Algures entre 2 e 3 milhões de artigos de notícias são publicados online todos os dias. Tentar recolher esses dados de forma estruturada — títulos, datas, fontes, texto completo do artigo — é mais ou menos tão agradável como montar móveis sem instruções.
Passei anos a criar e testar ferramentas de automação na , e o panorama da extração de notícias em 2026 é uma mistura estranha de oportunidade enorme e frustração genuína. O Google encerrou a sua API oficial de Notícias em 2011, os sites de notícias recorrem a medidas anti-bot cada vez mais agressivas (Cloudflare, CAPTCHAs, barreiras de renderização JavaScript), e os layouts mudam com tanta frequência que um scraper que funciona na segunda pode avariar na quarta. Entretanto, equipas de negócio — de RP e vendas a investigadores académicos e engenheiros de IA — precisam de dados estruturados de notícias mais do que nunca.
Por isso, decidi testar 15 ferramentas de extração de notícias entre APIs, plataformas no-code e bibliotecas open-source. O objetivo: dar-lhe uma comparação normalizada sobre preço, esforço de manutenção, extração limpa de texto e adequação a casos de uso reais que nenhum outro guia oferece.
O que faz os melhores scrapers de notícias destacarem-se em 2026?
A maioria dos artigos sobre “melhores scrapers de notícias” ignora por completo os critérios de avaliação, por isso aqui fica o que eu testei de facto. A maior parte desses artigos limita-se a listar funcionalidades e segue em frente. Mas, depois de anos a construir infraestrutura de scraping, aprendi que os critérios que interessam aos utilizadores empresariais são específicos — e muitas vezes deixados de lado.
Eis a estrutura de avaliação que usei:
| Critério | O que avaliei |
|---|---|
| Abordagem | API, ferramenta de browser no-code ou biblioteca open-source |
| Tratamento anti-bot | Rotação de proxies, resolução de CAPTCHA, suporte a browser headless |
| Extração limpa de texto | Consegue remover anúncios/sidebars/navegação e devolver apenas o corpo do artigo? |
| Saída de metadados | Autor, data, imagens, URL de origem, categoria |
| Formatos de exportação | CSV, JSON, Google Sheets, Airtable, Notion, etc. |
| Paginação / suporte a lotes | Consegue lidar com resultados em várias páginas e URLs em lote? |
| Carga de manutenção | Quebra quando os layouts dos sites mudam? Adaptativo por IA vs. baseado em seletores |
| Custo normalizado por 1K resultados | Comparação justa de preços (inclui plano gratuito) |
| Melhor caso de uso | Monitorização de RP, geração de leads, investigação académica, pipeline de LLM, etc. |
Dois critérios precisam de contexto extra. Custo normalizado por 1K resultados importa porque cada fornecedor apresenta preços de forma diferente — por crédito, por pedido, por pesquisa, por linha. Sem normalização, está a comparar maçãs com submarinos. E carga de manutenção é o maior problema que ouço dos utilizadores. Fórum atrás de fórum, a queixa é a mesma: “os sites de notícias adoram partir os meus crawlers todas as terças-feiras.” Classifiquei cada ferramenta numa escala de três níveis:
- 🟢 Baixa manutenção: Adaptativo por IA ou API totalmente gerida — alterações de layout não quebram o fluxo de trabalho
- 🟡 Manutenção média: Lida com anti-bot, mas a lógica de extração ainda pode quebrar
- 🔴 Alta manutenção: Baseada em seletores — quando o site muda, corrige-se manualmente
Que scraper de notícias combina com o seu papel? Uma matriz de decisão
As recomendações de scrapers tratam quase sempre todos os leitores da mesma forma, e esse é o problema central. Um gestor de RP que acompanha menções à marca tem necessidades completamente diferentes de um programador Python a construir um pipeline RAG. Por isso, antes da lista completa, aqui vai uma estrutura rápida:
| Caso de uso | Melhor abordagem | Ferramentas recomendadas |
|---|---|---|
| Resumo diário de notícias (não técnico) | Ferramenta de browser no-code ou RSS | Thunderbit, Octoparse, ParseHub |
| Monitorização de RP / media em escala | API de notícias com alertas | Newscatcher, Webz.io, Newsdata.io |
| Extração de leads de vendas a partir de notícias | Scraper com IA e enriquecimento de subpáginas | Thunderbit (scraping de subpáginas + extração de email/telefone), Apify |
| Investigação académica / construção de corpus | Biblioteca open-source | Newspaper4k |
| Pipeline de LLM / ingestão RAG | API de distilação para Markdown | Thunderbit API, ScraperAPI |
| Inteligência competitiva / preços | Scraping agendado | Thunderbit (Raspador Agendado), Bright Data |
Já sabe em que categoria se encaixa? Siga em frente. Caso contrário, a análise completa abaixo vai ajudar.
Os 15 melhores scrapers de notícias em resumo
Aqui está a comparação principal — preços normalizados para custo por 1.000 resultados no nível pago mais baixo, manutenção avaliada na escala de três níveis.
| Ferramenta | Tipo | Plano gratuito | Custo por 1K resultados (estim.) | Anti-bot | Texto limpo | Manutenção | Melhor caso de uso |
|---|---|---|---|---|---|---|---|
| Thunderbit | IA no-code (extensão Chrome + cloud) | 6 páginas/mês grátis | ~$3–$15 | Forte (modo browser + cloud) | Sim (IA + subpágina) | 🟢 Baixa | Equipas de negócio, geração de leads, monitorização diária |
| SerpApi | API | 250 pesquisas/mês | ~$15 | Forte (específico para SERP) | Não (apenas snippets) | 🟢 Baixa | Dashboards de Google Notícias SERP |
| ScraperAPI | API | 1.000 créditos/mês | ~$1–$5 | Forte (proxy + renderização JS) | Não (HTML bruto) | 🟡 Média | Programadores que querem infraestrutura anti-bot |
| Newsdata.io | API de notícias | 200 pedidos/dia | ~$5–$15 | N/A (API gerida) | Parcial (premium) | 🟢 Baixa | Metadados de notícias estruturados |
| Apify | Plataforma cloud | $5 em créditos grátis | ~$1–$6 | Forte | Varia consoante o actor | 🟡 Média | Fluxos de trabalho cloud personalizados |
| Oxylabs | API empresarial | 2.000 resultados de teste | ~$0.50–$2 | Muito forte | Parcial | 🟢 Baixa | SERP + web em escala empresarial |
| ScrapingBee | API | Créditos de teste | ~$2–$5 | Forte (Chrome headless) | Parcial (básico) | 🟡 Média | Sites de notícias muito dependentes de JS |
| Scrapingdog | API SERP | 1.000 créditos | ~$0.10–$0.50 | Forte | Não (dados SERP) | 🟢 Baixa | Monitorização SERP com orçamento limitado |
| Bright Data | Plataforma empresarial | 1.000 pedidos em teste | ~$0.30–$0.50 | Muito forte | Sim (News Scraper) | 🟢 Baixa | Dados de notícias empresariais em escala |
| Octoparse | No-code desktop + cloud | Plano gratuito limitado | ~$5–$10 (amortizado) | Forte | Sim (com modelos) | 🟡 Média | Scraping visual no-code |
| ParseHub | No-code desktop | 5 projetos, 200 páginas/execução | ~$5–$12 (amortizado) | Moderado | Sim (com configuração) | 🔴 Alta | Iniciantes, pequenos projetos |
| Newscatcher | API de notícias | Sem plano gratuito público | Personalizado (empresarial) | N/A (API gerida) | Sim (enriquecido por NLP) | 🟢 Baixa | Monitorização de RP/media |
| Webz.io | Plataforma de dados de notícias | Sem plano gratuito self-service | Personalizado (empresarial) | N/A (feed gerido) | Sim (texto completo + metadados) | 🟢 Baixa | Arquivos históricos, treino de LLM |
| Newspaper4k | Python open-source | Grátis | $0 (+ custos de servidor) | Nenhum | Sim (concebido para isso) | 🔴 Alta | Programadores, construção de corpus |
| HasData | API SERP | Créditos grátis | ~$0.25–$0.60 | Forte | Não (dados SERP) | 🟢 Baixa | Endpoint SERP de notícias com orçamento limitado |
Conclusões rápidas: Scrapingdog e HasData são as opções API mais baratas por pedido. Thunderbit e Newspaper4k lideram na extração de texto limpo de artigos (de formas muito diferentes). Bright Data e Oxylabs dominam o segmento empresarial. Dores de cabeça com manutenção? Fique pelas ferramentas 🟢.
1. Thunderbit — Melhor scraper de notícias no-code com IA para equipas de negócio
 é a ferramenta que a minha equipa e eu construímos especificamente para resolver o problema de “preciso de dados deste site, e não quero escrever código nem manter seletores.” Para extração de notícias, o fluxo de trabalho é o mais simples possível: abra uma página de notícias, clique em AI Suggest Fields, reveja as colunas que o Thunderbit propõe (título, data, fonte, URL, resumo — lê a estrutura da página e percebe o que existe) e depois clique em Scrape.
é a ferramenta que a minha equipa e eu construímos especificamente para resolver o problema de “preciso de dados deste site, e não quero escrever código nem manter seletores.” Para extração de notícias, o fluxo de trabalho é o mais simples possível: abra uma página de notícias, clique em AI Suggest Fields, reveja as colunas que o Thunderbit propõe (título, data, fonte, URL, resumo — lê a estrutura da página e percebe o que existe) e depois clique em Scrape.
Algumas funcionalidades combinam-se para tornar o Thunderbit especialmente forte para notícias:
- Extração adaptativa por IA: Não há seletores CSS para escrever ou manter. A IA lê o layout atual da página em cada execução, o que significa que quando um site de notícias é redesenhado (e eles todos o fazem), o scraper não quebra.
- Scraping de subpáginas: Depois de extrair uma lista de links de artigos, pode clicar em Scrape Subpages para visitar cada artigo e extrair o texto completo, autor, data de publicação e imagens. É assim que obtém conteúdo limpo do artigo, e não apenas títulos.
- Field AI Prompt: Pode instruir a IA por coluna — por exemplo, “extraia apenas o corpo principal do artigo, excluindo navegação e anúncios” ou “classifique o sentimento deste artigo como positivo, neutro ou negativo.” Isto é único entre ferramentas no-code e extremamente útil para análise de notícias.
- Browser Scraping vs. Cloud Scraping: O modo browser usa a sua própria sessão (útil para sites que bloqueiam IPs cloud), enquanto o modo cloud pode processar até 50 páginas de cada vez para maior velocidade.
- Raspador Agendado: Configure execuções diárias ou semanais com intervalos de tempo em linguagem natural — ótimo para monitorização contínua de notícias.
- Exportar em todo o lado: Excel, CSV, Google Sheets, Airtable, Notion — tudo suportado.
Preços e limitações
O Thunderbit oferece um plano gratuito (6 páginas/mês) e um teste de 10 páginas. Os planos pagos começam em cerca de para 500 créditos (1 crédito = 1 linha). A extensão Chrome é necessária para o modo browser. As funcionalidades de IA consomem créditos, por isso uso intensivo em milhares de artigos exigirá um plano pago — mas, para a maioria das equipas de negócio que fazem monitorização diária ou investigação semanal, o custo é modesto.
Manutenção: 🟢 Baixa. A IA lê a página de novo a cada execução.
Melhor para: Equipas de vendas, RP e operações sem perfil técnico que querem dados de notícias diários sem construir ou manter scrapers.
Para uma análise mais profunda de como o Thunderbit trata , consulte o nosso guia.
2. SerpApi — Melhor para dados estruturados de Google Notícias SERP
 é uma API específica para SERP que devolve JSON estruturado a partir dos resultados do Google Notícias. Se o seu caso de uso é “dê-me os principais resultados do Google Notícias para uma palavra-chave, estruturados e prontos para um dashboard”, o SerpApi é uma boa opção. Devolve títulos, fonte, data, snippet e miniatura — mas não o texto completo do artigo. Seria necessário um passo adicional (ou outra ferramenta) para obter o corpo real do artigo.
é uma API específica para SERP que devolve JSON estruturado a partir dos resultados do Google Notícias. Se o seu caso de uso é “dê-me os principais resultados do Google Notícias para uma palavra-chave, estruturados e prontos para um dashboard”, o SerpApi é uma boa opção. Devolve títulos, fonte, data, snippet e miniatura — mas não o texto completo do artigo. Seria necessário um passo adicional (ou outra ferramenta) para obter o corpo real do artigo.
Funcionalidades principais:
- Saída JSON estruturada a partir de SERPs do Google Notícias
- Anti-deteção tratado do lado deles (específico de SERP)
- Suporta vários locais e idiomas do Google Notícias
Preços: Plano gratuito com 250 pesquisas/mês. Os planos pagos começam em $75/mês para 5.000 pesquisas — cerca de $15 por 1.000 resultados.
Limitação: Devolve apenas snippets. Se precisar do texto completo do artigo, o SerpApi é o primeiro passo, não a pipeline inteira.
Manutenção: 🟢 Baixa (API gerida, eles tratam das alterações do Google).
Melhor para: Programadores a construir dashboards de monitorização de notícias ou a alimentar ferramentas analíticas com dados SERP.
3. ScraperAPI — Melhor API de scraping económica com rotação de proxies
 é uma API de scraping de uso geral, não específica para notícias, mas eficaz para obter páginas de notícias. O seu valor central é a rotação de proxies, renderização JavaScript e tratamento de CAPTCHA — a infraestrutura anti-bot que, de outra forma, teria de construir sozinho.
é uma API de scraping de uso geral, não específica para notícias, mas eficaz para obter páginas de notícias. O seu valor central é a rotação de proxies, renderização JavaScript e tratamento de CAPTCHA — a infraestrutura anti-bot que, de outra forma, teria de construir sozinho.
Funcionalidades principais:
- Rotação de proxies com IPs residenciais e de datacenter
- Renderização JavaScript para sites de notícias dinâmicos
- Tratamento de CAPTCHA
- Devolve HTML bruto — o conteúdo do artigo é analisado por si
Preços: Plano gratuito com 1.000 créditos/mês (mais créditos de teste). A renderização JS custa mais créditos por pedido. Os planos pagos começam em $49/mês. O custo normalizado é aproximadamente $1–$5 por 1.000 pedidos, dependendo do uso de JS.
Limitação: Sem análise de artigos integrada. Recebe HTML, não texto limpo. Combine com Newspaper4k ou com o seu próprio parser para extração de artigos.
Manutenção: 🟡 Média (trata do anti-bot, mas a lógica de extração é sua).
Melhor para: Programadores que querem infraestrutura anti-bot sem construir a sua própria rede de proxies.
4. Newsdata.io — Melhor API de notícias dedicada para metadados estruturados
 é uma API de notícias criada de raiz, cobrindo . Devolve dados estruturados — título, descrição, fonte, data, categorias, sentimento — e conteúdo completo do artigo nos planos premium.
é uma API de notícias criada de raiz, cobrindo . Devolve dados estruturados — título, descrição, fonte, data, categorias, sentimento — e conteúdo completo do artigo nos planos premium.
Funcionalidades principais:
- Pesquisa por palavra-chave, categoria, idioma, país
- Análise de sentimento incluída
- Arquivo histórico de notícias (planos pagos)
- Sem infraestrutura de scraping para gerir
Preços: Plano gratuito com 200 pedidos/dia e campos limitados. Os planos pagos desbloqueiam conteúdo completo e dados históricos. O custo por 1.000 resultados depende do nível do plano, mas fica na faixa dos $5–$15.
Limitação: Abrange as suas próprias fontes indexadas — não pode apontar para um URL arbitrário e dizer “extraia isto”. Se uma publicação de nicho não estiver no índice deles, não a encontrará aqui.
Manutenção: 🟢 Baixa (API de notícias totalmente gerida).
Melhor para: Equipas que precisam de metadados estruturados de notícias e não querem gerir qualquer infraestrutura de scraping.
5. Apify — Melhor plataforma cloud para fluxos de trabalho personalizados de scraping de notícias
 é uma plataforma cloud baseada em actors, com scrapers pré-construídos para Google Notícias, publicações específicas e extração geral de artigos. Fica num ponto intermédio entre no-code e desenvolvimento totalmente personalizado.
é uma plataforma cloud baseada em actors, com scrapers pré-construídos para Google Notícias, publicações específicas e extração geral de artigos. Fica num ponto intermédio entre no-code e desenvolvimento totalmente personalizado.
Funcionalidades principais:
- Actors pré-construídos para Google Notícias, extração de artigos e muito mais
- Suporta renderização JavaScript e execução em browser headless
- Execução cloud com agendamento
- Exportação para JSON, CSV, Excel, XML e mais
Preços: Plano gratuito com . Planos pagos a $49, $499 e $999/mês. O custo por 1.000 resultados varia consoante o actor — cerca de $1–$6 para actors de extração de notícias.
Limitação: Os actors pré-construídos são mantidos pela comunidade e podem quebrar quando os sites de notícias mudam. Exige mais configuração do que ferramentas puramente no-code.
Manutenção: 🟡 Média (os actors podem precisar de atualizações quando os sites mudam).
Melhor para: Equipas que querem execução cloud e se sentem confortáveis a escolher e configurar actors de marketplace.
6. Oxylabs — Melhor infraestrutura de scraping de nível empresarial
 é um serviço de scraping empresarial com um pool de mais de 100 milhões de proxies, resolução de CAPTCHA e renderização de browser. A sua API SERP Scraper lida com resultados do Google Notícias com geotargeting, e a API Web Scraper funciona para páginas de notícias arbitrárias.
é um serviço de scraping empresarial com um pool de mais de 100 milhões de proxies, resolução de CAPTCHA e renderização de browser. A sua API SERP Scraper lida com resultados do Google Notícias com geotargeting, e a API Web Scraper funciona para páginas de notícias arbitrárias.
Funcionalidades principais:
- Infraestrutura massiva de proxies com geotargeting
- API SERP Scraper para Google Notícias
- API Web Scraper para URLs arbitrários
- Saída JSON/CSV, pedidos concorrentes em grande escala
Preços: A partir de $49/mês para dados SERP. Preços empresariais personalizados para alto volume. Teste gratuito até 2.000 resultados.
Limitação: Caro para equipas pequenas. Concebido sobretudo para operações em grande escala.
Manutenção: 🟢 Baixa (API empresarial totalmente gerida).
Melhor para: Empresas que precisam de dados de notícias em alto volume, com geotargeting e fiabilidade empresarial.
7. ScrapingBee — Melhor para sites de notícias muito dependentes de JavaScript
 é uma API de scraping focada na renderização JavaScript com execução real de browser. Se o site de notícias de que precisa carrega conteúdo via JS no lado do cliente (e muitos sites modernos fazem isso), o ScrapingBee lida bem com isso.
é uma API de scraping focada na renderização JavaScript com execução real de browser. Se o site de notícias de que precisa carrega conteúdo via JS no lado do cliente (e muitos sites modernos fazem isso), o ScrapingBee lida bem com isso.
Funcionalidades principais:
- Chrome headless com rotação de proxies
- Tratamento de CAPTCHA
- Funcionalidade básica de “Article Extraction” para algumas páginas
- Devolve HTML bruto, JSON ou saída em estilo Markdown
Preços: Planos a partir de . Baseado em créditos, com renderização JS a custar mais. Créditos de teste disponíveis.
Limitação: A funcionalidade de extração de artigos é básica face às alternativas com IA. Devolve sobretudo HTML — ainda vai precisar de parsing na maioria dos fluxos de trabalho.
Manutenção: 🟡 Média (trata do anti-bot, mas a extração precisa de configuração do utilizador).
Melhor para: Programadores a extrair sites de notícias pesados em JS que querem HTML renderizado sem gerir browsers headless.
8. Scrapingdog — Melhor API SERP económica para notícias
 é uma API SERP económica com um endpoint dedicado para Google Notícias. Os tempos de resposta são rápidos (cerca de 2 segundos por pedido nos testes), e os preços são os mais competitivos desta lista entre as opções API.
é uma API SERP económica com um endpoint dedicado para Google Notícias. Os tempos de resposta são rápidos (cerca de 2 segundos por pedido nos testes), e os preços são os mais competitivos desta lista entre as opções API.
Funcionalidades principais:
- Endpoint dedicado para Google Notícias
- Saída JSON estruturada (títulos, fonte, data, snippets)
- Tempos de resposta rápidos
Preços: A partir de $40/mês para 400.000 pedidos — cerca de $0.10 por 1.000 resultados, o que é extremamente barato. Plano gratuito com 1.000 créditos.
Limitação: Devolve apenas dados SERP (títulos, snippets), não o conteúdo completo do artigo. É o mesmo compromisso do SerpApi, mas por uma fração do preço.
Manutenção: 🟢 Baixa (API SERP gerida).
Melhor para: Programadores atentos ao orçamento que precisam de dados SERP do Google Notícias em escala.
9. Bright Data — Melhor para dados empresariais de notícias em escala
 é o gigante empresarial. A plataforma inclui um produto dedicado News Scraper, infraestrutura massiva de proxies, resolução de CAPTCHA, renderização de browser e entrega posterior para S3, Snowflake e mais.
é o gigante empresarial. A plataforma inclui um produto dedicado News Scraper, infraestrutura massiva de proxies, resolução de CAPTCHA, renderização de browser e entrega posterior para S3, Snowflake e mais.
Funcionalidades principais:
- Produto dedicado News Scraper
- Conjuntos de dados pré-construídos e recolha em tempo real
- Gestão automatizada de proxies e resolução de CAPTCHA
- Recolha agendada e alertas
- Exportações para JSON, CSV, NDJSON, S3, Snowflake, GCS, Azure, SFTP
Preços: A partir de cerca de em pay-as-you-go. Planos empresariais personalizados disponíveis. Teste gratuito de 1.000 pedidos.
Limitação: Estrutura de preços complexa com compromissos mínimos. Concebido sobretudo para orçamentos empresariais.
Manutenção: 🟢 Baixa (gerido a nível empresarial, alta fiabilidade).
Melhor para: Grandes organizações que precisam de pipelines fiáveis e de alto volume para dados de notícias.
10. Octoparse — Melhor scraper visual no-code para páginas de notícias
 O Octoparse é uma aplicação desktop com um construtor visual de fluxos de trabalho “point-and-click”. Tem modelos pré-construídos para sites de notícias comuns, lida com paginação e scroll infinito, e oferece execução cloud para tarefas agendadas.
O Octoparse é uma aplicação desktop com um construtor visual de fluxos de trabalho “point-and-click”. Tem modelos pré-construídos para sites de notícias comuns, lida com paginação e scroll infinito, e oferece execução cloud para tarefas agendadas.
Funcionalidades principais:
- Construtor visual de fluxos de trabalho por clique
- Modelos pré-construídos para sites de notícias
- Execução cloud com agendamento
- Rotação de IP e resolução automática de CAPTCHA
- Exportação para Excel, CSV, JSON, bases de dados, Google Sheets
Preços: Plano gratuito com 10 tarefas e 50 mil exportações/mês. Planos pagos a partir de ~$89/mês.
Limitação: A extração baseada em seletores significa que os scrapers quebram quando os sites de notícias atualizam os layouts. Exige correções manuais — e os sites de notícias mudam de layout com muita frequência.
Manutenção: 🟡 Média (os modelos ajudam, mas os seletores ainda podem quebrar).
Melhor para: Utilizadores que querem um construtor visual no-code e não se importam com manutenção ocasional de modelos.
11. ParseHub — Melhor opção no-code gratuita para iniciantes
 O ParseHub é um scraper visual por clique com um plano gratuito generoso. Lida com conteúdo renderizado em JavaScript e funciona bem para projetos de investigação pontuais ou extração de notícias em pequena escala.
O ParseHub é um scraper visual por clique com um plano gratuito generoso. Lida com conteúdo renderizado em JavaScript e funciona bem para projetos de investigação pontuais ou extração de notícias em pequena escala.
Funcionalidades principais:
- Seleção visual de elementos (sem programação)
- Lida com páginas renderizadas em JavaScript
- Exportação para CSV/JSON
- Plano gratuito: 5 projetos, 200 páginas por execução
Preços: Plano gratuito com 5 projetos e 200 páginas/execução. Planos pagos a partir de $189/mês.
Limitação: Baseado em seletores CSS, por isso os scrapers quebram com frequência quando os layouts mudam. Escalabilidade limitada e mais lento do que ferramentas API. Os utilizadores no Reddit e em fóruns assinalam consistentemente a curva de aprendizagem e a fragilidade.
Manutenção: 🔴 Alta (os seletores quebram com frequência, sem adaptação por IA).
Melhor para: Iniciantes a fazer pequenos projetos pontuais de investigação de notícias que querem um ponto de partida gratuito.
12. Newscatcher — Melhor API de notícias para RP e monitorização de media
 é uma API dedicada de agregação de notícias que cobre . Foi criada de raiz para monitorização de media, tracking de RP e análise de tendências, com campos enriquecidos por NLP como sentimento, resumo e extração de entidades.
é uma API dedicada de agregação de notícias que cobre . Foi criada de raiz para monitorização de media, tracking de RP e análise de tendências, com campos enriquecidos por NLP como sentimento, resumo e extração de entidades.
Funcionalidades principais:
- Cobertura de mais de 70.000 fontes
- Enriquecimentos NLP: sentimento, resumo, extração de entidades, desduplicação, clustering
- Pesquisa por palavra-chave, tópico, fonte, idioma, país
- Acesso ao arquivo histórico
Preços: Preços empresariais (orçamentos personalizados). Sem plano gratuito público para testes, embora possam oferecer testes mediante pedido.
Limitação: O preço focado em empresas pode ficar fora do alcance de equipas pequenas. Sem plano gratuito self-service.
Manutenção: 🟢 Baixa (API totalmente gerida).
Melhor para: Equipas de RP e monitorização de media em empresas de média a grande dimensão.
13. Webz.io — Melhor para arquivos históricos de notícias e dados para treino de LLM
 é uma plataforma de dados de notícias com um arquivo histórico gigantesco — milhares de milhões de artigos ao longo de anos. Fornece feeds em tempo real e acesso a dados históricos, com saída JSON estruturada que inclui texto completo do artigo, metadados e enriquecimentos.
é uma plataforma de dados de notícias com um arquivo histórico gigantesco — milhares de milhões de artigos ao longo de anos. Fornece feeds em tempo real e acesso a dados históricos, com saída JSON estruturada que inclui texto completo do artigo, metadados e enriquecimentos.
Funcionalidades principais:
- Milhares de milhões de artigos em arquivo histórico
- Feeds em tempo real e acesso a dados históricos
- Texto completo do artigo com metadados estruturados
- Popular entre equipas de IA/ML para conjuntos de treino e pipelines RAG
Preços: Preços empresariais/personalizados (baseados no volume de dados). Sem plano gratuito self-service para notícias.
Limitação: Não foi concebido para utilizadores ocasionais. Apenas preços empresariais.
Manutenção: 🟢 Baixa (feed de dados totalmente gerido).
Melhor para: Equipas de IA/ML a construir conjuntos de treino e equipas empresariais que precisam de arquivos históricos de notícias profundos.
14. Newspaper4k — Melhor biblioteca open-source para extração de artigos
 é uma biblioteca Python (sucessora do Newspaper3k) concebida de raiz para extrair conteúdo limpo de artigos. Remove anúncios, sidebars e navegação, e devolve apenas o artigo: título, texto, autores, data de publicação, imagens, palavras-chave e resumo.
é uma biblioteca Python (sucessora do Newspaper3k) concebida de raiz para extrair conteúdo limpo de artigos. Remove anúncios, sidebars e navegação, e devolve apenas o artigo: título, texto, autores, data de publicação, imagens, palavras-chave e resumo.
Funcionalidades principais:
- Extrai o corpo limpo do artigo, removendo ruído
- Devolve título, autores, data de publicação, imagens, palavras-chave, resumo
- Totalmente grátis e open-source
- Leve e rápida para páginas HTML estáticas
Preços: Grátis. Mas vai precisar do seu próprio servidor, infraestrutura de proxies e tempo de desenvolvimento.
Limitação: Sem tratamento anti-bot integrado. Falha em sites de notícias muito dinâmicos/renderizados em JS. Exige conhecimentos de Python e uma pipeline personalizada para qualquer coisa além da extração básica. Quando a estrutura HTML de um site muda, terá de corrigir isso.
Manutenção: 🔴 Alta (quebra quando o HTML do site muda, requer correções manuais).
Melhor para: Programadores Python a construir pipelines personalizadas de extração de notícias que querem controlo máximo sobre o parsing dos artigos.
15. HasData — Melhor API SERP económica com endpoint de notícias
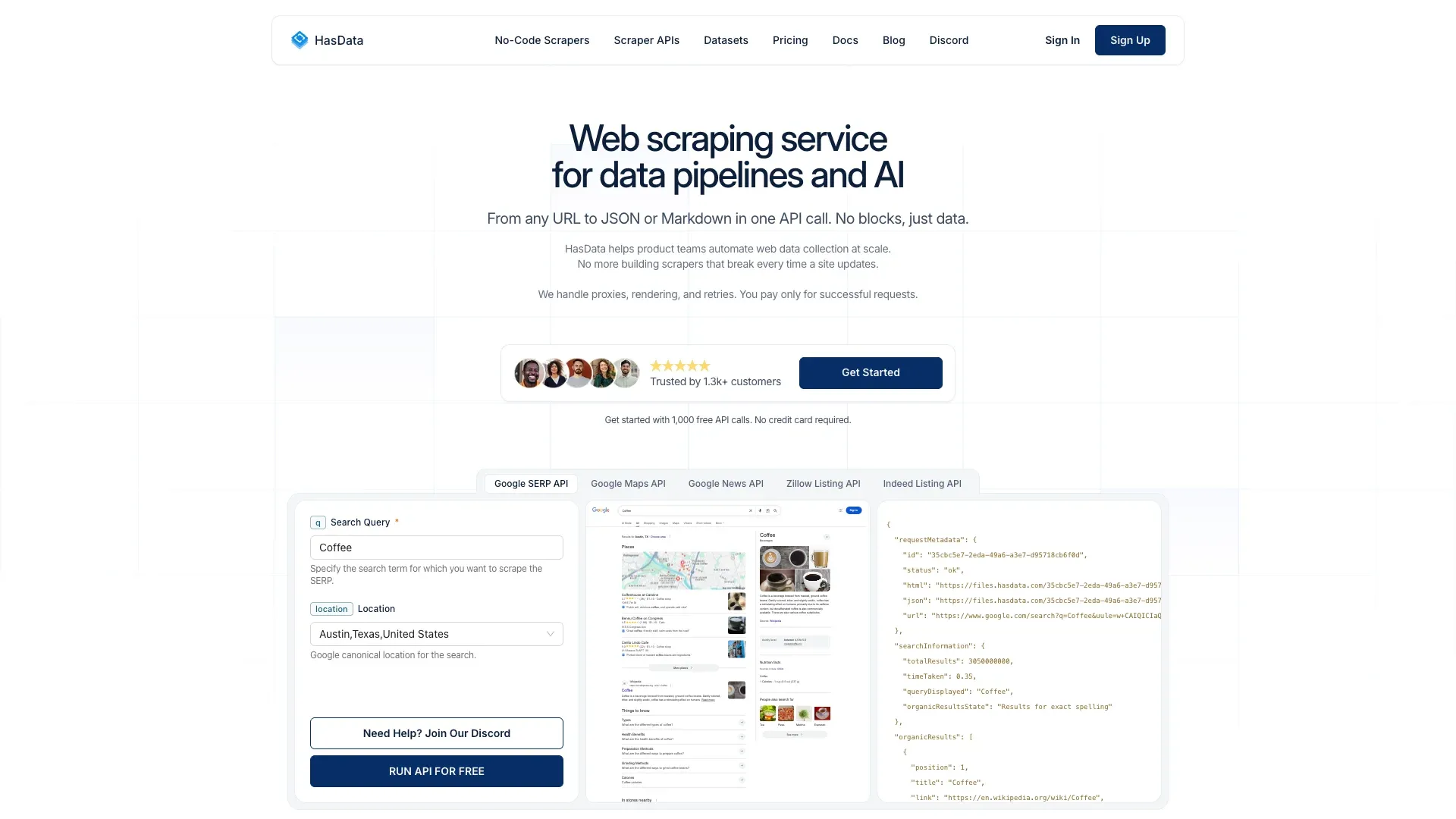 é uma API SERP com um endpoint dedicado para Google Notícias. Devolve JSON estruturado com resultados de notícias a preços competitivos.
é uma API SERP com um endpoint dedicado para Google Notícias. Devolve JSON estruturado com resultados de notícias a preços competitivos.
Funcionalidades principais:
- Endpoint dedicado para Google Notícias
- Saída JSON estruturada
- Tempo de resposta de cerca de 3–4 segundos por pedido
- Créditos grátis para teste
Preços: A partir de (5 créditos por pedido de notícias = 40.000 pedidos). Isso dá cerca de $0.25–$0.60 por 1.000 resultados.
Limitação: Devolve dados SERP (títulos, snippets), não o conteúdo completo do artigo.
Manutenção: 🟢 Baixa (API SERP gerida).
Melhor para: Equipas com orçamento limitado que precisam de dados SERP do Google Notícias sem o preço do SerpApi.
Padrões que vale a pena notar
Depois de trabalhar com as 15 ferramentas, alguns padrões destacam-se.
As APIs SERP (SerpApi, Scrapingdog, HasData) são excelentes para dados estruturados de títulos, mas deixam-no sem resposta quando precisa do texto completo do artigo. As APIs de notícias dedicadas (Newsdata.io, Newscatcher, Webz.io) resolvem o problema dos metadados de forma brilhante, mas não conseguem extrair URLs arbitrários. As ferramentas no-code (Thunderbit, Octoparse, ParseHub) dão-lhe flexibilidade para extrair qualquer página — embora os perfis de manutenção variem imenso. E o Newspaper4k oferece a extração de artigos mais limpa, se estiver disposto a construir e manter a pipeline por si.
API vs. No-code vs. Open-source: o custo real por 1.000 artigos
Ninguém mais normaliza esta comparação entre todas as categorias. Aqui está a conta:
| Método | Tempo de configuração | Custo por 1K artigos | Manutenção | Melhor para |
|---|---|---|---|---|
| Open-source (Newspaper4k) | Horas–dias | $0 (mas com custos de servidor + tempo de desenvolvimento) | 🔴 Alta | Programadores com necessidades personalizadas |
| API de notícias (Newsdata.io, Newscatcher, Webz.io) | Minutos | $5–$50+ | 🟢 Baixa | Dados estruturados, arquivos históricos |
| API de scraping (ScraperAPI, ScrapingBee, Oxylabs) | 30 min | $1–$5 | 🟡 Média | Programadores que querem tratamento anti-bot |
| IA no-code (Thunderbit, Octoparse, ParseHub) | 2 minutos | $3–$15 | 🟢–🟡 | Utilizadores de negócio, equipas não técnicas |
O custo oculto das ferramentas open-source “grátis” é o tempo de desenvolvimento. Um programador sénior a passar 4 horas por mês a corrigir uma pipeline quebrada do Newspaper4k? Isso não é grátis — é caro.
No outro extremo, APIs empresariais como Webz.io e Newscatcher têm pouca manutenção, mas trazem preços que só fazem sentido em escala.
Para a maioria das equipas de negócio com quem falo, o ponto ideal é uma ferramenta de IA no-code (como o Thunderbit) para scraping flexível e ad hoc, ou uma API de notícias dedicada para monitorização estruturada e contínua.
O problema da manutenção: porque é que a maioria dos scrapers de notícias quebra (e quais não quebram)
Isto merece uma secção própria.
É a queixa número um que vejo em fóruns, tickets de suporte e conversas com utilizadores. Os sites de notícias mudam de layout constantemente — por vezes semanalmente. Um scraper construído com seletores CSS ou XPath pode funcionar na perfeição hoje e devolver lixo amanhã.
Aqui está como as 15 ferramentas se distribuem no espectro da manutenção:
| Nível de manutenção | Ferramentas | O que acontece quando um site muda |
|---|---|---|
| 🟢 Baixa (adaptativo por IA ou API gerida) | Thunderbit, SerpApi, Newsdata.io, Newscatcher, Webz.io, Scrapingdog, HasData, Oxylabs, Bright Data | A IA relê a página, ou o fornecedor da API trata disso. Não precisa de tocar em nada. |
| 🟡 Média (modelo + proxy) | ScraperAPI, ScrapingBee, Apify, Octoparse | O anti-bot é tratado, mas a lógica de extração ou o actor/modelo pode precisar de atualização. |
| 🔴 Alta (baseada em seletores) | ParseHub, Newspaper4k | Quando o site muda, o scraper quebra. Corrige manualmente os seletores ou as regras de parsing. |
A abordagem do Thunderbit merece destaque específico: como a IA lê a estrutura atual da página sempre que executa um scraping, não há seletores hardcoded para manter. Já vi os nossos utilizadores extraírem as mesmas fontes de notícias durante meses sem precisarem de atualizar a configuração, mesmo depois de esses sites terem feito alterações de layout. Esse é o tipo de fiabilidade que interessa quando está a preparar um briefing diário de notícias ou um relatório semanal de concorrência.
Texto limpo de artigos: quais scrapers de notícias realmente removem o ruído?
“Consegui os dados, mas estão cheios de anúncios, menus de navegação e lixo na sidebar.” É mais ou menos três em cada cinco perguntas de suporte que vejo sobre extração de notícias.
Aqui está a análise honesta:
| Capacidade de texto limpo | Ferramentas |
|---|---|
| Devolve texto limpo do artigo de forma nativa | Newspaper4k, Thunderbit (com scraping de subpáginas + Field AI Prompt), Newsdata.io (premium), Webz.io, Bright Data (News Scraper), Newscatcher |
| Devolve apenas títulos/snippets (sem texto completo) | SerpApi, Scrapingdog, HasData, Oxylabs (modo SERP) |
| Devolve HTML bruto (o utilizador tem de analisar) | ScraperAPI, ScrapingBee |
| Varia consoante a configuração | Apify, Octoparse, ParseHub |
O Newspaper4k é o padrão de ouro para remover ruído de páginas de notícias normais — foi literalmente construído para isso. Mas exige Python e falha em sites muito dependentes de JS.
O Field AI Prompt do Thunderbit é o equivalente no-code: pode instruir a IA por coluna para “extrair apenas o corpo principal do artigo, excluindo navegação e anúncios”, e também pode etiquetar, categorizar ou resumir o texto durante a extração. Para equipas que precisam de texto limpo de artigos sem escrever código, esta é a opção mais prática que encontrei.
Se tiver interesse em como a extração com IA se compara aos métodos tradicionais, o nosso artigo sobre aprofunda o tema.
Extrair notícias de forma responsável: bases legais e éticas
Não encontrei nenhum artigo concorrente que aborde isto — uma lacuna que vale a pena preencher, especialmente para leitores empresariais.
robots.txt: Verifique sempre. Muitos grandes sites de notícias proíbem explicitamente a extração de certos caminhos. Ferramentas responsáveis (incluindo o Thunderbit) permitem scraping baseado em browser que respeita o contexto da sessão, mas ainda assim deve rever o robots.txt do site antes de executar tarefas em grande escala.
Termos de Serviço: Há uma diferença significativa entre extrair metadados (títulos, datas, URLs) para investigação interna e republicar artigos completos protegidos por direitos de autor. O primeiro é, em geral, de risco mais baixo; o segundo pode gerar exposição legal real. Casos recentes como e mostram que o panorama legal ainda está em evolução.
Boas práticas: Use APIs oficiais quando disponíveis (Google News RSS, Newsdata.io, Newscatcher). Faça cache de forma responsável. Limite a taxa de pedidos. Nunca contorne paywalls. Várias ferramentas desta lista — incluindo Thunderbit, ScraperAPI e Bright Data — oferecem limitação de taxa integrada ou funcionalidades de scraping ético que ajudam a manter-se dentro dos limites.
Este artigo é informativo e não constitui aconselhamento jurídico. Se estiver a fazer scraping em escala empresarial, consulte a sua equipa jurídica.
Como o Thunderbit encaixa no seu fluxo de trabalho de scraping de notícias
Como a minha equipa construiu o Thunderbit, conheço melhor do que ninguém os seus pontos fortes e limites para scraping de notícias. Eis como o fluxo de trabalho realmente funciona.
O fluxo típico para um utilizador de negócio é o seguinte:
- Abra uma página de notícias (resultados do Google Notícias, homepage de uma publicação, uma página de pesquisa por tema) no Chrome.
- Clique na extensão Thunderbit e carregue em AI Suggest Fields. O Thunderbit lê a página e propõe colunas — título, data, fonte, URL, snippet, imagem, etc.
- Ajuste as colunas se necessário. Quer classificação de sentimento? Adicione uma coluna com um Field AI Prompt como “classificar o sentimento como positivo, neutro ou negativo.” Quer apenas artigos de uma categoria específica? Adicione um prompt de filtro.
- Clique em Scrape. Escolha o modo Browser (usa a sua sessão, bom para sites que bloqueiam IPs cloud) ou o modo Cloud (mais rápido, processa até 50 páginas de cada vez).
- Faça Scrape Subpages para visitar cada URL de artigo e extrair o corpo completo, autor, data de publicação e imagens.
- Exportar para Excel, CSV, , Airtable ou Notion.
Para monitorização contínua, o Raspador Agendado permite definir execuções diárias ou semanais com intervalos em linguagem natural (por exemplo, “todas as segundas a sextas às 8h”). E como o Thunderbit suporta , a monitorização internacional de notícias é simples.
Onde o Thunderbit é menos ideal: fazer scraping de milhões de artigos por mês ao menor custo possível por unidade — nessa situação, uma API empresarial como Bright Data ou Webz.io será mais rentável. E se precisar de enriquecimento NLP profundo (extração de entidades, clustering, desduplicação) incorporado na resposta da API, o Newscatcher foi criado especificamente para isso.
Pode experimentar o Thunderbit gratuitamente através da — sem necessidade de cartão de crédito.
Como escolher o scraper de notícias certo
A minha folha de apoio, condensada a partir de testes com as 15 ferramentas:
- Utilizador empresarial não técnico que quer dados diários de notícias? Comece com o Thunderbit. Dois cliques, sem código, a IA trata das alterações de layout.
- Programador a construir um pipeline de monitorização? SerpApi ou Scrapingdog para dados SERP. ScraperAPI ou ScrapingBee para HTML bruto com anti-bot.
- Equipa empresarial que precisa de escala e fiabilidade? Bright Data ou Oxylabs.
- Equipa de RP a seguir menções à marca em milhares de fontes? Newscatcher ou Newsdata.io.
- Investigador a construir um corpus de texto? Newspaper4k (se se sentir à vontade com Python) ou scraping de subpáginas do Thunderbit (se não se sentir).
- Engenheiro de IA a alimentar um pipeline RAG? Thunderbit API ou Webz.io para texto de artigos limpo e estruturado.
- Com orçamento apertado? Scrapingdog para API, plano gratuito do Thunderbit para no-code, Newspaper4k para open-source.
A ferramenta certa depende da sua tolerância à manutenção, orçamento e nível de competências técnicas. Não tem a certeza? Comece por um plano gratuito — a maioria destas ferramentas oferece um — e veja qual o fluxo de trabalho que se adapta à sua realidade.
Para mais opções e comparações, o nosso resumo dos cobre o panorama mais amplo. E, se quiser perceber antes de escolher uma ferramenta, esse guia é um bom ponto de partida.
Conclusão
A extração de notícias em 2026 é um problema resolvido — escolha a ferramenta certa para a sua situação e os dados fluem. As recomendações “tamanho único” acabaram. As APIs SERP são ótimas para títulos, mas não lhe dão texto de artigos. As APIs de notícias dedicadas são fantásticas para metadados estruturados, mas não conseguem extrair URLs arbitrários. As ferramentas no-code com IA, como o Thunderbit, dão-lhe flexibilidade e baixa manutenção, enquanto as bibliotecas open-source lhe dão controlo ao custo dos seus fins de semana.
A minha recomendação honesta: decida se precisa de títulos, texto completo de artigos ou metadados enriquecidos — depois associe isso ao nível de manutenção e orçamento que consegue suportar. E, se quiser ver como é a extração moderna de notícias adaptativa por IA sem escrever uma única linha de código, . Acho que vai ficar surpreendido com o quanto consegue fazer em apenas alguns cliques.
Boa extração — e que o texto dos seus artigos esteja sempre limpo, os seus seletores nunca quebrem e a exportação vá parar à folha de cálculo certa.
FAQs
1. Qual é o melhor scraper de notícias para utilizadores não técnicos?
O Thunderbit é a opção mais forte para utilizadores não técnicos. O seu fluxo de trabalho com IA e 2 cliques não exige programação nem seletores CSS. A IA lê automaticamente a estrutura da página, sugere campos de extração e adapta-se quando os layouts mudam — por isso não precisa de manter nada. Também exporta diretamente para Google Sheets, Airtable e Notion.
2. Posso obter o texto completo dos artigos nos scrapers de notícias, ou só os títulos?
Depende da ferramenta. APIs SERP como SerpApi, Scrapingdog e HasData devolvem apenas títulos e snippets. APIs de notícias dedicadas como Newsdata.io e Webz.io devolvem o texto completo nos planos premium. Ferramentas no-code como o Thunderbit podem extrair o texto completo do artigo através de scraping de subpáginas, e o Newspaper4k foi criado especificamente para extração limpa de artigos em Python. Verifique sempre se uma ferramenta devolve HTML bruto, snippets ou o corpo limpo do artigo antes de decidir.
3. Os scrapers de notícias quebram quando os websites mudam de layout?
Ferramentas baseadas em seletores (ParseHub, Octoparse, Newspaper4k, pipelines Scrapy personalizadas) quebram com frequência quando os sites de notícias atualizam os layouts — e isso acontece muitas vezes. Ferramentas adaptativas por IA como o Thunderbit relêem a estrutura da página a cada execução, por isso as mudanças de layout não quebram o fluxo. APIs geridas (SerpApi, Newsdata.io, Newscatcher) tratam das mudanças do lado deles. Se a manutenção for uma preocupação, dê prioridade às ferramentas classificadas como 🟢 Baixa na tabela comparativa.
4. Qual é a forma mais barata de extrair notícias em escala?
Para scraping via API, o Scrapingdog oferece o custo por pedido mais baixo (a partir de cerca de $0.10 por 1.000 resultados). Para scraping no-code, o plano gratuito do Thunderbit cobre pequenos projetos, e os planos pagos começam em cerca de $9/mês. Para open-source, o Newspaper4k é grátis — mas tenha em conta o tempo de desenvolvimento e os custos de servidor, que podem aumentar rapidamente.
5. É legal fazer scraping de sites de notícias?
Extrair dados publicamente acessíveis para investigação interna é, em geral, de risco mais baixo, mas republicar artigos completos protegidos por direitos de autor pode criar exposição legal. Verifique sempre o robots.txt e os Termos de Serviço de um site antes de fazer scraping. Use APIs oficiais quando existirem, respeite os limites de taxa e nunca contorne paywalls. Casos recentes como hiQ v. LinkedIn e Meta v. Bright Data mostram que o panorama legal ainda está em evolução. Para scraping em escala empresarial, consulte a sua equipa jurídica.
Saiba mais