A web está crescendo numa velocidade que faz até aquele café da manhã apressado parecer devagar — e olha que eu sou rápido pra comer. Em 2026, extrair dados da internet já não é mais coisa só de quem manja de tecnologia; virou o tempero secreto por trás de prospecção de vendas, monitoramento de preços no ecommerce, pesquisas de mercado e até análise de imóveis. Com , escolher a biblioteca certa pode ser o que separa horas de trabalho manual de uma planilha cheia de insights prontos pra ação — antes mesmo da concorrência terminar o almoço.
O mais bacana é que, em 2026, as bibliotecas de raspagem web aparecem de todo jeito: tem desde extensão de Chrome com IA e sem código até frameworks robustos pra quem é dev raiz. Seja você um vendedor querendo leads no Excel, um gestor de operações monitorando centenas de SKUs ou um programador Python criando um crawler sob medida, tem uma solução perfeita pra você. Depois de anos mexendo com SaaS e automação (e virando muita noite), reuni as 10 melhores bibliotecas de raspagem web que você precisa conhecer este ano — e ainda dou dicas pra escolher a que vai facilitar sua vida.
O que Faz uma Biblioteca de Raspagem Web Ser Top em 2026?
Antes de partir pra lista, vale entender o que realmente importa na hora de escolher uma biblioteca de raspagem web. Pela minha experiência, as melhores ferramentas de 2026 têm alguns pontos em comum:
- Facilidade de uso: Dá pra qualquer um usar e ter resultado em minutos ou precisa ser ninja em Python?
- Aguenta conteúdo dinâmico: Consegue extrair dados de sites modernos, cheios de JavaScript, ou trava se não for HTML puro?
- Compatibilidade com linguagens e plataformas: Funciona na sua linguagem favorita — Python, JavaScript, Java — ou até direto no navegador?
- Escalabilidade: Dá conta de centenas ou milhares de páginas sem engasgar?
- Integração e exportação: Permite exportar pra Excel, Google Sheets, Notion ou direto pro seu pipeline de dados?
- IA e automação: Em 2026, ferramentas com IA que entendem comandos em linguagem natural são um diferencial — principalmente pra quem não quer programar.
A real é que as equipes de negócios querem velocidade, precisão e o mínimo de configuração possível. Quanto menos tempo você perder arrumando raspador quebrado ou mexendo em código, mais rápido vai agir com os dados. E com IA e automação no navegador cada vez mais avançadas, até quem não é técnico consegue extrair dados que antes só um dev dava conta ().
Bora pra lista.
Top 10 Bibliotecas de Raspagem Web que Você Precisa Conhecer em 2026
- para raspagem web com IA e sem código direto no navegador
- para parsing de HTML e limpeza de dados em Python
- para crawling em larga escala e pipelines de dados
- para automação de navegador e extração de sites dinâmicos com JavaScript
- para parsing rápido de XML/HTML em Python
- para seleção de HTML no estilo jQuery em Python
- para HTTP, parsing de HTML e renderização de JS em Python
- para automação de formulários e tarefas simples de navegador em Python
- para automação headless do Chrome em Node.js
- para parsing robusto de HTML em Java
1. Thunderbit
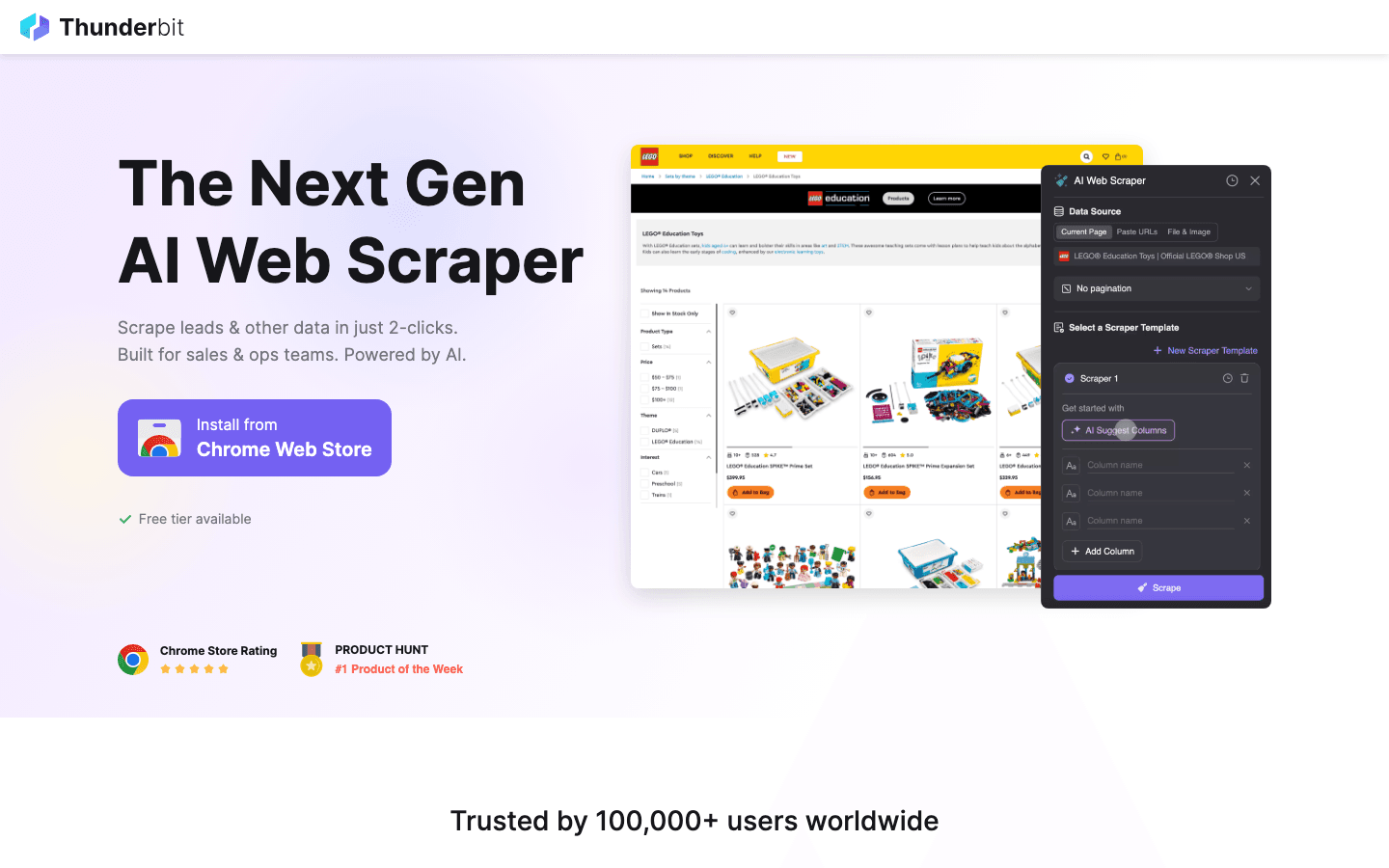
é minha principal dica pra quem quer extrair dados da web sem programar nada. Essa permite que você só descreva o que quer (“Pegue todos os nomes de produtos, preços e imagens desta página”) e a IA faz o resto. Sem template, sem configuração — só clicar em “Sugerir Campos com IA”, ajustar se quiser e começar a raspagem.
Por que o Thunderbit é destaque em 2026:
- Interface sem código e linguagem natural: Qualquer um pode usar — vendas, operações, marketing, imobiliário. Não precisa saber nada de Python.
- Sugerir Campos com IA: A IA lê a página e já sugere as melhores colunas pra extrair.
- Raspagem de subpáginas: Quer mais detalhes? O Thunderbit visita cada subpágina (tipo página de produto ou perfil) e já preenche sua tabela ().
- Templates prontos pra sites populares: Amazon, Zillow, Shopify e outros — extrai dados com um clique.
- Exportação pra Excel, Google Sheets, Notion, Airtable: Seus dados já vão direto pra onde sua equipe precisa.
- Suporte a 34 idiomas: Perfeito pra equipes globais.
- Raspagem na nuvem ou no navegador: Você escolhe o que encaixa melhor — nuvem é super rápida pra sites públicos, modo navegador resolve login.
O Thunderbit já é usado por mais de 30.000 pessoas no mundo todo, e o plano gratuito permite extrair dados de até 6 páginas (ou 10 com bônus de teste). Se você quer ver como é a raspagem web moderna, começa por aqui.
2. Beautiful Soup

é uma biblioteca clássica do Python, queridinha de cientistas de dados e analistas pela facilidade e eficiência pra lidar com HTML bagunçado. Se você já tentou extrair dados de uma página cheia de tag quebrada ou formatação esquisita, o Beautiful Soup é seu melhor amigo.
Destaques do Beautiful Soup:
- Lida com HTML irregular: Perfeito pra limpar e extrair dados de páginas “feias” ().
- Fácil de aprender: Até quem tá começando em Python pega rápido.
- Flexível: Funciona bem com Requests e pode ser combinado com lxml pra mais velocidade.
- Principais usos: Extração rápida de dados, limpeza de web data, integração com scripts pequenos.
Se você lida com páginas estáticas ou precisa organizar HTML confuso, o Beautiful Soup é uma ótima pedida.
3. Scrapy

é o peso-pesado do Python pra raspagem web. É um framework completo pra criar crawlers escaláveis e pipelines de dados. Se você precisa extrair dados de milhares de páginas, seguir links e processar grandes volumes, o Scrapy foi feito pra isso.
Por que o Scrapy é destaque:
- Altamente modular: Dá pra criar spiders, pipelines e middlewares complexos ().
- Ideal pra grandes projetos: Perfeito pra pesquisa de mercado, análise de concorrência ou qualquer tarefa que envolva muitos sites.
- Assíncrono e rápido: Feito pra velocidade e eficiência.
- Comunidade ativa: Tem muitos plugins, tutoriais e suporte.
O Scrapy tem uma curva de aprendizado, mas pra grandes volumes, é imbatível.
4. Selenium

é a principal ferramenta pra automação de navegadores. Usada tanto pra testar aplicações web quanto pra extrair dados de sites que exigem login, cliques ou pop-ups. Se você precisa interagir com sites dinâmicos e cheios de JavaScript, o Selenium simula um usuário de verdade ().
Pontos fortes do Selenium:
- Automatiza navegadores reais: Chrome, Firefox, Safari, Edge — você escolhe.
- Lida com logins, pop-ups e ações do usuário: Ótimo pra extrair dados depois de autenticação ou em fluxos multi-etapas.
- Suporte a várias linguagens: Python, Java, C# e mais.
- Melhor uso: Sites que bloqueiam raspadores simples ou quando precisa simular comportamento humano.
É mais pesado que bibliotecas baseadas em HTTP, mas às vezes só um navegador real resolve.
5. lxml
é um parser de XML e HTML super rápido pra Python. Se velocidade é prioridade (tipo processar milhares de documentos grandes), o lxml é imbatível ().
Por que o lxml é favorito:
- Extremamente rápido: Supera a maioria dos outros parsers Python, principalmente em arquivos grandes.
- Robusto: Lida com XML e HTML, integrando bem com outras ferramentas.
- Ótimo pra: Processar grandes volumes de dados, combinar com Beautiful Soup ou Scrapy pra mais potência.
Se você precisa de escala ou processar arquivos enormes, o lxml é indispensável.
6. PyQuery
traz o poder dos seletores do jQuery pro Python. Se você curte selecionar elementos com $('.classe') no jQuery, o PyQuery permite o mesmo nos seus scripts de raspagem ().
Destaques do PyQuery:
- Seletores no estilo jQuery: Intuitivo pra quem já mexeu com front-end.
- Código conciso e legível: Facilita seleções complexas.
- Integração com lxml: Rápido e eficiente por trás dos panos.
- Melhor uso: Projetos que pedem manipulação rápida de HTML no estilo jQuery em Python.
É uma ótima ponte pra quem vem do desenvolvimento web e quer extrair dados.
7. Requests-HTML
é uma biblioteca Python que junta a simplicidade do Requests (pra HTTP) com parsing de HTML e até renderização de JavaScript.
O que diferencia o Requests-HTML:
- Tudo em um só pacote: Busca páginas, faz parsing de HTML e até renderiza JavaScript.
- Fácil pra iniciantes: Perfeito pra projetos pequenos e médios.
- Ótimo pra: Scripts rápidos, sites com algum conteúdo dinâmico e quem busca simplicidade.
Se você tá começando ou precisa de uma ferramenta flexível pra tarefas menores, o Requests-HTML é uma ótima escolha.
8. MechanicalSoup

é uma biblioteca Python pra automação de formulários e interações simples no navegador. Baseada no Beautiful Soup e Requests, facilita logins, preenchimento de formulários e navegação básica ().
Por que o MechanicalSoup é útil:
- Automatiza formulários e logins: Ideal pra extrair dados atrás de autenticação.
- API simples: Fácil pra quem tá começando.
- Melhor uso: Tarefas repetitivas no navegador, fluxos simples e sites onde automação completa é exagero.
Não é tão poderoso quanto o Selenium pra sites complexos, mas é muito mais leve e fácil pra necessidades básicas.
9. Puppeteer
é uma biblioteca Node.js pra controlar o Chrome ou Chromium em modo headless. É a queridinha pra extrair dados de sites super interativos e cheios de JavaScript ().
Superpoderes do Puppeteer:
- Automação completa do navegador: Clica, rola, preenche formulários e interage como um usuário real.
- Lida com conteúdo dinâmico: Perfeito pra sites que carregam dados via JavaScript.
- Ótimo pra: Ecommerce, redes sociais ou qualquer site onde raspadores tradicionais falham.
Se você é dev JavaScript ou precisa extrair dados da “web moderna”, o Puppeteer é essencial.
10. Jsoup
é referência pra parsing de HTML em Java. É tipo o Beautiful Soup, mas pra quem desenvolve em Java ().
Por que equipes Java adoram o Jsoup:
- API simples e poderosa: Extrai e manipula dados com poucas linhas de código.
- Lida com HTML bagunçado: Limpa e faz parsing até de páginas mal formatadas.
- Melhor uso: Integrar raspagem em aplicações Java ou fluxos de backend.
Se seu stack é Java, o Jsoup é a escolha óbvia.
Tabela Comparativa das Bibliotecas de Raspagem Web
Veja um comparativo rápido das 10 bibliotecas:
| Biblioteca | Linguagem | Facilidade de Uso | Conteúdo Dinâmico | IA/Sem Código | Principais Usos | Melhor Para |
|---|---|---|---|---|---|---|
| Thunderbit | Ext. Chrome | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Sim | Vendas, operações, pesquisa, imóveis | Não programadores, equipes de negócios |
| Beautiful Soup | Python | ⭐⭐⭐⭐ | ⭐ | Não | Parsing HTML, limpeza de dados | Iniciantes em Python, analistas |
| Scrapy | Python | ⭐⭐⭐ | ⭐⭐ | Não | Crawling em larga escala, pipelines | Devs, projetos de big data |
| Selenium | Multi | ⭐⭐ | ⭐⭐⭐⭐⭐ | Não | Automação de navegador, logins | QA, extração de sites dinâmicos |
| lxml | Python | ⭐⭐⭐ | ⭐ | Não | Parsing rápido, arquivos grandes | Usuários avançados, grandes volumes |
| PyQuery | Python | ⭐⭐⭐⭐ | ⭐ | Não | Seleção estilo jQuery | Devs web, scripts concisos |
| Requests-HTML | Python | ⭐⭐⭐⭐ | ⭐⭐ | Não | Scripts rápidos, renderização JS | Iniciantes, projetos pequenos |
| MechanicalSoup | Python | ⭐⭐⭐⭐ | ⭐⭐ | Não | Automação de formulários, logins | Tarefas simples de navegador |
| Puppeteer | Node.js | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Não | Sites JS pesados, automação | Devs JS, raspagem web dinâmica |
| Jsoup | Java | ⭐⭐⭐⭐ | ⭐ | Não | Parsing HTML em Java | Equipes Java, fluxos de backend |
Como Escolher a Biblioteca de Raspagem Web Ideal pra Sua Empresa
Qual biblioteca usar? Aqui vão minhas dicas, baseadas em anos de tentativa, erro e algumas madrugadas de depuração:
- Não programadores ou equipes de negócios: Comece pelo Thunderbit. A abordagem sem código/IA entrega resultado em minutos. Se sua equipe só quer os dados no Excel ou Sheets, não complique.
- Devs Python: Beautiful Soup e Requests-HTML são ótimos pra tarefas pequenas. Scrapy é ideal pra projetos grandes. Combine com lxml ou PyQuery pra mais potência.
- Precisa lidar com login ou conteúdo dinâmico? Selenium (multi-linguagem) ou Puppeteer (Node.js) são as melhores opções.
- Equipes Java: Jsoup é a escolha certa pra integrar raspagem em apps Java.
- Precisa automatizar formulários ou fluxos simples? MechanicalSoup é leve e fácil de usar.
Fatores-chave pra considerar:
- Nível técnico: Ferramentas sem código como Thunderbit são perfeitas pra equipes não técnicas. Devs podem preferir a flexibilidade das bibliotecas com código.
- Complexidade dos dados: Pra páginas simples e estáticas, Beautiful Soup ou Jsoup são ótimos. Pra sites dinâmicos e cheios de JavaScript, vá de Selenium ou Puppeteer.
- Escala: Scrapy e lxml brilham em tarefas de grande volume e alta velocidade.
- Integração: O Thunderbit exporta direto pra Sheets, Notion e Airtable, economizando tempo nos fluxos de negócio.
Pra mais dicas sobre como escolher a ferramenta certa, dá uma olhada no .
Conclusão: Liberte o Poder dos Dados da Web com as Ferramentas Certas
Raspagem web em 2026 já não é mais só pra dev ou cientista de dados. Com a explosão de ferramentas sem código e com IA, qualquer equipe — de vendas a pesquisa — pode acessar o ouro dos dados online. A biblioteca certa pode economizar centenas de horas por ano (), aumentar a precisão e dar uma vantagem real pro seu negócio.
Minha dica? Pense no que você precisa — velocidade, escala, familiaridade técnica — e teste algumas opções. O é uma ótima porta de entrada, e bibliotecas open source como Beautiful Soup ou Scrapy estão sempre aí pra quem quer colocar a mão na massa.
Quer se aprofundar? Dá uma olhada no pra mais guias ou se inscreve no nosso pra tutoriais práticos.
Boas raspagens — e que seus dados estejam sempre limpos, organizados e prontos pra uso.
Perguntas Frequentes
1. Qual a biblioteca de raspagem web mais fácil pra quem não programa em 2026?
é a melhor opção pra quem não programa. A extensão de Chrome com IA permite extrair dados usando comandos em linguagem natural — sem precisar de código.
2. Qual biblioteca é melhor pra extrair dados de sites dinâmicos ou cheios de JavaScript?
(Node.js) e (multi-linguagem) são ideais pra sites dinâmicos renderizados por JavaScript. Eles automatizam navegadores reais e lidam com interações complexas.
3. Qual a diferença entre Beautiful Soup e Scrapy?
é ótimo pra extrair dados de páginas únicas ou projetos pequenos, especialmente com HTML bagunçado. é um framework completo pra criar crawlers escaláveis e processar grandes volumes de dados.
4. Posso exportar dados extraídos direto pro Google Sheets ou Notion?
Sim — permite exportação direta pra Google Sheets, Notion, Airtable e Excel. A maioria das bibliotecas exige que você crie a lógica de exportação manualmente.
5. Como escolher a biblioteca de raspagem web ideal pro meu negócio?
Considere seu nível técnico, a complexidade dos sites, o volume de dados e as necessidades de integração. Ferramentas sem código como Thunderbit são ideais pra equipes de negócios, enquanto devs podem preferir Scrapy, Beautiful Soup ou Puppeteer pra mais controle.
Saiba Mais