A web tornou-se um ambiente selvagem e em constante mudança — pense menos em “biblioteca digital” e mais em “selva de dados”. Em 2025, se estiver a tentar extrair dados de sites modernos, não vai esbarrar apenas num muro de JavaScript — vai deparar-se com uma fortaleza. Já vi de perto como as ferramentas tradicionais de scraping cedem sob o peso de conteúdo dinâmico, rolagem infinita e barreiras antibôt. É por isso que a ascensão do python headless browser não é apenas uma tendência — é uma verdadeira revolução para quem precisa de extração de dados web fiável e escalável.
E não são só os técnicos que se preocupam com isso. Em 2025, , e mais de . Seja em vendas, ecommerce ou operações, o python headless browser certo faz toda a diferença entre “dados ao alcance da mão” e “dados fora de alcance”. Por isso, vamos pôr de lado o ruído — testei, comparei e usei estas ferramentas, e estou aqui para analisar os 10 melhores python headless browsers para scraping moderno (com destaque especial para a forma como a IA está a mudar o jogo para quem não programa).
O que torna um Python Headless Browser essencial para o scraping moderno?
Vamos simplificar o jargão: um python headless browser é, no fundo, um navegador que controlas com código Python, mas sem a janela gráfica a aparecer no ecrã. Ele carrega páginas, executa JavaScript, clica em botões, preenche formulários — tudo de forma invisível, nos bastidores. Pensa nele como um navegador fantasma, a trabalhar sem parar enquanto bebes o café.
Porque é que isto importa? Porque os sites modernos foram feitos para utilizadores, não para bots. Escondem dados atrás de JavaScript, exigem login e esperam que interajas como uma pessoa real. Os scrapers tradicionais, que se limitam a fazer fetch do HTML, ficam a olhar para cascas vazias. Já os headless browsers simulam o comportamento real de um utilizador — esperam por chamadas AJAX, fazem scroll em feeds infinitos e capturam o conteúdo exatamente como o vês no Chrome ou no Firefox ().
Mas há mais:
- Velocidade e eficiência: os headless browsers dispensam a renderização visual, por isso são mais rápidos e consomem menos memória — ideais para scraping em escala ().
- Suporte a conteúdo dinâmico: executam JavaScript, por isso obténs os dados reais renderizados — não apenas o HTML bruto.
- Superpoderes de automação: precisas de fazer login, avançar páginas ou lidar com pop-ups? Os python headless browsers automatizam tudo isso.
- Escalabilidade: corre centenas de instâncias na nuvem, extrai milhares de páginas em paralelo e faz tudo isso sem esforço.
Para utilizadores de negócios, isto significa que finalmente dá para recolher leads, monitorizar concorrentes ou acompanhar preços — mesmo que o site tenha a segurança de Fort Knox. E, com as ferramentas mais recentes com IA, nem precisas de ser programador para entrar no jogo.
Como escolhemos os melhores Python Headless Browsers
Não me limitei a atirar nomes de navegadores para o ar. Eis o que considerei:
- Desempenho e velocidade: consegue lidar com sites modernos e pesados em JavaScript com rapidez e fiabilidade?
- Suporte a navegadores: funciona com Chrome, Firefox, WebKit ou até motores mais antigos como IE?
- Facilidade de utilização: é amigável para quem não programa ou exige um PhD em Python?
- Recursos de IA e no-code: utilizadores de negócios conseguem usar IA para automatizar scraping sem escrever scripts?
- Comunidade e suporte: há uma comunidade ativa, boa documentação e desenvolvimento contínuo?
- Recursos únicos: oferece algo especial — como modelos instantâneos, scraping na nuvem ou navegação por subpáginas?
Já vi equipas perderem semanas a lutar com a configuração, só para depois esbarrarem num novo problema quando o layout do site mudava. As melhores ferramentas não funcionam apenas — adaptam-se, escalam e facilitam-te a vida.
Top 10 melhores Python Headless Browsers para scraping moderno
Aqui está a minha lista definitiva, com uma análise aprofundada do que faz cada ferramenta brilhar — ou tropeçar.
1. Thunderbit
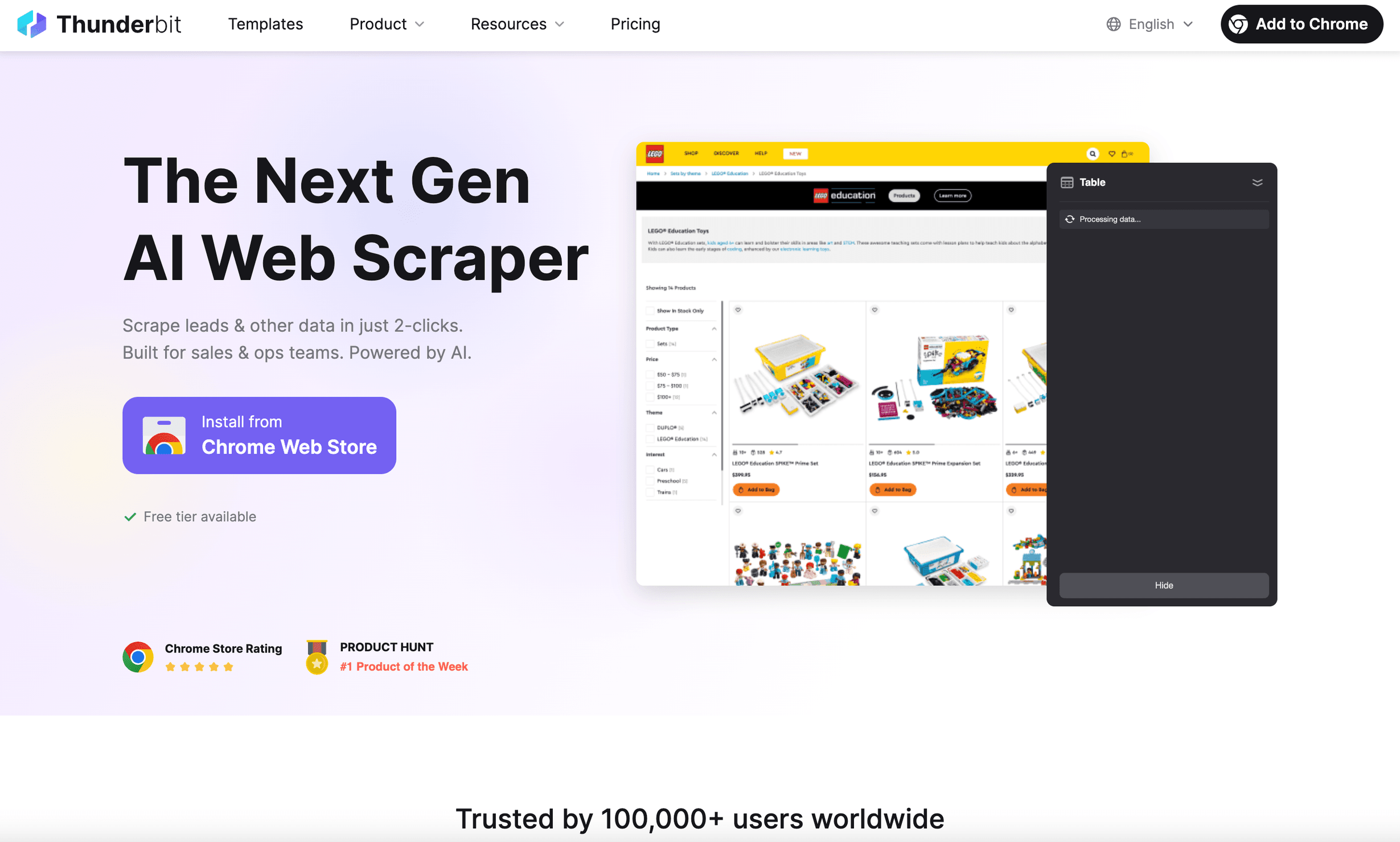 é o python headless browser que eu gostava de já ter tido há anos. Não é apenas uma ferramenta de automação de navegador — é uma extensão Chrome de AI Web Scraper criada para utilizadores de negócios que querem resultados, não dores de cabeça.
é o python headless browser que eu gostava de já ter tido há anos. Não é apenas uma ferramenta de automação de navegador — é uma extensão Chrome de AI Web Scraper criada para utilizadores de negócios que querem resultados, não dores de cabeça.
Porque é que o Thunderbit se destaca:
- AI Suggest Fields: basta clicar em “AI Suggest Fields” e a IA do Thunderbit lê a página, recomenda os dados a extrair e configura o scraper por ti ().
- Modelos instantâneos de dados: para sites populares (Amazon, Zillow, LinkedIn etc.), recebes modelos com um clique — sem configuração.
- Scraping de subpáginas e paginação: o Thunderbit consegue clicar em subpáginas, lidar com rolagem infinita e juntar todos os dados numa única tabela.
- Prompts em linguagem natural: descreve o que queres em inglês simples; a IA do Thunderbit trata do resto.
- Scraping na nuvem ou no navegador: executa extrações localmente ou na nuvem (até 50 páginas de cada vez para ganhar velocidade).
- Sem necessidade de programação: a sério — se sabes usar um navegador, sabes usar o Thunderbit.
- Exportação gratuita de dados: exporta para Excel, Google Sheets, Notion ou Airtable com um clique.
Já vi o Thunderbit poupar horas a equipas de vendas e operações — a extrair leads, monitorizar preços ou agregar dados de produtos sem tocar numa linha de código. É usado por em todo o mundo, e o feedback é sempre o mesmo: “Não acredito como isto é fácil”.
Ideal para: utilizadores não técnicos, equipas de negócio, qualquer pessoa que queira que a IA faça o trabalho pesado.
2. Selenium
 é o OG da automação de navegador. Se alguma vez pesquisaste “python headless browser” no Google, é muito provável que tenhas dado de caras com o Selenium WebDriver.
é o OG da automação de navegador. Se alguma vez pesquisaste “python headless browser” no Google, é muito provável que tenhas dado de caras com o Selenium WebDriver.
Vantagens:
- Compatível com todos os principais navegadores: Chrome, Firefox, Safari, Edge, até Internet Explorer (para os mais corajosos).
- Comunidade gigantesca: muitos tutoriais, plugins e respostas no Stack Overflow.
- Altamente flexível: automatiza tudo o que um utilizador consegue fazer — cliques, formulários, navegação.
Desvantagens:
- A configuração pode dar trabalho: vais ter de lidar com drivers de navegador e manter as versões sincronizadas.
- Mais lento do que ferramentas modernas: o protocolo WebDriver adiciona overhead, e escalar para centenas de navegadores é um pouco desajeitado.
- API verbosa: escreves mais código do que com Playwright ou Puppeteer.
Ideal para: equipas que já têm experiência com Selenium, testes cross-browser ou fluxos de automação legados.
3. Puppeteer
 é a biblioteca de automação de alto nível da Google para Chrome/Chromium. Embora seja nativa de Node.js, os utilizadores de Python podem entrar na brincadeira através do Pyppeteer.
é a biblioteca de automação de alto nível da Google para Chrome/Chromium. Embora seja nativa de Node.js, os utilizadores de Python podem entrar na brincadeira através do Pyppeteer.
Vantagens:
- Otimizado para Chrome: rápido, eficiente e bem integrado com o Chrome DevTools.
- API assíncrona: ótimo para sites modernos e pesados em JavaScript.
- Funcionalidades ricas: capturas de ecrã, exportação em PDF, interceptação de rede.
Desvantagens:
- Só Chromium: sem suporte para Firefox ou Safari.
- Nativo de Node.js: utilizadores de Python precisam de recorrer ao Pyppeteer (que hoje já não é mantido — ver mais abaixo).
Ideal para: programadores que querem automação rápida e fiável no Chrome e não precisam de suporte cross-browser.
4. Playwright
 é o novato da área, criado pela Microsoft — e rapidamente se tornou a minha opção padrão para scraping avançado.
é o novato da área, criado pela Microsoft — e rapidamente se tornou a minha opção padrão para scraping avançado.
Vantagens:
- Suporte a vários navegadores: automatiza Chromium, Firefox e WebKit com uma única API.
- Auto-waiting: chega de adivinhar quando uma página está pronta — o Playwright espera por ti.
- Concorrência: executa vários contextos de navegador em paralelo para uma velocidade impressionante.
- Python em primeiro lugar: bindings nativos para Python, tanto assíncronos como síncronos.
Desvantagens:
- Instalação mais pesada: traz vários navegadores, por isso a configuração fica um pouco mais pesada.
- Ainda exige programação: não é tão amigável para utilizadores não técnicos como o Thunderbit.
Ideal para: programadores que precisam de automação robusta e moderna — especialmente para aplicações web complexas e dinâmicas.
5. Headless Chrome
 é o motor que alimenta muitas das ferramentas acima. Podes controlá-lo diretamente através do Chrome DevTools Protocol (CDP) para obter a máxima flexibilidade.
é o motor que alimenta muitas das ferramentas acima. Podes controlá-lo diretamente através do Chrome DevTools Protocol (CDP) para obter a máxima flexibilidade.
Vantagens:
- Suporte web de topo: se funciona no Chrome, funciona no Headless Chrome.
- Controlo refinado: acesso a cada canto e detalhe do navegador.
Desvantagens:
- Curva de aprendizagem íngreme: vais precisar de falar CDP ou usar uma biblioteca wrapper.
- Só Chrome: sem suporte cross-browser.
Ideal para: especialistas a construir pipelines de automação personalizados ou a integrar o Chrome em baixo nível.
6. Pyppeteer
 é a porta não oficial de Puppeteer para Python. Trouxe a automação assíncrona do Chrome para Python, mas… há um senão.
é a porta não oficial de Puppeteer para Python. Trouxe a automação assíncrona do Chrome para Python, mas… há um senão.
Vantagens:
- API ao estilo de Puppeteer: se conheces o Puppeteer, vais sentir-te em casa.
- Automação rápida do Chrome: ótimo para sites dinâmicos.
Desvantagens:
- Sem manutenção: o projeto original já não recebe atualizações (os programadores recomendam migrar para o Playwright).
- Só Chromium: sem Firefox ou Safari.
Ideal para: projetos legados que já usam Pyppeteer. Para projetos novos, usa Playwright.
7. Splash
 é um headless browser leve e programável, com API HTTP, desenvolvido pela equipa da Scrapinghub (hoje Zyte).
é um headless browser leve e programável, com API HTTP, desenvolvido pela equipa da Scrapinghub (hoje Zyte).
Vantagens:
- Leve: usa QtWebKit, por isso consome menos recursos do que o Chrome.
- API HTTP: controla a ferramenta a partir de qualquer linguagem, não só Python.
- Ótimo para Scrapy: integra-se perfeitamente com spiders do Scrapy para renderização de JS.
Desvantagens:
- Motor WebKit mais antigo: pode ter dificuldades com JavaScript mais avançado.
- Requer script em Lua: para interações mais avançadas, vais precisar de aprender um pouco de Lua.
Ideal para: utilizadores de Scrapy que precisam de renderização ocasional de JS ou de tarefas leves de renderização no servidor.
8. PhantomJS
 é o headless browser original e programável, baseado em WebKit. Foi pioneiro — mas hoje está amplamente obsoleto.
é o headless browser original e programável, baseado em WebKit. Foi pioneiro — mas hoje está amplamente obsoleto.
Vantagens:
- Script simples: fácil de automatizar com JavaScript.
- Suporte legado: ainda funciona para sites antigos e estáticos.
Desvantagens:
- Sem manutenção: sem atualizações desde 2016.
- Motor desatualizado: não consegue lidar com sites modernos e pesados em JS.
- Riscos de segurança: sem patches recentes.
Ideal para: manter scripts legados. Para projetos novos, migra para Playwright ou Puppeteer.
9. HtmlUnit
 é um headless browser baseado em Java que simula o comportamento de navegação. É rápido e leve, mas não é um verdadeiro motor de navegador.
é um headless browser baseado em Java que simula o comportamento de navegação. É rápido e leve, mas não é um verdadeiro motor de navegador.
Vantagens:
- Java puro: ótimo para ambientes muito centrados em Java.
- Rápido em páginas estáticas: sem necessidade de iniciar um navegador completo.
Desvantagens:
- Suporte limitado a JS: tem dificuldade em sites modernos e dinâmicos.
- Não é nativo de Python: exige camadas de integração (por exemplo, o HtmlUnitDriver do Selenium).
Ideal para: fluxos baseados em Java, testes de apps legados ou scraping de páginas simples renderizadas no servidor.
10. TrifleJS
 é um headless browser para Internet Explorer (IE), pensado para automatizar aplicações web legadas no Windows.
é um headless browser para Internet Explorer (IE), pensado para automatizar aplicações web legadas no Windows.
Vantagens:
- Automação do IE: lida com apps antigos de intranet ou sistemas que só funcionam no IE.
- API parecida com a do PhantomJS: são necessárias poucas mudanças em scripts do PhantomJS.
Desvantagens:
- Só para Windows: sem suporte multiplataforma.
- Obsoleto: o IE foi descontinuado; o TrifleJS é de nicho e raramente é mantido.
Ideal para: fluxos legados específicos em que a automação do IE ainda é necessária.
Tabela comparativa de recursos: Python Headless Browsers em resumo
| Ferramenta | Suporte a navegadores | Desempenho e escala | Facilidade de uso | Recursos de IA/no-code | Comunidade e suporte | Ideal para |
|---|---|---|---|---|---|---|
| Thunderbit | Chrome (extensão/nuvem) | Alto (paralelismo na nuvem) | Mais fácil — sem código | Sim (IA, modelos) | Em crescimento, ativa | Não programadores, vendas/ops, extração rápida de dados |
| Selenium | Todos os principais navegadores | Moderado | Moderada (configuração) | Não | Enorme, madura | Cross-browser, legados, automação de testes |
| Puppeteer | Chromium/Chrome | Muito alto | Alta (devs) | Não | Grande (Node.js) | Apenas Chrome, devs, automação rápida |
| Playwright | Chromium, Firefox, WebKit | Muito alto (multi-contexto) | Alta (devs) | Não | Em rápido crescimento | Avançado, multi-browser, scraping moderno |
| Headless Chrome | Chrome/Edge | Muito alto | Baixa (CDP manual) | Não | N/A (base) | Personalizado, especialistas, controlo de baixo nível |
| Pyppeteer | Chromium/Chrome | Alto | Moderada (async) | Não | Pequena, sem manutenção | Scripts legados de Pyppeteer |
| Splash | QtWebKit | Moderado | Moderada (API/Lua) | Não | Nichada (Scrapy/Zyte) | Utilizadores do Scrapy, renderização leve de JS |
| PhantomJS | WebKit (antigo) | Baixo (hoje desatualizado) | Moderada (JS) | Não | Extinta | Apenas legado |
| HtmlUnit | Simulado (Java) | Moderado/alto (estático) | Baixa (Java) | Não | Pequena, centrada em Java | Fluxos Java, páginas simples/estáticas |
| TrifleJS | Internet Explorer (Trident) | Baixo/moderado | Moderada (JS, Win) | Não | Pequena, legado | Automação legada apenas no IE |
Como escolher o Python Headless Browser certo para o seu negócio
Aqui vai o meu guia rápido para escolher a ferramenta certa:
- Precisas de scraping rápido, sem código e com ajuda de IA? Vai para . É a forma mais fácil para não programadores obterem dados fiáveis — especialmente para equipas de vendas, ecommerce ou pesquisa.
- Queres máximo controlo e suporte cross-browser? é a melhor escolha. É robusto, moderno e pensado para escala.
- Já investiste em Selenium? Continua com — ainda é o rei para fluxos legados e multi-browser.
- A construir automação só para Chrome como programador? (ou Playwright) é rápido e poderoso.
- A fazer scraping de páginas simples e estáticas num ambiente Java? é leve e fácil de integrar.
- A manter scripts legados ou apps que só funcionam no IE? e são os teus amigos — em último recurso.
E lembra-te: a melhor ferramenta é aquela que se encaixa no teu fluxo de trabalho, nas competências da tua equipa e nas necessidades do teu negócio. Às vezes, isso significa combinar ferramentas — usar o Thunderbit para tarefas rápidas, o Playwright para o trabalho pesado e o Selenium para sistemas legados.
FAQs
1. O que é um python headless browser e por que preciso de um para scraping?
Um python headless browser é um navegador que controlas com código Python, mas que corre de forma invisível (sem interface gráfica). É essencial para scraping de sites modernos e pesados em JavaScript porque consegue executar scripts, lidar com interações do utilizador e extrair conteúdo totalmente renderizado — algo que os scrapers HTML tradicionais não fazem.
2. Qual é o melhor python headless browser para utilizadores não técnicos?
é a melhor escolha para quem não programa. Usa IA para automatizar a configuração, oferece modelos instantâneos e permite extrair dados em apenas alguns cliques — sem necessidade de programação.
3. Como é que Playwright e Puppeteer diferem para utilizadores de Python?
O Playwright suporta vários navegadores (Chromium, Firefox, WebKit) e tem bindings robustos para Python, o que o torna ideal para automação avançada. O Puppeteer é exclusivo do Chrome e nativo de Node.js, mas os utilizadores de Python podem usar Pyppeteer (embora esteja sem manutenção). Para novos projetos em Python, o Playwright é a melhor escolha.
4. O Selenium ainda é relevante para scraping web moderno?
Sim — o Selenium continua amplamente usado, especialmente para testes cross-browser e automação legada. No entanto, é mais lento e mais complexo de configurar do que ferramentas mais recentes como Playwright ou Thunderbit, e é menos eficiente para scraping em escala.
5. Quando devo usar ferramentas legadas como PhantomJS, HtmlUnit ou TrifleJS?
Apenas para manter ou migrar fluxos antigos. PhantomJS e TrifleJS estão obsoletos, e o HtmlUnit é melhor para ambientes Java com páginas simples. Para projetos novos, fica com ferramentas modernas e ativamente mantidas.
Se estás pronto para ver como é o scraping moderno com IA, . E, para mais aprofundamentos sobre automação web, consulta o . Boa extração — que os teus dados estejam sempre frescos e os teus navegadores, para sempre headless.
Saiba mais