtas |
| Armazenamento de saída de ferramentas (saída do shell, leituras de arquivos mantidas no histórico) | ~20–30% | ~5.000 tokens | Sim — leituras menores, escopo de ferramenta mais restrito |
| Reenvio do prompt de sistema (~15K base) | ~10–15% | ~3.000 tokens | Parcialmente — cache de leitura a 0,1x |
| Raciocínio em várias rodadas (loops encadeados de chamada de ferramentas) | ~10–15% | ~2.500 tokens | Escolha do modelo + prompts melhores |
| Pings de heartbeat / keep-alive | ~5–10% | ~1.500 tokens | Sim — mudança de configuração |
| Chamadas de subagentes | ~5–10% | ~1.500 tokens | Sim — roteamento de modelo |
O maior bloco — acúmulo de contexto — é o histórico da conversa sendo reenviado a cada chamada de API. Um dump real de sessão mostrou 185.400 tokens apenas na caixa de Messages, sem o modelo sequer ter respondido ainda. O prompt de sistema e as ferramentas adicionaram outros ~35.800 tokens de overhead fixo em cima disso.
A lição é direta: se você não limpa sessões entre tarefas sem relação, está pagando para retransmitir todo o seu histórico de conversa em cada turno.
Como monitorar o uso de tokens do OpenClaw (não dá para cortar o que você não vê)
Antes de mudar qualquer coisa, obtenha visibilidade sobre para onde seus tokens estão indo. Sair direto para “usar um modelo mais barato” sem monitoramento é como tentar emagrecer sem jamais subir numa balança.
Verifique seu painel do OpenRouter
Se você roteia pelo OpenRouter, a página de Activity é o painel mais fácil e sem configuração inicial. Você pode filtrar por modelo, provedor, chave de API e período. A visualização de Usage Accounting detalha prompt, completion, reasoning e tokens em cache em cada requisição. Há um botão de Exportação (CSV ou PDF) para análise em períodos mais longos.
O que observar: qual modelo consumiu mais tokens e se os pedidos de heartbeat ou subagentes estão aparecendo como itens inesperadamente grandes.
Audite seus logs locais de API
O OpenClaw armazena os dados da sessão em ~/.openclaw/agents.main/sessions/sessions.json, que inclui totalTokens por sessão. Você também pode rodar openclaw logs --follow --json para registro em tempo real por requisição.
Um aviso importante: o totalTokens em sessions.json não é atualizado após compactação, então o painel pode mostrar valores antigos, anteriores à compactação. Confie mais em /status e /context detail do que nos totais armazenados.
Use ferramentas de terceiros para rastreamento (para usuários moderados ou intensos)
LiteLLM proxy oferece um endpoint compatível com OpenAI na frente de mais de 100 provedores e registra automaticamente o gasto por chave virtual, modelo, usuário e equipe. O grande diferencial: orçamentos rígidos por chave que sobrevivem ao /clear — um subagente descontrolado não consegue ultrapassar o limite que você definiu.
Helicone é ainda mais simples — uma troca de base URL em uma linha que oferece uma visão de Sessions agrupando requisições relacionadas. Um único prompt “corrija esse bug” que se divide em 8 ou mais chamadas de subagentes aparece como uma linha de sessão com o custo total real. Plano gratuito: 10.000 requisições/mês.
Checagens rápidas dentro do OpenClaw
Para monitoramento do dia a dia, quatro comandos na sessão resolvem:
/status— mostra uso de contexto, últimos tokens de entrada/saída, custo estimado/usage full— rodapé de uso por resposta/context detail— detalhamento por arquivo, habilidade e ferramenta/compact [guidance]— força compactação com string opcional de foco
Rode /context detail antes e depois de mudar a configuração. É assim que você mede se as otimizações realmente funcionaram.
O confronto dos modelos mais baratos do OpenClaw: quais LLMs econômicos realmente aguentam trabalho agentic
A maioria dos guias erra aqui. Mostram uma tabela de preços, apontam para a linha mais barata e encerram o assunto. Benchmarks não preveem desempenho agentic no mundo real — um ponto que a comunidade vem destacando com força e repetidamente. Como disse um usuário: “benchmarks não ajudam em nada para entender qual funciona melhor para IA agentic”.
A percepção crucial: o modelo mais barato nem sempre gera o resultado mais barato. Um modelo que falha e tenta de novo quatro vezes custa mais do que um modelo intermediário que acerta na primeira tentativa. Em sistemas agentic de produção, planeje uma taxa de retry de 5–10% — e, se cinco chamadas de LLM são encadeadas e a etapa quatro falha, um retry ingênuo reexecuta as cinco etapas.
Aqui está minha matriz de capacidade, com uma “pontuação agentic real” baseada em relatos de usuários reais, e não em benchmarks sintéticos:
| Modelo | Entrada $/1M | Saída $/1M | Confiabilidade em chamadas de ferramentas | Raciocínio em várias etapas | Pontuação agentic real (1–5) | Melhor uso |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0,10 | $0,40 | Misto — loops ocasionais | Básico | ⭐2,5 | Heartbeats, buscas simples |
| GPT-OSS-120B | $0,04 | $0,19 | Adequado | Adequado | ⭐3,0 | Experimentação barata, tarefas críticas de velocidade |
| DeepSeek V3.2 | $0,26 | $0,38 | Inconsistente (6 issues abertas) | Bom | ⭐3,0 | Muito raciocínio, pouca chamada de ferramentas |
| Kimi K2.5 | $0,38 | $1,72 | Bom (via :exacto) | Adequado | ⭐3,5 | Programação simples a intermediária |
| MiniMax M2.5 / M2.7 | $0,28 | $1,10 | Bom | Bom | ⭐4,0 | Modelo diário para programação geral |
| Claude Haiku 4.5 | $1,00 | $5,00 | Excelente | Bom | ⭐4,5 | Fallback intermediário confiável |
| Claude Sonnet 4.6 | $3,00 | $15,00 | Excelente | Excelente | ⭐5,0 | Tarefas complexas em várias etapas |
| Claude Opus 4.5/4.6 | $5,00 | $15,00 | Excelente | Excelente | ⭐5,0 | Reserve só para os problemas mais difíceis |
Um alerta sobre DeepSeek e Gemini Flash para chamadas de ferramentas
O DeepSeek V3.2 parece ótimo no papel — 72–74% no SWE-Bench, 11–36x mais barato que o Sonnet. Na prática, seis issues separadas no GitHub em Cline, Roo Code, Continue e NVIDIA NIM documentam comportamento quebrado em tool calling. O veredito do confronto direto da Composio: “o DeepSeek V3.2 construiu partes do app, mas tropeçou em execução, velocidade e confiabilidade.” A síntese de Zvi Mowshowitz: “ok e barato, mas.”
O Gemini 2.5 Flash tem uma lacuna parecida. Um tópico no Google AI Developers Forum, intitulado “Very frustrating experience with Gemini 2.5 function calling performance”, abre com: “o comportamento de function calling dos modelos Gemini se tornou completamente pouco confiável e imprevisível.”
O OpenRouter destacou uma nuance crítica: “a propensão de um modelo para chamar ferramentas e a precisão dessas chamadas pode variar drasticamente entre hosts com os mesmos pesos.” Se você roteia modelos baratos pelo OpenRouter, procure a tag :exacto — uma troca silenciosa de provedor pode transformar da noite para o dia um modelo barato confiável em um loop caro de retries.
Quando usar cada modelo
- Gemini Flash-Lite: heartbeats, keep-alive pings, perguntas e respostas simples. Nunca para chamadas de ferramentas em várias etapas.
- MiniMax M2.5/M2.7: seu modelo diário para tarefas gerais de programação. SWE-Pro 56,22, Terminal-Bench 2 57,0% por uma fração do preço do Sonnet.
- Claude Haiku 4.5: o fallback confiável quando modelos baratos travam em chamadas de ferramentas. Excelente confiabilidade com custo cerca de 3x menor que o Sonnet.
- Claude Sonnet 4.6: trabalho agentic complexo em várias etapas. É aqui que você vê o dinheiro valer a pena.
- Claude Opus: reserve para os problemas mais difíceis. Não deixe esse ser o padrão para nada.
(Os preços dos modelos mudam com frequência — confirme as tarifas atuais no OpenRouter ou nas páginas diretas dos provedores antes de fechar qualquer configuração.)
Os vazamentos ocultos de tokens que a maioria dos guias ignora
Usuários dos fóruns relatam que desativar recursos específicos reduz bastante os custos, mas nenhum guia que encontrei reúne numa lista única todos os vazamentos ocultos com seu impacto real em tokens. O desmonte completo:
| Vazamento oculto | Custo em tokens por ocorrência | Como corrigir | Chave de configuração |
|---|---|---|---|
| Heartbeat padrão no Opus | ~100.000 tokens/execução sem isolamento | Override para Haiku + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Criação de subagentes | ~20.000 tokens por criação antes de qualquer trabalho | Roteie subagentes para Haiku | subagents.model |
| Carregamento completo do contexto da base de código | ~3.000–15.000 tokens por auto-explore | .clawignore para node_modules, dist, lockfiles | .clawrules + .clawignore |
| Auto-resumo de memória | ~500–2.000 tokens/sessão | Desativar ou reduzir frequência | memory: false ou memory.max_context_tokens |
| Acúmulo do histórico da conversa | ~500+ tokens/turno (cumulativo) | Inicie novas sessões entre tarefas sem relação | Disciplina de /clear |
| Overhead de ferramentas do servidor MCP | ~7.000 tokens para 4 servidores; 50.000+ para 5 ou mais | Mantenha o MCP mínimo | Remover MCPs não usados |
| Inicialização de habilidades/plugins | 200–1.000 tokens por habilidade carregada | Desative habilidades não usadas | skills.entries.<name>.enabled: false |
| Agent Teams (modo de planejamento) | ~7x o custo de uma sessão padrão | Use apenas para trabalho realmente paralelo | Prefira sequência |
O vazamento do heartbeat merece destaque próprio. Por padrão, os heartbeats disparam no modelo principal (Opus) a cada 30 minutos. Definir isolatedSession: true reduz isso de cerca de 100.000 tokens por execução para 2.000–5.000 tokens — uma redução de 95–98% nesse único bloco.
Três vitórias rápidas que economizam mais tokens em menos de dois minutos
As três são sem risco e levam menos de dois minutos:
-
/clearentre tarefas sem relação (5 segundos). Esse é o maior economizador de tokens. O consenso dos fóruns estima redução de 50–70% só por limpar o histórico da sessão antes de começar um novo trabalho. Lembra daqueles 185 mil tokens na caixa de Messages do dump de /context?/clearapaga isso. -
/model haiku-4.5para tarefas operacionais (10 segundos). A troca tática de modelo gera redução de 60–80% no custo em tarefas rotineiras. O Haiku lida muito bem com a maioria das tarefas de programação direta, buscas em arquivos e mensagens de commit. -
Enxugue
.clawrulespara menos de 200 linhas + adicione.clawignore(90 segundos). Seu arquivo de regras é carregado em toda e qualquer mensagem. Com 200 linhas, isso representa cerca de 1.500–2.000 tokens por turno; com 1.000 linhas, são 8.000–10.000 tokens cobrando cada requisição permanentemente. Combinado com um.clawignoreexcluindonode_modules/,dist/, lockfiles e código gerado, um desenvolvedor afirma ter alcançado redução de 92% de tokens só com essa disciplina.
Passo a passo: três configurações prontas para copiar e cortar o uso de tokens do OpenClaw

A seguir, três configurações completas e comentadas de openclaw.json — desde “só quero começar” até “stack de otimização completa”. Cada uma inclui comentários inline e estimativas de custo mensal.
Antes de começar:
- Nível: Iniciante (Config A) → Intermediário (Config B) → Avançado (Config C)
- Tempo necessário: ~5 minutos para a Config A, ~15 minutos para a Config C
- O que você vai precisar: OpenClaw instalado, um editor de texto e acesso a
~/.openclaw/openclaw.json
Config A: Iniciante — só economizar dinheiro
Cinco linhas. Zero complexidade. Troca o modelo padrão de Opus para Sonnet, desativa o overhead de memória e isola os heartbeats no Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // antes era Opus — economia imediata de 3-5x
"heartbeat": {
"every": "55m", // alinhado ao TTL de cache de 1h para maximizar hits
"model": "anthropic/claude-haiku-4-5", // Haiku para pings, não Opus
"isolatedSession": true // ~100k → 2-5k tokens por execução
}
}
},
"memory": { "enabled": false } // economiza ~500-2k tokens/sessão
}
O que você deve ver depois de aplicar isso: rode /status antes e depois. Seu custo por requisição deve cair de forma visível, e os itens de heartbeat na página de Activity do OpenRouter devem mostrar Haiku em vez de Opus.
| Faixa de uso | Padrão (Opus) | Config A (Sonnet + heartbeats em Haiku) | Economia |
|---|---|---|---|
| Leve (~10 consultas/dia) | ~$100 | ~$35 | 65% |
| Moderado (~50 consultas/dia) | ~$500 | ~$250 | 50% |
| Intenso (~200 consultas/dia) | ~$1.750 | ~$900 | 49% |
Config B: Intermediária — roteamento inteligente em três níveis
Sonnet como principal para trabalho real. Haiku para subagentes e compactação. Gemini Flash-Lite como fallback econômico quando o Claude estiver com throttling. Cadeias de fallback tratam indisponibilidades do provedor automaticamente.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // se o Sonnet estiver com throttling
"google/gemini-2.5-flash-lite" // último recurso ultrabarato
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55min < TTL de cache de 1h = hits de cache
"model": "google/gemini-2.5-flash-lite", // centavos por ping
"isolatedSession": true,
"lightContext": true // contexto mínimo nas chamadas de heartbeat
},
"subagents": {
"maxConcurrent": 4, // reduzido do padrão 8
"model": "anthropic/claude-haiku-4-5" // subagentes não precisam de Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // resumos de compactação via Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Resultado esperado: as entradas de subagentes nos seus logs devem agora mostrar preço de Haiku. Os heartbeats devem custar quase nada. Sua cadeia de fallback garante que uma queda do Claude não paralise a sessão — ela degrada de forma elegante para o Gemini.
| Faixa de uso | Padrão | Config B | Economia |
|---|---|---|---|
| Leve | ~$100 | ~$20 | 80% |
| Moderado | ~$500 | ~$150 | 70% |
| Intenso | ~$1.750 | ~$500 | 71% |
Config C: Power user — stack completa de otimização
Atribuição de modelo por subagente, compactação de contexto fixa em Haiku, roteamento de visão para Gemini Flash, .clawrules + .clawignore enxutos e habilidades não usadas desativadas. Esta é a configuração que leva você à faixa de 85–90% de economia.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // provedor diferente como backup
"minimax/minimax-m2-7", // fallback econômico para o dia a dia
"anthropic/claude-haiku-4-5" // último recurso
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // sem heartbeats durante a madrugada
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // reduzido do padrão 20000
"imageModel": "google/gemini-3-flash" // tarefas visuais via modelo barato
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // memória mínima
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Exemplo de override por subagente — cole em ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: Executa verificações de lint/format e aplica correções triviais
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
.clawignore mínimo viável — isso sozinho reduz bootstraps típicos de 150 mil caracteres para algo entre 30–50 mil:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Faixa de uso | Padrão | Config C | Economia |
|---|---|---|---|
| Leve | ~$100 | ~$12 | 88% |
| Moderado | ~$500 | ~$90 | 82% |
| Intenso | ~$1.750 | ~$220 | 87% |
Esses números batem com dois relatos independentes de usuários reais: o caso documentado de Praney Behl de $600–750/mês → $3–4/dia (corte de 90%) e os estudos de caso da LaoZhang mostrando $943 → $347 (63%), $1.750 → $1.000 (64%), $200 → $70 (65%) com otimização parcial.
Como usar o comando /model para controlar o uso de tokens do OpenClaw em tempo real
O comando /model troca o modelo ativo para o próximo turno enquanto preserva o contexto da conversa — sem reset, sem perder histórico. Esse é o hábito diário que multiplica a economia ao longo do tempo.
Fluxo de trabalho prático:
- Trabalhando numa refatoração pesada em vários arquivos? Fique no Sonnet.
- Pergunta rápida do tipo “o que esse regex faz?”?
/model haiku, pergunte, depois/model sonnetpara voltar. - Mensagem de commit ou polimento de documentação?
/model flash-lite, pronto.
Você pode criar aliases em openclaw.json em commands.aliases para mapear nomes curtos (haiku, sonnet, opus, flash) às strings completas dos provedores. Economiza alguns toques de teclado a cada troca.
A conta: 50 consultas/dia no Sonnet dá algo em torno de US$ 3/dia. As mesmas 50 consultas divididas em 70/20/10 entre Haiku/Sonnet/Opus ficam em cerca de US$ 1,10/dia. Em um mês, isso vai de US$ 90 para US$ 33 — 63% mais barato sem mudar ferramentas, só hábitos.
Bônus: acompanhando preços de modelos do OpenClaw entre provedores com Thunderbit
Acompanhe preços de modelos entre provedores com IA Get Started Free
Com tantos modelos e provedores — OpenRouter, API direta da Anthropic, Google AI Studio, DeepSeek, MiniMax — os preços mudam o tempo todo. A Anthropic reduziu o preço de saída do Opus em cerca de 67% de uma hora para outra. O Google apertou os limites do Gemini no plano gratuito em 50–80% em dezembro de 2025. Manter uma planilha estática de preços atualizada manualmente é uma batalha perdida.
Thunderbit resolve isso sem precisar de código de scraping. É uma extensão de Chrome de AI web scraper feita exatamente para esse tipo de extração estruturada de dados.
O fluxo que eu uso:
- Abra a página de modelos do OpenRouter no Chrome e clique em “AI Suggest Fields” do Thunderbit. Ele lê a página e propõe colunas — nome do modelo, preço de entrada, preço de saída, janela de contexto, provedor.
- Clique em Scrape e depois exporte diretamente para o Google Sheets.
- Configure uma extração agendada em linguagem natural — “toda segunda-feira às 9h, reextraia a lista de modelos do OpenRouter” — e ela roda automaticamente na nuvem.
A partir daí, seu rastreador pessoal de preços se atualiza sozinho. Qualquer modelo que fique 30% mais barato de repente — ou qualquer provedor que receba uma tag Exacto — aparece na sua planilha de segunda-feira de manhã sem você fazer nada. Escrevemos mais sobre extração de dados com IA para negócios no nosso blog.
Comparando preços em páginas diretas dos provedores (Anthropic, Google, DeepSeek)? O scraping de subpáginas do Thunderbit segue cada link de modelo até a página de detalhes e extrai as tarifas por provedor — útil quando você quer saber se rotear Kimi K2.5 via OpenRouter sai mais barato do que ir direto pelo NVIDIA Build. Veja preços do Thunderbit para detalhes do plano e do plano gratuito.
Principais conclusões para cortar o uso de tokens do OpenClaw
O framework é: Entender → Monitorar → Roteirizar → Otimizar.
Ações de maior impacto, em ordem:
- Não deixe Opus como padrão. Troque o modelo principal para Sonnet ou MiniMax M2.7. Isso sozinho já reduz o custo em 3–5x.
- Isole os heartbeats. Defina
isolatedSession: truee roteie os heartbeats para Gemini Flash-Lite. Isso transforma um consumo de ~100k tokens em ~2–5k. - Roteie subagentes para Haiku. Cada spawn carrega cerca de 20k tokens de contexto antes de fazer qualquer coisa. Não deixe isso acontecer no Opus.
- Use
/clearcom disciplina. É gratuito, leva 5 segundos e, segundo o consenso da comunidade, economiza mais do que qualquer outra ação isolada. - Adicione
.clawignore. Excluirnode_modules, lockfiles e artefatos de build reduz drasticamente o contexto carregado no bootstrap. - Monitore com
/context detailantes e depois das mudanças. Se você não mede, não melhora.
O modelo mais barato depende da tarefa. Gemini Flash-Lite para heartbeats. MiniMax M2.7 para programação diária. Haiku para chamadas de ferramentas confiáveis. Sonnet para trabalhos complexos em várias etapas. Opus só para os problemas realmente mais difíceis — e nada além disso.
A maioria dos leitores consegue ver uma economia de 50–70% numa única tarde com a Config A ou B. A faixa completa de 85–90% exige empilhar tudo o que vimos — roteamento de modelos, correção dos vazamentos ocultos, .clawignore, disciplina de sessão —, mas é perfeitamente possível, e funciona de forma duradoura.
Perguntas frequentes
1. Quanto custa o OpenClaw por mês?
Depende totalmente da sua configuração, do volume de uso e dos modelos escolhidos. Usuários leves (~10 consultas/dia) costumam gastar US$ 5–30/mês com otimização, ou mais de US$ 100 com os padrões. Usuários moderados (~50 consultas/dia) ficam entre US$ 90–400/mês. Usuários intensos podem chegar a US$ 600–2.000+/mês com os padrões — um extremo documentado foi US$ 5.623 em um único mês. A própria telemetria interna da Anthropic sugere uma mediana de US$ 13/desenvolvedor/dia ativo.
2. Qual é o modelo mais barato do OpenClaw que ainda funciona bem para programar?
O MiniMax M2.5/M2.7 é o melhor modelo diário para uso geral — boa confiabilidade em tool calling, SWE-Pro 56,22, a cerca de US$ 0,28/US$ 1,10 por milhão de tokens. Para heartbeats e consultas simples, o Gemini 2.5 Flash-Lite a US$ 0,10/US$ 0,40 é difícil de bater. O Claude Haiku 4.5, a US$ 1/US$ 5, é o fallback intermediário confiável quando você precisa de excelente tool calling sem pagar o preço do Sonnet.
3. Posso usar modelos de plano gratuito com o OpenClaw?
Tecnicamente, sim. O GPT-OSS-120B é gratuito no tag :free do OpenRouter e no NVIDIA Build. O Gemini Flash-Lite tem plano gratuito (15 RPM, 1.000 requisições/dia). O DeepSeek oferece 5 milhões de tokens grátis no cadastro. Mas planos gratuitos têm limites agressivos, velocidades mais lentas e disponibilidade pouco confiável. Modelos pagos baratos — centavos por milhão de tokens — são bem mais confiáveis para uso regular.
4. Trocar de modelo no meio da conversa com /model faz perder o contexto?
Não. O /model preserva todo o contexto da sessão — o próximo turno vai para o novo modelo com o histórico completo intacto. Isso é confirmado na documentação de conceitos do OpenClaw e funciona do mesmo jeito no Claude Code. Você pode alternar livremente entre Haiku para perguntas rápidas e Sonnet para trabalho complexo sem perder nada.
5. Qual é a forma mais rápida de reduzir minha conta do OpenClaw hoje?
Digite /clear entre tarefas sem relação. É grátis, leva cinco segundos e apaga o histórico da conversa que é reenviado em toda chamada de API. Uma sessão real mostrou 185.000 tokens de histórico acumulado — tudo isso sendo retransmitido e recobrado em cada turno. Limpar isso antes de começar um novo trabalho é o hábito com melhor retorno que você pode criar.
Experimente Thunderbit para scraping de dados da web com IA Get Started Free




