A web em 2025 é um lugar selvagem — metade do tráfego que você vê nem é humano. Isso mesmo: bots e crawlers já respondem por mais de 50% de toda a atividade na internet (), e só uma fração deles são os “bons” bots que você quer: mecanismos de busca, pré-visualizadores de redes sociais e ferramentas de análise. O resto? Bem, vamos dizer apenas que nem sempre estão ali para ajudar. Como alguém que passou anos criando ferramentas de automação e IA na , vi de perto como o crawler certo — ou errado — pode impulsionar ou arruinar seu SEO, distorcer suas métricas, consumir sua banda ou até disparar um incidente de segurança em grande escala.
Se você administra um negócio, cuida de um site ou só quer manter sua operação digital em ordem, saber quem está batendo na porta do seu servidor é mais importante do que nunca. Por isso, reuni este guia de 2025 com os crawlers mais importantes — o que fazem, como identificá-los e como manter seu site aberto aos bons bots enquanto impede os mal-intencionados.
O que torna um crawler “conhecido”? User-Agent, IPs e verificação
Vamos começar pelo básico: o que exatamente é um crawler “conhecido”? Em termos simples, é um bot que se identifica com uma string de user-agent consistente (como Googlebot/2.1 ou bingbot/2.0) e, idealmente, rastreia a partir de faixas de IP públicas ou blocos ASN que você possa verificar (). Os grandes nomes — Google, Microsoft, Baidu, Yandex, DuckDuckGo — publicam documentação sobre seus bots e, em muitos casos, oferecem ferramentas ou arquivos JSON com seus IPs oficiais (, , ).
Mas aqui está o problema: confiar só no user-agent é arriscado. A falsificação é comum — bots maliciosos muitas vezes se passam por Googlebot ou Bingbot só para passar pelas suas defesas (). Por isso, o padrão-ouro é a verificação dupla: checar tanto o user-agent quanto o endereço IP (ou ASN), usando consultas DNS reversas ou listas publicadas. Se você usa uma ferramenta como a , pode automatizar esse processo — extraindo logs, combinando user-agents e cruzando IPs para montar uma lista confiável e em tempo real de quem está rastreando seu site.
Como usar esta lista de crawlers
Então, o que fazer na prática com uma lista de crawlers conhecidos? É assim que recomendo colocá-la para funcionar:
- Lista de permissão/allowlist: Garanta que os bots que você quer (mecanismos de busca, pré-visualizadores de redes sociais) nunca sejam bloqueados por engano pelo firewall, CDN ou WAF. Use os IPs e user-agents oficiais para uma allowlist precisa.
- Filtragem de analytics: Remova o tráfego de bots dos seus relatórios para que os números reflitam visitantes humanos de verdade — e não só o Googlebot e o AhrefsBot dando voltas no seu site ().
- Gestão de bots: Defina regras de crawl-delay ou limitação para ferramentas de SEO mais agressivas e bloqueie ou desafie bots desconhecidos ou maliciosos.
- Análise automatizada de logs: Use ferramentas de IA (como a Thunderbit) para extrair, classificar e rotular a atividade de crawlers nos seus logs, identificando tendências, impostores e mantendo suas políticas atualizadas.
Manter sua lista de crawlers atualizada não é uma tarefa de “configurar e esquecer”. Novos bots surgem, os antigos mudam de comportamento e os invasores ficam mais sofisticados a cada ano. Automatizar atualizações — raspando documentações oficiais ou repositórios do GitHub com a Thunderbit — pode economizar horas e muita dor de cabeça.
1. Thunderbit: identificação de crawlers e gestão de dados com IA
não é apenas um Raspador Web IA — é um assistente de dados para equipes que querem entender e gerir o tráfego de crawlers. Veja o que faz a Thunderbit se destacar:

- Pré-processamento semântico: Antes de extrair dados, a Thunderbit converte páginas da web e logs em conteúdo estruturado no estilo Markdown. Esse pré-processamento em “nível semântico” faz com que a IA realmente entenda o contexto, os campos e a lógica do que está a ler. Isso salva o dia em páginas complexas, dinâmicas ou pesadas em JavaScript (pense no Facebook Marketplace ou em longos tópicos de comentários), onde os scrapers tradicionais baseados em DOM falham.
- Verificação dupla: A Thunderbit consegue reunir rapidamente documentação oficial de IPs de crawlers e listas de ASN, e depois cruzá-las com os logs do seu servidor. O resultado? Uma “allowlist confiável de crawlers” em que você realmente pode confiar — sem conferência manual.
- Extração automatizada de logs: Alimente a Thunderbit com os seus logs brutos, e ela os transforma em tabelas estruturadas (Excel, Sheets, Airtable), rotulando visitantes de alta frequência, caminhos suspeitos e bots conhecidos. A partir daí, você pode enviar os resultados ao seu WAF ou CDN para bloqueio automático, limitação de taxa ou desafios de CAPTCHA.
- Conformidade e auditoria: A extração semântica da Thunderbit mantém um trilho de auditoria claro — quem acedeu ao quê, quando e como isso foi tratado. Isso ajuda muito em necessidades de conformidade como GDPR, CCPA e outras.
Já vi equipas reduzirem em 80% o trabalho de gestão de crawlers com a Thunderbit — e, finalmente, perceberem quais bots ajudam, quais atrapalham e quais estão apenas a fingir.
2. Googlebot: o padrão dos mecanismos de busca
é o padrão-ouro dos web crawlers. Ele é responsável por indexar o seu site para a Pesquisa Google — bloqueie-o e será como colocar uma placa de “Fechado” na sua montra digital.
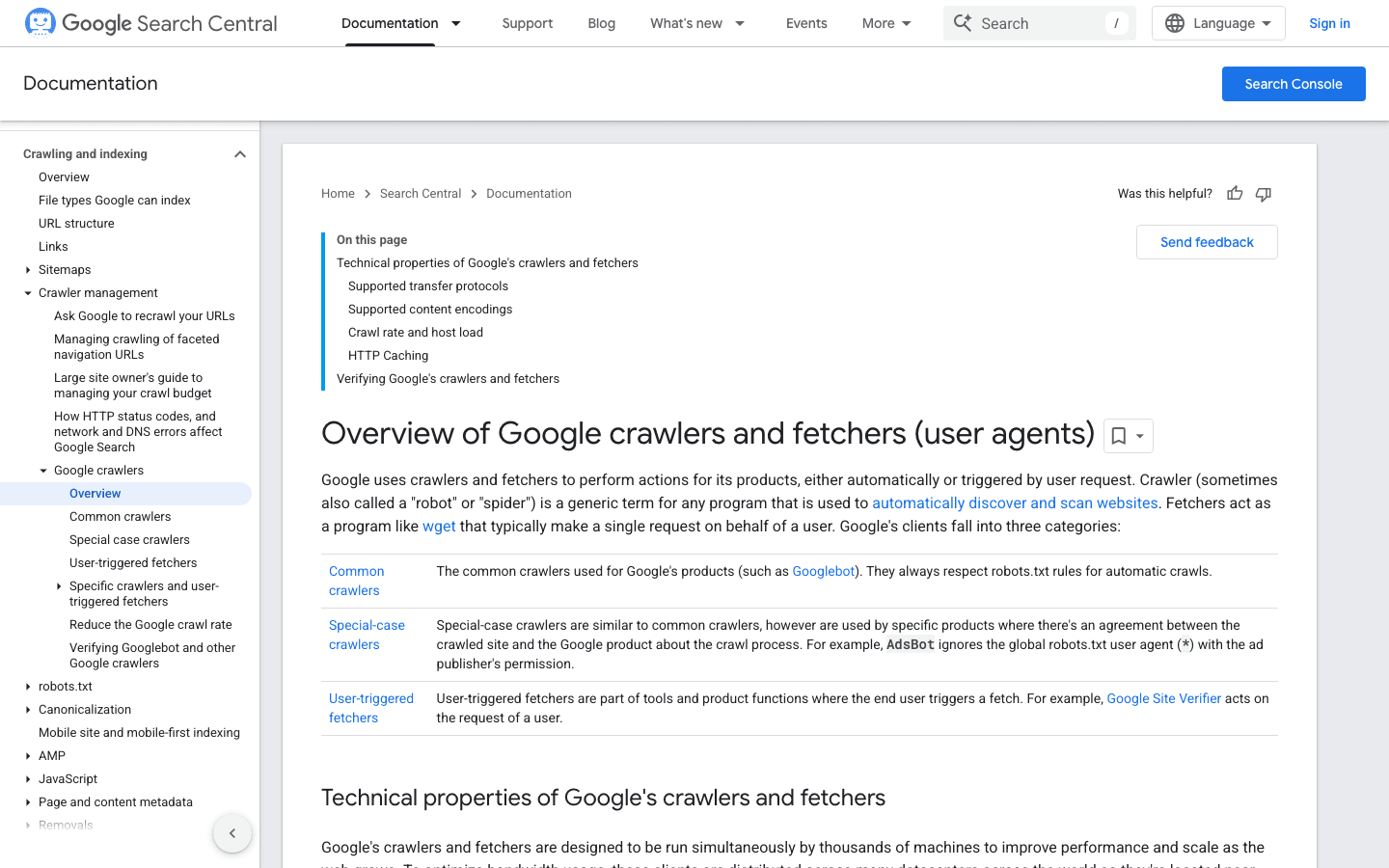
- User-Agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Verificação: Use o ou a .
- Dicas de gestão: Permita sempre o Googlebot. Use o robots.txt para orientar — não bloquear — o rastreamento, e ajuste a taxa de rastreamento no Google Search Console se necessário.
3. Bingbot: o explorador da web da Microsoft
alimenta os resultados de busca do Bing e do Yahoo. É o segundo crawler mais importante para a maioria dos sites.
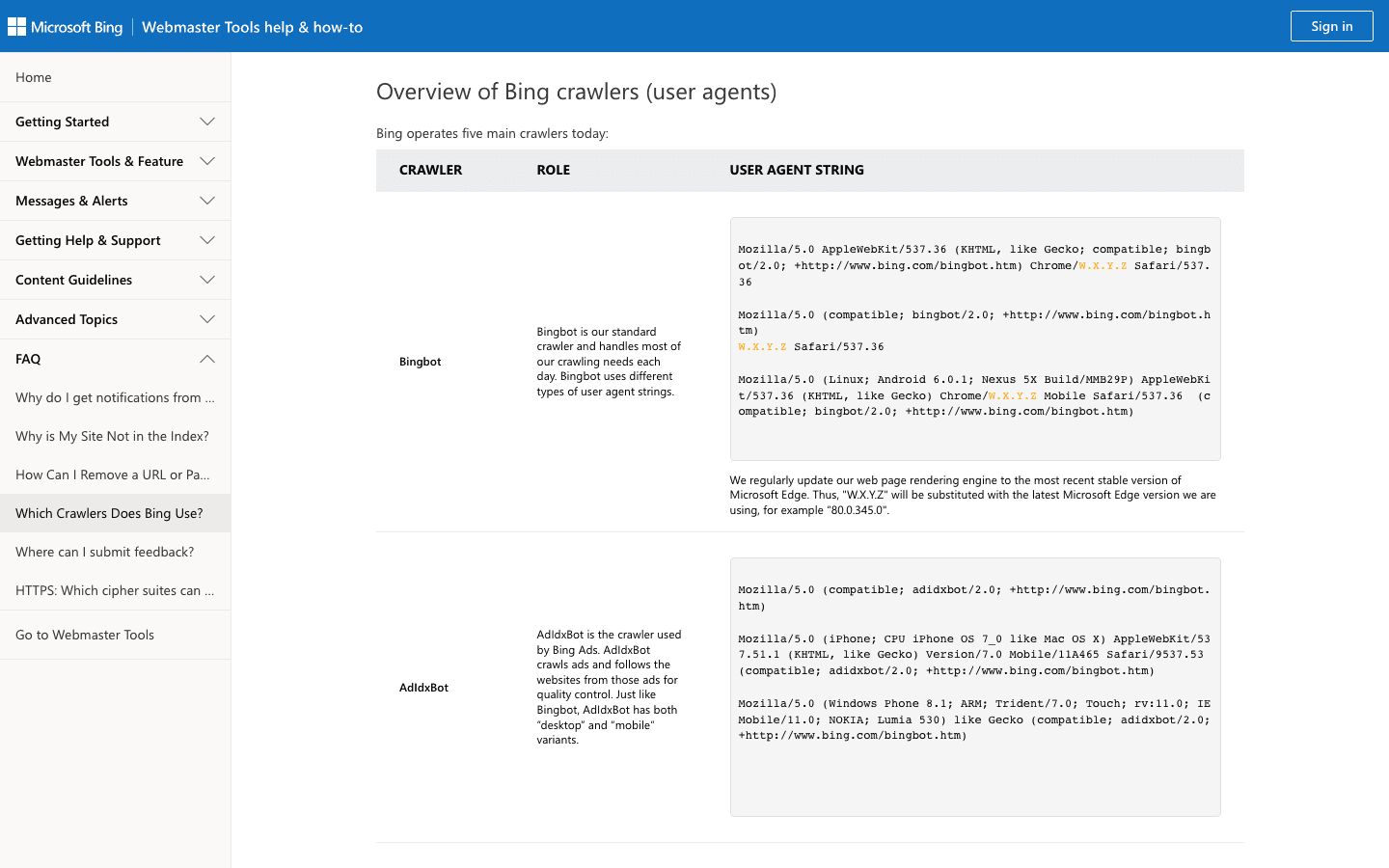
- User-Agent:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Verificação: Use a e a .
- Dicas de gestão: Permita o Bingbot, gerencie a taxa de rastreamento no Bing Webmaster Tools e use o robots.txt para ajustes finos.
4. Baiduspider: o principal crawler de busca da China
é a porta de entrada para o tráfego de busca chinês.
- User-Agent:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - Verificação: Não há lista oficial de IPs; verifique se há
.baidu.comno DNS reverso, mas esteja ciente das limitações. - Dicas de gestão: Permita se quiser tráfego da China. Use o robots.txt para definir regras, mas observe que o Baiduspider às vezes as ignora. Se não precisar de SEO para a China, considere limitar a taxa ou bloquear para poupar banda.
5. YandexBot: o crawler do mecanismo de busca russo
é essencial para os mercados russo e da CEI.
- User-Agent:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - Verificação: O DNS reverso deve terminar em
.yandex.ru,.yandex.netou.yandex.com. - Dicas de gestão: Permita se estiver a segmentar utilizadores de língua russa. Use o Yandex Webmaster para controlar o rastreamento.
6. DuckDuckBot: crawler de busca com foco em privacidade
alimenta a busca centrada em privacidade do DuckDuckGo.
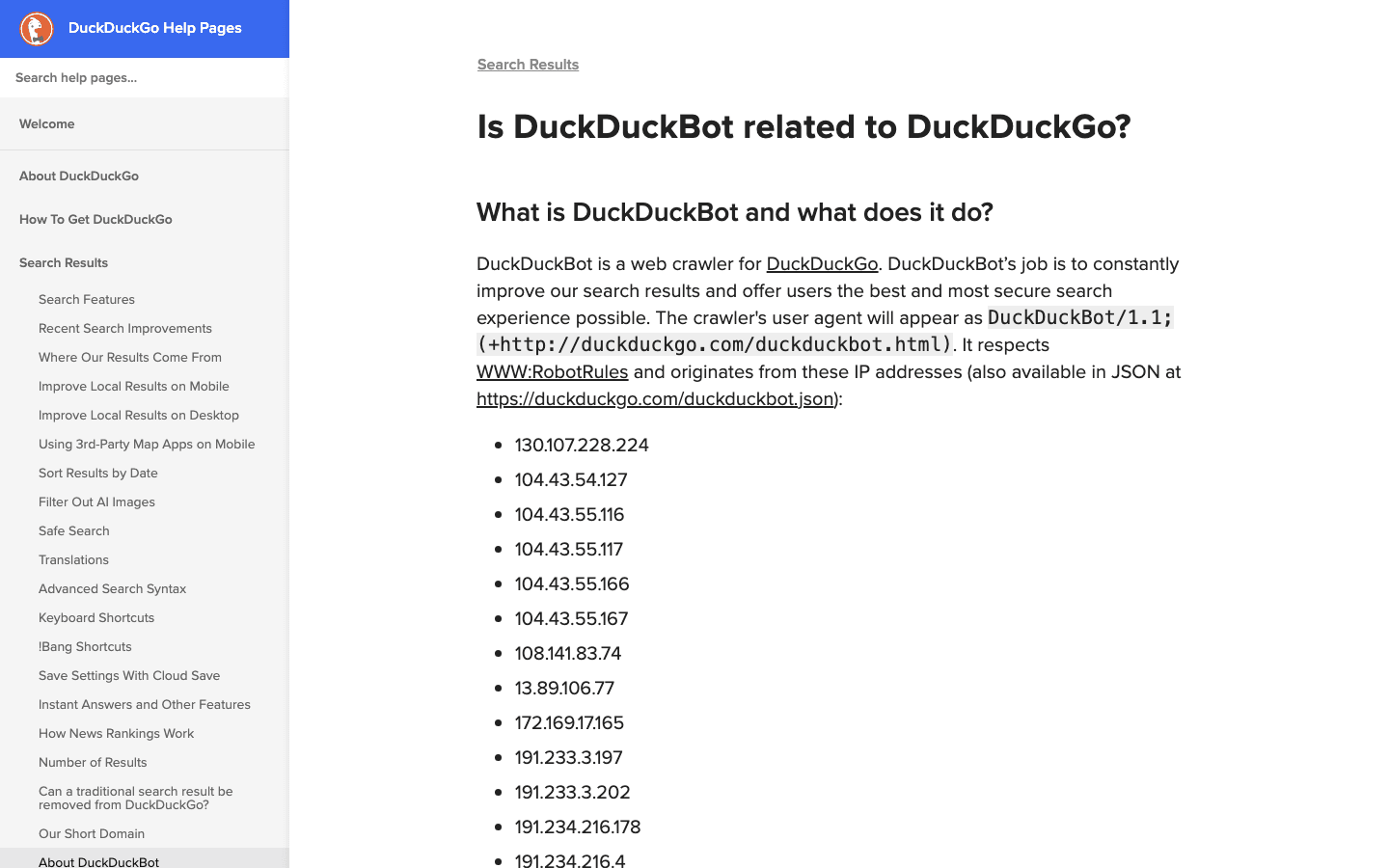
- User-Agent:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - Verificação: .
- Dicas de gestão: Permita, a menos que você não tenha interesse nenhum em utilizadores que valorizam privacidade. Baixa carga de rastreamento, fácil de gerir.
7. AhrefsBot: análise de SEO e backlinks
é um crawler de ferramenta de SEO de primeira linha — ótimo para análise de backlinks, mas pode consumir muita banda.
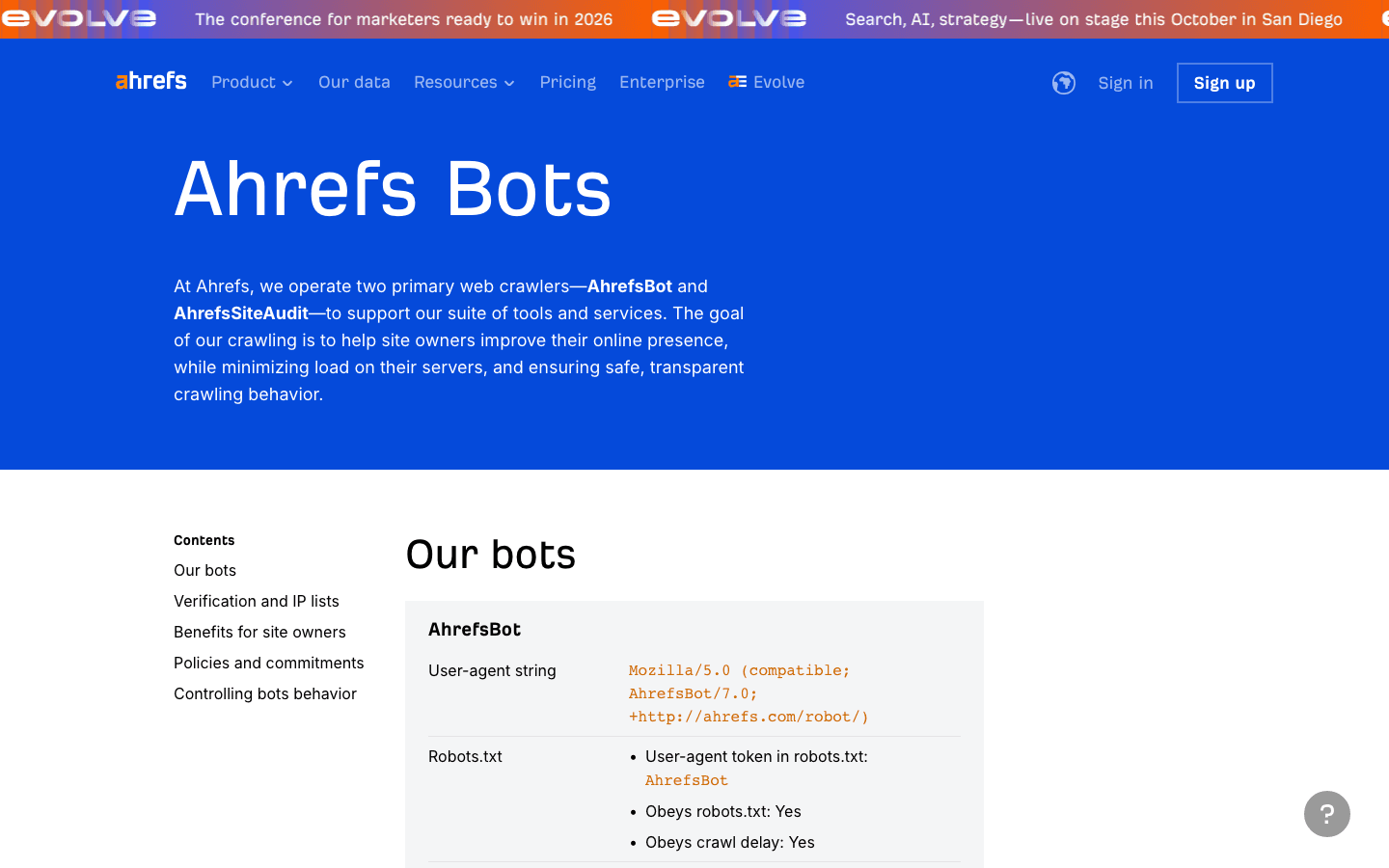
- User-Agent:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - Verificação: Não há lista pública de IPs; verifique pelo UA e pelo DNS reverso.
- Dicas de gestão: Permita se você usa Ahrefs. Use o robots.txt para crawl-delay ou bloqueio. Você pode .
8. SemrushBot: insights competitivos de SEO
é outro grande crawler de SEO.
- User-Agent:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(além de variantes comoSemrushBot-BA,SemrushBot-SI, etc.) - Verificação: Pelo user-agent; não há lista pública de IPs.
- Dicas de gestão: Permita se você usa Semrush; caso contrário, limite ou bloqueie com o robots.txt ou regras do servidor.
9. FacebookExternalHit: bot de pré-visualização para redes sociais
busca os dados Open Graph para prévias de links no Facebook e Instagram.
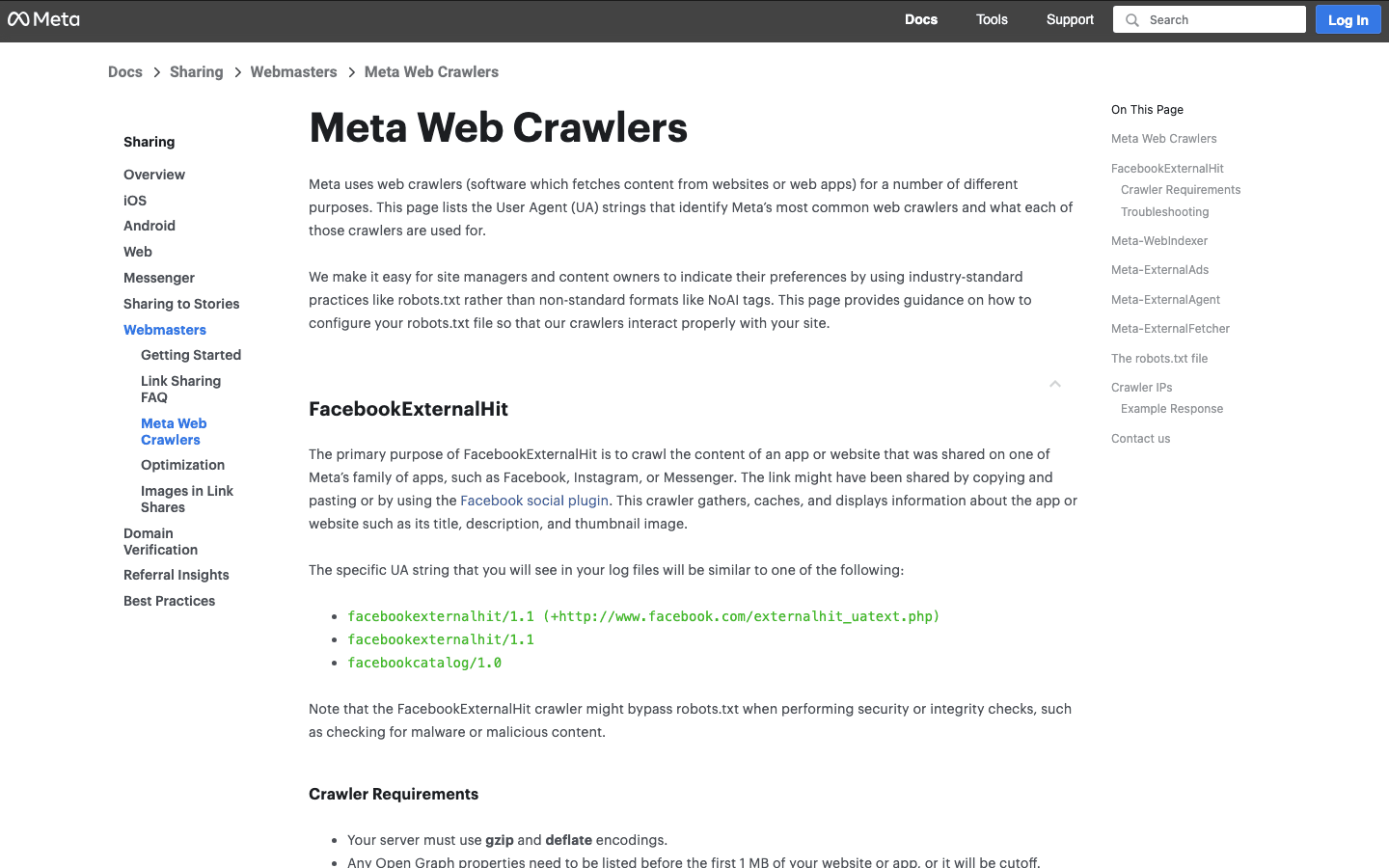
- User-Agent:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - Verificação: Pelo user-agent; os IPs pertencem ao ASN do Facebook.
- Dicas de gestão: Permita para obter prévias sociais ricas. Bloquear significa não ter miniaturas nem resumos no Facebook/Instagram.
10. Twitterbot: crawler de pré-visualização de links do X (Twitter)
busca os dados do Twitter Card para o X (Twitter).
- User-Agent:
Twitterbot/1.0 - Verificação: Pelo user-agent; ASN do Twitter (AS13414).
- Dicas de gestão: Permita para prévias no Twitter. Use metatags do Twitter Card para obter os melhores resultados.
Tabela comparativa: lista de crawlers em resumo
| Crawler | Finalidade | Exemplo de User-Agent | Método de verificação | Impacto nos negócios | Dicas de gestão |
|---|---|---|---|---|---|
| Thunderbit | Análise de logs/crawlers com IA | N/A (ferramenta, não um bot) | N/A | Gestão de dados, classificação de bots | Use para extração de logs e construção de allowlist |
| Googlebot | Indexação da Pesquisa Google | Googlebot/2.1 | DNS e lista de IPs | Crítico para SEO | Permita sempre, gerencie via Search Console |
| Bingbot | Busca do Bing/Yahoo | bingbot/2.0 | DNS e lista de IPs | Importante para SEO no Bing/Yahoo | Permita, gerencie via Bing Webmaster Tools |
| Baiduspider | Busca do Baidu (China) | Baiduspider/2.0 | DNS reverso, string UA | Essencial para SEO na China | Permita se estiver segmentando a China, monitore a banda |
| YandexBot | Busca do Yandex (Rússia) | YandexBot/3.0 | DNS reverso para .yandex.ru | Essencial para Rússia/Europa Oriental | Permita se estiver segmentando RU/CEI, use ferramentas do Yandex |
| DuckDuckBot | Busca do DuckDuckGo | DuckDuckBot/1.1 | Lista oficial de IPs | Público focado em privacidade | Permita, baixo impacto |
| AhrefsBot | Análise de SEO/backlinks | AhrefsBot/7.0 | String UA, DNS reverso | Ferramenta de SEO, pode consumir muita banda | Permita/limite/bloqueie via robots.txt |
| SemrushBot | Análise de SEO/concorrência | SemrushBot/1.0 (além de variantes) | String UA | Ferramenta de SEO, pode ser agressiva | Permita/limite/bloqueie via robots.txt |
| FacebookExternalHit | Prévias de links sociais | facebookexternalhit/1.1 | String UA, ASN do Facebook | Engajamento em redes sociais | Permita para prévias, use tags OG |
| Twitterbot | Prévias de links do Twitter | Twitterbot/1.0 | String UA, ASN do Twitter | Engajamento no Twitter | Permita para prévias, use tags Twitter Card |
Gerindo sua lista de crawlers: melhores práticas para 2025
- Atualize regularmente: O cenário de crawlers muda rápido. Programe revisões trimestrais e use ferramentas como a Thunderbit para raspar e comparar listas oficiais ().
- Verifique, não confie: Sempre confira user-agent e IP/ASN. Não deixe impostores entrarem e distorcerem as suas métricas ou extraírem os seus dados ().
- Inclua bons bots na allowlist: Garanta que crawlers de busca e redes sociais nunca sejam bloqueados por regras anti-bot ou firewalls.
- Limite ou bloqueie bots agressivos: Use robots.txt, crawl-delay ou regras de servidor para ferramentas de SEO que passam do ponto.
- Automatize a análise de logs: Use ferramentas com IA (como a Thunderbit) para extrair, classificar e rotular a atividade de crawlers — economizando tempo e captando tendências que você talvez não perceba.
- Equilibre SEO, analytics e segurança: Não bloqueie os bots que movem seu negócio, mas também não deixe os ruins agirem livremente.
Conclusão: mantendo sua lista de crawlers atualizada e acionável
Em 2025, gerir sua lista de crawlers não é só uma tarefa de TI — é um trabalho crítico para o negócio que afeta SEO, analytics, segurança e conformidade. Com os bots já a compor a maior parte do tráfego da web, você precisa saber quem está a visitar, porquê e o que fazer a respeito. Mantenha sua lista atualizada, automatize o que puder e use ferramentas como a para sair na frente. A web só fica mais movimentada — e uma estratégia inteligente e acionável para crawlers é sua melhor defesa (e seu melhor ataque) nesse mundo movido por bots.
FAQs
1. Por que é importante manter uma lista atualizada de crawlers?
Porque os bots já representam mais da metade de todo o tráfego da web, e só uma pequena parte deles é benéfica. Manter sua lista atualizada garante que você permita os bons bots (para SEO e prévias sociais) e bloqueie ou limite os ruins, protegendo suas métricas, sua banda e a segurança dos seus dados.
2. Como posso saber se um crawler é legítimo ou falso?
Não confie só no user-agent — sempre verifique o endereço IP ou o ASN usando listas oficiais ou consultas de DNS reverso. Ferramentas como a Thunderbit podem automatizar esse processo, comparando logs com IPs e user-agents de bots publicados.
3. O que devo fazer se um bot desconhecido estiver rastreando meu site?
Investigue o user-agent e o IP. Se não estiver na sua allowlist e não corresponder a um bot conhecido, considere limitar, desafiar ou bloquear. Use ferramentas de IA para classificar e monitorar novos crawlers à medida que aparecem.
4. Como a Thunderbit ajuda na gestão de crawlers?
A Thunderbit usa IA para extrair, estruturar e classificar a atividade de crawlers a partir de logs, facilitando a criação de allowlists, a identificação de impostores e a automação da aplicação de políticas. Seu pré-processamento semântico é especialmente robusto para sites complexos ou dinâmicos.
5. Qual é o risco de bloquear um crawler importante como Googlebot ou Bingbot?
Bloquear crawlers de mecanismos de busca pode remover seu site dos resultados de pesquisa e matar seu tráfego orgânico. Sempre revise com cuidado seu firewall, robots.txt e regras anti-bot para garantir que não está, sem querer, expulsando os bots mais importantes.
Saiba mais: