
Resumo executivo
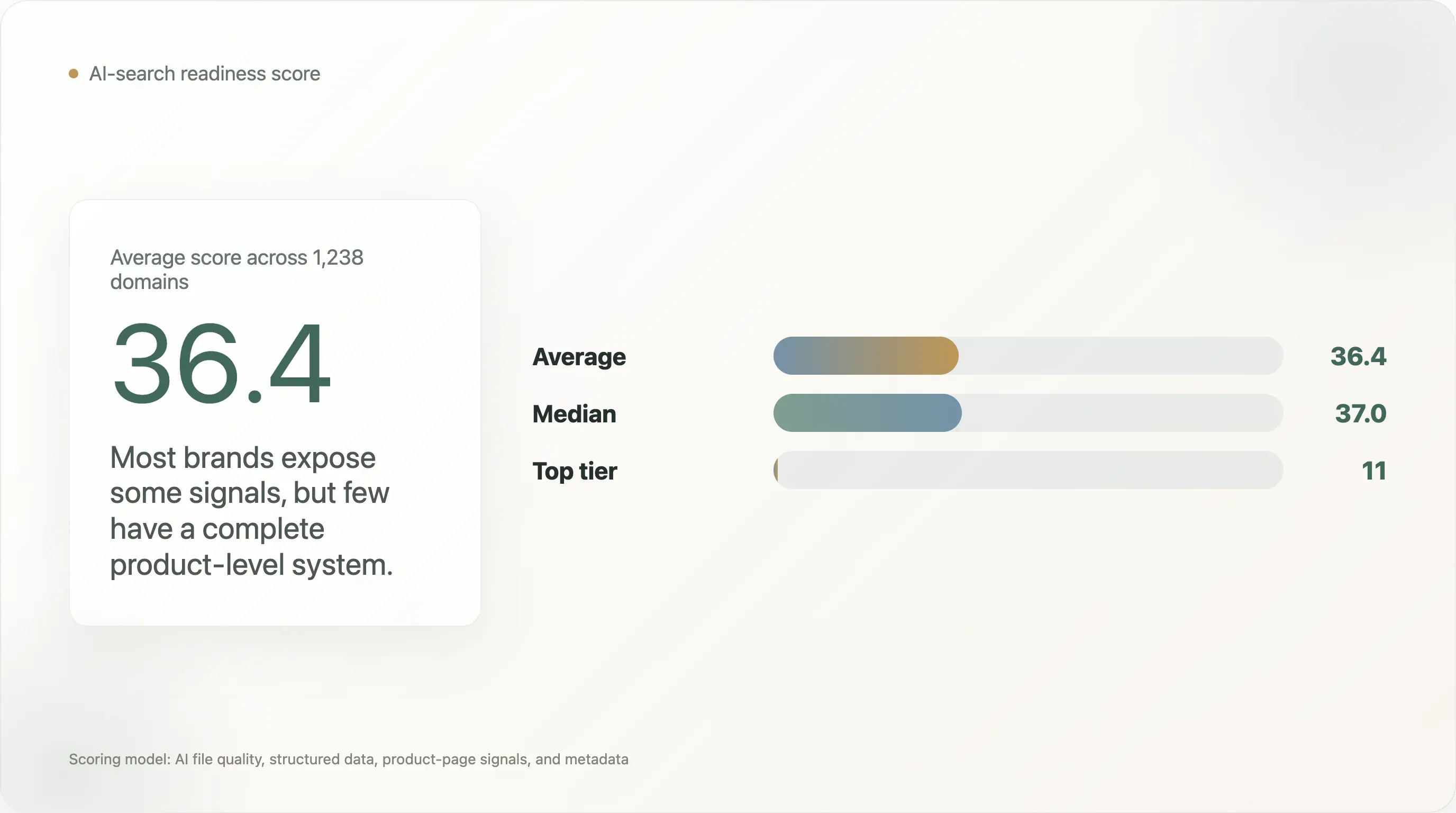
Esta pesquisa classifica 1.238 domínios DTC quanto à prontidão para busca por IA usando quatro camadas: qualidade do arquivo de IA, dados estruturados gerais, sinais estruturados de páginas de produto e metadados. A pontuação média é 36,4 de 100, e a mediana é 37,0. Apenas 11 domínios alcançaram o nível ai_ready neste modelo de pontuação.
A principal descoberta é a lacuna entre a descobribilidade superficial e a compreensão em nível de produto. O maior grupo de qualidade de llms.txt é platform_default, com 629 domínios. Isso significa que muitas marcas têm um arquivo básico legível por IA porque a própria plataforma o gerou. Mas o schema de Product na homepage aparece em apenas 0,9% dos domínios pontuados, e o schema de Product em páginas de produto aparece em 39,2% dos domínios pontuados em que páginas de produto foram testadas. Sinais de preço em páginas de produto aparecem em 48,1%, e sinais de avaliação ou classificação em 43,5%.
A distribuição por nível mostra o quão cedo o mercado ainda está:
| Nível de prontidão para IA | Domínios |
|---|---|
| Não pronto | 435 |
| Parcialmente pronto | 425 |
| Descoberta básica | 367 |
| Pronto para IA | 11 |
Essa divisão é útil porque separa três ideias que muitas vezes se misturam. Uma marca pode ser descobrível. Uma marca pode ter metadados. Uma marca pode ter llms.txt. Mas ser descobrível não é o mesmo que ser compreendida em nível de produto.
A distribuição de qualidade do llms.txt deixa isso ainda mais claro:
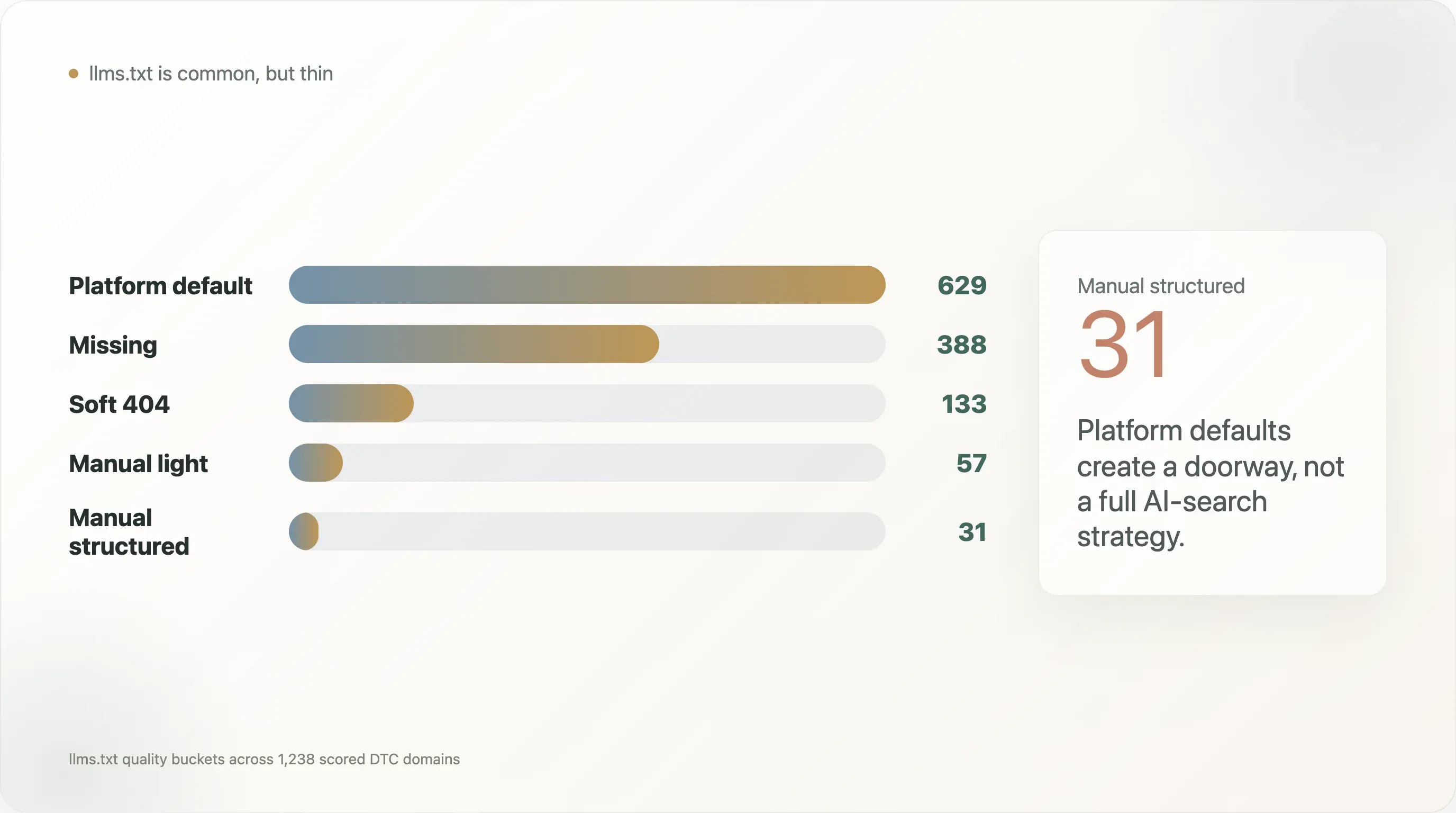
| Grupo de qualidade de llms.txt | Domínios |
|---|---|
| Padrão da plataforma | 629 |
| Ausente | 388 |
| Soft 404 | 133 |
| Manual leve | 57 |
| Manual estruturado | 31 |
Portanto, o melhor ângulo para este relatório não é "marcas DTC têm llms.txt". Esse título é superficial demais. O melhor recorte é: os padrões das plataformas criaram uma primeira camada fina de descobribilidade para IA, mas a maioria das marcas DTC ainda não construiu a camada de dados estruturados em nível de produto necessária para compras por IA e mecanismos de resposta.
Exemplos positivos mostram como uma melhor prontidão pode parecer. O nível ai_ready inclui marcas como Mokobara, Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods, La Maison Convertible, Unbloat, NuRange Coffee, Three Ships Beauty e Manukora. Esses exemplos importam porque mostram que a prontidão para IA não está restrita a uma categoria ou a um tipo de marca. Alimentos, beleza, bem-estar, móveis, vestuário e varejo especializado podem todos melhorar sua camada de produto legível por máquina.
As conclusões mais compartilháveis
-
A pontuação média de prontidão para IA no DTC é de apenas 36,4/100.
-
Apenas 11 dos 1.238 domínios pontuados alcançaram o nível
ai_ready. -
llms.txt é comum, mas em sua maioria gerado pela plataforma. O maior grupo de qualidade é o padrão da plataforma, com 629 domínios.
-
O llms.txt manual estruturado é raro. Apenas 31 domínios caem no grupo manual estruturado.
-
O schema de Product na homepage é quase inexistente. Ele aparece em apenas 0,9% dos domínios pontuados.
-
O schema de Product em páginas de produto é melhor, mas ainda incompleto. Ele aparece em 39,2% dos domínios pontuados em que páginas de produto foram testadas.
-
A prontidão para compras por IA exige fatos de produto, não apenas acesso do crawler. Preço, oferta, avaliações, disponibilidade e sinais de schema de product importam mais do que um arquivo raso sozinho.
1. Por que a prontidão para busca por IA é diferente do básico de SEO
O SEO tradicional pergunta se uma página pode ser rastreada, indexada, ranqueada e clicada. A busca por IA adiciona outra camada: o sistema consegue entender a marca, o produto, a oferta, o preço, as avaliações, a disponibilidade, as políticas e as relações entre entidades o suficiente para responder perguntas ou recomendar produtos?
Essa diferença importa para o DTC porque páginas de ecommerce estão cheias de detalhes que são fáceis para uma pessoa, mas confusos para uma máquina. Um comprador consegue olhar uma página de produto e entender o nome do produto, o preço, o tamanho, a opção de assinatura, o desconto, as avaliações, o status de estoque e a política de devolução. Um crawler ou agente de IA precisa que esses fatos sejam expressos de forma consistente.
Metadados ajudam. Open Graph ajuda. Tags canônicas ajudam. llms.txt pode ajudar crawlers a encontrar conteúdo importante. Mas a estrutura em nível de produto é o verdadeiro teste. Se um assistente de compras com IA estiver comparando cinco proteínas em pó, produtos de skincare, velas, vestidos ou assinaturas de café, ele precisa de fatos estruturados. Sem esses fatos, a marca pode ser visível, mas não compreendida de forma confiável.
Este relatório separa quatro camadas de prontidão:
- Camada de arquivo de IA: se llms.txt existe e se está ausente, é um soft 404, padrão da plataforma, manual leve ou manual estruturado.
- Camada geral de dados estruturados: JSON-LD, Organization, WebSite, BreadcrumbList e schema de Product.
- Camada da página de produto: schema de Product, sinais de oferta ou preço, sinais de avaliação ou review e sinais de disponibilidade.
- Camada de metadados: canonical, meta description, imagem do Open Graph, cartão do Twitter, hreflang e contexto semelhante legível por máquina.
O modelo em camadas importa porque evita uma conclusão superficial. Uma marca com llms.txt, mas sem fatos de produto, não está tão pronta quanto parece. Uma marca sem llms.txt, mas com schema rico em páginas de produto, pode ser mais compreensível do que a camada de arquivo sugere.
2. A história do llms.txt: uma camada fina, criada em sua maioria pelas plataformas
A auditoria de llms.txt produziu cinco grupos de qualidade:
| Grupo de qualidade | Domínios | Interpretação |
|---|---|---|
| Padrão da plataforma | 629 | Um arquivo padrão gerado pela plataforma, normalmente simples, mas válido |
| Ausente | 388 | Nenhum arquivo utilizável encontrado |
| Soft 404 | 133 | Uma resposta enganosa ou pouco útil |
| Manual leve | 57 | Arquivo criado por humanos ou personalizado, mas com estrutura limitada |
| Manual estruturado | 31 | Arquivo manual mais substancial, com títulos, links, termos de produto ou política |
Esta é a nuance mais importante do relatório. À primeira vista, a adoção de llms.txt parece forte porque arquivos padrão da plataforma são comuns. Mas padrão da plataforma não é o mesmo que uma estratégia de busca por IA bem pensada. Muitas vezes, trata-se apenas de uma camada básica de encaminhamento.
Isso não torna os arquivos padrão da plataforma inúteis. Eles podem ajudar crawlers a encontrar caminhos importantes. Também mostram a rapidez com que decisões em nível de plataforma podem mover o mercado. Uma plataforma pode dar a centenas de lojas um novo arquivo legível por máquina antes mesmo de a maioria das equipes de marca ter discutido operações de busca por IA.
Mas o grupo manual estruturado é muito menor: 31 domínios. Exemplos na auditoria incluem arquivos manuais estruturados de marcas como Dermalogica, Ad Hoc Atelier, DKNY e vários exemplos ai_ready como Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods e Three Ships Beauty. Esses são exemplos positivos úteis porque mostram o que significa ir além de um arquivo padrão: mais links, mais títulos, mais termos de produto, mais termos de política e uma estrutura mais intencional.
O grupo soft-404 também é importante. Um soft 404 significa que a solicitação retorna algo, mas não um arquivo llms.txt útil. Isso pode enganar auditorias simples. Para prontidão em busca por IA, não basta verificar existência. É preciso verificar qualidade.
3. A estrutura em nível de produto é a verdadeira lacuna
A lacuna mais forte nos dados está no schema de Product.
O schema de Product na homepage aparece em apenas 0,9% dos domínios pontuados. O schema de Product em páginas de produto aparece em 39,2% dos domínios pontuados em que páginas de produto foram testadas. Sinais de preço em páginas de produto aparecem em 48,1%, e sinais de avaliação ou classificação aparecem em 43,5%.
Esses números contam uma história clara. Fatos básicos de produto não são consistentemente legíveis por máquina, mesmo quando a marca tem uma loja de ecommerce.
Isso importa porque a busca por IA e as compras por IA provavelmente vão recompensar clareza. Se uma página de produto expõe schema de Product, ofertas, preço, disponibilidade, sinais de review e links de política, ela fornece fatos mais confiáveis às máquinas. Se esses fatos estiverem escondidos em JavaScript, templates inconsistentes, imagens ou widgets dinâmicos, as máquinas podem interpretar errado ou ignorar.
A lacuna de prontidão não é apenas sobre ranqueamento. É sobre representação. Quando sistemas de IA resumem uma categoria de produto, comparam opções, respondem perguntas de "melhor para" ou geram recomendações de compra, marcas com fatos de produto mais limpos podem ser incluídas com mais precisão.
Os exemplos positivos do grupo ai_ready deixam isso claro:
- Mokobara alcançou a maior pontuação da saída, com 83.
- Magic Mind, Le Petit Ballon e Maine Lobster Now pontuaram 81.
- Yo Mama's Foods pontuou 80.
- La Maison Convertible, Unbloat, Vinocheepo e NuRange Coffee pontuaram 79.
- Three Ships Beauty pontuou 77.
- Manukora pontuou 75.
Esses exemplos atravessam categorias. A prontidão para IA não é apenas um problema de beleza ou de tecnologia. Ela importa para alimentos, bem-estar, móveis, vestuário, produtos especializados e qualquer categoria em que um comprador possa pedir recomendações, comparações ou explicações a um sistema de IA.
4. Níveis de prontidão para IA: a maioria das marcas ainda está abaixo da linha
A distribuição por nível é:
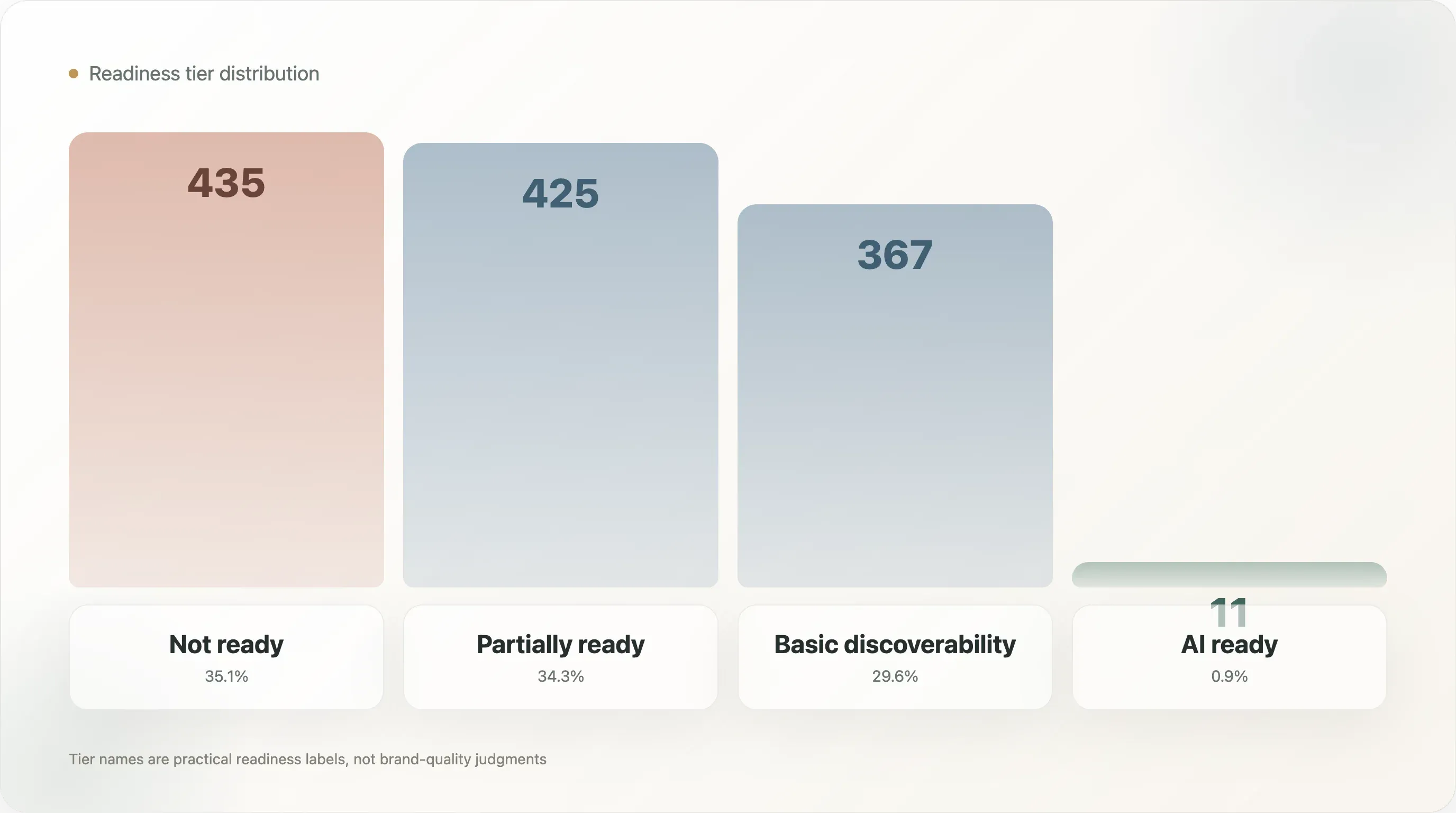
| Nível | Domínios | Participação na amostra |
|---|---|---|
| Não pronto | 435 | 35,1% |
| Parcialmente pronto | 425 | 34,3% |
| Descoberta básica | 367 | 29,6% |
| Pronto para IA | 11 | 0,9% |
Os nomes são intencionalmente práticos. Not ready não significa que a marca seja ruim. Significa que os sinais públicos usados por este modelo não mostram prontidão suficiente para busca por IA. Partially ready significa que algumas peças existem, mas camadas importantes estão faltando. Basic discoverability significa que a marca é mais visível para máquinas, mas ainda pode carecer de completude em nível de produto. AI ready significa que o domínio mostra uma combinação mais forte de qualidade do arquivo, dados estruturados, fatos de produto e metadados.
Apenas 11 domínios alcançaram a camada mais alta. Esse é o título principal, mas a visão mais útil está no formato do meio. A amostra está quase igualmente dividida entre não pronto, parcialmente pronto e descoberta básica. O mercado não está vazio. Ele está em transição. Muitas marcas têm alguns sinais, mas poucas têm um sistema completo.
Isso cria uma oportunidade de curto prazo. A prontidão para busca por IA ainda está no início o suficiente para que uma marca saia da média para um nível forte com trabalho relativamente prático: melhorar llms.txt, validar schema, expor fatos de produto, limpar metadados e tornar as páginas de produto mais fáceis de a máquina analisar.
5. Padrões por categoria: beleza e vestuário estão à frente, mas nenhuma categoria está concluída
A classificação por categoria é direcional, não exata. Ainda assim, a tabela de categorias mostra padrões úteis:
| Categoria | Amostra | Prontidão média para IA | llms estruturado ou manual | Schema em página de produto | Taxa de schema em página de produto |
|---|---|---|---|---|---|
| Beleza e skincare | 98 | 46,2 | 3 | 56 | 57,1% |
| Vestuário e calçados | 149 | 45,7 | 6 | 79 | 53,0% |
| Joias e acessórios | 34 | 44,5 | 0 | 20 | 58,8% |
| Pets | 15 | 43,5 | 0 | 8 | 53,3% |
| Bebês e crianças | 27 | 42,6 | 1 | 15 | 55,6% |
| Alimentos e bebidas | 118 | 42,5 | 5 | 58 | 49,2% |
| Casa e móveis | 48 | 42,3 | 0 | 23 | 47,9% |
| Saúde e bem-estar | 58 | 40,7 | 6 | 27 | 46,6% |
| Outdoor e esportes | 49 | 39,8 | 1 | 23 | 46,9% |
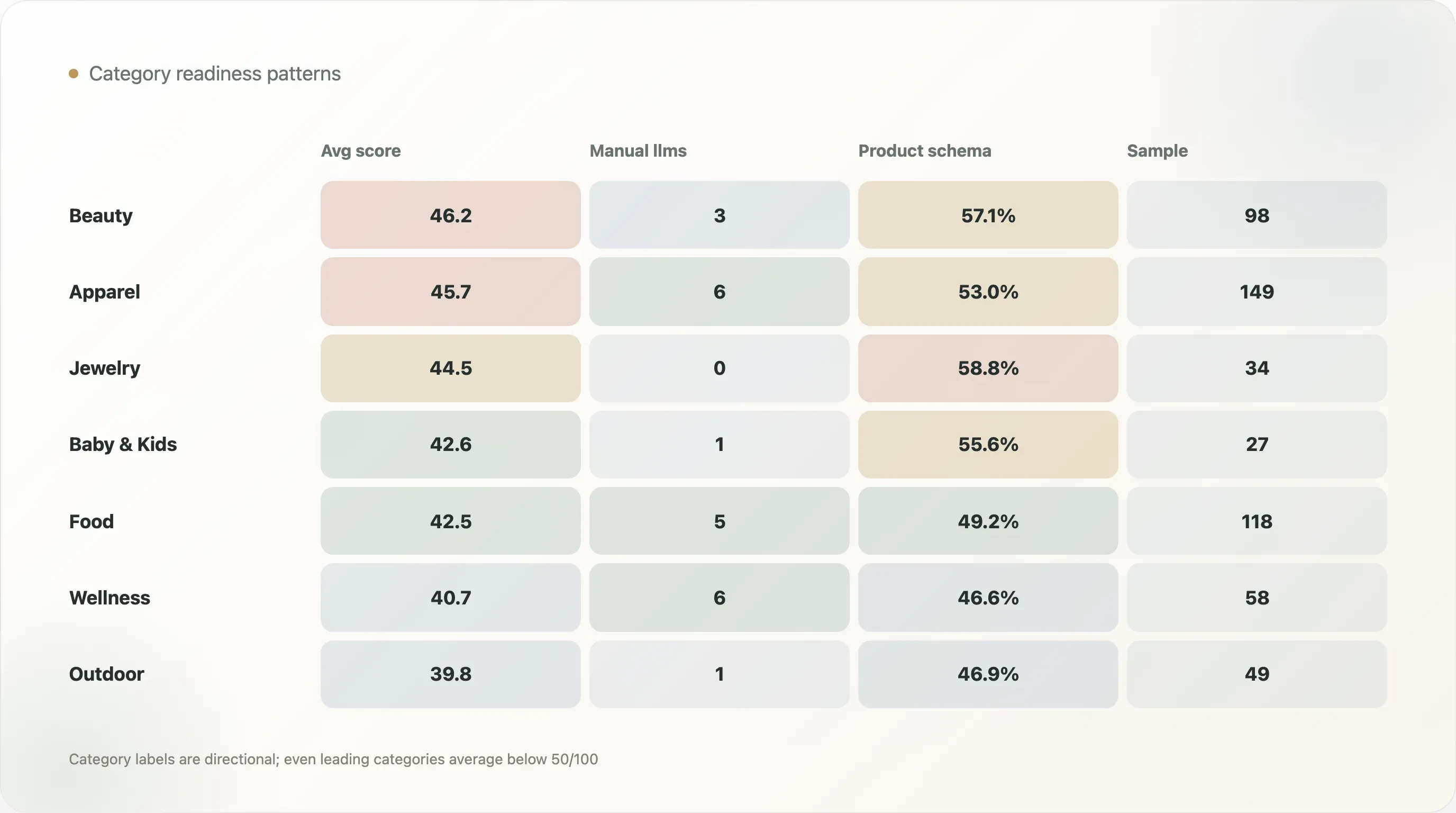
Beleza e skincare têm a maior pontuação média de prontidão para IA, com 46,2. Vestuário e calçados vêm em seguida, com 45,7. Essas categorias geralmente têm templates fortes de ecommerce, catálogos ricos de produtos, avaliações, variações, ativos visuais e necessidades de conteúdo. Elas podem se beneficiar mais rapidamente de um trabalho estruturado de produto.
Joias e acessórios têm uma taxa alta de schema em página de produto, com 58,8%, mas nenhuma detecção de llms.txt manual ou estruturado na tabela de categorias. Isso mostra por que a prontidão precisa ser em camadas. Uma categoria pode ser forte em schema de produto e fraca na qualidade do arquivo de IA.
Alimentos e bebidas incluem vários exemplos positivos fortes, como Maine Lobster Now, Yo Mama's Foods, NuRange Coffee e Manukora. Isso é importante porque produtos de alimentos e bebidas muitas vezes precisam de fatos claros: ingredientes, nutrição, porção, assinatura, origem, envio, armazenamento, avaliações e disponibilidade. Sistemas de IA só conseguem representar esses detalhes com precisão se o site os expuser de forma limpa.
Saúde e bem-estar tem uma taxa de llms manual ou estruturado de 10,3%, a mais alta entre as principais categorias da tabela, mas uma pontuação média de 40,7. Isso sugere que algumas marcas da categoria estão experimentando ativamente arquivos legíveis por IA, enquanto a estrutura de páginas de produto ainda tem espaço para melhorar. Dado o peso de confiança e educação nessa categoria, ela deveria ser uma das mais agressivas em fatos estruturados.
Nenhuma categoria está concluída. Até as categorias líderes têm média abaixo de 50/100. Isso torna o conteúdo de prontidão para IA específico por categoria uma boa oportunidade para redatores e consultores de SEO.
6. Como é um bom exemplo: padrões positivos de marcas prontas para IA
O grupo ai_ready é pequeno, mas útil porque mostra padrões que vale a pena copiar.
Mokobara obteve 83, a maior pontuação da saída. Ele aparece como exemplo de forte prontidão combinada, não apenas de vitória por um único sinal.
Magic Mind, Le Petit Ballon e Maine Lobster Now pontuaram 81 cada e entram no grupo manual estruturado de llms. Isso importa porque mostra trabalho deliberado na camada de arquivo, não apenas padrões da plataforma.
Yo Mama's Foods pontuou 80, também com llms manual estruturado. Marcas de alimentos podem se beneficiar de estrutura legível por IA porque os sistemas podem ser questionados sobre ingredientes, sabor, casos de uso, receitas, adequação a dietas e comparações.
Three Ships Beauty pontuou 77 com llms manual estruturado. Beleza é uma categoria ideal para prontidão estruturada para IA porque os compradores perguntam sobre tipo de pele, ingredientes, rotinas, textura, avaliações e alternativas.
Manukora pontuou 75. Mel e produtos de alimentos mais ligados ao bem-estar geralmente exigem educação sobre origem, qualidade, benefícios, certificações e uso, o que torna valiosos os sinais estruturados de produto e política.
A lição não é que toda marca precisa parecer idêntica. A lição é que a prontidão para IA é um sistema:
- Um arquivo llms.txt útil
- Metadados limpos
- Dados estruturados de organização e website
- Schema em página de produto
- Sinais de preço e oferta
- Sinais de avaliação ou review
- Sinais de disponibilidade
- Clareza de políticas e suporte
Qualquer camada ajuda. A combinação é o que cria prontidão.
7. Por que llms.txt sozinho não basta
llms.txt virou um atalho conveniente para prontidão para IA. Isso é compreensível porque é visível, fácil de checar e novo o suficiente para parecer estratégico. Mas esta pesquisa mostra por que ele não deve ser tratado como a história completa.
Um llms.txt padrão da plataforma pode criar uma porta de entrada básica. Ele pode apontar crawlers para páginas importantes. Pode dizer às máquinas que o site tem um ponto de entrada legível por IA. Mas, se as páginas de produto não expõem fatos de forma clara, a porta de entrada leva a uma sala bagunçada.
O problema da busca por IA não é apenas "o crawler consegue encontrar o site?" É:
- O crawler consegue identificar o produto?
- Consegue identificar a marca?
- Consegue interpretar o preço?
- Consegue interpretar a disponibilidade?
- Consegue identificar avaliações ou classificações?
- Consegue distinguir conteúdo do produto de conteúdo de marketing?
- Consegue entender as políticas?
- Consegue comparar variações?
- Consegue citar a página canônica correta?
llms.txt ajuda na navegação e na priorização. Dados estruturados de produto ajudam na compreensão. A prontidão para IA exige ambos.
8. O playbook do operador: como melhorar a prontidão para busca por IA
Para equipes de DTC e ecommerce, o fluxo de trabalho prático é simples.
Passo 1: verificar a camada do arquivo de IA. O domínio tem llms.txt? Ele é real ou é um soft 404? É padrão da plataforma, manual leve ou estruturado? Ele aponta para páginas úteis?
Passo 2: auditar metadados. Confirme tags canônicas, meta descriptions, imagens do Open Graph, cartões do Twitter, hreflang quando relevante e viewport mobile. Nada disso é glamouroso, mas ajuda as máquinas a construir contexto.
Passo 3: validar JSON-LD. Verifique Organization, WebSite, BreadcrumbList e schema de Product. O schema de Product é a lacuna mais importante no ecommerce.
Passo 4: auditar páginas de produto, não só a homepage. As compras por IA vão se importar com páginas de produto. Confirme nome do produto, descrição, imagem, preço, oferta, disponibilidade, SKU, reviews, classificações, variações e política de devolução.
Passo 5: tornar os fatos do produto estáveis. Evite esconder fatos críticos apenas em imagens, abas que não renderizam bem ou widgets em JavaScript que os crawlers podem não interpretar.
Passo 6: melhorar a clareza das políticas. Envio, devoluções, termos de assinatura, garantias, certificações e alegações de segurança devem ser fáceis de encontrar e de interpretar.
Passo 7: testar novamente após mudanças de template. O schema costuma quebrar durante redesigns, mudanças de tema, mudanças de app e migrações headless. Trate os dados estruturados como parte do QA.
Passo 8: assumir a propriedade do sistema. A prontidão para IA não deve ficar apenas com SEO. Ela envolve ecommerce, produto, conteúdo, engenharia, jurídico e atendimento ao cliente.
9. O que equipes de SEO e conteúdo podem citar
Esta pesquisa gera vários ângulos fortes de citação:
"Apenas 11 dos 1.238 domínios DTC pontuados alcançaram o nível pronto para IA." Este é o gancho de prontidão mais amplo.
"llms.txt é comum, mas em sua maioria gerado pela plataforma." O grupo padrão da plataforma contém 629 domínios, enquanto arquivos manuais estruturados aparecem em apenas 31.
"O schema de Product na homepage aparece em apenas 0,9% dos domínios pontuados." Esta é a lacuna de dados estruturados mais aguda.
"O schema de Product em páginas de produto aparece em 39,2% quando páginas de produto foram testadas." Isso adiciona nuance: páginas de produto são melhores que homepages, mas ainda incompletas.
"Beleza e vestuário lideram a tabela de categorias, mas ainda ficam abaixo de 50/100 em média." Isso cria um ângulo específico por categoria.
"A prontidão para IA é em camadas." Este é o ponto educativo mais importante para leitores que poderiam, de outra forma, equiparar llms.txt com prontidão.
A ressalva é essencial: os dados refletem sinais públicos de sites nesta amostra, não a adoção total do setor nem o desempenho interno de busca.
10. O que as compras por IA mudam para equipes de DTC
A descoberta tradicional em ecommerce foi construída em torno de páginas, rankings, anúncios e cliques. O comprador pesquisava, comparava resultados, abria páginas, lia avaliações e tomava decisões. As compras por IA e os mecanismos de resposta comprimem essa jornada. Um comprador pode perguntar por "o melhor molho com pouco açúcar para massa durante a semana", "uma mochila de bordo abaixo de US$ 200 com boas avaliações" ou "um limpador suave para pele sensível sem fragrância". O sistema de IA pode resumir opções antes mesmo de o comprador ver a página de uma marca.
Isso muda o trabalho da página de produto. A página ainda precisa convencer pessoas, mas também precisa descrever o produto com clareza suficiente para que máquinas o comparem. Tom de marca não basta. Imagens bonitas não bastam. Um nome de produto inteligente não basta. A máquina precisa de fatos: o que é, para quem é, quanto custa, se está disponível, quais variações existem, o que as avaliações dizem, quais alegações são sustentadas, quais ingredientes ou materiais importam e quais políticas se aplicam.
É por isso que a estrutura em nível de produto importa mais do que um arquivo genérico de IA. llms.txt pode ajudar um crawler a entender onde olhar. O schema de Product e fatos limpos na página de produto ajudam-no a entender o que encontrou.
O risco para marcas DTC não é apenas ficar de fora. É ser representada de forma errada. Se uma página de produto for pouco clara, uma resposta de IA pode resumir o recurso errado, deixar de lado um diferencial importante, omitir uma política relevante ou comparar o produto de forma injusta com concorrentes melhor estruturados. Nesse sentido, a prontidão para IA também é uma questão de proteção de marca.
Para categorias com jornadas de decisão complexas, os riscos são maiores. Compradores de beleza perguntam sobre tipo de pele, ingredientes, rotinas, sensibilidade e resultados. Compradores de alimentos perguntam sobre nutrição, alérgenos, origem, sabor, receitas e adequação à dieta. Compradores de vestuário perguntam sobre caimento, tamanho, materiais, devoluções e estilo. Compradores de bem-estar perguntam sobre evidências, uso, segurança e confiança. Compradores de casa perguntam sobre dimensões, materiais, entrega, montagem e durabilidade. Todos esses problemas são, ao mesmo tempo, de conteúdo legível por máquina e de marketing.
A oportunidade é que a maioria das marcas ainda está no começo. A pontuação média de prontidão é de apenas 36,4/100, e apenas 11 domínios alcançaram o nível ai_ready. Uma marca não precisa esperar por uma reformulação completa do site. Ela pode começar pelos templates, pelo schema, pela clareza das políticas e pelos fatos de produto.
11. Um plano de prontidão para IA por departamento
A prontidão para IA não deve pertencer apenas ao SEO. Ela envolve várias equipes.
SEO é dono da descobribilidade e da validação de schema. As equipes de SEO devem auditar tags canônicas, metadados, dados estruturados, schema de Product, breadcrumbs, hreflang e rastreabilidade. Também devem monitorar se o schema de produto sobrevive a mudanças de tema e atualizações de apps.
Ecommerce é dono dos fatos da página de produto. Nomes de produto, preços, variações, disponibilidade, bundles, assinaturas, avaliações, termos de envio e detalhes de devolução precisam estar claros e consistentes. Se esses fatos estiverem fragmentados em widgets, abas, imagens e scripts, as máquinas podem ter dificuldade.
Conteúdo é dono da profundidade explicativa. Sistemas de IA recompensam páginas que respondem perguntas com clareza. Guias de compra, tabelas de comparação, explicações de ingredientes, páginas de caso de uso, orientações de tamanho e seções de FAQ podem ajudar tanto pessoas quanto máquinas.
Engenharia é dona da qualidade da implementação. O schema deve ser válido, estável e dirigido por template. Os fatos de produto não devem depender totalmente de renderização frágil no lado do cliente. Os templates de páginas de produto devem ser testados após os releases.
Jurídico e compliance são donos das alegações. Se um produto faz alegações de saúde, sustentabilidade, segurança, ingredientes ou desempenho, essas alegações precisam ser precisas, sustentáveis e fáceis de interpretar. Sistemas de IA podem amplificar alegações pouco claras.
Atendimento ao cliente é dono das perguntas recorrentes. Os tickets de suporte revelam o que compradores e sistemas de IA podem perguntar: prazo de envio, caimento, ingredientes, compatibilidade, devoluções, cancelamento de assinatura, instruções de cuidado e comparações de produtos. Essas perguntas devem alimentar o conteúdo das páginas de produto.
A liderança é dona da priorização. A prontidão para IA compete com muitos outros projetos. O caso para a liderança é simples: fatos estruturados de produto apoiam SEO, busca por IA, feeds de produto, shopping pago, busca no site, suporte e conversão. Isso não é apenas um projeto de IA.
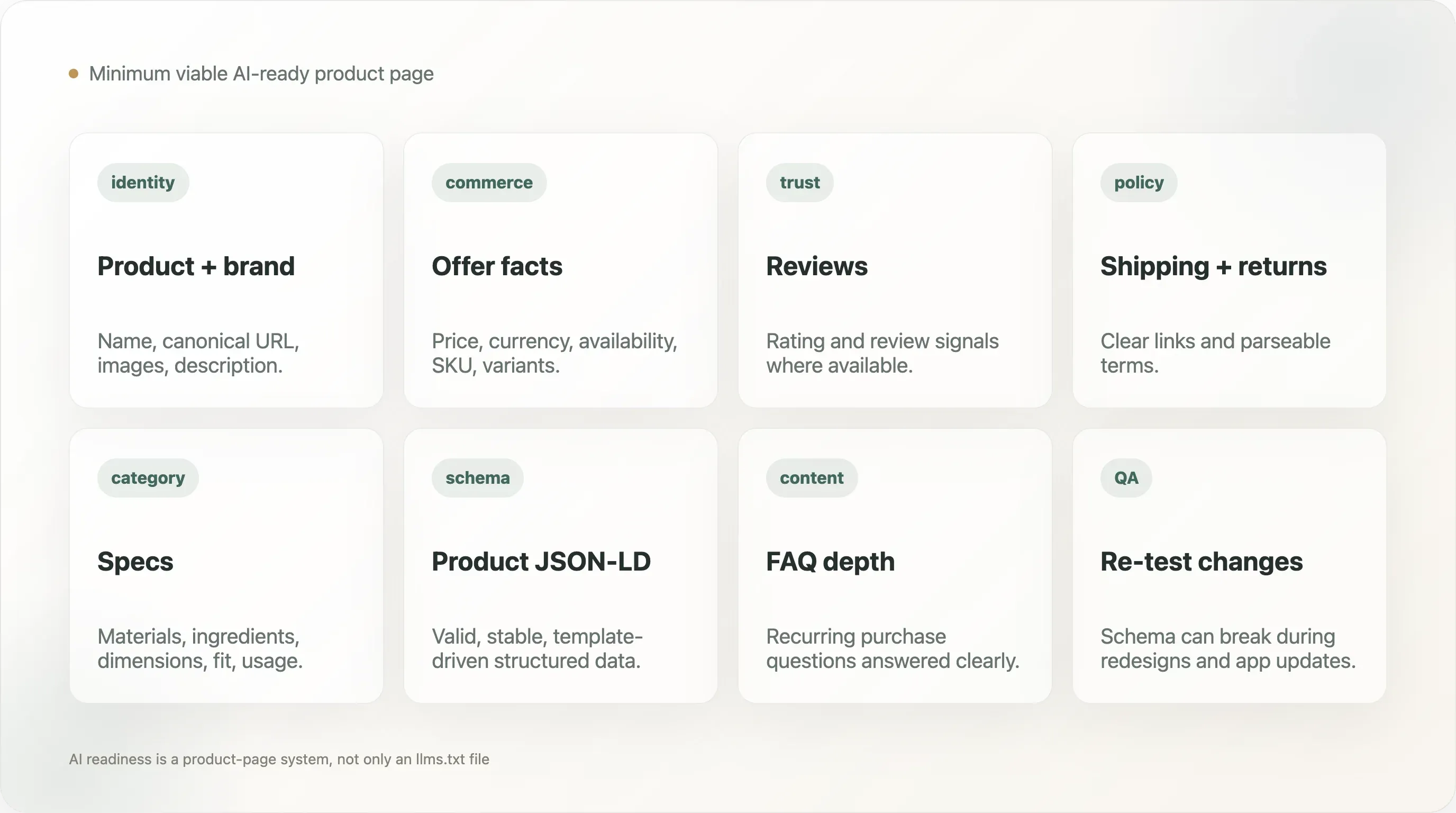
12. A página mínima viável pronta para IA
Uma página prática de produto DTC deve expor:
- Nome do produto
- Nome da marca
- URL canônica
- Descrição do produto
- Imagens do produto
- Preço
- Moeda
- Disponibilidade
- Informação sobre variações
- SKU ou identificador do produto quando relevante
- Sinais de review ou classificação quando disponíveis
- Detalhes da oferta
- Links para política de envio e devolução
- Fatos de material, ingrediente ou especificação quando relevantes para a categoria
- Conteúdo de FAQ ou suporte para dúvidas recorrentes de compra
A página também deve incluir schema de Product válido e evitar esconder fatos críticos apenas em imagens ou scripts que os crawlers podem não interpretar. Isso não exige páginas de produto sem personalidade. Exige separar design persuasivo de fatos estruturados confiáveis.
Para muitas marcas, o ganho mais rápido não é escrever um longo documento de estratégia de IA. É validar dez páginas importantes de produto, corrigir o schema e garantir que os fatos mais importantes do produto estejam visíveis no HTML e nos dados estruturados.
Metodologia
Esta pesquisa usa o conjunto de dados do relatório duplo de DTC coletado em 11 de maio de 2026. Ela pontua 1.238 domínios usando master.csv, detection.csv, seo_signals.csv, arquivos brutos llms.txt e HTML bruto de páginas de produto quando disponível.
O modelo de pontuação separa quatro camadas:
- Camada de arquivo de IA: existência e qualidade de llms.txt.
- Camada geral de dados estruturados: JSON-LD, Organization, WebSite, BreadcrumbList, Product e sinais estruturados relacionados.
- Camada da página de produto: schema de Product, sinais de oferta ou preço, sinais de avaliação ou review e sinais de disponibilidade.
- Camada de metadados: canonical, meta description, imagem do Open Graph, cartão do Twitter, hreflang e contexto relacionado da página.
O modelo gera uma pontuação de prontidão para IA de 0 a 100 e atribui os domínios a um de quatro níveis: não pronto, parcialmente pronto, descoberta básica e ai_ready.
Limitações
-
Prontidão para IA não é tráfego de IA. A pontuação não mede referências reais de sistemas de busca por IA ou agentes de compras.
-
Sinais públicos são um piso mínimo. Alguns dados estruturados podem carregar dinamicamente ou aparecer de formas que o rastreamento não capturou.
-
A qualidade de llms.txt é heurística. Arquivos manuais estruturados são identificados por características observáveis, como títulos, links, termos de produto e termos de política.
-
A detecção de páginas de produto depende de buscas tentadas em páginas de produto. As porcentagens de schema em páginas de produto se aplicam quando páginas de produto foram testadas e estavam disponíveis.
-
A amostra não é um censo completo de DTC. Ela tem viés para marcas visíveis em ecossistemas de ferramentas de ecommerce e listas públicas de DTC.
-
Os rótulos de categoria são direcionais. Eles são úteis para comparação ampla, mas não para taxonomia exata.
-
Os padrões de busca por IA ainda estão evoluindo. O modelo de pontuação foi criado como um benchmark prático de 2026, não como uma definição permanente.
Notas de reprodutibilidade
A pasta de entrega inclui:
analyze_ai_search_readiness.py— script de pontuação usado para avaliar domínios DTC emllms.txt, dados estruturados, sinais de páginas de produto e sinais de metadados.ai_search_readiness_scores.csv— pontuações de prontidão para IA em nível de domínio, níveis e sinais de componentes.llms_quality_audit.csv— auditoria da qualidade dellms.txtem nível de domínio, incluindo as classificações padrão da plataforma, soft-404, ausente, manual leve e manual estruturado.category_ai_readiness.csv— comparação de prontidão para IA em nível de categoria.top_ai_ready_brands.csv— domínios com maior pontuação para revisão editorial e seleção de exemplos.lowest_ai_ready_brands.csv— domínios com menor pontuação para análise de lacunas e revisão editorial.summary.json— métricas agregadas de destaque citadas neste relatório, incluindo tamanho da amostra, contagem por nível, pontuação média, mediana e taxas de sinais em páginas de produto.
Correções de metodologia, problemas no conjunto de dados e análises de acompanhamento são bem-vindos em support@thunderbit.com. Este relatório é publicado de forma independente de qualquer posição comercial que a Thunderbit detenha; construímos um raspador web com IA e temos interesse estrutural em que sites públicos de ecommerce se tornem mais fáceis de serem compreendidos com precisão por pessoas, mecanismos de busca e agentes de IA. O benchmark é baseado em 1.238 domínios DTC pontuados a partir de sinais públicos de sites coletados em 11 de maio de 2026. Os dados neste relatório falam por si. — Equipe de pesquisa da Thunderbit, maio de 2026.