

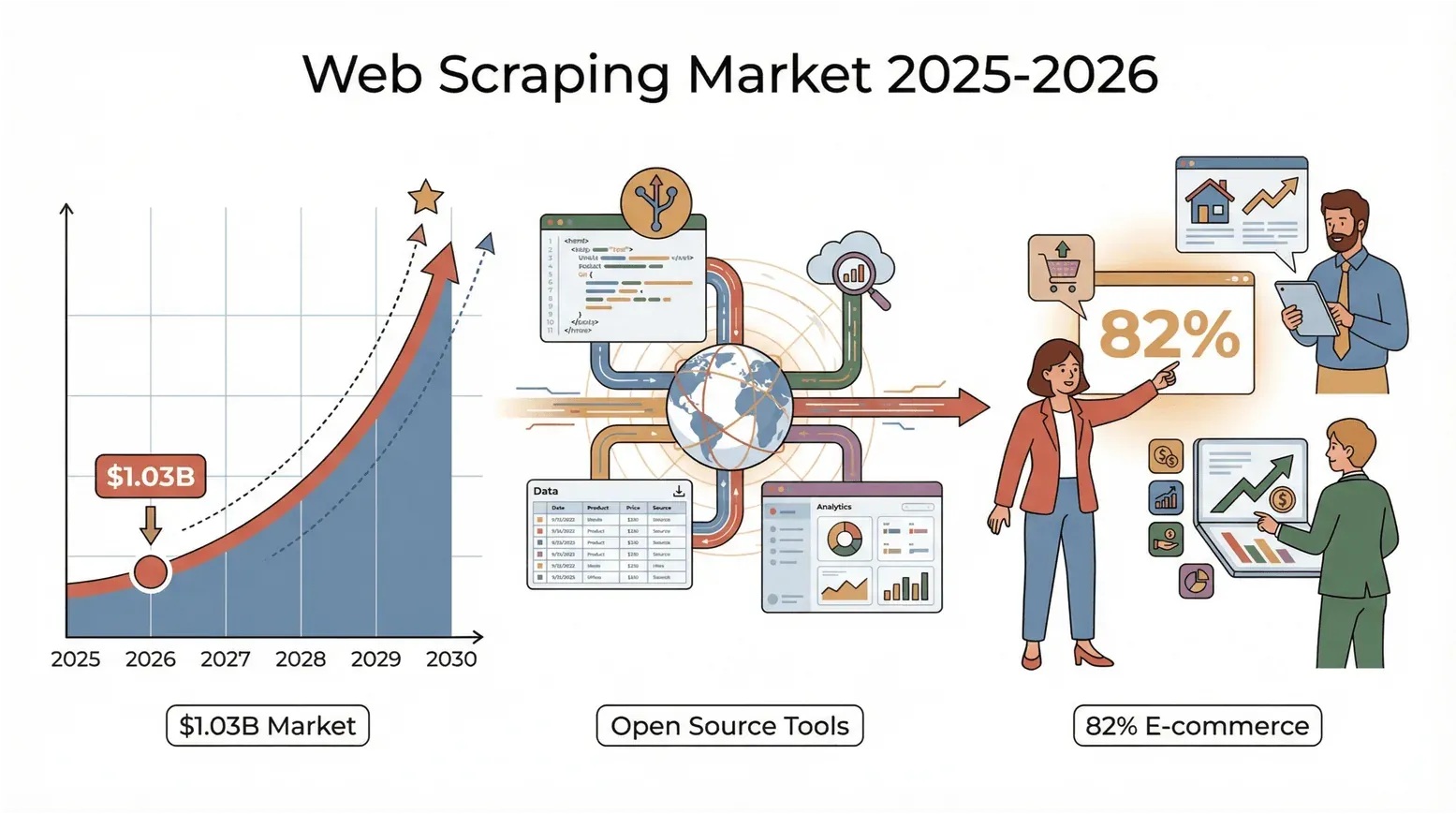
A web está cheia de dados e, em 2026, a corrida para transformar esse caos em insights está mais acesa do que nunca. Seja na área de vendas, e-commerce, mercado imobiliário ou simplesmente um apaixonado por dados como eu, provavelmente já percebeu que a velha rotina de “copiar e colar” já não dá conta do recado. Aqui vai um dado impressionante: o mercado global de web scraping atingiu US$ 1,03 bilhão em 2025, segundo a Mordor Intelligence (citada no relatório sobre o estado do web scraping em 2026 da PromptCloud), e deve praticamente dobrar até 2030.
E não são só as gigantes de tecnologia — 82% das empresas de e-commerce e mais de um terço das gestoras de investimento já raspam a web em busca de leads, preços e pesquisa de mercado (Browsercat). Em resumo: se você não usa uma ferramenta de web scraping, provavelmente está a deixar dinheiro — e insights — na mesa.
Mas aqui vem a boa notícia: as ferramentas open source de web scraping estão mais potentes, acessíveis e movidas pela comunidade do que nunca. Seja você um profissional de Python, um entusiasta de JavaScript ou um utilizador de negócios que só quer dados sem complicação, existe uma ferramenta para si. Passei anos a trabalhar com SaaS e automação e vi este ecossistema evoluir. Então, vamos mergulhar nas 5 melhores ferramentas open source de web scraping que vale a pena explorar em 2026 — e também ver como escolher a mais indicada para o seu caso.
Por que escolher ferramentas open source de web scraping?
O que é data scraping e como fazê-lo em 2026 Get Started Free
As ferramentas open source de web scraping são os canivetes suíços do mundo dos dados. São económicas (sem taxa de licença), flexíveis (dá para personalizar tudo) e transparentes (você vê exatamente como funcionam). Mas a verdadeira magia? A comunidade. Ferramentas open source contam com milhares de desenvolvedores e utilizadores a partilhar plugins, tutoriais e correções — por isso, você nunca fica sozinho (Oreate AI).
Em comparação com ferramentas comerciais, as opções open source colocam você ao volante. Você não fica preso ao roadmap ou aos preços de um fornecedor e pode adaptar os seus scrapers à medida que os sites mudam. Além disso, muitos serviços comerciais de scraping são, na prática, construídos em cima desses mesmos mecanismos open source — então porque não ir direto à fonte?
Como selecionamos as melhores ferramentas open source de web scraping
Com tantas opções por aí, foquei-me em alguns critérios principais:
- Facilidade de uso: Quem não programa consegue começar depressa? Há opções visuais ou baseadas em IA?
- Escalabilidade: A ferramenta lida com projetos grandes ou só com tarefas pontuais?
- Suporte a linguagens e plataformas: Python, JavaScript, navegador, desktop — algo para cada stack.
- Comunidade e manutenção: A ferramenta é atualizada com frequência? Há fóruns, documentação e plugins?
- Recursos exclusivos: deteção de campos com IA, scraping de subpáginas, agendamento, suporte na nuvem e mais.
Também considerei feedback do mundo real e casos de uso de negócios — porque a melhor ferramenta é aquela que realmente resolve o seu problema.
As 5 melhores ferramentas open source de web scraping para explorar
Vamos ao que interessa. Aqui está a minha seleção, da simplicidade com IA aos gigantes para desenvolvedores.
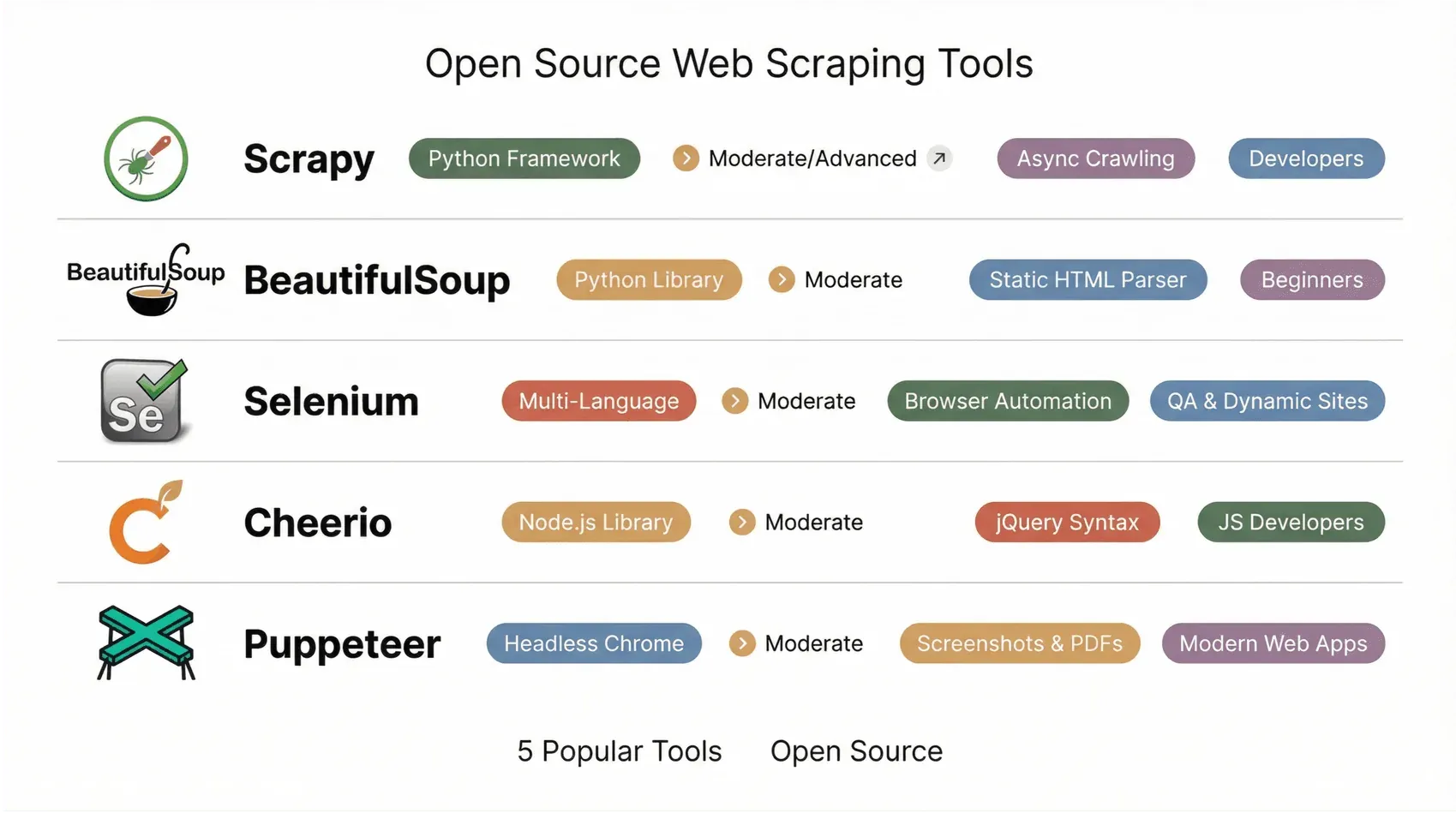
1. Scrapy
Scrapy é o sonho de qualquer desenvolvedor Python. É um framework testado em batalha para criar crawlers e pipelines de dados escaláveis e personalizáveis. Você define “spiders” em Python, e o Scrapy trata da fila, do controlo de taxa e da exportação para JSON, CSV ou XML. Na versão 2.14 (out. de 2025) e no patch 2.14.1 (jan. de 2026), grande parte do núcleo interno baseado em Twisted-Deferred foi reescrita como corrotinas nativas asyncio, com um novo ponto de entrada AsyncCrawlerProcess que se integra bem ao ecossistema assíncrono moderno de Python; o reactor de asyncio passou a ser o padrão para projetos criados de raiz. Atenção: o Scrapy 2.14+ exige Python 3.10 ou mais recente.
O ecossistema de plugins é enorme, com middlewares para proxies, cookies e até integração com navegador sem interface gráfica para sites dinâmicos. O Scrapy é o framework a que a maioria das equipas recorre quando precisa rastrear catálogos inteiros de e-commerce ou agregar notícias em grande escala. A curva de aprendizagem é acentuada para quem não programa, mas, se você quer potência e flexibilidade, o Scrapy entrega (Octoparse).
2. Beautiful Soup
Beautiful Soup é a biblioteca clássica de Python para analisar HTML de forma rápida e sem complicações. É querida por iniciantes e profissionais pela curva de aprendizagem suave e pelo parser tolerante (ela consegue lidar até com o HTML mais desorganizado). Você faz o download de uma página (normalmente com requests), carrega-a no Beautiful Soup e usa métodos simples para encontrar e extrair elementos.
É perfeita para projetos pequenos, protótipos e uso educativo. O senão? O Beautiful Soup não executa JavaScript, por isso funciona apenas com HTML estático. Para sites dinâmicos, vai precisar combiná-lo com algo como Selenium ou requests_html (ProsperaSoft).
3. Selenium
Selenium é a ferramenta original de automação de navegador. Criada inicialmente para testes, tornou-se uma favorita para fazer scraping de sites dinâmicos e pesados em JavaScript. O Selenium abre um navegador real (Chrome, Firefox etc.) e simula ações do utilizador — cliques, scroll, logins, o que você quiser. Se um humano consegue ver, o Selenium consegue raspar.
Suporta várias linguagens (Python, Java, JS, C#) e é ótimo para extrair dados por trás de logins ou fluxos interativos. O Selenium 4 também vem integrando de forma consistente o WebDriver BiDi, um protocolo bidirecional que permite ao seu script subscrever eventos do navegador (pedidos de rede, logs do console, mutações do DOM) e intercetar chamadas de rede — recursos que antes faziam do Puppeteer ou do Playwright a escolha mais fácil para scraping. A versão 4.40 (janeiro de 2026) e a 4.41 (fevereiro de 2026) ampliaram o suporte ao BiDi em bindings para Python, Java, .NET e Ruby. As desvantagens continuam: o Selenium é mais lento e pesado do que scrapers puramente HTTP, e gerir drivers de navegador ainda dá trabalho. Mas, para sites complicados — e para equipas que já padronizaram o Selenium para automação de testes — continua a ser uma opção sólida de scraping em 2026 (ScrapeHero).
4. Cheerio
Cheerio é o jQuery do mundo Node.js. Permite analisar HTML no servidor com uma sintaxe familiar, parecida com a do jQuery. É extremamente rápido e perfeito para páginas estáticas — basta buscar o HTML (com Axios ou Fetch), carregá-lo no Cheerio e usar seletores para ir buscar o que precisa.
O Cheerio não executa JavaScript, por isso é melhor para conteúdo estático. Mas integra-se lindamente com outras ferramentas do Node.js e é um favorito entre desenvolvedores que querem manter tudo em JavaScript (Cheerio Docs).
5. Puppeteer
Puppeteer é uma biblioteca Node.js para controlar o Chrome ou Chromium em modo headless. É uma escolha popular para raspar aplicações web modernas e aplicações de página única que precisam de renderização real de navegador: capturas de ecrã, geração de PDFs, interceção de rede, tudo por trás de uma API limpa de async/await. A equipa do Chrome na Google ainda mantém o Puppeteer e acompanha cada nova versão do Chrome e as atualizações do DevTools Protocol.
Um pouco de contexto útil para 2026: o ritmo de lançamentos do Puppeteer passou a concentrar-se mais na compatibilidade com o Chrome e em atualizações de dependências do que em novos recursos, e a equipa original que criou os recursos mais ambiciosos do Puppeteer acabou por criar o Playwright na Microsoft. Se você já investe no Puppeteer e só precisa de automação no Chrome, ele continua a ser uma escolha estável. Se está a começar do zero e quer suporte a múltiplos navegadores, um test runner nativo, locators com espera automática e um trace viewer, a maioria das equipas em 2026 aponta primeiro para o Playwright (Firecrawl — Playwright vs Puppeteer, Autonoma — Playwright vs Puppeteer 2026).
Experimente o Thunderbit AI Web Scraper grátis
Tabela comparativa rápida: melhores ferramentas open source de web scraping
| Ferramenta | Facilidade de uso | Plataforma/Linguagem | Conteúdo dinâmico | Melhor para | Pontos fortes exclusivos |
|---|---|---|---|---|---|
| Scrapy | Moderada/avançada (código) | Framework Python | Parcial | Desenvolvedores, cientistas de dados | Crawling assíncrono, plugins, comunidade enorme |
| BeautifulSoup | Moderada (código simples) | Biblioteca Python | Não | Iniciantes, parsing rápido | Parser tolerante, ótimo para HTML estático |
| Selenium | Moderada (scripting) | Multilíngue | Sim | QA, scraping de sites dinâmicos | Automação real de navegador, lida com logins e eventos do usuário |
| Cheerio | Moderada (código JS) | Biblioteca Node.js | Não | Devs de JS, páginas estáticas | Sintaxe jQuery, análise rápida de HTML |
| Puppeteer | Moderada (código JS) | Node.js (Chrome headless) | Sim | Devs, apps web modernos | Capturas de ecrã, PDFs, scraping de SPAs, API async/await |
Como escolher a ferramenta open source de web scraping certa para o seu caso
Como raspar qualquer site usando IA Get Started Free
Aqui está o meu guia rápido para escolher a ferramenta certa:
- Nível técnico: Não programa? Comece com Thunderbit, Octoparse, ParseHub ou WebHarvy. É desenvolvedor? Scrapy, Cheerio, Puppeteer ou Apify.
- Escala do projeto: Algo pontual ou pequeno? Beautiful Soup, Cheerio, WebHarvy. Em grande escala ou contínuo? Scrapy, Apify, Thunderbit (com agendamento).
- Tipo de dado: HTML estático? Use Cheerio, Beautiful Soup ou WebHarvy. Dinâmico/pesado em JavaScript? Puppeteer, Selenium, Thunderbit, Octoparse.
- Integração: Precisa exportar para Sheets, Notion ou bancos de dados? Thunderbit e Octoparse facilitam. Precisa de APIs ou pipelines personalizados? Scrapy e Apify são os seus aliados.
- Comunidade e suporte: Procure fóruns ativos, atualizações recentes e muitos tutoriais. Scrapy, Cheerio e Selenium têm comunidades enormes; Thunderbit e Octoparse têm bases de utilizadores em crescimento e muitos guias.
Teste algumas ferramentas num projeto pequeno — veja qual se encaixa no seu fluxo de trabalho e no seu nível de conforto. E não tenha medo de combinar abordagens: às vezes a solução mais rápida é fazer uma raspagem rápida com uma ferramenta visual e depois um crawl mais profundo com um framework baseado em código.
O valor da comunidade e do suporte contínuo no scraping open source
Um dos maiores benefícios do open source? A comunidade. Fóruns ativos, repositórios no GitHub e tópicos no Stack Overflow significam que você nunca está sozinho. Se surgir uma dificuldade, é muito provável que alguém já tenha resolvido — ou possa ajudar. Ferramentas orientadas pela comunidade recebem atualizações frequentes e novos recursos, e você encontra uma enxurrada de tutoriais, plugins e boas práticas (Oreate AI).
Por isso, para ferramentas visuais como Thunderbit e Octoparse, fóruns de utilizadores e partilha de templates são um verdadeiro tesouro. Para ferramentas de desenvolvedor, os issues no GitHub e grupos no Discord/Slack são onde a magia acontece. Quando você escolhe uma ferramenta open source, passa a fazer parte de uma rede global de solucionadores de problemas — e isso não tem preço.
Thunderbit:Uma solução de web scraping sem código, mais fácil para toda a gente
Sim, open source é ótimo — mas às vezes você não quer, na verdade, construir, ajustar e ficar a manter um scraper só para obter dados utilizáveis. E nem todos os problemas de scraping podem ser resolvidos com código open source — é aí que o Thunderbit encaixa na perfeição. Se leu até aqui e pensou: “Estas ferramentas são poderosas, mas eu só quero os dados sem criar ou manter scrapers”, o Thunderbit é o próximo passo natural.
Thunderbit é uma extensão do Chrome com IA, criada para utilizadores de negócios que se preocupam mais com resultados do que com infraestrutura. Em vez de escrever seletores ou scripts, você começa por clicar em AI Suggest Fields. A IA entende a estrutura da página, sugere colunas e você faz a raspagem com um segundo clique. Paginação, subpáginas e fluxos de lista para detalhe são tratados por si.
Um dos maiores pontos fortes do Thunderbit é ligar intenção humana e dados estruturados. Você pode descrever em linguagem simples o que quer (por exemplo, “recolher nomes de produtos, preços e avaliações”), e o Thunderbit transforma isso numa tabela limpa. O scraping de subpáginas facilita extrair dados mais ricos ao visitar automaticamente as páginas de detalhe. As exportações para Excel, Google Sheets, Notion e Airtable já vêm integradas, por isso os seus dados ficam prontos a usar de imediato.
O Thunderbit é especialmente popular entre equipas de vendas, marketing, e-commerce e mercado imobiliário que precisam de dados confiáveis, mas não querem manter pipelines open source. Oferece suporte a dezenas de idiomas, funciona bem em sites dinâmicos e tem uma versão gratuita generosa para começar. Embora não seja open source, complementa muito bem as ferramentas open source — pense nele como a forma mais rápida de validar ideias ou lidar com raspagens recorrentes de negócios sem sobrecarga de engenharia.
Conclusão: destravar dados da web com as melhores ferramentas open source
Web scraping já não é só para programadores ou grandes empresas. Com as ferramentas open source de hoje, qualquer pessoa pode transformar a web em dados estruturados e acionáveis — seja para montar uma lista de leads, monitorizar preços ou alimentar o seu próximo projeto de IA. O segredo é combinar a ferramenta com a sua necessidade: ferramentas visuais e com IA para velocidade e simplicidade, frameworks de código para potência e escala.
Então, o que vem agora? Escolha uma ferramenta desta lista, teste-a numa tarefa real e veja quanto tempo e esforço consegue poupar. E, se quiser uma vitória rápida, baixe o Thunderbit e descubra como o web scraping pode ser simples. A web é o seu oceano de oportunidades — vá buscar essas pérolas de dados.
Para mais análises detalhadas e tutoriais, confira o Blog da Thunderbit. Boas raspagens!
Experimente o Thunderbit AI Web Scraper grátis Get Started Free
Perguntas frequentes
1. Qual é a principal vantagem das ferramentas open source de web scraping em relação às comerciais?
As ferramentas open source são económicas, flexíveis e apoiadas por comunidades ativas. Você pode personalizá-las, evitar dependência de fornecedor e beneficiar de conhecimento partilhado e atualizações frequentes.
2. Qual ferramenta open source é melhor para utilizadores de negócios sem conhecimento técnico?
Thunderbit, Octoparse, ParseHub e WebHarvy são excelentes para quem não programa. O Thunderbit destaca-se pelo fluxo de trabalho com IA em dois cliques e pelas opções diretas de exportação.
3. Ferramentas open source conseguem lidar com sites dinâmicos e pesados em JavaScript?
Sim! Ferramentas como Thunderbit, Selenium, Puppeteer, Octoparse e ParseHub conseguem raspar conteúdo dinâmico ao renderizar páginas num navegador real ou headless.
4. Como saber se uma ferramenta é mantida e suportada ativamente?
Verifique o GitHub em busca de commits recentes, issues em aberto e atividade dos contribuidores. Procure fóruns ativos, posts recentes no blog e muitos plugins ou modelos enviados pela comunidade.
5. Qual é a melhor forma de começar com web scraping se eu for iniciante?
Comece com uma ferramenta visual ou com IA, como Thunderbit ou Octoparse. Tente raspar um pequeno conjunto de dados, exporte para Excel ou Sheets e vá experimentando. À medida que ganhar confiança, pode explorar ferramentas baseadas em código para projetos mais avançados.
Quer ver o Thunderbit em ação? Baixe a extensão do Chrome e junte-se a mais de 30.000 utilizadores que transformam a web em dados — sem precisar programar.
Saiba mais




