

Quase metade de todo o tráfego da internet já é gerado por bots. A maioria deles está coletando links, dados e URLs em grande escala. Se você ainda faz isso manualmente, está ficando para trás.
Teste 12 ferramentas de extração de links — de extensões de Chrome com IA a bibliotecas em Python — para descobrir quais realmente entregam resultados quando você precisa raspar milhares de URLs com rapidez.
Veja o que encontrei.
Por que os extratores de links são importantes
Vamos ser sinceros: a web está transbordando de dados, e as empresas estão correndo para transformar esse caos em insights acionáveis. Extratores de links e extratores de URL já são essenciais para equipes que querem:
- Gerar leads: equipes de vendas podem coletar links de perfis de empresas em diretórios ou no LinkedIn em poucos minutos e depois enviar essas URLs para ferramentas que extraem informações de contato. Chega de cliques sem fim.
- Agrupar conteúdo e turbinar o SEO: profissionais de marketing podem reunir todas as URLs de artigos de um blog, monitorar backlinks de concorrentes ou auditar a estrutura do site em busca de links quebrados.
- Monitorar concorrentes e fazer pesquisa de mercado: times de operações podem coletar automaticamente links de novos produtos, páginas de preço ou comunicados à imprensa — acompanhando a concorrência sem esforço.
- Automatizar fluxos de trabalho e economizar tempo: os extratores de links modernos lidam com URLs em massa, navegam por subpáginas e exportam dados em formatos estruturados (CSV, Excel, Google Sheets, Notion e muito mais). Isso significa fim das maratonas de copiar e colar e da limpeza de arquivos de texto bagunçados.
Considerando que dezenas de bilhões de páginas da web são rastreadas todos os dias, fazer isso manualmente simplesmente não é viável. O extrator de links certo é como ter um assistente turbinado, que nunca se cansa, nunca deixa um link passar e nunca pede pausa para o café.
Como escolhemos os melhores extratores de links
Com tantas opções no mercado, escolher o extrator de links ideal pode parecer um speed dating em uma conferência de tecnologia — todo mundo promete ser "a pessoa certa", mas só alguns realmente entregam. Veja como reduzi a lista aos 12 melhores:
- Facilidade de uso: pessoas sem conhecimento de programação conseguem usar sem precisar de um PhD em regex? Soluções no-code e low-code ganharam pontos extras.
- Raspagem em massa e em múltiplos níveis: consegue lidar com centenas de URLs ao mesmo tempo? Navega por subpáginas e segue links automaticamente?
- Exportação e integração: exporta para CSV, Excel, Google Sheets, Notion, Airtable ou via API? Quanto menos trabalho manual, melhor.
- Perfil de usuário e flexibilidade: é para usuários de negócios, analistas ou desenvolvedores? Algumas ferramentas são feitas para todo mundo; outras são mais específicas.
- Recursos avançados: reconhecimento orientado por IA, agendamento, escalabilidade em nuvem, limpeza de dados e templates para sites comuns.
- Preço e escalabilidade: há plano gratuito, pagamento por uso ou oferta corporativa? Avaliei o custo-benefício de cada uma.
Incluí desde extensões de navegador até plataformas corporativas, então tanto um fundador solo quanto uma equipe de dados de uma Fortune 500 vai encontrar uma opção adequada.
Thunderbit: o extrator de links mais inteligente para usuários de negócios
Vamos começar pelo topo. Thunderbit é minha principal recomendação para extração de links — e não só porque ajudei a construir a ferramenta. O Thunderbit é uma extensão de Chrome com IA para web scraping, pensada para usuários de negócios que querem resultados rápidos.
O que faz o Thunderbit se destacar? É como ter um estagiário de IA que realmente presta atenção. Você descreve em linguagem natural o que quer (“Capture todos os links de produtos e preços desta página”), e a IA do Thunderbit faz o restante. Não é preciso mexer em seletores nem escrever scripts.
Mas ele vai além:
- Suporte a URLs em massa: cole uma única URL ou uma lista com centenas — o Thunderbit processa tudo de uma vez.
- Navegação por subpáginas: precisa extrair links de uma página de lista e depois visitar cada página de detalhe para pegar mais URLs? A lógica de raspagem em múltiplas camadas do Thunderbit resolve isso.
- Exportação estruturada: depois de extrair os links, você pode renomear campos, categorizá-los e exportar diretamente para Google Sheets, Notion, Airtable, Excel ou CSV. Nada de dores de cabeça no pós-processamento.
Extraia links de qualquer site usando IA Get Started Free
O Thunderbit já conquistou a confiança de mais de 30.000 usuários no mundo todo — de equipes de vendas a corretores imobiliários e lojas de e-commerce independentes. E sim, existe um plano gratuito (raspe até 6 páginas, ou 10 com um bônus de teste), então você pode experimentar sem risco.
Experimente o Extrator de Links do Thunderbit Gratuitamente
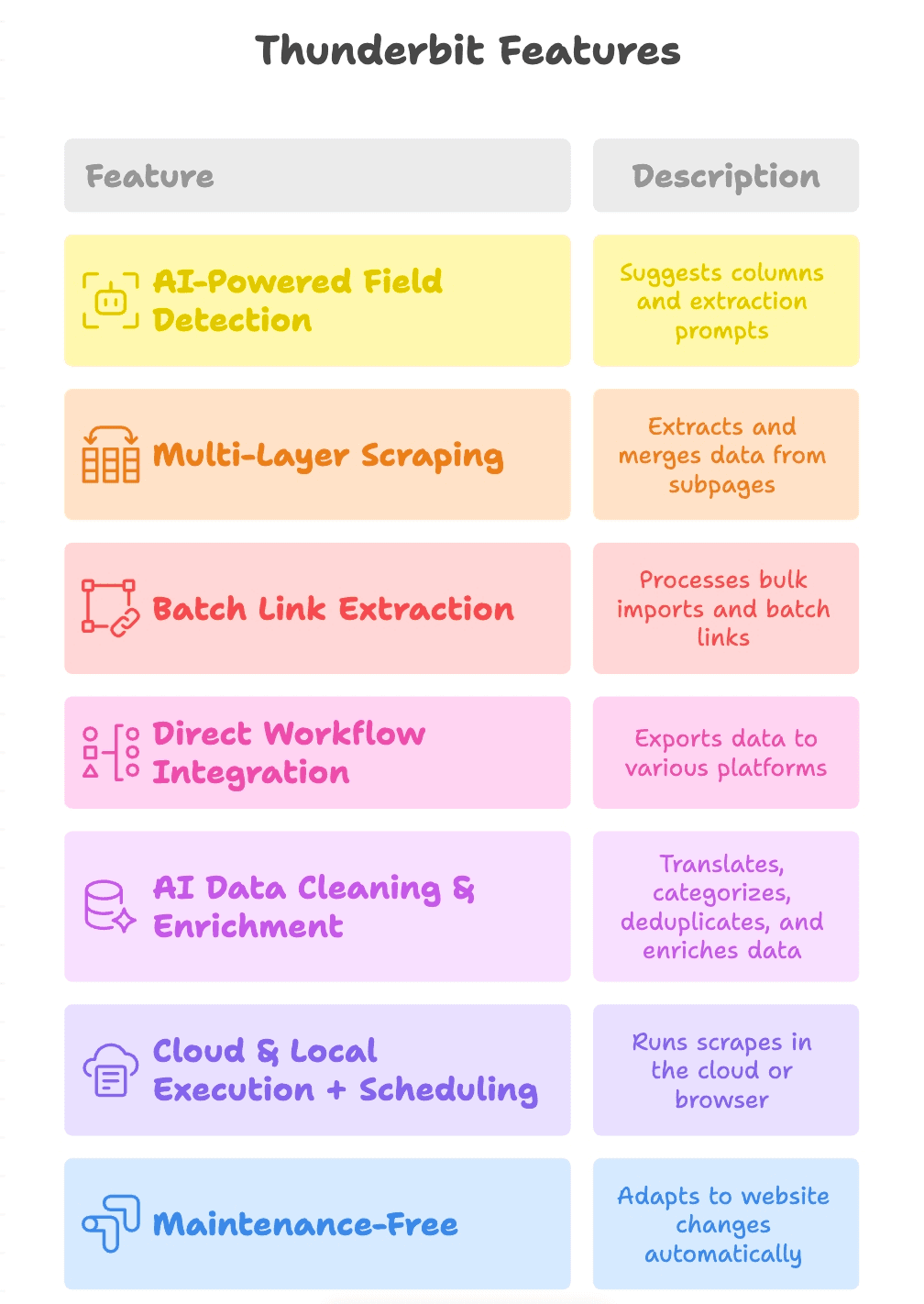
Recursos que fazem o Thunderbit se destacar
Vamos detalhar o que realmente diferencia o Thunderbit:
- Detecção de campos com IA: basta clicar em “AI Suggest Fields”, e o Thunderbit lê a página, sugere colunas (como “Link do Produto”, “URL do PDF”, “E-mail de Contato”) e até cria prompts de extração para cada campo.
- Raspagem em múltiplas camadas: o Thunderbit pode seguir links da página principal para subpáginas (como páginas de detalhes de produtos ou downloads de PDF), extrair mais links e reunir tudo em uma única tabela.
- Extração em lote de links: seja raspando uma página ou mil, o Thunderbit lida com importações em massa e extração em lote com facilidade.
- Integração direta com fluxos de trabalho: exporte os resultados para Google Sheets, Notion, Airtable ou baixe em CSV/Excel. Os dados chegam exatamente onde sua equipe precisa.
- Limpeza e enriquecimento de dados com IA: o Thunderbit pode traduzir, categorizar, remover duplicidades e até enriquecer seus dados durante a raspagem — entregando um resultado pronto para uso, não apenas um dump bruto.
- Execução em nuvem e local + agendamento: rode as raspagens na nuvem para ganhar velocidade ou no navegador em sites que exigem login. Agende tarefas recorrentes para manter os dados sempre atualizados.
- Sem manutenção: a IA do Thunderbit se adapta às mudanças dos sites, então você passa menos tempo corrigindo scrapers quebrados e mais tempo obtendo resultados.
Octoparse: scraper de links no-code para todos
Octoparse é um clássico no mundo da raspagem sem código. É um aplicativo de desktop (Windows/Mac) com interface visual, baseada em cliques. Você carrega uma página, clica nos links que quer e o Octoparse faz o resto.
- Ótimo para iniciantes: não precisa programar. Basta clicar, extrair e pronto.
- Lida com paginação e conteúdo dinâmico: o Octoparse pode clicar em botões “Next”, rolar a página e até fazer login em sites.
- Raspagem em nuvem e agendamento: os planos pagos permitem executar tarefas na nuvem e agendar processos recorrentes.
- Opções de exportação: baixe os dados em CSV, Excel, JSON ou envie para bancos de dados.
O plano gratuito é generoso para tarefas pequenas (até 10 tarefas e 50.000 linhas/mês), mas usuários mais intensivos vão precisar de um plano pago (a partir de cerca de US$ 75/mês).
Apify: extrator de URL flexível para fluxos de trabalho personalizados
Apify é o canivete suíço do web scraping. Ele oferece um marketplace de "actors" prontos (ferramentas de raspagem), além da possibilidade de escrever seus próprios scripts em JavaScript ou Python.
- Pronto para usar e personalizável: use actors da comunidade para tarefas comuns ou crie o seu para fluxos personalizados.
- Raspagem em massa e agendada: coloque URLs na fila, execute tarefas em paralelo e agende raspagens recorrentes.
- API em primeiro lugar: exporte para JSON, CSV, Excel ou Google Sheets e integre ao seu pipeline de dados.
- Pagamento por uso: créditos gratuitos todos os meses, depois cobrança conforme o uso.
O Apify é ideal para equipes semi-técnicas e desenvolvedores que querem flexibilidade e escalabilidade.
Bright Data URL Scraper: raspagem de links em nível corporativo
Bright Data foi feito para empresas que precisam raspar em grande escala. O Data Collector oferece um URL Scraper pré-configurado para trabalhos de alto volume.
- Lida com escalas gigantes: raspe milhares ou milhões de páginas, com infraestrutura robusta de proxies para evitar bloqueios.
- Templates prontos: scrapers pré-montados para e-commerce, redes sociais, imóveis e muito mais.
- Recursos corporativos: ferramentas de conformidade, suporte especializado e recursos avançados anti-bloqueio.
- Preço: começa em torno de US$ 350 por 100.000 carregamentos de página — claramente voltado para grandes empresas.
Se você é uma startup, talvez seja mais do que precisa. Mas, para raspagens de alto volume e críticas para o negócio, o Bright Data é uma potência.
WebHarvy: extrator visual de links com simplicidade de ponto e clique
WebHarvy é um aplicativo de desktop (Windows) que permite extrair links simplesmente clicando neles no navegador embutido.
- Extremamente simples: clique em um link e o WebHarvy destaca todos os elementos semelhantes para extração.
- Suporte a expressões regulares: padrões prontos para tarefas comuns, sem precisar programar.
- Exporta para Excel, CSV, JSON, XML, SQL: ótimo para usuários de negócios que querem os dados em formatos familiares.
- Licença vitalícia: pague uma vez e use para sempre.
Perfeito para pequenas empresas, pesquisadores ou qualquer pessoa que queira uma forma rápida e prática de obter links sem programar.
Web Scraper (extensão do Chrome): raspagem rápida de links no navegador
A extensão Web Scraper para Chrome é uma ferramenta gratuita e de código aberto que transforma seu navegador em um scraper.
- Defina sitemaps: diga como ele deve navegar e o que deve extrair.
- Lida com paginação e rastreamento em múltiplos níveis: navegue por categorias, subcategorias e páginas de detalhe.
- Exporta para CSV/XLSX: baixe os dados diretamente do navegador.
- Templates da comunidade: muitos sitemaps compartilhados para sites populares.
É perfeita para tarefas rápidas e pontuais, ou para estudantes e equipes pequenas com orçamento limitado.
ScraperAPI: scraper de links escalável para desenvolvedores
ScraperAPI é para desenvolvedores que querem buscar páginas em escala sem se preocupar com proxies, bloqueios ou CAPTCHAs.
- Baseado em API: envie uma URL e receba HTML ou dados já extraídos.
- Escala e proteção contra bots: rotação de proxies, renderização de JS e solução de CAPTCHA já incluídos.
- Integra com seu código: use com Python, Node.js ou qualquer linguagem.
- Preço: plano gratuito (~1000 chamadas de API), depois cobrança por requisição.
Ótimo para crawlers personalizados ou quando você precisa de confiabilidade e velocidade em escala.
ParseHub: scraper visual de links com seleção avançada
ParseHub é um aplicativo de desktop (Windows, Mac, Linux) que permite criar projetos de scraping visualmente.
- Seleção e navegação avançadas: clique, faça loops e extraia links condicionalmente — até mesmo de elementos dinâmicos ou ocultos.
- Lida com páginas aninhadas: navegue por categorias, depois páginas de detalhe e então extraia mais links.
- Exporta para CSV, Excel, JSON: execução na nuvem e acesso à API nos planos pagos.
- Plano gratuito: 5 projetos, até 200 páginas por execução.
O ParseHub é um favorito entre profissionais de marketing e pesquisadores que querem poder sem precisar codificar.
Scrapy: extrator de links em Python para desenvolvedores
Scrapy é o padrão ouro para desenvolvedores Python que querem controle total.
- Primeiro o código: crie spiders personalizados para rastrear e extrair links em qualquer escala.
- Suporta rastreamento distribuído: eficiente, assíncrono e altamente personalizável.
- Exporta para CSV, JSON, XML ou banco de dados: você controla a saída.
- Código aberto e gratuito: mas você precisará gerenciar seu próprio ambiente.
Se você domina Python, o Scrapy entrega um nível de potência difícil de superar.
Diffbot: scraper de links com IA para dados estruturados
Diffbot é o "cérebro de IA" do web scraping. Ele analisa páginas e devolve dados estruturados — incluindo links — sem necessidade de configuração manual.
- Reconhecimento automático de conteúdo: envie uma URL e receba dados estruturados (artigos, produtos, links etc.).
- Crawlbot e Knowledge Graph: rastreie sites inteiros ou consulte seu enorme índice da web.
- Baseado em API: integre com suas ferramentas de BI ou pipeline de dados.
- Preço corporativo: começa em torno de US$ 299/mês, mas o que você recebe acompanha o valor.
Melhor para empresas que querem dados limpos e estruturados sem precisar gerenciar scrapers.
Cheerio: scraper leve de links para Node.js
Cheerio é um parser de HTML rápido, com sintaxe parecida com jQuery, para Node.js.
- Muito rápido: processa HTML em milissegundos.
- Sintaxe familiar: se você conhece jQuery, vai se adaptar facilmente ao Cheerio.
- Ótimo para páginas estáticas: não renderiza JS, mas é perfeito para conteúdo renderizado no servidor.
- Código aberto e gratuito: combine com axios ou fetch para fazer as requisições.
Ideal para desenvolvedores que criam scripts personalizados e querem velocidade com simplicidade.
Puppeteer: automação de navegador para raspagem avançada de links
Puppeteer é uma biblioteca Node.js para controlar o Chrome em modo headless.
- Automação completa do navegador: carregue páginas, clique, role e interaja como um usuário real.
- Lida com conteúdo dinâmico e logins: perfeito para sites com muito JavaScript ou fluxos complexos.
- Controle fino: aguarde elementos, tire capturas de tela, intercepte requisições de rede.
- Código aberto e gratuito: mas consome mais recursos e é mais lento que ferramentas leves.
Use o Puppeteer quando precisar extrair links de sites que não colaboram com scrapers básicos.
Comparação rápida: qual extrator de links combina com suas necessidades?
Aqui vai uma comparação rápida das 12 ferramentas:
| Ferramenta | Melhor para | Suporte a massa e subpáginas | Opções de exportação | Preço |
|---|---|---|---|---|
| Thunderbit | Não programadores, negócios | Sim (IA, múltiplos níveis) | Excel, CSV, Sheets, Notion, Airtable | Teste gratuito, a partir de ~US$ 9/mês |
| Octoparse | Usuários no-code, analistas | Sim | CSV, Excel, JSON, armazenamento em nuvem | Plano gratuito, ~US$ 75/mês |
| Apify | Perfis semi-técnicos, devs | Sim | CSV, JSON, Sheets via API | Créditos gratuitos, cobrança por uso |
| Bright Data | Corporativo | Sim (alto volume) | CSV, JSON, NDJSON via API | ~US$ 350/100k páginas |
| WebHarvy | Não programadores, desktop | Sim | Excel, CSV, JSON, XML, SQL | Licença paga |
| Web Scraper Extension | Qualquer pessoa, rápido/gratuito | Sim | CSV, XLSX | Gratuito, código aberto |
| ScraperAPI | Desenvolvedores, usuários de API | Sim | JSON (HTML via API) | 1k requisições grátis, planos pagos |
| ParseHub | Não programadores, avançado | Sim | CSV, Excel, JSON, API | 5 projetos grátis, pago |
| Scrapy | Devs, Python | Sim | CSV, JSON, XML, banco de dados | Gratuito, código aberto |
| Diffbot | Corporativo, IA | Sim (rastreamento com IA) | JSON (dados estruturados via API) | ~US$ 299/mês+ |
| Cheerio | Devs, Node.js | Sim (código personalizado) | Personalizado (JSON etc.) | Gratuito, código aberto |
| Puppeteer | Devs, sites complexos | Sim (automação completa) | Personalizado (saída via script) | Gratuito, código aberto |
Como escolher o scraper de links certo para o seu negócio
Então, como decidir? Aqui está meu guia rápido:
- Sem habilidades de programação? Comece com Thunderbit, Octoparse, ParseHub, WebHarvy ou a extensão Web Scraper.
- Precisa de fluxos personalizados? Apify, ScraperAPI ou Cheerio são ótimas opções para desenvolvedores.
- Escala corporativa? Bright Data ou Diffbot foram feitos para isso.
- Desenvolvedor Python ou Node.js? Scrapy (Python) ou Cheerio/Puppeteer (Node.js) dão controle total.
- Quer exportar direto para Sheets/Notion? Thunderbit é a melhor escolha.
Escolha a ferramenta de acordo com seu nível técnico, volume de dados e necessidades de integração. A maioria oferece testes gratuitos, então vale experimentar sem medo.
Explore mais guias de web scraping Get Started Free
O valor único do Thunderbit para extração de links em 2026
Vamos voltar ao que torna o Thunderbit realmente diferente:
- Simplicidade impulsionada por IA: descreva o que você quer em português simples — a IA do Thunderbit cuida do resto.
- Raspagem em múltiplas camadas: extraia links da página principal, siga para subpáginas e capture mais URLs — tudo em um único fluxo.
- Importação em massa e processamento em lote: cole centenas de URLs, extraia links em massa e exporte dados estruturados na hora.
- Integração com fluxos de trabalho: exporte diretamente para Google Sheets, Notion, Airtable ou baixe em CSV/Excel.
- Manutenção zero: a IA do Thunderbit se adapta às mudanças dos sites, então você não fica constantemente corrigindo scrapers quebrados.
O Thunderbit faz a ponte entre "apenas extrair dados" e "obter dados que realmente podem ser usados". É a ferramenta que eu gostaria de ter tido anos atrás, quando estava afogado em tarefas manuais de dados.
Comece a Extrair Links Gratuitamente com o Thunderbit
Conclusão: extraia links com mais inteligência e acelere seu fluxo de trabalho
Dados da web são o combustível do crescimento dos negócios — e o extrator de links certo é o seu motor. Seja para montar listas de leads, monitorar concorrentes ou automatizar pesquisas, existe aqui uma ferramenta que se encaixa no seu caso e no seu nível técnico.
Se você quer ver como é a extração moderna de links, experimente o teste gratuito do Thunderbit. Acho que você vai se surpreender com o quanto dá para fazer em poucos cliques. E, se o Thunderbit não for a opção perfeita, teste algumas alternativas desta lista — nunca houve um momento melhor para automatizar o trabalho repetitivo e focar no que realmente importa.
Boa raspagem — e que seus links estejam sempre limpos, estruturados e prontos para ação. Se quiser aprofundar seus conhecimentos em web scraping, confira o Thunderbit Blog para mais guias e dicas.
Experimente o Extrator de Links do Thunderbit Gratuitamente Get Started Free
FAQs
1. Por que os extratores de links são essenciais?
Com quase metade do tráfego da internet vindo de bots e empresas raspando dados de forma agressiva, os extratores de links são vitais para transformar o caos da web em insights acionáveis. Eles ajudam a automatizar tarefas como geração de leads, agregação de conteúdo, auditorias de SEO e monitoramento de concorrentes, economizando enorme quantidade de tempo e esforço.
2. O que faz o Thunderbit se destacar entre outros extratores de links?
O Thunderbit usa IA para simplificar a raspagem — basta descrever seu objetivo em linguagem natural, e ele faz o resto. Ele suporta entrada de URLs em massa, raspagem em múltiplas camadas, detecção inteligente de campos e exportação fluida para plataformas como Google Sheets e Notion. É ideal para quem não programa e para usuários de negócios que querem resultados fortes sem complicação técnica.
3. Existem ferramentas de extração de links adequadas para desenvolvedores e fluxos personalizados?
Sim. Ferramentas como Apify, ScraperAPI, Cheerio, Puppeteer e Scrapy atendem desenvolvedores. Elas oferecem scripting, integração com API e flexibilidade para lidar com tarefas complexas de raspagem, operações em grande escala e automação avançada.
4. Quais ferramentas são melhores para quem não tem experiência em programação?
Thunderbit, Octoparse, ParseHub, WebHarvy e a extensão Web Scraper para Chrome são as melhores opções para usuários sem perfil técnico. Essas ferramentas oferecem interfaces visuais, templates prontos e recursos orientados por IA que tornam a extração de links acessível para todos.
5. Como devo escolher o extrator de links certo para minhas necessidades?
Considere suas habilidades técnicas, o volume de dados e suas necessidades de exportação. Quem não programa deve optar por ferramentas como Thunderbit ou Octoparse, enquanto desenvolvedores podem preferir Scrapy ou Puppeteer. Empresas podem considerar Bright Data ou Diffbot para operações em grande escala. Comece sempre com um teste gratuito para descobrir o que se encaixa melhor.




