
A web está cheia de dados e, sejamos francos: ninguém tem tempo para andar a copiar e colar milhares de listagens de produtos ou páginas de preços dos concorrentes. Se usa Linux — como eu uso na maior parte do meu trabalho de automação e desenvolvimento — já sabe que a plataforma é uma potência para equipas orientadas por dados. De facto, e . Mas aqui está o problema: encontrar o raspador web certo para Linux que se encaixe mesmo no seu fluxo de trabalho — seja você um utilizador de negócio sem perfil técnico ou um programador avançado — pode parecer procurar uma agulha num palheiro.
Por isso, preparei este guia aprofundado com as 18 melhores ferramentas de raspagem web para Linux em 2026. Desde soluções sem código e com IA, como a (sim, aquela que a minha equipa e eu construímos), até frameworks clássicos para programadores, como Scrapy e Beautiful Soup, esta lista é o seu atalho para escolher o melhor raspador web para Linux conforme a sua necessidade — sem a dor de cabeça de tentativa e erro.
Por que as ferramentas de raspagem web para Linux importam para utilizadores de negócio
Vamos ser práticos: recolher dados manualmente arruína a produtividade. Estudos mostram que equipas que dependem de copiar e colar perdem horas todas as semanas e acumulam taxas de erro próximas de 5% — uma receita para erros caros e oportunidades perdidas (). O Linux, com a sua estabilidade, segurança e flexibilidade, é a plataforma ideal para executar scrapers que precisam de funcionar 24/7 — seja num desktop, num servidor ou na nuvem.
Casos de uso comuns para ferramentas de raspagem web no Linux:
- Geração de leads: equipas de vendas extraem novos contactos de diretórios, redes sociais ou sites de avaliações, sem o trabalho manual ().
- Monitorização de preços: equipas de e-commerce recolhem automaticamente preços e dados de stock dos concorrentes, mantendo os seus próprios preços afiados e atualizados.
- Pesquisa da concorrência: equipas de marketing e operações acompanham lançamentos de produtos, avaliações e palavras-chave de SEO — chega de trabalhar às cegas.
- Inteligência de mercado: analistas agregam notícias, fóruns e dados sociais para identificar tendências em tempo real.
- Automação de fluxos de trabalho: algumas ferramentas — especialmente as que usam IA — conseguem até automatizar fluxos na web, como preencher formulários ou navegar em painéis, diretamente a partir da sua máquina Linux.
O melhor de tudo? A ferramenta certa de raspagem web para Linux pode dar poder a utilizadores sem conhecimentos técnicos — não apenas programadores — para aceder e aproveitar dados da web e tomar decisões de negócio mais inteligentes e rápidas.
Como selecionámos o melhor raspador web para Linux
Nem todo scraper é igual, especialmente no Linux. Eis o que considerei:
- Compatibilidade com Linux: todas as ferramentas aqui correm nativamente no Linux, via navegador ou com uma solução simples de contorno (como Wine ou acesso pela nuvem).
- Facilidade de utilização: desde prompts de IA em linguagem natural até interfaces visuais de apontar e clicar, privilegiei ferramentas que ajudam não programadores a obter resultados rapidamente — sem esquecer os utilizadores avançados que querem controlo total.
- Capacidade de extração de dados: consegue lidar com conteúdo dinâmico, paginação, subpáginas e vários tipos de dados? Aguenta truques anti-rastreamento?
- Escalabilidade e automação: agendamento, raspagem na nuvem, crawling distribuído — isto é indispensável para projetos sérios de dados.
- Integração e exportação: CSV, Excel, Google Sheets, APIs — se não consegue tirar os dados da ferramenta, qual é o objetivo?
- Preço e licenciamento: grátis, open source ou pago — há opções para todos os orçamentos, de fundadores a solo a equipas empresariais.
- Comunidade e suporte: bases de utilizadores ativas, boa documentação e suporte responsivo fazem uma enorme diferença quando surge um problema.
Também incluí feedback real de utilizadores, avaliações do setor e a minha própria experiência prática com estas ferramentas. Vamos à lista.
1. Thunderbit
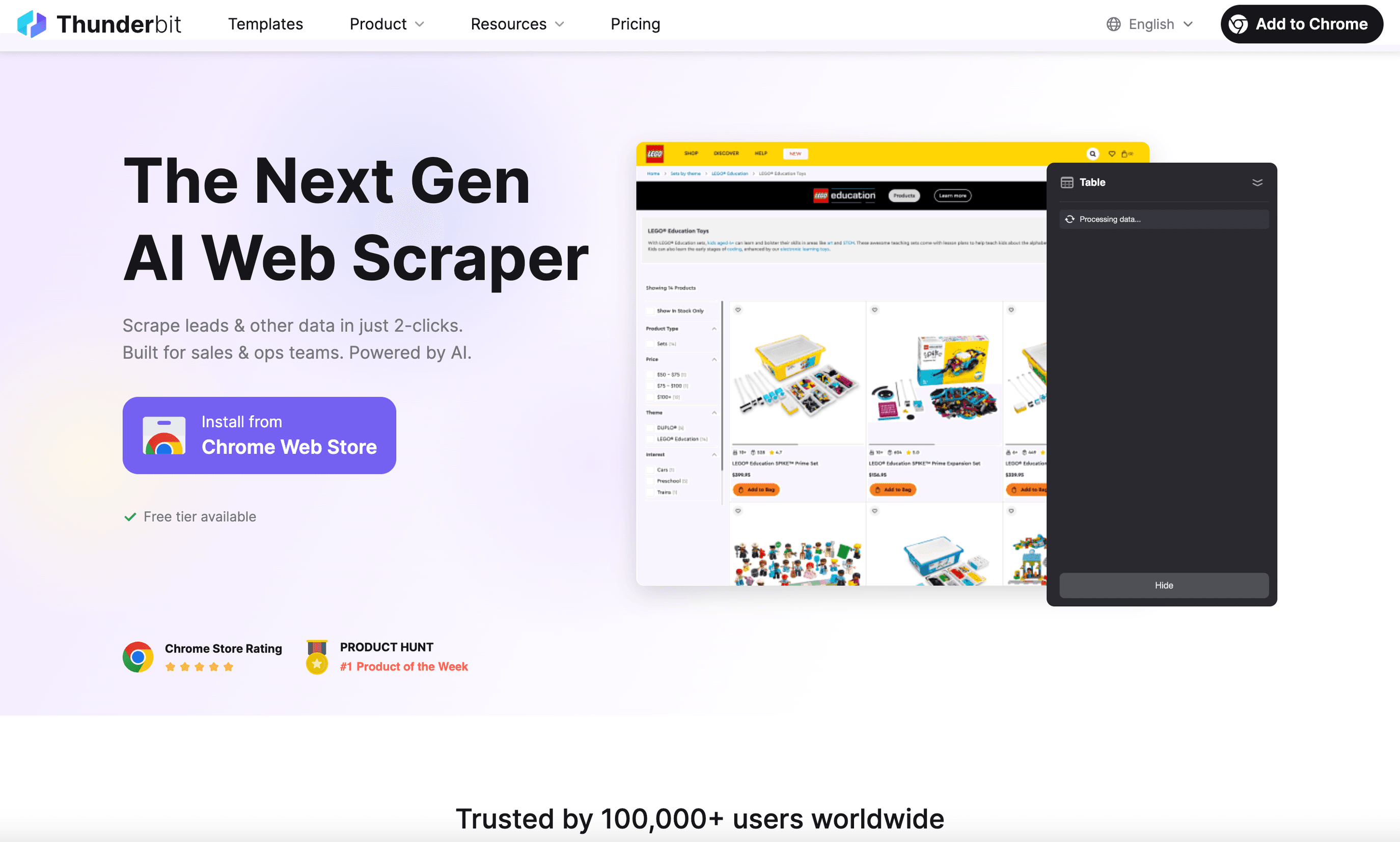 é a minha principal escolha para utilizadores de negócio que querem um raspador web para Linux que seja mesmo fácil de usar. Como uma , funciona perfeitamente no Linux (basta abrir o Chrome ou Chromium) e permite extrair dados de qualquer site em apenas dois cliques.
é a minha principal escolha para utilizadores de negócio que querem um raspador web para Linux que seja mesmo fácil de usar. Como uma , funciona perfeitamente no Linux (basta abrir o Chrome ou Chromium) e permite extrair dados de qualquer site em apenas dois cliques.
O que faz a Thunderbit destacar-se:
- Prompts em linguagem natural: basta descrever o que quer (“Extraia todos os nomes e preços de produtos desta página”) e a IA da Thunderbit trata do resto.
- Sugestão de campos por IA: clique uma vez e a Thunderbit analisa a página, sugerindo colunas e tipos de dados — sem seleção manual de campos.
- Raspagem de subpáginas e paginação: precisa de mais detalhes? A Thunderbit pode visitar cada subpágina (como páginas de detalhes de produtos) e enriquecer automaticamente a sua tabela.
- Raspagem na nuvem ou local: extraia até 50 páginas de uma vez na nuvem ou use o modo do navegador para sites que exigem login.
- Exportação instantânea: exporte com um clique para Excel, Google Sheets, Airtable, Notion, CSV ou JSON — sempre grátis.
- Ferramentas extra: extraia e-mails, números de telefone e imagens num clique. O preenchimento automático por IA também pode automatizar o preenchimento de formulários.
Preço: plano grátis (extrai de 6 a 10 páginas), planos pagos a partir de US$ 15/mês para 500 linhas (). Os utilizadores adoram a “curva de aprendizagem zero” e a forma como a ferramenta “transforma horas de trabalho em minutos” (). Para trabalhos maiores, pode ser necessário dividir em execuções menores, mas para a maioria dos casos de uso empresarial ela poupa imenso tempo.
Compatibilidade com Linux: 100%. Basta correr o Chrome/Chromium no seu desktop ou servidor Linux.
Ideal para: utilizadores de negócio sem perfil técnico (vendas, marketing, operações) que querem a configuração mais rápida e simples.
2. Scrapy
 é o padrão de ouro para programadores Python que querem um raspador web flexível e escalável para Linux. É open source, extremamente rápido (crawling assíncrono) e consegue lidar com tudo, desde raspagens simples até crawls distribuídos em grande escala.
é o padrão de ouro para programadores Python que querem um raspador web flexível e escalável para Linux. É open source, extremamente rápido (crawling assíncrono) e consegue lidar com tudo, desde raspagens simples até crawls distribuídos em grande escala.
Principais recursos:
- Crawling assíncrono e de alta velocidade — perfeito para raspar milhares de páginas.
- Altamente extensível: plugins para proxies, CAPTCHAs e muito mais.
- Integração com o ecossistema de dados em Python: exporta para JSON, CSV, bases de dados ou pandas.
- Lida com cookies, sessões e auto-throttling.
Preço: 100% grátis e open source.
Compatibilidade com Linux: nativa (instalação via pip). Funciona muito bem em servidores e contentores.
Ideal para: programadores a construir scrapers personalizados e de grande escala.
Atenção: há uma curva de aprendizagem para quem não programa, mas se conhece Python, é difícil bater o Scrapy.
3. Beautiful Soup
 é uma biblioteca Python leve para análise de HTML e XML. É a escolha certa para raspagens rápidas e diretas ou para limpar páginas web desorganizadas.
é uma biblioteca Python leve para análise de HTML e XML. É a escolha certa para raspagens rápidas e diretas ou para limpar páginas web desorganizadas.
Principais recursos:
- API simples e amigável — ótima para iniciantes.
- Funciona bem com requests para obter páginas.
- Lida com HTML danificado com elegância.
Preço: grátis e open source.
Compatibilidade com Linux: 100% (Python puro).
Ideal para: programadores e cientistas de dados que fazem tarefas pequenas ou médias de raspagem ou parsing.
Limitações: não lida com JavaScript ou conteúdo dinâmico — combine com Selenium ou Puppeteer se precisar disso.
4. Selenium
 é o clássico framework de automação de navegador. Permite controlar Chrome, Firefox ou outros navegadores para raspar sites dinâmicos e carregados de JavaScript.
é o clássico framework de automação de navegador. Permite controlar Chrome, Firefox ou outros navegadores para raspar sites dinâmicos e carregados de JavaScript.
Principais recursos:
- Automatiza navegadores reais — pode fazer login, clicar, deslocar e interagir como uma pessoa.
- Suporta Python, Java, C# e mais.
- Modo headless para correr em servidores Linux.
Preço: grátis e open source.
Compatibilidade com Linux: suporte total (basta instalar o driver certo do navegador).
Ideal para: engenheiros de QA, programadores de scraping e qualquer pessoa que precise simular comportamento de utilizador.
Atenção: consome muitos recursos e é mais lento do que scrapers puramente HTTP, mas às vezes é a única forma de obter os dados de que precisa.
5. Puppeteer
 é uma biblioteca Node.js da Google para controlar o Chrome/Chromium em modo headless. É como o Selenium, mas com uma API JavaScript moderna e integração estreita com os recursos do Chrome.
é uma biblioteca Node.js da Google para controlar o Chrome/Chromium em modo headless. É como o Selenium, mas com uma API JavaScript moderna e integração estreita com os recursos do Chrome.
Principais recursos:
- Executa JavaScript, lida com conteúdo dinâmico e tira capturas de ecrã.
- Rápido, estável e fácil de usar para devs de Node.js.
- Interceta pedidos de rede e bloqueia recursos indesejados.
Preço: grátis e open source.
Compatibilidade com Linux: instala o Chromium automaticamente; funciona em modo headless por defeito.
Ideal para: programadores que raspam aplicações web modernas ou sites de página única.
6. Octoparse
 é um raspador web sem código com interface de arrastar e largar e muitos modelos prontos. Embora a aplicação de desktop seja apenas para Windows/Mac, utilizadores de Linux podem aceder à plataforma na nuvem da Octoparse através do navegador ou correr a aplicação Windows com Wine.
é um raspador web sem código com interface de arrastar e largar e muitos modelos prontos. Embora a aplicação de desktop seja apenas para Windows/Mac, utilizadores de Linux podem aceder à plataforma na nuvem da Octoparse através do navegador ou correr a aplicação Windows com Wine.
Principais recursos:
- Mais de 100 modelos prontos de raspagem para sites como Amazon, eBay, Zillow, etc.
- Designer visual de fluxos de trabalho — apontar e clicar para construir o seu scraper.
- Raspagem e agendamento na nuvem — deixe os servidores da Octoparse fazerem o trabalho pesado.
- Exporta para Excel, CSV, JSON e bases de dados.
Preço: plano grátis (funcionalidades limitadas), planos pagos a partir de US$ 75–US$ 89/mês.
Compatibilidade com Linux: acesso via nuvem/web; aplicação de desktop via Wine.
Ideal para: não programadores que precisam rapidamente de dados de e-commerce ou marketplaces.
7. PhantomJS
 é um navegador WebKit headless que já foi a referência para automação leve de navegador. Hoje está descontinuado, mas ainda corre no Linux para tarefas simples ou legadas.
é um navegador WebKit headless que já foi a referência para automação leve de navegador. Hoje está descontinuado, mas ainda corre no Linux para tarefas simples ou legadas.
Principais recursos:
- Programável em JavaScript.
- Lida com JavaScript moderado e tira capturas de ecrã/PDFs.
- Não precisa de interface gráfica.
Preço: grátis e open source.
Compatibilidade com Linux: binário nativo.
Ideal para: projetos legados ou ambientes em que não é possível instalar o Chrome.
Observação: já não recebe manutenção — sites modernos podem não funcionar bem.
8. ParseHub
 é um raspador web visual e multiplataforma com aplicação nativa para Linux. É ótimo para não programadores que querem raspar sites complexos e dinâmicos.
é um raspador web visual e multiplataforma com aplicação nativa para Linux. É ótimo para não programadores que querem raspar sites complexos e dinâmicos.
Principais recursos:
- Interface de apontar e clicar — selecione elementos e crie fluxos visualmente.
- Lida com conteúdo dinâmico, mapas, scroll infinito e mais.
- Execução e agendamento na nuvem.
- Exporta para CSV, JSON ou via API.
Preço: plano grátis (5 projetos), planos pagos a partir de US$ 189/mês.
Compatibilidade com Linux: aplicação nativa para Linux, Windows e Mac.
Ideal para: analistas e utilizadores semitécnicos que querem controlo sem programar.
9. Kimurai
 é um framework de raspagem web em Ruby com suporte nativo ao Linux. É como o Scrapy, só que para programadores Ruby.
é um framework de raspagem web em Ruby com suporte nativo ao Linux. É como o Scrapy, só que para programadores Ruby.
Principais recursos:
- Suporte a múltiplos navegadores: Chrome headless, Firefox, PhantomJS ou HTTP puro.
- Processamento assíncrono para alta concorrência.
- DSL Ruby limpa para escrever spiders.
Preço: grátis e open source.
Compatibilidade com Linux: 100% (Ruby).
Ideal para: programadores Ruby ou equipas Rails que precisam de raspagem personalizada e com alta concorrência.
10. Apify
 é uma plataforma de raspagem web baseada na nuvem com SDKs open source e um marketplace de “actors” prontos. Pode executar scrapers na sua máquina Linux ou na nuvem.
é uma plataforma de raspagem web baseada na nuvem com SDKs open source e um marketplace de “actors” prontos. Pode executar scrapers na sua máquina Linux ou na nuvem.
Principais recursos:
- SDKs para Node.js, Python e mais.
- Marketplace de scrapers prontos.
- Execução na nuvem, agendamento e integração via API.
Preço: plano grátis, pagamento conforme o uso na nuvem.
Compatibilidade com Linux: CLI/SDK corre no Linux; plataforma na nuvem acessível pelo navegador.
Ideal para: programadores que querem uma mistura de código personalizado e infraestrutura pronta na nuvem.
11. Colly
 é um framework de raspagem web baseado em Go criado para velocidade e eficiência. Se é programador Go, esta é a sua ferramenta.
é um framework de raspagem web baseado em Go criado para velocidade e eficiência. Se é programador Go, esta é a sua ferramenta.
Principais recursos:
- Raspagem super-rápida e concorrente — mais de 1.000 pedidos/segundo num único núcleo.
- Crawling educado (respeita robots.txt), gestão de sessão/cookies.
- Baixo consumo de memória.
Preço: grátis e open source.
Compatibilidade com Linux: binários nativos de Go.
Ideal para: programadores Go que precisam de raspagem de alto desempenho.
12. PySpider
 é um sistema de crawler em Python com interface web. Pode gerir, agendar e monitorizar crawls no navegador.
é um sistema de crawler em Python com interface web. Pode gerir, agendar e monitorizar crawls no navegador.
Principais recursos:
- Interface web para programação e monitorização.
- Crawling distribuído, agendamento e tentativas automáticas.
- Integração com bases de dados e filas de mensagens.
Preço: grátis e open source.
Compatibilidade com Linux: concebido para implementação em Linux.
Ideal para: equipas que gerem vários projetos de scraping através de uma interface web.
13. WebHarvy
 é um scraper visual de apontar e clicar para Windows, mas utilizadores de Linux podem executá-lo via Wine. É conhecido pela deteção de padrões e pelo modelo de compra única.
é um scraper visual de apontar e clicar para Windows, mas utilizadores de Linux podem executá-lo via Wine. É conhecido pela deteção de padrões e pelo modelo de compra única.
Principais recursos:
- Navegue e clique para selecionar dados — sem programar.
- Deteção automática de padrões para listas.
- Exporta para CSV, JSON, XML e SQL.
Preço: licença única de cerca de US$ 139.
Compatibilidade com Linux: corre via Wine ou máquina virtual.
Ideal para: iniciantes ou profissionais independentes que querem um scraper visual rápido.
14. OutWit Hub
 é uma aplicação GUI nativa para Linux focada em raspagem web. Reconhece padrões de dados automaticamente e oferece recursos poderosos de extração e automação.
é uma aplicação GUI nativa para Linux focada em raspagem web. Reconhece padrões de dados automaticamente e oferece recursos poderosos de extração e automação.
Principais recursos:
- Deteta automaticamente links, imagens, tabelas, e-mails e muito mais.
- Editor de scripts para extração personalizada.
- Automação por macros e agendamento.
Preço: versão grátis (limitada), licença Pro na ordem dos US$ 50–US$ 100.
Compatibilidade com Linux: aplicação nativa para Linux, Windows e Mac.
Ideal para: não programadores com alguma inclinação técnica que querem um scraper desktop com GUI.
15. Portia
 é um raspador web visual e open source da Scrapinghub. Corre no navegador e permite anotar páginas para treinar scrapers.
é um raspador web visual e open source da Scrapinghub. Corre no navegador e permite anotar páginas para treinar scrapers.
Principais recursos:
- Interface baseada no navegador para extração visual.
- Integra-se com o Scrapy para projetos personalizados.
- Open source e extensível.
Preço: grátis e open source.
Compatibilidade com Linux: baseado no navegador; funciona em qualquer sistema operativo.
Ideal para: utilizadores que querem raspagem visual open source com integração ao Scrapy.
16. Content Grabber
 é um scraper visual de nível empresarial para Windows, mas pode ser executado no Linux via Wine ou virtualização.
é um scraper visual de nível empresarial para Windows, mas pode ser executado no Linux via Wine ou virtualização.
Principais recursos:
- Editor visual mais scripts em C# para lógica avançada.
- Gestão de múltiplos agentes e agendamento.
- Integra-se com bases de dados, APIs e muito mais.
Preço: licenças na casa dos milhares; edição server a partir de US$ 69/mês.
Compatibilidade com Linux: via Wine ou máquina virtual.
Ideal para: agências e grandes equipas que gerem muitos projetos de scraping.
17. Helium
 é uma biblioteca Python que simplifica a automação com Selenium. Foi criada para tornar a programação de navegador mais amigável.
é uma biblioteca Python que simplifica a automação com Selenium. Foi criada para tornar a programação de navegador mais amigável.
Principais recursos:
- Comandos intuitivos como
click("Login")ouwrite("email"). - Automatiza Chrome e Firefox.
- Ótima para scripts rápidos e tarefas de automação.
Preço: grátis e open source.
Compatibilidade com Linux: funciona no Linux (baseado em Selenium).
Ideal para: utilizadores de Python que acham o Selenium demasiado pesado.
18. Dexi.io
 é uma plataforma baseada na nuvem para extração de dados e automação. É acessível pelo navegador, por isso os utilizadores de Linux podem usá-la sem instalar nada.
é uma plataforma baseada na nuvem para extração de dados e automação. É acessível pelo navegador, por isso os utilizadores de Linux podem usá-la sem instalar nada.
Principais recursos:
- Designer visual de fluxos de trabalho para raspagem e automação.
- Agendamento, transformação de dados e integração via API.
- Escalabilidade e suporte de nível empresarial.
Preço: a partir de US$ 119/mês (Standard); planos superiores para escalas maiores.
Compatibilidade com Linux: aplicação web — funciona em qualquer sistema operativo.
Ideal para: profissionais e empresas que precisam de extração de dados web escalável e integrada.
Tabela rápida de comparação: ferramentas de raspagem web para Linux em resumo
| Ferramenta | Tipo / Recursos principais | Ideal para | Preço | Compatibilidade com Linux |
|---|---|---|---|---|
| Thunderbit | Extensão Chrome com IA, 2 cliques, subpáginas, nuvem/local | Utilizadores de negócio sem perfil técnico | Grátis, a partir de US$ 15/mês | ✔ Chrome no Linux |
| Scrapy | Framework Python, assíncrono, CLI, altamente extensível | Programadores, scrapers personalizados em grande escala | Grátis | ✔ Nativo |
| Beautiful Soup | Biblioteca Python, parsing simples de HTML/XML | Devs, cientistas de dados, tarefas pequenas | Grátis | ✔ Nativo |
| Selenium | Automação de navegador, sites pesados em JS | QA, devs, conteúdo dinâmico | Grátis | ✔ Nativo |
| Puppeteer | Node.js, Chrome headless, renderização JS | Devs Node, apps web modernos | Grátis | ✔ Nativo |
| Octoparse | Sem código, arrastar e largar, modelos na nuvem | Não programadores, e-commerce | Grátis, a partir de US$ 75/mês | ◐ Nuvem/Wine |
| PhantomJS | WebKit headless, JS programável | Legado, leve, sem Chrome | Grátis | ✔ Nativo |
| ParseHub | Visual, multiplataforma, apontar e clicar | Analistas, utilizadores semitécnicos | Grátis, a partir de US$ 189/mês | ✔ Nativo |
| Kimurai | Framework Ruby, múltiplos navegadores, assíncrono | Devs Ruby, alta concorrência | Grátis | ✔ Nativo |
| Apify | Plataforma na nuvem, SDKs, marketplace | Devs, híbrido entre código e nuvem | Plano grátis, por uso | ✔ Nativo/Nuvem |
| Colly | Framework Go, rápido, concorrente | Devs Go, alto desempenho | Grátis | ✔ Nativo |
| PySpider | Python, interface web, agendamento, distribuído | Equipas, múltiplos projetos | Grátis | ✔ Nativo |
| WebHarvy | Visual, deteção de padrões, licença única | Iniciantes, profissionais independentes | ~US$ 139 uma vez | ◐ Wine/VM |
| OutWit Hub | GUI nativa, deteção automática de dados, scripts | Não programadores, GUI desktop | Grátis, Pro US$ 50–US$ 100 | ✔ Nativo |
| Portia | Open source, visual, baseado no navegador | Open source, integração com Scrapy | Grátis | ✔ Navegador |
| Content Grabber | Empresarial, visual, scripts, multiagente | Agências, grandes equipas | $$$, a partir de US$ 69/mês | ◐ Wine/VM |
| Helium | Python, Selenium simplificado, API intuitiva | Utilizadores de Python, automação rápida | Grátis | ✔ Nativo |
| Dexi.io | Nuvem, fluxo visual, agendamento, API | Empresarial, automação escalável | A partir de US$ 119/mês | ✔ Navegador |
Como escolher o raspador web certo para Linux: principais considerações
Escolher a ferramenta certa é uma questão de alinhar as suas necessidades com as suas competências:
- Nível de competência técnica: quem não programa deve considerar Thunderbit, ParseHub, Octoparse ou OutWit Hub. Os programadores podem desbloquear mais poder com Scrapy, Puppeteer, Colly ou Kimurai.
- Complexidade dos dados: para páginas estáticas, Beautiful Soup ou Colly são rápidos e simples. Para sites dinâmicos e pesados em JavaScript, vai querer Selenium, Puppeteer ou uma ferramenta visual com suporte para JS.
- Escala e frequência: para tarefas pontuais, ferramentas sem código ou scrapers na nuvem bastam. Para crawls agendados e em grande escala, escolha Scrapy, PySpider ou Apify.
- Necessidade de integração: precisa de exportar para Excel, Sheets ou uma base de dados? Verifique se a ferramenta suporta o seu fluxo de trabalho.
- Orçamento: opções grátis e open source não faltam para programadores. Para utilizadores de negócio, Thunderbit e ParseHub oferecem pontos de entrada acessíveis, enquanto equipas empresariais podem investir em Dexi.io ou Content Grabber.
- Suporte e comunidade: ferramentas open source têm comunidades grandes; ferramentas comerciais oferecem suporte dedicado.
Dica profissional: não tenha medo de combinar ferramentas. Use a Thunderbit para prototipar e identificar padrões de dados e, depois, mude para o Scrapy em recolhas à escala de produção. Ou use o Selenium para fazer login e capturar cookies de sessão, e depois passe o trabalho para Colly ou Scrapy para raspar em alta velocidade.
Conclusão: encontre a sua melhor ferramenta de raspagem web para Linux em 2026
Os utilizadores de Linux têm uma enorme oferta de opções em 2026. Seja alguém que quer uma ferramenta sem código, com IA, que entrega resultados em minutos (Thunderbit), um framework robusto para programadores (Scrapy, Colly) ou uma plataforma de nível empresarial (Dexi.io), existe um raspador web para Linux que se encaixa nas suas necessidades e no seu fluxo de trabalho.
Principais conclusões:
- O Linux é a espinha dorsal da infraestrutura moderna de dados — a maioria dos melhores scrapers corre nativamente ou via navegador.
- Ferramentas com IA e sem código estão a democratizar a raspagem web para utilizadores de negócio.
- Frameworks para programadores continuam a dominar em flexibilidade, velocidade e escala.
- Teste antes de comprar — a maioria das ferramentas oferece planos grátis ou avaliações.
Pronto para começar? ou consulte o para mais guias sobre raspagem web, automação e crescimento orientado por dados.
FAQs
1. Qual é o raspador web mais fácil para Linux se eu não souber programar?
é a melhor escolha para utilizadores sem perfil técnico. Funciona como extensão do Chrome no Linux, usa IA para automatizar tudo e permite extrair dados em apenas dois cliques.
2. Qual raspador web para Linux é melhor para projetos personalizados em grande escala?
é a opção favorita dos programadores. É rápido, escalável e altamente personalizável — perfeito para recolhas grandes e recorrentes.
3. Posso raspar sites dinâmicos ou pesados em JavaScript no Linux?
Sim! Use ou para controlar navegadores reais e extrair conteúdo dinâmico. Ferramentas visuais como ParseHub e Thunderbit também dão suporte a sites dinâmicos.
4. Existem ferramentas grátis de raspagem web para Linux para uso empresarial?
Com certeza. Scrapy, Beautiful Soup, Selenium, Colly, PySpider e Kimurai são grátis e open source. Thunderbit e ParseHub oferecem planos gratuitos para tarefas menores.
5. Como escolher entre raspadores Linux sem código e baseados em código?
Se quer velocidade e simplicidade, vá para sem código (Thunderbit, ParseHub, Octoparse). Se precisa de flexibilidade, automação ou integração com outros sistemas, ferramentas baseadas em código (Scrapy, Puppeteer, Colly) são a melhor aposta.
Boa raspagem — e que os seus projetos de dados impulsionados por Linux corram mais suaves do que uma instalação nova do Ubuntu. Se quiser ver mais dicas sobre raspagem web, consulte o ou subscreva o nosso para tutoriais práticos.
Saiba mais