Os dados disponíveis na web são como ouro para quem sabe aproveitar — mas estão espalhados por milhares de sites, escondidos em HTML bagunçado e protegidos por CAPTCHAs e scripts anti-bot cada vez mais espertos. Se você já tentou copiar manualmente preços de produtos, informações de concorrentes ou listas de leads, sabe que é um caminho certo para dor no pulso e oportunidades que escapam. Por isso, a raspagem web virou uma habilidade indispensável para empresas modernas. Só para ter uma noção, o mercado de dados alternativos (onde a raspagem web está incluída) movimentou e não para de crescer.

Mas aqui vai o pulo do gato: enquanto Python é a escolha mais comum para quem está começando, Go (ou Golang, para os íntimos) é o motor por trás de alguns dos raspadores mais rápidos e parrudos do mercado. O segredo do Go? Concorrência de verdade, biblioteca padrão completíssima e uma performance que faz qualquer dev de backend abrir um sorriso. Já vi times cortarem o tempo de raspagem pela metade só trocando para Go — e com as ferramentas certas, você não precisa ser engenheiro do Google para embarcar nessa.
Quer transformar Go no seu superpoder para raspagem web? Vem comigo nesse passo a passo — do setup ao scraping avançado — com exemplos práticos, dicas de quem já ralou no dia a dia e como ferramentas de IA como o podem dar aquele gás no seu fluxo de trabalho.
Por que Apostar em Go para Raspagem Web? O Lado Prático
Vamos ser sinceros: quando o assunto é raspar milhares (ou milhões) de páginas, cada segundo conta. Go nasceu para esse tipo de missão pesada. Olha só por que cada vez mais empresas estão apostando em Go para raspagem web:
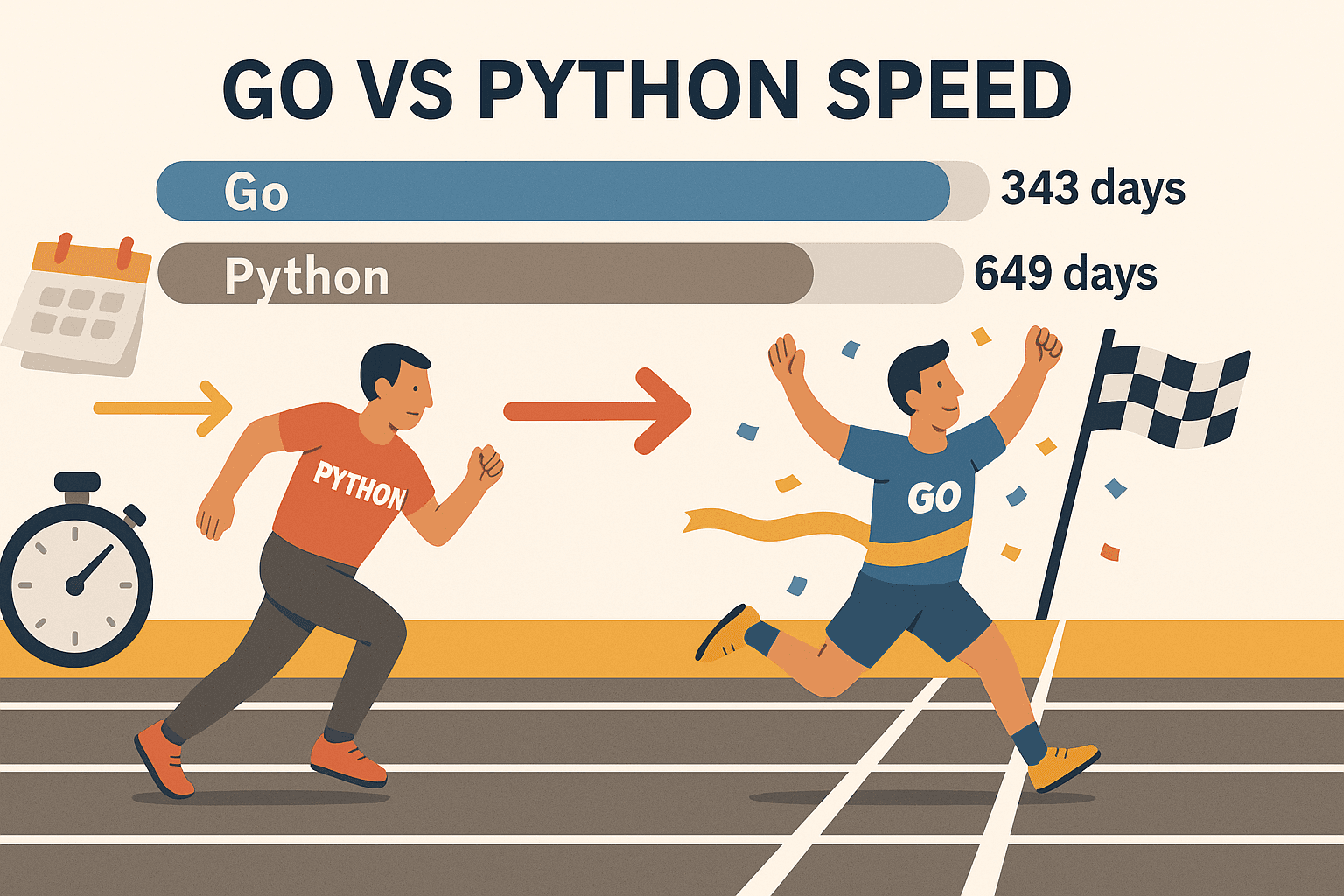
- Concorrência de verdade: As goroutines do Go (threads levinhas) permitem raspar centenas de páginas ao mesmo tempo — sem travar seu PC. Em um teste, Go raspou , enquanto Python levou 649 dias para o mesmo volume. Não é só mais rápido — é outro nível.
- Estabilidade e confiança: O sistema de tipos forte e a gestão eficiente de memória fazem do Go uma escolha certeira para crawlers que precisam rodar por dias ou semanas sem cair. Chega de acordar e descobrir que o script travou de madrugada.
- Rede de primeira: A biblioteca padrão do Go já vem com tudo para requisições HTTP, parsing de HTML e manipulação de JSON — sem precisar sair caçando pacote de terceiros só para começar.
- Implantação sem dor: Go compila para um binário só, então você pode rodar seu raspador em qualquer lugar — sem virtualenv, sem dor de cabeça com dependências.
- Adesão no mercado: Go já é a (passando Node.js) e é usada por gigantes como Google, Uber e Netflix.
Claro, Python ainda é ótimo para scripts rápidos ou quando você precisa de bibliotecas de machine learning. Mas se o que você quer é velocidade, escala e robustez, Go é imbatível — principalmente com bibliotecas como Colly e Goquery.
Passo 1: Preparando o Ambiente Go para Raspagem Web
Antes de sair raspando por aí, é preciso instalar e configurar o Go. A boa notícia? É rapidinho.
1. Instale o Go
- Acesse a e baixe o instalador para seu sistema (Windows, macOS ou Linux).
- Execute o instalador e siga as instruções. No Linux, também dá para usar o gerenciador de pacotes.
- Abra o terminal e digite:
Se aparecer algo como1go versiongo version go1.21.0 darwin/amd64, está tudo certo.
Deu ruim? Se o comando go não for reconhecido, confira se o PATH está certinho. No Linux/macOS, talvez precise adicionar export PATH=$PATH:/usr/local/go/bin no seu ~/.bash_profile ou ~/.zshrc.
2. Crie seu projeto Go
- Crie uma pasta para seu raspador:
1mkdir meu-raspador && cd meu-raspador - Inicialize um módulo Go:
Isso cria o arquivo1go mod init github.com/seunome/meu-raspadorgo.modpara gerenciar as dependências.
3. Escolha seu editor
- com a extensão Go é uma ótima pedida (autocompletar, lint e debug).
- JetBrains GoLand é queridinho de quem vive de Go.
- Vim/Neovim com plugins Go também funciona para quem curte o clássico.
4. Teste se está tudo ok
Crie um main.go simples:
1package main
2import "fmt"
3func main() {
4 fmt.Println("Go está instalado e funcionando!")
5}Execute:
1go run main.goSe aparecer sua mensagem, pode seguir em frente.
Passo 2: Fazendo sua Primeira Requisição HTTP em Go
Hora de buscar sua primeira página! O pacote net/http do Go facilita a vida.
Exemplo básico de GET HTTP:
1package main
2import (
3 "fmt"
4 "io"
5 "net/http"
6)
7func main() {
8 resp, err := http.Get("https://example.com")
9 if err != nil {
10 fmt.Println("Erro ao buscar a URL:", err)
11 return
12 }
13 defer resp.Body.Close()
14 body, err := io.ReadAll(resp.Body)
15 if err != nil {
16 fmt.Println("Erro ao ler o corpo da resposta:", err)
17 return
18 }
19 fmt.Println(string(body))
20}Fique ligado:
- Sempre cheque erros depois do
http.Get. - Use
defer resp.Body.Close()para não vazar recurso. - Use
io.ReadAllpara ler toda a resposta.
Dicas de ouro:
- Para definir headers personalizados (tipo User-Agent de navegador), use
http.NewRequest:1req, _ := http.NewRequest("GET", "https://example.com", nil) 2req.Header.Set("User-Agent", "Mozilla/5.0") 3client := &http.Client{} 4resp, err := client.Do(req) - Sempre confira
resp.StatusCode— 200 é sucesso, mas 403 ou 404 indicam bloqueio ou página inexistente.
Passo 3: Fazendo Parsing de HTML e Extraindo Dados com Go
Buscar o HTML é só o começo. Agora é hora de extrair o que interessa — nomes de produtos, preços, links e por aí vai.
Conheça o Goquery: Uma biblioteca Go que traz seletores no estilo jQuery para parsing de HTML.
Instale o Goquery:
1go get github.com/PuerkitoBio/goqueryExemplo: Extraindo nomes e preços de produtos
1package main
2import (
3 "fmt"
4 "net/http"
5 "github.com/PuerkitoBio/goquery"
6)
7func main() {
8 resp, err := http.Get("https://example.com/products")
9 if err != nil {
10 panic(err)
11 }
12 defer resp.Body.Close()
13 doc, err := goquery.NewDocumentFromReader(resp.Body)
14 if err != nil {
15 panic(err)
16 }
17 doc.Find("div.product").Each(func(i int, s *goquery.Selection) {
18 name := s.Find("h2").Text()
19 price := s.Find(".price").Text()
20 fmt.Printf("Produto %d: %s - %s\n", i+1, name, price)
21 })
22}Como funciona:
doc.Find("div.product")pega todos os containers de produto.- Dentro de cada um,
s.Find("h2").Text()pega o nome es.Find(".price").Text()pega o preço.
Expressões regulares: Para padrões simples (tipo e-mails), o pacote regexp do Go resolve fácil. Para HTML mais complexo, vá de Goquery.
Passo 4: Turbine seu Raspador com Bibliotecas Go (Colly & Gocolly)
Quer ir além? é o framework de raspagem web mais famoso para Go. Ele cuida de crawling, concorrência, cookies e muito mais — assim você foca nos dados, não na infraestrutura.
Por que Colly é top:
- API simples: Registre callbacks para os elementos que quer raspar.
- Concorrência: Raspe centenas de páginas em paralelo com
colly.Async(true). - Crawling automático: Siga links e pagine fácil.
- Recursos anti-bot: Defina headers, alterne user agents e gerencie cookies.
- Tratamento de erros: Hooks prontos para requisições que falham.
Instale o Colly:
1go get github.com/gocolly/colly/v2Exemplo básico de raspador com Colly:
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly/v2"
5)
6func main() {
7 c := colly.NewCollector(
8 colly.AllowedDomains("example.com"),
9 colly.Async(true),
10 )
11 c.OnHTML(".product-list-item", func(e *colly.HTMLElement) {
12 name := e.ChildText("h2")
13 price := e.ChildText(".price")
14 fmt.Printf("Produto: %s - %s\n", name, price)
15 })
16 c.OnRequest(func(r *colly.Request) {
17 r.Headers.Set("User-Agent", "Mozilla/5.0")
18 })
19 c.OnError(func(r *colly.Response, err error) {
20 fmt.Println("Falha na requisição:", r.Request.URL, "->", err)
21 })
22 c.Visit("https://example.com/products")
23 c.Wait()
24}Comparativo de recursos: Goquery vs. Colly
| Recurso | Goquery | Colly |
|---|---|---|
| Parsing de HTML | Sim | Sim (usa Goquery internamente) |
| Requisições HTTP | Manual | Integrado |
| Concorrência | Manual (goroutines) | Fácil (Async(true)) |
| Crawling/Seguir links | Manual | Automático |
| Recursos anti-bot | Manual | Integrado |
| Tratamento de erros | Manual | Integrado |
Colly economiza muito tempo em raspagens mais complexas.
Passo 5: Lidando com Desafios Reais na Raspagem Web com Go
Raspar dados na prática nem sempre é moleza. Veja como driblar os principais obstáculos:
1. Bloqueio de IP
- Troque proxies usando
http.Transportdo Go ou o suporte a proxy do Colly. - Diminua o ritmo das requisições com delays aleatórios.
2. User-Agent e Headers
- Sempre defina um User-Agent realista (tipo Chrome ou Firefox).
- Imite headers de navegador (Accept-Language, etc.).
3. CAPTCHAs
- Se aparecer CAPTCHA, provavelmente você está raspando rápido demais ou de forma muito óbvia.
- Use navegadores headless (como ) para sites que exigem JavaScript ou interação visual.
- Para sites com proteção pesada, vale integrar um serviço de resolução de CAPTCHA.
4. Paginação
- Com Colly, siga links de “Próxima página” automaticamente:
1c.OnHTML("a.next", func(e *colly.HTMLElement) { 2 e.Request.Visit(e.Attr("href")) 3})
5. Conteúdo Dinâmico (JavaScript)
- As libs HTTP do Go não executam JS. Use um navegador headless (Rod, chromedp) ou tente raspar APIs internas se encontrar.
6. Quando o bicho pega... Use Thunderbit
Às vezes, o site é dinâmico demais ou você precisa dos dados para ontem, sem programar. É aí que entra o . O Thunderbit é uma extensão Chrome de raspagem web com IA que:
- Usa IA para identificar e extrair campos — só clicar em “IA Sugerir Colunas”.
- Navega por subpáginas e paginação automaticamente.
- Roda em navegador real (ou na nuvem), lidando com sites cheios de JavaScript e bloqueios anti-bot.
- Exporta direto para Excel, Google Sheets, Airtable ou Notion — sem código.
- Permite agendar raspagens e automatizar a coleta de dados para sua equipe.
Thunderbit é a solução perfeita para times de vendas, negócios ou qualquer um que precise de dados organizados sem programar. E sim, sou suspeito — minha equipe criou o Thunderbit justamente para resolver esses perrengues.
Combinando Go e Thunderbit para Produtividade Máxima
Aqui vai o segredo: você não precisa escolher entre Go e Thunderbit. Os melhores times usam os dois.
Exemplo de fluxo de trabalho:
- Use Go (com Colly) para rastrear uma lista gigante de URLs ou coletar dados básicos em escala.
- Passe as URLs para o Thunderbit para extrair informações detalhadas e estruturadas — ótimo para subpáginas, conteúdo dinâmico ou sites com bloqueios.
- Exporte os dados do Thunderbit para Google Sheets ou CSV.
- Use Go de novo para processar, juntar ou analisar os dados como quiser.
Essa abordagem híbrida te dá a velocidade e controle do Go, junto com a flexibilidade e inteligência artificial do Thunderbit. É como ter um canivete suíço e uma furadeira elétrica na mesma caixa de ferramentas.
Comparando Soluções de Raspagem Web em Go: Go Puro vs. Colly vs. Thunderbit
Confira um comparativo rápido para te ajudar a escolher a melhor ferramenta:
| Aspecto | Go puro (net/http + html) | Go + Colly (Biblioteca) | Thunderbit (IA sem código) |
|---|---|---|---|
| Setup & Aprendizado | Difícil (exige código) | Médio (API mais fácil) | Muito fácil (sem código, IA) |
| Concorrência | Manual (goroutines) | Integrada (Async(true)) | Paralelismo em nuvem/navegador |
| Conteúdo Dinâmico (JS) | Precisa de navegador headless | Algum suporte a JS, ou Rod | Navegador completo, lida com JS |
| Anti-bot | Manual (proxies, headers) | Recursos integrados | Quase automático, IPs em nuvem |
| Estruturação de dados | Código personalizado | Callbacks, structs próprios | IA sugere e formata automaticamente |
| Exportação | Personalizado (CSV, BD, etc.) | Personalizado | Excel, Sheets, Notion, Airtable |
| Manutenção | Alta (atualizar código) | Média | Baixa (IA se adapta a mudanças) |
| Melhor para | Devs, pipelines customizados | Devs, prototipagem rápida | Não programadores, equipes de negócio |
Dica: Use Go/Colly para projetos customizados, em larga escala ou integrados ao backend. Use Thunderbit quando quiser agilidade, facilidade ou lidar com sites chatos no front-end.
Principais Lições: Como Começar com Raspagem Web em Go
- Go é uma máquina para raspagem web — principalmente quando velocidade, concorrência e robustez são prioridade.
- Comece pelo básico: Configure o ambiente Go, faça requisições HTTP e faça parsing de HTML com Goquery.
- Dê um up com Colly: Para crawling, concorrência e recursos anti-bot, Colly é seu parceiro.
- Supere os desafios: Troque proxies, defina headers e use navegadores headless ou Thunderbit para sites mais complicados.
- Misture ferramentas: Não tenha medo de usar Go e Thunderbit juntos para tirar o melhor dos dois mundos.
A raspagem web multiplica resultados para vendas, operações e pesquisa. Com Go, as bibliotecas certas e um toque de IA, você automatiza tarefas chatas e foca no que realmente importa para o negócio.
Recursos Extras para Raspagem Web com Go
Quer se aprofundar? Dá uma olhada nesses materiais que eu curto:
Boas raspagens — que seus dados estejam sempre organizados, seus raspadores voando e seu café sempre forte.
Perguntas Frequentes
1. Por que usar Go para raspagem web em vez de Python ou JavaScript?
Go entrega concorrência, velocidade e confiabilidade de outro nível — especialmente para projetos de raspagem em larga escala ou que precisam rodar por muito tempo. É perfeito para raspar milhares de páginas rapidinho e gerar um binário portátil.
2. Qual a forma mais fácil de fazer parsing de HTML em Go?
Use a biblioteca . Ela traz seletores no estilo jQuery para navegar e extrair dados do DOM sem dor de cabeça.
3. Como lidar com sites que usam conteúdo renderizado em JavaScript no Go?
Você vai precisar de uma biblioteca de navegador headless como ou . Ou, se preferir, use o para uma solução sem código, baseada em navegador, que já lida com JS automaticamente.
4. Como evitar bloqueios ao raspar dados?
Troque o User-Agent, use proxies, adicione delays entre as requisições e imite o comportamento de um navegador real. O Colly facilita essas práticas e o Thunderbit já resolve a maioria dos bloqueios sozinho.
5. Posso combinar Go e Thunderbit no meu fluxo de trabalho?
Com certeza! Use Go para crawling em larga escala ou integração com backend, e Thunderbit para extração com IA, raspagem de subpáginas e exportação para ferramentas de negócio. É uma dupla poderosa para devs e equipes de negócio.
Pronto para levar sua raspagem web para outro nível? Teste a ou confira o para mais dicas, tutoriais e conteúdos sobre automação e IA.