

A web está crescendo mais rápido do que nunca e, se você trabalha com negócios, tecnologia ou é simplesmente um nerd de dados como eu, provavelmente já percebeu: o verdadeiro ouro está nos dados que você consegue coletar — e não só nos que você consegue ver. Hoje, as empresas correm para automatizar a coleta de dados da web, e a previsão é que a indústria global de web scraping chegue a US$ 2 bilhões até 2030. E aqui vai um dado curioso: mais de 65% das organizações já usam crawlers ou scrapers para alimentar seus fluxos de trabalho de IA, analytics e operações de negócio.
Então, como entrar nessa? Para a maioria das pessoas, a resposta é Python. É a linguagem preferida para criar crawlers de sites — simples, poderosa e cheia de bibliotecas que deixam o crawling e o scraping muito mais tranquilos. Neste guia, vou mostrar o que é um website crawler, por que Python é a melhor escolha, como criar o seu próprio passo a passo e como ferramentas como Thunderbit podem deixar tudo ainda mais fácil (principalmente se você prefere clicar em vez de codar). Seja você um desenvolvedor, um profissional de marketing orientado por dados ou alguém que só quer automatizar tarefas chatas, aqui você vai encontrar algo para turbinar seu jogo com dados da web.
O que é um Website Crawler? (E por que isso importa?)
Vamos simplificar: um website crawler é um programa que navega automaticamente pela web, visita páginas, segue links e, opcionalmente, coleta dados no caminho. Pense nele como um surfista sobre-humano na internet — que nunca dorme, nunca se cansa e nunca fecha a aba errada sem querer. Crawlers são a base dos mecanismos de busca (como o Googlebot), mas também são usados por empresas para tudo, de monitoramento de preços a pesquisa de mercado.
Mas espera aí — qual é a diferença entre crawling e scraping? Crawling é sobre descobrir e navegar pelas páginas (como mapear uma cidade), enquanto scraping é sobre extrair dados específicos dessas páginas (como juntar todos os cardápios dos restaurantes da cidade). Na prática, a maioria dos projetos faz os dois: faz o crawl para encontrar as páginas e faz o scraping para obter os dados necessários (Baeldung).
Casos reais de uso empresarial para crawlers:
- Geração de leads: Coleta automaticamente informações de contato em diretórios ou redes sociais.
- Monitoramento de preços: Acompanha preços e estoques dos concorrentes em milhares de produtos.
- Monitoramento de conteúdo: Recebe alertas quando sua marca é citada em notícias, blogs ou fóruns.
- Auditoria de SEO: Varre seu próprio site em busca de links quebrados ou metadados ausentes.
- Pesquisa de mercado: Consolida anúncios de imóveis, vagas de emprego ou avaliações de produtos para análise.
Se você já quis se clonar para dar conta da pesquisa na web, um crawler é a melhor saída.
Por que Website Crawlers são importantes para automação de negócios
Vamos ao que interessa. Por que as empresas estão investindo em crawlers e scrapers? Porque o retorno sobre o investimento é enorme. Veja rapidamente como diferentes equipes usam crawlers — e o que ganham com isso:
| Caso de uso | Principal benefício | Quem usa |
|---|---|---|
| Geração de leads | Automatiza a criação de listas de prospecção e economiza horas | Vendas, Recrutamento |
| Monitoramento de preços | Insights em tempo real sobre concorrentes, precificação dinâmica | E-commerce, Times de Produto |
| Monitoramento de conteúdo | Proteção de marca, identificação de tendências | Marketing, PR |
| Auditoria de SEO | Saúde do site, melhora de posicionamento | SEO, Webmasters |
| Pesquisa de mercado | Dados atualizados e em grande escala para análise | Analistas, Equipes de Pesquisa |
Um estudo de caso mostrou que automatizar uma tarefa semanal de coleta de dados (fazendo scraping de 5 a 7 sites) economizou mais de 50 horas por ano para um único funcionário — multiplique isso por um time e dá para entender por que as empresas “não conseguem imaginar voltar atrás” depois que começam a usar crawlers.
Python: a melhor escolha para criar um Website Crawler
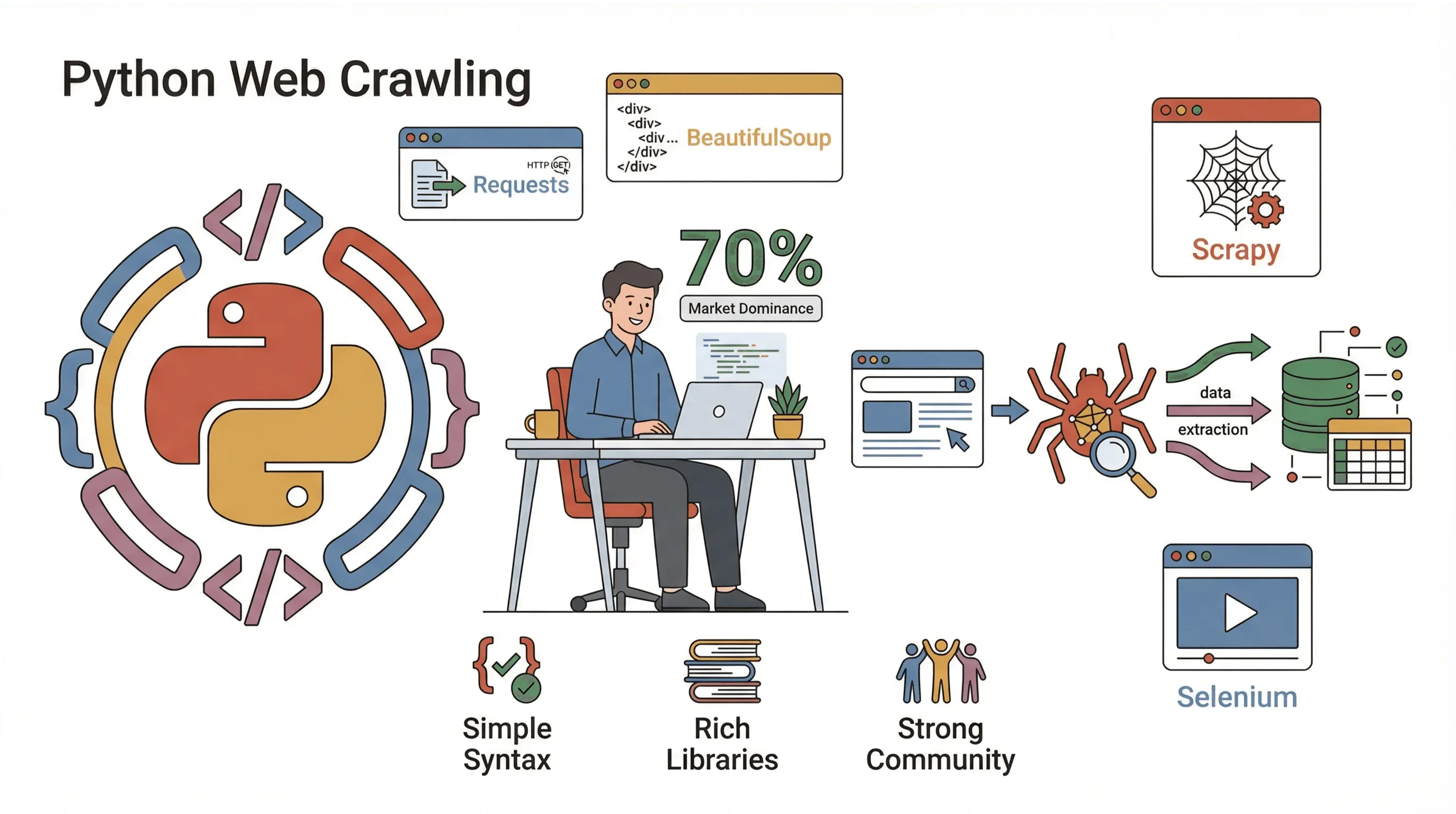 Então, por que Python é o rei do web crawling? Três motivos principais:
Então, por que Python é o rei do web crawling? Três motivos principais:
- Simplicidade: A sintaxe do Python é fácil de ler, amigável para iniciantes e permite escrever crawlers funcionais em poucas linhas.
- Ecossistema de bibliotecas: Python tem uma ampla variedade de bibliotecas para todas as etapas do crawling — buscar páginas, analisar HTML, lidar com JavaScript e muito mais.
- Comunidade: Com quase 70% dos projetos de web scraping rodando em Python, existe uma comunidade enorme, muitos tutoriais e respostas para praticamente qualquer problema que você encontrar.
Principais bibliotecas Python para web crawling:
- Requests: A forma mais simples de buscar páginas web (HTTP GET/POST).
- BeautifulSoup: A opção clássica para analisar HTML e encontrar elementos.
- Scrapy: Um framework completo de crawling para projetos em grande escala.
- Selenium: Automatiza navegadores para scraping de sites pesados em JavaScript.
Comparado a outras linguagens (como Java ou C#), Python permite sair da ideia para um crawler funcionando em muito menos tempo. E, se você trabalha com dados, pode conectar a saída do crawler diretamente ao Pandas para análise — sem aquela confusão de exportar e importar arquivos.
Comparando métodos de parsing: Regex vs. BeautifulSoup vs. Scrapy
Quando o assunto é extrair dados de páginas web, você tem opções. Veja como os principais métodos se comparam:
| Método | Como funciona | Vantagens 🟢 | Desvantagens 🔴 | Ideal para |
|---|---|---|---|---|
| Regex | Faz correspondência de padrões no HTML bruto | Rápido para padrões simples e conhecidos | Frágil, quebra quando o HTML muda | Soluções rápidas, extração de URLs |
| BeautifulSoup | Converte HTML em árvore e busca por tags | Fácil, flexível, lida bem com HTML bagunçado | Mais lento em páginas enormes, lógica de crawl manual | Scripts de scraping pequenos/médios |
| Scrapy | Framework completo de crawling, parsing com CSS/XPath | Rápido, escalável, cuida de crawling e parsing | Curva de aprendizado maior, mais configuração | Crawlers grandes e de produção |
- Regex é como usar um detector de metal na praia — rápido, mas você vai perder coisa se a areia mudar.
- BeautifulSoup é como ter um mapa e uma pá — você pode cavar em qualquer lugar, mas precisa andar pela praia sozinho.
- Scrapy é como trazer uma equipe inteira com caminhões e GPS — exagerado para um projeto pequeno, mas imbatível para trabalhos grandes.
Para quem está começando, recomendo começar com Requests + BeautifulSoup. Você aprende os fundamentos e pode migrar para Scrapy quando estiver pronto para escalar.
Passo a passo: como criar um Website Crawler simples em Python
Pronto para colocar a mão na massa? Vamos construir um crawler básico que visita páginas, segue links e coleta alguns dados. Vou guiar você em cada etapa, com código que dá para copiar e adaptar.
Passo 1: configurando seu ambiente Python
Primeiro, verifique se você tem Python 3.10+ instalado. (Confira com python --version.) Recomendo criar um ambiente virtual para o projeto:
python -m venv venv
source venv/bin/activate # No Windows: venv\Scripts\activate
Depois, instale as bibliotecas necessárias:
pip install requests beautifulsoup4
Pronto! Abra seu editor de código favorito e prepare-se para escrever o crawler.
Passo 2: escrevendo seu primeiro script de website crawler
Vamos começar buscando uma única página. Aqui vai um script simples:
import requests
def crawl_page(url):
response = requests.get(url)
response.raise_for_status() # Lança erro se não for 200 OK
print(response.text[:500]) # Mostra os primeiros 500 caracteres como prévia
crawl_page("https://www.scrapingcourse.com/ecommerce/")
Você deve ver um bloco de HTML no console — prova de que o seu script está conversando com a web.
Passo 3: seguindo links e coletando mais dados
Agora vamos fazer o crawler seguir links e visitar várias páginas. Vamos manter uma lista de URLs para visitar e um conjunto de URLs já vistos (para evitar loops):
from bs4 import BeautifulSoup
start_url = "https://www.scrapingcourse.com/ecommerce/"
urls_to_visit = [start_url]
visited_urls = set()
max_pages = 20 # Limite de segurança
while urls_to_visit and len(visited_urls) < max_pages:
current_url = urls_to_visit.pop(0)
try:
resp = requests.get(current_url)
resp.raise_for_status()
except Exception as e:
print(f"Falha ao recuperar {current_url}: {e}")
continue
soup = BeautifulSoup(resp.text, "html.parser")
print(f"Crawled: {current_url}")
for link_tag in soup.find_all("a", href=True):
url = link_tag['href']
if not url.startswith("http"):
url = requests.compat.urljoin(current_url, url)
if url.startswith(start_url) and url not in visited_urls:
urls_to_visit.append(url)
visited_urls.add(current_url)
Esse script vai fazer crawl de até 20 páginas, seguindo links que permanecem no mesmo site. Você verá cada URL conforme ela for rastreada.
Passo 4: extraindo dados das páginas
Digamos que você queira coletar nomes e preços de produtos em cada página. Veja como isso pode ser feito:
product_data = []
while urls_to_visit and len(visited_urls) < max_pages:
# ... (mesma lógica acima)
soup = BeautifulSoup(resp.text, "html.parser")
if "/page/" in current_url or current_url == start_url:
items = soup.find_all("li", class_="product")
for item in items:
name = item.find("h2", class_="product-name")
price = item.find("span", class_="price")
link = item.find("a", class_="woocommerce-LoopProduct-link")
if name and price and link:
product_data.append({
"name": name.get_text(),
"price": price.get_text(),
"url": link['href']
})
# ... (resto da lógica de crawl)
# Salvar em CSV
import csv
with open("products.csv", "w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=["name", "price", "url"])
writer.writeheader()
writer.writerows(product_data)
print(f"{len(product_data)} produtos extraídos.")
Agora você tem um arquivo CSV com todos os produtos extraídos — pronto para análise, upload ou para mostrar aos amigos.
Passo 5: depurando e otimizando seu crawler
Construir um crawler é uma coisa; deixá-lo robusto é outra. Aqui vão algumas dicas da minha própria experiência (e de algumas dores de cabeça bem reais):
- Defina um cabeçalho User-Agent: Alguns sites bloqueiam “Python-requests” por padrão. Finja ser um navegador:
headers = {"User-Agent": "Mozilla/5.0"} requests.get(url, headers=headers) - Trate erros com elegância: Use try/except para pular páginas quebradas ou bloqueadas.
- Evite loops infinitos: Sempre acompanhe as URLs visitadas e defina um limite máximo de páginas.
- Limite a frequência das requisições: Adicione
time.sleep(1)entre as requisições para evitar bloqueios. - Verifique o robots.txt: Sempre respeite as regras de crawling do site (veja mais aqui).
- Registre o progresso: Mostre ou grave cada URL enquanto faz o crawl — isso salva vidas na hora de depurar.
Se o seu crawler começar a ser bloqueado, devolver conteúdo estranho ou deixar de capturar dados, revise os headers, reduza a velocidade e confira se você não está acionando mecanismos anti-bot.
Thunderbit: simplificando o crawling de sites com IA
Extraia dados de qualquer site usando IA Get Started Free
Agora vamos falar do botão fácil do web crawling: Thunderbit. Por mais que eu goste de Python, às vezes você só quer os dados — sem configuração, sem depuração e sem manutenção. Thunderbit é uma extensão de Chrome de web scraper com IA que permite extrair dados de qualquer site em apenas alguns cliques.
O que torna o Thunderbit especial?
- Sugestão de campos por IA: A IA do Thunderbit analisa a página e recomenda quais dados você pode extrair — sem precisar inspecionar HTML ou escrever seletores.
- Sem código, direto no navegador: Funciona no browser, então também roda em sites com login e páginas pesadas em JavaScript.
- Scraping de subpáginas: Precisa de mais detalhes? O Thunderbit pode visitar automaticamente cada subpágina (como páginas de produto) e enriquecer sua tabela.
- Exportação instantânea: Exporte seus dados para Excel, Google Sheets, Airtable ou Notion — sem precisar lidar com CSV manualmente.
- Scraping em nuvem ou local: Escolha entre scraping rápido na nuvem (para sites públicos) ou modo navegador (para sites com login ou mais complicados).
- Agendamento: Configure coletas automáticas — sem cron jobs e sem servidores.
Para usuários de negócio, o Thunderbit é um divisor de águas. Você sai de “eu preciso desses dados” para “aqui está minha planilha” em minutos, não em horas. E, se você é desenvolvedor, o Thunderbit pode complementar seus scripts — use-o para tarefas rápidas ou como plano B quando seu código precisar descansar.
Quer ver como funciona? Baixe a extensão do Chrome e teste em um site que você gosta. O plano gratuito permite extrair algumas páginas, e os planos pagos começam em apenas US$ 15/mês para 500 créditos.
Experimente o Thunderbit AI Web Scraper grátis
Principais pontos de atenção ao criar um Website Crawler em Python
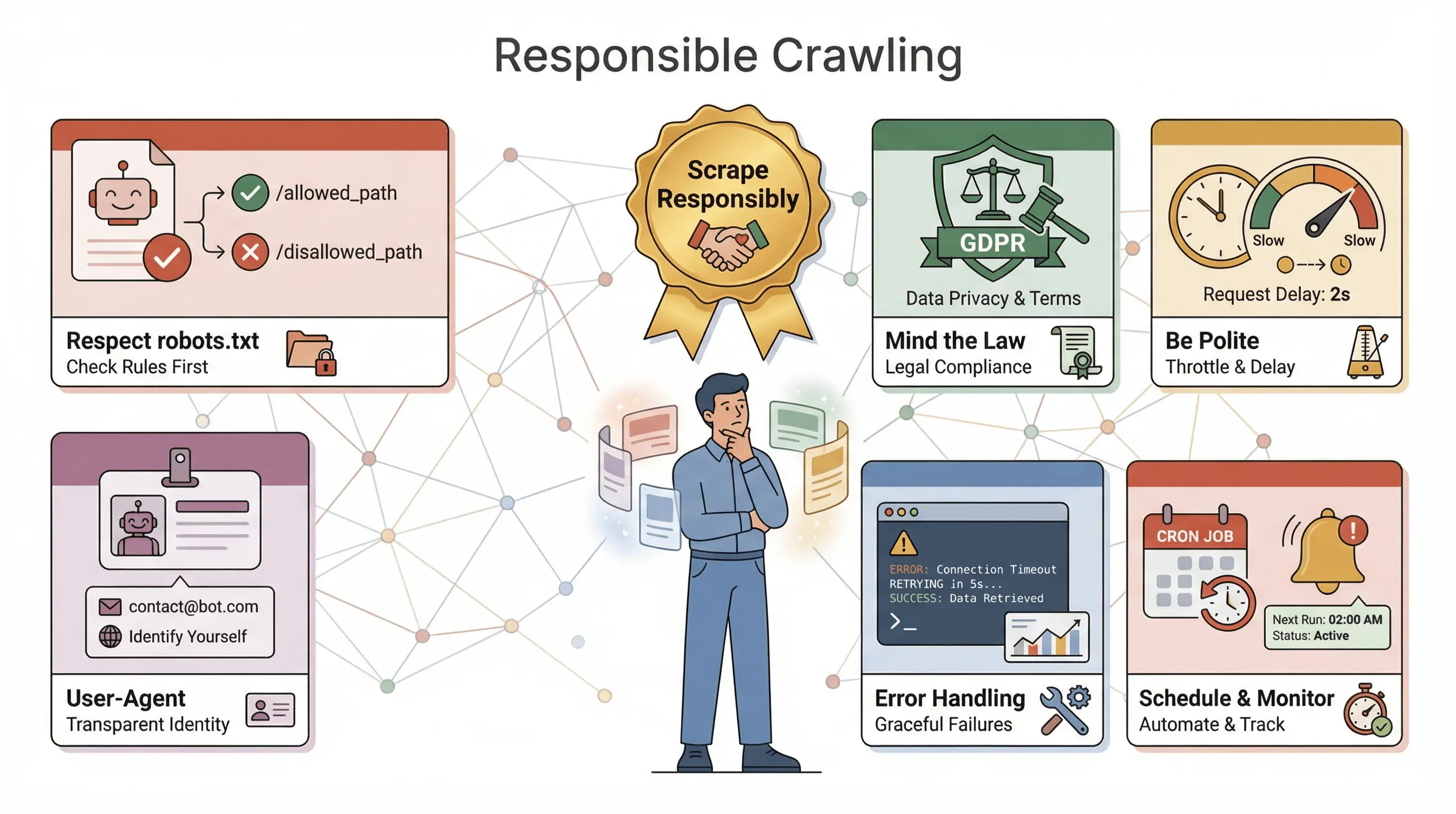 Antes de soltar seu crawler pelo mundo, alguns avisos importantes — e um pouco de sabedoria:
Antes de soltar seu crawler pelo mundo, alguns avisos importantes — e um pouco de sabedoria:
- Respeite o robots.txt: A maioria dos sites publica um arquivo
robots.txtdizendo o que os crawlers podem ou não fazer. Ignorar isso pode fazer você ser bloqueado — ou pior, se meter em problemas legais. Sempre verifique e siga essas regras (mais aqui). - Observe a lei: Alguns termos de uso proíbem scraping. E, se você estiver coletando dados pessoais, leis de privacidade como GDPR e CCPA podem se aplicar (dataprixa.com). Na dúvida, fique com dados públicos e não sensíveis.
- Seja educado: Não bombardeie os sites com requisições — reduza a taxa do crawler, varie atrasos e evite fazer scraping em horários de pico.
- Identifique-se: Use uma string personalizada de User-Agent e considere incluir contato caso esteja fazendo scraping em grande escala.
- Trate erros e registre logs: Espere que os sites mudem, as páginas quebrem e os dados venham confusos. Implemente tratamento de erro, logging e monitoramento para corrigir problemas rapidamente.
- Agende e monitore: Para crawls recorrentes, use ferramentas de agendamento (como cron ou o scheduler integrado do Thunderbit) e configure alertas se o crawler começar a falhar ou a coletar zero dados.
A regra de ouro: faça scraping com responsabilidade. A web é um recurso compartilhado — não seja “aquele bot” que estraga tudo para os outros.
Dicas avançadas: escalando e aprimorando seu Website Crawler em Python
Depois de dominar o básico, talvez você queira dar um upgrade no seu crawler. Aqui vão alguns movimentos avançados:
- Lidar com JavaScript: Use Selenium ou Playwright para extrair dados de sites que carregam conteúdo dinamicamente.
- Escalar: Para projetos grandes, migre para Scrapy ou use bibliotecas assíncronas (como
aiohttp) para requisições concorrentes. - Usar proxies: Alterne endereços IP para evitar bloqueios em crawls de alto volume.
- Automatizar pipelines de dados: Escreva direto em bancos de dados ou integre com armazenamento em nuvem para grandes conjuntos de dados.
- Monitorar e alertar: Configure logging, verificações de saúde e notificações para crawlers de longa duração.
Se o seu crawler se tornar crítico para o negócio, considere usar serviços gerenciados ou APIs para tirar o peso do trabalho pesado. E, se você estiver extraindo dados de vários sites com layouts diferentes, modularize o código para facilitar a atualização dos parsers.
Conclusão e principais aprendizados
O que é Data Scraping e como fazer em 2025 Get Started Free
Criar um website crawler em Python é uma das habilidades mais poderosas que você pode aprender no mundo orientado por dados de hoje. Veja o que cobrimos:
- Website crawlers automatizam o processo de visitar páginas e extrair dados da web — algo essencial para automação de negócios, pesquisa e inteligência competitiva.
- Python é a melhor escolha para criar crawlers, graças à sintaxe simples, às bibliotecas poderosas e à comunidade gigantesca.
- Os métodos de parsing importam: use regex para soluções rápidas, BeautifulSoup para a maioria dos scripts e Scrapy para trabalhos maiores.
- Passo a passo, você pode sair de buscar uma página para rastrear um site inteiro e salvar dados estruturados — sem precisar de doutorado.
- Thunderbit vai além, permitindo fazer scraping com IA, sem código e com exportação instantânea — perfeito para usuários de negócio ou para quem quer resultado rápido.
- Crawling responsável é fundamental: respeite as regras dos sites, trate erros e coloque a ética em primeiro lugar.
- Escalar é possível com as ferramentas certas — seja Selenium para JavaScript, Scrapy para concorrência ou Thunderbit para automação sem código.
A melhor forma de aprender é começar pequeno — escreva um script, teste o Thunderbit e veja quais dados você consegue desbloquear. A web está cheia de oportunidades (ou de um banquete de dados, se você for faminto como eu).
Quer ir mais fundo? Confira estes recursos:
- O que é Data Scraping e como fazer em 2025
- Como extrair dados de sites para o Excel usando IA
- Blog da Thunderbit para mais dicas, guias e técnicas avançadas.
Boas extrações — e que seus scrapers sejam rápidos, seus dados limpos e seu café nunca acabe.
Experimente o Thunderbit AI Web Scraper agora
FAQs
1. Qual é a diferença entre um website crawler e um web scraper?
Um crawler visita e descobre páginas de forma sistemática (como mapear um site), enquanto um scraper extrai dados específicos dessas páginas. Na prática, a maioria dos projetos usa os dois: o crawl encontra as páginas e o scraping coleta os dados.
2. Por que Python é tão popular para criar website crawlers?
Python é fácil de aprender, tem bibliotecas poderosas (como Requests, BeautifulSoup, Scrapy e Selenium) e uma comunidade enorme. Quase 70% dos projetos de web scraping usam Python, o que o torna o padrão do setor.
3. Quando devo usar regex, BeautifulSoup ou Scrapy para parsing?
Use regex para padrões simples e previsíveis. BeautifulSoup é a melhor opção para a maioria dos scripts — fácil e flexível. Scrapy é ideal para crawlers grandes ou de produção que precisam de velocidade, concorrência e recursos robustos.
4. Como o Thunderbit se compara a programar um crawler em Python?
O Thunderbit permite fazer scraping com IA e sem código — basta clicar, selecionar os campos e exportar. É perfeito para usuários de negócio ou tarefas rápidas. Python dá mais controle e personalização, mas exige programação e manutenção.
5. Quais questões legais ou éticas devo observar ao fazer crawling de sites?
Sempre verifique e respeite o robots.txt, siga os termos de uso do site, evite coletar dados sensíveis ou pessoais sem consentimento e limite suas requisições para não sobrecarregar os servidores. Scraping responsável ajuda a manter a web aberta para todos.
Pronto para testar você mesmo? Baixe o Thunderbit ou abra seu editor Python favorito e comece a rastrear. Os dados estão por aí — vá buscá-los!
Experimente o AI Web Scraper Get Started Free
Saiba mais




