Se você já tentou extrair dados de um site moderno — como um portal imobiliário, uma loja de ecommerce ou até o seu feed favorito de redes sociais — provavelmente bateu num muro. Você carrega a página, dá uma olhada no HTML e… nada. Os detalhes valiosos que você quer (preços, anúncios, avaliações) simplesmente não estão ali. Isso acontece porque a web de hoje já não é só HTML — ela é movida por JavaScript, e quase 99% de todos os sites agora usam scripts no lado do cliente para renderizar conteúdo (). Os crawlers tradicionais são como tentar assistir a um filme lendo o roteiro — eles perdem a ação que acontece ao vivo.
Passei anos em SaaS e automação e vi de perto como essa mudança deixou usuários de negócios, equipes de vendas e pesquisadores coçando a cabeça. Mas aqui vai a boa notícia: dominar o crawling em JavaScript já não é só para desenvolvedores. Com a abordagem certa (e uma ajudinha de ferramentas de IA como o ), qualquer pessoa consegue extrair dados até dos sites mais dinâmicos e interativos. Vamos entender o que é o crawling em JavaScript, por que isso importa e como começar — sem precisar programar.
O que é crawling em JavaScript? Por que isso é importante para a extração moderna de dados da web?
Vamos começar pelo básico. Crawling em JavaScript significa usar uma ferramenta ou bot capaz de carregar uma página da web, executar todo o JavaScript dela e extrair o conteúdo que aparece depois que os scripts rodam. Isso é um salto enorme em relação ao scraping de HTML “à moda antiga”, que só captura o código-fonte bruto enviado pelo servidor. Na web de hoje, esse HTML bruto muitas vezes é só uma estrutura vazia — o conteúdo real (listas de produtos, avaliações, preços) é preenchido por JavaScript, às vezes só depois de rolar a página, clicar ou interagir.
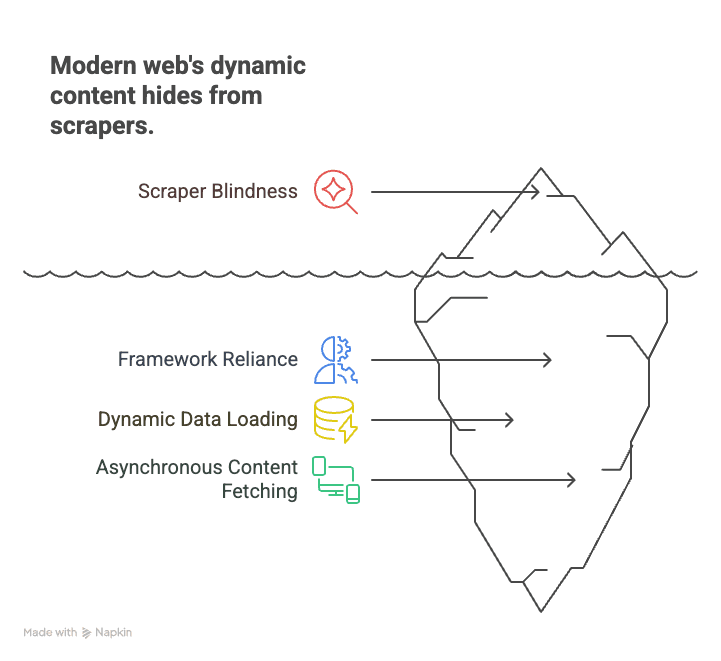
Por que isso importa? Porque a web moderna é construída sobre frameworks como React, Angular e Vue. Essas aplicações de página única (SPAs) carregam dados sob demanda, tornando os scrapers estáticos “cegos” para boa parte do conteúdo. Por exemplo:
- Ecommerce: preços e níveis de stock dos produtos só carregam depois que você rola a página ou seleciona um filtro.
- Imóveis: os anúncios aparecem conforme você desce a página, com detalhes carregados dinamicamente.
- Redes sociais: posts, comentários e curtidas são buscados de forma assíncrona e não aparecem no HTML inicial.
Os crawlers tradicionais fazem a requisição da página, encontram uma casca vazia e perdem tudo o que é importante. Já o crawling em JavaScript é como abrir a página no Chrome, deixar todos os scripts rodarem e depois capturar exatamente o que você vê — como uma pessoa faria.
Em resumo: se você quer extrair dados de praticamente qualquer site moderno em 2025, precisa dominar o crawling em JavaScript. Caso contrário, vai deixar passar a maior parte do conteúdo ().
Principais desafios do crawling em JavaScript (e como superá-los)
Crawling em JavaScript não é só “scraping, mas com mais etapas”. Ele traz os seus próprios obstáculos. Veja com o que você vai lidar — e como vencer cada desafio.
Renderização dinâmica de conteúdo
O desafio: a maior parte do conteúdo nem está no HTML. Ele é carregado via JavaScript depois que a página abre — às vezes após uma rolagem, um clique ou uma chamada de rede. Se você apenas buscar o HTML, recebe espaços reservados ou contêineres vazios.
A solução: use um navegador headless — uma ferramenta que simula um navegador real, executa todos os scripts e espera o conteúdo aparecer. Ferramentas como e são os padrões da indústria aqui. Elas permitem:
- Abrir uma página e deixar o JavaScript rodar.
- Esperar que elementos específicos carreguem (como “.product-list”).
- Extrair o conteúdo totalmente renderizado do DOM.
Essa abordagem agora é o padrão ouro para extrair dados de sites dinâmicos ().
Barreiras anti-bot e de automação
O desafio: os sites estão ficando mais inteligentes para bloquear bots. Espere encontrar:
- CAPTCHAs
- Bloqueio de IPs ou limitação de taxa
- Impressão digital do navegador (verificar se você é um usuário real)
- Armadilhas honeypot (links falsos para apanhar bots)
A solução: faça o crawling com responsabilidade e imite o comportamento humano:
- Respeite o robots.txt e os termos de serviço.
- Controle as suas requisições — adicione atrasos aleatórios e não sobrecarregue o servidor.
- Alterne IPs se estiver a extrair em escala (mas faça isso de forma ética).
- Use cabeçalhos reais do navegador e evite sinais óbvios de bot.
- Não extraia dados atrás de login nem burle CAPTCHAs sem permissão.
O Thunderbit, por exemplo, incentiva os usuários a extrair apenas dados publicamente acessíveis e já incorpora boas práticas de conformidade ().
Rolagem infinita e eventos acionados pelo usuário
O desafio: muitos sites usam rolagem infinita ou exigem cliques para carregar mais dados. Se o seu scraper captura só o que está visível inicialmente, você perde a maior parte do conteúdo.
A solução: use automação de navegador para:
- Simular a rolagem (carregando mais resultados como um usuário faria).
- Clicar em botões “Carregar mais” ou abas.
- Aguardar o novo conteúdo aparecer antes de extrair.
A IA do Thunderbit consegue detectar esses padrões e lidar com rolagem ou paginação para você, então não precisa escrever scripts personalizados ().
Mantendo desempenho e escala
O desafio: executar um navegador headless para cada página consome muitos recursos. Extrair centenas ou milhares de páginas pode ser lento e pesado para o computador.
A solução: use crawling concorrente — execute vários navegadores ou abas em paralelo. Ou, melhor ainda, terceirize o trabalho para a nuvem. O acelerador de scraping em nuvem do Thunderbit (também conhecido como Lightning Network) pode extrair até 50 páginas de uma vez, acelerando enormemente tarefas grandes ().
Thunderbit: tornando o crawling em JavaScript simples e poderoso
Falando francamente: a maioria dos usuários de negócios não quer escrever código, depurar seletores ou ficar a cuidar de scripts. É por isso que criámos o — um raspador web com IA, feito para quem não é desenvolvedor e precisa de dados de sites dinâmicos e pesados em JavaScript.
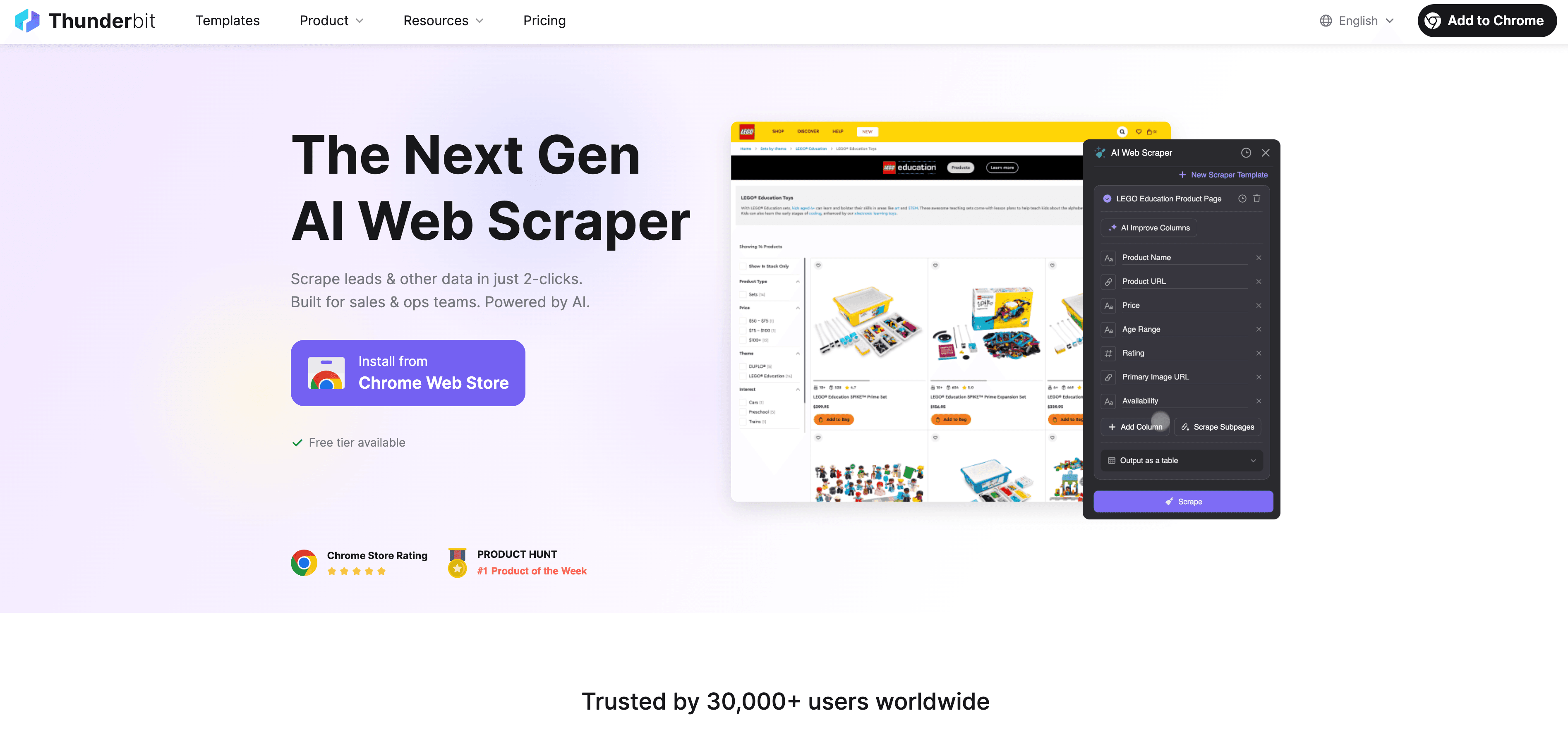
Veja como o Thunderbit tira a dor do crawling em JavaScript:
- AI Suggest Fields: basta clicar em “AI Suggest Fields” e a IA do Thunderbit analisa a página, recomenda as melhores colunas para extrair e define os tipos de dados corretos. Acabou o chute ou o vai-e-vem de tentativa e erro.
- Extração em linguagem natural: descreva o que quer em português simples (“pegue nome do produto, preço e avaliação”) e o Thunderbit descobre como obter isso.
- Lida com conteúdo dinâmico: o Thunderbit roda num navegador real (o seu Chrome ou na nuvem), então executa todo o JavaScript e espera o conteúdo carregar — como uma pessoa.
- Suporte a subpáginas e paginação: precisa extrair várias páginas ou seguir links para subpáginas (como detalhes de produto)? O Thunderbit faz isso automaticamente, combinando todos os dados numa única tabela.
- Aceleração na nuvem: para tarefas grandes, a Lightning Network do Thunderbit extrai até 50 páginas de uma vez na nuvem, sem fazer o seu computador suar.
- Interface sem código e fácil de usar: se você sabe usar Excel, sabe usar o Thunderbit. É clicar e apontar, sem configuração técnica.
- Exportação gratuita de dados: exporte os seus dados para Excel, Google Sheets, Airtable, Notion ou JSON — sem taxas extras.
O Thunderbit é confiável para mais de 30.000 usuários no mundo todo, de equipes de vendas a operadores de ecommerce e profissionais do setor imobiliário ().
AI Suggest Fields e extração em linguagem natural
É aqui que o Thunderbit realmente brilha. Em vez de ficar vasculhando o HTML ou escrevendo seletores XPath, basta clicar num botão e a IA do Thunderbit faz o trabalho pesado. Ela lê a página, entende a estrutura e recomenda exatamente o que extrair. Se quiser algo específico, é só escrever em português claro — a IA do Thunderbit mapeia o seu pedido para os elementos certos.
Isso muda o jogo para iniciantes. Você não precisa saber nada de HTML, CSS ou JavaScript. É só dizer o que quer e deixar a IA cuidar do resto ().
Crawling com paginação e subpáginas
O Thunderbit não é só para uma página. Ele consegue:
- Detectar e lidar com paginação (clicando em “Próximo” ou rolando para carregar mais).
- Extrair subpáginas (como detalhes de produto, perfis de autores ou avaliações) e mesclar os dados na sua tabela principal.
- Lidar com rolagem infinita simulando ações do usuário, para que você obtenha todos os dados, e não apenas o que aparece primeiro.
Por exemplo: vai extrair uma categoria de ecommerce com 20 páginas de produtos? O Thunderbit clica automaticamente em todas as páginas e combina os resultados. Precisa de detalhes de cada página de produto? Use a extração de subpáginas, e o Thunderbit visitará cada link, recolherá as informações extra e enriquecerá o seu conjunto de dados ().
Lightning Network e aceleração na nuvem: escalando o seu crawling em JavaScript
Quando você precisa extrair centenas ou milhares de páginas, fazer isso uma por uma simplesmente não é prático. É aí que entra a Lightning Network do Thunderbit.
- Scraping em nuvem: descarregue o trabalho pesado nos servidores em nuvem do Thunderbit (nos EUA, na UE e na Ásia). A nuvem pode extrair até 50 páginas ao mesmo tempo, acelerando enormemente tarefas grandes.
- Crawling concorrente: em vez de esperar que cada página carregue no seu navegador, a nuvem do Thunderbit distribui a tarefa entre vários workers. Vai extrair 1.000 páginas de produtos? A nuvem pode terminar em minutos, não em horas.
- Scraping agendado: precisa monitorizar preços ou anúncios todos os dias? Configure uma extração agendada em linguagem simples (“todos os dias às 9h”) e o Thunderbit executa a tarefa automaticamente, exportando os dados para a sua planilha do Google ou base de dados ().
Isso salva a vida de equipes de vendas, ecommerce e operações que precisam de dados atualizados em escala — sem contratar um desenvolvedor ou manter servidores.
Extração multi-página e em lote
O Thunderbit facilita:
- Extrair diretórios ou catálogos inteiros (por exemplo, todos os produtos de uma categoria, todos os anúncios de uma região).
- Exportar os resultados para Excel, Google Sheets, Airtable ou Notion com um clique.
- Poupar horas (ou dias) de trabalho manual — um usuário extraiu centenas de anúncios imobiliários, com detalhes dos corretores, em menos de 10 minutos.
Guia passo a passo: como começar a fazer crawling em JavaScript com Thunderbit
Pronto para testar? Veja como começar com o Thunderbit — mesmo que você nunca tenha extraído dados de um site antes.
Configurando o seu primeiro crawl
- Instale o Thunderbit: baixe a . Crie uma conta gratuita.
- Escolha o alvo: navegue até o site que quer extrair. Se ele exigir login, faça login primeiro (o Thunderbit funciona no contexto do seu navegador).
- Abra o Thunderbit: clique no ícone do Thunderbit na barra de ferramentas do Chrome. Escolha a sua fonte de dados (página atual, lista de URLs ou envio de ficheiro).
- Escolha o modo de execução: para tarefas pequenas ou sites que exigem login, use o modo Navegador. Para tarefas em larga escala, mude para o modo Nuvem para extração paralela.
- AI Suggest Fields: clique em “AI Suggest Fields”. A IA do Thunderbit vai analisar a página e recomendar colunas para extração (como “Nome do Produto”, “Preço”, “URL da Imagem”).
- Ajuste as colunas: renomeie, adicione ou remova campos conforme necessário. Adicione instruções personalizadas de IA se quiser formatar ou categorizar os dados.
- Configure paginação/rolagem: se o site usa paginação ou rolagem infinita, ative a opção correspondente nas configurações do Thunderbit.
- Clique em “Scrape”: o Thunderbit vai carregar a(s) página(s), executar todo o JavaScript e extrair os dados para uma tabela.
Extraindo e exportando dados
- Pré-visualize os resultados: o Thunderbit mostra os seus dados numa tabela. Faça uma verificação rápida de completude e precisão.
- Exporte: clique em “Exportar” para baixar em Excel, CSV, JSON ou enviar diretamente para Google Sheets, Airtable ou Notion.
- Valide: compare algumas linhas com o site ao vivo para garantir que tudo confere.
- Solução de problemas: se estiver faltando dado, tente rolar a página primeiro, ajustar as instruções de IA ou mudar para o modo Nuvem para melhor desempenho.
Para um passo a passo mais detalhado, confira os ou o .
Melhores práticas para um crawling em JavaScript seguro e em conformidade
Com grande poder de scraping vem grande responsabilidade. Veja como ficar do lado certo da lei (e da ética):
- Respeite o robots.txt e os Termos de Serviço: sempre verifique se o site permite extração de dados. Se disser “sem bots”, não force a barra ().
- Evite extrair dados pessoais: GDPR e CCPA tratam nomes, e-mails e perfis como dados protegidos — mesmo que sejam públicos. Só extraia informações pessoais se tiver um motivo legítimo e consentimento.
- Não burle logins ou CAPTCHAs: isso entra numa zona cinzenta legal (ou pior). Fique com dados públicos.
- Controle as suas requisições: não sobrecarregue os servidores. O modo Nuvem do Thunderbit distribui as requisições ao longo do tempo e alterna IPs para evitar bloqueios.
- Use os dados com ética: não republique conteúdo protegido por direitos autorais nem use indevidamente informações extraídas.
- Apague mediante solicitação: se alguém pedir para remover os dados, remova.
O Thunderbit foi criado para incentivar a conformidade — apenas dados públicos, sem invasão e com opções claras de exportação para uso responsável.
Evitando riscos legais
- Fique apenas com dados públicos e não pessoais.
- Não extraia sites que proíbem explicitamente a prática.
- Na dúvida, peça permissão ou use a API oficial do site.
- Guarde registros do que foi extraído e quando.
- Atenda imediatamente a notificações de cessar e desistir.
Para um aprofundamento, veja .
Comparando soluções de crawling em JavaScript: Thunderbit vs. ferramentas tradicionais
| Aspecto | Puppeteer/Playwright (Código) | Sitebulb (Crawler de SEO) | Thunderbit (IA sem código) |
|---|---|---|---|
| Tempo de configuração | Horas (exige programação) | Moderado (configuração) | Minutos (clicar e apontar) |
| Nível de habilidade necessário | Alto (só devs) | Médio | Baixo (qualquer pessoa) |
| Lida com conteúdo em JS | Sim (script manual) | Sim (para SEO) | Sim (IA, automático) |
| Paginação/Subpáginas | Script manual | Limitado | Automático (IA detecta) |
| Manutenção | Alta (quebra com mudanças) | Moderada | Baixa (a IA se adapta) |
| Escalabilidade | Manual (escrever código) | Limitada | Nuvem integrada (50x) |
| Opções de exportação | Manual (escrever código) | CSV/Excel | Excel, Sheets, Notion |
| Melhor para | Devs, fluxos personalizados | Auditorias de SEO | Usuários de negócios, analistas |
O Thunderbit é o vencedor claro para usuários de negócios que querem resultados rápidos, sem dor de cabeça técnica ().
Conclusão e principais aprendizados
O crawling em JavaScript deixou de ser uma habilidade de nicho — hoje é indispensável para qualquer pessoa que precisa de dados da web em 2025. Com quase 99% dos sites a rodarem scripts no lado do cliente, o scraping tradicional simplesmente já não dá conta do recado (). A boa notícia? Você não precisa ser desenvolvedor para dominá-lo.
O que vale lembrar:
- Conteúdo dinâmico está em todo lugar: se quiser extrair sites modernos, precisa de uma ferramenta que execute JavaScript.
- Os desafios são reais, mas têm solução: navegadores headless, espera inteligente e aceleração na nuvem tornam possível extrair até os dados mais difíceis.
- O Thunderbit facilita tudo: com sugestões de campos por IA, extração em linguagem natural, suporte a subpáginas e paginação e aceleração na nuvem, o Thunderbit coloca um crawling em JavaScript poderoso nas mãos de qualquer pessoa.
- Mantenha a conformidade: respeite sempre as regras do site, as leis de privacidade e as diretrizes éticas.
- Comece hoje: instale o Thunderbit, escolha um site e veja quanta informação você consegue desbloquear em apenas alguns cliques.
Quer se aprofundar? Confira o para mais guias ou assista aos nossos para demonstrações passo a passo.
Boa extração — e que os seus dados sejam sempre dinâmicos, completos e prontos para a ação.
Perguntas frequentes
1. O que é crawling em JavaScript e em que ele difere do scraping tradicional?
O crawling em JavaScript usa uma ferramenta que carrega uma página da web, executa todo o JavaScript e extrai o conteúdo que aparece depois que os scripts rodam. O scraping tradicional captura apenas o HTML bruto, perdendo a maior parte do conteúdo nos sites modernos.
2. Por que preciso de crawling em JavaScript para extrair dados de negócios?
Porque praticamente todos os sites modernos usam JavaScript para carregar conteúdo dinamicamente. Sem crawling em JavaScript, você vai perder listas de produtos, avaliações, preços e outros dados importantes.
3. Como o Thunderbit simplifica o crawling em JavaScript para iniciantes?
O Thunderbit usa IA para sugerir campos, lidar com conteúdo dinâmico e automatizar paginação e extração de subpáginas. Você pode descrever o que quer em português simples — sem precisar programar.
4. Crawling em JavaScript é legal? O que devo observar?
O crawling em JavaScript é legal quando feito com responsabilidade — fique com dados públicos, respeite o robots.txt e os termos de serviço e evite extrair informações pessoais sem consentimento. O Thunderbit incentiva a conformidade e o uso responsável.
5. Como posso escalar meu crawling em JavaScript para tarefas grandes?
A Lightning Network do Thunderbit (scraping em nuvem) permite extrair até 50 páginas por vez, facilitando tarefas grandes como monitorização de preços ou geração de leads em milhares de páginas.
Saiba mais: