

A web transborda de dados, e a vontade de os extrair cresce depressa — embora, se procurar um único número sobre o tamanho desse mercado, vá encontrar estimativas que divergem numa ordem de grandeza, dependendo de o analista estar a contar software, serviços, proxies ou os três. A leitura mais honesta é que o web scraping já se afirmou naquele canto silencioso, mas essencial, da pilha de dados.
Se é analista de negócios, profissional de marketing ou apenas um principiante curioso, a capacidade de extrair dados de um site está rapidamente a tornar-se uma competência indispensável. E, se for como eu, provavelmente quer saltar a rotina infinita de copiar e colar e ir direto ao que interessa: insights acionáveis, folhas de cálculo limpas e talvez até um pouco de magia da automação.
É aí que entra o Python. É o canivete suíço do mundo dos dados — simples o suficiente para iniciantes, mas poderoso bastante para lidar com tudo, desde extrair dados de uma única página até rastrear milhares. Neste tutorial prático, vou mostrar os fundamentos do web scraping com Python, explicar como lidar com sites dinâmicos e até apresentar o Thunderbit, o nosso raspador web sem código, com IA, que torna a extração de dados tão fácil quanto pedir comida por app. Se veio aqui para aprender a programar ou só quer um atalho, está no sítio certo.
O que é Web Scraping e por que usar Python para extrair dados de um site?
Extraia dados de qualquer site com IA Get Started Free
Web scraping é o processo automatizado de extrair informações de sites e convertê-las num formato estruturado — pense em folhas de cálculo, CSVs ou bases de dados — para análise ou uso nos negócios (PromptCloud). Em vez de copiar e colar dados manualmente, um scraper imita o que uma pessoa faria, mas a uma velocidade e escala muito maiores.
Porque é que isto é tão valioso? Porque, no mundo dos negócios de hoje, a tomada de decisão orientada por dados é o nome do jogo. Quanto maior a empresa, mais decisões precisam de ser sustentadas por números reais, e não por intuição — e muitos desses números começam a vida na página de alguém na web.
Imagine conseguir monitorizar preços de concorrentes todos os dias, reunir anúncios de imóveis ou criar uma lista personalizada de leads — tudo sem esforço.
Então, por que Python? Eis por que é a linguagem preferida para web scraping:
- Legibilidade e simplicidade: a sintaxe do Python é limpa e amigável para iniciantes, o que facilita escrever e perceber scripts de scraping (PromptCloud).
- Ecossistema rico: bibliotecas como
requests,BeautifulSoup,ScrapyeSeleniumtornam o scraping, o parsing e a automação de ações no navegador muito mais fáceis. - Suporte da comunidade: como o Python está consistentemente entre as linguagens de programação mais populares do mundo, há infinitos tutoriais, fóruns e exemplos de código para ajudar.
- Escalabilidade: o Python consegue lidar com tudo, desde scripts simples e pontuais até crawlers em grande escala.
Resumindo: Python é a sua porta de entrada para o mundo dos dados da web, seja você um principiante completo ou um analista experiente.
Primeiros passos: fundamentos do tutorial de web scraping em Python
Antes de mergulharmos no código, vamos decompor o fluxo básico para extrair dados de um site com Python:
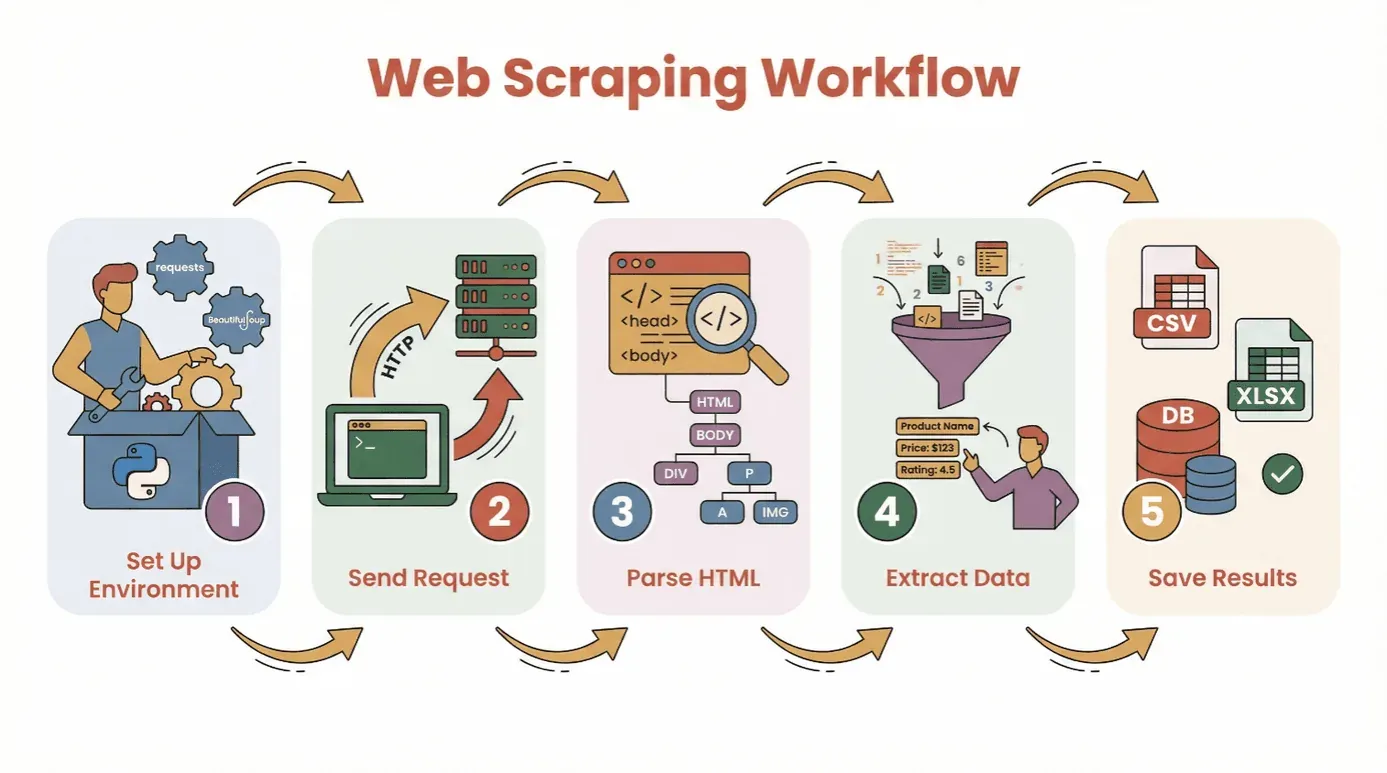
- Configure o seu ambiente: instale o Python e as bibliotecas necessárias (
requests,BeautifulSoupetc.). - Envie um pedido: use Python para obter o conteúdo HTML da página-alvo.
- Faça o parsing do HTML: use um parser para navegar pela estrutura da página.
- Extraia os dados: localize e recolha a informação de que precisa.
- Guarde os resultados: armazene os dados em CSV, Excel ou numa base de dados para análise.
Não precisa de ser um génio da programação para começar. Se sabe instalar o Python e correr um script, já está a meio do caminho. Para quem está a começar do zero, recomendo usar um ambiente virtual ou um notebook Jupyter, mas também pode usar qualquer editor de texto básico.
Bibliotecas essenciais:
requests— para obter páginas webBeautifulSoup— para fazer o parsing do HTMLpandas— para guardar e limpar dados (opcional, mas altamente recomendado)
Como escolher a biblioteca certa de Web Scraping em Python: BeautifulSoup, Scrapy ou Selenium?
Nem todas as ferramentas de scraping em Python são iguais. Aqui vai um resumo rápido das três opções mais populares:
| Ferramenta | Ideal para | Pontos fortes | Limitações |
|---|---|---|---|
| BeautifulSoup | Páginas simples e estáticas; iniciantes | Fácil de usar, configuração mínima, ótima documentação | Não é a melhor opção para crawls grandes ou conteúdo dinâmico |
| Scrapy | Crawling em grande escala, com várias páginas | Rápida, assíncrona, pipelines nativos, lida com crawling e armazenamento | Curva de aprendizagem mais acentuada, exagerada para tarefas pequenas, não executa JavaScript |
| Selenium | Sites dinâmicos ou pesados em JavaScript, automação | Consegue renderizar JS, simular ações do utilizador, suporta logins e cliques | Mais lenta, consome mais recursos, configuração mais complexa |
BeautifulSoup: a opção ideal para parsing simples de HTML
BeautifulSoup é perfeita para iniciantes e projetos pequenos. Permite fazer parsing de HTML e extrair elementos com apenas algumas linhas de código. Se o site-alvo for maioritariamente estático (sem carregamento sofisticado via JavaScript), BeautifulSoup + requests é tudo o que precisa.
Exemplo:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
print(titles)
Quando usar: extrações pontuais, blogs simples, páginas de produto ou diretórios.
Scrapy: para crawling estruturado ou em grande escala
Scrapy é um framework completo para rastrear sites inteiros ou lidar com milhares de páginas. É assíncrono (ou seja, rápido), oferece pipelines para limpar/guardar dados e pode seguir links automaticamente.
Exemplo:
import scrapy
class ProductSpider(scrapy.Spider):
name = "products"
start_urls = ["https://example.com/products"]
def parse(self, response):
for item in response.css('div.product'):
yield {
'name': item.css('h2::text').get(),
'price': item.css('span.price::text').get()
}
Quando usar: projetos grandes, crawls agendados ou quando precisa de velocidade e estrutura.
Selenium: lidando com sites dinâmicos e pesados em JavaScript
Selenium controla um navegador real (como Chrome ou Firefox), por isso consegue lidar com sites que carregam dados com JavaScript, exigem login ou precisam que clique em botões.
Exemplo:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
driver.find_element(By.NAME, "username").send_keys("myuser")
driver.find_element(By.NAME, "password").send_keys("mypassword")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
dashboard = driver.find_element(By.ID, "dashboard").text
print(dashboard)
driver.quit()
Quando usar: redes sociais, sites de ações, infinite scroll ou qualquer coisa que pareça vazia ao “ver o código-fonte”.
Passo a passo: como extrair dados de um site usando Python (tutorial para iniciantes)
Vamos ver um exemplo real usando requests e BeautifulSoup. Vamos extrair títulos, autores e preços de um site simples de livros.
Passo 1: configurar o seu ambiente Python
Primeiro, instale as bibliotecas de que vai precisar:
pip install requests beautifulsoup4 pandas
Depois, importe-as no seu script:
import requests
from bs4 import BeautifulSoup
import pandas as pd
Passo 2: enviar um pedido ao site
Obtenha o conteúdo HTML:
url = "http://books.toscrape.com/catalogue/page-1.html"
response = requests.get(url)
if response.status_code == 200:
html = response.text
else:
print(f"Falha ao obter a página: {response.status_code}")
Passo 3: fazer o parsing do conteúdo HTML
Crie um objeto BeautifulSoup:
soup = BeautifulSoup(html, 'html.parser')
Encontre todos os contentores de livros:
books = soup.find_all('article', class_='product_pod')
print(f"Encontrámos {len(books)} livros nesta página.")
Passo 4: extrair os dados de que precisa
Percorra cada livro e recolha os detalhes:
data = []
for book in books:
title = book.h3.a['title']
price = book.find('p', class_='price_color').text
data.append({"Título": title, "Preço": price})
Passo 5: guardar os dados para análise
Converta num DataFrame e guarde:
df = pd.DataFrame(data)
df.to_csv('books.csv', index=False)
Agora tem um ficheiro CSV limpo, pronto para análise!
Dicas de resolução de problemas:
- Se os resultados vierem vazios, verifique se os dados são carregados por JavaScript (veja a próxima secção).
- Inspecione sempre a estrutura HTML com as ferramentas de desenvolvimento do navegador.
- Trate dados em falta com
get_text(strip=True)e verificações condicionais.
Superar conteúdo dinâmico: extrair dados de sites renderizados por JavaScript
Os sites modernos adoram JavaScript. Às vezes, os dados que quer não estão no HTML inicial — são carregados depois de a página aparecer. Se o seu scraper estiver a devolver nada, talvez esteja a lidar com conteúdo dinâmico.
Como lidar com isso:
- Selenium: simula um navegador real, espera o conteúdo carregar e pode clicar em botões ou fazer scroll na página.
- Playwright/Puppeteer: mais avançados, mas com a mesma ideia (navegadores headless).
Guia rápido de Selenium:
- Instale o Selenium e um driver de navegador (por exemplo, ChromeDriver).
- Use esperas explícitas para deixar o conteúdo carregar.
- Extraia o HTML renderizado e faça o parsing com BeautifulSoup, se necessário.
Exemplo:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com/dynamic")
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# Extraia os dados como antes
driver.quit()
Quando precisa de Selenium?
- Se
requests.get()devolve HTML sem dados, mas os vê no navegador. - Se o site usa infinite scroll, pop-ups ou exige login.
Simplificar o Web Scraping com IA: usando o Thunderbit para extrair dados de um site
Experimente o Raspador Web IA Thunderbit Extraia dados de qualquer site em 2 cliques — sem necessidade de código. Get Started Free
Vamos ser sinceros — às vezes só quer os dados, não o código. É aí que Thunderbit entra. O Thunderbit é uma extensão do Chrome com IA que permite extrair dados de qualquer site com apenas alguns cliques — sem precisar de Python.
Como o Thunderbit funciona:
- Instale a extensão Chrome do Thunderbit.
- Abra o site-alvo.
- Clique no ícone do Thunderbit e selecione “Sugerir Campos com IA”. A IA do Thunderbit analisa a página e recomenda quais os dados a extrair (por exemplo, nomes de produtos, preços, e-mails).
- Ajuste os campos, se necessário, e clique em “Extrair”.
- Exporte os dados diretamente para Excel, Google Sheets, Notion ou Airtable.
Por que o Thunderbit é incrível:
- Sem necessidade de código. Até a minha mãe consegue usar (e ela ainda me chama quando o Wi-Fi falha).
- Lida com subpáginas e paginação. Precisa de extrair detalhes de produtos em várias páginas? O Thunderbit pode clicar em tudo e juntar os dados por si.
- Instruções em linguagem natural. Basta dizer o que quer (“extraia todos os títulos e preços dos produtos”) e deixar a IA tratar do resto.
- Modelos instantâneos para sites populares. Amazon, Zillow, LinkedIn e muito mais — um clique e está feito.
- Exportação de dados gratuita. Faça download em CSV, Excel ou envie diretamente para as suas ferramentas favoritas.
O Thunderbit é usado por mais de 100.000 utilizadores em todo o mundo. Há um plano gratuito que pode testar sem pagar nada — veja a página de preços para confirmar a cota atual, já que os limites mudaram algumas vezes. Para utilizadores empresariais, poupa tempo; para quem usa Python, é uma ótima forma de dimensionar um trabalho antes de decidir se vale a pena escrever o próprio scraper.
Experimente o Thunderbit grátis – sem código
Depois da extração: limpar e analisar dados com Pandas e NumPy
Extrair dados é só o primeiro passo. Dados brutos da web costumam vir desarrumados — duplicados, valores em falta, formatos estranhos. É aí que as bibliotecas pandas e NumPy do Python brilham.
Tarefas comuns de limpeza:
- Remover duplicados:
df.drop_duplicates(inplace=True) - Lidar com valores em falta:
df.fillna('Unknown')oudf.dropna() - Converter tipos de dados:
df['Price'] = df['Price'].str.replace('$','').astype(float) - Interpretar datas:
df['Date'] = pd.to_datetime(df['Date']) - Filtrar outliers:
df = df[df['Price'] > 0]
Análise básica:
- Estatísticas resumidas:
df.describe() - Agrupar por categoria:
df.groupby('Category')['Price'].mean() - Gráficos rápidos:
df['Price'].hist()oudf.groupby('Category')['Price'].mean().plot(kind='bar')
Para matemática mais avançada ou operações rápidas com arrays, o NumPy é o seu aliado. Mas, para a maioria dos utilizadores de negócios, o pandas cobre 95% do que precisa.
Recursos: se está a começar no pandas, veja o guia 10 Minutes to pandas.
Boas práticas e dicas para ter sucesso com web scraping em Python
Web scraping é poderoso, mas também traz responsabilidades. Aqui fica o meu checklist para fazer scraping como um profissional — e não acabar bloqueado ou processado:
- Respeite o robots.txt e os Termos de Serviço. Verifique sempre se o site permite scraping (PromptCloud).
- Não sobrecarregue os servidores. Adicione atrasos entre pedidos (
time.sleep(2)) e faça scraping a uma velocidade humana. - Use cabeçalhos realistas. Defina uma string de User-Agent para imitar um navegador.
- Lide com erros com elegância. Use blocos try/except e tente novamente em pedidos com falha.
- Alterne proxies se necessário. Para scraping em grande escala, considere usar pools de proxies para evitar banimento de IP.
- Seja ético e legal. Não extraia dados pessoais nem conteúdo atrás de login sem permissão.
- Documente o seu processo. Anote o que extraiu, de onde e quando.
- Use APIs oficiais quando estiverem disponíveis. Às vezes, há uma forma melhor do que raspar HTML.
Para mais dicas, veja o Guia Definitivo de Web Scraping.
Conclusão e principais aprendizagens
Fazer web scraping com Python é um superpoder para quem quer transformar o caos da web em dados estruturados e acionáveis. Seja usando código (com requests, BeautifulSoup, Scrapy ou Selenium) ou uma ferramenta sem código como o Thunderbit, tem as ferramentas para extrair dados de um site e desbloquear novos insights.
Lembre-se:
- Comece simples — extraia uma única página antes de enfrentar projetos grandes.
- Escolha a ferramenta certa para a sua necessidade (BeautifulSoup para o básico, Scrapy para escala, Selenium para sites dinâmicos, Thunderbit para sem código).
- Limpe e analise os seus dados com pandas e NumPy.
- Faça sempre scraping com responsabilidade e ética.
Pronto para testar você mesmo? Comece com um projeto pequeno — talvez extrair os títulos das notícias de hoje ou uma lista de produtos — e veja como consegue passar de uma página web bruta para uma folha de cálculo limpa em pouco tempo. E, se quiser saltar o código, descarregue o Thunderbit e deixe a IA fazer o trabalho pesado.
Para mais tutoriais, dicas e conhecimento sobre web scraping, veja o Blog do Thunderbit.
Leia mais tutoriais de Web Scraping
Perguntas frequentes
1. O que é web scraping e por que o Python é popular para isso?
Web scraping é a extração automatizada de dados de sites. O Python é popular para web scraping por causa da sintaxe legível, de bibliotecas poderosas (como BeautifulSoup, Scrapy e Selenium) e do forte suporte da comunidade (PromptCloud).
2. Que biblioteca de Python devo usar para web scraping?
Use BeautifulSoup para páginas simples e estáticas; Scrapy para crawling em grande escala ou em várias páginas; e Selenium para sites dinâmicos ou pesados em JavaScript. Cada uma tem os seus pontos fortes, dependendo da sua necessidade (IPRoyal).
3. Como lidar com sites que carregam dados com JavaScript?
Para conteúdo renderizado por JavaScript, use Selenium (ou Playwright) para simular um navegador e aguarde o conteúdo carregar antes de extrair os dados. Às vezes, consegue encontrar um endpoint de API subjacente ao inspecionar o tráfego de rede.
4. O que é o Thunderbit e como simplifica o web scraping?
Thunderbit é uma extensão do Chrome com IA que permite extrair dados de qualquer site sem programar. Usa IA para sugerir campos, lidar com subpáginas e paginação, e exporta os dados diretamente para Excel, Google Sheets, Notion ou Airtable.
5. Como posso limpar e analisar dados extraídos em Python?
Use pandas para remover duplicados, lidar com valores em falta, converter tipos de dados e fazer análises. O NumPy é ótimo para operações numéricas. Para visualização, o pandas integra-se com o Matplotlib para gráficos rápidos (10 Minutes to pandas).
Boa extração — e que os seus dados estejam sempre limpos, estruturados e prontos para a ação.
Experimente o Raspador Web IA Get Started Free
Saiba mais




