
Se você está a explorar ferramentas de raspagem web com IA, provavelmente já se cruzou com o Crawl4AI. É um projeto open-source bastante popular, que tem vindo a chamar a atenção de desenvolvedores pela velocidade e flexibilidade. Mas e se você não programa — ou só quer obter dados rapidamente, sem andar às voltas com scripts em Python? Seja porque está a considerar o Crawl4AI para o seu próximo projeto ou porque procura uma alternativa mais fácil de usar, especialmente se trabalha em vendas, marketing, e-commerce ou imobiliário, está no sítio certo. Nesta análise, vou explicar o que o Crawl4AI oferece, onde se destaca e onde pode ficar aquém. Também vou mostrar como o Thunderbit se compara como uma solução moderna, sem código, para utilizadores de negócios que querem raspar a web com apenas alguns cliques.
O que é o Crawl4AI?
O Crawl4AI é uma biblioteca Python open-source criada para rastreamento de sites e extração de dados, com foco especial em casos de uso com IA e modelos de linguagem de grande porte (LLMs). Ganhou tração no GitHub pelo rastreamento paralelo de alta velocidade e pela capacidade de exportar dados em formatos amigos da IA, como JSON e Markdown. Em resumo, é uma ferramenta para desenvolvedores que querem extrair dados de sites em escala e depois alimentar esses dados em modelos de IA, painéis de analytics ou bases de dados personalizadas.
![]()
Principais produtos e recursos:
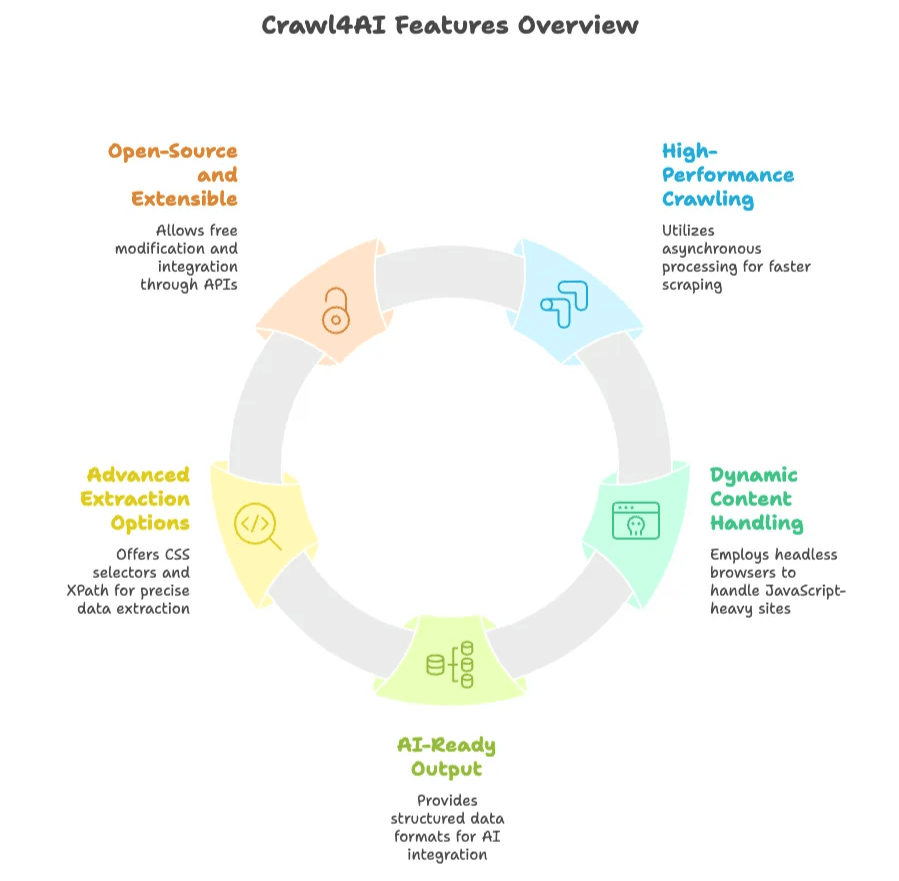
- Rastreamento de alto desempenho: usa processamento assíncrono e paralelo para rastrear várias páginas ao mesmo tempo, ficando muito mais rápido do que muitos raspadores tradicionais.
- Tratamento de conteúdo dinâmico: controla um navegador headless (como o Chromium via Playwright) para executar JavaScript e raspar sites modernos e dinâmicos.
- Saída pronta para IA: exporta dados como texto estruturado (JSON, Markdown ou HTML limpo), pronto para IA ou análise de dados.
- Opções avançadas de extração: permite definir regras de extração com seletores CSS ou XPath e até integrar LLMs para sumarização ou extração de conteúdo.
- Open-source e extensível: gratuito para usar, modificar e expandir. Oferece uma API Python, interface de linha de comando e API REST para integração flexível.
A filosofia do Crawl4AI é “democratizar os dados”, oferecendo aos desenvolvedores um raspador rápido, orientado por código, sem paywalls ou restrições típicas de ferramentas comerciais. Se domina Python, é uma forma poderosa de recolher grandes volumes de dados da web rapidamente.
Para quem é o Crawl4AI?
O Crawl4AI foi criado sobretudo para utilizadores técnicos — pense em desenvolvedores, cientistas de dados, investigadores de IA e qualquer pessoa que se sinta confortável a escrever scripts em Python. Alguns casos de uso típicos incluem:
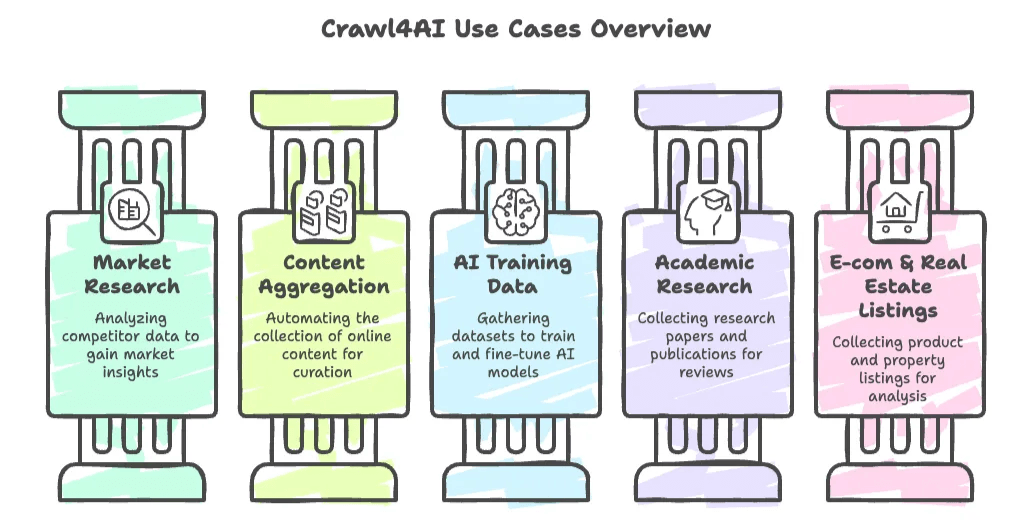
- Pesquisa de mercado e análise da concorrência: raspe sites de concorrentes, notícias ou redes sociais à procura de insights.
- Agregação de conteúdo: automatize a recolha de notícias, blogs ou publicações em fóruns para curadoria ou acompanhamento de tendências.
- Recolha de dados para treino de IA: reúna grandes conjuntos de dados (como documentação, perguntas e respostas ou artigos) para treinar ou afinar modelos de linguagem.
- Pesquisa académica: recolha automaticamente artigos científicos, jurisprudência ou publicações online para revisões bibliográficas.
- Listagens de e-commerce e imobiliário: desenvolvedores podem criar rastreadores personalizados para recolher listagens de produtos ou imóveis para análise.
Mas há um senão: o Crawl4AI não foi pensado para utilizadores sem perfil técnico. Se é gestor de vendas, profissional de marketing ou agente imobiliário sem experiência em programação, provavelmente vai achar a configuração e a utilização intimidantes. A ferramenta parte do princípio de que você percebe de Python e sabe configurar regras de extração e resolver problemas técnicos.
Plano de preços do Crawl4AI
Um dos maiores atrativos do Crawl4AI é o preço: é totalmente gratuito. Sendo um projeto open-source, não há taxas de licença, planos de subscrição nem paywalls. Pode instalá-lo via pip e começar a usar de imediato.
No entanto, o “gratuito” vem com algumas ressalvas:
- Configuração e manutenção: será preciso investir tempo para preparar o ambiente, escrever scripts e manter os fluxos de raspagem.
- Custos indiretos: se estiver a executar rastreamentos grandes, pode ter de pagar por proxies, servidores ou recursos na cloud.
- Suporte: não há apoio oficial ao cliente — apenas fóruns da comunidade e issues no GitHub.
Para empresas com talento técnico interno, isto pode ser uma solução económica. Mas, para equipas sem perfil técnico, o tempo e o esforço necessários para pôr tudo a funcionar podem facilmente superar a vantagem do preço zero.
Feedback de utilizadores sobre o Crawl4AI
Para perceber mesmo como o Crawl4AI se comporta na prática, fui analisar avaliações de utilizadores em blogs de tecnologia, diretórios de ferramentas de IA e fóruns da comunidade. Eis o que encontrei:
O que os utilizadores gostam
- Velocidade e custo-benefício: desenvolvedores elogiam a rapidez com que o Crawl4AI consegue raspar sites grandes, muitas vezes superando ferramentas pagas. O facto de ser gratuito é um grande diferencial.
- Flexibilidade open-source: os utilizadores gostam de ter controlo total sobre o código, sem dependência de fornecedor nem restrições de funcionalidades.
- Saída pronta para IA: a exportação de dados estruturados e limpos (especialmente em JSON ou Markdown) poupa tempo a quem alimenta modelos de IA ou ferramentas de analytics.
Onde os utilizadores encontram dificuldades
Mas os elogios vêm acompanhados de alguns alertas importantes — especialmente para iniciantes ou pessoas sem experiência em programação.
1. Curva de aprendizagem acentuada
Um tema recorrente é que o Crawl4AI não é amigo de iniciantes. Se está a começar em web scraping ou não domina Python, a curva de aprendizagem vai ser alta. Não há interface de clicar e arrastar; tudo é feito por scripts e ficheiros de configuração. Configurar o ambiente, escrever regras de extração e lidar com rastreamento assíncrono exigem conhecimento técnico. Um avaliador resumiu sem rodeios: “Se você não programa, vai se perder.”
2. Pouco amigável para quem está a começar agora
Mesmo para quem já tem alguma bagagem técnica, o Crawl4AI pode ser desafiante. A documentação está a melhorar, mas a comunidade ainda é pequena, por isso conseguir ajuda pode demorar. Utilizadores relatam bugs ou bloqueios em sites complexos, e muitas vezes a solução passa por vasculhar issues no GitHub ou no Stack Overflow. Também faltam recursos nativos para necessidades comuns de negócio — como fazer login em sites, resolver CAPTCHAs ou agendar rastreamentos recorrentes. Se quiser raspar dados num cronograma ou lidar com autenticação, vai precisar de construir esses recursos por conta própria.
Exemplo do mundo real:
- Um gestor de marketing de uma empresa de e-commerce de média dimensão tentou usar o Crawl4AI para monitorizar preços da concorrência. Depois de vários dias a lutar com scripts em Python e drivers de navegador, desistiu e mudou para uma ferramenta sem código. As barreiras técnicas e a falta de suporte tornaram a solução inviável para a equipa.
- Um agente imobiliário queria raspar listagens de propriedades em vários sites. Achou a configuração do Crawl4AI excessivamente complexa e não conseguiu avançar para além da configuração inicial. Sem um programador disponível, o projeto ficou parado.
Em resumo, embora o Crawl4AI seja uma potência para desenvolvedores, é difícil de vender a utilizadores de negócios que só querem obter dados sem dores de cabeça.
Principais conclusões da análise do Crawl4AI
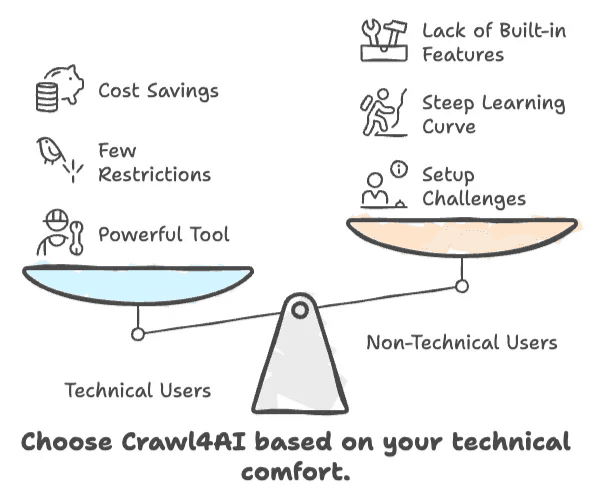
- O Crawl4AI é rápido, flexível e gratuito — mas só se você se sentir confortável com código.
- Utilizadores sem perfil técnico vão sofrer com a configuração, a curva de aprendizagem e a falta de funcionalidades empresariais nativas.
- Se precisa de uma solução sem código, baseada em clique, o Crawl4AI provavelmente não é para você.
- Para desenvolvedores e profissionais de IA, é uma ferramenta poderosa e com poucas restrições.
- Para utilizadores de negócios, o tempo e o esforço exigidos podem superar a poupança de custos.
Apresentando o Thunderbit: o raspador web com IA e sem código para utilizadores de negócios
Depois de ver onde o Crawl4AI fica aquém para utilizadores sem perfil técnico, vamos falar de uma alternativa melhor: Thunderbit.
O Thunderbit é uma extensão Chrome de raspagem web com IA criada especificamente para utilizadores de negócios — equipas de vendas, marketing, e-commerce e imobiliário que querem extrair dados de qualquer site rapidamente, sem precisar de programar. Já testei muitas ferramentas de raspagem, e o Thunderbit destaca-se pela simplicidade e pela potência.
O que torna o Thunderbit diferente?
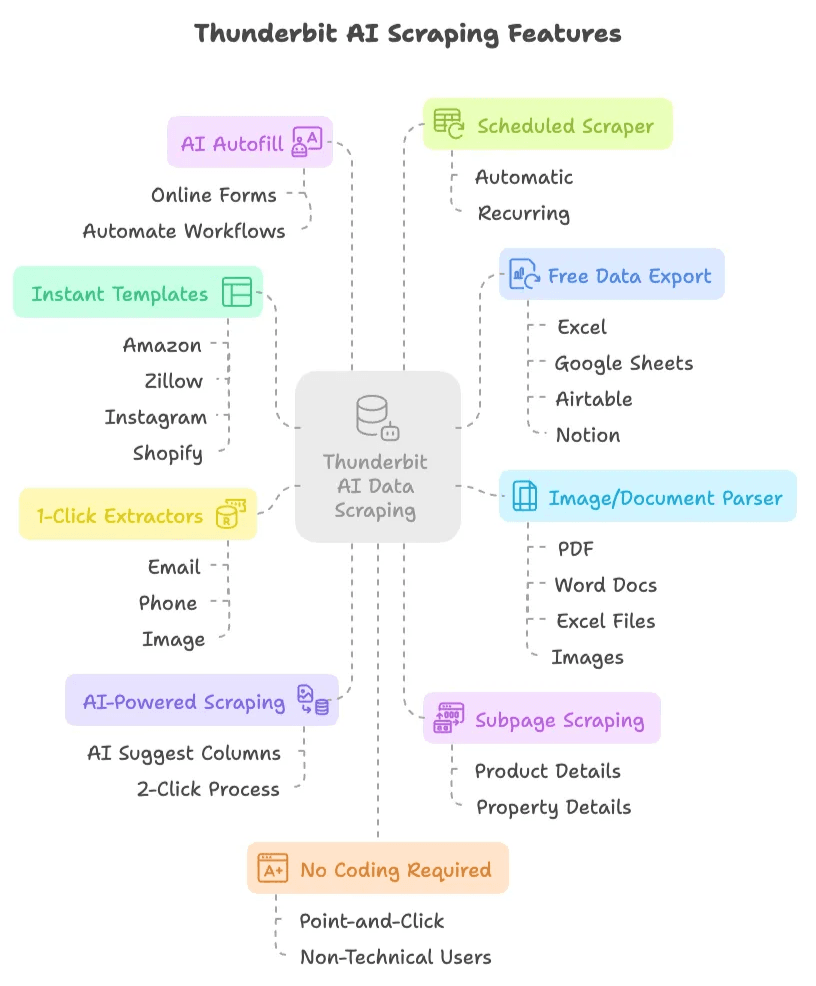
- Raspagem com IA em 2 cliques: basta clicar em “Sugerir colunas com IA”, deixar a IA recomendar o que extrair e depois clicar em “Raspar”. Pronto. Sem scripts, sem seletores, sem dor de cabeça.
- Raspagem de subpáginas: a IA do Thunderbit pode visitar automaticamente subpáginas (como detalhes de produtos ou imóveis) e enriquecer a sua tabela de dados — sem configuração manual.
- Modelos instantâneos de raspagem de dados: para sites populares como Amazon, Zillow, Instagram e Shopify, pode exportar dados com um clique usando modelos prontos.
- Exportação de dados gratuita: exporte os dados raspados para Excel, Google Sheets, Airtable ou Notion — sem pagar extra.
- Preenchimento automático com IA (totalmente gratuito): use IA para preencher formulários online e automatizar fluxos de trabalho. Basta selecionar o contexto e deixar o Thunderbit fazer o resto.
- Raspador agendado: configure raspagens automáticas e recorrentes com um agendamento simples — sem jobs cron nem configuração de servidor.
- Extratores de email, telefone e imagem com 1 clique: capture instantaneamente emails, números de telefone ou imagens de qualquer site.
- Analisador de imagens/documentos: extraia tabelas de PDFs, documentos Word, ficheiros Excel ou imagens. Envie o ficheiro, deixe a IA estruturar os dados e clique em “Raspar”.
- Sem necessidade de programação: tudo funciona por clique, pensado para utilizadores sem perfil técnico.
Raspe dados de qualquer site usando IA Get Started Free
O Thunderbit existe para tornar os dados da web acessíveis a todos — e não apenas a desenvolvedores. Se quiser ver como funciona, confira a página de download da extensão Chrome do Thunderbit ou navegue pelo blog do Thunderbit para ver casos de uso reais.
Experimente o Raspador Web IA do Thunderbit gratuitamente
Planos de preços do Thunderbit
O Thunderbit usa um sistema simples de créditos: 1 crédito = 1 linha de saída. Veja como os planos se dividem:
| Nível | Preço mensal | Preço anual (por mês) | Créditos (mensais) |
|---|---|---|---|
| Gratuito | Gratuito | Gratuito | 6 páginas |
| Starter | US$ 15 | US$ 9 | 500 |
| Pro 1 | US$ 38 | US$ 16,5 | 3.000 |
| Pro 2 | US$ 75 | US$ 33,8 | 6.000 |
| Pro 3 | US$ 125 | US$ 68,4 | 10.000 |
| Pro 4 | US$ 249 | US$ 137,5 | 20.000 |
Pode começar gratuitamente e raspar até 6 páginas (ou 10 com o teste grátis). Os planos pagos libertam mais créditos e funcionalidades avançadas, mas até o plano gratuito já é generoso para quem usa pouco. Para mais detalhes, visite a página de Preços do Thunderbit.
Thunderbit vs. Crawl4AI: comparação lado a lado
Vamos pôr o Thunderbit e o Crawl4AI frente a frente para que veja onde cada ferramenta se destaca — e onde o Thunderbit facilita a vida de utilizadores de negócios.
| Recurso / Critério | Thunderbit | Crawl4AI |
|---|---|---|
| Interface sem código, baseada em clique | ✅ | ❌ |
| Sugerir colunas com IA (autoidentificação) | ✅ | ❌ |
| Raspagem de subpáginas (automática) | ✅ | ❌ |
| Modelos instantâneos (Amazon etc.) | ✅ | ❌ |
| Exportação gratuita de dados (Excel, Sheets) | ✅ | ❌ |
| Preenchimento automático com IA (formulários) | ✅ | ❌ |
| Raspagem agendada (sem código) | ✅ | ❌ |
| Extração de email/telefone/imagem com 1 clique | ✅ | ❌ |
| Extração de tabelas de imagens/documentos | ✅ | ❌ |
| Lida com conteúdo dinâmico | ✅ | ✅ |
| Open-source | ❌ | ✅ |
| Exige programação | ❌ | ✅ |
| Possui plano gratuito | ✅ | ✅ |
| Suporte da comunidade | ✅ | ⚠️ (limitado) |
| Feito para utilizadores de negócios | ✅ | ❌ |
| Feito para desenvolvedores | ⚠️ | ✅ |
| Preço | $ (gratuito e pagos) | Gratuito |
| Suporte ao cliente | ✅ | ❌ |
Legenda:
✅ = Sim
❌ = Não
⚠️ = Limitado/parcial
$ = planos pagos disponíveis
Conclusão
Se você é desenvolvedor, gosta de mexer com código e quer controlo total, o Crawl4AI é uma ferramenta poderosa e gratuita para raspagem web em grande escala. Mas, se é um utilizador de negócios — especialmente em vendas, marketing, e-commerce ou imobiliário — e só quer obter dados sem complicação, o Thunderbit é o vencedor claro. Foi feito para utilizadores sem perfil técnico, com automação por IA, modelos instantâneos e uma interface amigável que o leva do site à folha de cálculo em segundos.
Raspe qualquer site com o Thunderbit
Perguntas frequentes
1. Como o Thunderbit se compara a outros raspadores web com IA, como o Crawl4AI?
O Thunderbit foi criado para utilizadores sem perfil técnico, oferecendo uma interface sem código, baseada em clique, enquanto o Crawl4AI é uma biblioteca Python open-source voltada para desenvolvedores. O Thunderbit automatiza tarefas complexas com IA, tornando a raspagem web acessível a todos.
2. Que recursos exclusivos o Thunderbit oferece para utilizadores de negócios?
O Thunderbit oferece sugestões de colunas com IA, raspagem de subpáginas, modelos instantâneos para sites populares e exportação gratuita de dados para Excel ou Google Sheets — tudo sem programar. Também inclui raspagem agendada e extratores com 1 clique para emails, números de telefone e imagens.
3. O Thunderbit consegue lidar com extração de dados complexos, como PDFs ou imagens?
Com certeza! A IA do Thunderbit consegue extrair tabelas de PDFs, documentos Word, ficheiros Excel e imagens. Basta enviar o ficheiro, deixar a IA estruturar os dados e clicar em “Raspar” para obter resultados instantâneos. Saiba mais no blog do Thunderbit.
Saiba mais
- O que é raspagem de dados e como fazer isso em 2025 – Blog do Thunderbit
- As melhores ferramentas e softwares de raspagem web em 2025 – Blog do Thunderbit
- As principais ferramentas de coleta de dados com IA para conjuntos prontos para modelagem – Medium
- Como raspadores web com IA podem ajudar na extração e análise de dados - Forbes
Experimente o Raspador Web IA Get Started Free




