O cenário dos negócios em 2026 virou um verdadeiro festival de dados — e todo mundo quer garantir o seu lugar à mesa. Seja no comercial, operações, marketing ou produto, a pressão para coletar, analisar e agir com base em dados nunca foi tão intensa. Vejo isso todo dia: equipes atoladas em copiar e colar manualmente, planilhas espalhadas por todo lado e links de pesquisas pipocando nos grupos. E a situação só piora: 80% dos dados do mundo já são não estruturados e esse número só cresce (). Se você ainda não usa um software de coleta de dados de verdade, não está só ficando para trás — está perdendo oportunidades de tomar decisões mais inteligentes, agilizar processos e, claro, evitar muita dor de cabeça.

Com anos de estrada em SaaS e automação, já vi de perto como a ferramenta certa transforma o caos dos dados em vantagem competitiva. Mas com tanta opção — de web 스크래퍼 com IA a plataformas de pesquisa e formulários interativos — como escolher o melhor para o seu time? Bora facilitar. Aqui estão os 6 melhores softwares de coleta de dados para 2026, cada um com seu diferencial, pontos fortes e casos de uso ideais. Seja para extrair leads da web, rodar pesquisas detalhadas ou só captar feedback rapidinho, essa lista vai te ajudar a achar a solução perfeita.
Por Que Escolher Bem o Software de Coleta de Dados Faz Toda Diferença
Vamos falar a real: coletar dados é o coração dos negócios modernos. O software certo não é só um extra — é o que separa horas perdidas em tarefas manuais de insights prontos para ação. Segundo a , 76% dos líderes empresariais sentem mais pressão para embasar decisões com dados, e empresas que acertam nisso têm 23 vezes mais chances de conquistar clientes e 19 vezes mais lucratividade ().
Mas tem um porém: mais de 60% dos profissionais de dados dizem que coletar dados é a parte mais cansativa do trabalho (). A ferramenta certa automatiza o que é repetitivo, diminui erros e libera o time para o que realmente importa: interpretar e agir sobre os dados.
Principais usos nos negócios:
- Geração de leads: Extração de contatos da web, criação de listas de prospecção.
- Pesquisa de mercado: Aplicação de pesquisas, análise de opinião do cliente.
- Feedback do cliente: Coleta de NPS, CSAT ou avaliações de produtos.
- Análise da concorrência: Monitoramento de preços, estoque ou tendências.
- Automação de fluxos: Envio de dados para CRMs, dashboards ou ferramentas analíticas.
Resumindo: escolher o software de coleta de dados é alinhar sua necessidade — dados estruturados ou não, pesquisa ou web 스크래퍼, análises simples ou avançadas — à ferramenta que faz isso melhor.
Como Selecionamos os Melhores Softwares de Coleta de Dados
Nada de sorteio. Avaliei:
- Facilidade de uso: Qualquer um consegue começar rápido? Tem IA ou arrasta-e-solta?
- Funcionalidades: Suporta o tipo de dado que você precisa (web, pesquisa, upload de arquivos etc.)? Tem lógica, agendamento ou automação?
- Análises: Oferece relatórios, dashboards ou opções de exportação?
- Integrações: Dá para enviar dados para Sheets, CRMs ou outros apps?
- Preço: Tem versão gratuita? Escala para equipes ou empresas?
- Diferenciais: O que faz se destacar — IA, análises profundas, experiência do usuário?
Também pesquisei avaliações de usuários, opiniões de especialistas e casos reais. Cada ferramenta brilha em um ponto, então você pode escolher a que mais faz sentido para o seu cenário.
Os 6 Melhores Softwares de Coleta de Dados
- para web 스크래퍼 com IA e automação
- para pesquisas e análises de nível corporativo
- para formulários online flexíveis e acessíveis
- para coleta de dados rápida, gratuita e simples
- para pesquisas robustas com ótimos relatórios e integrações
- para formulários e pesquisas interativos e envolventes
1. Thunderbit
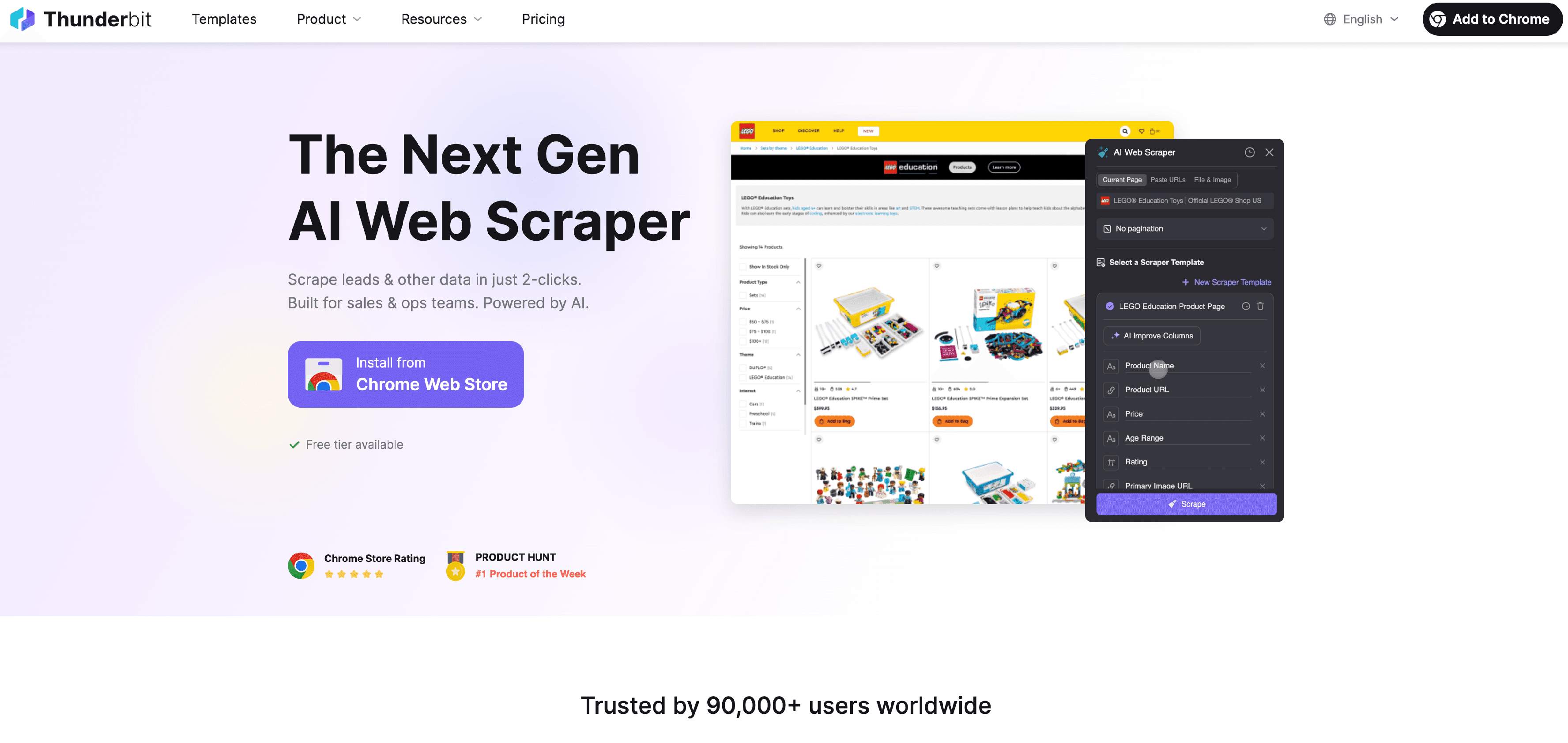
é minha escolha número um para coleta de dados web — e não é só porque participei do desenvolvimento. É a única ferramenta da lista que une web 스크래퍼 com IA a uma interface sem código, feita para negócios. Se você já perdeu horas copiando dados de sites, o Thunderbit vai virar seu novo melhor amigo.
Por Que o Thunderbit se Destaca
O Thunderbit nasceu para domar o caos dos dados não estruturados da web. Equipes de vendas usam para extrair leads de diretórios, profissionais de ecommerce monitoram SKUs de concorrentes, e times de marketing coletam informações de produtos ou contatos — tudo sem precisar programar. É só abrir a , clicar em “Sugerir Campos com IA” e deixar a IA identificar o que está na página. Você pode ajustar as colunas, clicar em “Raspar” e pronto — dados organizados, prontos para exportar para Excel, Google Sheets, Airtable ou Notion.
O Thunderbit vai além de raspar uma página só. Ele lida com paginação (passando por várias páginas de listagem) e raspagem de subpáginas (entrando em cada produto ou perfil para pegar mais detalhes). Tem até modelos prontos para sites populares como Amazon e Zillow, para você extrair dados em um clique.
E o diferencial: a IA do Thunderbit pode rotular, categorizar e transformar dados automaticamente. Precisa extrair e-mails, telefones ou imagens? Já está incluso. Quer agendar raspagens ou automatizar preenchimento de formulários? O Thunderbit faz.
Principais Recursos do Thunderbit para Empresas
- Sugestão de Campos com IA: Descreva o que precisa e a IA monta o web 스크래퍼 para você.
- Raspagem de Subpáginas e Paginação: Extraia listas e aprofunde nos detalhes automaticamente.
- Exportação Gratuita de Dados: Envie para Excel, Google Sheets, Airtable, Notion ou baixe como CSV/JSON — sem custo extra.
- Extratores com Um Clique: Pegue e-mails, telefones ou imagens de qualquer página instantaneamente.
- Raspagem Agendada: Automatize coletas recorrentes (ex: checagem diária de preços).
- Raspagem em Nuvem ou Navegador: Execute tarefas na nuvem para mais velocidade ou no navegador para sites que exigem login.
- Preço Acessível: Versão gratuita (6 páginas), depois R$ 15/mês para 500 créditos (linhas). Exportação sempre gratuita.
O que dizem os usuários? Um profissional de vendas contou que o Thunderbit permitiu “criar um banco de contatos de influenciadores em minutos, sem precisar comprar listas” (). Outro disse que transformou horas de pesquisa manual em “dois cliques”.
Se você quer transformar a web no seu próprio banco de dados — sem programação ou dor de cabeça com TI — o Thunderbit é imbatível.
2. Qualtrics
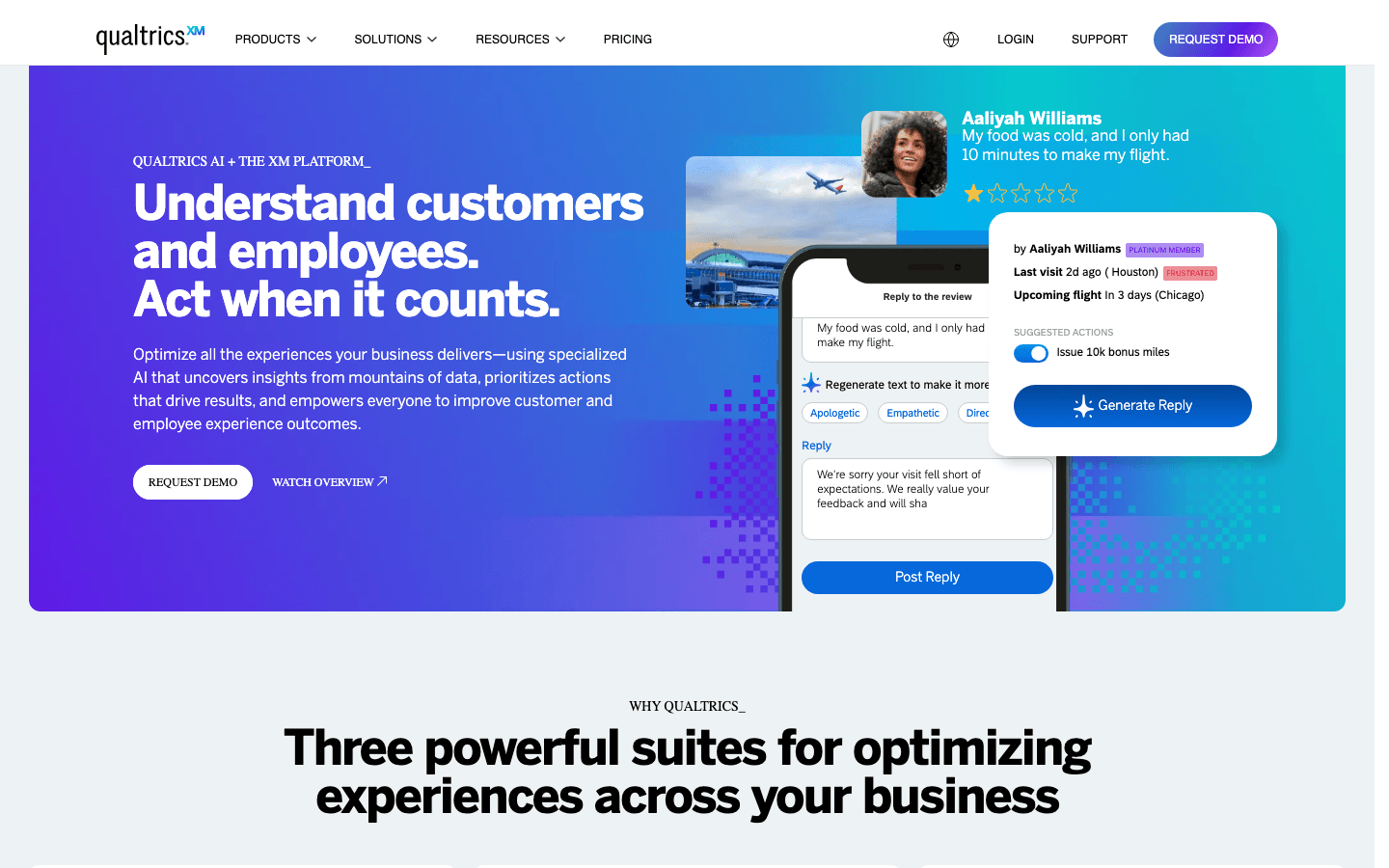
é referência mundial em plataformas de pesquisa e análise para grandes empresas. Se sua organização precisa de pesquisas avançadas, relatórios detalhados e análises dignas de cientista de dados, o Qualtrics é a escolha — desde que o orçamento permita.
Qualtrics para Análises Profundas de Pesquisas
O Qualtrics se destaca por lógica de pesquisa avançada, distribuição multicanal e análises robustas. Você pode criar pesquisas com ramificações, randomização e validação. Distribua por e-mail, web, celular ou SMS. Quando os dados chegam, o Qualtrics oferece dashboards em tempo real, segmentação, análises estatísticas e até análise de texto com IA.
É ideal para:
- Programas de engajamento de funcionários
- Satisfação do cliente (NPS, CSAT)
- Pesquisas de mercado
- Pesquisas acadêmicas
O Qualtrics integra com Salesforce, Tableau e outras ferramentas corporativas. Segurança e conformidade? Pode confiar. Mas atenção: a curva de aprendizado é alta e o preço começa em torno de US$ 420/mês para pequenas empresas, podendo chegar a dezenas de milhares por ano em planos corporativos ().
Se você precisa analisar e visualizar dados em grande escala — e tem recursos para isso — o Qualtrics é o padrão ouro.
3. Zoho Forms
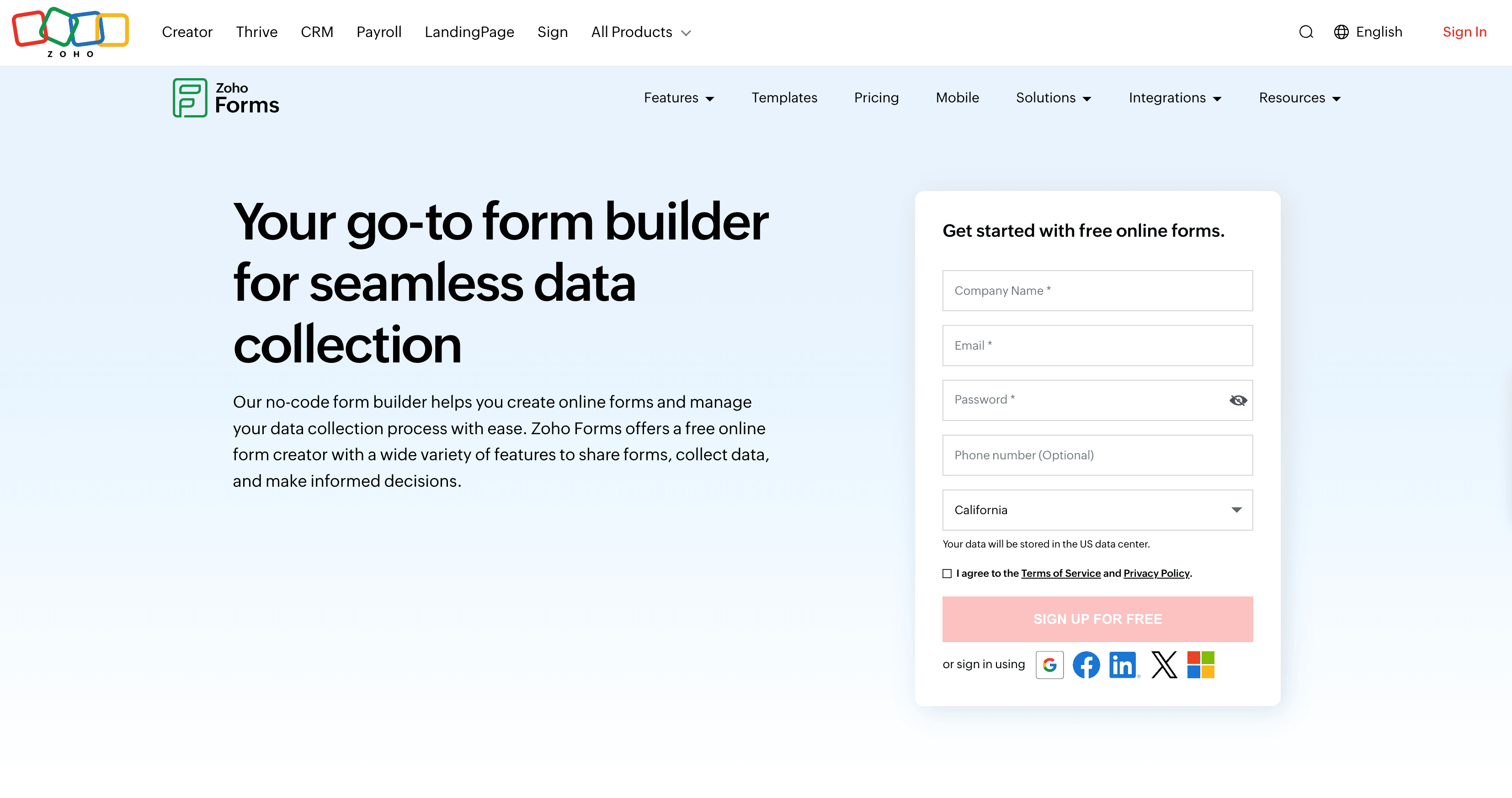
é o canivete suíço para pequenas equipes e empresas que querem economizar. É um construtor de formulários online com arrasta-e-solta, cheio de recursos e sem pesar no bolso.
Zoho Forms na Prática
O Zoho Forms é perfeito para:
- Captura de leads (integra direto com Zoho CRM)
- Inscrição em eventos
- Feedback de clientes
- Solicitações e aprovações internas
São mais de 30 tipos de campos (incluindo upload de arquivos e assinaturas), lógica condicional, temas personalizáveis e suporte móvel/offline. Se você já usa apps Zoho, a integração é total. Se não, ainda conecta com Google Sheets, Slack e outros via Zapier.
Preço? Tem versão gratuita (1 usuário, 5 formulários), depois planos pagos a partir de US$ 12/mês para 1 usuário e 10.000 envios. Planos mais altos liberam mais usuários e recursos, mas até o de US$ 25/mês já atende a maioria das pequenas equipes ().
O único ponto fraco? As análises são básicas, e o ideal é já estar no ecossistema Zoho. Mas para PMEs que querem mais que o Google Forms sem a complexidade do Qualtrics, o Zoho Forms é uma ótima escolha.
4. Google Forms
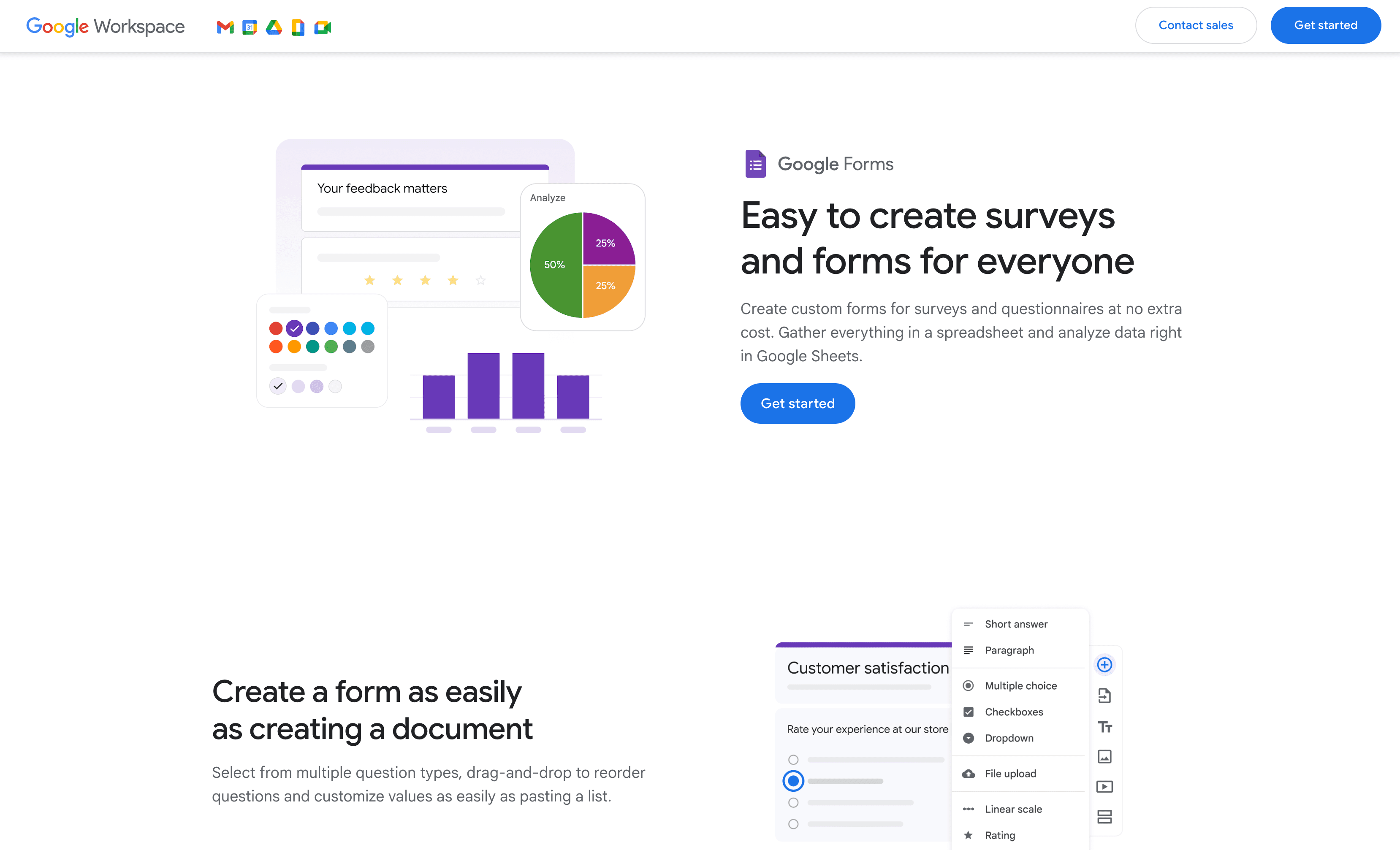
é o campeão da coleta de dados rápida e gratuita. Precisa de uma pesquisa, RSVP ou formulário de feedback em cinco minutos — e sem gastar nada? O Google Forms resolve.
Google Forms para Coleta de Dados Rápida e Simples
O que faz do Google Forms um clássico:
- Formulários e respostas ilimitados, grátis ()
- Colaboração em tempo real (várias pessoas editam juntas)
- Exportação automática para Google Sheets para análise instantânea
- Lógica básica de pular perguntas e alguns tipos de questões
É perfeito para enquetes internas, inscrições em eventos, quizzes educacionais e feedback simples. A interface é super intuitiva e integra com o Google Workspace.
Pontos negativos? Personalização limitada, análises básicas e integrações fora do Google exigem Zapier ou complementos. Mas para custo zero e implantação instantânea, é difícil superar.
5. SurveyMonkey
é sinônimo de pesquisas online — e com razão. Equilibra poder e facilidade de uso, ideal para equipes que querem recursos robustos sem a complexidade de ferramentas corporativas.
Relatórios e Integrações do SurveyMonkey
O SurveyMonkey se destaca por:
- Mais de 15 tipos de perguntas (NPS, ranking, matriz etc.)
- Lógica de pular, ramificações e piping
- Análises em tempo real e relatórios customizados
- Mais de 200 integrações (Salesforce, HubSpot, Slack, Tableau e mais)
Você pode enviar pesquisas por e-mail, acompanhar respondentes e até automatizar follow-ups. O painel de relatórios é intuitivo, permitindo filtrar, segmentar e compartilhar resultados facilmente. O SurveyMonkey também suporta colaboração em equipe e segurança de nível empresarial.
O preço começa com plano gratuito (10 perguntas, 25 respostas por pesquisa), depois US$ 25–39/mês para planos pagos com limites maiores (). Para a maioria das empresas, o SurveyMonkey é o “ponto de equilíbrio” ideal.
6. Typeform
é a escolha de quem valoriza experiência do usuário — se você quer que seus formulários pareçam conversas, não interrogatórios, o Typeform é para você.
Typeform para Pesquisas Agradáveis ao Usuário
O diferencial do Typeform é a interface de uma pergunta por vez, que lembra um chat e gera 30–40% mais respostas completas (). Dá para adicionar imagens, GIFs, vídeos e personalizar a marca. Lógicas inteligentes personalizam o fluxo, e integrações com Google Sheets, HubSpot, Slack e outros facilitam a automação.
É ideal para:
- Quizzes de geração de leads
- Feedback de clientes
- Pesquisas de marketing
- Inscrições em eventos
O plano gratuito é bem limitado (10 respostas/mês), mas os pagos começam em US$ 25/mês para 100 respostas. Se você quer que a coleta de dados também fortaleça sua marca, o Typeform vale o investimento.
Tabela Comparativa dos Softwares de Coleta de Dados
Veja um comparativo rápido para ajudar na escolha:
| Ferramenta | Melhor Para | Principais Recursos | Preço Inicial | Facilidade de Uso | Análises/Relatórios | Integrações | Diferenciais |
|---|---|---|---|---|---|---|---|
| Thunderbit | Web 스크래퍼, vendas, operações, ecommerce | Web 스크래퍼 com IA, subpáginas/paginação, exportação instantânea | Grátis (6 páginas), R$ 15/mês | Muito fácil, sem código | Não possui, só exportação | Sheets, Excel, Notion, API | IA, lida com dados web não estruturados |
| Qualtrics | Pesquisas corporativas, análises profundas | Lógica avançada, dashboards, segmentação, multicanal | US$ 420/mês+ | Curva de aprendizado alta | Avançada, tempo real | Salesforce, Tableau, API | Potência analítica, nível corporativo |
| Zoho Forms | PMEs, equipes econômicas, usuários Zoho | Construtor arrasta-e-solta, lógica, aprovações, mobile/offline | Grátis, US$ 12/mês+ | Fácil, algum aprendizado | Básica, exporta para Zoho | Zoho Suite, Sheets, Zapier | Preço acessível, automação de fluxos |
| Google Forms | Formulários rápidos, gratuitos e simples | Formulários ilimitados, exporta para Sheets, lógica básica | Grátis | Extremamente fácil | Básica, exporta para Sheets | Google Workspace, add-ons | Grátis e ilimitado, implantação instantânea |
| SurveyMonkey | Pesquisas empresariais, relatórios | Modelos, lógica, análises em tempo real, 200+ integrações | Grátis, US$ 25–39/mês+ | Intuitivo, robusto | Forte, relatórios customizados | Salesforce, Slack, Tableau | Equilíbrio entre poder e usabilidade, marca forte |
| Typeform | Formulários e pesquisas interativos | UX conversacional, lógica inteligente, mídia rica, branding | Grátis (10 resp), US$ 25/mês | Moderno, polido | Taxas de conclusão/abandono | Sheets, HubSpot, Slack, API | Melhor UX, aumenta taxas de resposta |
Como Escolher o Software de Coleta de Dados Ideal para Você
Aqui vai um guia rápido:
-
Precisa raspar dados da web (leads, produtos, concorrentes)?
Use o . É o único web 스크래퍼 com IA da lista, ideal para dados não estruturados e automação de pesquisas repetitivas. -
Vai rodar pesquisas complexas e precisa de análises profundas?
é a melhor opção — se o orçamento permitir e você precisar de insights corporativos. -
Tem orçamento apertado ou já usa Zoho?
oferece formulários poderosos, lógica e automação de fluxos por um preço baixo. -
Precisa de um formulário rápido e gratuito para coleta básica?
é imbatível em agilidade e simplicidade. -
Quer pesquisas robustas com ótimos relatórios e integrações?
equilibra poder e facilidade, com modelos e análises para a maioria dos negócios. -
Busca máxima experiência do usuário e engajamento?
entrega formulários lindos e interativos, aumentando taxas de resposta e percepção da marca.
Dica de ouro: Aproveite os testes gratuitos, experimente com seu caso real e peça feedback da equipe. Às vezes, o “melhor” é o que todo mundo realmente usa.
Conclusão: Encontre o Software de Coleta de Dados Perfeito
Dados são o combustível do crescimento em 2026 — mas só se você coletar e agir de forma eficiente. Seja para raspar leads da web, rodar pesquisas corporativas ou só captar feedback rápido, tem uma ferramenta nesta lista para sua necessidade e bolso.
Thunderbit democratiza a coleta de dados web com IA, Qualtrics lidera em análises, Zoho Forms é o herói das PMEs, Google Forms é o clássico gratuito, SurveyMonkey é o coringa e Typeform é o rei do engajamento.
Avalie suas necessidades, teste algumas opções e lembre-se: o software certo não só coleta dados — ele revela insights, economiza tempo e dá vantagem real ao seu time.
Perguntas Frequentes
1. Qual a principal diferença entre Thunderbit e ferramentas tradicionais de pesquisa?
O Thunderbit foi criado para extrair e estruturar dados não estruturados da web (como listas de produtos, contatos ou pesquisas de concorrentes) usando IA, enquanto ferramentas tradicionais como Qualtrics ou SurveyMonkey são voltadas para coletar respostas via formulários e pesquisas.
2. O Google Forms é realmente gratuito para respostas ilimitadas?
Sim! O Google Forms permite criar formulários e coletar respostas ilimitadas sem custo, ideal para coletas básicas e pesquisas rápidas.
3. Quando escolher Qualtrics em vez de SurveyMonkey?
Prefira o Qualtrics se precisar de análises avançadas, lógica complexa e integrações corporativas — especialmente para grandes programas de experiência do cliente ou funcionários. O SurveyMonkey é melhor para a maioria das PMEs ou equipes que querem recursos robustos sem a complexidade ou preço corporativo.
4. Posso usar mais de uma ferramenta de coleta de dados ao mesmo tempo?
Com certeza. Muitas equipes usam Thunderbit para extração web, Typeform para geração de leads e Google Forms para pesquisas internas — tudo junto. Só garanta um plano para consolidar e analisar os dados depois.
5. Como saber qual software de coleta de dados é o ideal para minha equipe?
Comece identificando seu principal uso (web 스크래퍼, pesquisas, formulários), recursos necessários (análises, integrações, branding) e orçamento. Teste algumas ferramentas com dados reais, peça feedback da equipe e escolha a que melhor se encaixa no seu fluxo e objetivos.
Quer ver o Thunderbit em ação? e experimente raspar seu primeiro site gratuitamente. Para mais dicas e conteúdos sobre automação de dados, acesse o . Boas coletas!
Saiba Mais