
Meu primeiro projeto de scraping envolvia um script Python feito na mão, um proxy partilhado e uma prece. Ele quebrava a cada três dias.
Em 2026, as APIs de scraping tratam das partes mais difíceis — proxies, renderização, CAPTCHAs, novas tentativas automáticas — para que você não tenha de se preocupar com isso. Elas são a base de tudo, de monitorização de preços a pipelines de dados de treino para IA.
Mas há uma mudança importante: ferramentas com IA, como a Thunderbit, estão a tornar muitos casos de uso de APIs desnecessários para quem não é programador. Mais sobre isso abaixo.
Aqui estão 10 APIs de scraping que usei ou avaliei — no que cada uma se destaca, onde fica aquém e quando talvez nem precise de uma API.
Por que considerar a Thunderbit com IA em vez de APIs tradicionais de Web Scraping?
Antes de mergulharmos na lista de APIs, vale a pena falar do elefante na sala: automação com IA. Passei anos a ajudar equipas a automatizar tarefas aborrecidas, e posso dizer: há um motivo para cada vez mais empresas saltarem APIs pesadas em código e irem direto para agentes de IA como a Thunderbit.
Veja o que diferencia a Thunderbit das APIs tradicionais de web scraping:
-
Chamadas de API em estilo cascata para 99% de sucesso
A IA da Thunderbit não chama apenas uma API e espera pelo melhor. Ela usa um padrão em cascata — escolhe automaticamente o melhor método de scraping para cada tarefa, tenta novamente quando é necessário e garante uma taxa de sucesso de 99%. Você recebe os dados, não a dor de cabeça.
-
Configuração sem código em dois cliques
Esqueça escrever scripts em Python ou perder-se na documentação da API. Com a Thunderbit, basta clicar em “AI Suggest Fields” e “Scrape”. Só isso. Até a minha mãe conseguiria usar (e ela ainda acha que “a nuvem” é só mau tempo).
-
Scraping em lote: rápido e preciso
O modelo de IA da Thunderbit consegue processar milhares de sites diferentes em paralelo, adaptando-se a cada layout no momento. É como ter um exército de estagiários — mas sem pedirem pausa para café.
-
Sem manutenção
Os sites mudam constantemente. As APIs tradicionais? Quebram. A Thunderbit? A IA volta a ler a página a cada execução, por isso você não precisa de atualizar código quando um site muda o layout ou adiciona um novo botão.
-
Extração de dados personalizada e pós-processamento
Precisa de limpar, rotular, traduzir ou resumir os seus dados? A Thunderbit faz isso durante a extração — pense nela como pegar em 10.000 páginas da web, pô-las no ChatGPT e receber de volta um conjunto de dados perfeitamente estruturado.
-
Scraping de subpáginas e paginação
A IA da Thunderbit consegue seguir links, lidar com paginação e até enriquecer a sua tabela com dados de subpáginas — tudo sem código personalizado.
-
Exportação gratuita de dados e integrações
Exporte para Excel, Google Sheets, Airtable, Notion, ou descarregue em CSV/JSON — sem paywall, sem complicações.
Aqui vai uma comparação rápida para deixar isso claro:
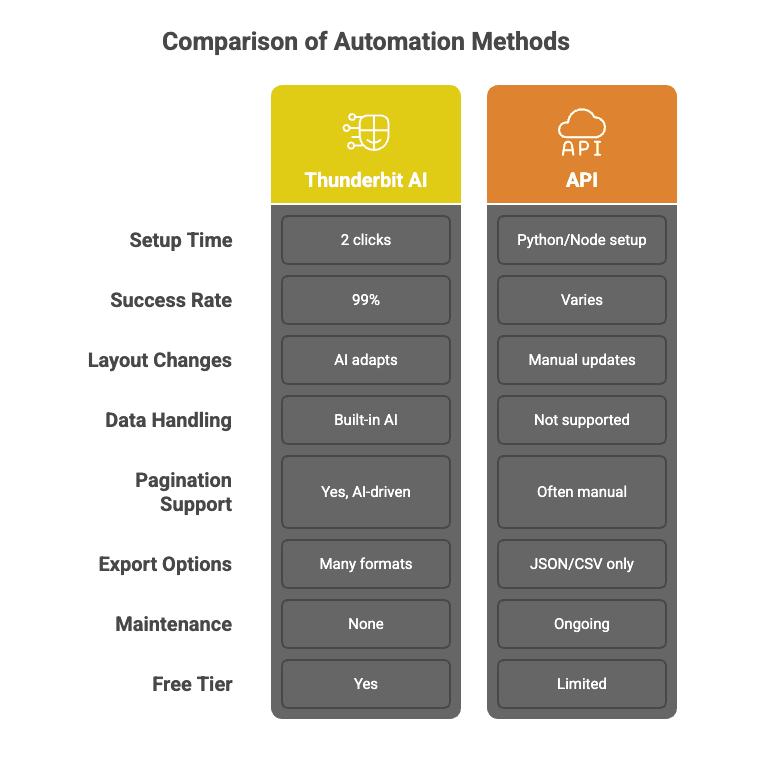
Quer ver na prática? Veja a extensão Thunderbit para Chrome.
O que é uma API de data scraping?
Vamos voltar ao básico por um instante. Uma API de data scraping é uma ferramenta que permite extrair dados de sites de forma programática — sem precisar de construir os seus próprios scrapers do zero. Pense nela como um robô que você envia para ir buscar os preços mais recentes, avaliações ou anúncios, e que traz os dados de volta num formato organizado (normalmente JSON ou CSV).
Como funcionam? A maioria das APIs de scraping trata das partes mais complicadas — proxies rotativos, resolução de CAPTCHAs, renderização de JavaScript — para que você se possa concentrar no que realmente importa: os dados. Você envia um pedido (normalmente com uma URL e alguns parâmetros), e a API devolve o conteúdo pronto para o seu fluxo de trabalho.
Principais vantagens:
- Velocidade: APIs conseguem fazer scraping de milhares de páginas por minuto.
- Escalabilidade: Precisa de monitorizar 10.000 produtos? Sem problema.
- Integração: Ligue ao seu CRM, ferramenta de BI ou data warehouse com pouca dor de cabeça.
Mas, como vamos ver, nem todas as APIs são iguais — e nem todas são tão “configure e esqueça” como prometem.
Como avaliei estas APIs
Passei bastante tempo na linha da frente — a testar, a partir e, por vezes, a derrubar os meus próprios servidores sem querer (não contem à minha antiga equipa de TI). Para esta lista, foquei-me em:
- Fiabilidade: Funciona mesmo, até em sites difíceis?
- Velocidade: Quão rápido entrega resultados em escala?
- Preço: É acessível para startups e escalável para empresas?
- Escalabilidade: Aguenta milhões de pedidos ou bloqueia aos 100?
- Facilidade para programadores: A documentação é clara? Há SDKs e exemplos de código?
- Suporte: Quando as coisas correm mal (e vão correr), há ajuda disponível?
- Feedback dos utilizadores: Avaliações do mundo real, não só marketing.
Também dei muito peso a testes práticos, análise de reviews e feedback da comunidade Thunderbit (somos um grupo bastante exigente).
As 10 APIs que valem a pena considerar em 2026
Pronto para o prato principal? Aqui está a minha lista atualizada das melhores APIs e plataformas de web scraping para utilizadores de negócio e programadores em 2026.
1. Oxylabs
 Visão geral:
Visão geral:
A Oxylabs é o peso-pesado da extração de dados da web em nível empresarial. Com uma enorme pool de proxies e APIs especializadas para tudo, de SERPs a e-commerce, é a escolha ideal para empresas da Fortune 500 e para qualquer pessoa que precise de fiabilidade em escala.
Principais recursos:
- Grande rede de proxies (residenciais, datacenter, móveis, ISP) em mais de 195 países
- APIs de scraping com anti-bot, resolução de CAPTCHA e renderização em navegador sem interface
- Geotargeting, persistência de sessão e alta precisão dos dados (taxas de sucesso acima de 95%)
- OxyCopilot: assistente de IA que gera automaticamente código de parsing e consultas de API
Preço:
Começa em cerca de US$ 49/mês para uma única API, US$ 149/mês para acesso completo. Inclui teste gratuito de 7 dias com até 5.000 pedidos.
Feedback dos utilizadores:
Avaliada com 4,8/5 no G2, elogiada pela fiabilidade e pelo suporte. Principal ponto negativo? É cara, mas você recebe pelo que paga.
2. ScrapingBee
 Visão geral:
Visão geral:
A ScrapingBee é a melhor amiga do programador — simples, acessível e focada. Você envia uma URL, ela trata do Chrome sem interface, dos proxies e dos CAPTCHAs, e devolve a página renderizada ou apenas os dados de que precisa.
Principais recursos:
- Renderização em navegador sem interface (suporte a JavaScript)
- Rotação automática de IP e resolução de CAPTCHA
- Pool de proxies furtivos para sites difíceis
- Configuração mínima — basta uma chamada de API
Preço:
Plano gratuito com cerca de 1.000 chamadas/mês. Planos pagos começam em cerca de US$ 29/mês para 5.000 pedidos.
Feedback dos utilizadores:
Consistentemente 4,8/5 no G2. Programadores adoram a simplicidade; quem não programa pode achar a ferramenta um pouco básica demais.
3. Apify
 Visão geral:
Visão geral:
A Apify é o canivete suíço do web scraping. Você pode criar scrapers personalizados (“Actors”) em JavaScript ou Python, ou usar a enorme biblioteca de actors prontos para sites populares. É tão flexível quanto você precisar.
Principais recursos:
- Scrapers personalizados e prontos (Actors) para praticamente qualquer site
- Infraestrutura na nuvem, agendamento e gestão de proxies incluídos
- Exportação de dados para JSON, CSV, Excel, Google Sheets e muito mais
- Comunidade ativa e suporte no Discord
Preço:
Plano gratuito para sempre com US$ 5/mês em créditos. Planos pagos começam em US$ 39/mês.
Feedback dos utilizadores:
Acima de 4,7 no G2/Capterra. Programadores adoram a flexibilidade; iniciantes enfrentam uma curva de aprendizagem.
Veja como a Apify se compara à Thunderbit
4. Decodo (antiga Smartproxy)
 Visão geral:
Visão geral:
A Decodo (renomeada a partir da Smartproxy) foca-se em valor e praticidade. Combina uma infraestrutura robusta de proxies com APIs de scraping para web geral, SERPs, e-commerce e redes sociais — tudo numa só subscrição.
Principais recursos:
- API de scraping unificada para todos os endpoints (sem complementos separados)
- Scrapers especializados para Google, Amazon, TikTok e muito mais
- Dashboard amigável com playground e geradores de código
- Suporte por chat ao vivo 24/7
Preço:
Começa em cerca de US$ 50/mês para 25.000 pedidos. Teste gratuito de 7 dias com 1.000 pedidos.
Feedback dos utilizadores:
Elogiada pelo excelente custo-benefício e pelo suporte rápido. 4,7/5 no G2.
5. Octoparse
 Visão geral:
Visão geral:
A Octoparse é a campeã do no-code. Se você odeia código, mas adora dados, esta app de desktop point-and-click (com recursos na nuvem) permite criar scrapers visualmente e executá-los localmente ou na nuvem.
Principais recursos:
- Criador visual de fluxos de trabalho — basta clicar para selecionar os campos de dados
- Extração na nuvem, agendamento e rotação automática de IP
- Modelos para sites populares e marketplace para scrapers personalizados
- Octoparse AI: integra RPA e ChatGPT para limpeza de dados e automação de fluxos
Preço:
Plano gratuito para até 10 tarefas locais. Planos pagos começam em US$ 119/mês (recursos na nuvem, tarefas ilimitadas). Teste gratuito de 14 dias para recursos premium.
Feedback dos utilizadores:
4,4/5 no G2. Muito apreciada por quem não programa, mas utilizadores avançados podem esbarrar em limitações.
6. Bright Data
 Visão geral:
Visão geral:
A Bright Data é a gigante do setor — se precisa de escala, velocidade e todos os recursos imagináveis, esta é a sua plataforma. Com a maior rede de proxies do mundo e um poderoso IDE de scraping, foi feita para empresas.
Principais recursos:
- Mais de 150 milhões de IPs (residenciais, móveis, ISP, datacenter)
- Web Scraper IDE, coletores de dados prontos e conjuntos de dados disponíveis para compra
- Anti-bot avançado, resolução de CAPTCHA e suporte a navegador sem interface
- Foco em conformidade e aspetos legais (iniciativa Ethical Web Data)
Preço:
Pay-as-you-go: cerca de US$ 1,05 por 1.000 pedidos, proxies a partir de US$ 3–15/GB. Testes gratuitos para a maioria dos produtos.
Feedback dos utilizadores:
Elogiada pelo desempenho e pelos recursos, mas o preço e a complexidade podem ser um obstáculo para equipas menores.
Veja as ofertas da Bright Data
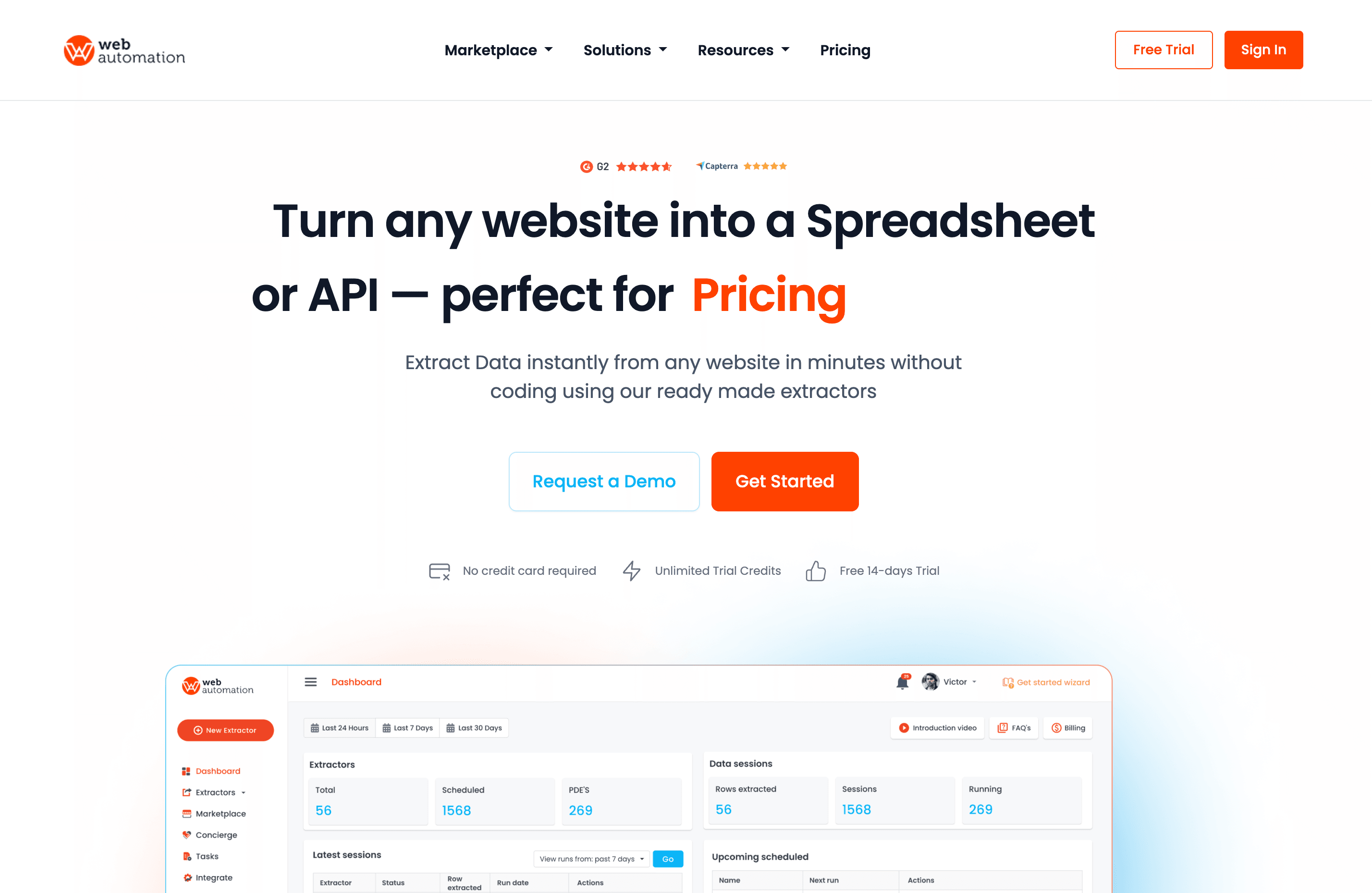
7. WebAutomation
 Visão geral:
Visão geral:
A WebAutomation é uma plataforma baseada na nuvem pensada para quem não é programador. Com um marketplace de extratores prontos e um construtor no-code, é perfeita para utilizadores de negócio que querem dados, não código.
Principais recursos:
- Extratores prontos para sites populares (Amazon, Zillow etc.)
- Construtor de extratores sem código com interface point-and-click
- Agendamento, entrega de dados e manutenção na nuvem incluídos
- Preço por linha (você paga pelo que extrai)
Preço:
Plano Project por US$ 74/mês (~400 mil linhas/ano), pay-as-you-go a US$ 1 por 1.000 linhas. Teste gratuito de 14 dias com 10 milhões de créditos.
Feedback dos utilizadores:
Os utilizadores adoram a facilidade de uso e o preço transparente. O suporte é útil e a manutenção fica a cargo da equipa.
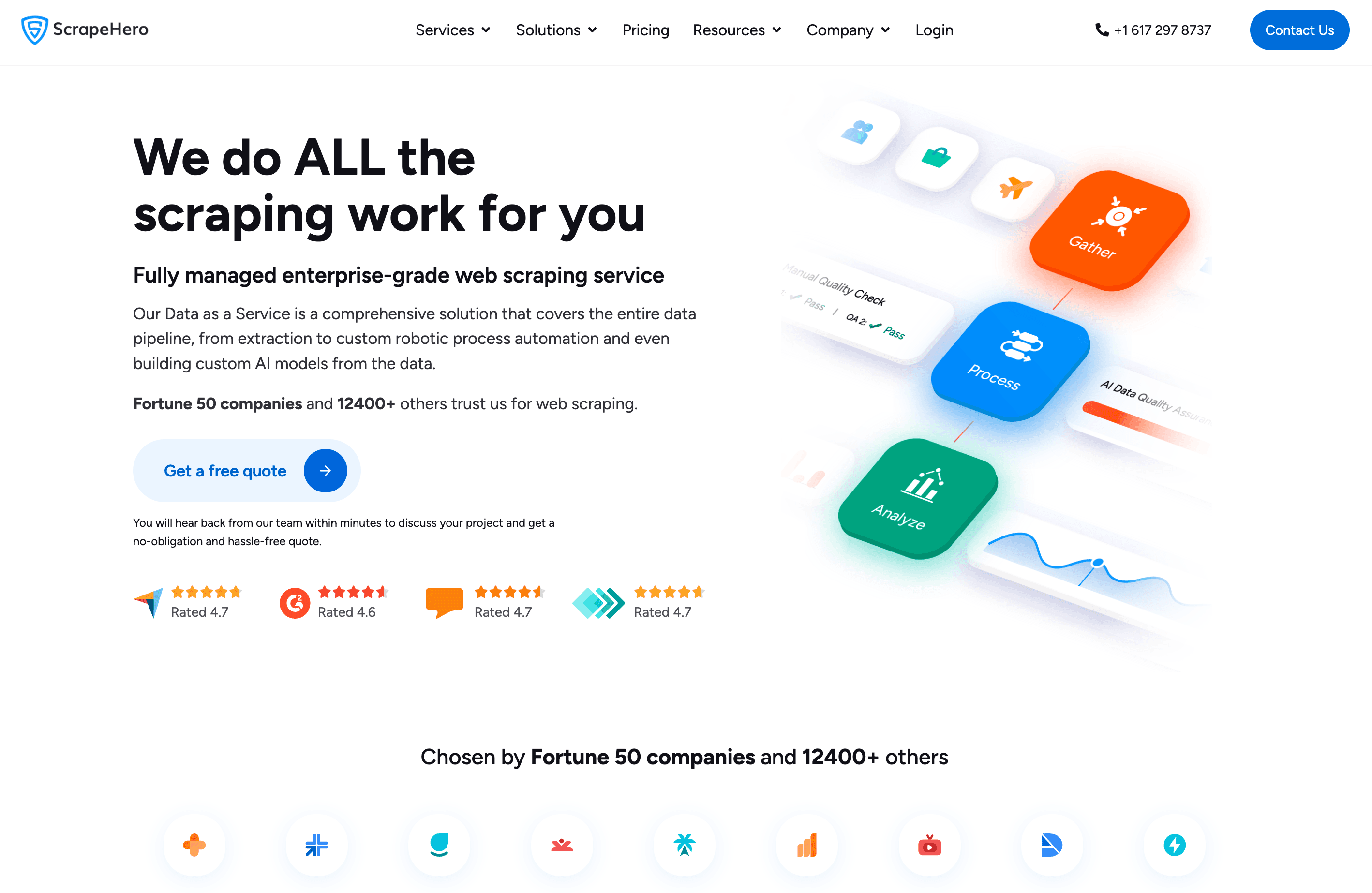
8. ScrapeHero
 Visão geral:
Visão geral:
A ScrapeHero começou como uma consultoria de scraping à medida e agora oferece uma plataforma na nuvem de self-service. Você pode usar scrapers prontos para sites populares ou pedir projetos totalmente geridos.
Principais recursos:
- ScrapeHero Cloud: scrapers prontos para Amazon, Google Maps, LinkedIn e muito mais
- Operação sem código, agendamento e entrega na nuvem
- Soluções personalizadas para necessidades específicas
- Acesso por API para integração programática
Preço:
Planos na nuvem a partir de apenas US$ 5/mês. Projetos personalizados a partir de US$ 550 por site (pagamento único).
Feedback dos utilizadores:
Elogiada pela fiabilidade, qualidade dos dados e suporte. Excelente para crescer de uma solução DIY para uma solução gerida.
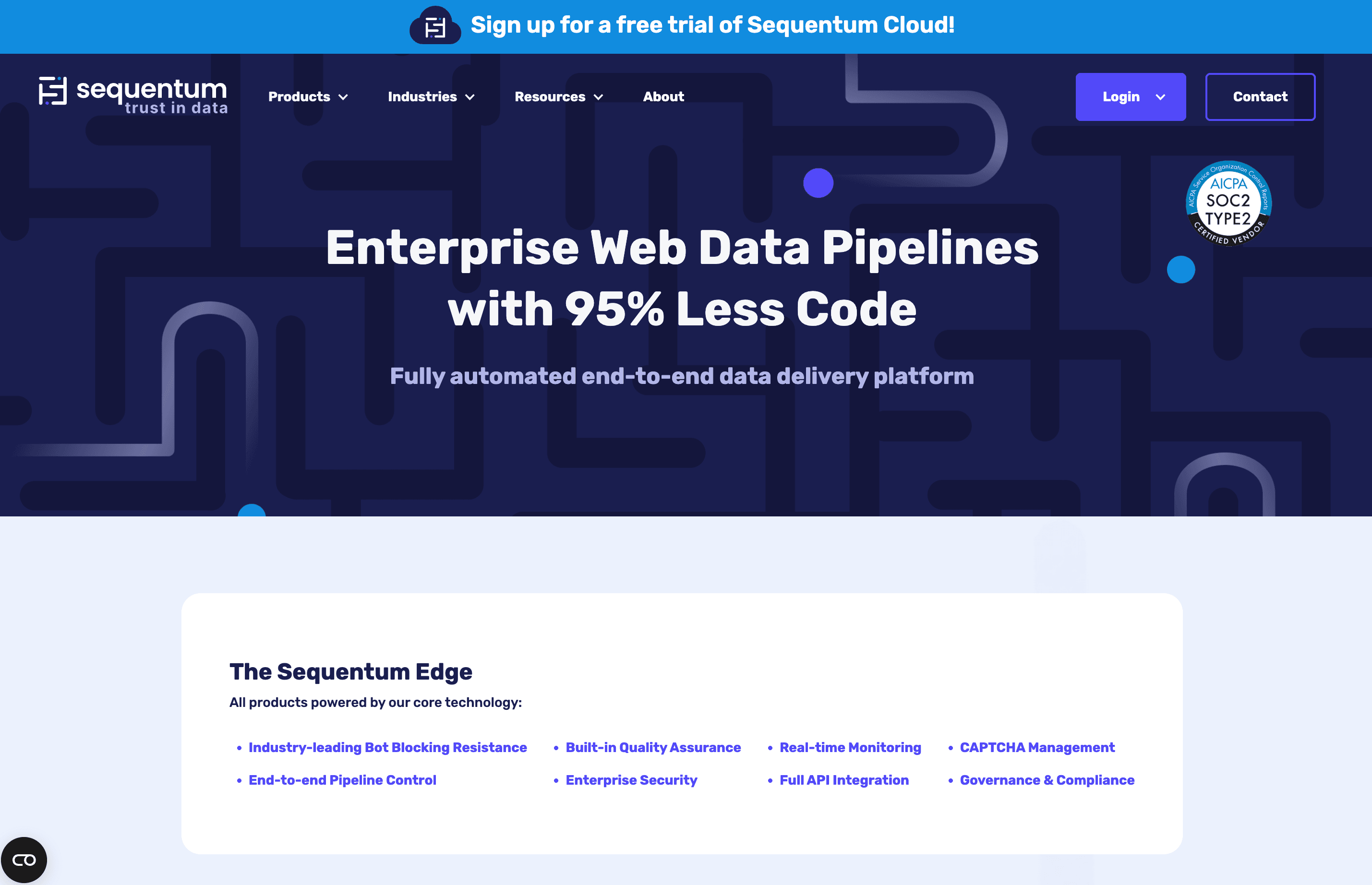
9. Sequentum
 Visão geral:
Visão geral:
A Sequentum é o canivete suíço corporativo — feita para conformidade, rastreabilidade e escala massiva. Se precisa de certificação SOC-2, trilhos de auditoria e colaboração em equipa, esta é a sua ferramenta.
Principais recursos:
- Construtor de agentes low-code (point-and-click com scripting)
- Implementação como SaaS na nuvem ou on-premise
- Gestão de proxies, resolução de CAPTCHA e navegadores sem interface integrados
- Trilhos de auditoria, acesso baseado em funções e conformidade SOC-2
Preço:
Pay-as-you-go (US$ 6/hora de execução, US$ 0,25/GB de exportação), plano Starter por US$ 199/mês. Crédito gratuito de US$ 5 no registo.
Feedback dos utilizadores:
As empresas adoram os recursos de conformidade e a escalabilidade. Há uma curva de aprendizagem, mas o suporte e a formação são excelentes.
10. Grepsr
 Visão geral:
Visão geral:
A Grepsr é um serviço gerido de extração de dados — basta dizer o que precisa, e eles constroem, executam e mantêm os scrapers por si. Perfeita para empresas que querem dados sem a dor de cabeça técnica.
Principais recursos:
- Extração gerida (“Grepsr Concierge”) — eles configuram e mantêm tudo
- Dashboard na nuvem para agendamento, monitorização e download de dados
- Vários formatos de saída e integrações (Dropbox, S3, Google Drive)
- Cobrança por registo de dados (não por pedido)
Preço:
Pacote inicial por US$ 350 (extração única), subscrições recorrentes sob orçamento personalizado.
Feedback dos utilizadores:
Os clientes adoram a experiência sem intervenção e o suporte responsivo. Ótima opção para equipas sem perfil técnico e para quem valoriza tempo mais do que ajustes finos.
Tabela rápida de comparação: principais APIs de Web Scraping
Aqui está a cola de referência das 10 plataformas:
| Plataforma | Tipos de dados compatíveis | Preço inicial | Teste gratuito | Facilidade de uso | Suporte | Recursos notáveis |
|---|---|---|---|---|---|---|
| Oxylabs | Web, SERP, e-com, imóveis | US$ 49/mês | 7 dias/5 mil req | Focada em devs | 24/7, enterprise | OxyCopilot IA, enorme pool de proxies, geotargeting |
| ScrapingBee | Web geral, JS, CAPTCHA | US$ 29/mês | 1 mil chamadas/mês | API simples | E-mail, fóruns | Chrome sem interface, proxies furtivos |
| Apify | Qualquer web, pronto/personalizado | Gratuito/US$ 39/mês | Gratuito para sempre | Flexível, complexa | Comunidade, Discord | Marketplace de Actors, infraestrutura na nuvem, integrações |
| Decodo | Web, SERP, e-com, social | US$ 50/mês | 7 dias/1 mil req | Amigável | Chat ao vivo 24/7 | API unificada, playground de código, ótimo custo-benefício |
| Octoparse | Qualquer web, no-code | Gratuito/US$ 119/mês | 14 dias | Visual, sem código | E-mail, fórum | Interface point-and-click, nuvem, Octoparse AI |
| Bright Data | Toda a web, conjuntos de dados | US$ 1,05/1 mil req | Sim | Poderosa, complexa | 24/7, enterprise | Maior rede de proxies, IDE, dados prontos |
| WebAutomation | Estruturados, e-com, imóveis | US$ 74/mês | 14 dias/10 milhões de linhas | No-code, modelos | E-mail, chat | Extratores prontos, preço por linha |
| ScrapeHero | E-com, mapas, vagas, personalizado | US$ 5/mês | Sim | No-code, gerida | E-mail, tickets | Scrapers na nuvem, projetos personalizados, entrega via Dropbox |
| Sequentum | Qualquer web, enterprise | US$ 0/US$ 199/mês | Crédito de US$ 5 | Low-code, visual | Atendimento próximo | Trilhos de auditoria, SOC-2, on-prem/nuvem |
| Grepsr | Qualquer dado estruturado, gerido | US$ 350 única vez | Execução de amostra | Totalmente gerida | Representante dedicado | Configuração concierge, pagamento por dados, integrações |
Escolhendo a ferramenta certa de web scraping para o seu negócio
Então, qual ferramenta deve escolher? Veja como eu separo isso para as equipas que aconselho:
-
Se você quer zero código, resultados imediatos e limpeza de dados com IA:
Vá de Thunderbit. É o caminho mais rápido de “preciso de dados” para “já tenho os dados” — e você não precisa ficar a monitorizar scripts ou APIs.
-
Se você é programador e gosta de controlo e flexibilidade:
Experimente Apify, ScrapingBee ou Oxylabs. Elas oferecem mais poder, mas você vai precisar de tratar de alguma configuração e manutenção.
-
Se você é um utilizador de negócio que quer uma ferramenta visual:
A WebAutomation é fantástica para scraping point-and-click, sobretudo para e-commerce e geração de leads.
-
Se você precisa de conformidade, rastreabilidade ou recursos empresariais:
A Sequentum foi feita para você. É mais cara, mas compensa em setores regulados.
-
Se você só quer que outra pessoa trate de tudo:
Os serviços geridos da Grepsr ou da ScrapeHero são o caminho. Você paga um pouco mais, mas a sua pressão arterial agradece.
E, se ainda estiver em dúvida, a maioria destas plataformas oferece testes gratuitos — por isso vale a pena experimentar!
Principais conclusões
- As APIs de web scraping agora são essenciais para negócios orientados por dados — o mercado deve atingir US$ 1,8 bilhão até 2030.
- O scraping manual ficou para trás — entre tecnologia anti-bot, proxies e mudanças nos sites, APIs e ferramentas de IA são a única forma de escalar.
- Cada API/plataforma tem os seus pontos fortes:
- Oxylabs e Bright Data para escala e fiabilidade
- Apify para flexibilidade
- Decodo para valor
- WebAutomation para no-code
- Sequentum para conformidade
- Grepsr para dados geridos sem intervenção
- A automação com IA (como a Thunderbit) está a mudar o jogo — oferecendo taxas de sucesso mais altas, manutenção zero e processamento de dados integrado que as APIs tradicionais não conseguem igualar.
- A melhor ferramenta é aquela que se encaixa no seu fluxo de trabalho, orçamento e nível técnico. Não tenha medo de testar!
Se você está pronto para deixar para trás scripts a partir e depuração sem fim, experimente a Thunderbit — ou veja mais guias no Blog da Thunderbit para análises aprofundadas sobre scraping de Amazon, Google, PDFs e muito mais.
E lembre-se: no mundo dos dados da web, a única coisa que muda mais rápido do que os próprios sites é a tecnologia que usamos para os recolher. Mantenha a curiosidade, automatize sempre e que os seus proxies nunca sejam bloqueados.




