

A Temu hoje alcança mais de 416 milhões de usuários ativos mensais em mais de 50 mercados. O catálogo vai de utensílios de cozinha a acessórios para pets, passando por fitas de LED. Se você trabalha com ecommerce, dropshipping ou inteligência competitiva, provavelmente já quis levar os dados da Temu para uma planilha — e depois descobriu que a Temu realmente, mas realmente, não quer que isso aconteça.
Passei bastante tempo pesquisando e testando ferramentas de scraping para sites de ecommerce protegidos. A Temu é um dos alvos mais difíceis que existem. A maioria dos guias online ou entrega um tutorial em Python que quebra em uma semana, ou aponta para APIs corporativas que custam mais do que o seu orçamento mensal de anúncios.
Na prática, a maioria dos usuários de negócios — dropshippers, operadores individuais, equipes de marketing — só quer uma planilha limpa com nomes de produtos, preços, imagens, avaliações e informações do vendedor. Ninguém quer depurar scripts em Playwright às 2h da manhã.
Este guia foi criado para preencher essa lacuna: uma análise prática, organizada por nível de habilidade, dos melhores scrapers de Temu que realmente funcionam em 2026, além das melhores práticas que transformam uma extração bruta em inteligência competitiva contínua. Seja você um completo iniciante ou um desenvolvedor montando um pipeline de dados, há uma seção aqui para você.
Experimente o Thunderbit para extrair dados da Temu
Por que extrair dados da Temu? Principais casos de uso para equipes de negócios
Os dados da Temu não são apenas interessantes — são estrategicamente úteis.
A plataforma se tornou uma força na definição de preços em categorias de produtos de baixo e médio ticket. Mesmo que você não venda na Temu, seus clientes estão comparando os seus preços com o que veem lá. Veja como diferentes equipes usam os dados da Temu:
| Caso de uso | Dados necessários | Por que isso importa |
|---|---|---|
| Pesquisa de produtos para dropshipping | Título, preço, imagem, avaliação, número de avaliações, quantidade vendida, variações | Encontra produtos de baixo custo com sinais de demanda para comparação entre Amazon, Shopify, AliExpress, TikTok Shop |
| Precificação competitiva | Preço atual, preço original, % de desconto, moeda, frete, carimbo de data/hora | Cria uma base para estratégia de preços e planejamento de promoções |
| Sourcing de produtos | Especificações, imagens, variações, vendedor/loja, ID do item, categoria | Identifica tipos de produto e anúncios no estilo de fornecedor que valem uma verificação mais profunda |
| Análise de tendências de mercado | Palavra-chave de busca, categoria, quantidade vendida, número de avaliações, avaliação | Mostra quais produtos estão ganhando tração entre categorias |
| Marketing e pesquisa criativa | Título, imagem, número de avaliações, avaliação, descrições, rótulos de categoria | Revela mensagens, ganchos visuais, combos e alegações usados por anúncios de alto volume |
| Monitoramento de estoque e disponibilidade | URL do produto, disponibilidade, estimativa de frete, preço, carimbo de data/hora | Registra rupturas de estoque, mudanças de depósito local e variações de preço ao longo do tempo |
Quem procura por “melhores scrapers de Temu” costuma se dividir em três grupos. Usuários sem conhecimento técnico querem uma extensão do Chrome que gere uma planilha. Operadores com algum conhecimento técnico querem uma ferramenta visual com modelos e agendamento. Desenvolvedores querem uma API, um script em Playwright e uma estratégia de proxy.
Este artigo cobre os três — mas começa pelo maior grupo: pessoas que precisam de dados, não de código.
O que faz os melhores scrapers de Temu se destacarem em 2026
Um scraper que lida com Amazon ou Shopify não necessariamente sobrevive na Temu. Os critérios de avaliação para este artigo são:
- Confiabilidade na Temu — Ele realmente entrega dados limpos ou é bloqueado, retorna linhas vazias ou quebra depois de uma mudança no layout?
- Facilidade de uso — Um usuário de negócios sem conhecimentos técnicos consegue começar sem escrever código?
- Completude dos dados — Ele oferece enriquecimento de subpáginas (visitando cada página de detalhe do produto para especificações, variações, informações do vendedor)?
- Esforço de manutenção — Ele se adapta quando a Temu muda a estrutura das páginas?
- Agendamento e monitoramento — Ele consegue executar extrações recorrentes e exportar para um destino de dados vivo?
- Destinos de exportação — CSV, Excel, Google Sheets, Airtable, Notion, JSON?
- Clareza de custo — Quanto custa de fato, por mês, um fluxo realista de extração na Temu?
Relatos da comunidade no r/webscraping do Reddit descrevem consistentemente a Temu como um dos sites de ecommerce mais difíceis de extrair. Um usuário escreveu que “nem consegue obter um preço como comprador”, enquanto outro observou que Temu e Shopee têm equipes fortalecendo continuamente os mecanismos anti-bot. Não há dados públicos de taxa de falha específicos da Temu, mas o Relatório Bad Bot 2025 da Imperva mostrou que o tráfego automatizado superou o tráfego humano, com bots representando 51% de todo o tráfego da internet. Esse é o ambiente contra o qual a Temu está se defendendo.
Defesas anti-bot da Temu: por que a maioria dos scrapers falha
A maioria dos artigos sobre scraping da Temu gasta uma frase nas medidas anti-bot: “a Temu usa anti-bot”. Isso não ajuda.
Se você estiver escolhendo uma ferramenta, precisa saber quais defesas a Temu usa e quais recursos da ferramenta vencem cada uma delas. Aqui está o mapa prático:
| Defesa da Temu | O que faz | Capacidade necessária na ferramenta | Exemplos de ferramentas |
|---|---|---|---|
| WAF / verificações do Cloudflare no navegador | Bloqueia user-agents automatizados, identifica bots por fingerprint, retorna páginas de desafio | Infraestrutura em nuvem com IPs residenciais rotativos e fingerprints reais de navegador | Thunderbit (scraping em nuvem), Bright Data, Oxylabs, ScraperAPI |
| Renderização pesada em JavaScript | Os dados do produto carregam via JS; o HTML bruto fica vazio | Navegador headless ou renderização completa no navegador | Thunderbit (modo de scraping no navegador), Playwright, Selenium, ParseHub, atores de navegador do Apify |
| Seletores CSS dinâmicos | Os nomes das classes mudam entre implantações, quebrando scrapers baseados em CSS | Detecção de campos com IA (sem depender de seletores fixos) | Thunderbit (a IA lê a página do zero a cada vez), criador de scraper com IA da Bright Data |
| Limitação de taxa | Reduz a velocidade de requisições sequenciais | Requisições concorrentes na nuvem com limitação inteligente | Thunderbit (até 50 páginas por vez via nuvem), ScraperAPI, Bright Data |
| Desafios CAPTCHA | Interrompe sessões após comportamento suspeito | Resolução de CAPTCHA integrada ou estratégia com menos gatilhos | Bright Data, Oxylabs, ScraperAPI premium/ultra-premium |
| Scroll infinito / carregamento preguiçoso | Só os primeiros produtos aparecem sem interação | Scroll inteligente, detecção de paginação, automação de interações | paginação do Thunderbit, scroll inteligente do Apify, construtor de fluxos do Octoparse |
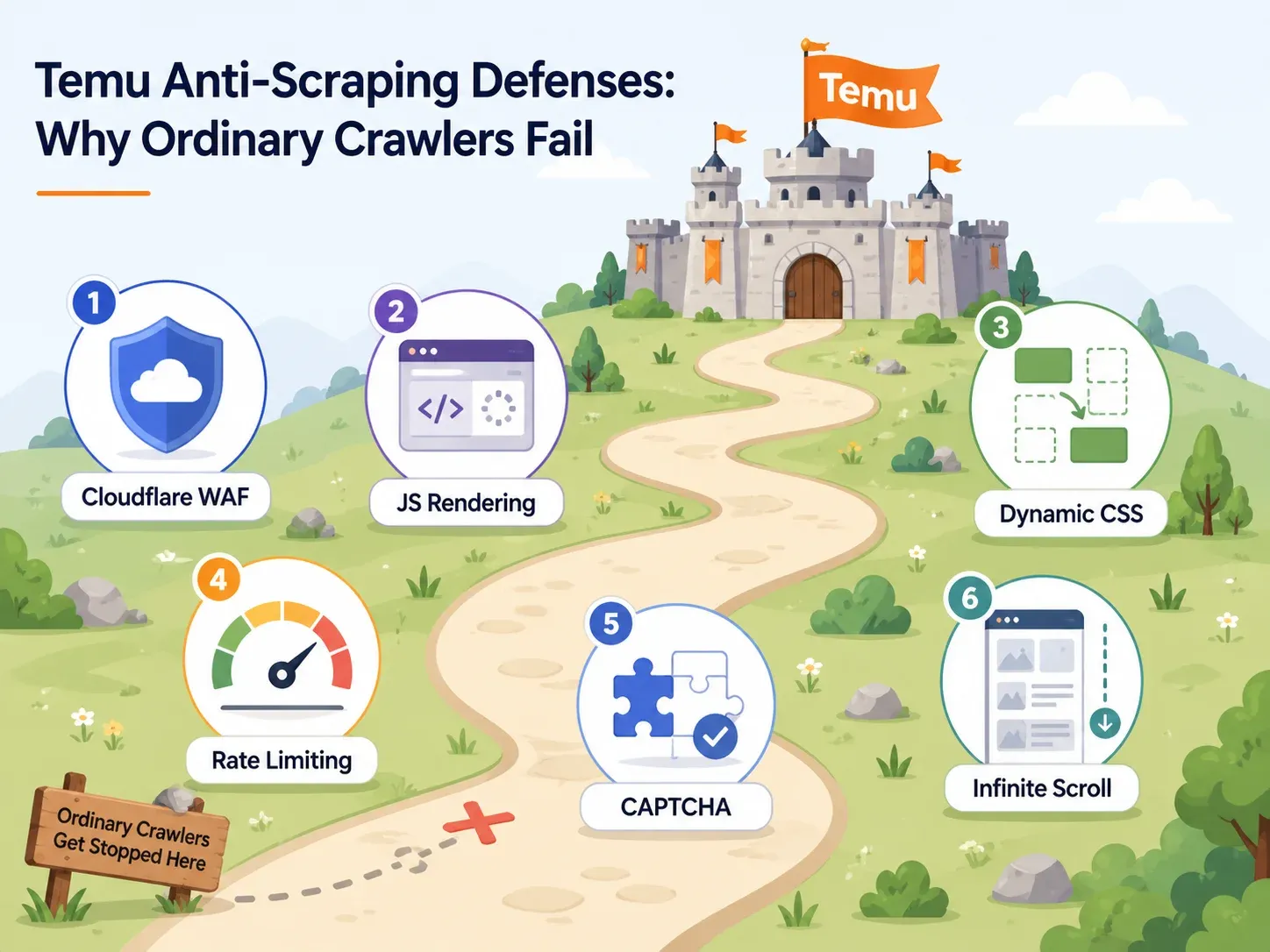
WAF do Cloudflare e bloqueio de IP
A porta de entrada da Temu é protegida por verificações de integridade do navegador no estilo Cloudflare. Requisições HTTP básicas — do tipo que um simples requests.get() em Python faz — são desafiadas, recebem 403 ou são atendidas com dados incompletos.
As ferramentas que funcionam aqui precisam de IPs residenciais ou móveis rotativos e fingerprints reais de navegador. A análise 2025 do Radar da Cloudflare informou que, no início de 2025, os bots não baseados em IA passaram a ser responsáveis por cerca de metade das requisições de páginas HTML. Essa é a escala da automação da qual plataformas como a Temu estão se defendendo.
Renderização em JavaScript e seletores dinâmicos
É aqui que a maioria dos scrapers iniciantes falha em silêncio.
Se você visualizar o código-fonte da página da Temu, muitas vezes encontrará apenas uma casca vazia — os cards de produto, preços e imagens reais são injetados por JavaScript depois que a página carrega. Um scraper que lê apenas HTML bruto não retorna nada útil. Além disso, os nomes das classes CSS e as estruturas do DOM da Temu mudam entre implantações. Um scraper que depende de um seletor CSS fixo, como .product-card__price, funciona hoje e amanhã pode devolver colunas vazias.
Scrapers baseados em IA (como o Thunderbit) leem a página semanticamente a cada vez, então não dependem de nomes de classe específicos permanecerem iguais.
Limitação de taxa e desafios CAPTCHA
Se você atingir a Temu rápido demais ou muitas vezes a partir de um único IP, vai disparar limitação de taxa ou desafios CAPTCHA. Algumas ferramentas lidam com isso por meio de limitação inteligente e resolução de CAPTCHA integrada. Outras deixam isso por sua conta — o que, para um usuário sem conhecimento técnico, é praticamente um beco sem saída.
Para scraping em nuvem, o ponto-chave é ter requisições concorrentes distribuídas entre IPs limpos com lógica automática de retentativa.
Melhores scrapers de Temu por nível de habilidade: análise completa
Encontre sua linha e vá direto para a seção correspondente:
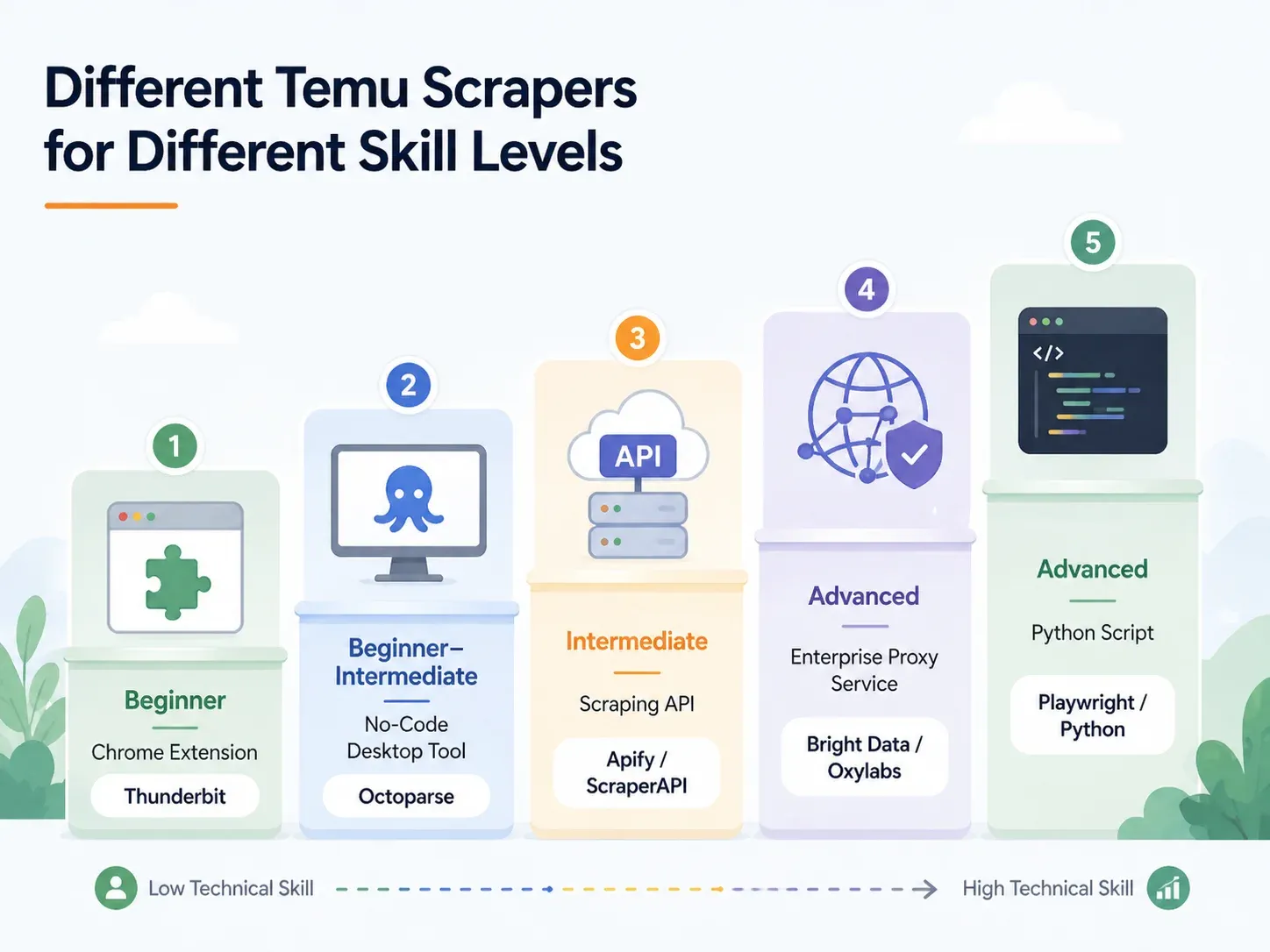
| Abordagem | Nível de habilidade | Tempo de configuração | Tratamento anti-bot | Ideal para |
|---|---|---|---|---|
| Extensão Chrome com IA (ex.: Thunderbit) | Iniciante | < 2 min | Tratado (nuvem ou navegador) | Dropshippers, profissionais de marketing, operações de ecommerce |
| Ferramenta desktop sem código (ex.: Octoparse, ParseHub) | Iniciante–Intermediário | 10–60 min | Parcial (configuração de proxy necessária) | Extração recorrente com modelos |
| API/serviço de scraping (ex.: ScraperAPI, Apify) | Intermediário | 15–45 min | Integrado | Desenvolvedores integrando em pipelines |
| Proxy gerenciado/Corporativo (ex.: Bright Data, Oxylabs) | Avançado/Corporativo | Horas–dias | Infraestrutura completa | Alto volume, entrega para data warehouse |
| Script Python personalizado (Playwright/Selenium) | Avançado | 1–4 h+ | Manual (configuração de proxy + CAPTCHA) | Controle total, personalização de casos extremos |
Thunderbit: o melhor scraper de Temu para usuários sem conhecimento técnico
Thunderbit é uma extensão do Chrome com IA criada para usuários de negócios — equipes de vendas, operadores de ecommerce, dropshippers, profissionais de marketing — que precisam de dados estruturados de sites sem escrever código. Trabalho na equipe do Thunderbit, então conheço o produto muito bem. Vou ser direto sobre o que ele faz e onde se encaixa.
O fluxo principal tem dois cliques: abrir uma página da Temu, clicar em AI Suggest Fields, revisar as colunas sugeridas (nome do produto, preço, imagem, avaliação etc.) e depois clicar em Scrape.
A IA do Thunderbit lê a estrutura da página e propõe automaticamente nomes de colunas e tipos de dados. Ela não depende de seletores CSS fixos, então quando a Temu muda os nomes das classes ou o layout dos cards, o scraper se adapta.
Recursos principais para a Temu:
- Modo de scraping em nuvem: Mais rápido para páginas públicas, processa até 50 páginas por vez. Ideal para páginas de categoria, resultados de busca e listagens de produtos que não exigem login.
- Modo de scraping no navegador: Usa sua sessão atual do Chrome, incluindo cookies, localidade e estado de login. É o melhor quando região, pop-ups ou conteúdo autenticado influenciam o que a página mostra.
- Scrape Subpages: Depois de extrair uma página de listagem, clique em "Scrape Subpages" para visitar cada página de detalhe do produto e acrescentar colunas como descrição completa, variações, informações do vendedor, estimativa de frete e especificações — sem configuração extra.
- Field AI Prompts: Classifique, traduza ou reformate dados durante a extração. Por exemplo: "Classifique este produto em Utensílios de Cozinha, Eletrodomésticos Pequenos, Organização ou Outro."
- Extração agendada: Defina um agendamento em linguagem natural ("toda segunda-feira às 9h"), informe as URLs e o Thunderbit executa a extração na nuvem e exporta para Google Sheets, Airtable ou outro destino.
- Exportações gratuitas: Excel, CSV, Google Sheets, Airtable, Notion, JSON — sem bloqueio pago para exportação. As imagens são exportadas como anexos reais no Airtable e no Notion.
Preço: plano gratuito com até 6 páginas (ou 10 com bônus de teste); os planos pagos começam em torno de $15/mês (mensal) ou $9/mês (anual) para 500 créditos, com 1 crédito = 1 linha de saída.
Extraia dados da Temu com IA Get Started Free
Comparação lado a lado: Thunderbit vs. script Python na mesma página da Temu
O contraste é evidente:
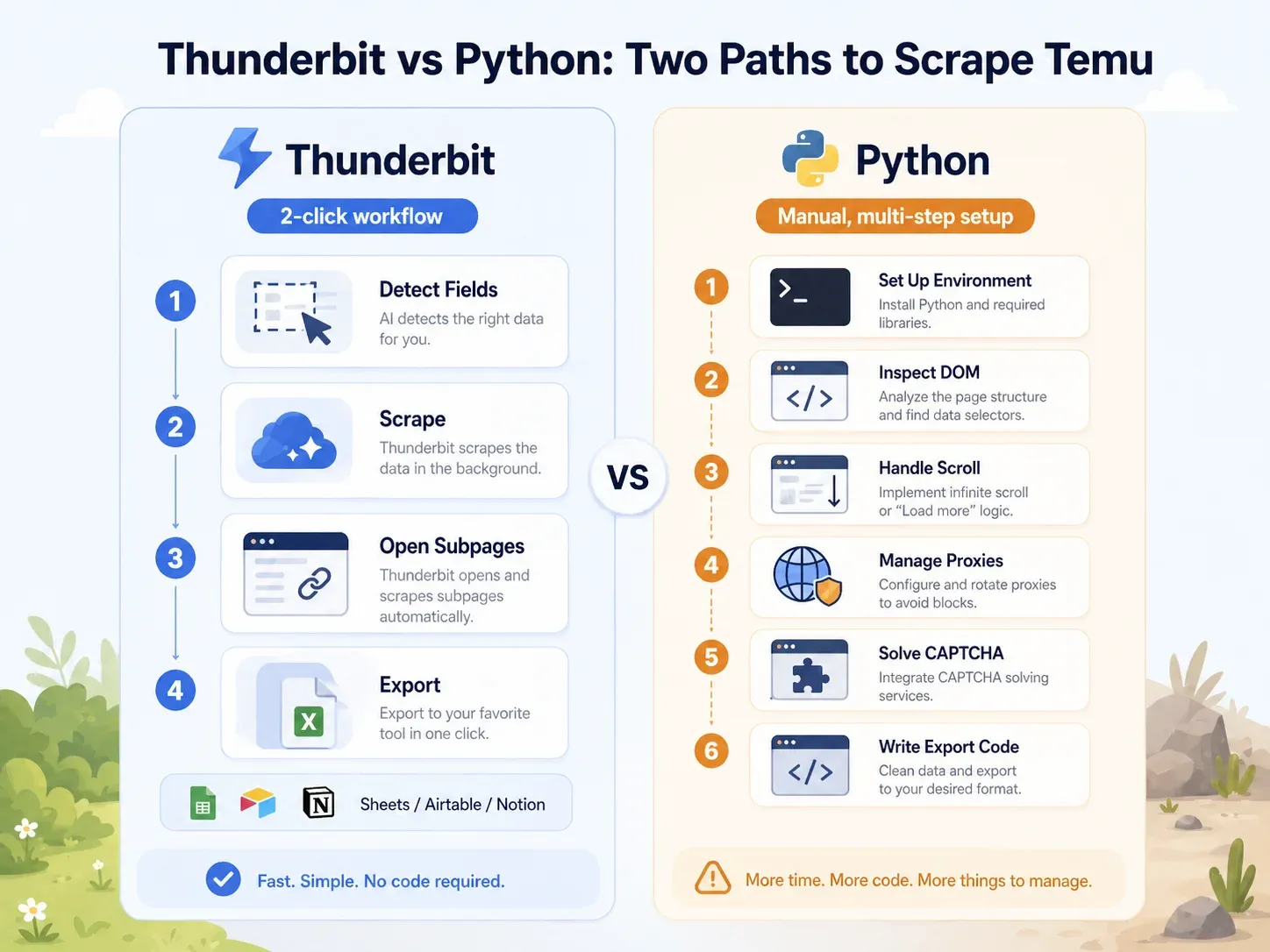
| Tarefa | Thunderbit | Python (Playwright) |
|---|---|---|
| Abrir página de categoria da Temu | Abrir a página no Chrome | Configurar ambiente Python, instalar Playwright, instalar navegadores |
| Identificar campos | Clicar em "AI Suggest Fields" | Inspecionar DOM, chamadas de rede, payloads JSON |
| Lidar com carregamento dinâmico | Modo navegador/nuvem + paginação | Escrever lógica de scroll/espera, interceptar requisições |
| Lidar com bloqueios | Tentar modo nuvem ou modo navegador | Adicionar proxies, cabeçalhos, fingerprinting, retentativas, CAPTCHA |
| Extrair campos da listagem | Clicar em "Scrape" | Escrever seletores ou lógica de parsing de API |
| Enriquecer páginas de produto | Clicar em "Scrape Subpages" | Criar um crawler separado para PDP |
| Exportar | Clicar em Sheets/Airtable/Notion/Excel | Escrever código de integração com CSV/JSON/Sheets |
| Configuração típica para um usuário de negócios | Menos de 2 minutos | 1–4 horas no mínimo; manutenção contínua |
Um protótipo mínimo em Playwright para a Temu poderia parecer com isto (pseudocódigo — não pronto para produção):
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
page.wait_for_load_state("networkidle")
for _ in range(8):
page.mouse.wheel(0, 2000)
page.wait_for_timeout(1200)
cards = page.locator("[data-product-id], a[href*='goods.html']")
# O código de produção ainda precisa de seletores, proxies, retentativas,
# tratamento de CAPTCHA, crawl de PDP e lógica de exportação.
print(cards.count())
Isso já tem mais de 10 linhas antes de você extrair um único campo, e ainda não tocou em proxies, CAPTCHA, enriquecimento de PDP ou exportação. Para um usuário sem conhecimento técnico, o Thunderbit comprime todo esse fluxo em alguns cliques. Para um desenvolvedor, a rota em Python oferece mais controle — mas com um custo de manutenção muito maior.
Octoparse e ParseHub: scrapers de Temu para desktop sem código
Se você quer mais controle do que uma extensão do Chrome, mas não quer escrever código, Octoparse e ParseHub são as principais opções.
Octoparse tem um modelo público de Temu Details Scraper. A saída de exemplo inclui IDs de produto, títulos, preços, dados do vendedor/loja, URLs de imagem, descontos, URLs da loja e especificações detalhadas. Isso é uma vantagem real — você pode começar com um modelo em vez de construir um fluxo do zero. O Octoparse também oferece extração em nuvem, agendamento e criação visual de fluxos.
As ressalvas para a Temu:
- Complementos anti-bot (proxies residenciais a $3/GB, solução de CAPTCHA a US$ 1–US$ 1,50 por mil) podem ficar caros.
- Os modelos podem quebrar quando a Temu muda o layout. Talvez seja necessário atualizar seletores ou esperar o Octoparse manter o modelo.
- A configuração leva de 10 a 60 minutos, dependendo da complexidade da página.
Preço do Octoparse: plano gratuito com 10 tarefas e 50 mil exportações mensais de dados; Standard em torno de US$ 75/mês no plano anual; Professional em torno de US$ 108/mês no plano anual. Complementos para proxies, CAPTCHA e serviços gerenciados são cobrados à parte.
ParseHub é um scraper visual para desktop/web que lida bem com páginas dinâmicas (ele executa um navegador Chromium completo). No entanto, os planos pagos começam em US$ 189/mês, o que é alto para um operador individual. Não encontrei um modelo público forte e específico para Temu durante a pesquisa. O ParseHub é mais adequado para equipes já confortáveis em construir projetos visuais de scraping.
| Ferramenta | Pontos fortes para Temu | Pontos fracos na Temu | Preço |
|---|---|---|---|
| Octoparse | Modelo público da Temu, fluxo visual, extração em nuvem, agendamento | Manutenção do modelo, complementos anti-bot aumentam o custo | Gratuito; ~US$ 75/mês no Standard anual; ~US$ 108/mês no Pro anual; complementos à parte |
| ParseHub | Lida bem com páginas dinâmicas, construtor visual de fluxos | Preço inicial mais alto, sem modelo público relevante da Temu encontrado | Planos pagos a partir de US$ 189/mês |
APIs de scraping: ScraperAPI, Apify e Bright Data para a Temu
Serviços de scraping baseados em API cuidam de proxies, renderização e lógica anti-bot, para que os desenvolvedores possam se concentrar em analisar e armazenar dados. Eles fazem sentido quando você está montando um pipeline, e não executando uma exportação única para planilha.
ScraperAPI é uma API para desenvolvedores voltada a rotação de proxy e renderização. Sua página de preços informa um teste de 7 dias com 5.000 créditos, Hobby a US$ 49/mês por 100.000 créditos, e níveis superiores a partir daí. O detalhe para a Temu: a renderização em JavaScript e os pools premium de proxy consomem de 10 a 75 créditos por requisição, dependendo do nível. Essa multiplicação de créditos significa que seu custo real por linha pode ser muito maior do que o preço divulgado.
Apify é uma plataforma com marketplace de "actors" prontos (scrapers). Existem vários actors para Temu. Um Temu Scraper mantido pela comunidade cobra cerca de US$ 5 por 1.000 produtos no nível gratuito. Outro Temu Products Scraper cobra US$ 4 por 1.000 resultados. O risco: a qualidade dos actors varia, a manutenção depende da comunidade e alguns podem ser descontinuados ou quebrar quando a Temu for atualizada. Verifique sempre a data de "última modificação" e as avaliações dos usuários antes de se comprometer.
Bright Data é a opção corporativa. Sua página de scraper da Temu informa que os trabalhos rodam na infraestrutura da Bright Data com rotação de proxy, geo-targeting, lógica de CAPTCHA/desbloqueio e autoscaling. Os formatos de saída incluem JSON, CSV, Parquet e entrega direta para S3, GCS, Azure Blob, BigQuery e Snowflake. Avaliações do setor apontam o Web Scraper API pay-as-you-go em torno de US$ 2,5 por 1.000 registros, com planos contratados a partir de cerca de US$ 499/mês. Poderoso, mas com preço para equipes com orçamento real.
Oxylabs também tem uma página dedicada de Temu Scraper API. Os planos começam em US$ 49/mês, com teste gratuito de até 2.000 resultados. É uma alternativa forte à Bright Data para equipes de desenvolvimento que querem dados estruturados da Temu via API.
| API/Plataforma | Evidência específica da Temu | Força | Fraqueza | Ideal para |
|---|---|---|---|---|
| ScraperAPI | Nenhuma página específica da Temu encontrada, mas os recursos anti-bot para ecommerce estão documentados | Endpoint simples, renderização JS, proxies premium | Multiplicadores de créditos para recursos premium; desenvolvedores precisam analisar os dados | Pipelines de desenvolvedor |
| Apify | Vários actors da Temu no marketplace | Caminho mais rápido para desenvolvedores se o actor corresponder e for mantido | A qualidade dos actors varia; alguns são descontinuados | Desenvolvedores que querem marketplace de actors + agendamento |
| Bright Data | Página dedicada de scraper da Temu | Infraestrutura corporativa, desbloqueio, entrega para data warehouse | Caro; ainda exige conhecimento de web scraping | Equipes de dados em escala corporativa |
| Oxylabs | Página dedicada de Temu Scraper API | Preço claro por resultado, tratamento de JS, alegações de IP/CAPTCHA | Fluxo de trabalho de API para desenvolvedores | Equipes de desenvolvimento que precisam de acesso à API da Temu |
Scripts Python personalizados (Playwright/Selenium): controle total, alto esforço
Scrapers Python personalizados oferecem flexibilidade máxima — esse é o lado positivo. Em geral, Playwright é um ponto de partida melhor do que Selenium para a Temu por causa do modelo de autoespera e do melhor tratamento de páginas pesadas em JavaScript.
Mas a troca é dura.
Um protótipo leva de 1 a 4 horas. Um scraper de produção precisa de rotação de proxy, fingerprints realistas de navegador, estratégia de CAPTCHA, retentativas, validação de esquema, armazenamento de saída, monitoramento, alertas e revisão jurídica.
E ele quebra. As comunidades de scraping no Reddit descrevem repetidamente o scraping moderno de ecommerce como instável quando os sites usam Cloudflare, renderização em JavaScript e fingerprints anti-bot.
| Modo de falha | Causa típica | Mitigação | |---|---|---|---| | HTML vazio / produtos ausentes | O JS carrega os cards de produto depois do HTML inicial | Use Playwright, espere a rede e o DOM | | Só os primeiros produtos | Scroll infinito / carregamento preguiçoso | Loop de scroll, espera por inatividade da rede, limiar de contagem de cards | | Preços ausentes ou inconsistentes | Estado de região/sessão/moeda ou resposta anti-bot | Defina localidade, cookies, proxy com geotargeting | | 403 / desafio / CAPTCHA | Reputação do IP, fingerprint de headless, taxa de requisição | Proxies residenciais, navegador furtivo, taxa menor | | Quebra de seletor | Mudanças no DOM/classes, testes A/B | Extração semântica ou parsing de API, se disponível |
Scripts personalizados não são a opção “gratuita”. Eles trocam custo de assinatura por tempo de desenvolvedor, gastos com proxy, custos de CAPTCHA e risco de manutenção. Se você tem um engenheiro de scraping na equipe e precisa de lógica incomum, este é o caminho certo. Para todos os demais, na prática, é a opção mais cara.
Melhor prática: scraping de subpáginas para dados completos de produtos Temu
Esta é a melhor prática de maior impacto neste artigo — e quase nenhum outro guia cobre isso.
Uma página de categoria ou de busca da Temu mostra o básico: título, miniatura, preço, avaliação aproximada. Mas os campos que realmente tornam uma linha acionável — descrições detalhadas, listas de variações, contagem completa de avaliações, estimativas de frete, nomes de vendedores, tabelas de especificações — vivem na página de detalhe do produto (PDP).
Se você extrai apenas a página de listagem, está trabalhando com um conjunto de dados parcial.
O fluxo em duas etapas:
- Etapa 1 — Extrair a página de listagem (PLP): Extraia nome do produto, preço, miniatura e avaliação de uma página de busca ou categoria da Temu.
- Etapa 2 — Enriquecer via scraping de subpáginas: Visite a PDP de cada produto e acrescente colunas como descrição completa, número de avaliações, opções de variação, prazo de entrega e informações do vendedor.
Veja como os dados ficam antes e depois:
| Campo | Da PLP (Etapa 1) | Adicionado da PDP (Etapa 2) |
|---|---|---|
| Título do produto | ✅ | — |
| Preço | ✅ | ✅ (verificado / % de desconto) |
| Miniatura | ✅ | — |
| Avaliação em estrelas | ✅ | ✅ (com número de avaliações) |
| Descrição completa | ❌ | ✅ |
| Variações (tamanhos, cores) | ❌ | ✅ |
| Nome do vendedor | ❌ | ✅ |
| Estimativa de frete | ❌ | ✅ |
| Especificações detalhadas | ❌ | ✅ |
No Thunderbit, isso é um clique: depois da extração inicial, clique em "Scrape Subpages". A IA visita cada URL de produto e acrescenta as colunas adicionais — sem configuração extra, sem spider separado, sem manutenção de seletores. O modelo Temu Details do Octoparse e o actor da Temu no Apify também suportam campos em nível de PDP, mas com mais configuração e manutenção. Em Python, você precisaria construir um crawler separado para PDP, manter seus seletores e lidar com paginação dentro das páginas de detalhe — um investimento adicional significativo.
Melhor prática: scraping agendado da Temu para monitoramento contínuo de preço e estoque
Extrações pontuais são úteis para descoberta de produtos. Inteligência competitiva exige observação repetida.
Os preços mudam, os produtos ficam sem estoque, novos itens aparecem todos os dias e o nível de desconto varia com as promoções. Uma extração semanal ou diária cria uma tabela histórica que sua equipe realmente consegue usar.
Três casos de uso que valem a automação:
- Monitoramento de preços: Acompanhe semanalmente os 50 principais SKUs da Temu de um concorrente. Receba os preços atualizados exportados automaticamente para o Google Sheets para comparação instantânea com a sua própria precificação.
- Monitoramento de estoque e disponibilidade: Detecte quando um produto em alta fica sem estoque, uma nova variação aparece ou a estimativa de frete muda.
- Detecção de novos produtos/tendências: Agende uma extração diária da seção "New Arrivals" da Temu ou de uma página de categoria prioritária. Ordene por quantidade vendida ou número de avaliações para identificar cedo os produtos em ascensão.
No Thunderbit, você configura isso descrevendo o intervalo em linguagem natural ("toda segunda-feira às 9h"), inserindo as URLs de destino e clicando em "Schedule". A extração roda na nuvem e exporta para o destino escolhido. Como a IA lê a página do zero a cada vez, as extrações agendadas se adaptam automaticamente às mudanças de layout da Temu — você não precisa atualizar seletores quando a Temu redesenha um card de produto.
A alternativa: configurar um cron job, manter um script Python, configurar rotação de proxy, montar um pipeline de saída e corrigir seletores toda vez que a Temu mudar o layout. Para uma equipe sem conhecimento técnico, isso não é viável. Para um desenvolvedor, é sobrecarga contínua. Apify e Bright Data também oferecem execuções agendadas, mas com configuração mais técnica e custo mínimo mais alto.
Melhor prática: fluxo completo de dados da Temu (extrair → limpar → exportar → agir)
A maioria dos guias de scraping termina em “baixar CSV”.
Mas usuários de negócios precisam dos dados dentro das ferramentas em que realmente trabalham — Google Sheets para colaboração, Airtable para bases de produtos, Notion para painéis da equipe. A verdadeira melhor prática é um fluxo de ponta a ponta:
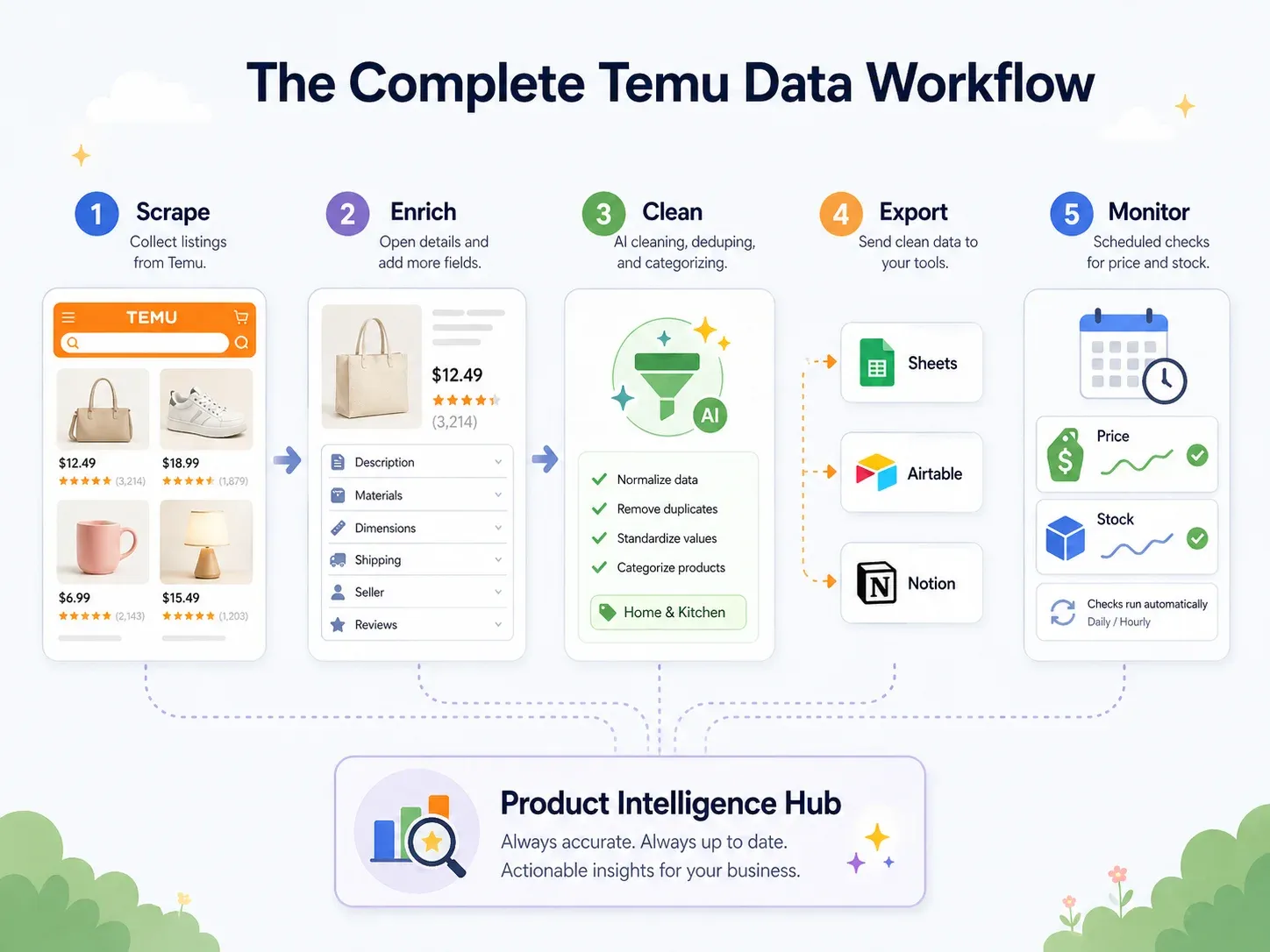
| Etapa do fluxo | O que acontece | Capacidade do Thunderbit |
|---|---|---|
| Extrair | Extrair dados das páginas da Temu | AI Suggest Fields → Scrape (2 cliques) |
| Enriquecer | Visitar a página de detalhe de cada produto | Scrape Subpages (1 clique) |
| Limpar e rotular | Categorizar produtos, normalizar preços, traduzir títulos | Field AI Prompt — rotular, formatar, traduzir durante a extração |
| Exportar | Enviar dados para ferramentas de negócios | Exportação gratuita para Excel, Google Sheets, Airtable, Notion; download em CSV/JSON |
| Monitorar | Acompanhar mudanças ao longo do tempo | Scheduled Scraper com intervalos em linguagem natural |
Aqui vai um exemplo concreto: você extrai 200 produtos de cozinha da Temu. Durante a extração, um Field AI Prompt categoriza automaticamente cada produto em "Utensílios / Eletrodomésticos Pequenos / Organização / Limpeza / Decoração". Os preços são normalizados para valores numéricos em USD. Os títulos dos produtos em chinês são traduzidos para inglês. Os dados são exportados diretamente para uma base do Airtable com as imagens dos produtos preservadas (não apenas URLs — anexos reais de imagem, como descrito no guia de scraping de imagens do Thunderbit). Uma extração agendada atualiza os dados semanalmente.
Algumas instruções úteis de Field AI Prompt para dados da Temu:
- "Classifique este produto em uma destas categorias: Utensílios de Cozinha, Eletrodomésticos Pequenos, Organização, Limpeza, Decoração, Outro. Retorne apenas a categoria."
- "Traduza o título do produto para inglês conciso, preservando nomes de marca, quantidades, tamanhos e números de modelo."
- "Normalize o preço como um número, sem símbolos de moeda."
- "Rotule a demanda como Alta, Média ou Baixa com base na avaliação, no número de avaliações e na quantidade vendida. Se faltar dado, retorne Desconhecido."
Esse fluxo transforma uma extração bruta em um banco de inteligência de produto vivo — sem que um desenvolvedor precise montar um pipeline ETL separado.
Melhores scrapers de Temu comparados: tabela lado a lado
| Ferramenta | Nível de habilidade | Tempo de configuração | Tratamento anti-bot | Scraping de subpáginas | Agendamento | Opções de exportação | Faixa de preço | Ideal para |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Iniciante | Minutos | Modo navegador, modo nuvem, detecção de campos por IA | Sim (Scrape Subpages) | Sim (agendamentos em linguagem natural) | Excel, CSV, Google Sheets, Airtable, Notion, JSON | Gratuito 6 páginas; pago a partir de ~US$ 9–15/mês por 500 créditos | Equipes de ecommerce sem conhecimento técnico, dropshippers |
| Octoparse | Iniciante–Intermediário | 10–60 min | Extração em nuvem, complementos de proxy/CAPTCHA | Sim (fluxos com modelo) | Sim (planos pagos/nuvem) | Excel, CSV, JSON, HTML, XML, banco de dados, Google Sheets | Gratuito; ~US$ 75/mês no Standard anual; complementos à parte | Operadores que querem fluxos visuais + modelo da Temu |
| ParseHub | Iniciante–Intermediário | 30–60 min | Renderização dinâmica, rotação de IP paga | Sim (fluxos de projeto) | Planos pagos | CSV/JSON, Dropbox/S3 nos planos pagos | Pago a partir de US$ 189/mês | Equipes que constroem projetos visuais para sites dinâmicos |
| ScraperAPI | Desenvolvedor | Horas | Rotação de proxy, renderização JS, pools premium | Código personalizado | DataPipeline/agendador | HTML/JSON/CSV | Teste com 5 mil créditos; Hobby US$ 49/mês; níveis superiores disponíveis | Desenvolvedores criando pipelines personalizados para Temu |
| Apify | Intermediário | 10–30 min se o actor servir | Lógica de navegador/proxy específica do actor | Depende do actor | Sim | JSON, CSV, Excel, API/datasets | Plataforma gratuita; actors da Temu ~US$ 4–5/1 mil produtos | Desenvolvedores/operadores que conseguem avaliar a qualidade do actor |
| Bright Data | Avançado/Corporativo | Horas–dias | Proxy completo, CAPTCHA, desbloqueio, autoscaling | Personalizado via scraper/API | Sim | JSON, CSV, Parquet, S3, GCS, Azure, BigQuery, Snowflake | ~US$ 2,5/1 mil registros PAYG; contratado a partir de ~US$ 499/mês | Equipes de dados corporativas, extração em alto volume |
| Oxylabs | Avançado | Horas | Tratamento de JS, alegações de IP/CAPTCHA | Personalizado via API | Sim | JSON/saída em API | A partir de US$ 49/mês; teste de até 2 mil resultados | Equipes de desenvolvimento que precisam de acesso à API da Temu |
| Python personalizado (Playwright) | Avançado | 1–4 h+; manutenção contínua | Proxies manuais, CAPTCHA, fingerprints | Totalmente personalizado | Cron/fila/manual | Personalizado | Tempo de dev + custos de proxy/CAPTCHA/hospedagem | Casos extremos, equipes com engenheiros de scraping |
Qual scraper de Temu você deve escolher? Recomendações rápidas
- Dropshipper que precisa pesquisar produtos rapidamente? Comece com o plano gratuito do Thunderbit. É o caminho mais rápido de “quero dados da Temu” para “tenho uma planilha”. Se funcionar nas páginas-alvo — e deve funcionar na maioria das páginas públicas de categoria e produto — pronto.
- Operador que quer controle visual e modelos reutilizáveis? O Octoparse tem um modelo público de Temu Details e um construtor visual de fluxos. Espere de 10 a 30 minutos de configuração e alguma configuração de proxy/CAPTCHA.
- Desenvolvedor montando um pipeline de dados ou uma ferramenta interna? ScraperAPI ou Apify oferecem fluxos de API/actors que se integram a código e tarefas agendadas. Avalie os actors do Apify com cuidado — verifique o status de manutenção e as avaliações dos usuários.
- Equipe corporativa que precisa de dados Temu em alto volume e entrega para warehouse? Bright Data é a opção de infraestrutura. É caro, mas lida com escala, desbloqueio e entrega para S3/BigQuery/Snowflake.
- Engenheiro de scraping que precisa de lógica incomum? Um Playwright/Selenium personalizado dá controle total. Só reserve orçamento para manutenção contínua, custos com proxy e tratamento de CAPTCHA.
Para a maioria dos usuários de negócios sem conhecimento técnico, eu recomendaria testar primeiro o plano gratuito do Thunderbit. A pergunta imediata é sempre “consigo obter as linhas que preciso desta página exata da Temu?” — e você consegue responder isso em menos de dois minutos sem gastar nada. Para desenvolvedores, rode um benchmark de custo por linha bem-sucedida entre Apify, ScraperAPI e um pequeno protótipo em Playwright antes de comprometer orçamento.
Experimente o Thunderbit grátis para extrair dados da Temu
FAQs sobre scraping da Temu
É legal extrair dados da Temu?
Depende da jurisdição, dos dados que você está coletando, do método de acesso e de como você usa os dados. Os Termos de Uso da Temu restringem explicitamente o acesso automatizado, incluindo rastreamento, scraping ou spidering de páginas ou dados. Os tribunais dos EUA ofereceram algum precedente favorável para acessar dados publicamente disponíveis (a decisão hiQ v. LinkedIn do Nono Circuito), mas decisões posteriores também mantiveram alegações de quebra de contrato e invasão. A resposta curta: extrair dados públicos de produtos para pesquisa pode ser defensável em alguns contextos, mas os Termos de Serviço, a lei de privacidade, direitos autorais e a forma como você usa os dados importam. Isto não é aconselhamento jurídico — consulte um advogado para uso comercial.
Com que frequência a Temu muda o layout do site?
Não há uma cadência pública documentada. Relatos da comunidade e o ecossistema de ferramentas tratam a Temu como um alvo dinâmico, atualizado com frequência. Considere que os seletores CSS podem quebrar a qualquer momento e prefira extração por IA/semântica ou modelos mantidos ativamente em vez de seletores codificados.
Posso extrair dados da Temu sem ser bloqueado?
Para páginas públicas limitadas e com ritmo responsável, sim — especialmente usando ferramentas com renderização real de navegador, suporte a sessão e limitação de taxa. Nenhuma ferramenta deve ser tratada como garantia universal. O scraping em nuvem com IPs rotativos funciona bem para páginas públicas de catálogo; o scraping no navegador com sua sessão atual funciona melhor quando região, login ou pop-ups afetam os dados.
Que dados posso extrair das páginas de produto da Temu?
Os campos públicos comuns incluem título do produto, URL, preço atual, preço original, percentual de desconto, URLs de imagem, avaliação em estrelas, número de avaliações, quantidade vendida, nome do vendedor/loja, informações de frete, categoria, especificações do produto, variações (cores, tamanhos) e carimbo de data/hora da extração. Os campos exatos disponíveis dependem do tipo de página (listagem vs. detalhe) e da região.
Preciso de proxies para extrair dados da Temu?
Para extração manual em modo navegador em pequena escala (algumas páginas por vez), talvez não. Para coleta em nuvem, agendada ou em alto volume, proxies ou infraestrutura gerenciada anti-bloqueio normalmente são necessários. Ferramentas como Thunderbit, Bright Data e ScraperAPI embutem o gerenciamento de proxy em suas plataformas, então você não precisa configurá-lo separadamente.
Se quiser se aprofundar em tópicos relacionados, confira nossos guias sobre web scraping para comparação de preços, melhores scrapers de ecommerce, como extrair dados de sites para o Excel e como extrair para o Google Sheets. Você também pode assistir a tutoriais no canal do Thunderbit no YouTube.
Experimente o Thunderbit para extrair dados da Temu Get Started Free
Saiba mais




