A internet está cheia de dados valiosos — mas a maior parte deles não foi feita para ser baixada facilmente. Em 2025, a raspagem web deixou de ser uma habilidade restrita e virou algo indispensável para quem acompanha preços, vagas, imóveis e concorrentes. O problema? O Github está lotado de projetos de raspagem. Alguns são bem feitos, outros são confusos, e muitos estão largados há anos. Como escolher o melhor — principalmente se você não é programador?
Neste artigo, vou te mostrar os 15 principais projetos de raspagem web no Github para 2025. Mas não vou só jogar uma lista: vou detalhar cada um em relação à facilidade de instalar, para que tipo de uso serve, se aguenta conteúdo dinâmico, frequência de atualização, opções de exportação de dados e para quem realmente é indicado. E se você já cansou de mexer com código, vou mostrar como ferramentas sem código e com IA, como o , estão mudando o jogo para profissionais de negócios e quem não é da área técnica.
Como Selecionamos os 15 Melhores Projetos de Raspagem Web no Github
Vamos falar a real: nem todo projeto do Github é igual. Alguns são testados por milhares de pessoas, outros são só experimentos de fim de semana que nunca foram pra frente. Para esta seleção, foquei em projetos que seguem estes critérios:
- Popularidade e Comunidade: Projetos com boa aceitação (de alguns milhares até mais de 90 mil estrelas) e colaboradores ativos.
- Atividade Recente: Ferramentas que continuam recebendo atualizações em 2025 — nada de projetos largados.
- Documentação e Facilidade de Uso: Documentação clara, exemplos de código e curva de aprendizado razoável.
- Uso no Mundo Real: Utilizados de verdade em empresas ou pesquisas, não só para demonstração.
E como a raspagem web não é igual para todo mundo, comparei cada projeto em relação a:
- Complexidade de Instalação e Configuração: Dá para começar rapidinho ou vai precisar instalar um monte de coisa e lidar com dependências?
- Adequação ao Caso de Uso: É feito para e-commerce, notícias, pesquisa ou outro segmento?
- Suporte a Páginas Dinâmicas: Aguenta sites modernos, cheios de JavaScript?
- Saúde do Projeto: Está sendo mantido ou o último commit já é quase uma relíquia?
- Opções de Exportação de Dados: Entrega dados prontos para uso ou só o HTML cru?
- Público-Alvo: É para quem está começando em Python, engenheiros de dados ou equipes não técnicas?
Cada projeto recebe tags rápidas para esses pontos, assim você pode focar no que faz sentido para o seu caso — seja você fera no código ou só quer seus dados direto no Google Sheets.

Complexidade de Instalação: Quão Fácil é Começar a Raspagem?
Vamos ser sinceros: para muita gente, o maior desafio é só conseguir rodar um raspador. Veja como classifiquei a complexidade de instalação:
- Plug & Play (Zero Configuração): Instale e use. Mínima configuração, ótimo para quem está começando.
- Médio (Linha de Comando, Pouco Código): Exige algum código ou uso do terminal, mas é tranquilo se você já escreveu scripts antes.
- Avançado (Drivers, Anti-bot, Código Pesado): Precisa configurar ambiente, instalar drivers de navegador ou ter domínio de Python/JS.
Veja onde cada projeto se encaixa:
- Plug & Play: MechanicalSoup (Python), Nokogiri (Ruby), Maxun (para usuários finais, depois de instalado)
- Médio: Scrapy, Crawlee, Node Crawler, Selenium, Playwright, Colly, Puppeteer, Katana, Scrapling, WebMagic
- Avançado: Heritrix, Apache Nutch (ambos exigem Java, arquivos de configuração ou stack de big data)
Se você não é desenvolvedor, as opções "Plug & Play" ou sem código são as mais indicadas. Para os outros, "Médio" significa que vai precisar escrever algum código, mas nada de outro mundo — a não ser que você fuja de chaves e colchetes.
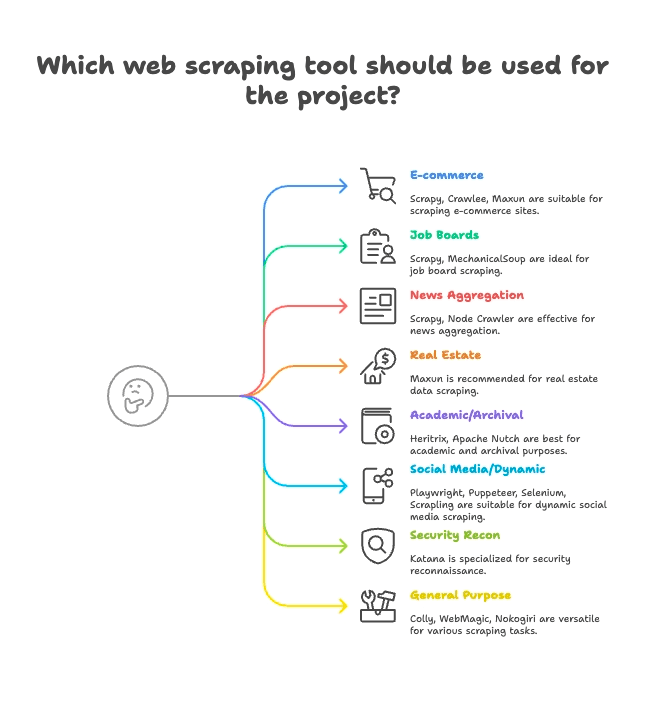
Agrupamento por Caso de Uso: Ache o Raspador Certo para o Seu Setor
Nem todo raspador serve para tudo. Veja como agrupei os 15 principais de acordo com o melhor uso:
E-commerce & Monitoramento de Preços
- Scrapy: Raspagem de produtos em grande escala e várias páginas
- Crawlee: Versátil, funciona em sites estáticos e dinâmicos de e-commerce
- Maxun: Sem código, ótimo para extrair listas de produtos rapidinho
Vagas de Emprego & Recrutamento
- Scrapy: Lida bem com paginação e listas estruturadas
- MechanicalSoup: Bom para portais de vagas com login
Notícias & Agregação de Conteúdo
- Scrapy: Feito para rastrear sites de notícias em grande escala
- Node Crawler: Rápido para agregação de notícias estáticas
Imóveis
- Thunderbit: Raspagem de subpáginas com IA para anúncios e detalhes
- Maxun: Seleção visual para dados de propriedades
Pesquisa Acadêmica & Arquivamento Web
- Heritrix: Arquivamento completo de sites (arquivos WARC)
- Apache Nutch: Rastreamento distribuído para conjuntos de dados de pesquisa
Redes Sociais & Conteúdo Dinâmico
- Playwright, Puppeteer, Selenium: Raspam feeds dinâmicos, simulam logins
- Scrapling: Raspagem furtiva para sites com defesas anti-bot
Segurança & Reconhecimento
- Katana: Descoberta rápida de URLs, rastreamento para segurança
Uso Geral / Multipropósito
- Colly: Raspagem de alta performance em Go para qualquer site
- WebMagic: Baseado em Java, flexível para vários domínios
- Nokogiri: Parsing em Ruby para scripts personalizados
Suporte a Páginas Dinâmicas: Esses Projetos Dão Conta do Recado?
Sites modernos amam JavaScript. React, Vue, scroll infinito, AJAX — se você já tentou raspar uma página e não veio nada, sabe do que estou falando.
Veja como cada projeto lida com conteúdo dinâmico:
- Suporte Completo a JS (Navegador Headless):
- Selenium: Controla navegadores reais, executa todo o JS
- Playwright: Multi-navegador, multi-linguagem, suporte robusto a JS
- Puppeteer: Chrome/Firefox headless, renderização completa de JS
- Crawlee: Alterna entre HTTP e navegador (via Puppeteer/Playwright)
- Katana: Modo headless opcional para JS
- Scrapling: Integra Playwright para raspagem furtiva de JS
- Maxun: Usa navegador por trás para conteúdo dinâmico
- Sem Suporte Nativo a JS (Só HTML Estático):
- Scrapy: Precisa de plugin Selenium/Playwright para JS
- MechanicalSoup, Node Crawler, Colly, WebMagic, Nokogiri, Heritrix, Apache Nutch: Todos pegam só HTML, não lidam com JS direto
A IA do Thunderbit brilha aqui: detecta e raspa conteúdo dinâmico automaticamente — sem configuração manual, plugins ou dor de cabeça com seletores. Só clicar em “Sugerir Campos com IA” e deixar que ele faça o trabalho pesado, até em sites feitos em React. Para saber mais, dá uma olhada no .
Saúde e Confiabilidade dos Projetos: Esse Raspador Vai Estar Vivo no Ano que Vem?
Nada pior do que montar seu fluxo de trabalho em uma ferramenta e depois descobrir que ela foi largada. Veja como estão os principais projetos:
- Ativamente Mantidos (Atualizações Frequentes):
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- Estáveis, mas com Atualizações Mais Lentas:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- Modo de Manutenção (Especializados, Lentos):
- Heritrix:
- Apache Nutch:
Thunderbit é um serviço gerenciado, então você nunca precisa se preocupar com código largado. O time mantém a IA, os templates e as integrações sempre atualizados — além de oferecer onboarding, tutoriais e suporte se precisar de uma força.
Manipulação e Exportação de Dados: Do HTML Cru ao Dado Pronto para o Negócio
Conseguir os dados é só metade do caminho. Você precisa deles em um formato que sua equipe use — CSV, Excel, Google Sheets, Airtable, Notion ou até uma API ao vivo.
- Exportação Estruturada Nativa:
- Scrapy: Exporta para CSV, JSON, XML
- Crawlee: Datasets e storages flexíveis
- Maxun: CSV, Excel, Google Sheets, API JSON
- Thunderbit:
- Manipulação Manual de Dados (Definido pelo Usuário):
- MechanicalSoup, Node Crawler, Selenium, Playwright, Puppeteer, Colly, WebMagic, Nokogiri, Scrapling: Você escreve o código para salvar/exportar os dados
- Exportação Especializada:
- Heritrix: WARC (arquivos de web archive)
- Apache Nutch: Conteúdo bruto para armazenamento/índice
A exportação estruturada e as integrações do Thunderbit economizam muito tempo para quem trabalha com dados. Chega de manipular CSVs ou escrever código só para juntar tudo — basta clicar e usar.
Para Quem é Cada Projeto de Raspagem Web do Github?
Nem toda ferramenta serve para todo mundo. Veja para quem eu recomendaria cada uma:
- Iniciantes em Python: MechanicalSoup, Scrapling (para quem quer se aventurar)
- Engenheiros de Dados: Scrapy, Crawlee, Colly, WebMagic, Node Crawler
- Profissionais de QA & Automação: Selenium, Playwright, Puppeteer
- Pesquisadores de Segurança: Katana
- Rubyistas: Nokogiri
- Desenvolvedores Java: WebMagic, Heritrix, Apache Nutch
- Usuários Não Técnicos / Equipes de Negócios: Maxun, Thunderbit
- Analistas, Growth Hackers: Maxun, Thunderbit
Se você não curte código ou quer resultado rápido, Thunderbit e Maxun são as melhores pedidas. Para os outros, escolha a ferramenta que combina com sua linguagem e objetivo.
Os 15 Melhores Projetos de Raspagem Web do Github: Comparativo Detalhado
Vamos analisar cada projeto, agrupado por caso de uso, com tags rápidas e destaques.
E-commerce, Monitoramento de Preços e Rastreamento Geral
— 57,1k estrelas, atualização em junho de 2025

- Resumo: Framework Python assíncrono de alto nível para rastreamento e raspagem em larga escala.
- Instalação: Médio (código Python, framework assíncrono)
- Uso: E-commerce, notícias, pesquisa, spiders multipágina
- Suporte JS: Não (precisa de plugin Selenium/Playwright)
- Manutenção: Ativo
- Exportação: CSV, JSON, XML nativos
- Público: Desenvolvedores, engenheiros de dados
- Destaques: Escalável, robusto, muitos plugins. Curva de aprendizado íngreme para iniciantes.
— 17,9k estrelas, 2025

- Resumo: Biblioteca Node.js completa para raspagem estática e dinâmica.
- Instalação: Médio (código Node/TS)
- Uso: E-commerce, redes sociais, automação
- Suporte JS: Sim (integração com Puppeteer/Playwright)
- Manutenção: Muito ativo
- Exportação: Flexível (datasets, storages)
- Público: Equipes de desenvolvimento JS/TS
- Destaques: Ferramentas anti-bloqueio, fácil alternância entre HTTP e navegador.
— 13k estrelas, junho de 2025

- Resumo: Plataforma open-source de extração de dados web sem código, com interface visual.
- Instalação: Médio (deploy em servidor), Fácil (para usuários finais)
- Uso: Multipropósito, e-commerce, negócios
- Suporte JS: Sim (navegador embutido)
- Manutenção: Ativo e crescendo
- Exportação: CSV, Excel, Google Sheets, API JSON
- Público: Usuários não técnicos, analistas, equipes
- Destaques: Raspagem por apontar e clicar, navegação multinível, pode ser hospedado por você.
Vagas, Recrutamento e Interações Simples
— 4,8k estrelas, 2024

- Resumo: Biblioteca Python para automação de formulários e navegação simples.
- Instalação: Plug & Play (Python, pouco código)
- Uso: Portais de vagas com login, sites estáticos
- Suporte JS: Não
- Manutenção: Maduro, manutenção leve
- Exportação: Não possui (manual)
- Público: Iniciantes em Python, scripts rápidos
- Destaques: Simula sessões de navegador em poucas linhas. Não serve para sites dinâmicos.
Agregação de Notícias & Conteúdo Estático
— 6,8k estrelas, 2024

- Resumo: Crawler server-side rápido e concorrente com parsing Cheerio.
- Instalação: Médio (callbacks/async em Node)
- Uso: Notícias, raspagem estática de alta velocidade
- Suporte JS: Não (apenas HTML)
- Manutenção: Atividade moderada (v2 beta)
- Exportação: Não possui (definido pelo usuário)
- Público: Devs Node.js, alta concorrência
- Destaques: Rastreamento assíncrono, controle de taxa, API estilo jQuery.
Imóveis, Listagens e Raspagem de Subpáginas

- Resumo: Raspador web sem código, com IA, voltado para negócios.
- Instalação: Plug & Play (extensão Chrome, instalação em 2 cliques)
- Uso: Imóveis, e-commerce, vendas, marketing, qualquer site
- Suporte JS: Sim (IA detecta conteúdo dinâmico)
- Manutenção: Atualizações contínuas, serviço gerenciado
- Exportação: Um clique para Sheets, Airtable, Notion, CSV, JSON
- Público: Usuários não técnicos, equipes de negócios, vendas, marketing
- Destaques: “Sugerir Campos com IA”, raspagem de subpáginas, exportação instantânea, onboarding, templates, .
Pesquisa Acadêmica & Arquivamento Web
— 3k estrelas, 2023

- Resumo: Crawler de arquivamento web em escala, do Internet Archive.
- Instalação: Avançado (aplicação Java, arquivos de configuração)
- Uso: Arquivamento web, rastreamento de domínios inteiros
- Suporte JS: Não (apenas fetch)
- Manutenção: Mantido (lento, mas estável)
- Exportação: WARC (arquivos de web archive)
- Público: Arquivos, bibliotecas, instituições
- Destaques: Escalável, robusto, compatível com padrões. Não serve para raspagem pontual.
— 3k estrelas, 2024

- Resumo: Crawler open-source para big data e motores de busca.
- Instalação: Avançado (Java+Hadoop para escala)
- Uso: Rastreamento para motores de busca, big data
- Suporte JS: Não (apenas HTTP)
- Manutenção: Ativo (Apache)
- Exportação: Conteúdo bruto para armazenamento/índice
- Público: Empresas, big data, pesquisa acadêmica
- Destaques: Arquitetura de plugins, rastreamento distribuído.
Redes Sociais, Conteúdo Dinâmico e Automação
— ~30k estrelas, 2025

- Resumo: Automação de navegador para raspagem e testes, suporta todos os principais browsers.
- Instalação: Médio (drivers, multi-linguagem)
- Uso: Sites com muito JS, fluxos de teste, redes sociais
- Suporte JS: Sim (automação completa do navegador)
- Manutenção: Ativo, maduro
- Exportação: Não possui (manual)
- Público: Engenheiros de QA, desenvolvedores
- Destaques: Multi-linguagem, simula comportamento real de usuário.
— 73,5k estrelas, 2025

- Resumo: Automação moderna de navegador para raspagem e testes E2E.
- Instalação: Médio (scripts multi-linguagem)
- Uso: Web apps modernos, redes sociais, automação
- Suporte JS: Sim (headless ou navegador real)
- Manutenção: Muito ativo
- Exportação: Não possui (usuário implementa)
- Público: Devs que precisam de controle robusto do navegador
- Destaques: Multi-browser, auto-wait, interceptação de rede.
— 90,9k estrelas, 2025

- Resumo: API de alto nível para automação do Chrome/Firefox.
- Instalação: Médio (scripts Node)
- Uso: Raspagem headless no Chrome, conteúdo dinâmico
- Suporte JS: Sim (Chrome/Firefox)
- Manutenção: Ativo (equipe do Chrome)
- Exportação: Não possui (customizado no código)
- Público: Devs Node.js, front-end
- Destaques: Controle avançado do navegador, screenshots, PDF, interceptação de rede.
— 5,4k estrelas, junho de 2025

- Resumo: Raspagem furtiva e de alta performance com recursos anti-bot.
- Instalação: Médio (código Python)
- Uso: Raspagem furtiva, anti-bloqueio, sites dinâmicos
- Suporte JS: Sim (integração Playwright)
- Manutenção: Ativo, de ponta
- Exportação: Não possui (manual)
- Público: Devs Python, hackers, engenheiros de dados
- Destaques: Furtividade, proxy, anti-bloqueio, assíncrono.
Reconhecimento de Segurança
— 13,8k estrelas, 2025

- Resumo: Crawler web rápido para segurança, automação e descoberta de links.
- Instalação: Médio (CLI ou biblioteca Go)
- Uso: Rastreamento de segurança, descoberta de endpoints
- Suporte JS: Sim (modo headless opcional)
- Manutenção: Ativo (ProjectDiscovery)
- Exportação: Saída em texto (listas de URLs)
- Público: Pesquisadores de segurança, devs Go
- Destaques: Velocidade, concorrência, parsing JS headless.
Raspagem Multipropósito / Geral
— 24,3k estrelas, 2025

- Resumo: Framework de raspagem rápido e elegante para Go.
- Instalação: Médio (código Go)
- Uso: Raspagem de alta performance, multipropósito
- Suporte JS: Não (apenas HTML)
- Manutenção: Ativo, commits recentes
- Exportação: Não possui (definido pelo usuário)
- Público: Devs Go, foco em performance
- Destaques: Assíncrono, controle de taxa, raspagem distribuída.
— 11,6k estrelas, 2023

- Resumo: Framework flexível de crawler em Java, estilo Scrapy.
- Instalação: Médio (Java, API simples)
- Uso: Raspagem geral em Java
- Suporte JS: Não (pode ser estendido com Selenium)
- Manutenção: Comunidade ativa
- Exportação: Pipelines plugáveis
- Público: Devs Java
- Destaques: Pool de threads, agendadores, anti-bloqueio.
— 6,2k estrelas, 2025

- Resumo: Parser HTML/XML nativo e rápido para Ruby.
- Instalação: Plug & Play (gem Ruby)
- Uso: Parsing HTML/XML em apps Ruby
- Suporte JS: Não (apenas parsing)
- Manutenção: Ativo, acompanha o Ruby
- Exportação: Não possui (use Ruby para formatar)
- Público: Rubyistas, devs Rails
- Destaques: Velocidade, compliance, seguro por padrão.
Comparativo Rápido de Funcionalidades
Veja uma tabela comparativa — incluindo o Thunderbit:
| Projeto | Complexidade de Instalação | Caso de Uso | Suporte JS | Manutenção | Exportação de Dados | Público | Estrelas Github |
|---|---|---|---|---|---|---|---|
| Scrapy | Médio | E-commerce, notícias | Não | Ativo | CSV, JSON, XML | Devs, engenheiros de dados | 57,1k |
| Crawlee | Médio | Versátil, automação | Sim | Muito ativo | Datasets flexíveis | Equipes JS/TS | 17,9k |
| MechanicalSoup | Plug & Play | Estático, formulários | Não | Maduro | Nenhum (manual) | Iniciantes Python | 4,8k |
| Node Crawler | Médio | Notícias, estático | Não | Moderado | Nenhum (manual) | Devs Node.js | 6,8k |
| Selenium | Médio | JS pesado, testes | Sim | Ativo | Nenhum (manual) | QA, devs | ~30k |
| Heritrix | Avançado | Arquivamento, pesquisa | Não | Mantido | WARC | Arquivos, instituições | 3k |
| Apache Nutch | Avançado | Big data, busca | Não | Ativo | Conteúdo bruto | Empresas, pesquisa | 3k |
| WebMagic | Médio | Java, geral | Não | Comunidade ativa | Pipelines plugáveis | Devs Java | 11,6k |
| Nokogiri | Plug & Play | Parsing Ruby | Não | Ativo | Nenhum (manual) | Rubyistas | 6,2k |
| Playwright | Médio | Dinâmico, automação | Sim | Muito ativo | Nenhum (manual) | Devs, QA | 73,5k |
| Katana | Médio | Segurança, descoberta | Sim | Ativo | Saída texto | Segurança, devs Go | 13,8k |
| Colly | Médio | Alta perf., geral | Não | Ativo | Nenhum (manual) | Devs Go | 24,3k |
| Puppeteer | Médio | Dinâmico, automação | Sim | Ativo | Nenhum (manual) | Devs Node.js | 90,9k |
| Maxun | Fácil (usuário) | Sem código, negócios | Sim | Ativo | CSV, Excel, Sheets, API | Não técnicos, analistas | 13k |
| Scrapling | Médio | Furtivo, anti-bot | Sim | Ativo | Nenhum (manual) | Devs Python, hackers | 5,4k |
| Thunderbit | Plug & Play | Sem código, negócios | Sim | Gerenciado, atualizado | Sheets, Airtable, Notion | Não técnicos, negócios | N/A |
Por Que o Thunderbit é a Melhor Opção para Usuários Não Técnicos e Empresas
Vamos ser diretos: a maioria dos projetos open-source do Github é feita por desenvolvedores, para desenvolvedores. Ou seja, instalação, manutenção e resolver pepino fazem parte do pacote. Se você é de negócios, marketing, vendas ou só quer resultado — sem dor de cabeça com regex — o Thunderbit foi feito pra você.
Veja por que o Thunderbit se destaca:
- Simplicidade Sem Código e com IA: Instale a , clique em “Sugerir Campos com IA” e comece a raspar. Sem Python, sem seletores, sem drama de “pip install”.
- Suporte a Páginas Dinâmicas: A IA do Thunderbit lê e extrai dados de sites modernos, cheios de JavaScript (React, Vue, AJAX), sem configuração manual.
- Raspagem de Subpáginas: Precisa coletar detalhes de cada produto ou anúncio? A IA do Thunderbit navega por subpáginas e junta tudo em uma tabela — sem código personalizado.
- Exportação Pronta para Negócios: Um clique para exportar para Google Sheets, Airtable, Notion, CSV ou JSON. Ideal para leads, monitoramento de preços ou agregação de conteúdo.
- Atualizações e Suporte Contínuos: O Thunderbit é um serviço gerenciado — sem risco de “abandonware”. Você conta com onboarding, tutoriais e uma biblioteca crescente de templates para sites populares.
- Público-Alvo: Thunderbit é para quem não é técnico, equipes de negócios e todos que valorizam agilidade e confiabilidade em vez de mexer com código.
Não precisa acreditar só em mim — o Thunderbit já é usado por mais de 30.000 pessoas no mundo todo, incluindo equipes da Accenture, Grammarly e Puma. E sim, já fomos Produto da Semana no Product Hunt.
Quer ver como a raspagem pode ser fácil? .
Conclusão: Como Escolher a Solução de Raspagem Web Ideal em 2025
Resumindo: o Github é um verdadeiro baú de ferramentas poderosas de raspagem, mas a maioria foi feita para desenvolvedores. Se você gosta de programar, frameworks como Scrapy, Crawlee, Playwright e Colly dão controle total. Se está na academia ou segurança, Heritrix, Nutch e Katana são as escolhas certas.
Mas se você é de negócios, analista ou só quer dados — rápido, estruturado e pronto para uso — o Thunderbit é o caminho. Sem instalação, sem manutenção, sem código. Só resultado.
E agora? Se ficou curioso, teste um projeto do Github que combine com seu perfil e objetivo. Ou, se quiser pular a curva de aprendizado e ver resultados em minutos, e comece a raspar hoje mesmo.
Quer se aprofundar em raspagem web? Confira outros guias no , como ou .
Boas raspagens — que seus dados sejam sempre limpos, organizados e prontos para uso. Se travar, lembra: provavelmente tem um repositório no Github para isso... ou você pode deixar a IA do Thunderbit fazer o trabalho pesado.