O YouTube tem mais de e . Também é uma das plataformas mais difíceis de extrair dados sem esbarrar numa parede de CAPTCHAs, erros 429 ou bloqueios diretos de IP.
Se você já tentou puxar dados de canais, comentários ou transcrições em qualquer escala, conhece bem a frustração. Você consegue alguns milhares de resultados e, depois, o YouTube fecha a porta. Passei bastante tempo analisando como diferentes abordagens de scraping se comportam perante as defesas anti-robô do YouTube, que estão sempre a evoluir, e a diferença entre ferramentas que funcionam de forma fiável e ferramentas que são bloqueadas em minutos é enorme.
Este guia apresenta os 6 melhores scrapers do YouTube para 2026 — ferramentas pensadas mesmo para lidar com a hostilidade do YouTube sem queimar o seu IP nem travar o seu fluxo de trabalho. Quer seja um profissional de marketing a acompanhar canais concorrentes, uma equipa de vendas à procura de contactos de criadores ou um developer a montar um pipeline de dados, há aqui uma opção que faz sentido.
O que o YouTube realmente bloqueia em 2026 (e por que a maioria dos scrapers falha)
As defesas anti-robô do YouTube não são uma barreira única — são um sistema em camadas. Perceber contra o que está a lutar é o primeiro passo para não ser bloqueado.
Veja o que o YouTube faz em 2026 para detetar e travar acessos automatizados:

- Verificações de reputação e velocidade de IP: pedidos repetidos a partir de IPs de datacenter, VPNs ou proxies partilhados são assinalados rapidamente. Vai ver erros 403, limites de taxa 429 ou ecrãs a pedir “faça login para confirmar que não é um robô”.
- Impressão digital do navegador e do JavaScript: o YouTube verifica se o cliente se comporta como um navegador real — executando scripts, renderizando elementos e mantendo o estado esperado. Navegadores headless e clientes HTTP puros costumam falhar nestas verificações sem aviso (só recebe dados vazios ou incompletos).
- Confiança em cookies e sessão: se os pedidos não vierem de uma sessão de navegador reconhecida e de longa duração, o YouTube aumenta a verificação. Sessões com login e histórico de navegação recebem mais confiança do que sessões novas e anónimas.
- Análise comportamental: intervalos de pedido uniformes, scroll rápido demais ou padrões repetidos de página disparam o throttling. O YouTube procura navegação que nenhum humano faria.
- Portas de CAPTCHA: quando o risco é alto, o YouTube força a verificação humana — especialmente em resultados de pesquisa e secções de comentários.
- Aplicação de quotas da API: a API oficial do YouTube Data aplica quotas diárias ao nível do projeto (10.000 unidades/dia por defeito), e fluxos intensivos em pesquisa consomem isso em minutos.
A experiência típica: começa a extrair dados, obtém algumas centenas de resultados e depois encontra o Erro 429, uma parede de CAPTCHA ou dados degradados sem aviso. Scrapers na nuvem a correr a partir de IPs de datacenter são especialmente vulneráveis.
This paragraph contains content that cannot be parsed and has been skipped.
A conclusão: ferramentas que operam dentro de uma sessão real de navegador (como o Thunderbit) contornam naturalmente muitas destas verificações, porque o pedido parece idêntico ao de uma pessoa a navegar no YouTube. Scrapers apenas na nuvem precisam de rotação de proxy, resolução de CAPTCHA e ritmo cuidadoso para sobreviver.
API do YouTube vs. melhores scrapers do YouTube: um framework prático de decisão
A API YouTube Data v3 é a forma “oficial” de aceder a dados do YouTube de maneira programática. É fiável para metadados básicos em baixo volume — mas o modelo de quotas torna-a pouco prática para a maioria dos fluxos reais de inteligência competitiva e pesquisa.
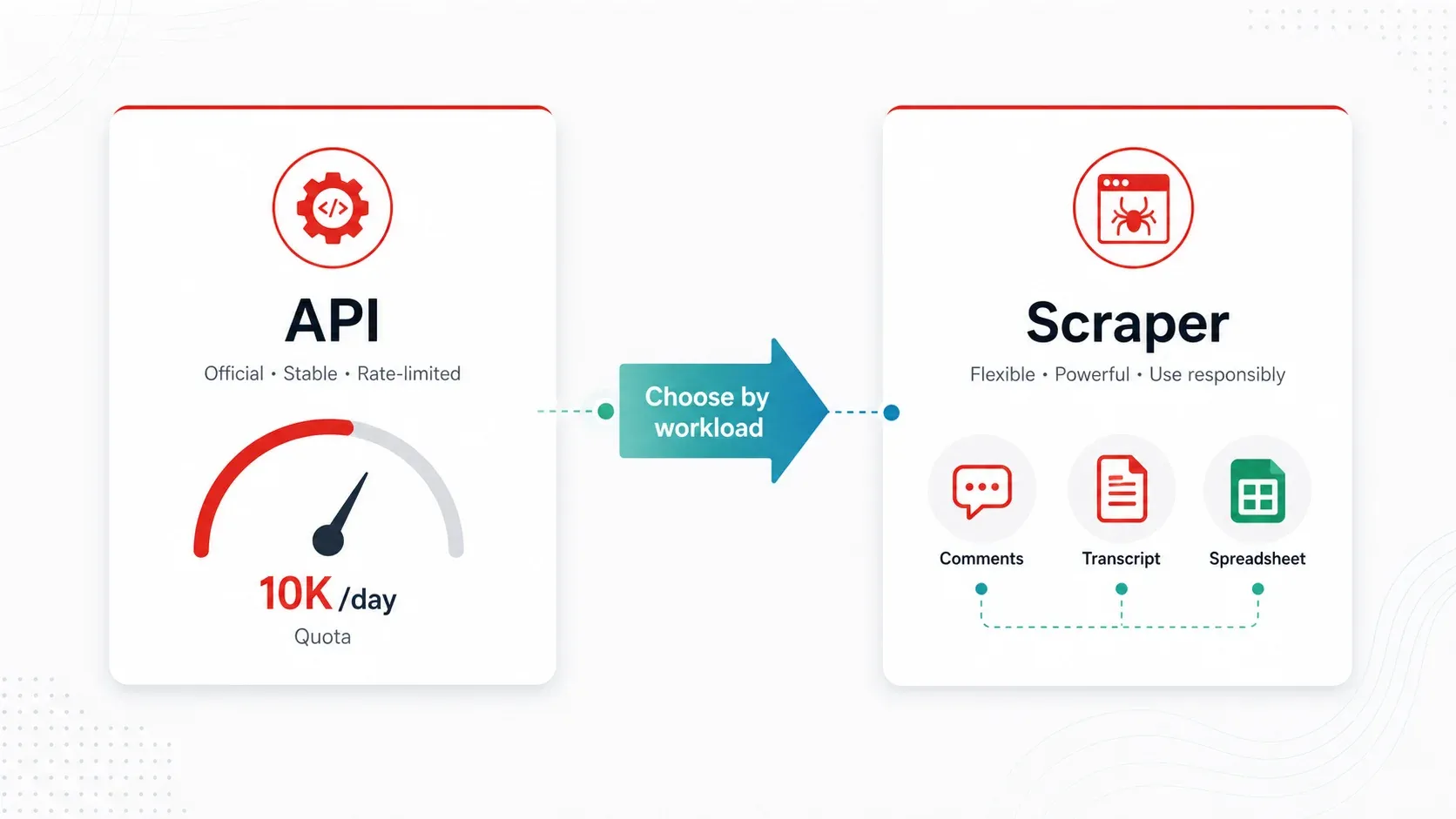
Fazendo as contas: cada projeto da API recebe . Custos dos principais endpoints:
search.list= 100 unidades por página (máximo de 50 resultados por página)videos.list= 1 unidade por chamada (até 50 IDs de vídeo por chamada)commentThreads.list= 1 unidade por chamada (até 100 threads por chamada)
Ou seja, se fizer 100 pesquisas por palavras-chave por dia, já terá gasto toda a sua quota diária antes de enriquecer sequer um vídeo. Um fluxo pesado em comentários é mais barato por chamada, mas a paginação real, os comentários desativados e a expansão de respostas consomem capacidade depressa.
Quando a API basta:
- Precisa de menos de 100 vídeos/dia e apenas de metadados públicos (título, visualizações, gostos, duração)
- Um developer pode configurar OAuth e gerir a quota
Quando um scraper é melhor:
- Precisa de comentários em escala (a API funciona, mas o atrito da quota é real)
- Precisa de transcrições/legendas em texto (a API não expõe facilmente o texto das legendas para uso em massa)
- Monitora 100+ canais regularmente (a quota esgota-se, o agendamento é manual)
- Precisa de dados enriquecidos ou rotulados (categorização, tradução ou deteção de campos com IA)
- É um utilizador não técnico que só quer uma folha de cálculo
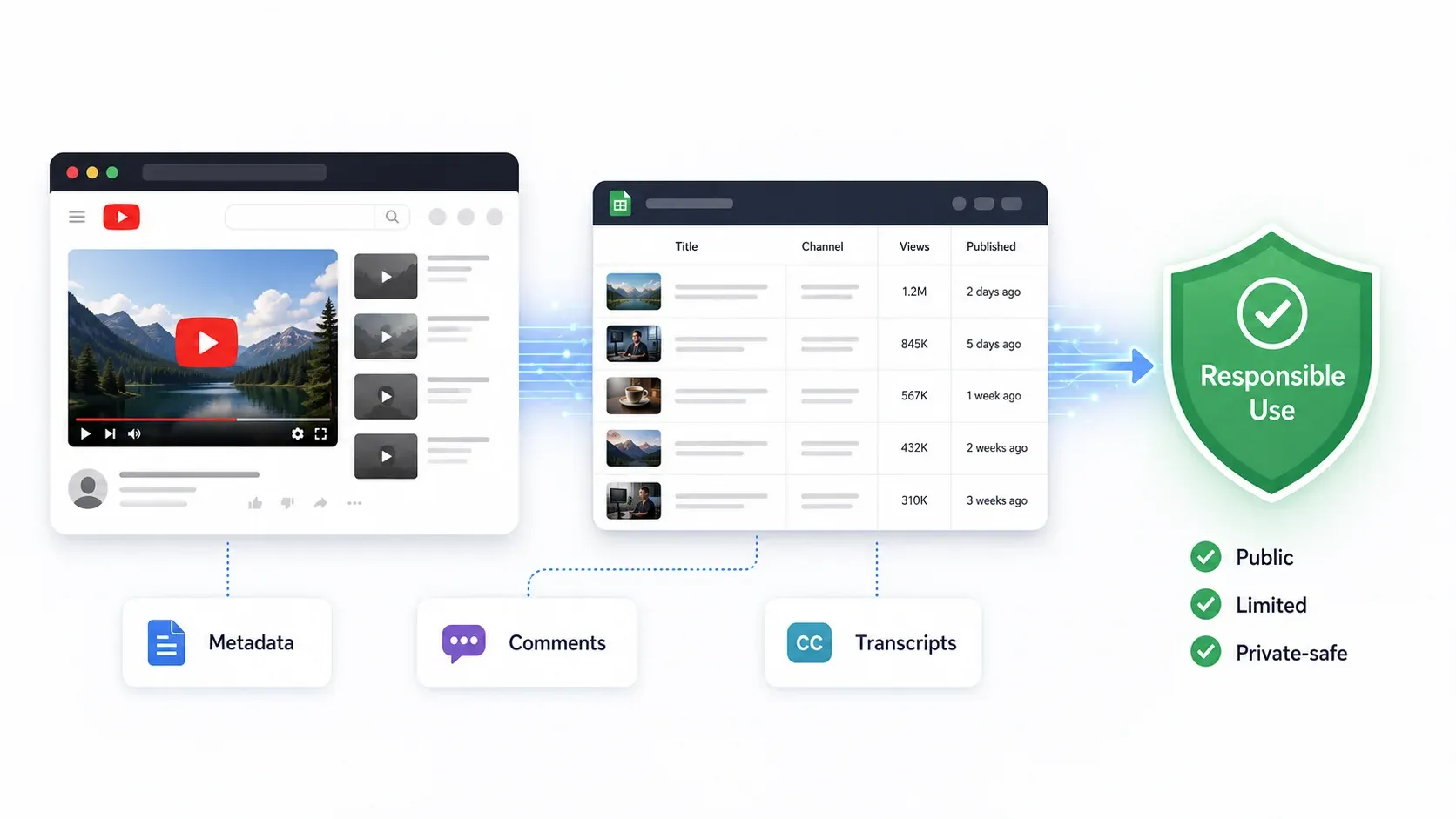
A API também não expõe tudo o que vê na web: dados da vitrine de Shorts, e-mails públicos nas descrições de canais, publicações da comunidade e alguns metadados de canal só ficam acessíveis via scraping das páginas reais do YouTube.
Para a maioria dos utilizadores empresariais que fazem pesquisa competitiva, prospeção de criadores ou estratégia de conteúdo, uma ferramenta de scraping é mais prática do que a API.
Como escolhemos os 6 melhores scrapers do YouTube
Cada ferramenta desta lista foi avaliada com os mesmos critérios — com peso no que realmente interessa quando o YouTube está ativamente a tentar bloqueá-lo:
This paragraph contains content that cannot be parsed and has been skipped.
Todas as ferramentas foram avaliadas com base nos padrões atuais de bloqueio do YouTube que os utilizadores encontram em 2026.
1. Thunderbit
é uma extensão Chrome com IA que transforma páginas do YouTube em dados estruturados em cerca de dois cliques. Em vez de correr num servidor na nuvem (que o YouTube sinaliza facilmente), o Thunderbit funciona dentro da sua própria sessão de navegador — por isso, para o YouTube, parece que está simplesmente a navegar normalmente.
O fluxo principal para o YouTube é: instale a , abra uma página de canal, de resultados de pesquisa ou de vídeo do YouTube e clique em “AI Suggest Fields”. A IA lê a página e sugere colunas — título do vídeo, URL, visualizações, data de envio, descrição, URL da miniatura, texto do comentário, autor, gostos e muito mais. Revê, clica em “Scrape” e exporta diretamente para Google Sheets, Excel, Airtable, Notion, CSV ou JSON. Sem código, sem seletores, sem chaves de API.
Principais recursos para scraping do YouTube:
- Deteção de campos com IA: a IA do Thunderbit lê qualquer página do YouTube em que esteja e sugere colunas relevantes automaticamente. Não precisa de mapear manualmente seletores CSS ou XPaths.
- Scraping de subpáginas: extraia a lista de vídeos de um canal e depois abra cada página de vídeo para enriquecer com comentários, descrições, tags e transcrições (se visíveis).
- Scraping agendado: configure tarefas recorrentes para monitorizar canais semanalmente, sem intervenção manual.
- Modo de navegador: corre dentro da sua sessão autenticada, reduzindo a marcação de “IP de datacenter na nuvem” que aciona a maioria dos bloqueios do YouTube.
- Exportação gratuita: os dados vão para Google Sheets, Excel, Airtable ou Notion sem paywall na exportação.
Abordagem anti-bloqueio: scraping em sessão de navegador com a própria sessão autenticada do utilizador. O YouTube vê um navegador real, cookies reais e histórico real de sessão. Para tarefas de grande volume, lotes pequenos e agendados reduzem ainda mais o risco.
Preço: plano gratuito (6 páginas), bónus de teste (10 páginas). Os planos pagos são baseados em créditos. Consulte para valores atuais.
Melhor para: profissionais de marketing, equipas de vendas, estrategas de conteúdo e utilizadores de operações que querem pesquisa rápida de canais/pesquisa/comentários sem configuração técnica.
Como extrair dados do YouTube com Thunderbit (passo a passo)
- Instale a .
- Abra uma página de canal, resultados de pesquisa, playlist ou página de vídeo do YouTube.
- Clique em “AI Suggest Fields” — a IA lê a página e sugere colunas (título, URL, visualizações, data, descrição, miniatura etc.).
- Revise e ajuste os campos sugeridos, se necessário.
- Clique em “Scrape” — os dados são extraídos para uma tabela estruturada.
- Exporte para Google Sheets, Excel, Airtable, Notion, CSV ou JSON.
Para extração mais profunda (por exemplo, puxar comentários de cada vídeo de um canal), use o scraping de subpáginas: primeiro extraia a lista de vídeos e depois deixe o Thunderbit visitar cada página de vídeo e extrair comentários, descrições ou a disponibilidade da transcrição.
O processo inteiro leva menos de dois minutos para uma tarefa típica de pesquisa de canal. Sem chaves de API, sem configuração de proxy, sem código.
2. Apify
Apify é uma plataforma de scraping na nuvem com “Actors” pré-construídos para o YouTube — scrapers especializados para vídeos, comentários, canais, Shorts e transcrições. Foi pensada para developers que querem criar pipelines de dados automatizados, em vez de fazer pesquisas pontuais.
O ecossistema do YouTube no Apify inclui Actors separados para tarefas diferentes. Um Actor bem mantido, intitulado “YouTube Scraper — Videos, Comments & Transcripts”, aceita canais, playlists, pesquisas e URLs diretas de vídeos. Tem suporte para filtro de Shorts, extração de comentários e transcrições com timestamps.
Principais recursos:
- Actors separados para vídeos, comentários, canais, Shorts e transcrições
- Aceita termos de pesquisa, URLs de canais e IDs de playlists como entrada
- Agendamento na nuvem e integrações com webhooks
- Exportação para JSON, CSV, Excel ou envio para bases de dados via API
- Controlo de taxa ao nível do Actor e rotação de proxy
Abordagem anti-bloqueio: ritmo específico por Actor, infraestrutura de proxy do Apify e acesso à API interna do YouTube (Innertube) quando aplicável. Cada Actor implementa a sua própria lógica de retry e limitação de taxa.
Preço: o Actor citado “YouTube Scraper” lista aproximadamente US$ 15 por 1.000 vídeos, US$ 8 por 1.000 comentários e US$ 5 por transcrição. Os planos da plataforma começam em US$ 49/mês.
Desvantagens: os custos de utilização sobem depressa em tarefas grandes. A interface é orientada para developers — utilizadores não técnicos podem achá-la complexa. Os esquemas de saída variam entre Actors, por isso muitas vezes é preciso limpar os dados. A qualidade dos Actors varia bastante no marketplace.
Melhor para: developers a montar pipelines de dados automatizados, equipas que precisam de extração agendada para APIs ou bases de dados e equipas de operações de marketing a executar fluxos recorrentes de sentimento em comentários.
3. Bright Data
Bright Data é uma plataforma de infraestrutura de dados empresarial com a maior rede de proxies residenciais do setor e scrapers dedicados para o YouTube. Se precisa de extrair dados do YouTube em escala massiva e entre regiões, esta é a artilharia pesada.
A Bright Data oferece vários scrapers de YouTube (perfis de canais, vídeos, comentários) além de conjuntos de dados do YouTube prontos a comprar. O serviço de scraping gerido significa que eles constroem e mantêm o scraper por si.
Principais recursos:
- Mais de 150 milhões de IPs residenciais em 195 países
- Scrapers específicos para YouTube, para canais, vídeos e comentários
- Renderização completa do navegador e resolução de CAPTCHA
- Scraping com segmentação geográfica (compare resultados do YouTube entre países)
- Opção de serviço gerido (eles tratam da manutenção)
- Processamento em lote de até 5 mil URLs por pedido
Abordagem anti-bloqueio: enorme pool de proxies residenciais, rotação automatizada de IP, emulação de impressão digital do navegador e resolução integrada de CAPTCHA. Esta é a infraestrutura anti-bloqueio mais forte da lista.
Preço: teste grátis (1 mil pedidos por uma semana), pay-as-you-go a US$ 3,50 por 1 mil registos, plano Scale a US$ 499/mês com 384.000 registos incluídos e US$ 2,30 por 1 mil adicionais.
Desvantagens: exagerado para projetos pequenos. Preços complexos (largura de banda + pedidos + IPs podem gerar “choque de faturação” se os limites não forem definidos). A plataforma exige mais configuração do que uma extensão Chrome.
Melhor para: grandes empresas, agências a monitorizar centenas de canais e equipas que precisam de dados do YouTube específicos por região em escala empresarial.
4. Octoparse
Octoparse é uma ferramenta de scraping para desktop e nuvem com interface visual de apontar e clicar. Cria fluxos de extração do YouTube clicando nos elementos da página — sem código, mas com mais personalização do que uma extensão simples.
O Octoparse tem modelos pré-construídos para o YouTube, incluindo um YouTube Comments & Replies Scraper atualizado em abril de 2026. Extrai nomes de utilizador, texto do comentário, gostos, hora de publicação e threads de resposta a partir de URLs de vídeo.
Principais recursos:
- Criador de fluxos visuais sem código — clique nos elementos para definir a lógica do scraping
- Modelos pré-construídos do YouTube para comentários, resultados de pesquisa e metadados de vídeo
- Agendamento na nuvem com rotação automática de proxy
- Exportação para Excel, CSV, JSON e ligações a base de dados
- Rotação de IP integrada e anti-deteção nos planos na nuvem
Abordagem anti-bloqueio: execução na nuvem com rotação de IP integrada e medidas anti-deteção. Os modelos lidam com scroll infinito e carregamento dinâmico nas páginas normais do YouTube.
Preço: o modelo de comentários do YouTube está listado a US$ 0,20 por 1.000 linhas. Os planos da plataforma começam em cerca de US$ 75/mês (Standard, faturado anualmente), com servidores na nuvem, agendamento e opções de proxy.
Desvantagens: páginas complexas do YouTube (scroll infinito, comentários carregados preguiçosamente, separadores de Shorts) podem exigir ajuste de tempos de espera e comportamento de scroll. A extração de transcrições/legendas é limitada em comparação com o yt-dlp ou atores dedicados de transcrição. Curva de aprendizagem para fluxos avançados.
Melhor para: analistas de marketing e investigadores de negócio que preferem ferramentas visuais de fluxo de trabalho, mas precisam de mais personalização do que uma extensão Chrome.
5. YT-DLP
YT-DLP (disponível no GitHub) é uma ferramenta de linha de comandos de código aberto que extrai metadados de vídeos, legendas, transcrições e muito mais do YouTube (e de mais de 1.000 outros sites). É o canivete suíço para utilizadores técnicos que querem controlo máximo e custo de subscrição zero.
Para trabalhos no estilo scraping, o yt-dlp pode extrair metadados sem descarregar ficheiros de vídeo usando flags como --skip-download, --write-info-json, --dump-json e --flat-playlist. Distingue legendas geradas automaticamente das escritas por humanos — uma distinção que a maioria das outras ferramentas não faz.
Principais recursos:
- Extrai metadados do vídeo (título, visualizações, gostos, data de envio, descrição, tags) sem descarregar o vídeo
- Descarrega playlists e canais completos em massa
- Acesso a legendas/transcrições (geradas automaticamente E escritas por humanos, separadamente)
- Processamento em lote com modelos de saída personalizados
- Suporte a cookies/autenticação para acesso baseado em sessão
- Totalmente gratuito, com comunidade open source ativa
Abordagem anti-bloqueio: cookies do utilizador para autenticação (--cookies-from-browser), definições ajustáveis de throttle e atualizações do extrator mantidas pela comunidade, que se adaptam às mudanças do YouTube.
Preço: gratuito.
Desvantagens: exige familiaridade com linha de comandos. Não tem interface visual. Parte quando o YouTube muda (a comunidade corrige rapidamente, mas ainda assim tem de atualizar e depurar). Não há agendamento nativo nem exportação para folhas de cálculo — tem de montar o seu próprio pipeline.
Melhor para: developers, cientistas de dados e equipas técnicas que precisam de controlo máximo sobre metadados e extração de transcrições e não se importam com comandos de terminal.
6. Phantombuster
Phantombuster é uma plataforma de automação na nuvem com “Phantoms” específicos para YouTube, pensados mais para growth marketing e geração de leads do que para armazenamento puro de dados. É a escolha quando o seu objetivo é encontrar contactos de criadores e montar listas de prospeção.
O YouTube Channel Video Extractor do Phantombuster recolhe informações do canal, listas de vídeos e e-mails públicos das descrições dos canais. A documentação oficial de limite de taxa informa que o YouTube Channel Video Extractor suporta até 100 vídeos por execução e avisa que atividade incomum ainda pode acionar restrições do YouTube.
Principais recursos:
- Scraper de canal do YouTube (contagem de subscritores, lista de vídeos, informações do canal, e-mails públicos)
- Extração de vídeos e comentários para análise competitiva
- Integração com CRM e ferramentas de outreach
- Agendamento e automação de fluxos de trabalho
- Teste grátis de 14 dias, plano Start a US$ 56/mês (cobrado anualmente, 20h/mês de execução)
Abordagem anti-bloqueio: atrasos incorporados entre ações, sessões de navegador do Phantom, execução na nuvem com automação em ritmo controlado. Foi pensado para fluxos seguros e cadenciados, e não para extração em massa de alta velocidade.
Preço: plano Start a US$ 56/mês (anual), Grow a US$ 128/mês, Scale a US$ 352/mês. O custo por 1.000 resultados varia consoante o tempo de execução, e não por preço por registo.
Desvantagens: mais lento do que ferramentas focadas em pipeline. O preço é baseado em horas de execução e créditos, não num custo limpo por linha. Suporte limitado a transcrições/legendas. O limite de 100 vídeos por execução significa que canais grandes exigem várias rondas.
Melhor para: profissionais de growth marketing a fazer pesquisa de influenciadores, equipas de vendas a extrair informações de contacto de criadores e agências a monitorizar a atividade de concorrentes no YouTube.
Todo o tipo de dado que pode extrair do YouTube (matriz por ferramenta)
Ferramentas diferentes suportam tipos diferentes de dados do YouTube. Antes de se comprometer com uma ferramenta, precisa de saber exatamente o que vai obter. Veja a divisão:
This paragraph contains content that cannot be parsed and has been skipped.
Dados mais valiosos por caso de uso de negócio:
- Comentários → análise de sentimento, mineração de objeções, reclamações sobre concorrentes, pesquisa de audiência
- Transcrições → pipelines de LLM/RAG, análise da mensagem de concorrentes, reaproveitamento de conteúdo
- Metadados do canal → prospeção de criadores, acompanhamento de concorrentes, prospeção de vendas/influenciadores
- Metadados do vídeo → estratégia de conteúdo, análise de títulos/miniaturas, cadência de publicação, ideação de SEO
- E-mails públicos → outreach para criadores (use com responsabilidade e em conformidade com regras de e-mail/privacidade)
Melhores scrapers do YouTube comparados: tabela lado a lado
This paragraph contains content that cannot be parsed and has been skipped.
Vencedores por categoria:
- Melhor para utilizadores não técnicos: Thunderbit
- Melhor para pipelines de developer: Apify
- Melhor para escala empresarial: Bright Data
- Melhor construtor visual: Octoparse
- Melhor opção técnica gratuita: YT-DLP
- Melhor fluxo de trabalho para growth marketing: Phantombuster
Scrapers do YouTube gratuitos vs. pagos: quando as ferramentas grátis bastam
Ferramentas gratuitas funcionam quando a tarefa é limitada, pouco frequente e quando está confortável com manutenção técnica. Veja quando ficar no gratuito e quando vale a pena investir:
This paragraph contains content that cannot be parsed and has been skipped.
A verdade nua e crua: ferramentas gratuitas como o YT-DLP são poderosas, mas exigem manutenção técnica contínua. Mudanças no layout do YouTube, expiração de cookies, ajustes de throttle e formatação de saída precisam todos de atenção manual. Um script que parte de duas em duas semanas pode custar mais em horas de engenharia do que uma subscrição paga de scraper.
Ferramentas com IA como o Thunderbit leem as páginas de novo a cada execução e adaptam-se automaticamente às mudanças de layout. Esse custo oculto de manutenção é o que justifica ferramentas pagas para a maioria das equipas de negócio.
Como realmente ficam os dados extraídos do YouTube (amostras reais de saída)
Uma das maiores falhas nas análises de scrapers é que ninguém mostra o que realmente vai receber. Aqui estão exemplos realistas de saída extraída do YouTube:
Exemplo 1: metadados de canal
This paragraph contains content that cannot be parsed and has been skipped.
Exemplo 2: exportação de comentários
This paragraph contains content that cannot be parsed and has been skipped.
Exemplo 3: extração de transcrição
100:00:00.000 - 00:00:04.200 Hoje estamos a comparar seis fluxos de scraping do YouTube para profissionais de marketing.
200:00:04.200 - 00:00:09.800 A principal diferença é se precisa de metadados, comentários ou transcrições.
300:00:09.800 - 00:00:15.300 Para utilizadores não técnicos, um scraper baseado em navegador costuma ser mais fácil de manter.Problemas comuns de limpeza que pode esperar:
- Contagens de visualizações podem incluir sufixos localizados (K, M) ou rótulos noutra língua
- Datas de envio às vezes aparecem de forma relativa (“há 3 anos”) em vez de datas ISO
- Comentários podem vir ordenados por Destaques em vez de Recentes por defeito
- Respostas ocultas e comentários carregados preguiçosamente exigem scroll ou paginação
- Campos de e-mail público podem ficar escondidos atrás de interação ou restrições da conta
- Transcrições podem não estar disponíveis, ser geradas automaticamente ou estar numa língua inesperada
No caso do Thunderbit, o fluxo é: AI Suggest Fields → Scrape → Export to Google Sheets. A IA trata da deteção de campos, por isso não precisa de definir manualmente como “visualizações” ou “data de envio” aparecem na página.
É legal extrair dados do YouTube em 2026?
A versão curta: extrair dados públicos disponíveis no YouTube geralmente traz menos risco do que aceder a dados privados, mas isso não significa liberdade total.
Os do YouTube proíbem explicitamente o acesso automatizado, exceto por mecanismos de busca públicos que sigam robots.txt ou com autorização prévia por escrito do YouTube. Ainda assim, a aplicação contra pesquisas comerciais legítimas é rara — o YouTube foca-se sobretudo em abuso em grande escala, pirataria de conteúdo e violações de privacidade.
O precedente jurídico nos EUA traz alguma clareza. A decisão do Nono Circuito no caso concluiu que havia dúvidas sérias sobre se a extração de dados públicos viola o CFAA. A que extrair dados de sites públicos não é crime. Mas os termos de utilização da plataforma, direitos de autor, privacidade e leis antispam continuam a aplicar-se.
Diretrizes práticas:
- Recolha apenas dados públicos a que a sua conta tem permissão para aceder
- Não faça scraping de dados pessoais em escala desnecessária
- Não contorne controlos de acesso nem paywalls
- Respeite direitos de autor — não republique transcrições ou conteúdo de vídeo na íntegra
- Limite a taxa das tarefas e evite sobrecarregar os servidores do YouTube
- Para outreach, cumpra CAN-SPAM, GDPR e regras locais
- Consulte um profissional jurídico em casos de uso de alto risco
As ferramentas desta lista incluem limitação de taxa e ritmo respeitoso por design. Isso não é só boa ética — é o que mantém o seu scraping a funcionar no longo prazo.
Qual scraper do YouTube deve escolher?
Aqui vai um guia rápido de decisão:
- Thunderbit → Melhor para utilizadores não técnicos que querem scraping rápido e resistente a bloqueios do YouTube para folhas de cálculo. Comece por aqui se é profissional de marketing, vendas ou estratega de conteúdo.
- Apify → Melhor para developers que constroem pipelines automatizados com tarefas agendadas, webhooks e entrega via API.
- Bright Data → Melhor para extração em escala empresarial, entre regiões, com infraestrutura gerida anti-bloqueio.
- Octoparse → Melhor para analistas que querem construção visual de fluxos com mais personalização do que uma extensão Chrome.
- YT-DLP → Melhor opção gratuita para utilizadores técnicos que precisam de controlo máximo sobre metadados e transcrições.
- Phantombuster → Melhor para profissionais de growth marketing que fazem prospeção de criadores e geração de leads baseada no YouTube.
A chave para não ser bloqueado não é um truque secreto — é escolher uma ferramenta com anti-deteção inteligente incorporada. Scraping em sessão de navegador, rotação de proxy, ritmo controlado e lotes pequenos agendados reduzem o risco. Forçar milhares de pedidos a partir de um único IP na nuvem é o que o faz ser bloqueado.
Se quer ver como é o scraping moderno do YouTube sem código, experimente o plano gratuito do . Dois cliques para dados estruturados. E, se as suas necessidades forem mais técnicas ou em escala empresarial, as outras ferramentas desta lista também dão resposta. Para mais abordagens de web scraping, confira os nossos guias sobre e . Também pode ver tutoriais no .
Perguntas frequentes
Que dados dá para extrair de um canal do YouTube?
Os dados públicos extraíveis incluem títulos de vídeo, URLs, miniaturas, visualizações, gostos (quando visíveis), datas de envio, descrições, duração, comentários, respostas, nomes/handles dos comentadores, gostos em comentários, transcrições/legendas (geradas automaticamente e escritas por humanos), indicadores de Shorts, nome do canal, handle, número de subscritores, número de vídeos, visualizações totais, descrição, links e e-mails públicos, se visíveis na página do canal.
Quantos vídeos do YouTube posso extrair por dia sem ser bloqueado?
Não existe um número universal. Ferramentas baseadas em navegador como o Thunderbit têm menor risco para fluxos semelhantes aos humanos porque funcionam dentro de uma sessão real. O YouTube Channel Video Extractor do Phantombuster suporta até 100 vídeos por execução. Plataformas na nuvem com rotação de proxy podem lidar com milhares, desde que o ritmo seja adequado. Scripts brutos em servidores na nuvem, sem limitação de taxa, serão bloqueados rapidamente. A abordagem mais segura são lotes pequenos e agendados, em vez de uma execução gigantesca.
Posso extrair comentários do YouTube para análise de sentimento?
Sim. Thunderbit, Apify, Bright Data e Octoparse suportam extração em massa de comentários com autor, timestamp, gostos e contagem de respostas. Exporte para Google Sheets ou CSV para análise. O actor do YouTube no Apify suporta explicitamente um máximo configurável de comentários por vídeo para este caso de uso.
Existe algum scraper gratuito do YouTube que realmente funcione em 2026?
O YT-DLP é a melhor opção gratuita para utilizadores técnicos — especialmente para metadados e transcrições. O Thunderbit oferece um plano gratuito para utilizadores não técnicos (6 páginas, com bónus de teste para 10) que exporta diretamente para Google Sheets. Ambos funcionam, mas o YT-DLP exige competência com linha de comandos, enquanto o Thunderbit só precisa de um navegador.
Como os scrapers do YouTube evitam bloqueios?
Ferramentas diferentes usam abordagens diferentes: scraping em sessão de navegador (Thunderbit) usa o contexto autenticado do navegador do utilizador; rotação de proxies residenciais (Bright Data, Apify) distribui pedidos por milhões de IPs; autenticação por cookies (YT-DLP) mantém a confiança da sessão; atrasos e cadência incorporados (Phantombuster) evitam a deteção comportamental. A abordagem mais fiável combina contexto real do navegador com ritmo conservador e tarefas menores agendadas.
Saiba mais